- Mailing Lists
- in
- AWS Lambda Under the Hood
Archives
- By thread 5217
-
By date
- June 2021 10
- July 2021 6
- August 2021 20
- September 2021 21
- October 2021 48
- November 2021 40
- December 2021 23
- January 2022 46
- February 2022 80
- March 2022 109
- April 2022 100
- May 2022 97
- June 2022 105
- July 2022 82
- August 2022 95
- September 2022 103
- October 2022 117
- November 2022 115
- December 2022 102
- January 2023 88
- February 2023 90
- March 2023 116
- April 2023 97
- May 2023 159
- June 2023 145
- July 2023 120
- August 2023 90
- September 2023 102
- October 2023 106
- November 2023 100
- December 2023 74
- January 2024 75
- February 2024 75
- March 2024 78
- April 2024 74
- May 2024 108
- June 2024 98
- July 2024 116
- August 2024 134
- September 2024 130
- October 2024 141
- November 2024 171
- December 2024 115
- January 2025 216
- February 2025 140
- March 2025 220
- April 2025 233
- May 2025 239
- June 2025 303
- July 2025 29
Subject: Paid Guest Post: Boost Engagement on your website
What could help make life more affordable?
AWS Lambda Under the Hood
AWS Lambda Under the Hood
WorkOS: enterprise-grade auth for modern SaaS apps (Sponsored)
WorkOS helps companies become Enterprise Ready ridiculously fast. → It supports a complete User Management solution along with SSO, SCIM, RBAC, & FGA. → Unlike other auth providers that rely on user-centric models, WorkOS is designed for B2B SaaS with an org modeling approach. → The APIs are flexible, easy-to-use, and modular. Pick and choose what you need and integrate in minutes. → Best of all, User Management is free up to 1 million MAUs and includes bot protection, impersonation, MFA, & more. Future-proof your auth stack with WorkOS Disclaimer: The details in this post have been derived from multiple AWS reInvent talks and articles by the Amazon engineering team. All credit for information about AWS Lambda’s internals goes to the presenters and authors. The link to these videos and articles is present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them. AWS Lambda is a serverless compute service that allows developers to run code without provisioning or managing servers. Lambda functions can be triggered by various AWS services, HTTP endpoints, or custom events generated by applications. This makes it highly versatile for building event-driven architectures. There are some interesting stats about AWS Lambda:
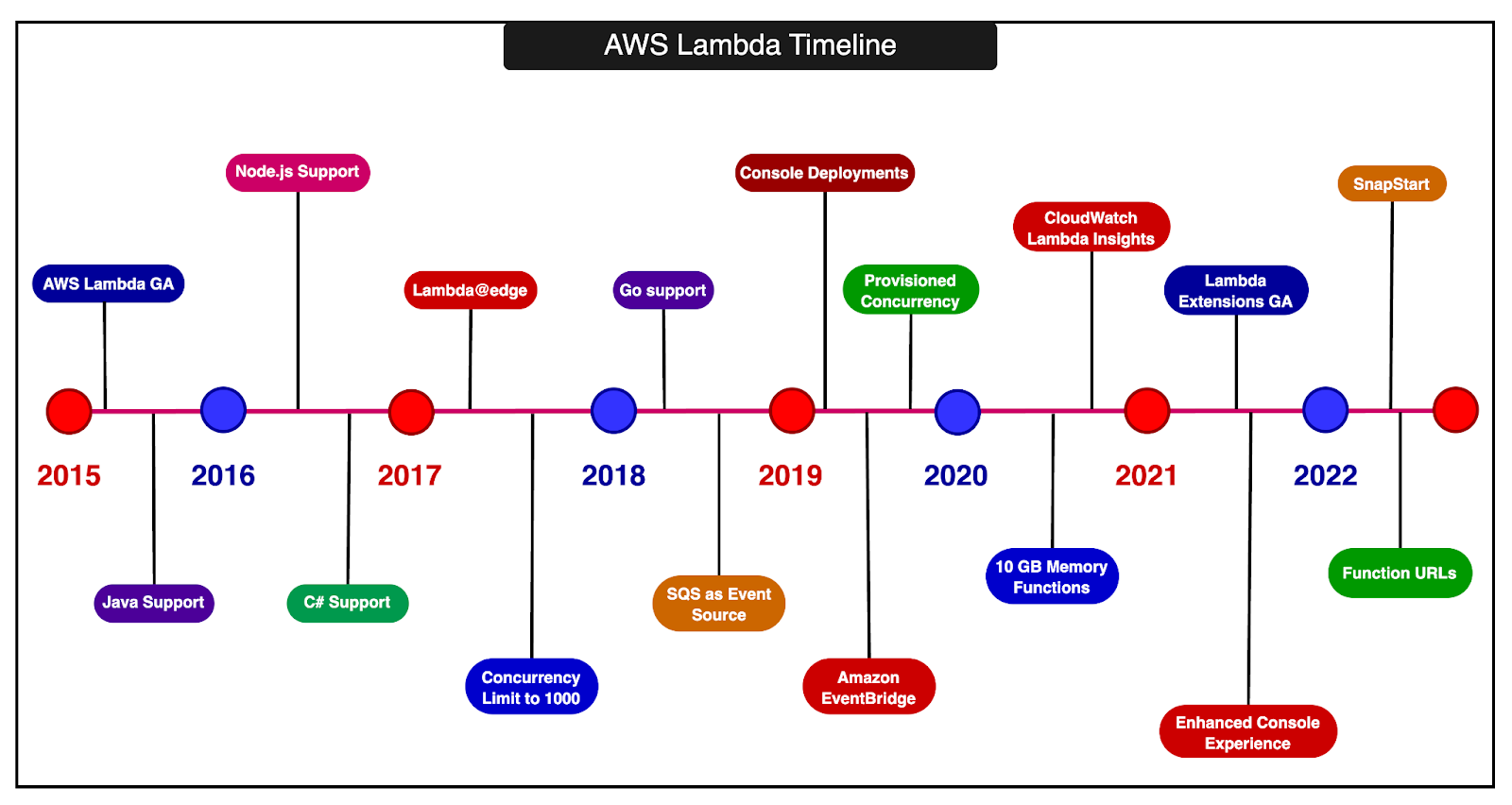
The timeline below shows the evolution of AWS Lambda over the years.
