- Mailing Lists
- in
- EP125: How does Garbage Collection work?
Archives
- By thread 5201
-
By date
- June 2021 10
- July 2021 6
- August 2021 20
- September 2021 21
- October 2021 48
- November 2021 40
- December 2021 23
- January 2022 46
- February 2022 80
- March 2022 109
- April 2022 100
- May 2022 97
- June 2022 105
- July 2022 82
- August 2022 95
- September 2022 103
- October 2022 117
- November 2022 115
- December 2022 102
- January 2023 88
- February 2023 90
- March 2023 116
- April 2023 97
- May 2023 159
- June 2023 145
- July 2023 120
- August 2023 90
- September 2023 102
- October 2023 106
- November 2023 100
- December 2023 74
- January 2024 75
- February 2024 75
- March 2024 78
- April 2024 74
- May 2024 108
- June 2024 98
- July 2024 116
- August 2024 134
- September 2024 130
- October 2024 141
- November 2024 171
- December 2024 115
- January 2025 216
- February 2025 140
- March 2025 220
- April 2025 233
- May 2025 239
- June 2025 303
- July 2025 12
Look back at some of our readers’ favorite recent charts
How companies can make big moves to beat the odds
EP125: How does Garbage Collection work?
EP125: How does Garbage Collection work?
This week’s system design refresher:
WorkOS: Modern Identity Platform for B2B SaaS (Sponsored)
Start selling to enterprises with just a few lines of code. → WorkOS provides a complete user management solution along with SSO, SCIM, Audit Logs, & Fine-Grained Authorization. → Unlike other auth providers that rely on user-centric models, WorkOS is designed for B2B SaaS with an org modeling approach. → The APIs are flexible, easy-to-use, and modular. Pick and choose what you need and integrate in minutes. → User management is free up to 1 million MAUs and comes standard with RBAC, bot protection, MFA, & more. Linux Performance Tools!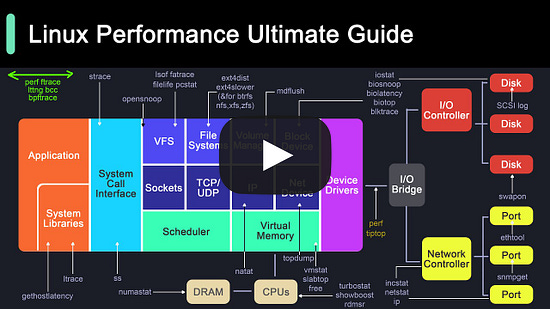 How does Garbage Collection work?Garbage collection is an automatic memory management feature used in programming languages to reclaim memory no longer used by the program. 
Latest articlesIf you’re not a paid subscriber, here’s what you missed.
To receive all the full articles and support ByteByteGo, consider subscribing: A Cheat Sheet for Designing Fault-Tolerant Systems
Designing fault-tolerant systems is crucial for ensuring high availability and reliability in various applications. Here are six top principles of designing fault-tolerant systems:
10 System Design Tradeoffs You Cannot IgnoreIf you don’t know trade-offs, you DON'T KNOW system design.
Over to you: Which other tradeoffs have you encountered? SPONSOR USGet your product in front of more than 1,000,000 tech professionals. Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases. Space Fills Up Fast - Reserve Today Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com © 2024 ByteByteGo
|

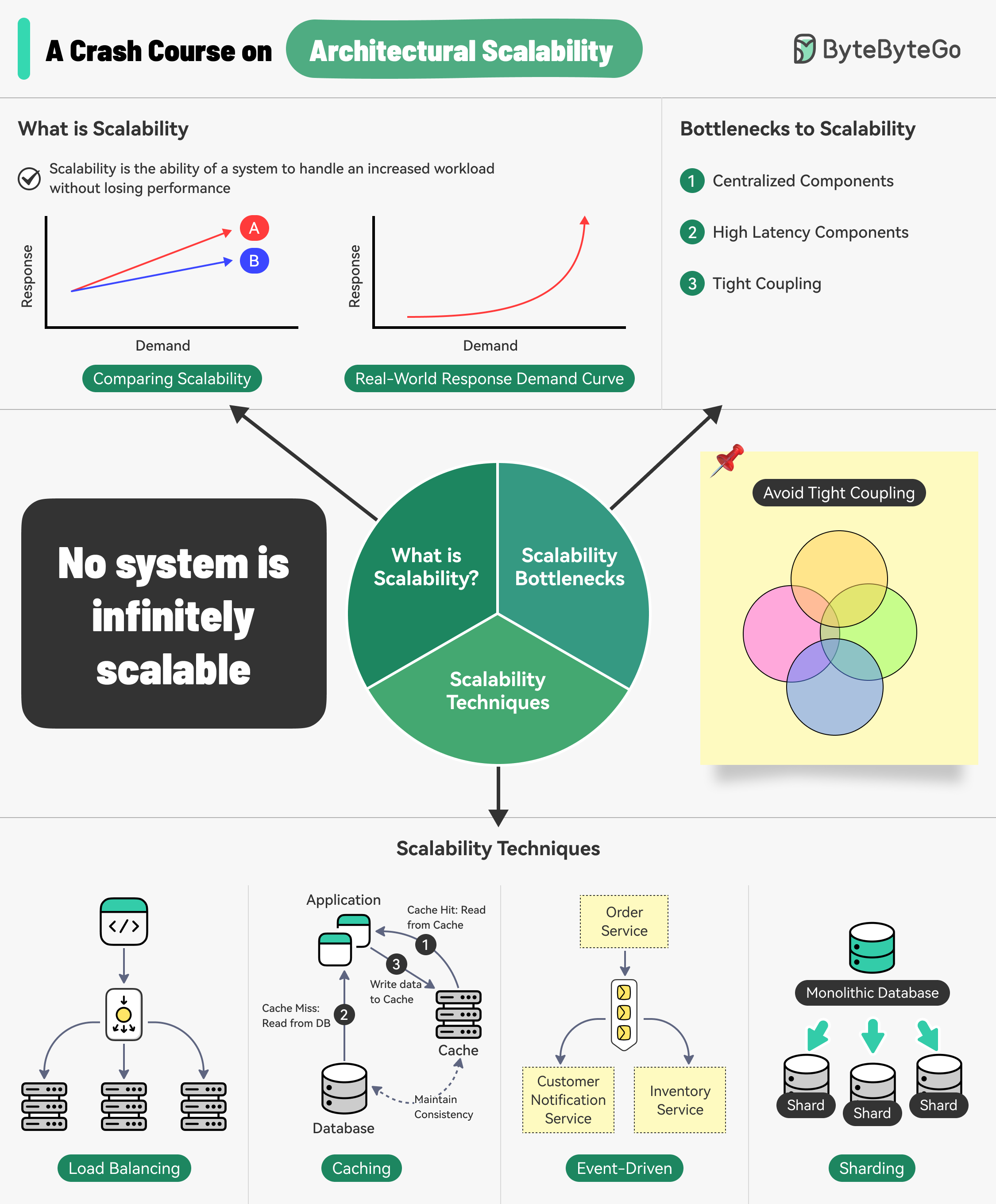


by "ByteByteGo" <bytebytego@substack.com> - 11:35 - 17 Aug 2024