- Mailing Lists
- in
- Common Failure Causes
Archives
- By thread 5322
-
By date
- June 2021 10
- July 2021 6
- August 2021 20
- September 2021 21
- October 2021 48
- November 2021 40
- December 2021 23
- January 2022 46
- February 2022 80
- March 2022 109
- April 2022 100
- May 2022 97
- June 2022 105
- July 2022 82
- August 2022 95
- September 2022 103
- October 2022 117
- November 2022 115
- December 2022 102
- January 2023 88
- February 2023 90
- March 2023 116
- April 2023 97
- May 2023 159
- June 2023 145
- July 2023 120
- August 2023 90
- September 2023 102
- October 2023 106
- November 2023 100
- December 2023 74
- January 2024 75
- February 2024 75
- March 2024 78
- April 2024 74
- May 2024 108
- June 2024 98
- July 2024 116
- August 2024 134
- September 2024 130
- October 2024 141
- November 2024 171
- December 2024 115
- January 2025 216
- February 2025 140
- March 2025 220
- April 2025 233
- May 2025 239
- June 2025 303
- July 2025 134
Common Failure Causes
Common Failure Causes
This is a sneak peek of today’s paid newsletter for our premium subscribers. Get access to this issue and all future issues - by subscribing today. Latest articlesIf you’re not a subscriber, here’s what you missed this month.
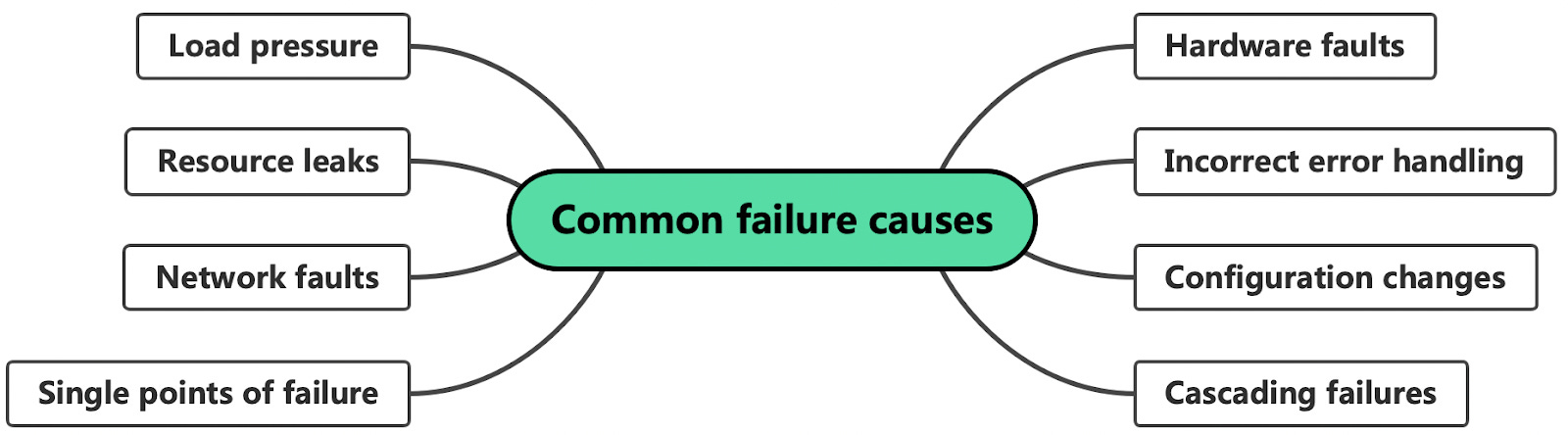
To receive all the full articles and support ByteByteGo, consider subscribing: Designing distributed systems is hard. Without careful planning, numerous issues can arise quickly. It's vital to understand potential pitfalls to be resilient against unforeseen failures. One of the most exciting books I've come across on this subject is "Understanding Distributed Systems." The author, Roberto Vitillo, held positions as a Principal Engineer/Engineering Manager at Microsoft and later as a Principal Engineer at Amazon. The book is organized into five parts: Part I: Communication Part II: Coordination Part III: Scalability Part IV: Resiliency Part V: Maintainability I approached Roberto to see if he'd be willing to share a chapter with our newsletter subscribers, and he graciously agreed. I selected the "Common Failure Causes" chapter. In this excerpt, we discuss 8 common causes of failure and briefly overview how to address them. For those interested in a deeper dive into other subjects, the e-book is available on Roberto's website, and the printed version can be found on Amazon. Common failure causesWe say that a system has a failure when it no longer provides a service to its users that meets its specification. A failure is caused by a fault: a failure of an internal component or an external dependency the system depends on. Some faults can be tolerated and have no user-visible impact at all, while others lead to failures. To build fault-tolerant applications, we first need to have an idea of what can go wrong. In the next few sections, we will explore some of the most common root causes of failures. By the end of it, you will likely wonder how to tolerate all these different types of faults.
