- Mailing Lists
- in
- How do We Design for High Availability?
Archives
- By thread 5222
-
By date
- June 2021 10
- July 2021 6
- August 2021 20
- September 2021 21
- October 2021 48
- November 2021 40
- December 2021 23
- January 2022 46
- February 2022 80
- March 2022 109
- April 2022 100
- May 2022 97
- June 2022 105
- July 2022 82
- August 2022 95
- September 2022 103
- October 2022 117
- November 2022 115
- December 2022 102
- January 2023 88
- February 2023 90
- March 2023 116
- April 2023 97
- May 2023 159
- June 2023 145
- July 2023 120
- August 2023 90
- September 2023 102
- October 2023 106
- November 2023 100
- December 2023 74
- January 2024 75
- February 2024 75
- March 2024 78
- April 2024 74
- May 2024 108
- June 2024 98
- July 2024 116
- August 2024 134
- September 2024 130
- October 2024 141
- November 2024 171
- December 2024 115
- January 2025 216
- February 2025 140
- March 2025 220
- April 2025 233
- May 2025 239
- June 2025 303
- July 2025 34
What should US healthcare leaders expect in the coming years?
Driver Monitoring Software that enables efficient tracking and management of driver activities.
How do We Design for High Availability?
How do We Design for High Availability?
Latest articlesIf you’re not a subscriber, here’s what you missed this month.
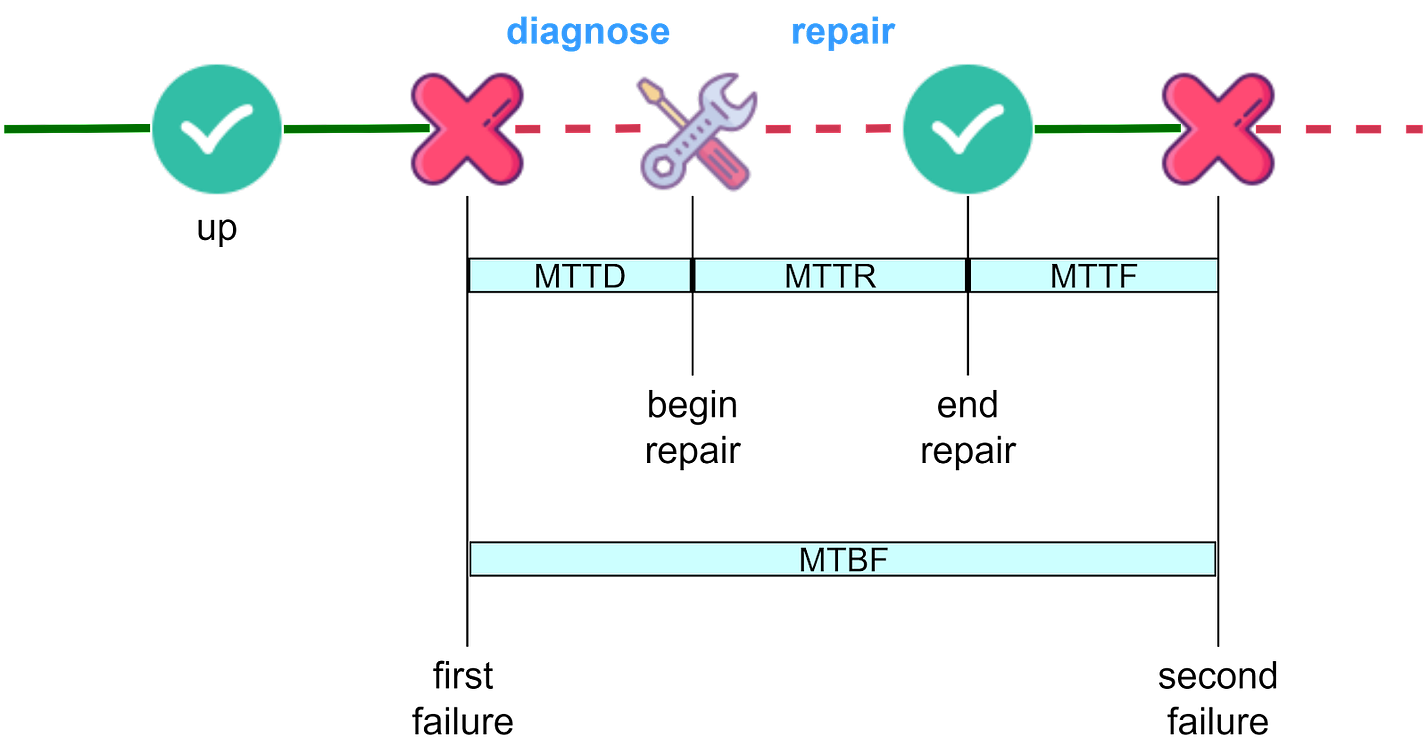
