- Mailing Lists
- in
- Embracing Chaos to Improve System Resilience: Chaos Engineering
Archives
- By thread 5315
-
By date
- June 2021 10
- July 2021 6
- August 2021 20
- September 2021 21
- October 2021 48
- November 2021 40
- December 2021 23
- January 2022 46
- February 2022 80
- March 2022 109
- April 2022 100
- May 2022 97
- June 2022 105
- July 2022 82
- August 2022 95
- September 2022 103
- October 2022 117
- November 2022 115
- December 2022 102
- January 2023 88
- February 2023 90
- March 2023 116
- April 2023 97
- May 2023 159
- June 2023 145
- July 2023 120
- August 2023 90
- September 2023 102
- October 2023 106
- November 2023 100
- December 2023 74
- January 2024 75
- February 2024 75
- March 2024 78
- April 2024 74
- May 2024 108
- June 2024 98
- July 2024 116
- August 2024 134
- September 2024 130
- October 2024 141
- November 2024 171
- December 2024 115
- January 2025 216
- February 2025 140
- March 2025 220
- April 2025 233
- May 2025 239
- June 2025 303
- July 2025 127
Maximise ROI: Insights from the 2023 Observability Forecast Report
White Label Fuel Monitoring Software
Embracing Chaos to Improve System Resilience: Chaos Engineering
Embracing Chaos to Improve System Resilience: Chaos Engineering
Latest articlesIf you’re not a subscriber, here’s what you missed this month.
To receive all the full articles and support ByteByteGo, consider subscribing: Imagine it's the early 2000s, and you're a developer with a bold idea. You want to test your software not in a safe, controlled environment but right where the action is: the production environment. This is where real users interact with your system. Back then, suggesting something like this might have gotten you some strange looks from your bosses. But now, testing in the real world is not just okay; it's often recommended. Why the big change? A few reasons stand out. Systems today are more complex than ever, pushing us to innovate faster and ensure our services are both reliable and strong. The rise of cloud technology, microservices, and distributed systems has changed the game. We've had to adapt our methods and mindsets accordingly. Our goal now is to make systems that can handle anything—be it a slowdown or a full-blown outage. Enter Chaos Engineering. In this issue, we dive into what chaos engineering is all about. We'll break down its key principles, how it's practiced, and examples from the real world. You'll learn how causing a bit of controlled chaos can actually help find and fix weaknesses before they become major problems. Prepare to see how embracing chaos can lead to stronger, more reliable systems. Let's get started!
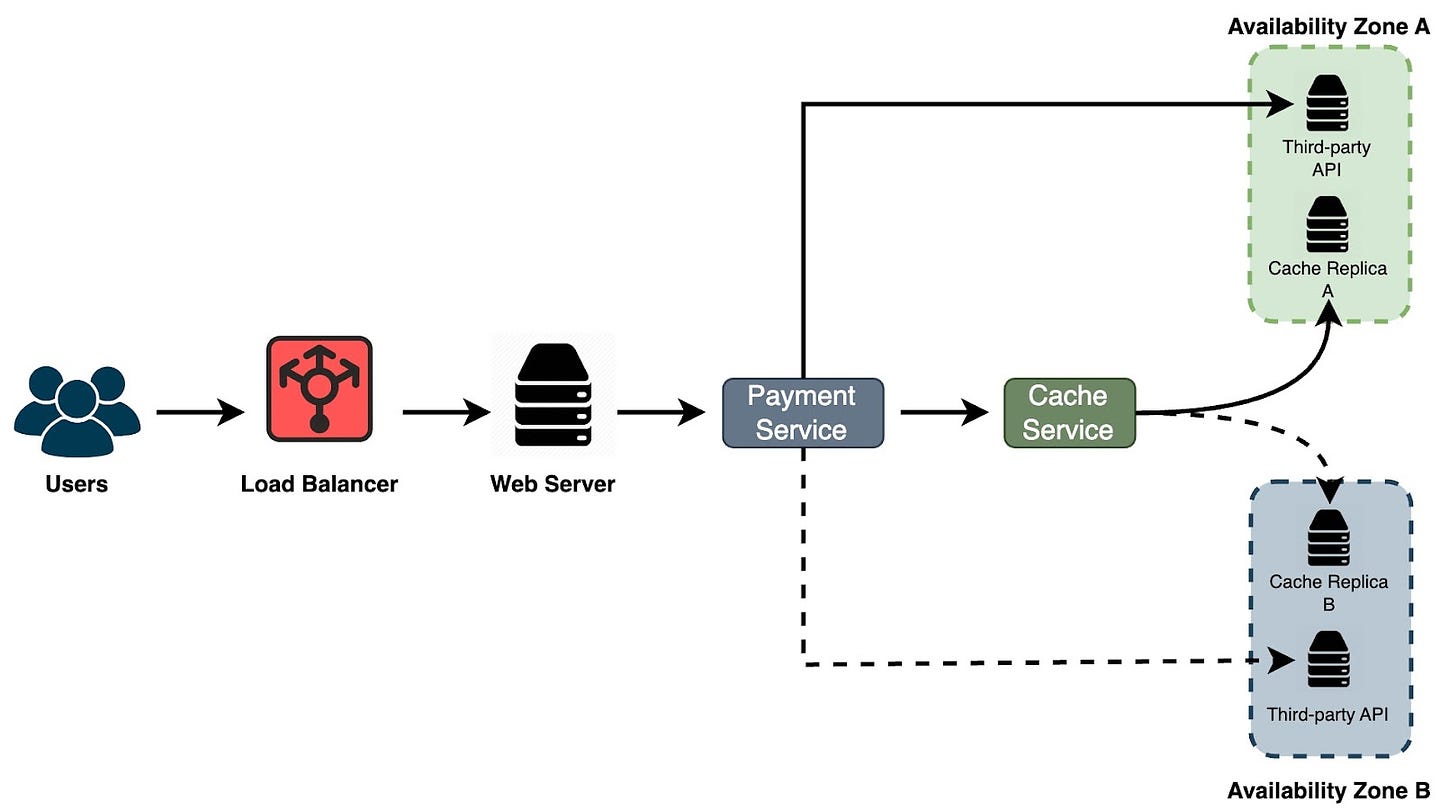
What is Chaos Engineering?So, what exactly is chaos engineering? It's a way to deal with unexpected issues in software development and keep systems up and running. Some folks might think that a server running an app will continue without a hitch forever. Others believe that problems are just part of the deal and that downtime is inevitable. Chaos engineering strikes a balance between these views. It recognizes that things can go wrong but asserts that we can take steps to prevent these issues from impacting our systems and the performance