- Mailing Lists
- in
- Database Indexing Strategies - Part 2
Archives
- By thread 5363
-
By date
- June 2021 10
- July 2021 6
- August 2021 20
- September 2021 21
- October 2021 48
- November 2021 40
- December 2021 23
- January 2022 46
- February 2022 80
- March 2022 109
- April 2022 100
- May 2022 97
- June 2022 105
- July 2022 82
- August 2022 95
- September 2022 103
- October 2022 117
- November 2022 115
- December 2022 102
- January 2023 88
- February 2023 90
- March 2023 116
- April 2023 97
- May 2023 159
- June 2023 145
- July 2023 120
- August 2023 90
- September 2023 102
- October 2023 106
- November 2023 100
- December 2023 74
- January 2024 75
- February 2024 75
- March 2024 78
- April 2024 74
- May 2024 108
- June 2024 98
- July 2024 116
- August 2024 134
- September 2024 130
- October 2024 141
- November 2024 171
- December 2024 115
- January 2025 216
- February 2025 140
- March 2025 220
- April 2025 233
- May 2025 239
- June 2025 303
- July 2025 176
Database Indexing Strategies - Part 2
Database Indexing Strategies - Part 2
This is a sneak peek of today’s paid newsletter for our premium subscribers. Get access to this issue and all future issues - by subscribing today. Latest articlesIf you’re not a subscriber, here’s what you missed this month.
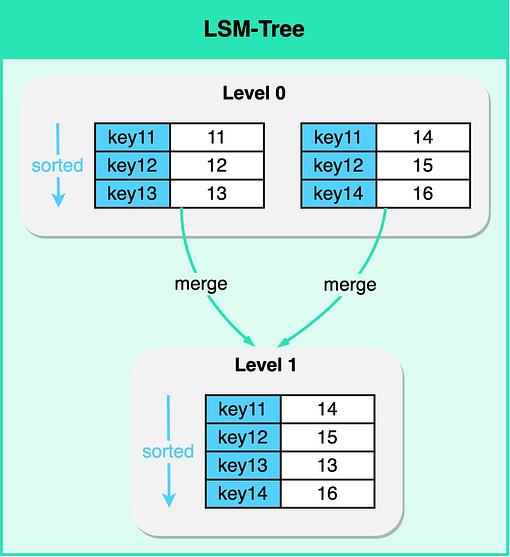
To receive all the full articles and support ByteByteGo, consider subscribing: In this article, we continue the exploration of effective database indexing strategies that we kicked off in the July 6 issue. We’ll discuss how indexing is used in non-relational databases and round off our discussion on general database indexing strategies with practical use cases and best practices. Indexing in Non-relational DatabasesIn the July 6 issue, we focused on indexing use cases for relational databases where records are stored as individual rows. There are other popular types of databases where some forms of indexing are also used. We will briefly discuss how indexing is used in the other common form of databases - NoSQL. NoSQL, LSM Tree, and IndexingNoSQL databases are a broad class of database systems, designed for flexibility, scalability, and the ability to handle large volumes of structured and unstructured data. A popular data structure used in some types of NoSQL databases, notably key-value and wide-column stores, is the Log-Structured Merge-tree (LSM Tree). Unlike traditional B-Tree-based index structures, LSM Trees are optimized for write-intensive workloads, making them ideal for applications where the rate of data ingestion is high.