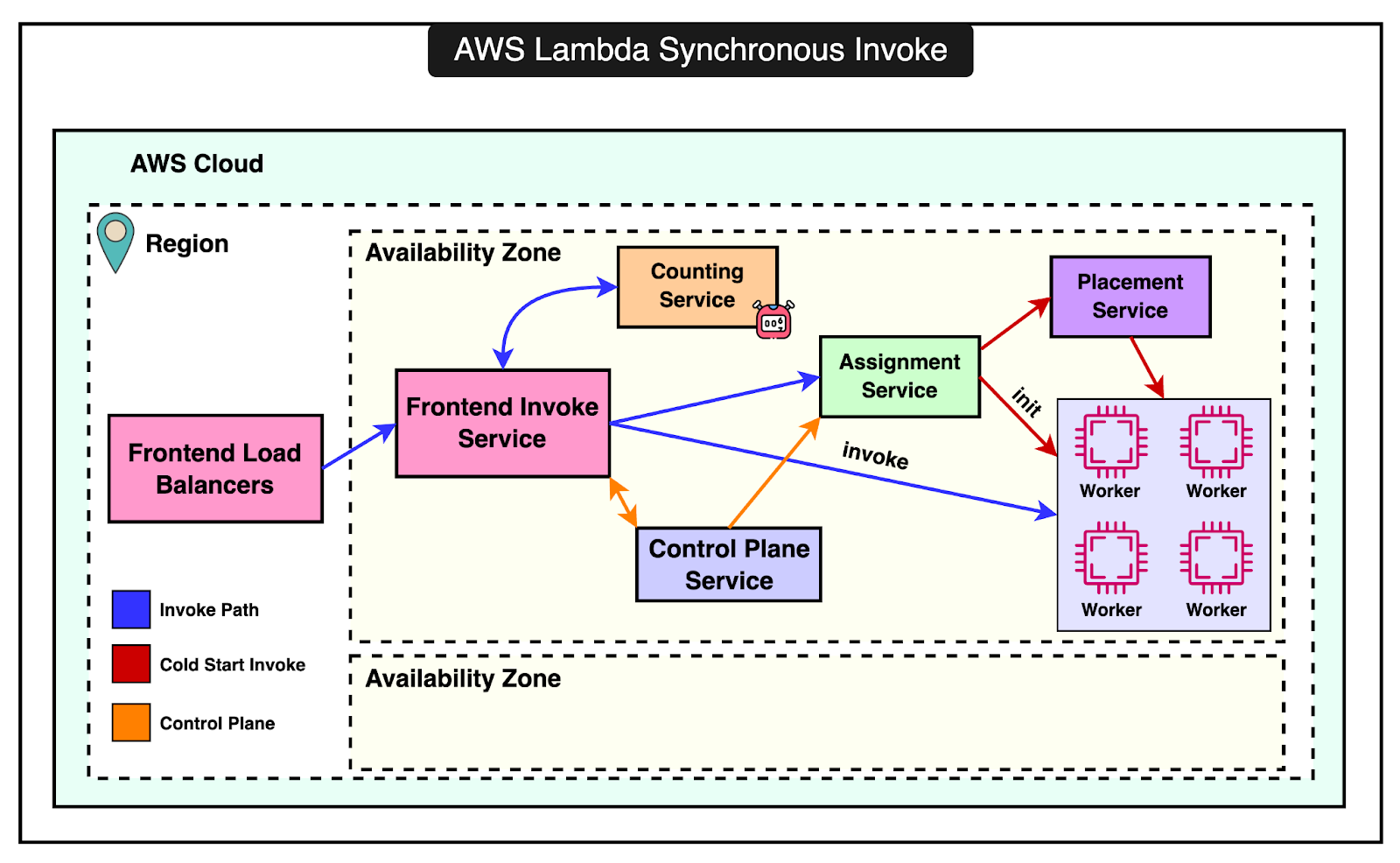
In this post, we will look at the architecture and internals of AWS Lambda. How is a Lambda Function Invoked?There are two types of invocation models supported by Lambda. 1 - Synchronous InvocationIn synchronous invocation, the caller directly calls the Lambda function. This can be done using the AWS CLI, SDK, or other services like the API Gateway. The diagram below shows the entire process:
The process involves the following components:
When an invocation occurs, it can have a warm or cold start. If a warm (already running) execution environment is available, the payload is sent directly to it, and the function runs immediately. If no warm environment is available, a new execution environment is created. The process involves initializing the runtime, downloading function code, and preparing the environment for execution. The assignment service keeps track of execution environments. If there are errors during initialization, the environment is marked unavailable. When environments are near the end of their lease, they are gracefully shut down to ensure stability and resource efficiency. 