- Mailing Lists
- in
- How Facebook served billions of requests per second Using Memcached
Archives
- By thread 5230
-
By date
- June 2021 10
- July 2021 6
- August 2021 20
- September 2021 21
- October 2021 48
- November 2021 40
- December 2021 23
- January 2022 46
- February 2022 80
- March 2022 109
- April 2022 100
- May 2022 97
- June 2022 105
- July 2022 82
- August 2022 95
- September 2022 103
- October 2022 117
- November 2022 115
- December 2022 102
- January 2023 88
- February 2023 90
- March 2023 116
- April 2023 97
- May 2023 159
- June 2023 145
- July 2023 120
- August 2023 90
- September 2023 102
- October 2023 106
- November 2023 100
- December 2023 74
- January 2024 75
- February 2024 75
- March 2024 78
- April 2024 74
- May 2024 108
- June 2024 98
- July 2024 116
- August 2024 134
- September 2024 130
- October 2024 141
- November 2024 171
- December 2024 115
- January 2025 216
- February 2025 140
- March 2025 220
- April 2025 233
- May 2025 239
- June 2025 303
- July 2025 42
How can tokenization be used to speed up financial transactions?
Important: Platform migration on May 18, 7-9 am UTC 🔧
How Facebook served billions of requests per second Using Memcached
How Facebook served billions of requests per second Using Memcached
Creating stronger passwords with AuthKit (Sponsored)
A common cause of data breaches and account hijacking is customers using weak or common passwords. There are two absolute truths about running a social network at the scale of Facebook:
These two factors determine whether people are going to stay on your social network or not. Even a few people leaving impacts the entire user base because the users are interconnected. Most people are online because their friends or relatives are online and there’s a domino effect at play. If one user drops off due to issues, there are chances that other users will also leave. Facebook had to deal with these issues early on because of its popularity. At any point in time, millions of people were accessing Facebook from all over the world. In terms of software design, this meant a few important requirements:
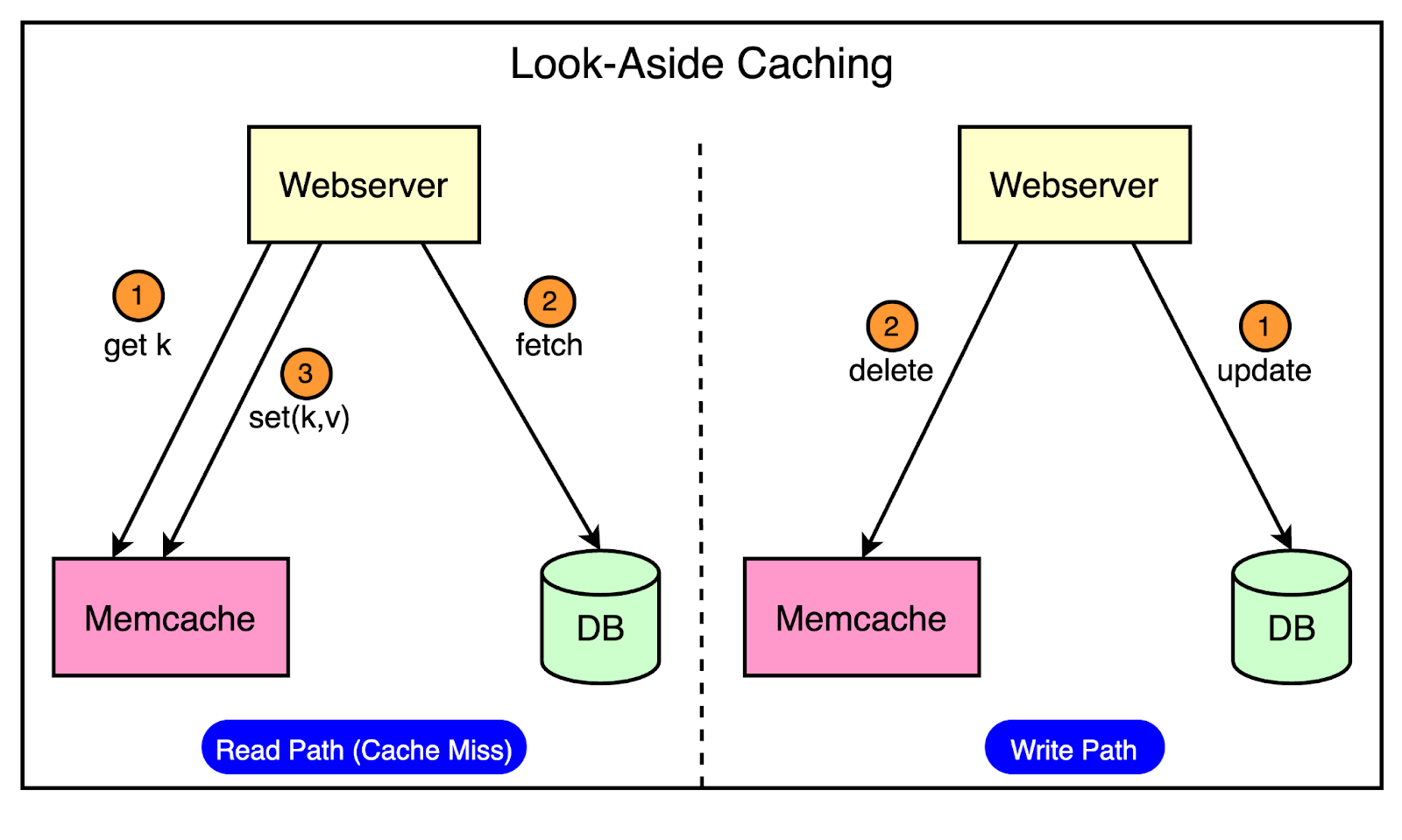
To achieve these goals, Facebook took up the open-source version of Memcached and enhanced it to build a distributed key-value store. This enhanced version was known as Memcache. In this post, we will look at how Facebook solved the multiple challenges in scaling memcached to serve billions of requests per second. Introduction to MemcachedMemcached is an in-memory key-value store that supports a simple set of operations such as set, get, and delete. The open-source version provided a single-machine in-memory hash table. The engineers at Facebook took up this version as a basic building block to create a distributed key-value store known as Memcache. In other words, “Memcached” is the source code or the running binary whereas “Memcache” stands for the distributed system behind it. Technically, Facebook used Memcache in two main ways: Query CacheThe job of the query cache was to reduce the load on the primary source-of-truth databases. In this mode, Facebook used Memcache as a demand-filled look-aside cache. You may have also heard about it as the cache-aside pattern. The below diagram shows how the look-aside cache pattern works for the read and write path.