To receive all the full articles and support ByteByteGo, consider subscribing: In an era where digital presence is vital for business continuity, the concept of high availability (HA) has become a cornerstone in system design. High availability refers to systems that can operate continuously without failure for extended periods. This article explores the evolution of high availability, how it is measured, how it is implemented in various systems, and the trade-offs involved in achieving it. What is High Availability?The concept of high availability originated in the 1960s and 1970s with early military and financial computing systems that needed to be reliable and fault tolerant. In the Internet age, there has been an explosion of digital applications for e-commerce, payments, delivery, finance, and more. Positive user experiences are crucial for business success. This escalated the need for systems with nearly 100% uptime to avoid losing thousands of users for even brief periods. For example, during a promotional flash sale event, just one minute of downtime could lead to complete failure and reputation damage. The goal of high availability is to ensure a system or service is available and functional for as close to 100% of the time as possible. While the terms high availability and uptime are sometimes used interchangeably, high availability encompasses more than just uptime measurements. How do We Measure High Availability?Two key concepts are relevant for calculating availability: Mean Time Between Failures (MTBF), and Mean Time To Repair (MTTR). MTBF and MTTRMTBF measures system reliability by totaling a system’s operational time and dividing it by the number of failures over that period. It is typically expressed in hours. A higher MTBF indicates better reliability. MTTR is the average time required to repair a failed component or system and return it to an operational state. It includes diagnosis time, spare part retrieval, actual repair, testing, and confirmation of operation. MTTR is also typically measured in hours. As shown in the diagram below, there are two additional related metrics - MTTD (Mean Time To Diagnose) and MTTF (Mean Time To Failure). MTTR can loosely include diagnosis time.
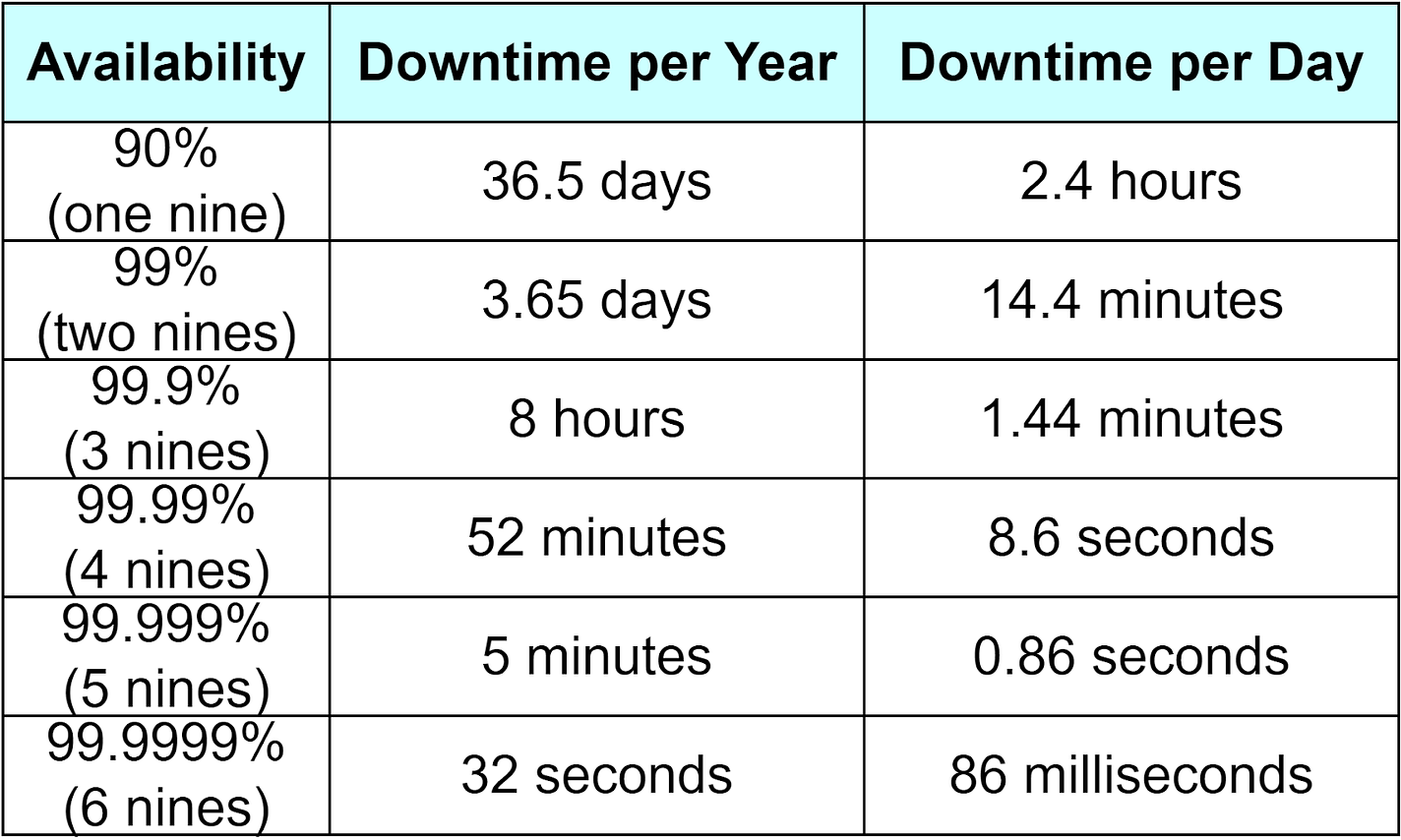
The NinesTogether, MTBF and MTTR are critical for calculating system availability. Availability is the ratio of total operational time to the sum of operational time and repair time. Using formulas: Availability=MTBFMTBF+MTTR For high-availability systems, the goal is to maximize MTBF (less frequent failures) and minimize MTTR (fast recovery from failures). These metrics help teams make informed decisions to improve system reliability and availability. As