- Mailing Lists
- in
- A Crash Course in Redis
Archives
- By thread 5343
-
By date
- June 2021 10
- July 2021 6
- August 2021 20
- September 2021 21
- October 2021 48
- November 2021 40
- December 2021 23
- January 2022 46
- February 2022 80
- March 2022 109
- April 2022 100
- May 2022 97
- June 2022 105
- July 2022 82
- August 2022 95
- September 2022 103
- October 2022 117
- November 2022 115
- December 2022 102
- January 2023 88
- February 2023 90
- March 2023 116
- April 2023 97
- May 2023 159
- June 2023 145
- July 2023 120
- August 2023 90
- September 2023 102
- October 2023 106
- November 2023 100
- December 2023 74
- January 2024 75
- February 2024 75
- March 2024 78
- April 2024 74
- May 2024 108
- June 2024 98
- July 2024 116
- August 2024 134
- September 2024 130
- October 2024 141
- November 2024 171
- December 2024 115
- January 2025 216
- February 2025 140
- March 2025 220
- April 2025 233
- May 2025 239
- June 2025 303
- July 2025 156
What is infrastructure monitoring?
Supporting older workers in a multigenerational workplace can benefit business
A Crash Course in Redis
A Crash Course in Redis
This is a sneak peek of today’s paid newsletter for our premium subscribers. Get access to this issue and all future issues - by subscribing today. Latest articlesIf you’re not a subscriber, here’s what you missed this month.