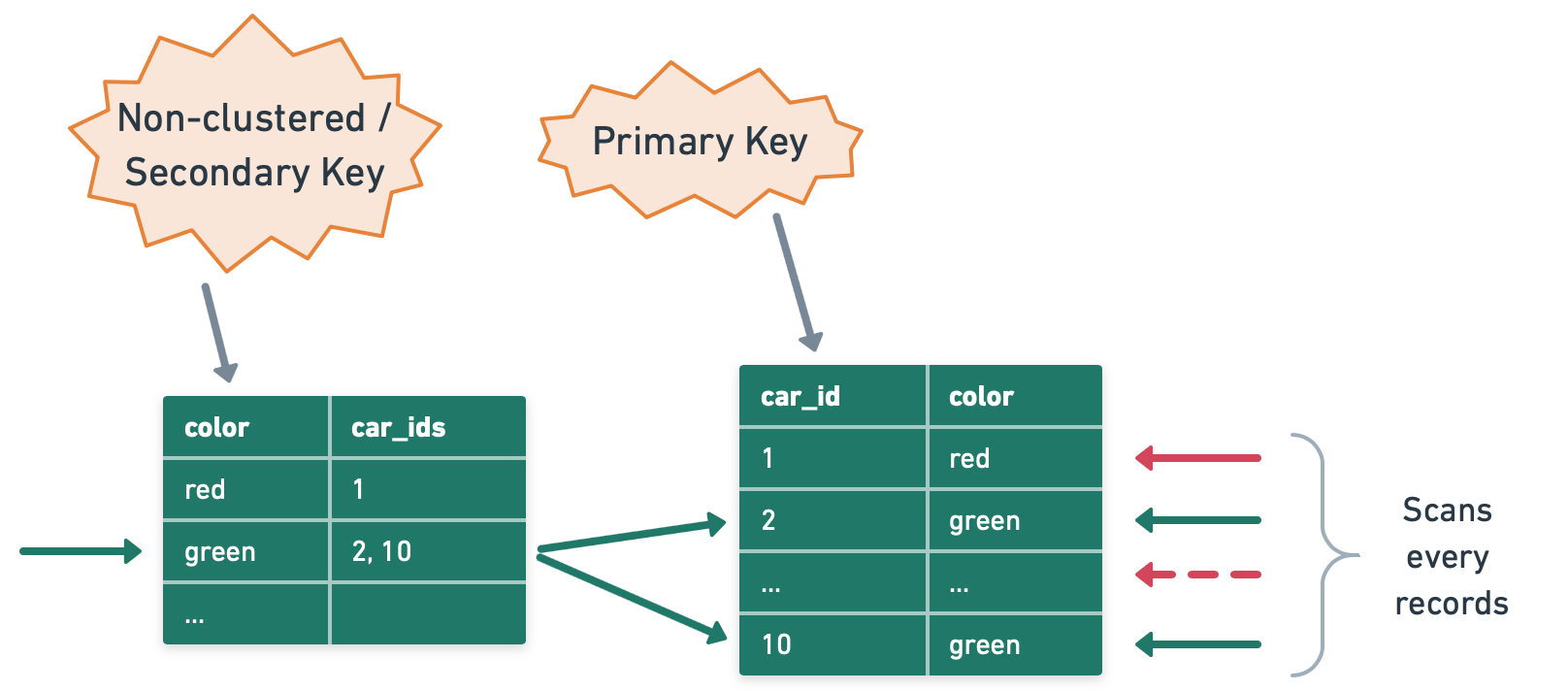
An LSM Tree is, in itself, a type of index. It maintains data in separate structures, each of which is a sorted tree-based index. The smaller structure resides in memory (known as a MemTable), while the larger one is stored on disk (called SSTables). Write operations are first made in the MemTable. When the MemTable reaches a certain size, its content is flushed to disk as an SSTable. The real magic of LSM Trees comes into play during read operations. While the read path is more complex due to data being spread across different structures, the LSM Tree employs techniques such as Bloom Filters and Partition Indexes to locate the required data rapidly. Secondary Index for LSM Tree-based DatabasesThe LSM tree is an efficient way to perform point lookups and range queries on primary keys. However, performing a query on a non-primary key requires a full table scan which is inefficient. This is where a secondary index is useful. A secondary index, as the name suggests, is an index that is created on a field other than the primary key field. Unlike the primary index where data is indexed based on the key, in a secondary index, data is indexed based on non-key attributes. It provides an alternative path for the database system to access the data, allowing for more efficient processing of queries that do not involve the key. Creating a secondary index in an LSM Tree-based database involves creating a new LSM Tree, where the keys are the values of the field on which the index is created, and the values are the primary keys of the corresponding records. When a query is executed that involves the indexed field, the database uses the secondary index to rapidly locate the primary keys of the relevant records, and then retrieves the full records from the primary index. However, one of the complexities of secondary indexes in LSM Tree-based databases is handling updates. Due to the write-optimized nature of LSM Trees, data in these databases is typically immutable, which means updates are handled as a combination of a write (for the new version of a record) and a delete (for the old version). To maintain consistency, both the primary data store and the secondary index need to be updated simultaneously. This can lead to performance trade-offs and increase the complexity of maintaining index consistency. Index Use CasesNow that we discussed how indexes are used in different types of database systems, let’s now turn our attention to some of the common indexing use cases. Point LookupThe simplest use case for an index is to speed up searches on a specific attribute or key. Let's consider an example: a car dealership has a table with columns 'car_id' and 'color'. 'Car_id' is the primary key and thus has an inherent clustered index. If we need to find a car by its 'car_id', the database can quickly locate the information.