shown in the diagram below, calculated availability is often discussed in terms of “nines”. Achieving “3 nines” availability allows only 1.44 minutes of downtime per day - challenging for manual troubleshooting. “4 nines” allows only 8.6 seconds of downtime daily, requiring automatic monitoring, alerts, and troubleshooting. This adds requirements like automatic failure detection and rollback planning in system designs.
Typical ArchitecturesTo achieve “4 nines” availability and beyond, we must consider:
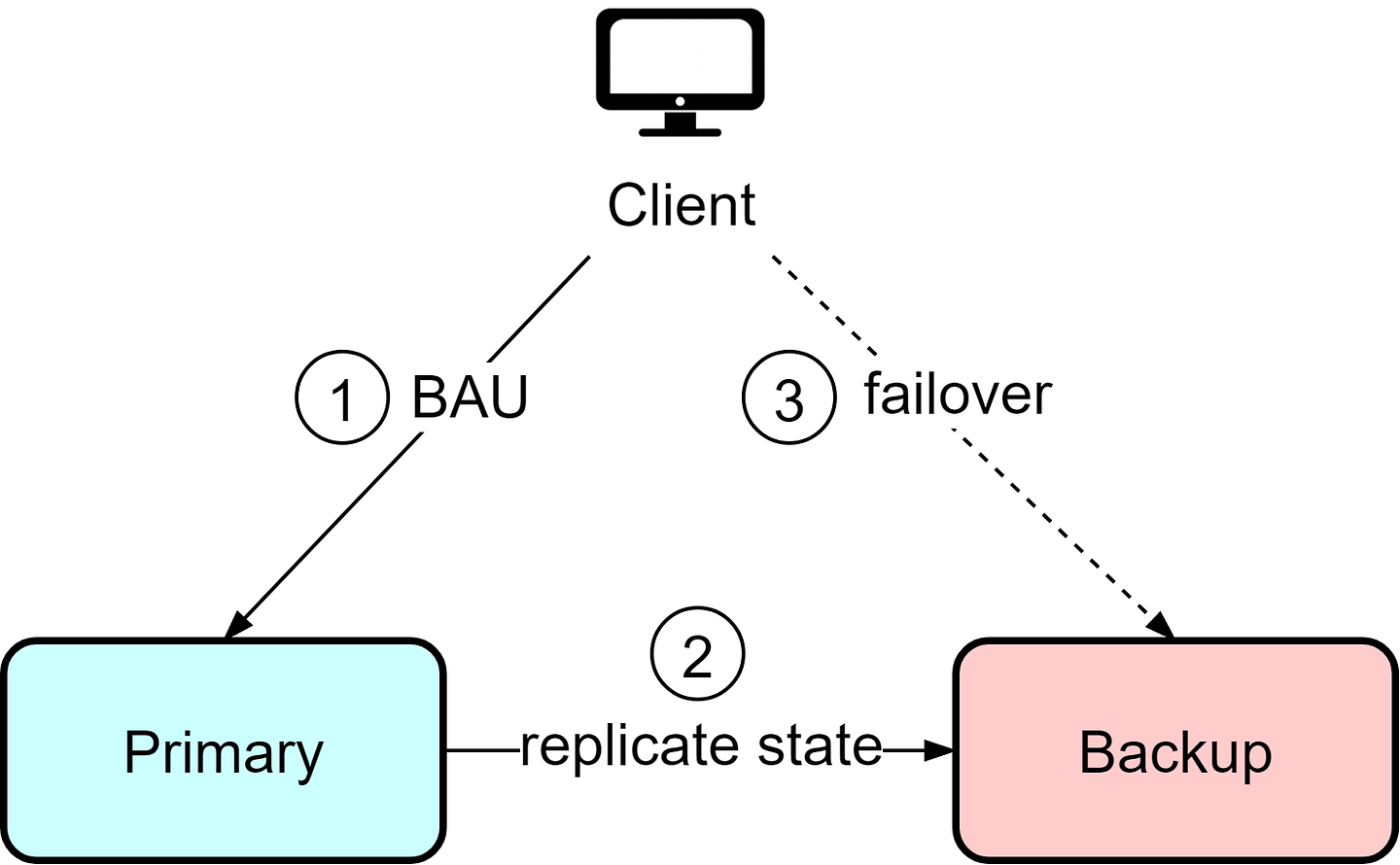
Let’s explore system designs in more detail. RedundancyThere is only so much we can do to optimize a single instance to be fault-tolerant. High availability is often achieved by adding redundancies. When one instance fails, others take over. For stateful instances like storage, we also need data replication strategies. Let's explore common architectures with different forms of redundancy and their tradeoffs. Hot-ColdIn the hot-cold architecture, there is a primary instance that handles all reads and writes from clients, as well as a backup instance. Clients interact only with the primary instance and are unaware of the backup. The primary instance continuously synchronizes data to the backup instance. If the primary fails, manual intervention is required to switch clients over to the backup instance.