To receive all the full articles and support ByteByteGo, consider subscribing: Redis (Remote Dictionary Server) is an open-source (BSD licensed), in-memory database, often used as a cache, message broker, or streaming engine. It has rich support for data structures, including basic data structures like String, List, Set, Hash, SortedSet, and probabilistic data structures like Bloom Filter, and HyperLogLog. Redis is super fast. We can run Redis benchmarks with its own tool. The throughput can reach nearly 100k requests per second. In this issue, we will discuss why Redis is fast in its architectural design. Redis ArchitectureRedis is an in-memory key-value store. There are several important functions:
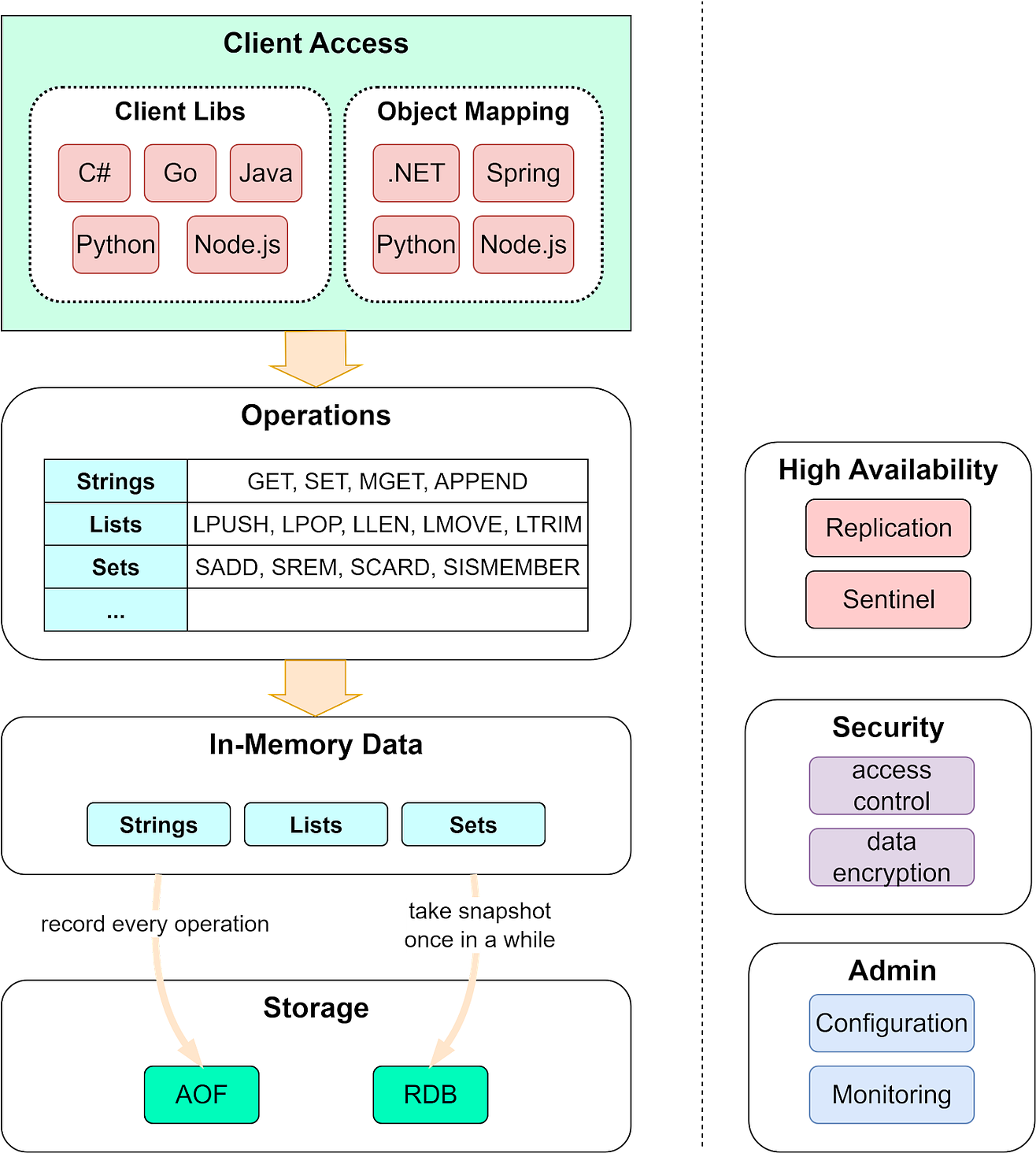
Below is a high-level diagram of Redis' architecture. Let’s walk through them one by one.
Client LibrariesThere are two types of clients to access Redis: one supports connections to the Redis database, and the other builds on top of the former and supports object mappings. Redis supports a wide range of languages, allowing it to be used in a variety of applications. In addition, the OM client