2 - Asynchronous InvocationIn asynchronous invocation, the caller doesn’t wait for the function’s response. Instead, the event is placed in an internal queue and processed separately. The process involves:
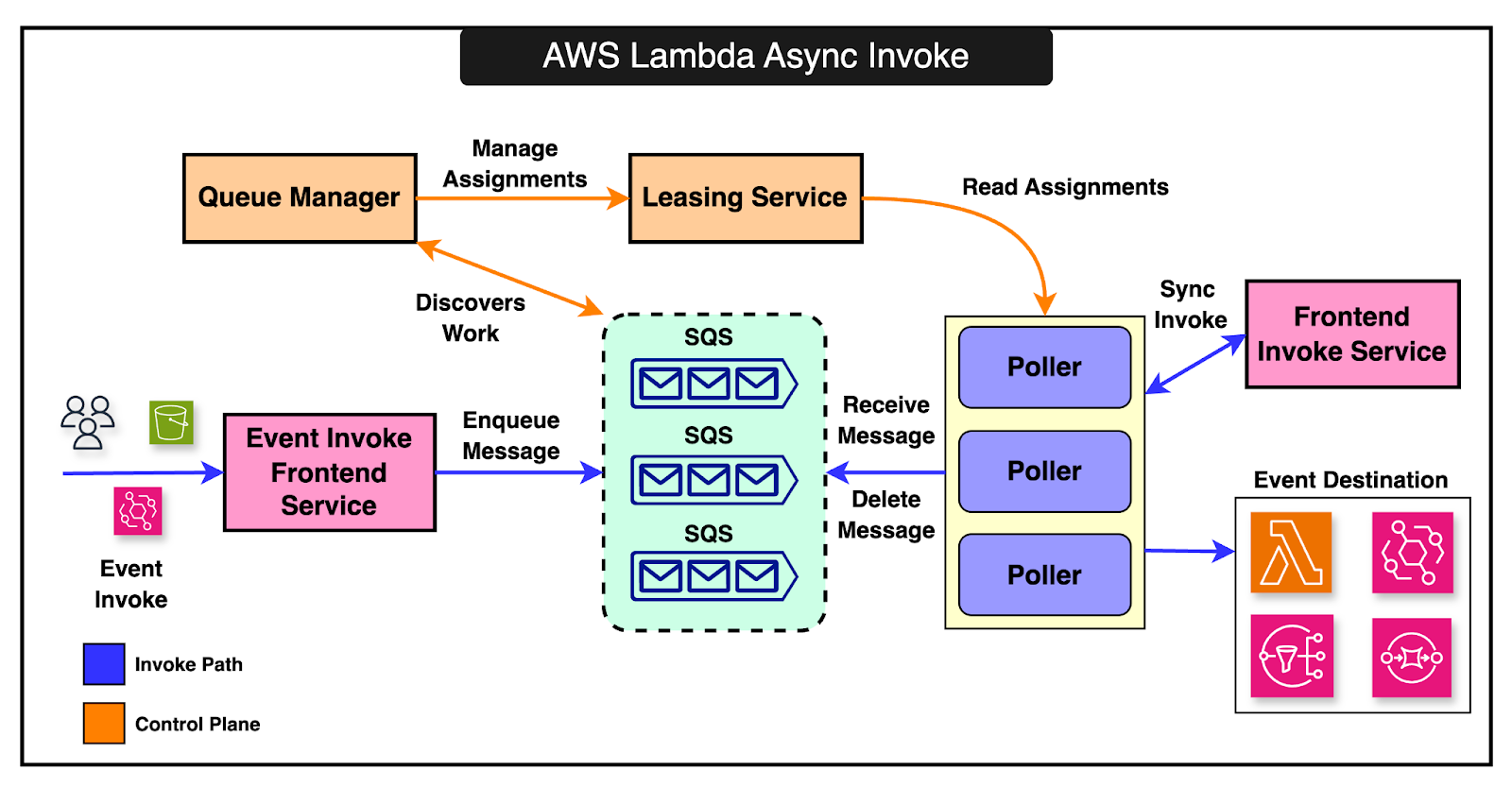
The diagram below shows the asynchronous invocation process:
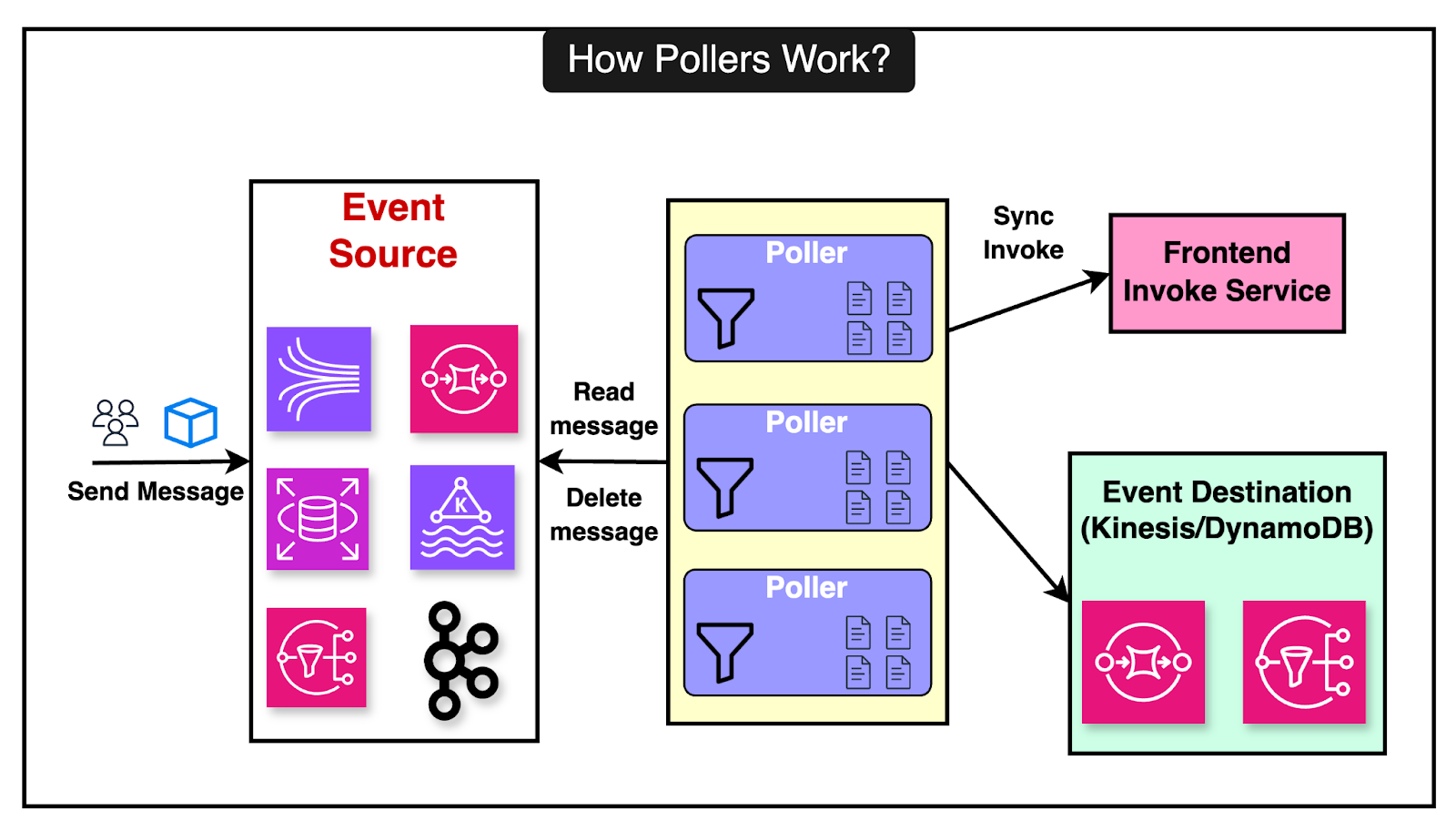
Lambda manages multiple internal queues, scaling them dynamically based on load. The queue manager oversees the creation, deletion, and monitoring of these queues to ensure efficient processing. As far as polling is concerned, Lambda can poll from various event sources like Kinesis, DynamoDB, SQS, Kafka, and Amazon MQ. The pollers perform the following functions:
Control plane services (such as State Manager and Stream Tracker) manage the pollers, ensuring they are assigned correctly, scaling them up or down, and handling failures gracefully. In case a function fails, the message is returned to the queue with a visibility timeout, allowing for retries. Latest articlesIf you’re not a paid subscriber, here’s what you missed.