of our apps. This approach involves experimenting on our live, production systems to identify weak spots and areas that aren't as reliable as they should be. It's about measuring how much we trust our system's resilience and working to boost that confidence However, it's important to understand that being 100% sure nothing will go wrong is unrealistic. Through chaos engineering, we intentionally introduce unexpected events to uncover vulnerabilities. These events can vary widely, such as taking down a server randomly, disrupting a data center, or tampering with load balancers and application replicas. In short, chaos engineering is about designing experiments that rigorously test our systems' robustness. Defining Chaos EngineeringThere are many ways to describe chaos engineering, but here's a definition that captures its essence well, sourced from https://principlesofchaos.org/. “Chaos Engineering is the discipline of experimenting on a system in order to build confidence in the system’s capability to withstand turbulent conditions in production.” This definition highlights the core objective of chaos engineering: to ensure our systems can handle the unpredictable nature of real-world operations. Performance Engineering vs. Chaos EngineeringWhen we talk about ensuring our systems run smoothly, two concepts often come up: performance engineering and chaos engineering. Let's discuss what sets these two apart and how they might overlap. Many developers are already familiar with performance engineering, which is in the same family as DevOps. It involves using a combination of tools, processes, and technologies to monitor our system's performance and make continuous improvements. This includes conducting various types of testing, such as load, stress, and endurance tests, all aimed at boosting the performance of our applications. On the flip side, chaos engineering is about intentionally breaking things. Yes, this includes stress testing, but it's more about observing how systems respond under unexpected stress. Stress testing could be seen as a form of chaos experiment. So, one way to look at it is to consider performance engineering as a subset of chaos engineering or the other way around, depending on how you apply these practices. Another way to view these two is as distinct disciplines within an organization. One team might focus solely on conducting chaos experiments and learning from the failures, while another might immerse itself in performance engineering tasks like testing and monitoring. Depending on the structure of the organization, the skill sets of the team, and various other factors, we might have separate teams for each discipline or one team that tackles both. Chaos Engineering in PracticeLet's consider an example to better understand chaos engineering. Imagine we have a system with a load balancer that directs requests to web servers. These servers then connect to a payment service, which, in turn, interacts with a third-party API and a cache service, all located in Availability Zone A. If the payment service fails to communicate with the third-party API or the cache, requests need to be rerouted to Availability Zone B to maintain high availability.