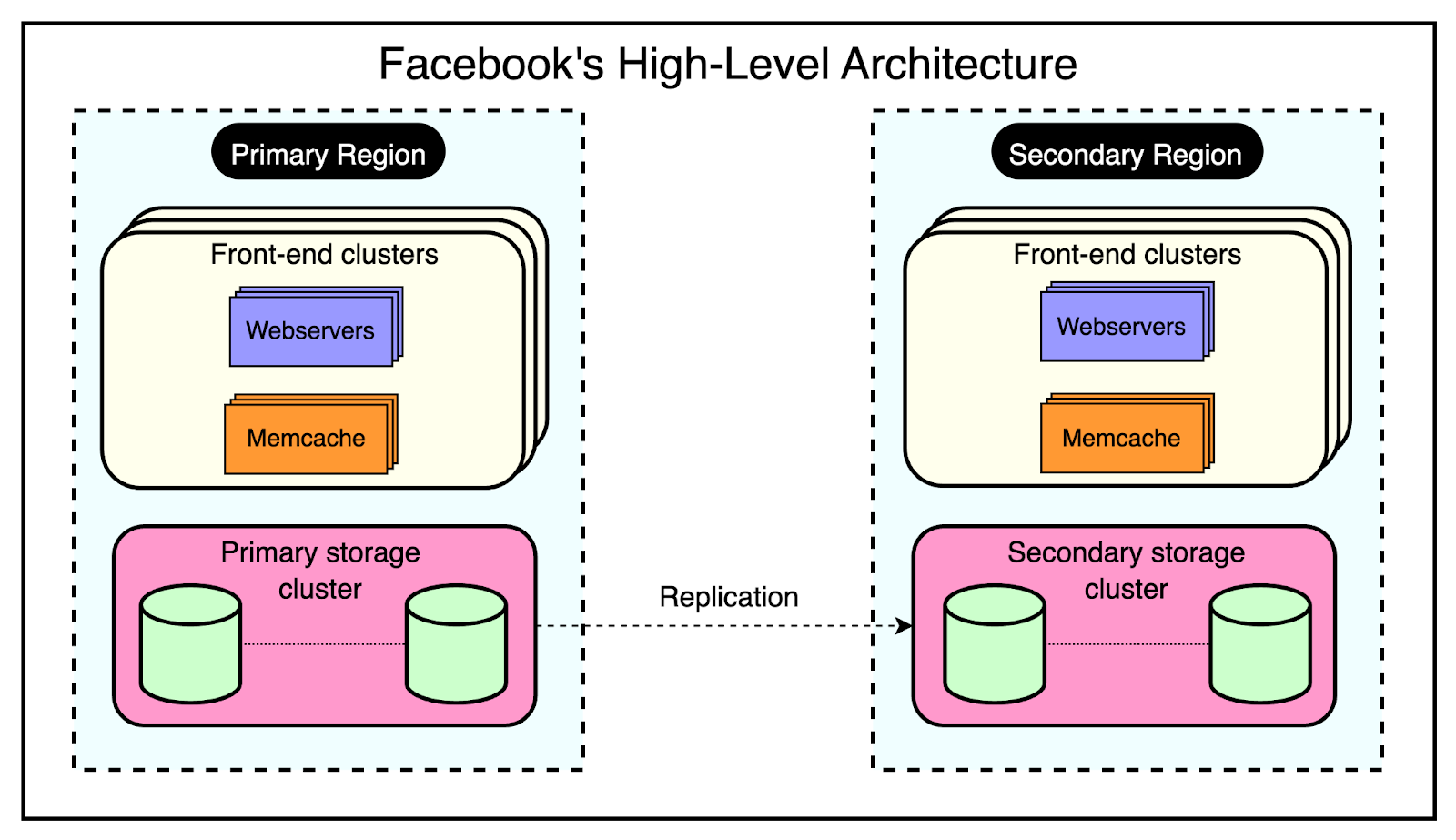
The read path utilizes a cache that is filled on-demand. This means that data is only loaded into the cache when a client specifically requests it. Before serving the request, the client first checks the cache. If the desired data is not found in the cache (a cache miss), the client retrieves the data from the database and also updates the cache. The write path takes a more interesting approach to updating data. After a particular key is updated in the database, the system doesn’t directly update the corresponding value in the cache. Instead, it removes the data for that key from the cache entirely. This process is known as cache invalidation. By invalidating the cache entry, the system ensures that the next time a client requests data for that key, it will experience a cache miss and be forced to retrieve the most up-to-date value directly from the database. This approach helps maintain data consistency between the cache and the database. Generic CacheFacebook also leverages Memcache as a general-purpose key-value store. This allows different teams within the organization to utilize Memcache for storing pre-computed results generated from computationally expensive machine learning algorithms. By storing these pre-computed ML results in Memcache, other applications can quickly and easily access them whenever needed. This approach offers several benefits such as improved performance and resource optimization. High-Level Architecture of FacebookFacebook’s architecture is built to handle the massive scale and global reach of its platform. At the time of their Memcached adoption, Facebook’s high-level architecture consisted of three key components: 1 - RegionsFacebook strategically places its servers in various locations worldwide, known as regions. These regions are classified into two types:
Each region, whether primary or secondary, contains multiple frontend clusters and a single storage cluster. 2 - Frontend ClustersWithin each region, Facebook employs frontend clusters to handle user requests and serve content. A frontend cluster consists of two main components:
The frontend clusters are designed to scale horizontally based on demand. As user traffic increases, additional web and Memcache servers can be added to the cluster to handle the increased load. 3 - Storage ClusterAt the core of each region lies the storage cluster. This cluster contains the source-of-truth database, which stores the authoritative copy of every data item within Facebook’s system. The storage cluster takes care of data consistency, durability, and reliability. By replicating data across multiple regions and employing a primary-secondary architecture, Facebook achieves high availability and fault tolerance. The below diagram shows the high-level view of this architecture:
One major philosophy that Facebook adopted was a willingness to expose slightly stale data instead of allowing excessive load on the backend. Rather than striving for perfect data consistency at all times, Facebook accepted that users may sometimes see outdated information in their feeds. This approach allowed them to handle high traffic loads without crumbling under excessive strain on the backend infrastructure. To make this architecture work at an unprecedented scale of billions of requests every day, Facebook had to solve multiple challenges such as:
In the next few sections, we will look at how Facebook handled each of these challenges. Within Cluster ChallengesThere were three important goals for the within-cluster operations:
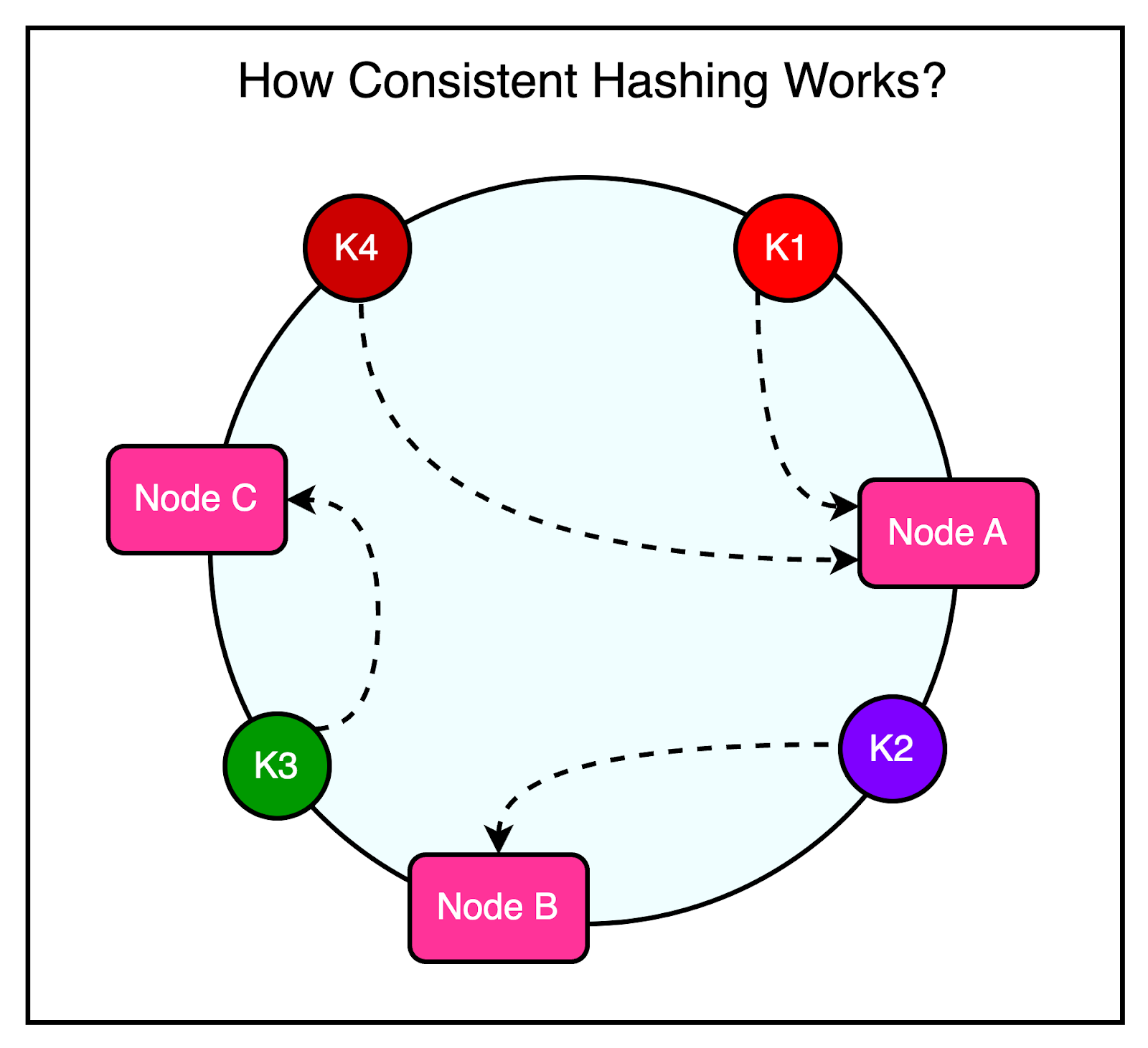
1 - Reducing LatencyAs mentioned earlier, every frontend cluster contains hundreds of Memcached servers, and items are distributed across these servers using techniques like Consistent Hashing. For reference, Consistent Hashing is a technique that allows the distribution of a set of keys across multiple nodes in a way that minimizes the impact of node failures or additions. When a node goes down or a new node is introduced, Consistent Hashing ensures that only a small subset of keys needs to be redistributed, rather than requiring a complete reshuffling of data. The diagram illustrates the concept of Consistent Hashing where keys are mapped to a circular hash space, and nodes are assigned positions on the circle. Each key is assigned to the node that falls closest to it in a clockwise direction.
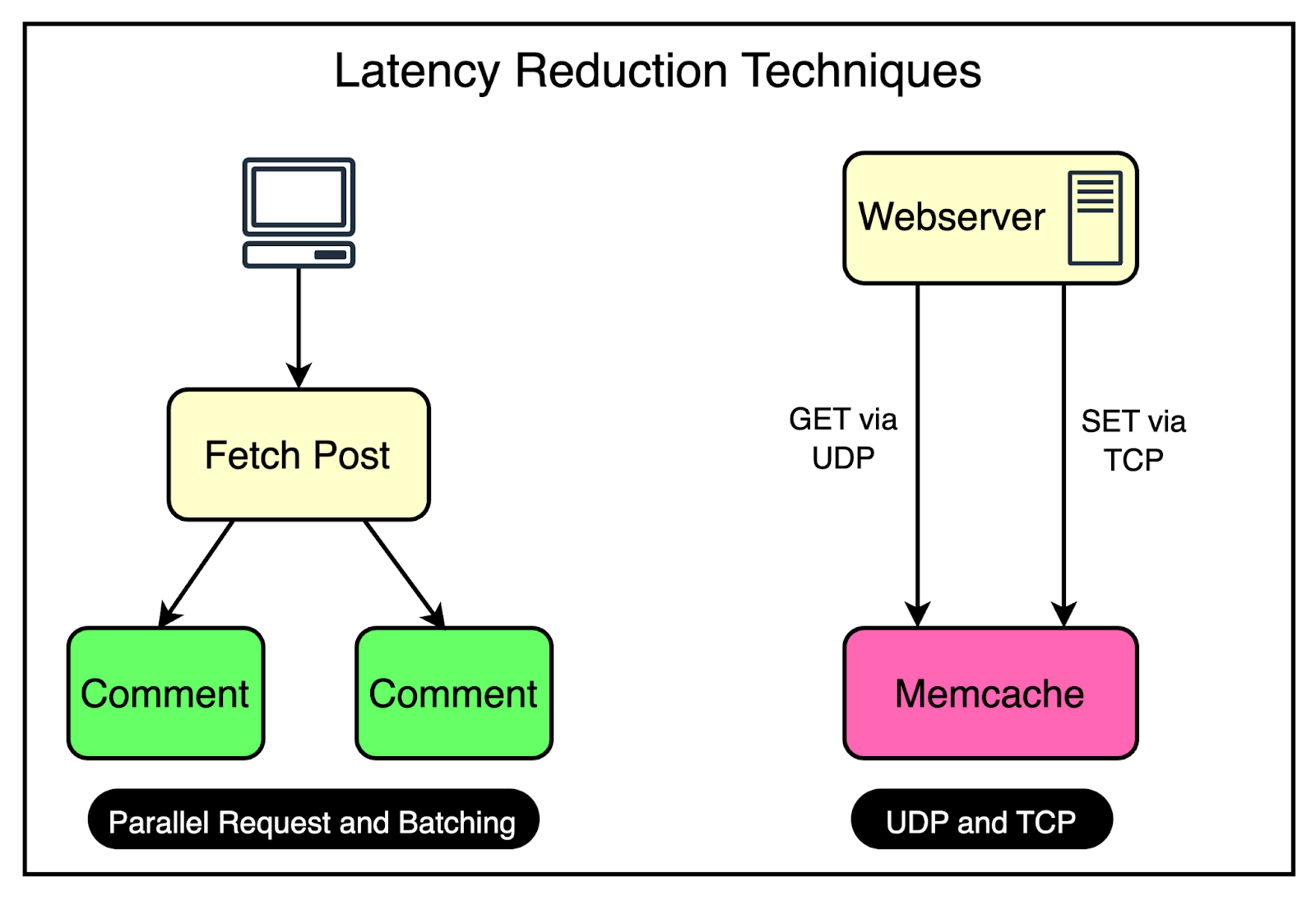
At Facebook's scale, a single web request can trigger hundreds of fetch requests to retrieve data from Memcached servers. Consider a scenario where a user loads a popular page containing numerous posts and comments. Even a single request can require the web servers to communicate with multiple Memcached servers in a short timeframe to populate the necessary data. This high-volume data fetching occurs not only in cache hit situations but also when there’s a cache miss. The implication is that a single Memcached server can turn into a bottleneck for many web servers, leading to increased latency and degraded performance for the end user. To reduce the possibility of such a scenario, Facebook uses a couple of important tricks visualized in the diagram.