To receive all the full articles and support ByteByteGo, consider subscribing: State Management in LambdaIn the earlier architecture of AWS Lambda, the Worker Manager service was responsible for coordinating the execution environments between the frontend invoke service and the worker hosts. The worker manager performed a couple of important tasks:
There were some challenges with the worker manager:
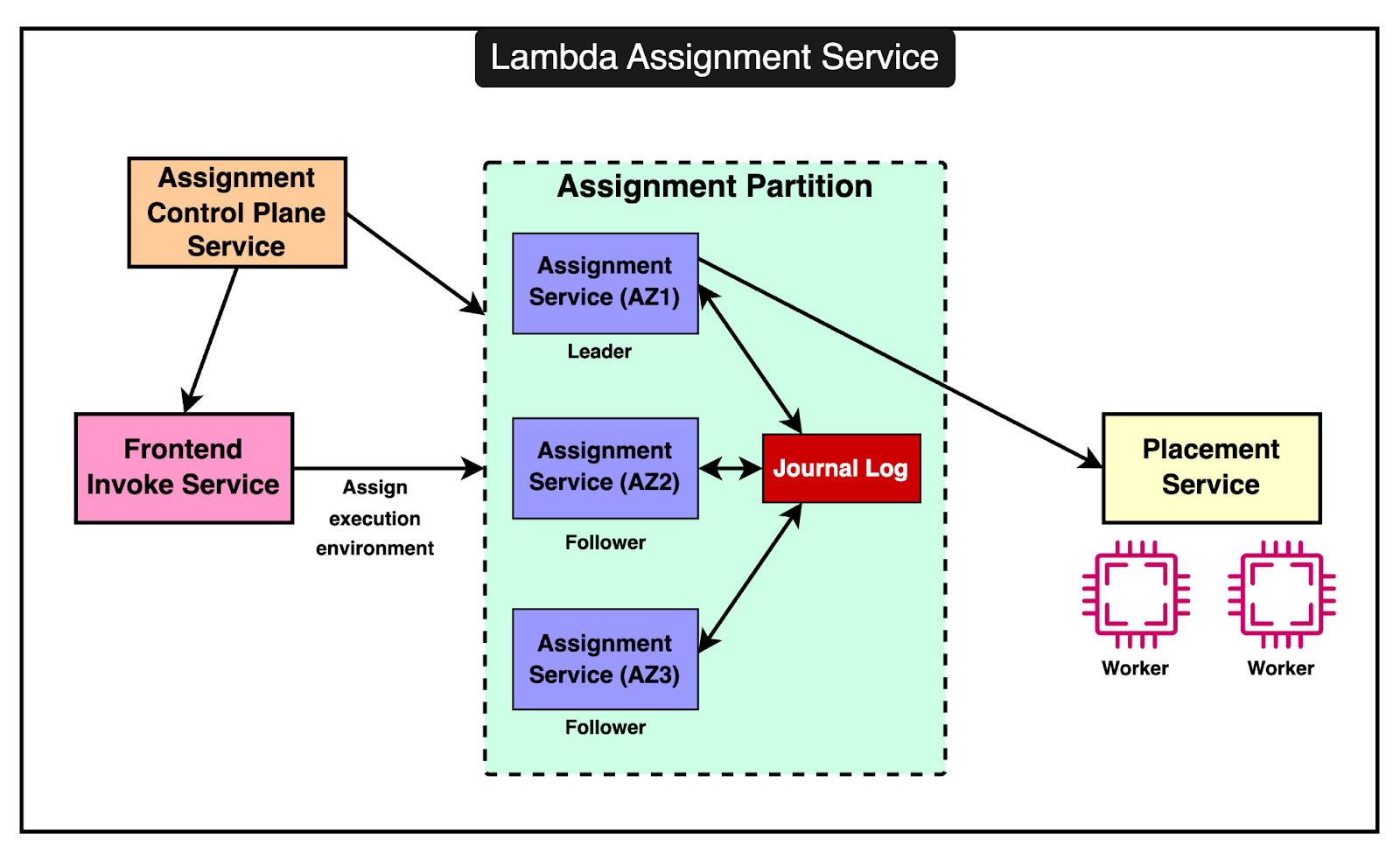
Introduction of the Assignment ServiceTo address the challenges with Worker Manager, AWS Lambda introduced the Assignment Service which offers a more robust and resilient way to manage execution environments. The Assignment Service is written in Rust, which is chosen for its performance, memory safety, and low latency characteristics. The diagram below shows the high-level design of the Assignment Service
The architecture of the Assignment Service has some key properties: 1 - Partitioned DesignThe Assignment Service is divided into multiple partitions. Each partition consists of one leader and two followers, spread across different Availability Zones (AZs). This ensures high availability and fault tolerance. Multiple partitions run simultaneously, with each Assignment Service host managing several partitions. This helps with load distribution and provides redundancy. 2 - External Journal Log ServiceThe leader in each partition writes the state of execution environments to an external journal log service. The followers read from this log to keep their state in sync with the leader. In case the leader fails, one of the followers can quickly take over as the new leader using the state information from the journal log. 3 - Frontend InteractionThe frontend invoke service interacts with the leader of the relevant partition to manage invocations. The leader coordinates with the placement service to create new execution environments and writes this information to the log for followers to update their state. 4 - Failure HandlingIf an AZ experiences an outage, the leader and followers in other AZs continue to operate. This means that execution environments in the unaffected AZs remain available and aren’t orphaned. If a leader fails, a follower can take over quickly using the replicated state, ensuring that there are no interruptions in service and reducing the chances of cold starts. The Role of Firecracker MicroVMFirecracker is a lightweight virtual machine manager (VMM) designed specifically for running serverless workloads such as AWS Lambda and AWS Fargate. It uses Linux’s Kernel-based Virtual Machine to create and manage microVMs. The primary goal of Firecracker is to provide secure and fast-booting microVMs. Initially, AWS Lambda used EC2 instances to run functions, dedicating a T2 instance to each tenant. This was secure but inefficient, leading to high overhead due to the need for provisioning entire EC2 instances for each function. In 2018, Lambda transitioned to using Firecracker for managing execution environments. This allowed for much smaller, lightweight microVMs, significantly reducing resource overhead and improving the fleet’s efficiency.