libraries allow us to model, index, and query documents. Data OperationsRedis has rich support for value data types, including Strings, Lists, Sets, Hashes, etc. As a result, Redis is suitable for a wide range of business scenarios. Depending on the data types, Redis supports different operations. The basic operations are similar to a relational database, which supports CRUD (Create-Read-Update-Delete):
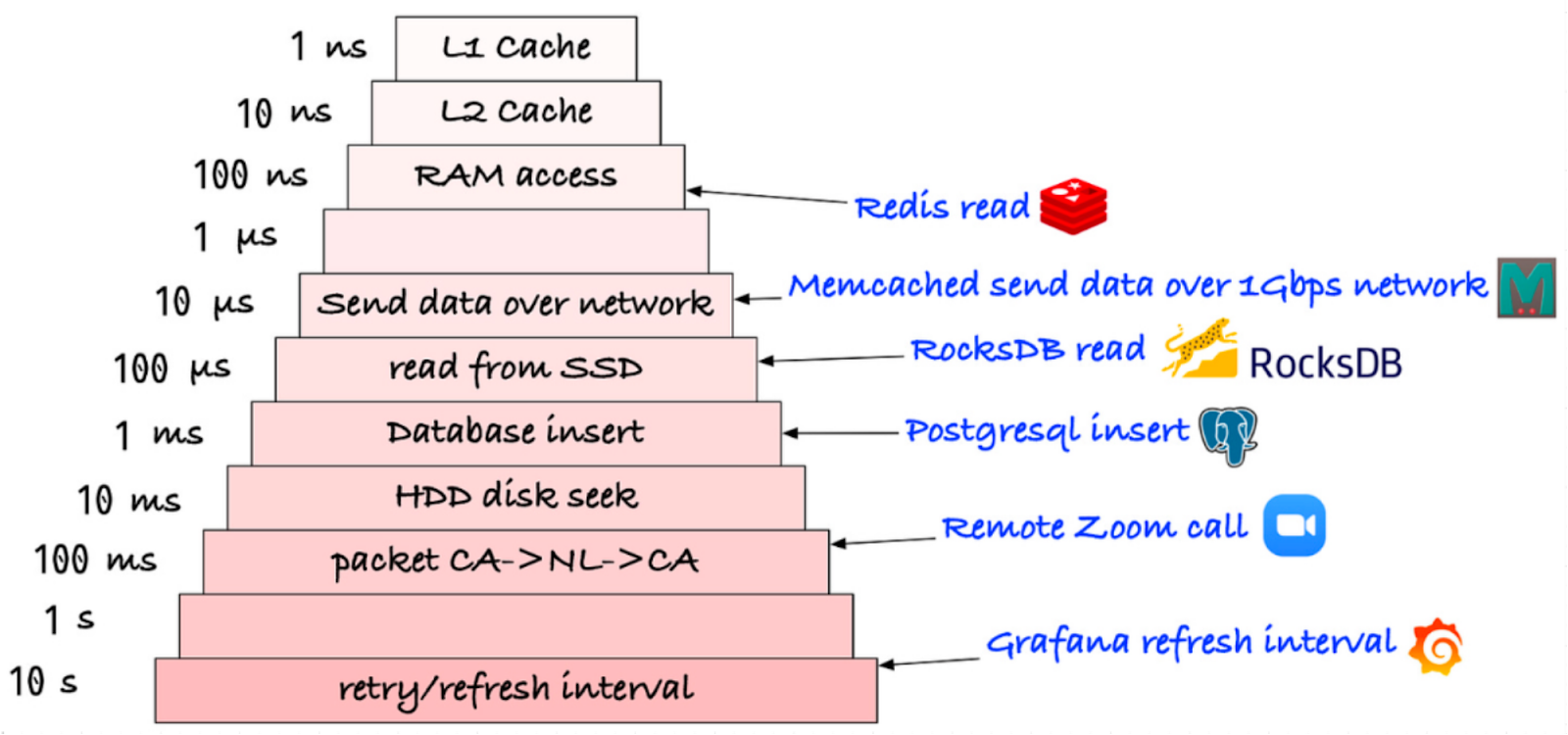
The data structures and operations are an important reason why Redis is so efficient. We will cover more in later sections. In-Memory v.s. On-DiskRedis holds the data in memory. The data reads and writes in memory are generally 1,000X - 10,000X faster than disk reads/writes. See the below diagram for details.
However, if the server is down, all the data will be lost. So Redis designs on-disk persistence as well for fast recovery. Redis has 4 options for persistence:
AOF works like a commit log, recording each write operation to Redis. So when the server is restarted, the write operations can be replayed and the dataset can be reconstructed.
RDB performs point-in-time snapshots at a predefined interval.
This persistence method combines the advantages of both AOF and RDB, which we will cover later.