Parallel Requests and BatchingTo understand the concept of parallel requests and batching, consider a simple analogy. Imagine going to the supermarket every time you need an item. It would be incredibly time-consuming and inefficient to make multiple trips for individual items. Instead, it’s much more effective to plan your shopping trip and purchase a bunch of items together in a single visit. The same optimization principle applies to data retrieval in Facebook's frontend clusters. To maximize the efficiency of data retrieval, Facebook constructs a Directed Acyclic Graph (DAG) that represents the dependencies between different data items. The DAG provides a clear understanding of which data items can be fetched concurrently and which items depend on others. By analyzing the DAG, the web server can determine the optimal order and grouping of data fetches. It identifies data items that can be retrieved in parallel, without any dependencies, and groups them in a single batch request. Using UDPFacebook employed a clever strategy to optimize network communication between the web servers and the Memcache server. For fetch requests, Facebook configured the clients to use UDP instead of TCP. As you may know, UDP is a connectionless protocol and much faster than TCP. By using UDP, the clients can send fetch requests to the Memcache servers with less network overhead, resulting in faster request processing and reduced latency. However, UDP has a drawback: it doesn’t guarantee the delivery of packets. If a packet is lost during transmission, UDP doesn’t have a built-in mechanism to retransmit it. To handle such cases, they treated UDP packet loss as a cache miss on the client side. If a response isn’t received within a specific timeframe, the client assumes that the data is not available in the cache and proceeds to fetch it from the primary data source. For update and delete operations, Facebook still used TCP since it provided a reliable communication channel that ensured the delivery of packets in the correct order. It removed the need for adding a specific retry mechanism, which is important when dealing with update and delete operations. All these requests go through a special proxy known as mcrouter that runs on the same machine as the webserver. Think of the mcrouter as a middleman that performs multiple duties such as data serialization, compression, routing, batching, and error handling. We will look at mcrouter in a later section. 2 - Reducing LoadThe most important goal for Memcache is to reduce the load on the database by reducing the frequency of data fetching from the database. Using Memcache as a look-aside cache solves this problem significantly. But at Facebook’s scale, two caching-related issues can easily appear.
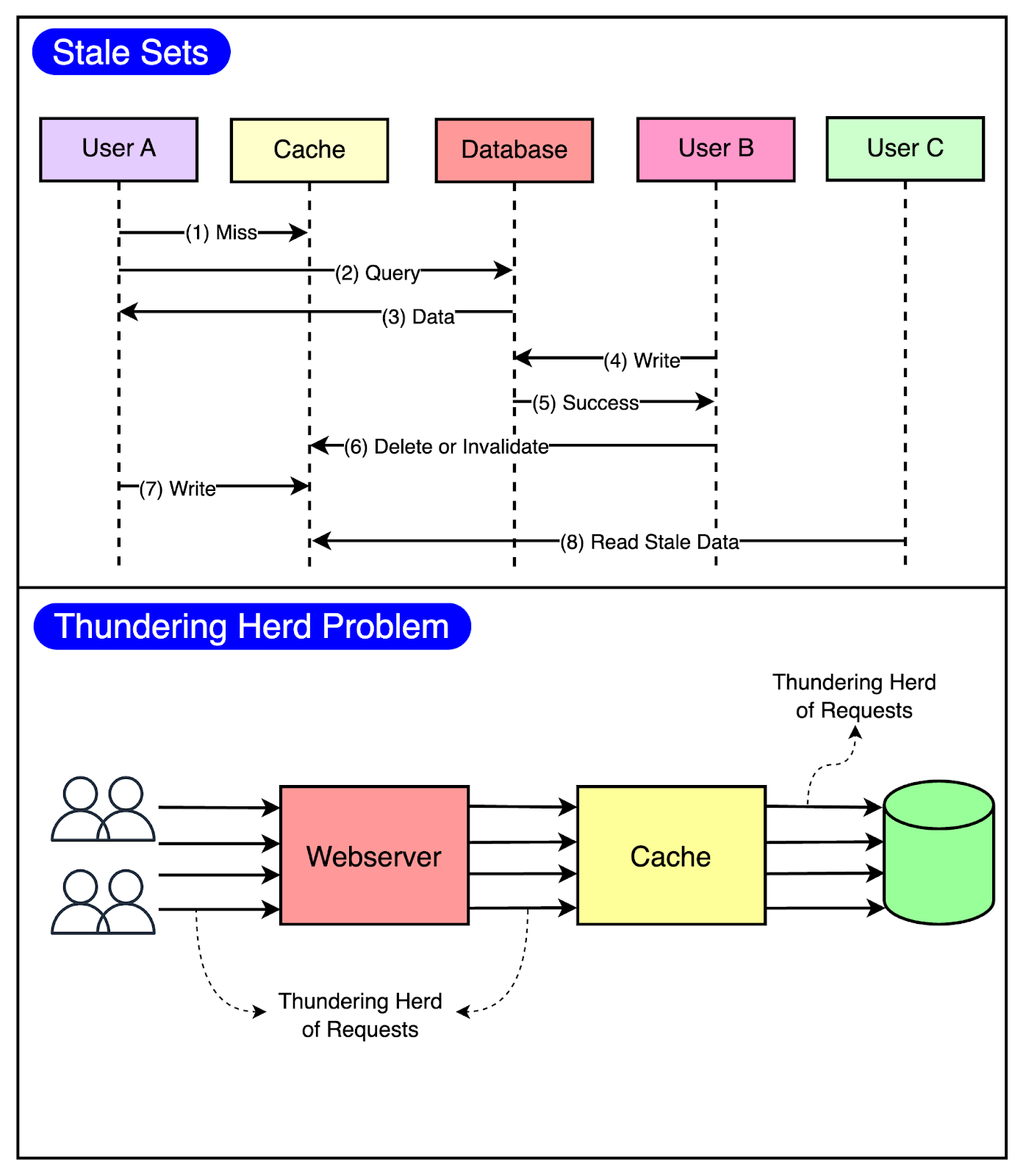
The below diagram visualizes both of these issues.