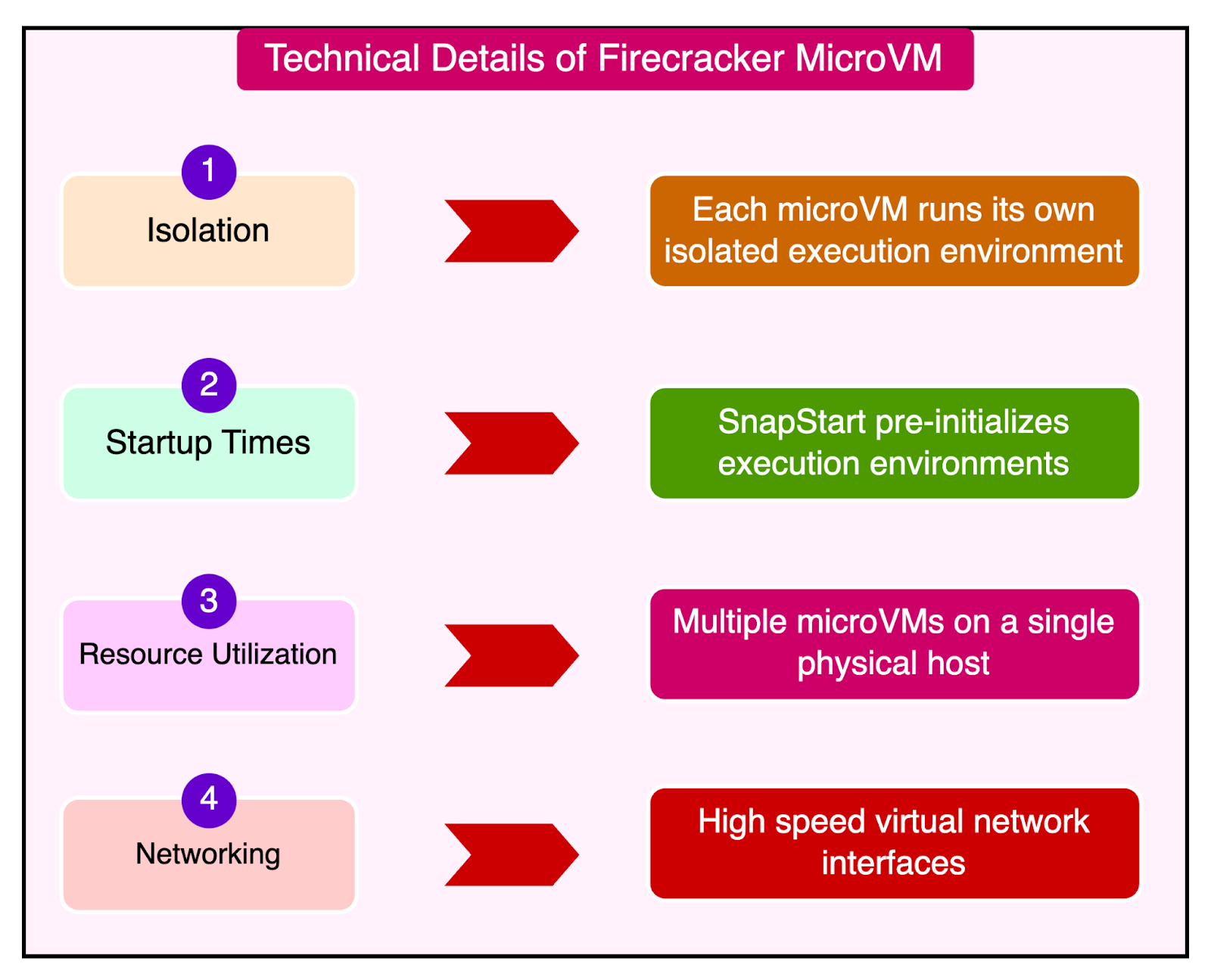
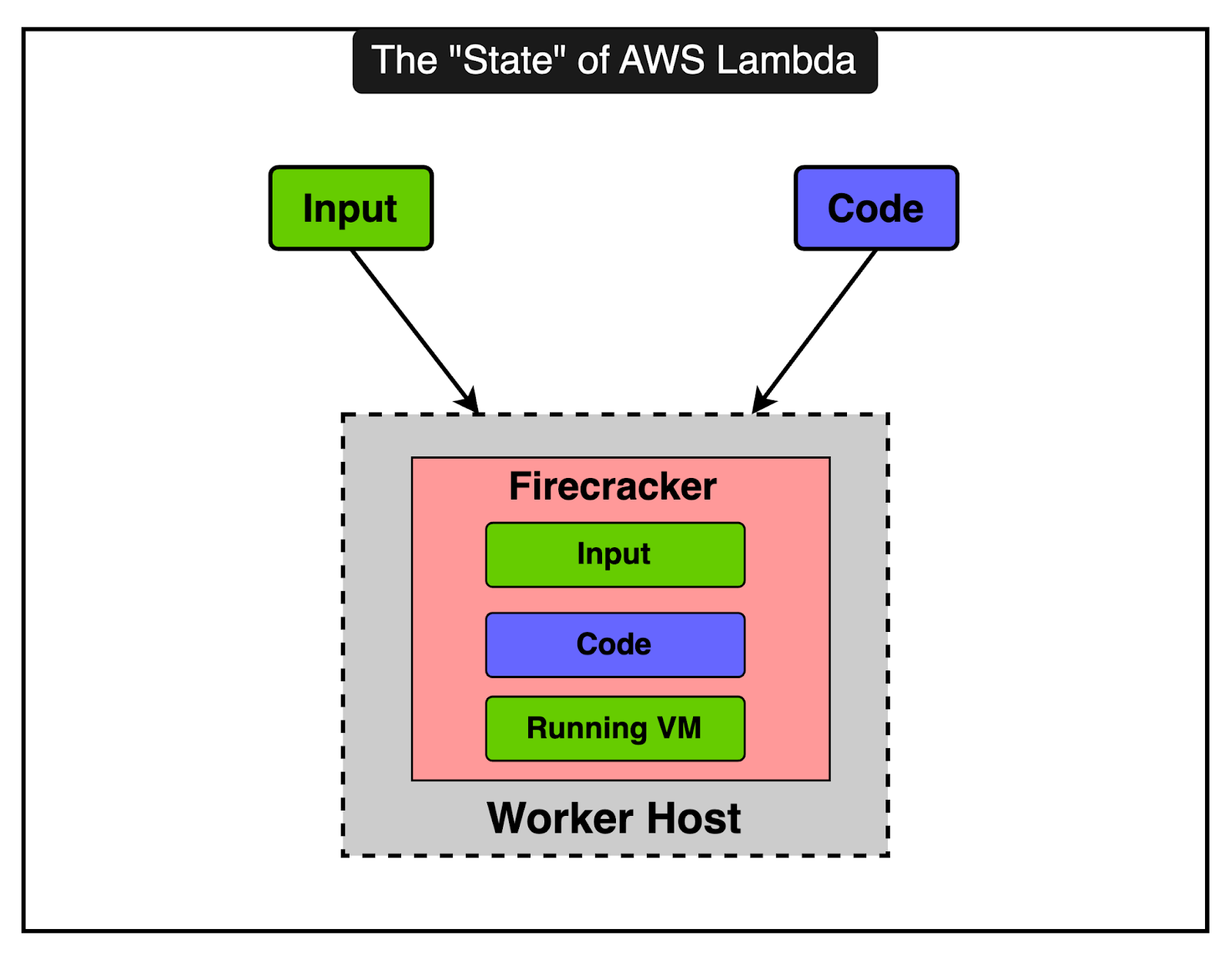
Here are some key technical details of the Firecracker implementation. 1 - MicroVMs and IsolationFirecracker enables the creation of microVMs, which are smaller and more efficient than traditional VMs. Each microVM runs its isolated execution environment, including the runtime, function code, and any extensions. Firecracker ensures a strong solution between microVMs, which is crucial for multi-tenant environments where different customer functions run on the same physical host. 2 - Startup TimesFirecracker microVMs are designed to boot in milliseconds, significantly reducing the cold start latency for Lambda functions. For further optimization, Lambda uses a feature called SnapStart (initially available for the Corretto Java 11 runtime). SnapStart pre-initializes execution environments and takes snapshots, which are restored on demand when needed. We will talk more about it in the next section. 