- Mailing Lists
- in
- How Google Spanner Powers Trillions of Rows with 5 Nines Availability
Archives
- By thread 4934
-
By date
- June 2021 10
- July 2021 6
- August 2021 20
- September 2021 21
- October 2021 48
- November 2021 40
- December 2021 23
- January 2022 46
- February 2022 80
- March 2022 109
- April 2022 100
- May 2022 97
- June 2022 105
- July 2022 82
- August 2022 95
- September 2022 103
- October 2022 117
- November 2022 115
- December 2022 102
- January 2023 88
- February 2023 90
- March 2023 116
- April 2023 97
- May 2023 159
- June 2023 145
- July 2023 120
- August 2023 90
- September 2023 102
- October 2023 106
- November 2023 100
- December 2023 74
- January 2024 75
- February 2024 75
- March 2024 78
- April 2024 74
- May 2024 108
- June 2024 98
- July 2024 116
- August 2024 134
- September 2024 130
- October 2024 141
- November 2024 171
- December 2024 115
- January 2025 216
- February 2025 140
- March 2025 220
- April 2025 233
- May 2025 239
- June 2025 45
The future of leadership: Get the latest issue of the McKinsey Quarterly
Major announcements coming next week at SAP Business Unleashed
How Google Spanner Powers Trillions of Rows with 5 Nines Availability
How Google Spanner Powers Trillions of Rows with 5 Nines Availability
How to monitor AWS container environments at scale (Sponsored)In this eBook, Datadog and AWS share insights into the changing state of containers in the cloud and explore why orchestration technologies are an essential part of managing ever-changing containerized workloads. Learn more about:
Disclaimer: The details in this post have been derived from Google Blogs and Research Papers. All credit for the technical details goes to the Google engineering team. The links to the original articles are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them. Cloud Spanner is a revolutionary database system developed by Google that uniquely combines the strengths of traditional relational databases with the scalability typically associated with NoSQL systems. Designed to handle massive workloads across multiple regions, Cloud Spanner provides a globally distributed, strongly consistent, and highly available platform for data management. Its standout feature is its ability to offer SQL-based queries and relational database structures while achieving horizontal scalability. This makes it suitable for modern, high-demand applications. Here are some features of Cloud Spanner:
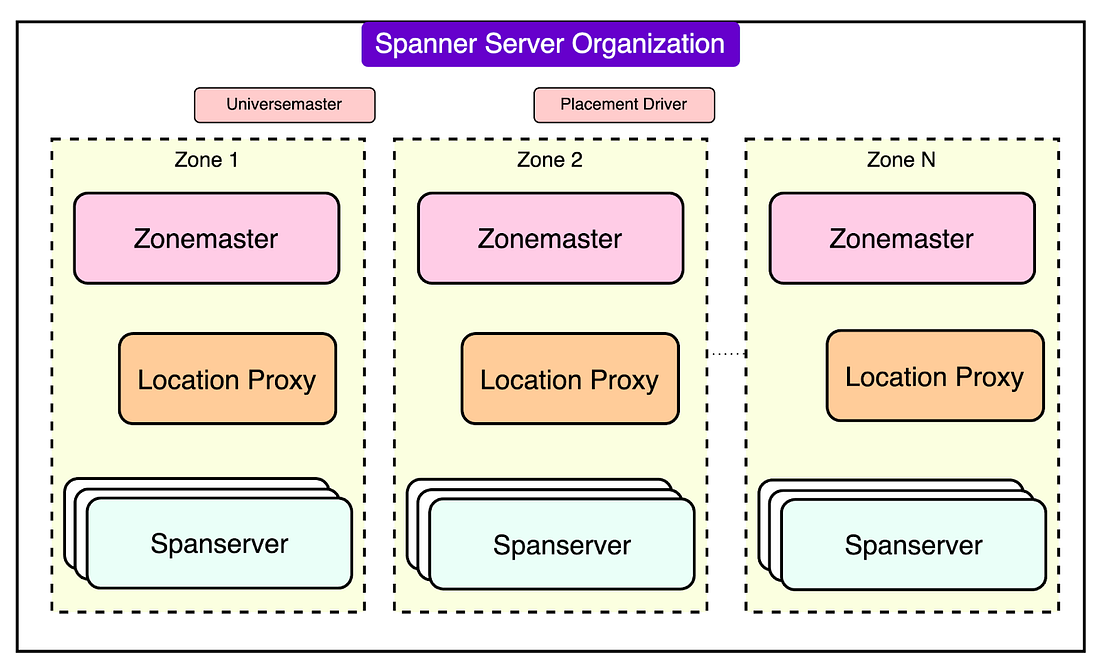
Overall, Google Spanner is a powerful solution for enterprises that need a database capable of handling global-scale operations while maintaining the robustness and reliability of traditional relational systems. In this article, we’ll learn about Google Cloud Spanner's architecture and how it supports the various capabilities that make it a compelling database option. The Architecture of Cloud SpannerThe architecture of Cloud Spanner is designed to support its role as a globally distributed, highly consistent, and scalable database. At the highest level, Spanner is organized into what is called a universe, a logical entity that spans multiple physical or logical locations known as zones. Each zone operates semi-independently and contains spanservers. These are specialized servers that handle data storage and transactional operations. Spanservers are built on concepts from Bigtable, Google’s earlier distributed storage system, and include enhancements to support complex transactional needs and multi-versioned data.