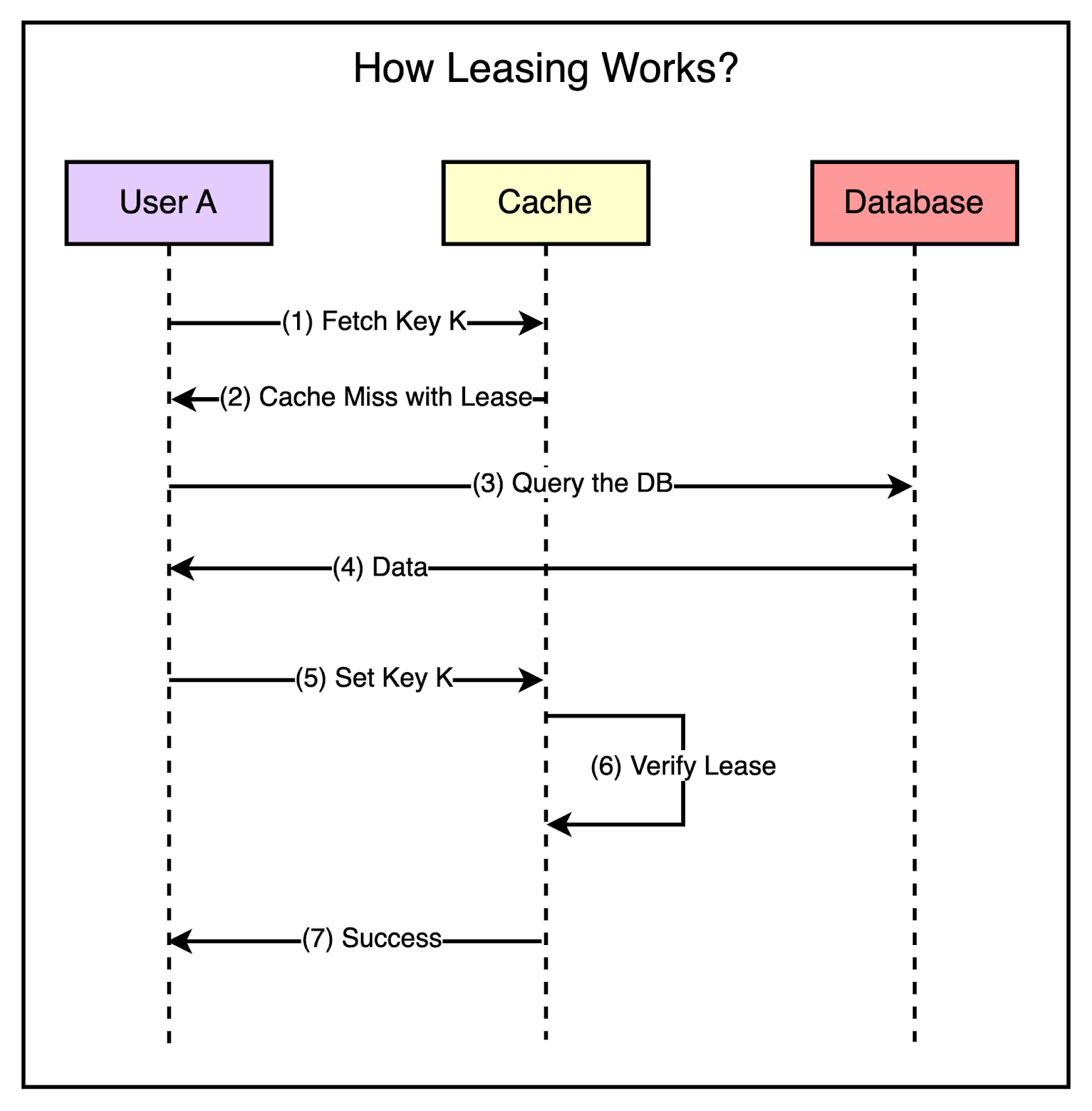
To minimize the probability of these two critical issues, Facebook used a technique known as leasing. Leasing helped solve both stale sets and thundering herds, helping Facebook reduce peak DB query rates from 17K/second to 1.3K/second. Stale SetsConsider that a client requests memcache for a particular key and it results in a cache miss. Now, it’s the client’s responsibility to fetch the data from the database and also update memcache so that future requests for the same key don’t result in a cache miss. This works fine most of the time but in a highly concurrent environment, the data being set by the client may get outdated by the time it gets updated in the cache. Leasing prevents this from happening. With leasing, Memcache hands over a lease (a 64-bit token bound to a specific key) to a particular client to set data into the cache whenever there’s a cache miss. The client has to provide this token when setting the value in the cache and memcache can verify whether the data should be stored by verifying the token. If the item was already invalidated by the time the client tried to update, Memcache will invalidate the lease token and reject the request. The below diagram shows the concept of leasing in a much better manner.
Thundering HerdsA slight modification to the leasing technique also helps solve the thundering herd issue. In this modification, Memcache regulates the rate of issuing the lease tokens. For example, it may return a token once every 5 seconds per key. For any requests for the key within 5 seconds of the lease token being issued, Memcache sends a special response requesting the client to wait and retry so that these requests don’t hit the database needlessly. This is because there’s a high probability that the client holding the lease token will soon update the cache and the waiting clients will get a cache hit when they retry. Latest articlesIf you’re not a paid subscriber, here’s what you missed.
To receive all the full articles and support ByteByteGo, consider subscribing: 3 - Handling FailuresIn a massive-scale system like Facebook, failures are an inevitable reality. With millions of users using the platform, any disruption in data retrieval from Memcache can have severe consequences. If clients are unable to fetch data from Memcache, it places an excessive load on the backend servers, potentially leading to cascading failures in downstream services. Two Levels of FailureFacebook faced two primary levels of failures when it comes to Memcache:
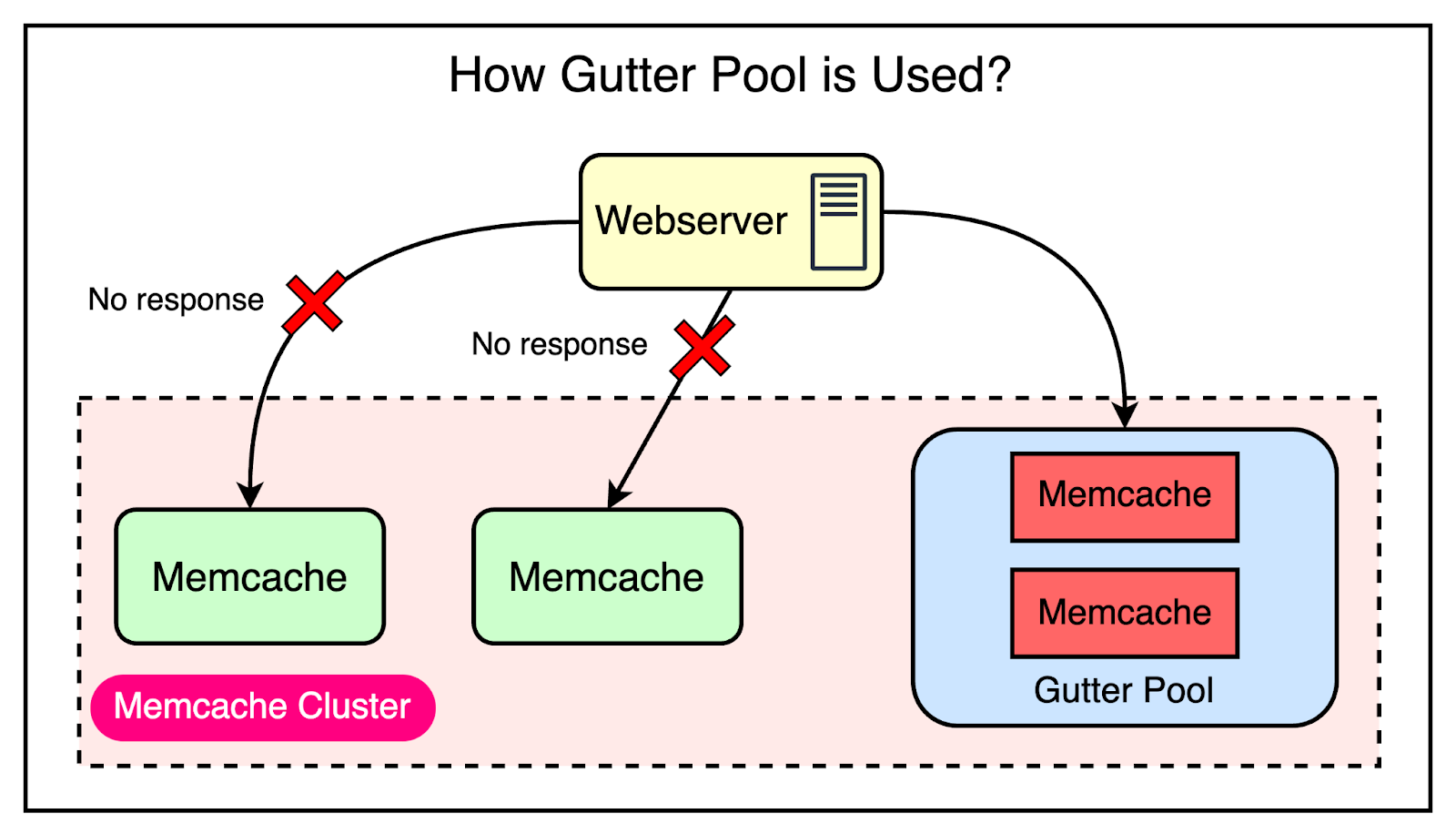