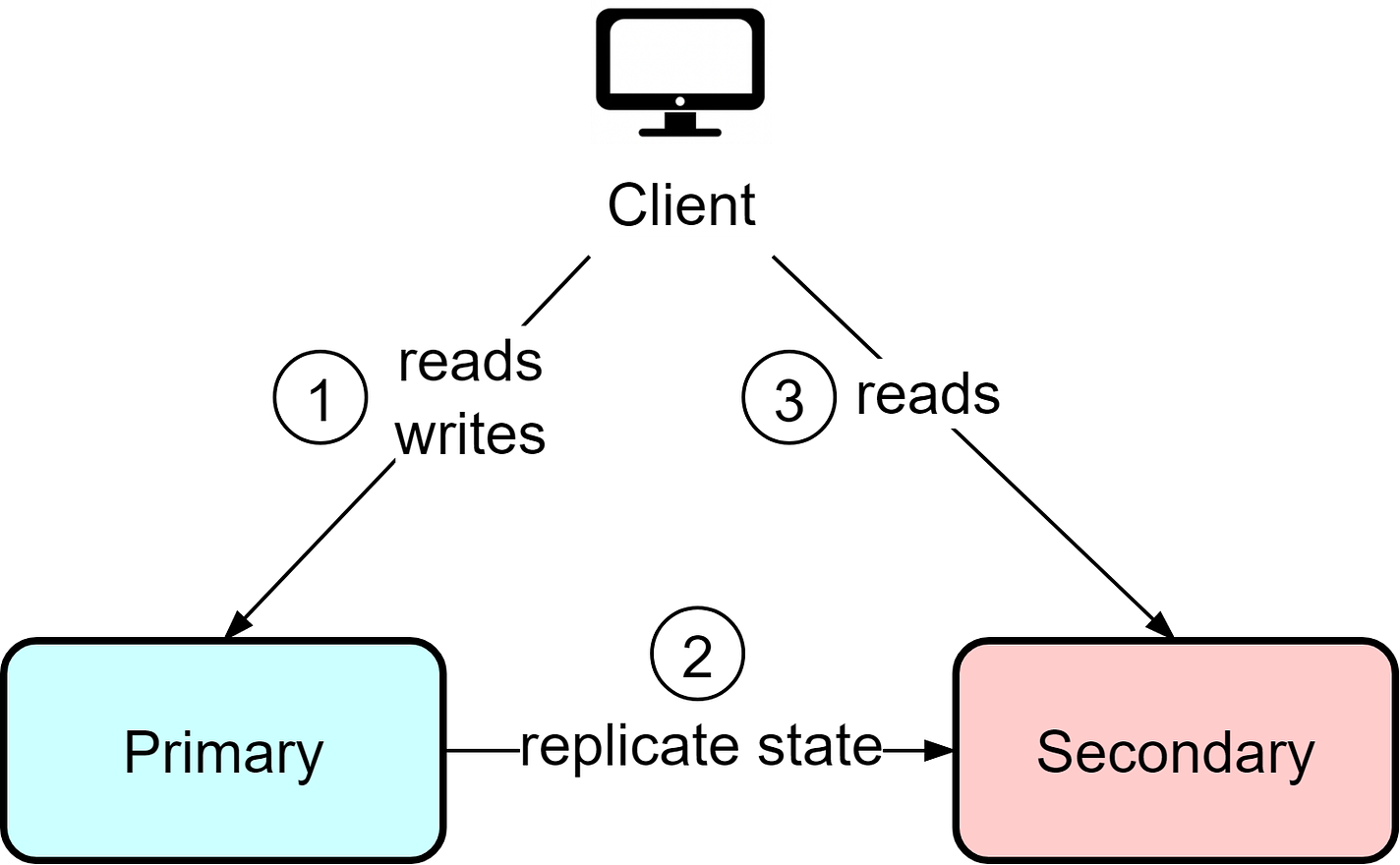
This architecture is straightforward but has some downsides. The backup instance represents waste resources since it is idle most of the time. Additionally, if the primary fails, there is potential for data loss depending on the last synchronization time. When recovering from the backup, manual reconciliation of the current state is required to determine what data may be missing. This means clients need to tolerate potential data loss and resend missing information. Hot-WarmThe hot-cold architecture wastes resources since the backup instance is under-utilized. The hot-warm architecture optimizes this by allowing clients to read from the secondary/backup instance. If the primary fails, clients can still read from the secondary with reduced capacity.