 Continue reading this post for free, courtesy of Alex Xu.A subscription gets you:
© 2024 ByteByteGo
|
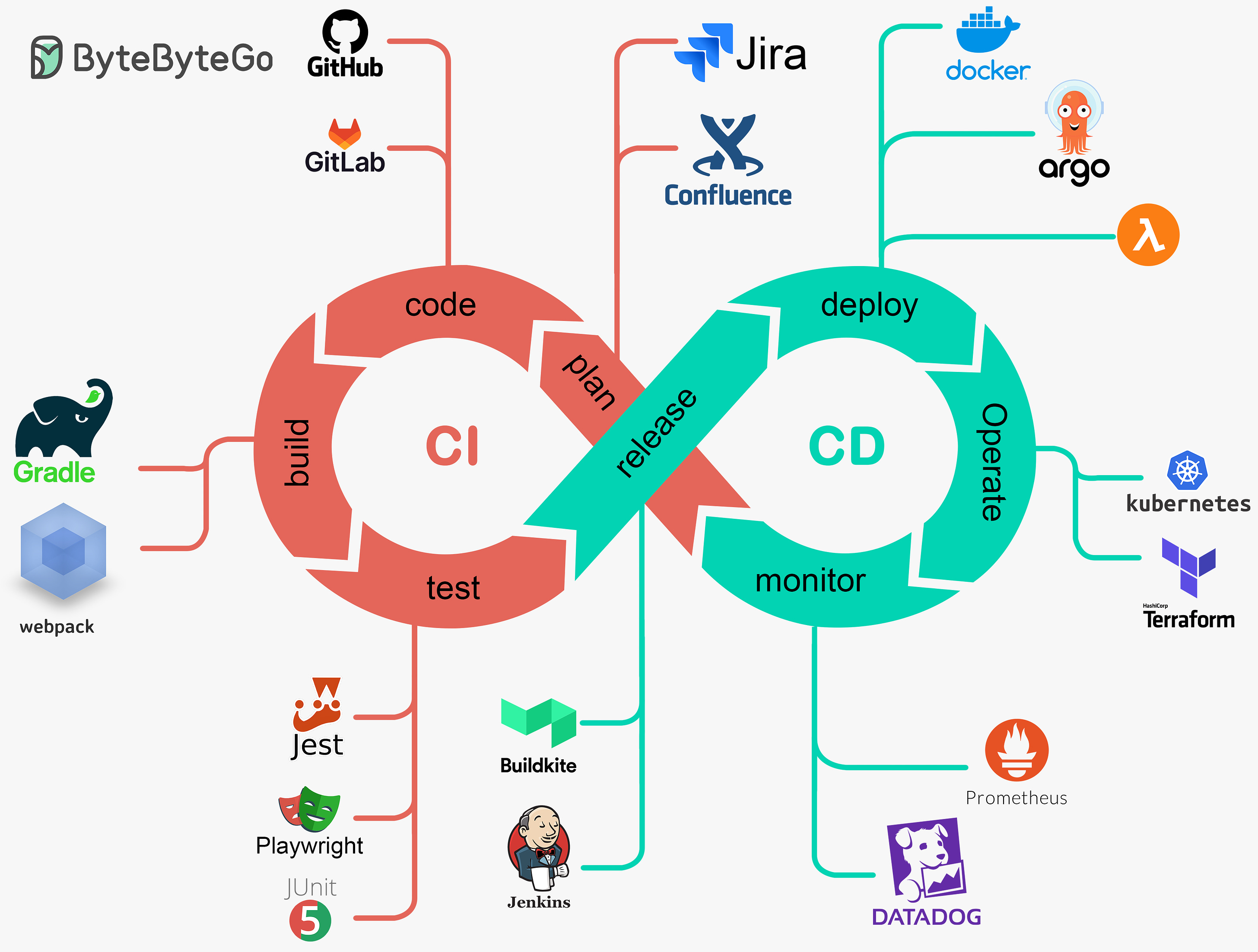

by "ByteByteGo" <bytebytego@substack.com> - 11:37 - 11 Apr 2024