- Mailing Lists
- in
- Database Indexing Strategies
Archives
- By thread 5314
-
By date
- June 2021 10
- July 2021 6
- August 2021 20
- September 2021 21
- October 2021 48
- November 2021 40
- December 2021 23
- January 2022 46
- February 2022 80
- March 2022 109
- April 2022 100
- May 2022 97
- June 2022 105
- July 2022 82
- August 2022 95
- September 2022 103
- October 2022 117
- November 2022 115
- December 2022 102
- January 2023 88
- February 2023 90
- March 2023 116
- April 2023 97
- May 2023 159
- June 2023 145
- July 2023 120
- August 2023 90
- September 2023 102
- October 2023 106
- November 2023 100
- December 2023 74
- January 2024 75
- February 2024 75
- March 2024 78
- April 2024 74
- May 2024 108
- June 2024 98
- July 2024 116
- August 2024 134
- September 2024 130
- October 2024 141
- November 2024 171
- December 2024 115
- January 2025 216
- February 2025 140
- March 2025 220
- April 2025 233
- May 2025 239
- June 2025 303
- July 2025 126
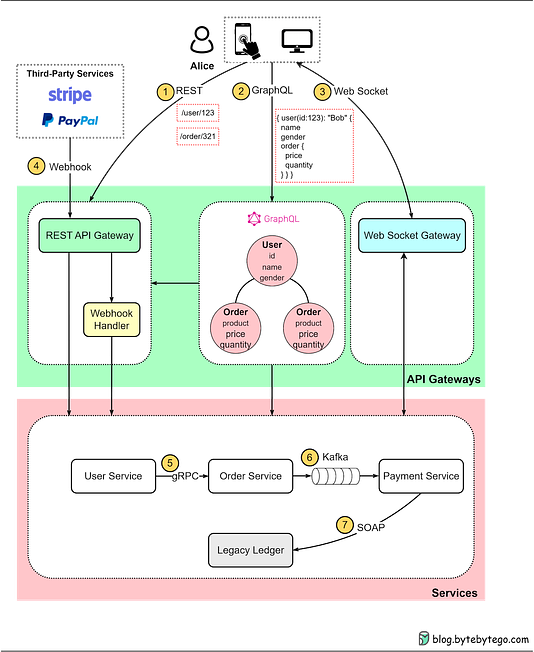
RE: TBS 2023 Attendees Email Contact List
Are you on social media? Here’s how businesses can use social channels to stand out.
Database Indexing Strategies
Database Indexing Strategies
This is a sneak peek of today’s paid newsletter for our premium subscribers. Get access to this issue and all future issues - by subscribing today. Latest articlesIf you’re not a subscriber, here’s what you missed this month:
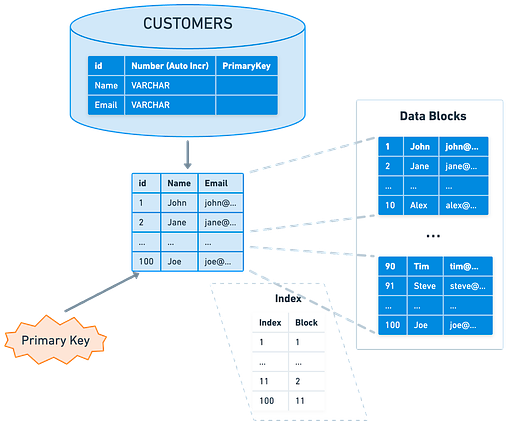
To receive all the full articles and support ByteByteGo, consider subscribing: In this article, we are going to explore effective database indexing strategies. Database performance is critical to any large-scale, data-driven application. Poorly designed indexes and a lack of indexes are primary sources of database application bottlenecks. Designing efficient indexes is critical to achieving good database and application performance. As databases grow in size, finding efficient ways to retrieve and manipulate data becomes increasingly important. A well-designed indexing strategy is key to achieving this efficiency. This article provides an in-depth look at index architecture and discusses best practices to help us design effective indexes to meet the needs of our application. Basics of IndexingLet's start with the basics of indexing in databases. An index, much like the index at the end of a book, is a data structure that speeds up data retrieval operations. Just as a book index lists keywords alongside page numbers to help locate information quickly, a database index serves a similar purpose, speeding up data retrieval without needing to scan every row in a database table.