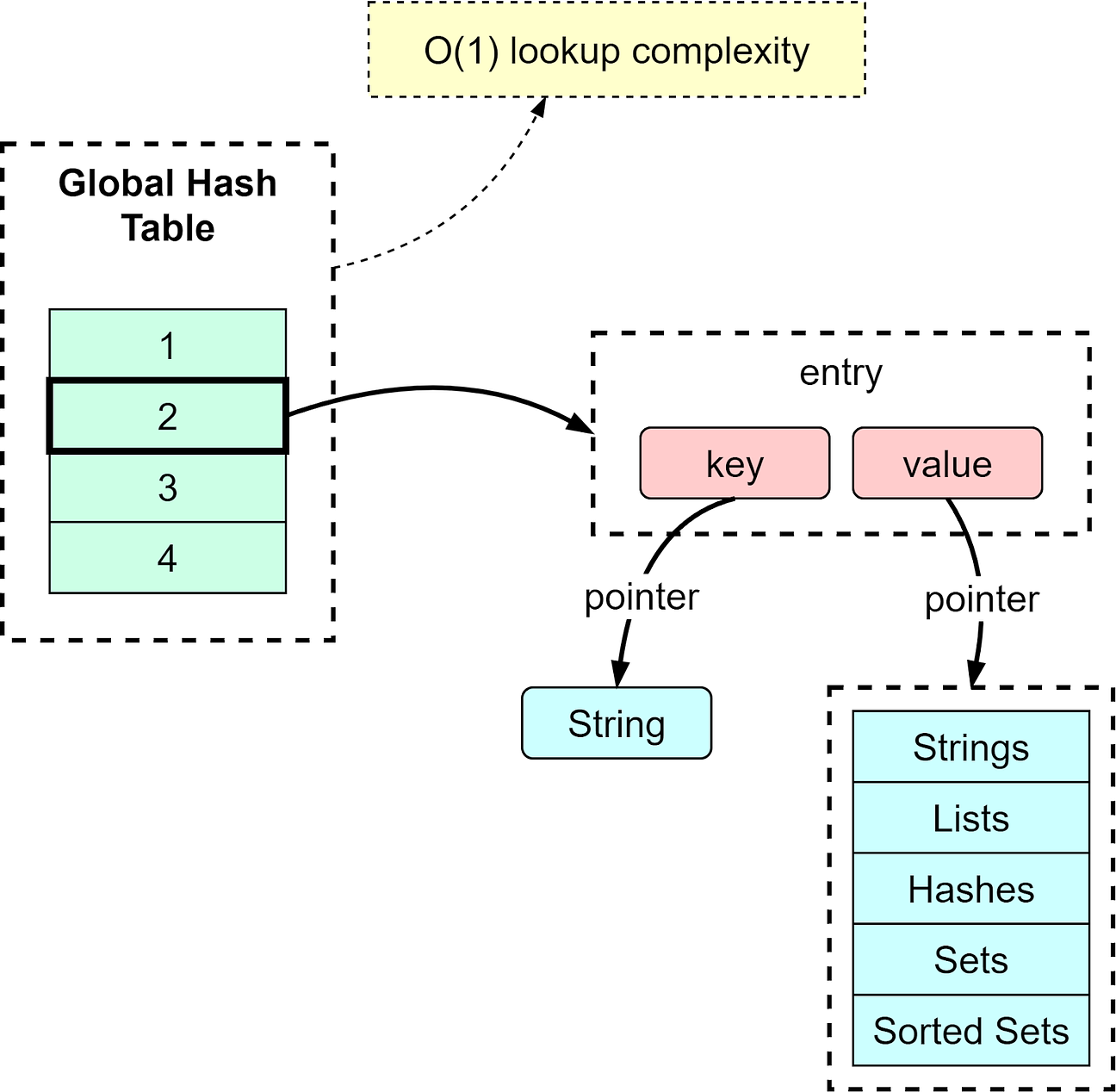
Persistence can be entirely disabled in Redis. This is sometimes used when Redis is a cache for smaller datasets, ClusteringRedis uses a leader-follower replication to achieve high availability. We can configure multiple replicas for reads to handle concurrent read requests. These replicas automatically connect to the master after restarts and hold an exact copy of the leader instance. When the Redis cluster is not used, Redis Sentinel provides high availability including failover, monitoring, and configuration management. Security and AdministrationRedis is often used as a cache and can hold sensitive data, so it is designed to be accessed via trusted clients inside trusted environments. Redis security module is responsible for managing the access control layer and authorizing the valid operations to be performed on the data. Redis also provides an admin interface for configuring and managing the cluster. Persistence, replication, and security configurations can all be done via the admin interface. Now we have covered the basic components of Redis architecture, we will dive into the design details that make Redis fast. In-Memory Data StructuresRedis is not the only in-memory database product in the market. But how can it achieve microsecond-level data access latency and become a popular choice for many companies? One important reason is that storing data in memory allows for more flexible data structures. These data structures don’t need to go through the process of serialization and deserialization like normal on-disk data structures do, so can be optimized for fast reads and writes. Key-Value MappingsRedis uses a hash table to hold all key-value pairs. The elements in the hash table hold the pointers to a key-value pair entry. The diagram below illustrates how the global hash table is structured. With the hash table, we can look up key-value pairs with O(1) time complexity.