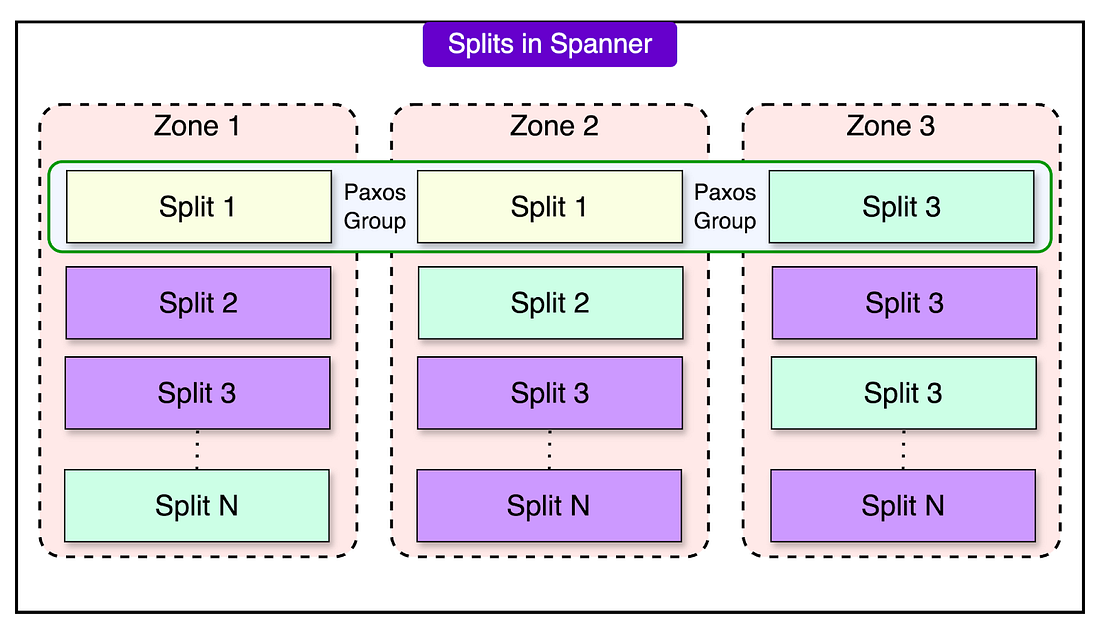
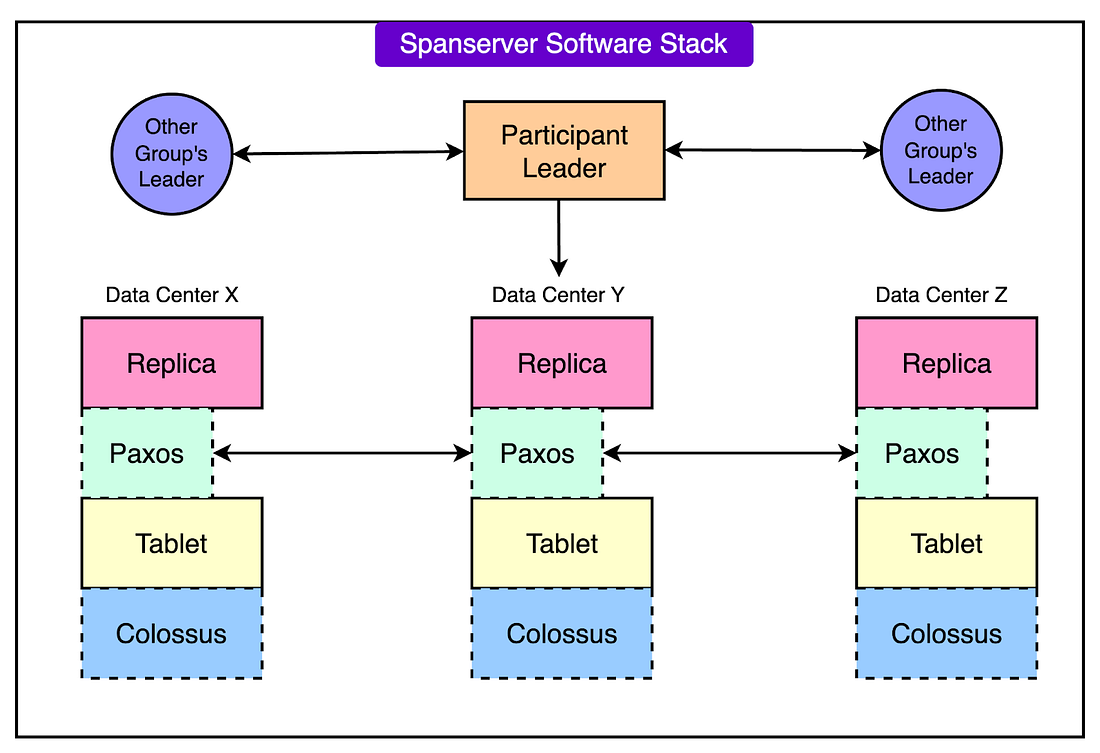
Some of the key architectural components of Spanner are as follows: 1 - Data Sharding and TabletsCloud Spanner manages data by breaking it into smaller chunks called tablets, distributed across multiple spanservers. Each tablet holds data as key-value pairs, with a timestamp for versioning. This structure allows Spanner to act as a multi-version database where old versions of data can be accessed if needed. Tablets are stored on Colossus, Google’s distributed file system. Colossus provides fault-tolerant and high-performance storage, enabling Spanner to scale storage independently of compute resources. 2 - Dynamic PartitioningData within tables is divided into splits, which are ranges of contiguous keys. These splits can be dynamically adjusted based on workload or size. When a split grows too large or experiences high traffic, it is automatically divided into smaller splits and redistributed across spanservers. This process, known as dynamic sharding, ensures even load distribution and optimal performance. Each split is replicated across zones for redundancy and fault tolerance. 3 - Paxos-Based ReplicationSpanner uses the Paxos consensus algorithm to manage replication across multiple zones. Each split has multiple replicas, and Paxos ensures that these replicas remain consistent. Among these replicas, one is chosen as the leader, responsible for managing all write transactions for that split. The leader coordinates updates to ensure they are applied in a consistent order. If the leader fails, Paxos elects a new leader, ensuring continued availability without manual intervention. The replicas not serving as leaders can handle read operations, reducing the workload on the leader and improving scalability.
4 - Multi-Zone DeploymentsSpanner instances span multiple zones within a region, with replicas distributed across these zones. This setup enhances availability because even if one zone fails, other zones can continue serving requests. For global deployments, data can be replicated across continents, providing low-latency access to users worldwide. 5 - Colossus Distributed File SystemAll data is stored on Colossus, which is designed for distributed and replicated file storage. Colossus ensures high durability by replicating data across physical machines, making it resilient to hardware failures. The file system is decoupled from the compute resources, allowing the database to scale independently and perform efficiently.