Handling Widespread OutagesTo mitigate the impact of a cluster going down, Facebook diverts web requests to other functional clusters. By redistributing the load, Facebook ensures that the problematic cluster is relieved of its responsibilities until it can be restored to health. Automated Remediation for Small OutagesFor small-scale outages, Facebook relies on an automated remediation system that automatically detects and responds to host-level issues by bringing up new instances to replace the affected ones. However, the remediation process is not instantaneous and can take some time to complete. During this time window, the backend services may experience a surge in requests as clients attempt to fetch data from the unavailable Memcache hosts. The common way of handling this is to rehash keys and distribute them among the remaining servers. However, Facebook’s engineering team realized that this approach was still prone to cascading failures. In their system, many keys can account for a significant portion of the requests (almost 20%) to a single server. Moving these high-traffic keys to another server during a failure scenario could result in overload and further instability. To mitigate this risk, Facebook went with the approach of using Gutter machines. Within each cluster, they allocate a pool of machines (typically 1% of the Memcache servers) specifically designated as Gutter machines. These machines are designed to take over the responsibilities of the affected Memcache servers during an outage. Here’s how they work:
The below diagram shows how the Gutter pool works:
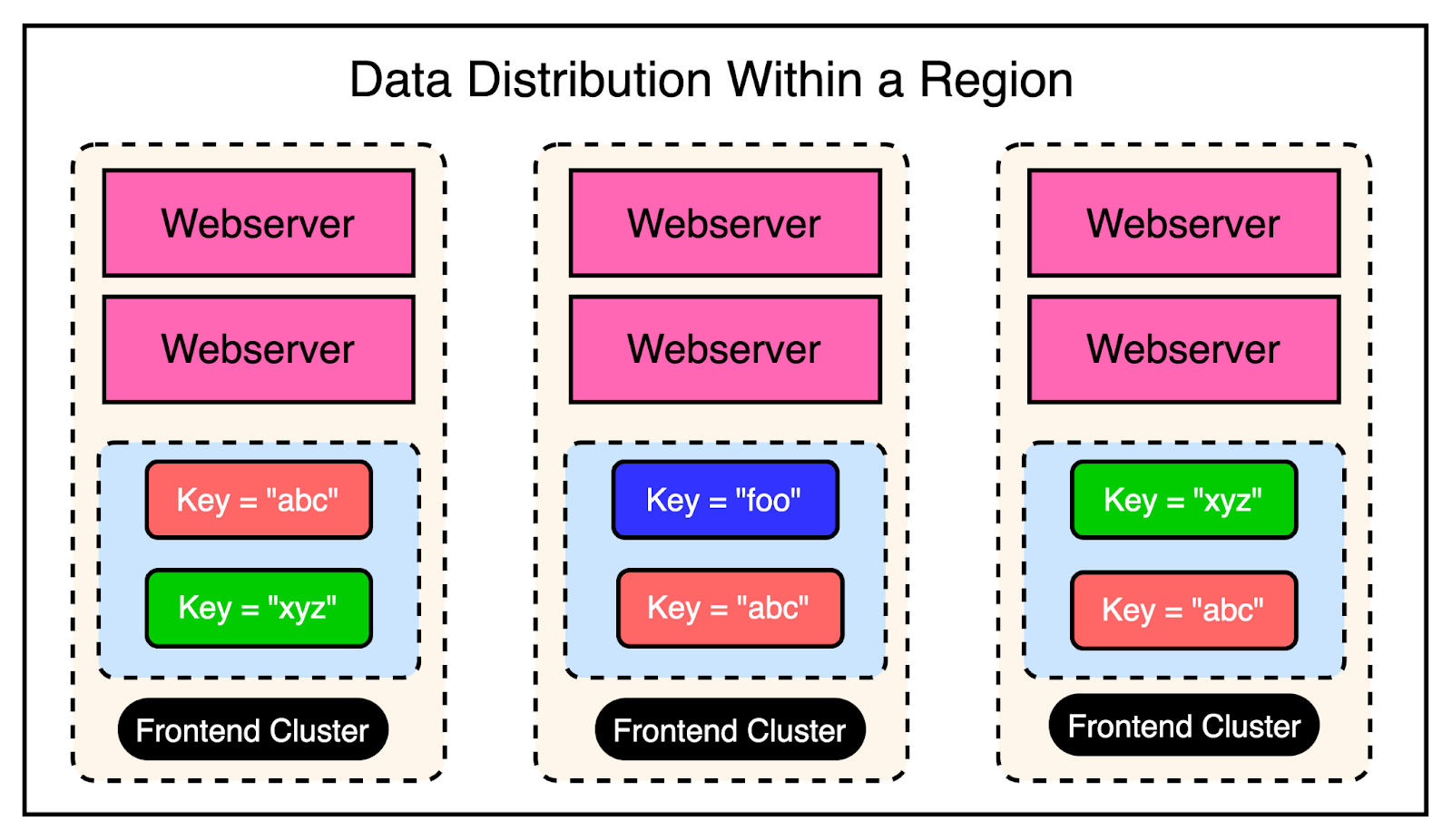
Though there are chances of serving stale data, the backend is protected. Remember that this was an acceptable trade-off for them when compared to availability. Region Level ChallengesAt the region level, there were multiple frontend clusters to deal with and the main challenge was handling Memcache invalidations across all of them. Depending on the load balancer, users can connect to different front-end clusters when requesting data. This results in caching a particular piece of data in multiple clusters. In other words, you can have a scenario where a particular key is cached in the Memcached servers of multiple clusters within the region. The below diagram shows this scenario:
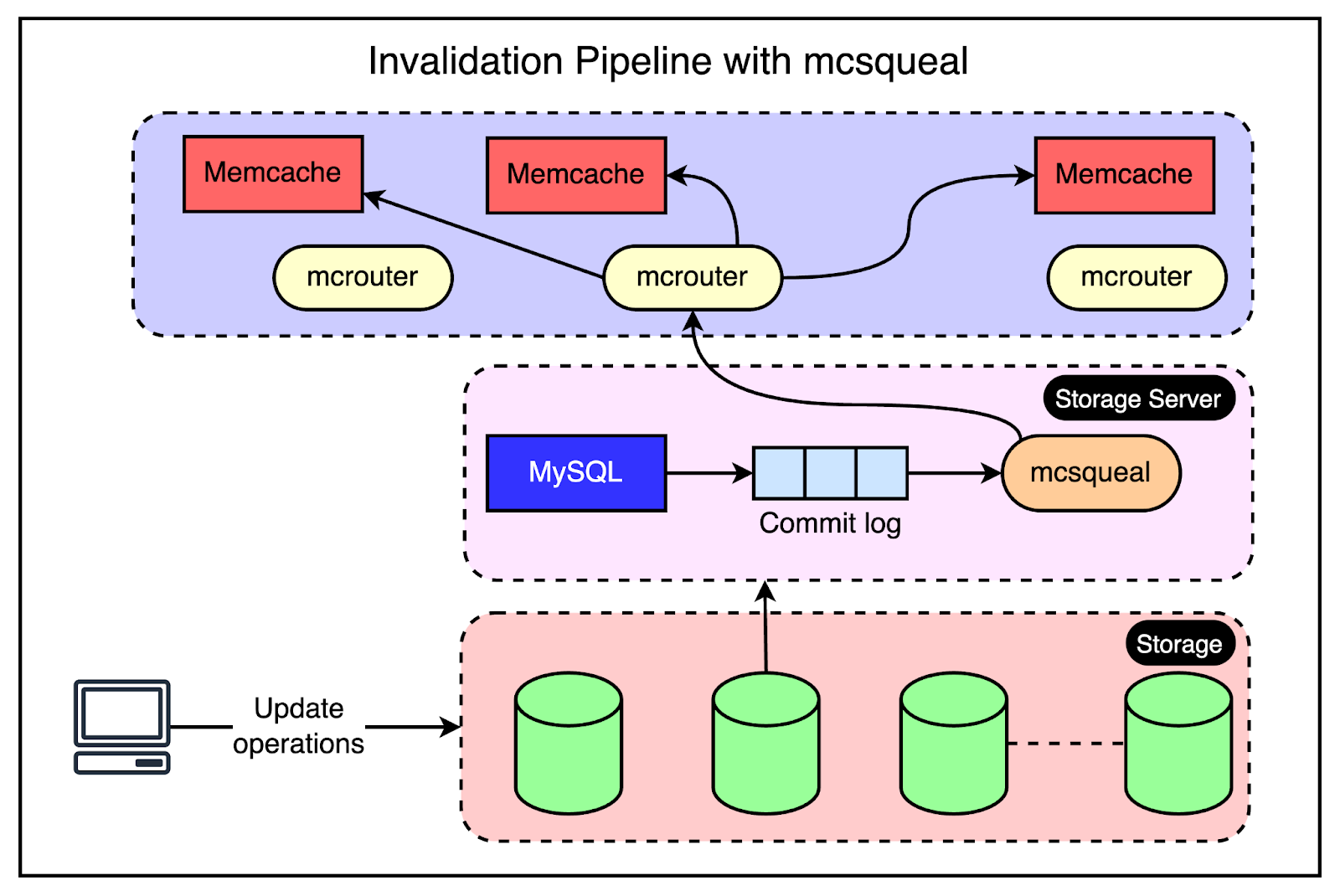
As an example, the keys “abc” and “xyz” are present in multiple frontend clusters within a region and need to be invalidated in case of an update to their values. Cluster Level InvalidationInvalidating this data at the cluster level is reasonably simpler. Any web server that modifies the data is responsible for invalidating the data in that cluster. This provides read-after-write consistency for the user who made the request. It also reduces the lifetime of the stale data within the cluster. For reference, read-after-write consistency is a guarantee that if a user makes some updates, he/she should always see those updates when they reload the page. Region Level InvalidationFor region-level invalidation, the invalidation process is a little more complex and the webserver doesn’t handle it. Instead, Facebook created an invalidation pipeline that works like this:
The below diagram explains this process.
Challenges with Global RegionsOperating at the scale of Facebook requires them to run and maintain data centers globally. However, expanding to multiple regions also creates multiple challenges. The biggest one is maintaining consistency between the data in Memcache and the persistent storage across the regions. In Facebook’s region setup, one region holds the primary databases while other geographic regions contain read-only replicas. The replicas are kept in sync with the primary using MySQL’s replication mechanism. However, when replication is involved, there is bound to be some replication lag. In other words, the replica databases can fall behind the primary database. There are two main cases to consider when it comes to consistency here: Writes from the Primary RegionLet’s say a web server in the primary region (US) receives a request from the user to update their profile picture. To maintain consistency, this change needs to be propagated to other regions as well.
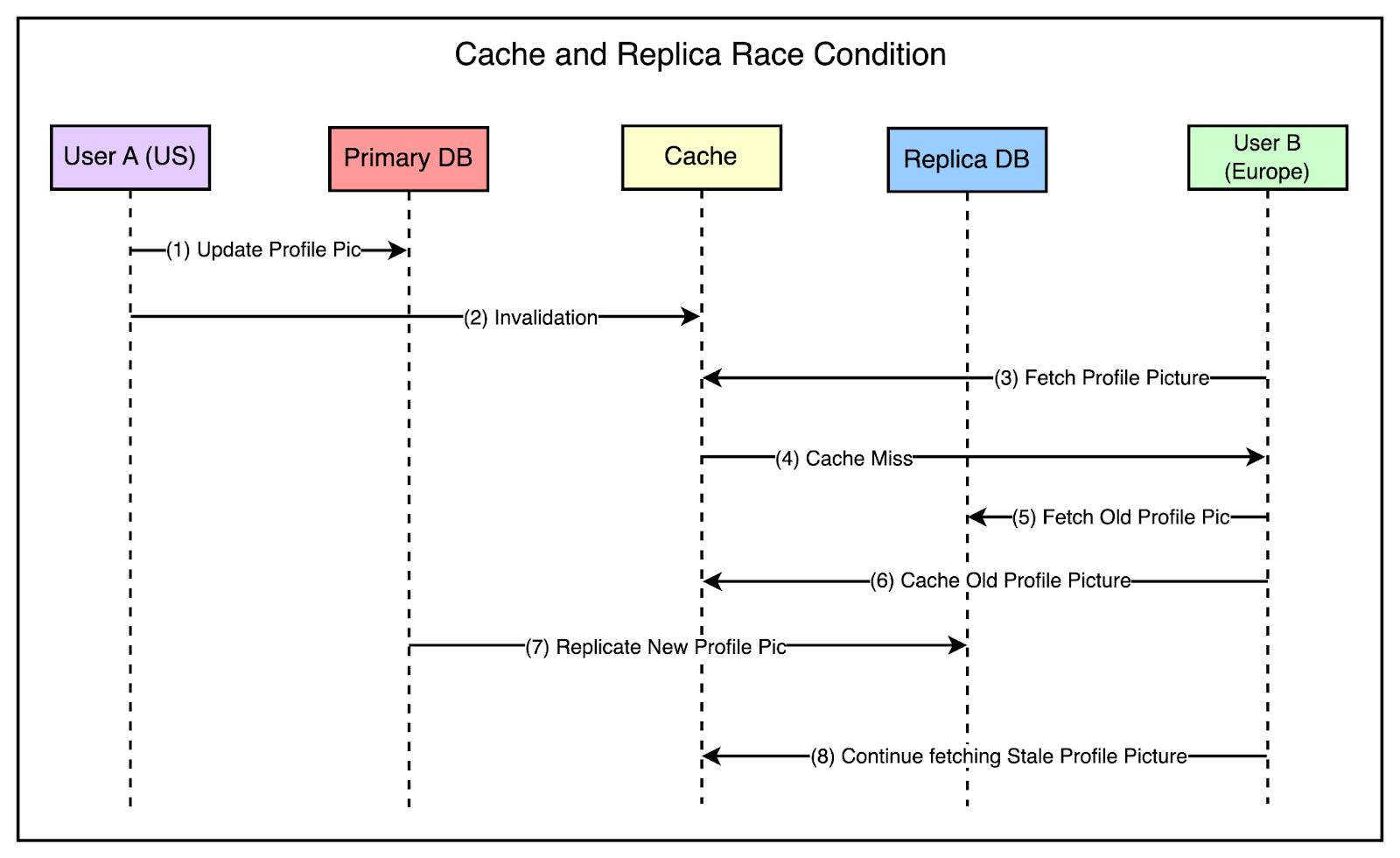
The tricky part is managing the invalidation along with the replication. If the invalidation arrives in the secondary region (Europe) before the actual change is replicated to the database in the region, there are chances of a race condition as follows:
The below diagram shows this scenario:
To avoid such race conditions, Facebook implemented a solution where the storage cluster having the most up-to-date information is responsible for sending invalidations within a region. It uses the same mcsqueal setup we talked about in the previous section. This approach ensures that invalidations don’t get sent prematurely to the replica regions before the change has been fully replicated in the databases. Writes from the Non-Primary RegionWhen dealing with writes originating from non-primary regions, the sequence of events is as follows:
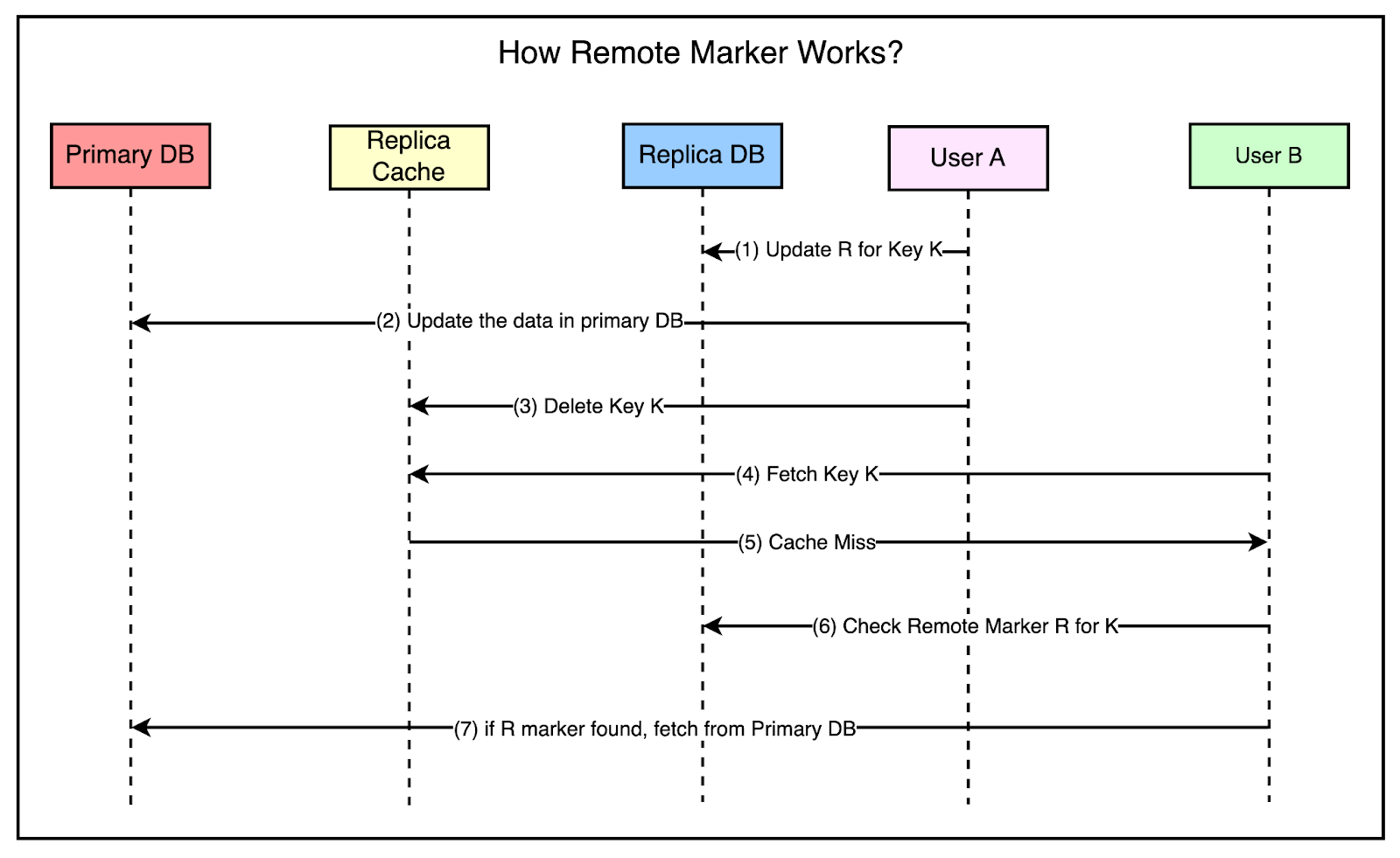
To solve this problem, Facebook used the concept of a remote marker. The remote marker is used to indicate whether the data in the local replica is potentially stale and it should be queried from the primary region. It works as follows:
The below diagram shows all the steps in more detail.
At this point, you may think that this approach is inefficient because they are first checking the cache, then the remote marker, and then making the query to the primary region. In this scenario, Facebook chose to trade off latency for a cache miss in exchange for a reduced probability of reading stale data. Single Server OptimizationsAs you can see, Facebook implemented some big architectural decisions to scale Memcached for