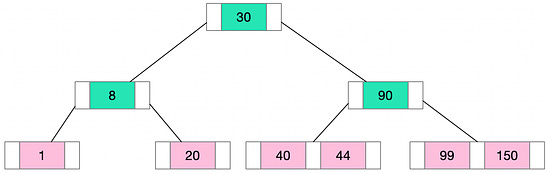
The structure of a database index includes an ordered list of values, with each value connected to pointers leading to data pages where these values reside. Index pages hold this organized structure which provides a more efficient way to locate specific information. Indexes are typically stored on disk. They are associated with a table to speed up data retrieval. Keys made from one or more columns in the table make up the index, which, for most relational databases, are stored in a B+ tree structure. This structure allows the database to locate associated rows efficiently. Finding the right indexes for a database is a balancing act between quick query responses and update costs. Narrow indexes, or those with fewer columns, save on disk space and maintenance, while wide indexes cater to a broader range of queries. Often, it requires several iterations of designs to find the most efficient index. In its simplest form, an index is a sorted table that allows for searches to be conducted in O(Log N) time complexity using binary search on a sorted data structure. Various data structures, such as B-Trees, Bitmaps, or Hash Maps, can be used to implement indexes. Though all these structures offer efficient data access, their implementation details differ. For relational databases, indexes are often implemented using a B+ Tree, which is a variant of B-Tree. Primer on B+ TreeThe B+ Tree is a specific type of tree data structure, and understanding it requires some background on its predecessor, the B-Tree. The B-Tree, or Balanced Tree, is a self-balancing tree data structure that maintains sorted data and allows for efficient insertion, deletion, and search operations. All these operations can be performed in O(Log N) time. Here’s what distinguishes the structure of a B-Tree:
The B-Tree is an excellent data structure for storing data that doesn't fit into the main memory because its design minimizes the number of disk accesses. And because the tree is balanced, with all leaf nodes at the same depth, lookup times remain consistent and predictable.
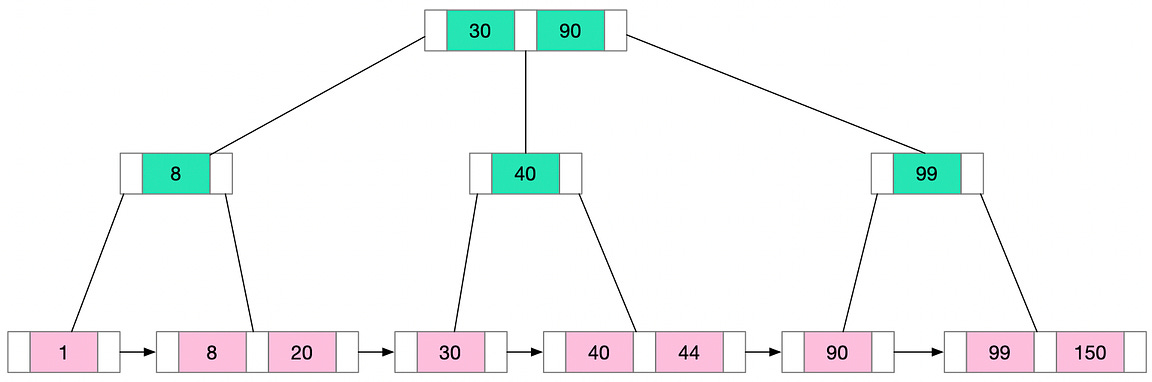
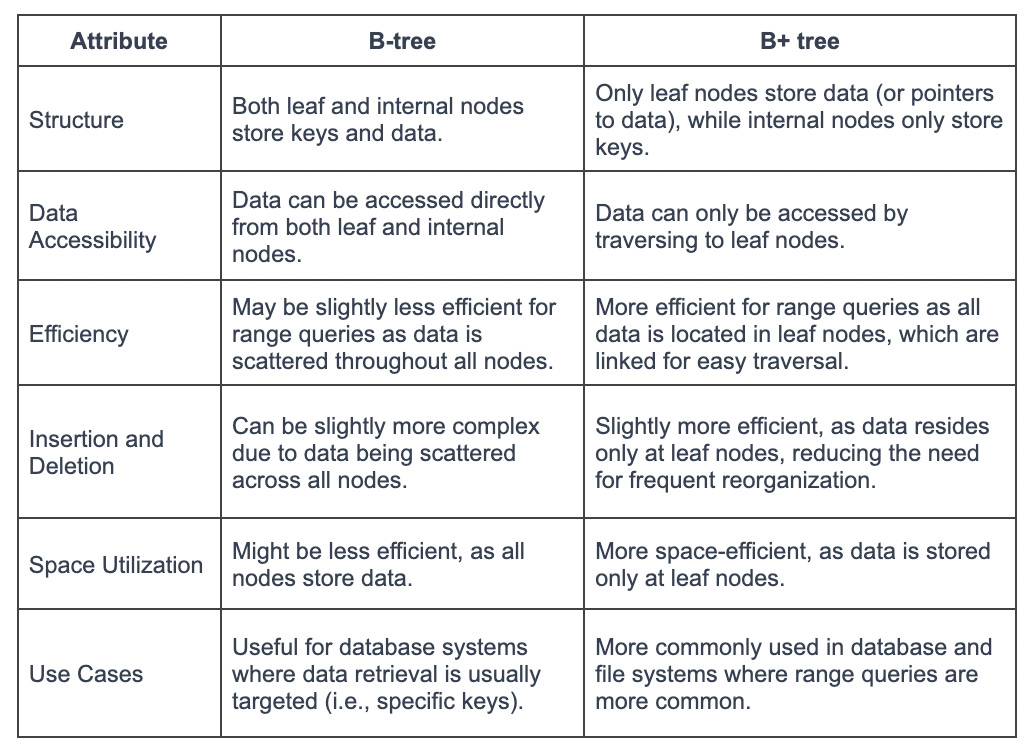
The B+ Tree is a variant of the B-Tree and is widely used in disk-based storage systems, especially for database indexes. The B+ Tree has certain unique characteristics that improve on the B-Tree.
These features make B+ Trees particularly well-suited for systems with large amounts of data that won't fit into main memory. Since data can only be accessed from the leaf nodes, every lookup requires a path traversal from the root to a leaf. All data access operations take a consistent amount of time. This predictability makes B+ Trees an attractive choice for database indexing.
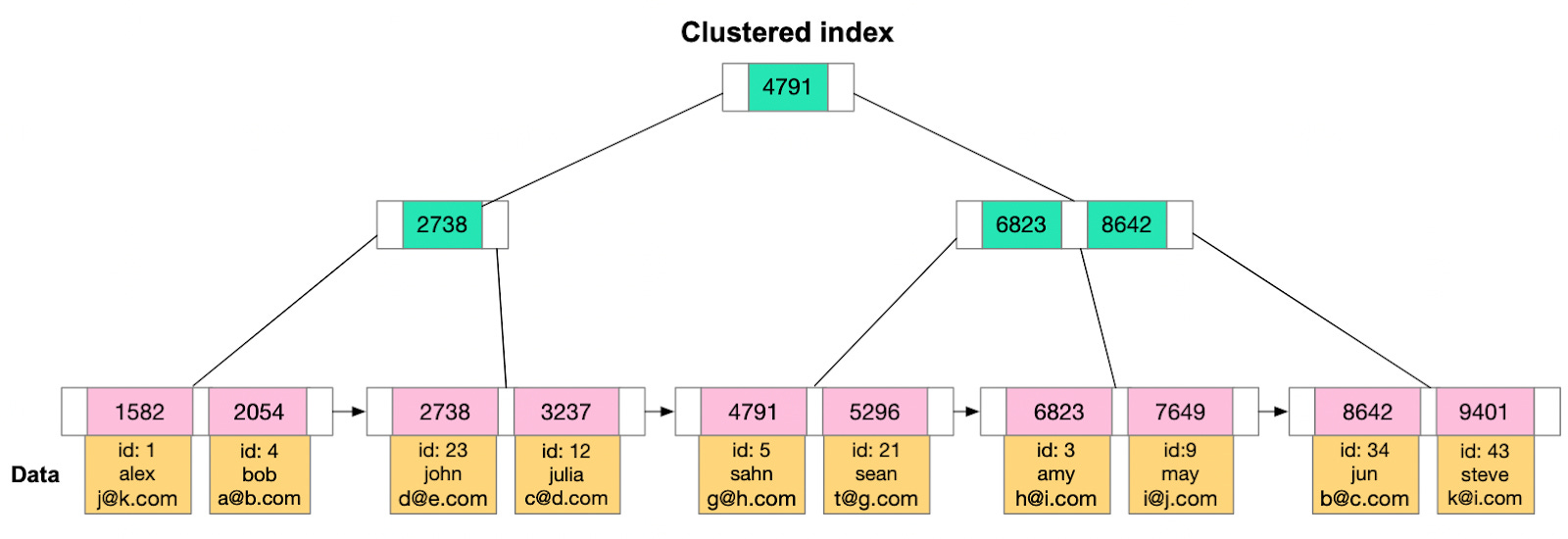
Now we understand how B+ Tree is used for indexing, let’s see how a typical database engine uses it to maintain indexes. Clustered IndexA clustered index reorders the way records in the table are physically stored. It does not store rows randomly or even in the order they were inserted. Instead, it organizes them to align with the order of the index, hence the term “clustered”. The specific column or columns used to arrange this order is referred to as the clustered key. The arrangement determines the physical order of data on disk. Think of it as a phonebook, which is sorted by last name, then first name. The data which is phone number and address is stored along with the sorted index. (maybe a picture of how a phone book works?) However, because the physical data rows can be sorted in only one order, a table can have only one clustered index. Adding or