- Mailing Lists
- in
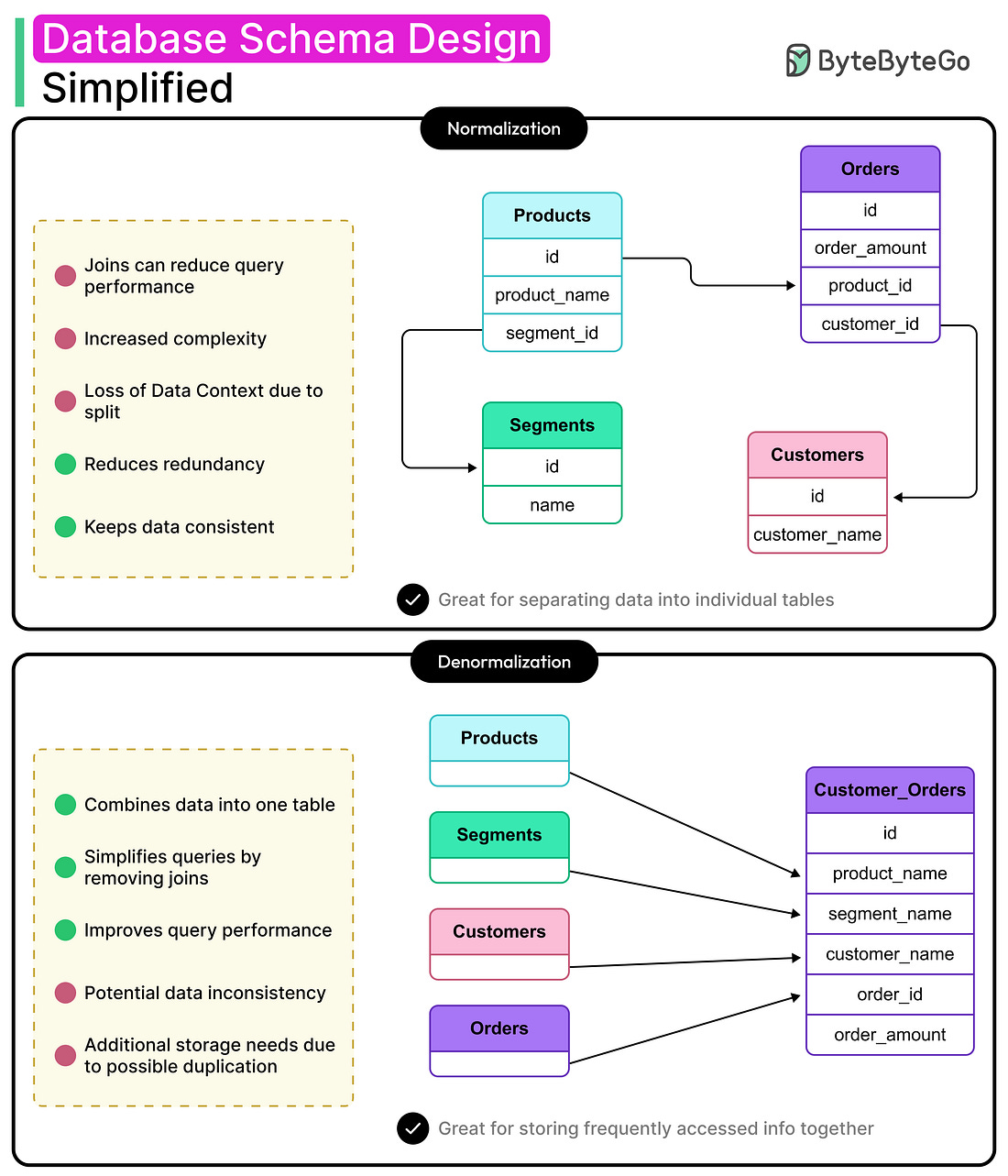
- Database Schema Design Simplified: Normalization vs Denormalization
Archives
- By thread 5018
-
By date
- June 2021 10
- July 2021 6
- August 2021 20
- September 2021 21
- October 2021 48
- November 2021 40
- December 2021 23
- January 2022 46
- February 2022 80
- March 2022 109
- April 2022 100
- May 2022 97
- June 2022 105
- July 2022 82
- August 2022 95
- September 2022 103
- October 2022 117
- November 2022 115
- December 2022 102
- January 2023 88
- February 2023 90
- March 2023 116
- April 2023 97
- May 2023 159
- June 2023 145
- July 2023 120
- August 2023 90
- September 2023 102
- October 2023 106
- November 2023 100
- December 2023 74
- January 2024 75
- February 2024 75
- March 2024 78
- April 2024 74
- May 2024 108
- June 2024 98
- July 2024 116
- August 2024 134
- September 2024 130
- October 2024 141
- November 2024 171
- December 2024 115
- January 2025 216
- February 2025 140
- March 2025 220
- April 2025 233
- May 2025 239
- June 2025 130
See what’s on the agenda at New Relic Now🔥
LAST CALL !!! Essential Business And Financial Acumen (15 & 16 July 2025)
Database Schema Design Simplified: Normalization vs Denormalization
Database Schema Design Simplified: Normalization vs Denormalization
Latest articlesIf you’re not a subscriber, here’s what you missed this month.