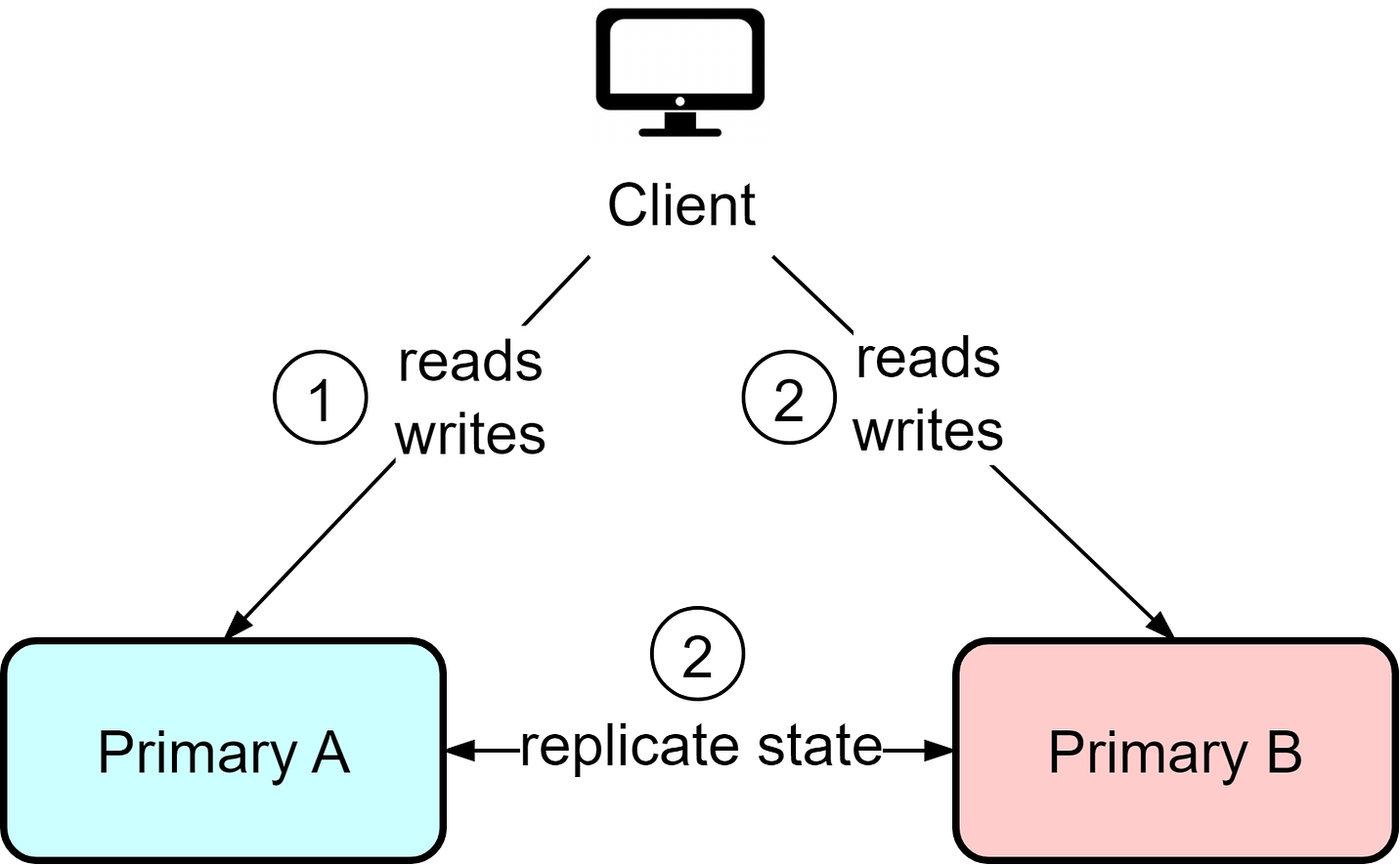
Since reads are allowed from the secondary, data consistency between the primary and secondary becomes crucial. Even if the primary instance is functioning normally, stale data could be returned from reads since requests go to both instances. Compared with hot-cold, the hot-warm architecture is more suitable for read-heavy workloads like news sites and blogs. The tradeoff is potential stale reads even during normal operation in order to utilize resources more efficiently. Hot-HotIn the hot-hot architecture, both instances act as primaries and can handle reads and writes. This provides flexibility, but it also means writes can occur to both instances, requiring bidirectional state replication. This can lead to data conflicts if certain data needs sequential ordering. For example, if user IDs are assigned from a sequence, user Bob may end up with ID 10 on instance A while user Alice gets assigned the same ID from instance B. The hot-hot architecture works best when replication needs are minimal, usually involving temporary data like user sessions and activities. Use caution with data requiring strong consistency guarantees.
Keep reading with a 7-day free trialSubscribe to ByteByteGo Newsletter to keep reading this post and get 7 days of free access to the full post archives. A subscription gets you:
© 2024 ByteByteGo
|
by "ByteByteGo" <bytebytego@substack.com> - 11:39 - 8 Feb 2024