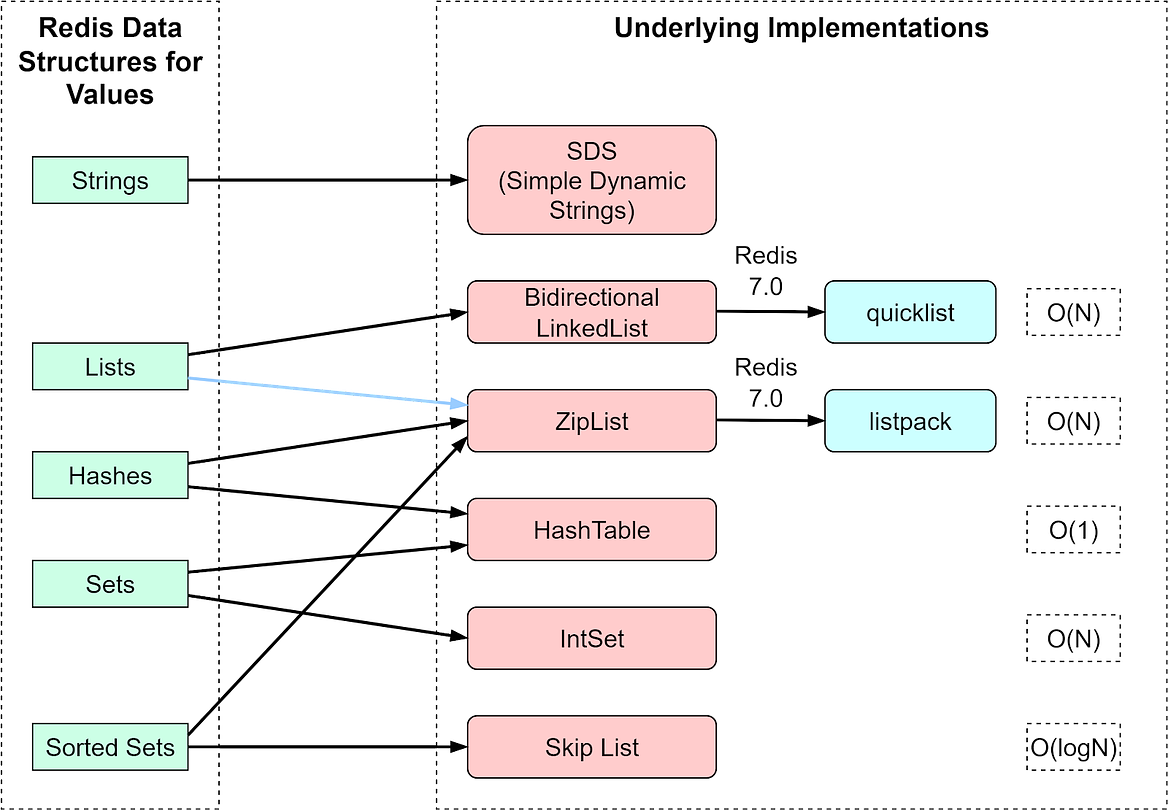
Like all hash tables, when the number of keys keeps growing, there can be hash conflicts, which means different keys fall into the same hash bucket. Redis solves this by chaining the elements in the same hash bucket. When the chains become too long, Redis will perform a rehash by leveraging two global hash tables. Value TypesThe diagram below shows how Redis implements the common data structures. String type has only one implementation, the SDS (Simple Dynamic Strings). List, Hash, Set, and SortedSet all have two types of implementations. Note that Redis 7.0 changed List implementation to quicklist, and ZipList was replaced by listpack.