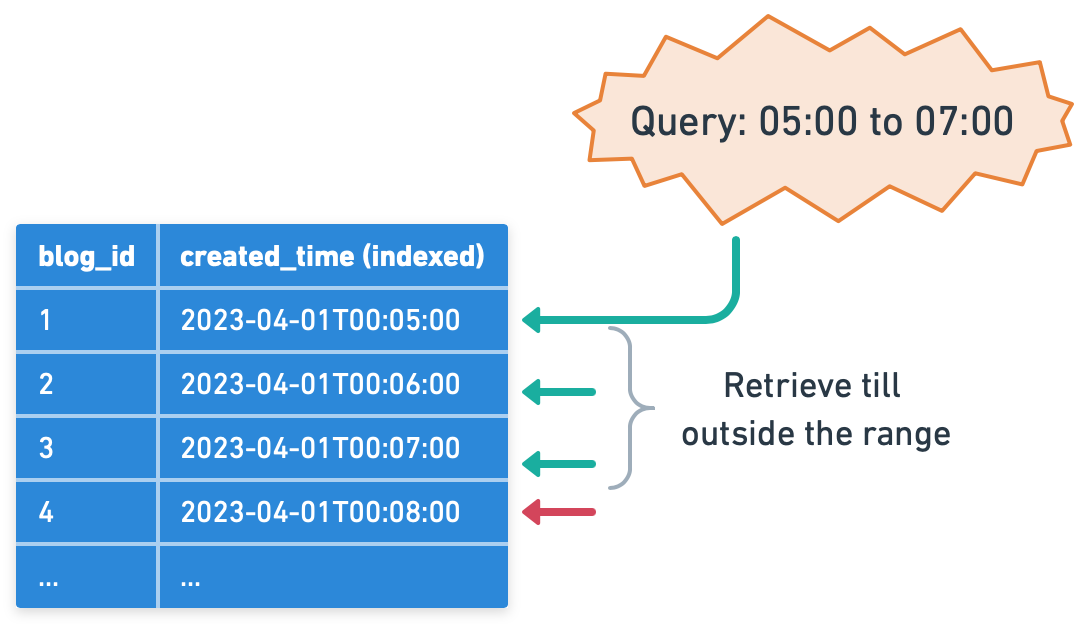
However, what if we need to find all cars of a certain color? Without an index on the 'color' column, the database would have to scan every row in the table. This is a time-consuming process for a large table. Creating a non-clustered index on the 'color' column allows the database to efficiently retrieve all cars of a particular color, transforming what was a full table scan into a much faster index scan. Range LookupIndexes can also be used to efficiently retrieve a range of values. Consider a blog platform where 'post_id' is the primary key and 'created_time' is another attribute. Without an index, to find the 20 most recent posts, the database would need to scan all records and sort them by 'created_time'.
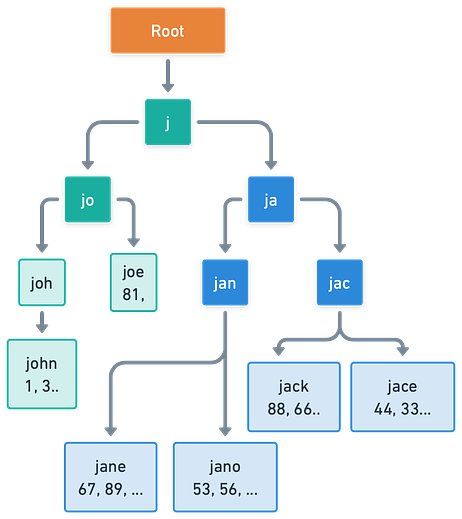
However, if 'created_time' is indexed, the database can use this index to quickly identify the most recent posts. This is because the index on 'created_time' stores post_id values in the order they were created, allowing the database to efficiently find the most recent entries without having to scan the entire table. Prefix SearchIndexes are also useful for prefix searches, thanks to their sorted nature. Imagine a scenario where a search engine keeps a table of previously searched terms and their corresponding popularity scores.