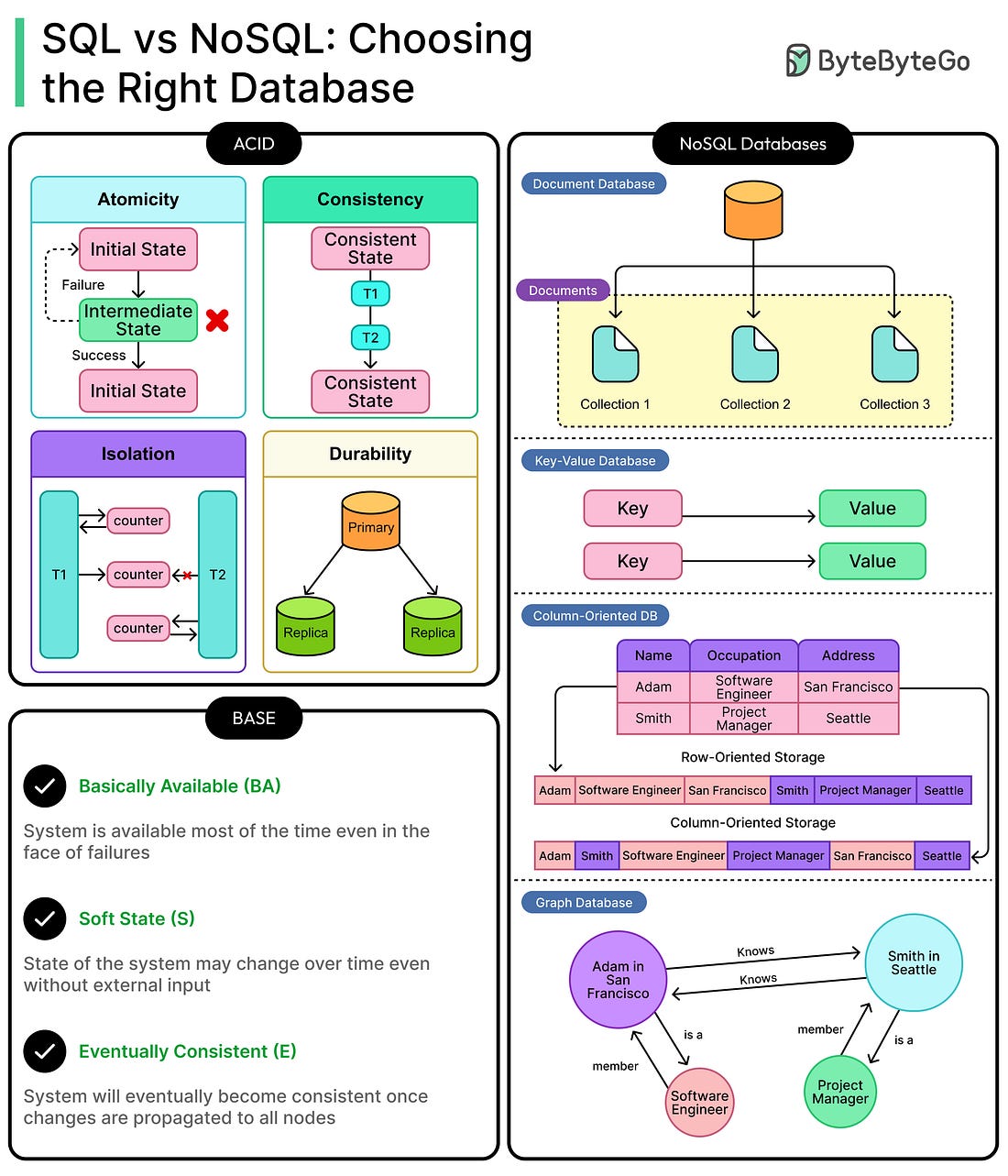
To receive all the full articles and support ByteByteGo, consider subscribing: Database schema design plays a crucial role in determining how quickly queries run, how easily features are implemented, and how well things perform at scale. Schema design is never static. What works at 10K users might collapse at 10 million. The best architects revisit schema choices, adapting structure to scale, shape, and current system goals. Done right, schema design can become a great asset for the system. It accelerates product velocity, reduces data duplication debt, and shields teams from late-stage refactors. Done wrong, it bottlenecks everything: performance, evolution, and sometimes entire features. Every engineering team hits the same fork in the road: normalize the schema for clean structure and consistency, or denormalize for speed and simplicity. The wrong choice doesn’t necessarily cause immediate issues. However, problems creep in through slow queries, fragile migrations, and data bugs that surface months later during a traffic spike or product pivot. In truth, normalization and denormalization aren't rival approaches, but just tools to get the job done. Each solves a different kind of problem. Normalization focuses on data integrity, minimal redundancy, and long-term maintainability. Denormalization prioritizes read efficiency, simplicity of access, and performance under load. In this article, we’ll look into both of them in detail. We’ll start with the foundations: normal forms and how they shape normalized schemas. We will then explore denormalization and the common strategies for implementing it. From there, we will map the trade-offs between normalization and denormalization The goal isn't to declare one approach as the winner. It's to understand their mechanics, consequences, and ideal use cases.
Foundations of Schema Design... Continue reading this post for free in the Substack app© 2025 ByteByteGo
|
by "ByteByteGo" <bytebytego@substack.com> - 11:36 - 12 Jun 2025