altering the clustered index can be time-consuming, as it requires physically reordering the rows of data. It's also important to select the clustered key carefully. Typically, it's beneficial to choose a unique, sequential key to avoid duplicate entries and minimize page splits when inserting new data. This is why, in many databases, the primary key constraint automatically creates a clustered index on that column if no other clustered index is explicitly defined.
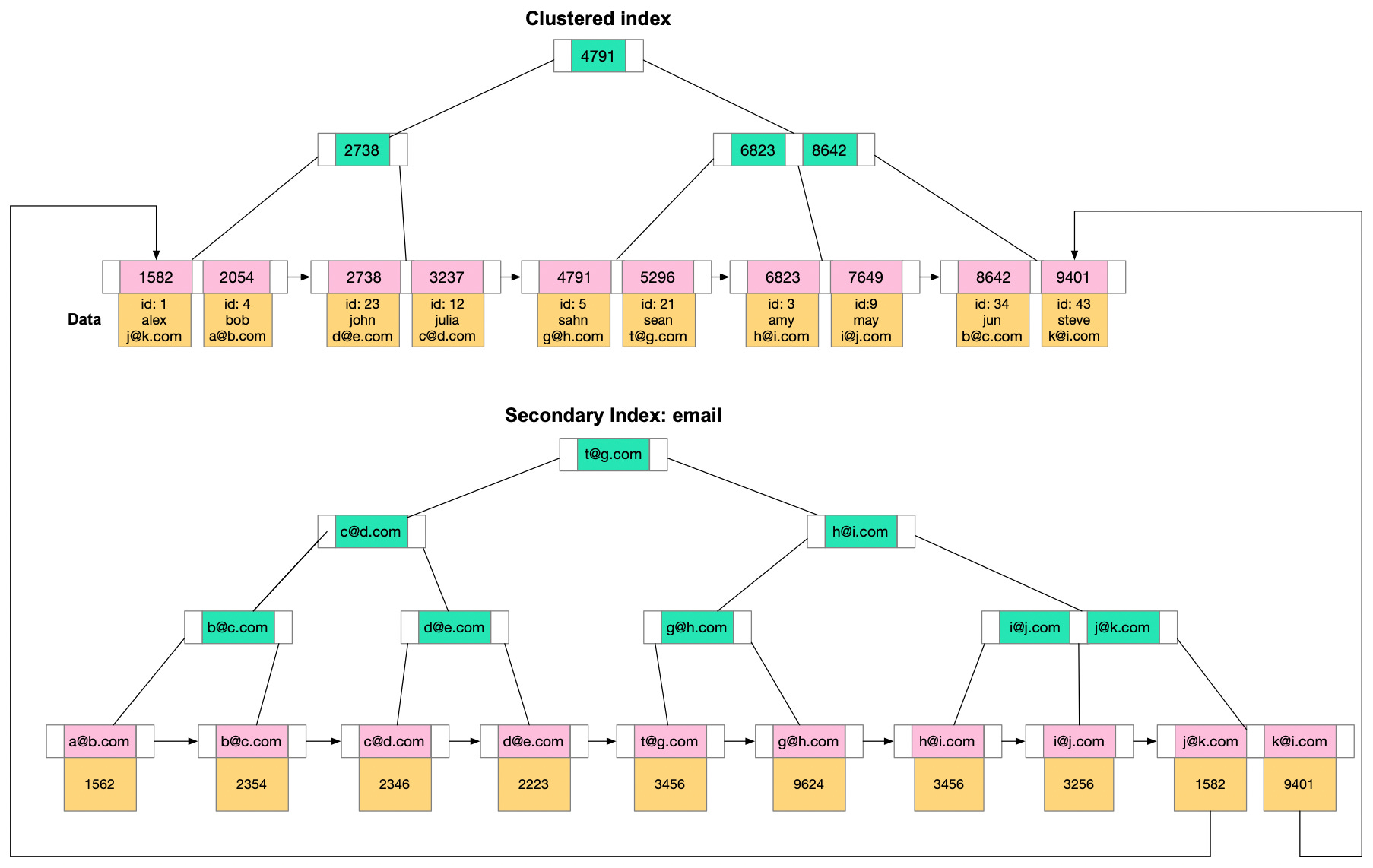
However, an exception to this general guidance is PostgreSQL. In PostgreSQL, data is stored in the order it was inserted, not based on the clustered index or any other index. However, PostgreSQL provides the CLUSTER command, which can be used to reorder the physical data in the table to match a specific index. It's important to note that this physical ordering is not automatically maintained when data is inserted or updated - to maintain the order, the CLUSTER command needs to be rerun. Non-clustered IndexNon-clustered indexes are a bit like the index found at the back of a book. They maintain a distinct list of key values, with each key having a pointer indicating the location of the row that contains that value. The pointers tie the index entries back to the data pages. Since non-clustered indexes are stored separately from the data rows, the physical order of the data isn't the same as the logical order established by the index. This separation means that accessing data using a non-clustered index involves at least two disk reads, one to access the index and another to access the data. This is in contrast to a clustered index, where the index and data are one and the same. A major advantage of non-clustered indexes is that we can have multiple non-clustered indexes on a table, each being useful for different