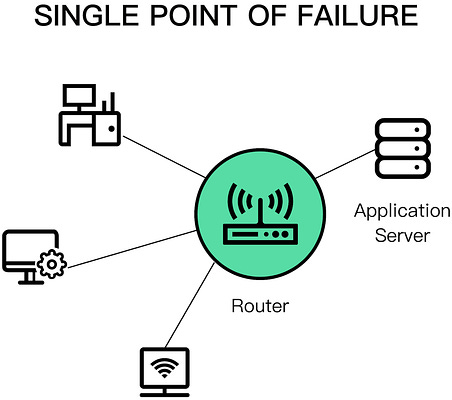
Hardware faultsAny physical part of a machine can fail. HDDs, memory modules, power supplies, motherboards, SSDs, NICs, or CPUs, can all stop working for various reasons. In some cases, hardware faults can cause data corruption as well. If that wasn't enough, entire data centers can go down because of power cuts or natural disasters. As we will discuss later, we can address many of these infrastructure faults with redundancy. You would think that these faults are the main cause for distributed applications failing, but in reality, they often fail for very mundane reasons. Incorrect error handlingA study from 2014 of user-reported failures from five popular distributed data stores found that the majority of catastrophic failures were the result of incorrect handling of non-fatal errors. In most cases, the bugs in the error handling could have been detected with simple tests. For example, some handlers completely ignored errors. Others caught an overly generic exception, like Exception in Java, and aborted the entire process for no good reason. And some other handlers were only partially implemented and even contained "FIXME" and "TODO" comments. In hindsight, this is perhaps not too surprising, given that error handling tends to be an afterthought. This is the reason the Go language puts so much emphasis on error handling. We will take a closer look at best practices for testing large distributed applications. Configuration changesConfiguration changes are one of the leading root causes for catastrophic failures. It's not just misconfigurations that cause problems, but also valid configuration changes to enable rarely-used features that no longer work as expected (or never did). What makes configuration changes particularly dangerous is that their effects can be delayed. If an application reads a configuration value only when it's actually needed, an invalid value might take effect only hours or days after it has changed and thus escape early detection. This is why configuration changes should be version-controlled, tested, and released just like code changes, and their validation should happen preventively when the change happens. We will discuss safe release practices for code and configuration changes in the context of continuous deployments. Single points of failureA single point of failure (SPOF) is a component whose failure brings the entire system down with it. In practice, systems can have multiple SPOFs.