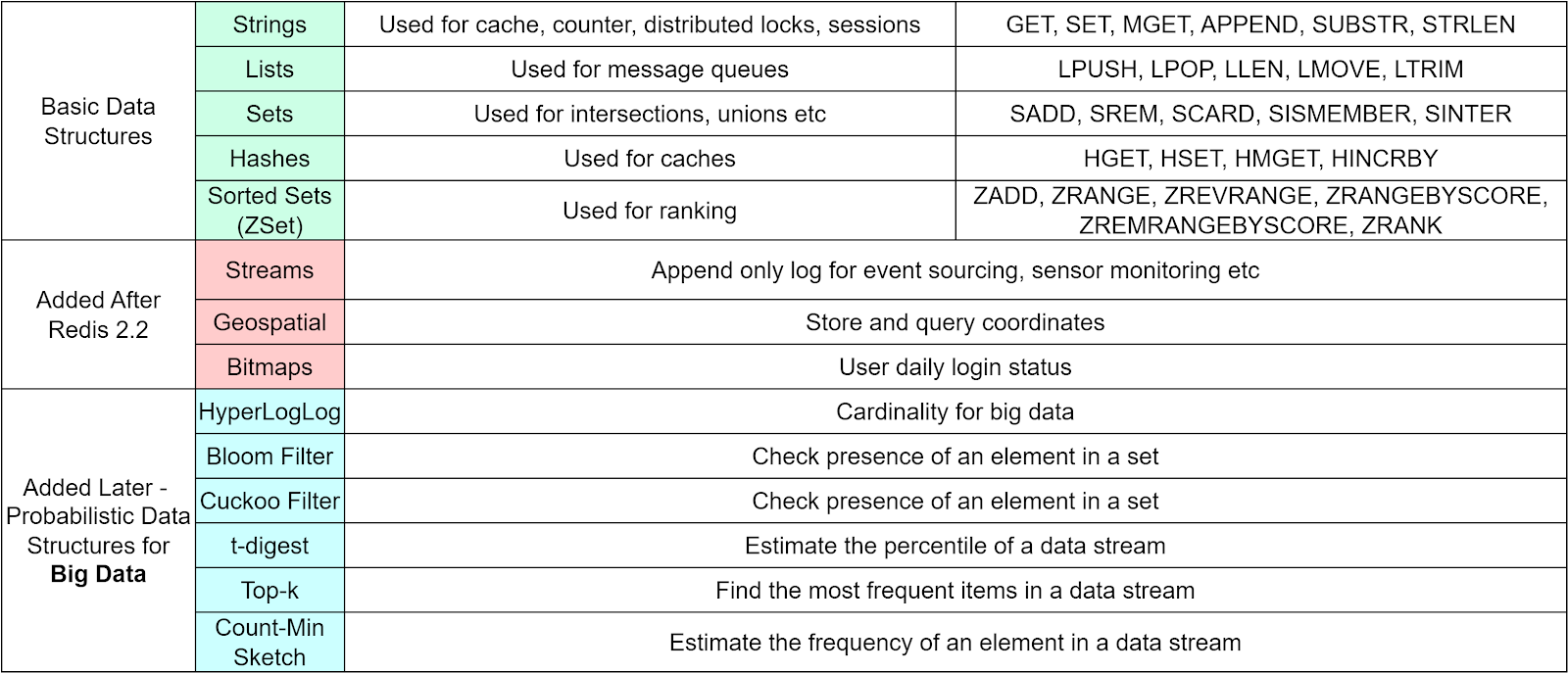
Besides these 5 basic data structures, Redis later added more data structures to support more scenarios. The diagram below lists the operations allowed on basic data structures and the usage scenarios. These data types cover most of the usage of a website. For example, geospatial data stores coordinates that can be used by a ride-hailing application like Uber; HyperLogLog calculates cardinality for massive amounts of data, suitable for counting unique visitors for a large website; Stream is used for message queues and can compensate the problems with List.