types of queries. They are especially beneficial for queries involving columns not included in the clustered index. They enhance the performance of queries that don't involve the clustered key or don't require scanning a range of data. It's important to consider the trade-off. While non-clustered indexes can speed up read operations, they can slow down write operations, as each index must be updated whenever data is modified in the table. It's crucial to strike a balance when deciding the number and type of non-clustered indexes for a given table.
Understanding Index TypesIndexes speed up data retrieval by providing a more efficient path to the data without scanning every row. There are different types of indexes. We’ll take a look at the common ones. Primary IndexThe primary index of a database is typically the main means of accessing data. When creating a table, the primary key often doubles as a clustered index, which means that the data in the table is physically sorted on disk based on this key. This ensures quick data retrieval when searching by the primary key. The efficiency of this setup largely depends on the nature of the primary key. If the key is sequential, writing to the table is generally efficient. But if the key isn't sequential, reshuffling of data might be needed to maintain the order. This can make the write process less efficient. Note that while the primary key often serves as the clustered index, this is not a hard and fast rule. The clustered index could be based on any column or set of columns, not necessarily the primary key.
Keep reading with a 7-day free trialSubscribe to ByteByteGo Newsletter to keep reading this post and get 7 days of free access to the full post archives. A subscription gets you:
© 2023 ByteByteGo
|

by "ByteByteGo" <bytebytego@substack.com> - 11:37 - 6 Jul 2023