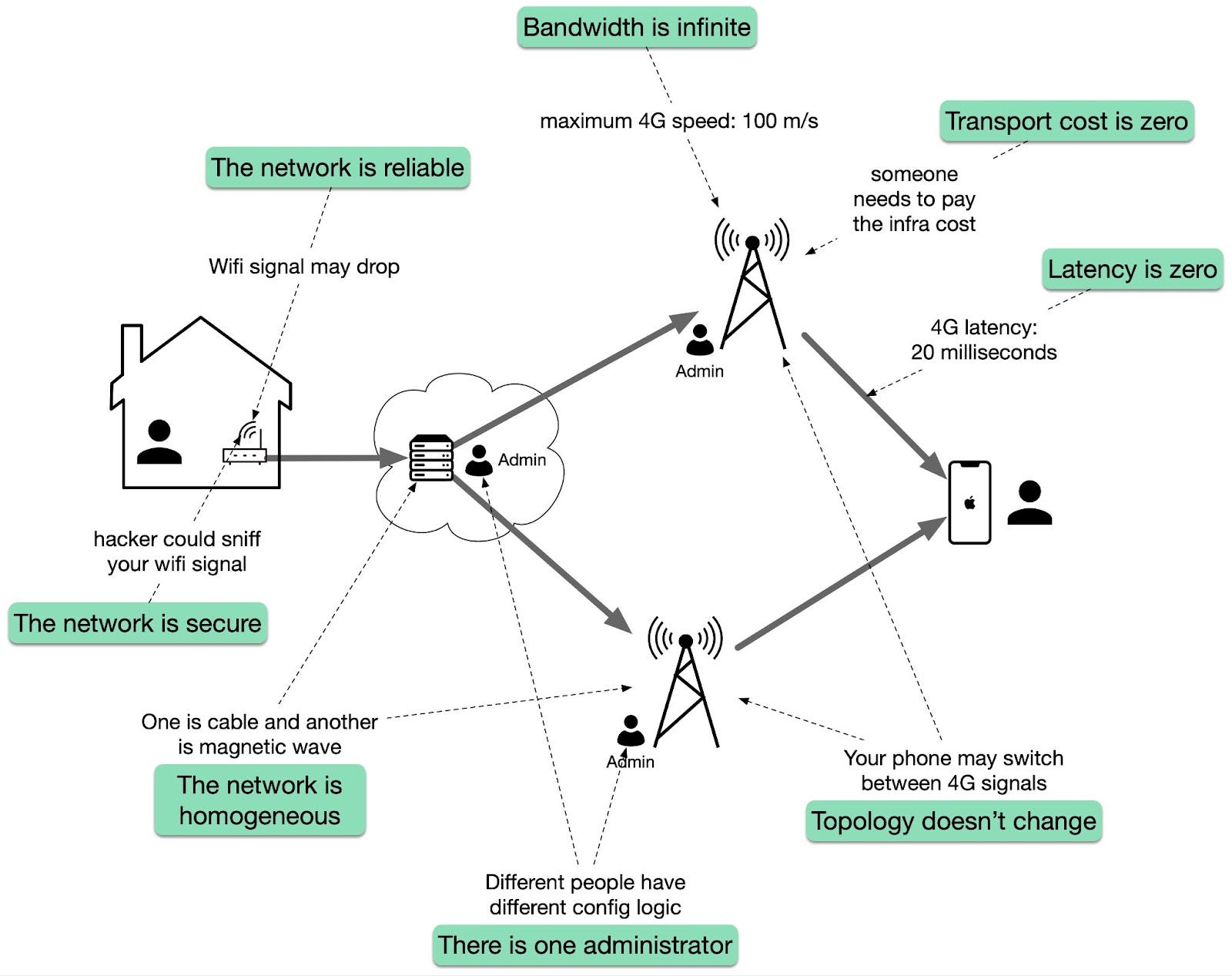
Humans make for great SPOFs, and if you put them in a position where they can cause a catastrophic failure on their own, you can bet they eventually will. For example, human failures often happen when someone needs to manually execute a series of operational steps in a specific order without making any mistakes. On the other hand, computers are great at executing instructions, which is why automation should be leveraged whenever possible. Another common SPOF is DNS. If clients can't resolve the domain name for an application, they won't be able to connect to it. There are many reasons why that can happen, ranging from domain names expiring, to entire root level domains going down. Similarly, the TLS certificate used by an application for its HTTP endpoints is also a SPOF. If the certificate expires, clients won't be able to open a secure connection with the application. Ideally, SPOFs should be identified when the system is designed. The best way to detect them is to examine every system component and ask what would happen if it were to fail. Some SPOFs can be architected away, e.g., by introducing redundancy, while others can't. In that case, the only option left is to reduce the SPOF's blast radius, i.e., the damage the SPOF inflicts on the system when it fails. Many of the resiliency patterns we will discuss later reduce the blast radius of failures. Network faultsWhen a client sends a request to a server, it expects to receive a response from it a while later. In the best case, it receives the response shortly after sending the request. If that doesn't happen, the client has two options: continue to wait or fail the request with a time-out exception or error.
Keep reading with a 7-day free trialSubscribe to ByteByteGo Newsletter to keep reading this post and get 7 days of free access to the full post archives.A subscription gets you:
© 2023 ByteByteGo
|
by "ByteByteGo" <bytebytego@substack.com> - 11:37 - 24 Aug 2023