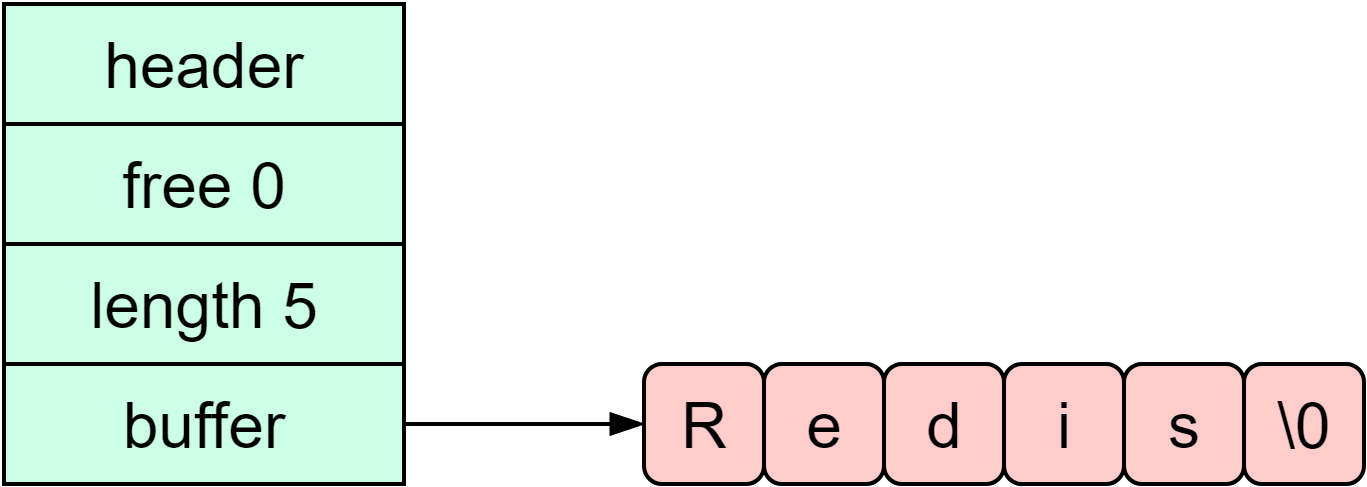
Now let’s look at why these underlying implementations are efficient. SDSRedis SDS stores sequences of bytes. It operates the data stored in buf array in a binary way, so SDS can store not only text but also binary data like audio, video, and images. The string length operation on an SDS has a time complexity of O(1) because the length is recorded in len attribute. The space is pre-allocated for an SDS, with free attribute recording the free space for future usage. The SDS API is thus safe, and there is no risk of overflow. The diagram below shows the attributes of an SDS.
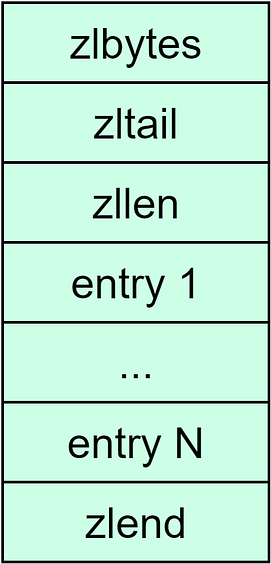
Zip ListA zip list is similar to an array. Each element of the array holds one piece of data. However, unlike an array, a zip list has 3 fields in the header:
The zip list also has a zlend at the end, which indicates the end of the list. In a zip list, locating the first or the last element is O(1) time complexity because we can directly find them by the fields in the header. Locating other elements needs to go through the elements one by one, and the time complexity is O(N).
Keep reading with a 7-day free trialSubscribe to ByteByteGo Newsletter to keep reading this post and get 7 days of free access to the full post archives.A subscription gets you:
© 2023 ByteByteGo
|
by "ByteByteGo" <bytebytego@substack.com> - 11:40 - 21 Sep 2023