their requirements. However, they also spent a significant time optimizing the performance of individual Memcache servers. While the scope of these improvements may seem small in isolation, their cumulative impact at Facebook’s scale was significant. Here are a few important optimizations that they made: Automatic Hash Table ExpansionAs the number of stored items grows, the time complexity of lookups in a hash table can degrade to O(n) if the table size remains fixed. This reduces the performance. Facebook implemented an automatic expansion mechanism for the hash table. When the number of items reaches a certain threshold, the hash table automatically doubles in size, ensuring that the time complexity of the lookups remains constant even as the dataset grows. Multi-Threaded Server ArchitectureServing a high volume of requests on a single thread can result in increased latency and reduced throughput. To deal with this, they enhanced the Memcache server to support multiple threads and handle requests concurrently. Dedicated UDP Port for Each ThreadWhen multiple threads share the same UDP port, contentions can occur and lead to performance problems. They implemented support for each thread to have its own dedicated UDP port so that the threads can operate more efficiently. Adaptive Slab AllocatorInefficient memory allocation and management can lead to fragmentation and suboptimal utilization of system resources. Facebook implemented an Adaptive Slab Allocator to optimize memory organization within each Memcache server. The slab allocator divides the available memory into fixed-size chunks called slabs. Each slab is further divided into smaller units of a specific size. The allocator dynamically adapts the slab sizes based on the observed request patterns to maximize memory utilization. ConclusionFacebook’s journey in scaling Memcached serves as a fantastic case study for developers and engineers. It highlights the challenges that come up when building a globally distributed social network that needs to handle massive amounts of data and serve billions of users. With their implementation and optimization of Memcache, Facebook demonstrates the importance of tackling scalability challenges at multiple levels. From high-level architectural decisions to low-level server optimizations, every aspect plays an important role in ensuring the performance, reliability, and efficiency of the system. Three key learning points to take away from this study are as follows:
References: SPONSOR USGet your product in front of more than 500,000 tech professionals. Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases. Space Fills Up Fast - Reserve Today Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing hi@bytebytego.com © 2024 ByteByteGo
|

by "ByteByteGo" <bytebytego@substack.com> - 11:35 - 14 May 2024