3 - Resource UtilizationBy running multiple microVMs on a single physical host, Firecracker improves CPU utilization, memory, and storage resources. This allows Lambda to handle more functions with fewer resources. Also, Firecracker supports the dynamic scaling of resources for quick adjustment to changing workloads. 4 - Storage and NetworkingLambda uses a virtual file system driver to present an EXT4 file system to the microVMs. This driver handles file system calls and maps them to the underlying storage. Firecracker optimizes network performance by providing high-speed virtual network interfaces, ensuring fast and reliable communication. Lambda as a Storage ServiceAWS Lambda is primarily known as a serverless compute service. However, it also incorporates significant storage service functionalities. Think of Lambda not just as a compute service but also as a storage service because it deals with storing and managing a lot of data behind the scenes. But why is storage important for Lambda? It’s because when you run a function on Lambda, it needs three main things:
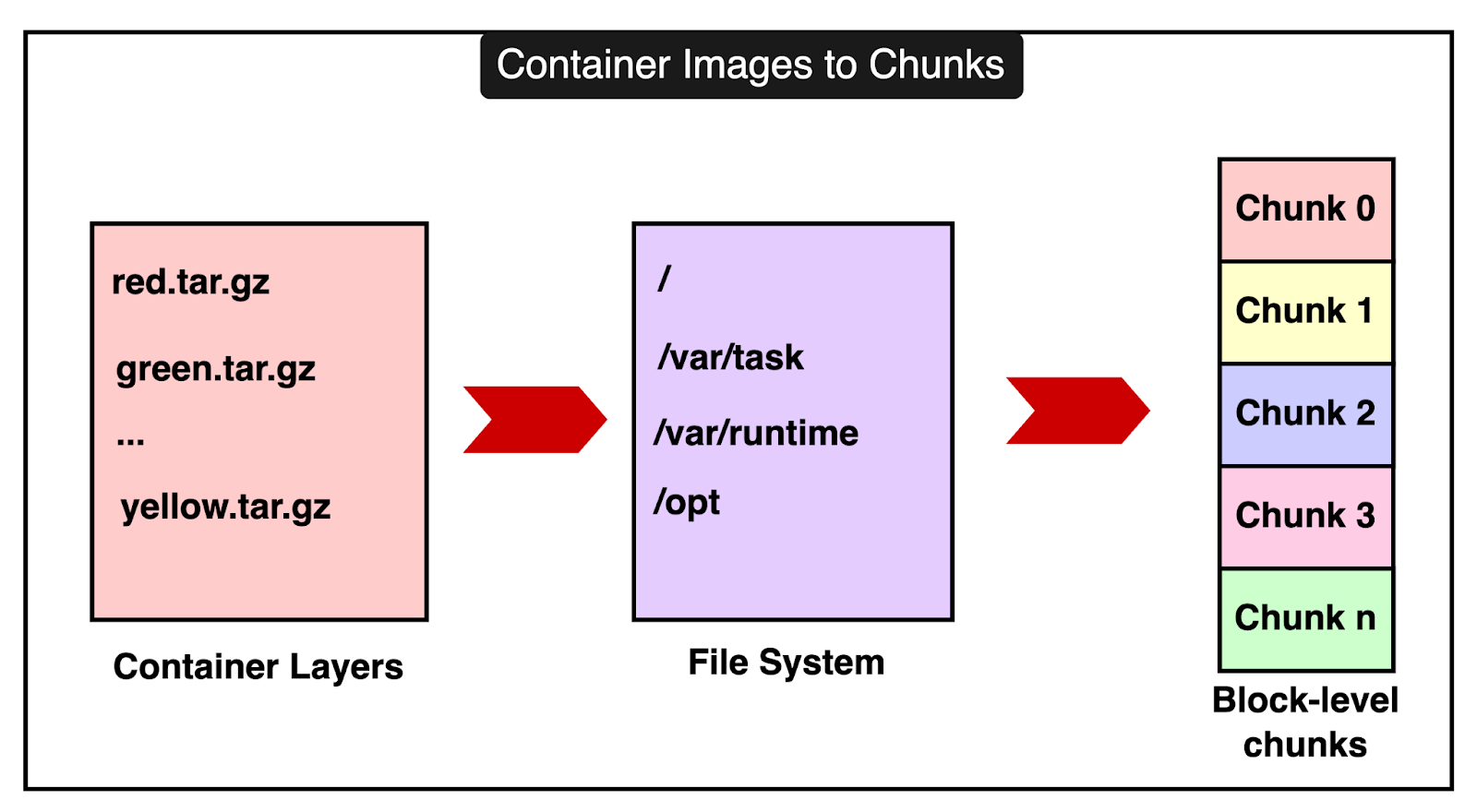
To make all of this work smoothly, Lambda needs to manage and store these components efficiently. 1 - Storing Code and Data EfficientlyInstead of storing your entire code or data as one big piece, Lambda breaks it down into smaller pieces called chunks. This process is known as chunking and it allows Lambda to handle large and complex functions more effectively.
Here’s how it works:
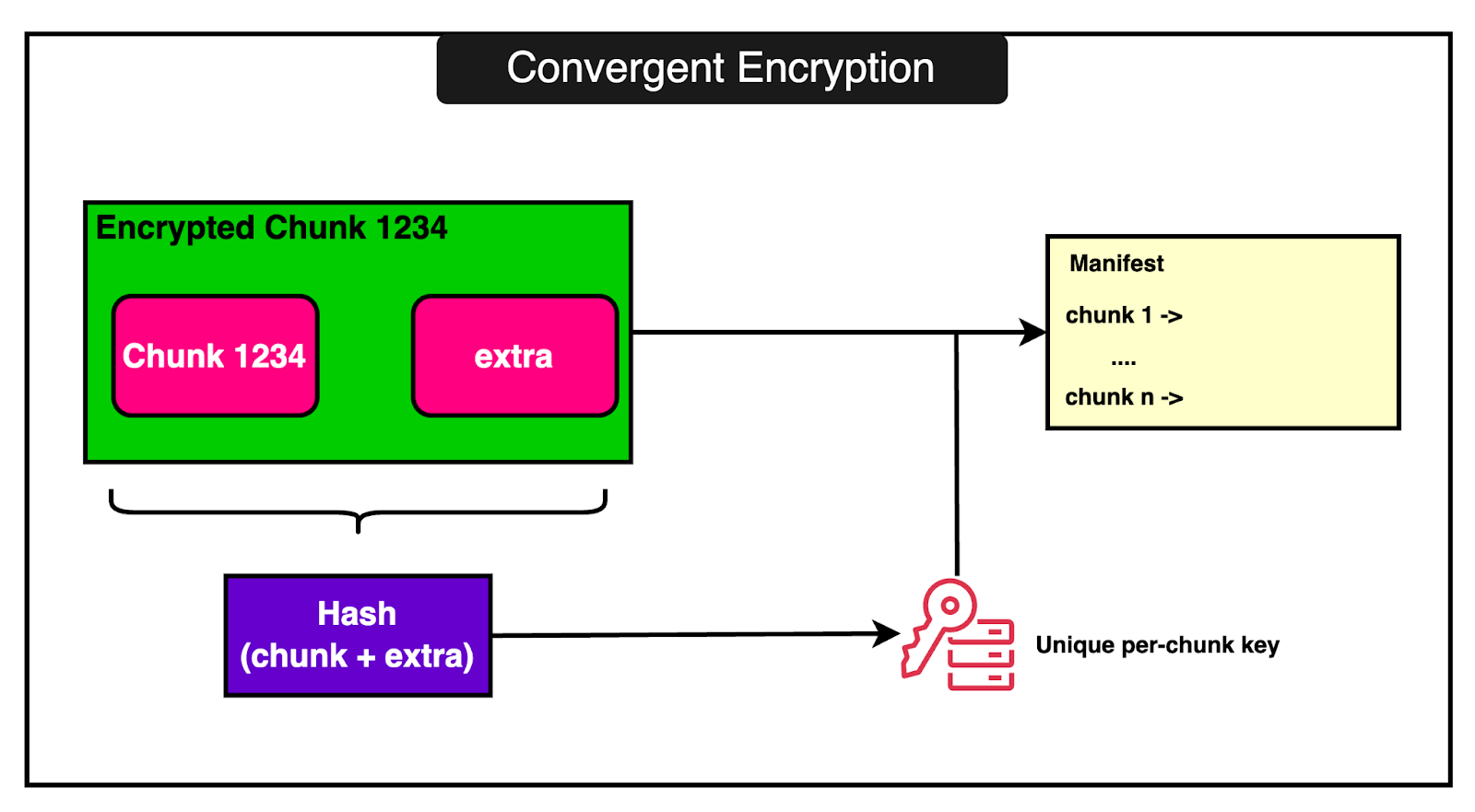
2 - Sharing Common DataLambda often runs many functions that use similar code or data such as base operating system layer or common runtime libraries. Instead of storing multiple copies of the same thing, it stores one copy and reuses it. To make sure the shared data is secure, Lambda uses a technique called convergent encryption.