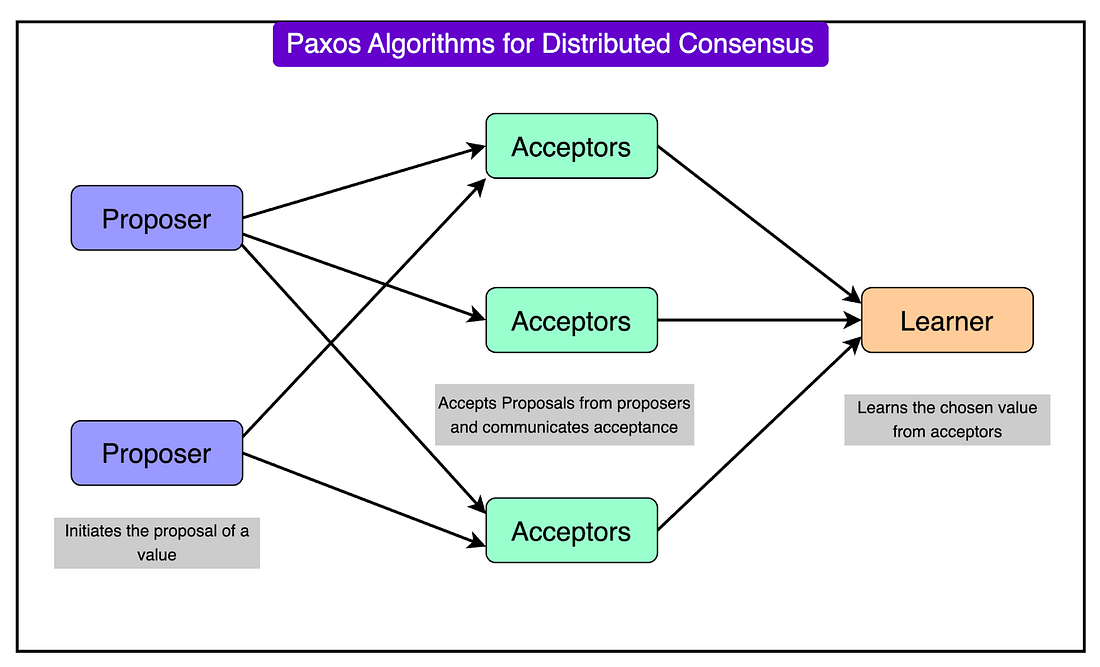
Paxos Mechanism in SpannerThe Paxos Mechanism is a critical component of Spanner’s architecture. It operates on the principle of distributed consensus, where a group of replicas (known as a Paxos group) agrees on a single value, such as a transaction's commit or the leader responsible for handling updates.
The leadership assignment works as follows:
The key responsibilities of the Paxos Leader are as follows:
Failures are inevitable in distributed systems, but Paxos ensures that Spanner remains available and consistent despite such issues. If the current leader fails due to a machine or zone outage, the Paxos group detects the failure and elects a new leader. The new leader is chosen from the remaining replicas in the Paxos group. This process avoids downtime and ensures that the data remains accessible. Read and Write Transactions in SpannerCloud Spanner manages transactions with a robust approach that ensures strong consistency, reliability, and high performance. Let’s look at how write and read transactions work in more detail: 1 - Write TransactionsWrite transactions in Cloud Spanner are designed to guarantee atomicity (all-or-nothing execution) and consistency (all replicas agree on the data). These transactions are managed by Paxos leaders coordinating the process to ensure data integrity even during failures. Here are the steps involved in the process:
There is some difference in the way Spanner handles single-split write versus multi-split write. For example, in a single-split write, suppose a user wants to add a row with ID 7 and value "Seven" to a table.