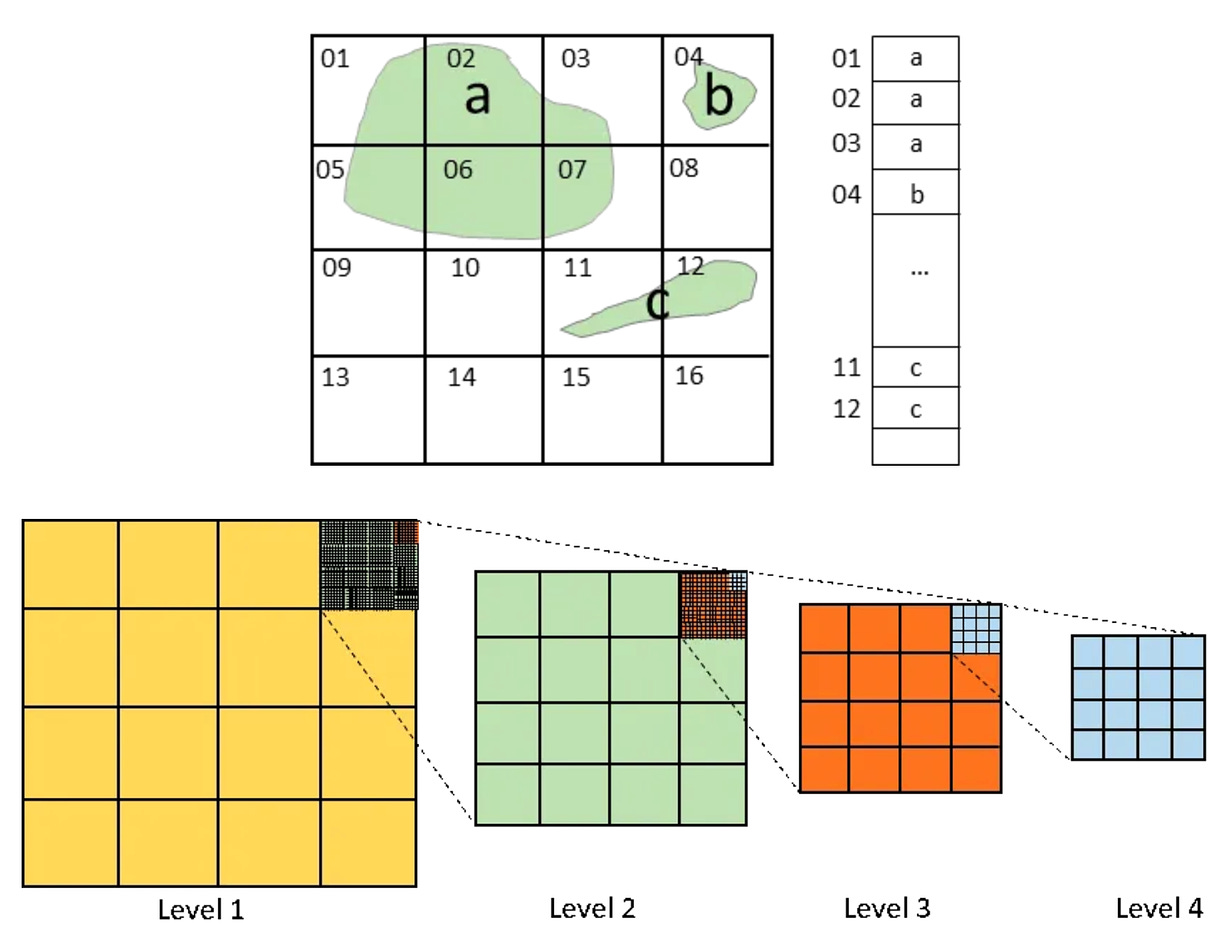
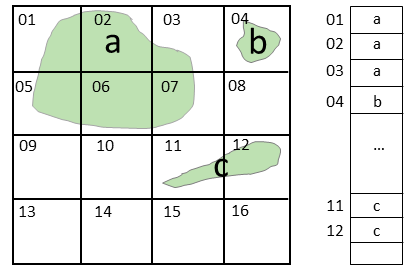
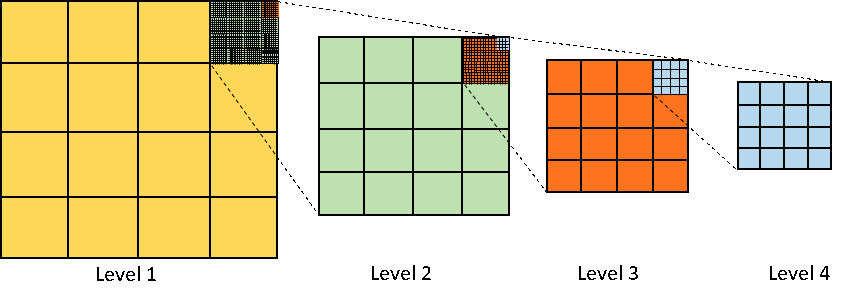
When a user starts typing a search term, the engine wants to suggest the most popular terms that start with the given prefix. A B-tree index on the search terms allows the engine to efficiently find all terms with the given prefix. Once these terms are found, they can be sorted by popularity score to provide the most relevant suggestions. In this scenario, a prefix search can be further optimized by using a trie or a prefix tree, a special kind of tree where each node represents a prefix of some string. Geo-Location LookupGeohashes are a form of spatial index that divides the Earth into a grid. Each cell in the grid is assigned a unique hash, and points within the same cell share the same hash prefix. This makes geohashes perfect for querying locations within a certain proximity.
To find all the points within a certain radius of a location, we only need to search for points that share a geohash prefix with the target location. This is a lot faster than calculating the distance to every point in the database... Keep reading with a 7-day free trialSubscribe to ByteByteGo Newsletter to keep reading this post and get 7 days of free access to the full post archives. A subscription gets you:
© 2023 ByteByteGo
|
by "ByteByteGo" <bytebytego@substack.com> - 11:39 - 3 Aug 2023