But how does convergent encryption work?
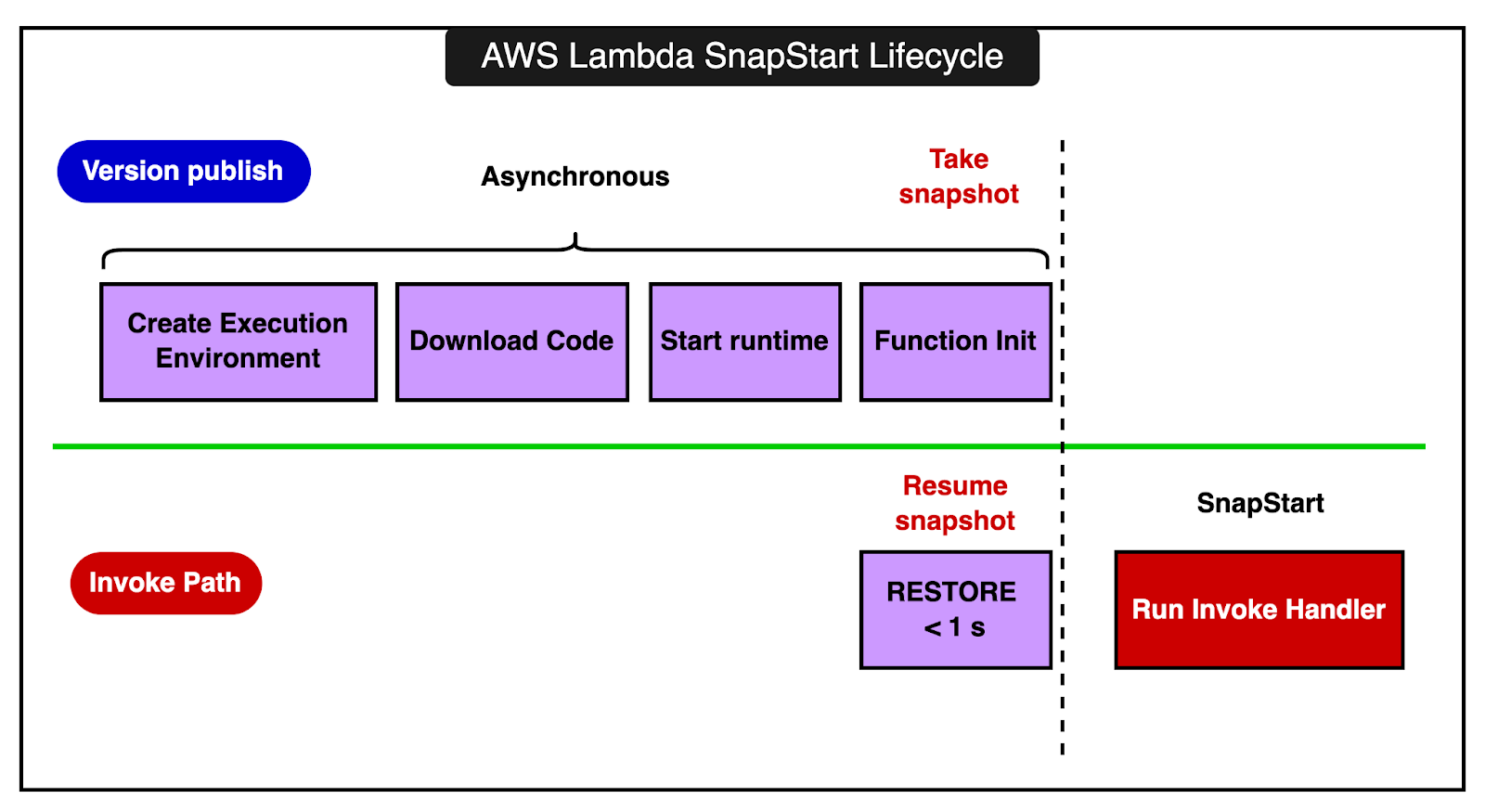
3 - Making Initialization Faster with SnapStartWhen a Lambda function is invoked and there isn’t an already running execution environment, Lambda has to create a new one. This involves several steps:
These steps can take time, especially for complex functions or runtimes like Java, which have longer startup times. This delay is known as cold start latency. SnapStart is a feature designed to significantly reduce cold start latency by pre-initializing the execution environment and then using snapshots.
Here’s how it works:
ConclusionAWS Lambda revolutionized the way developers build and deploy applications by providing a serverless environment that abstracts away the complexities of infrastructure management. Here are the main takeaways from the internals of AWS Lambda:
References: SPONSOR USGet your product in front of more than 500,000 tech professionals. Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases. Space Fills Up Fast - Reserve Today Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing hi@bytebytego.com © 2024 ByteByteGo
|
by "ByteByteGo" <bytebytego@substack.com> - 11:37 - 4 Jun 2024