However, for a multi-split write, if a transaction modifies rows in multiple splits (for example, writing to rows 2000, 3000, and 4000), Spanner uses a two-phase commit protocol:
2 - Read TransactionsRead transactions in Spanner are optimized for speed and scalability. They provide strong consistency without requiring locks, which allows reads to be processed efficiently even under high workloads. The different types of reads are as follows:
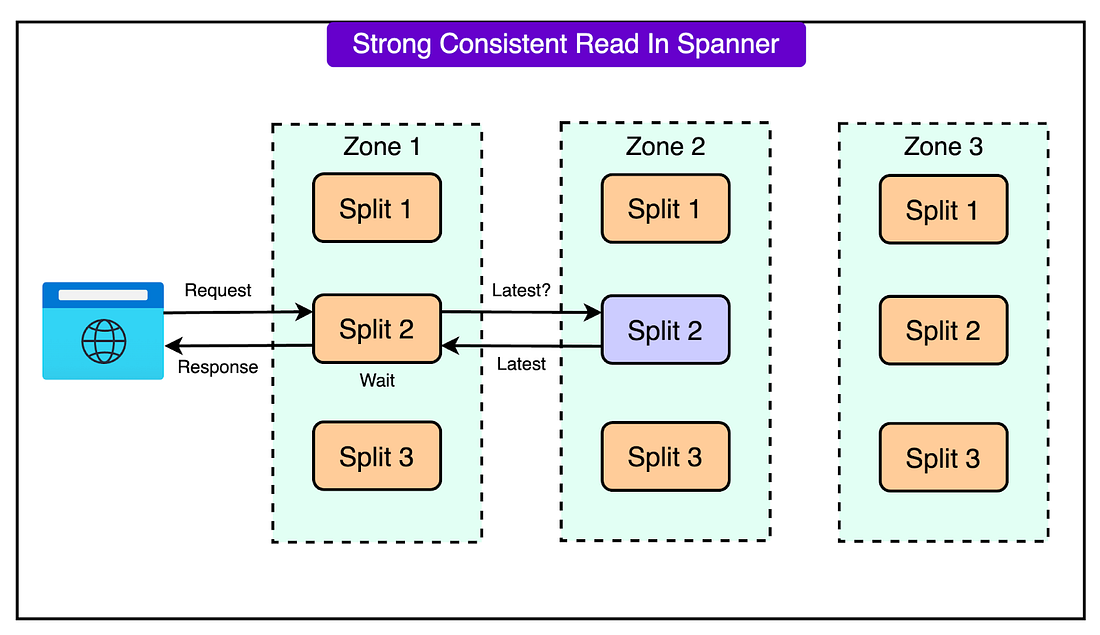
See the diagram below that shows the strong consistent read scenario.
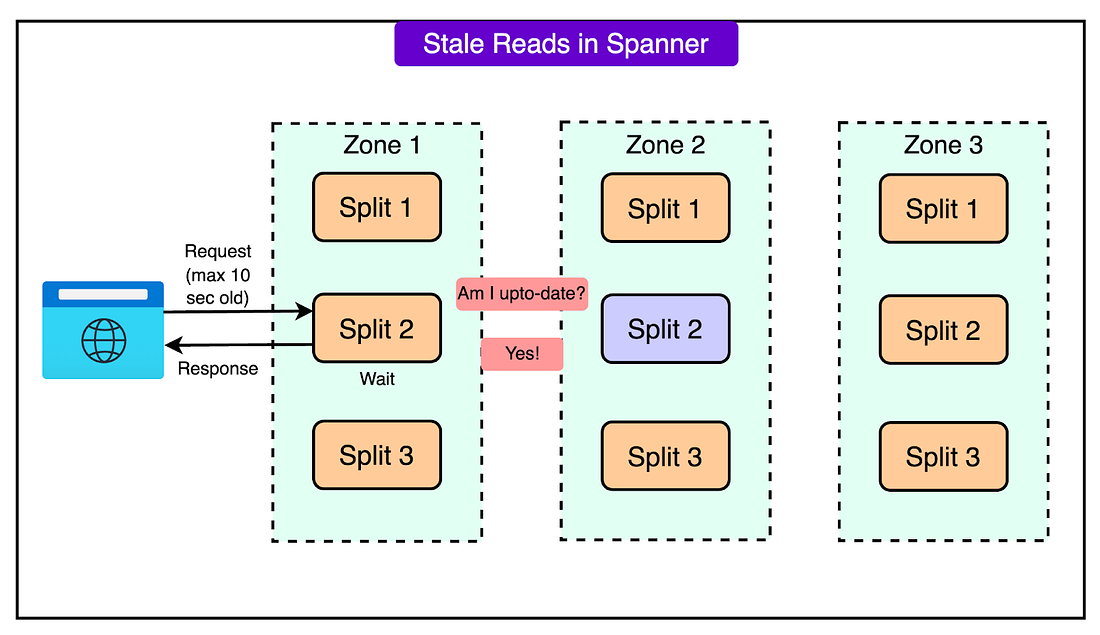
Also, the diagram below shows the stale reads scenario.
3 - Deadlock PreventionSpanner avoids deadlocks—a situation where two or more transactions wait for each other to release locks—by using the wound-wait algorithm. Here’s how it works:
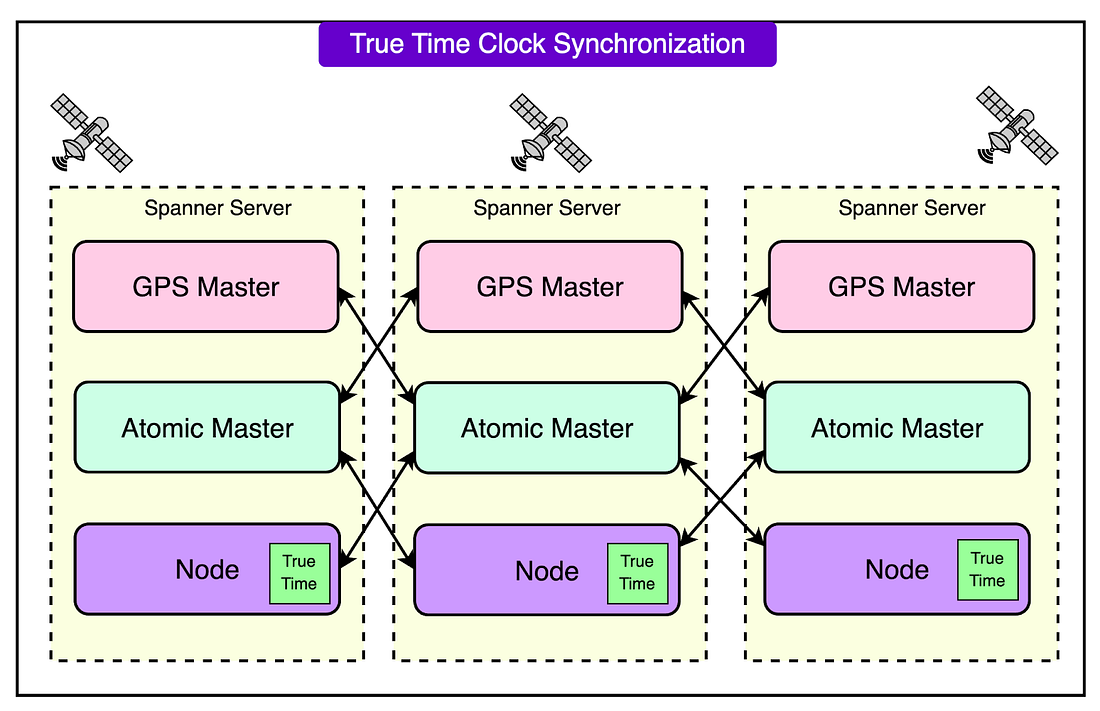
4 - Reliability and DurabilitySpanner’s design ensures that data remains consistent and available even during failures. All writes are stored in Google’s Colossus distributed file system, which replicates data across multiple physical machines. Even if one machine or zone fails, the data can be recovered from other replicas. TrueTime ensures that all transactions occur in a globally consistent order, even in a distributed environment. This guarantees that once a transaction is visible to one client, it is visible to all clients. The TrueTime APIThe TrueTime API is one of the key innovations in Cloud Spanner, enabling it to function as a globally distributed, strongly consistent database. TrueTime solves one of the most challenging problems in distributed systems: providing a globally synchronized and consistent view of time across all nodes in a system, even those spread across multiple regions and data centers. TrueTime is based on a combination of atomic clocks and GPS clocks, which work together to provide highly accurate and reliable time synchronization.
By using both atomic and GPS clocks, TrueTime mitigates the weaknesses of each system. For example:
Here’s how it works:
Time Representation and UncertaintyTrueTime represents time as an interval instead of a single point, explicitly acknowledging the uncertainty inherent in distributed systems.
Key Features Enabled By TrueTimeTrueTime provides some important features that make it so useful:
ConclusionGoogle Spanner stands as a great achievement in database engineering, seamlessly blending the reliability and structure of traditional relational databases with the scalability and global availability often associated with NoSQL systems. Its innovative architecture, supported by the Paxos consensus mechanism and the TrueTime API, provides a great foundation for handling distributed transactions, ensuring external consistency, and maintaining high performance at a global scale. Ultimately, Google Spanner redefines what is possible in distributed database systems, setting a standard for scalability, reliability, and innovation. References: SPONSOR USGet your product in front of more than 1,000,000 tech professionals. Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases. Space Fills Up Fast - Reserve Today Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com. © 2025 ByteByteGo
|
by "ByteByteGo" <bytebytego@substack.com> - 11:37 - 4 Feb 2025