- Mailing Lists
- in
- How LinkedIn Customizes Its 7 Trillion Message Kafka Ecosystem
Archives
- By thread 5315
-
By date
- June 2021 10
- July 2021 6
- August 2021 20
- September 2021 21
- October 2021 48
- November 2021 40
- December 2021 23
- January 2022 46
- February 2022 80
- March 2022 109
- April 2022 100
- May 2022 97
- June 2022 105
- July 2022 82
- August 2022 95
- September 2022 103
- October 2022 117
- November 2022 115
- December 2022 102
- January 2023 88
- February 2023 90
- March 2023 116
- April 2023 97
- May 2023 159
- June 2023 145
- July 2023 120
- August 2023 90
- September 2023 102
- October 2023 106
- November 2023 100
- December 2023 74
- January 2024 75
- February 2024 75
- March 2024 78
- April 2024 74
- May 2024 108
- June 2024 98
- July 2024 116
- August 2024 134
- September 2024 130
- October 2024 141
- November 2024 171
- December 2024 115
- January 2025 216
- February 2025 140
- March 2025 220
- April 2025 233
- May 2025 239
- June 2025 303
- July 2025 127
How LinkedIn Customizes Its 7 Trillion Message Kafka Ecosystem
How LinkedIn Customizes Its 7 Trillion Message Kafka Ecosystem
Cut your QA cycles down from hours to minutes with automated testing (Sponsored)
If slow QA processes bottleneck you or your software engineering team and you’re releasing slower because of it — you need to check out QA Wolf. They get engineering teams to 80% automated end-to-end test coverage and helps them ship 5x faster by reducing QA cycles from hours to minutes. QA Wolf takes testing off your plate. They can get you: ✔️ Unlimited parallel test runs ✔️ 24-hour maintenance and on-demand test creation ✔️ Human-verified bug reports sent directly to your team ✔️ Zero flakes, guaranteed The result? Drata’s team of 80+ engineers achieved 4x more test cases and 86% faster QA cycles. Disclaimer: The details in this post have been derived from the LinkedIn Engineering Blog. All credit for the technical details goes to the LinkedIn engineering team. The links to the original articles are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them. LinkedIn uses Apache Kafka, an open-source stream processing platform, as a key part of its infrastructure. Kafka was first developed at LinkedIn and later open-sourced. Many companies now use Kafka, but LinkedIn uses it on an exceptionally large scale. LinkedIn uses Kafka for multiple tasks like:
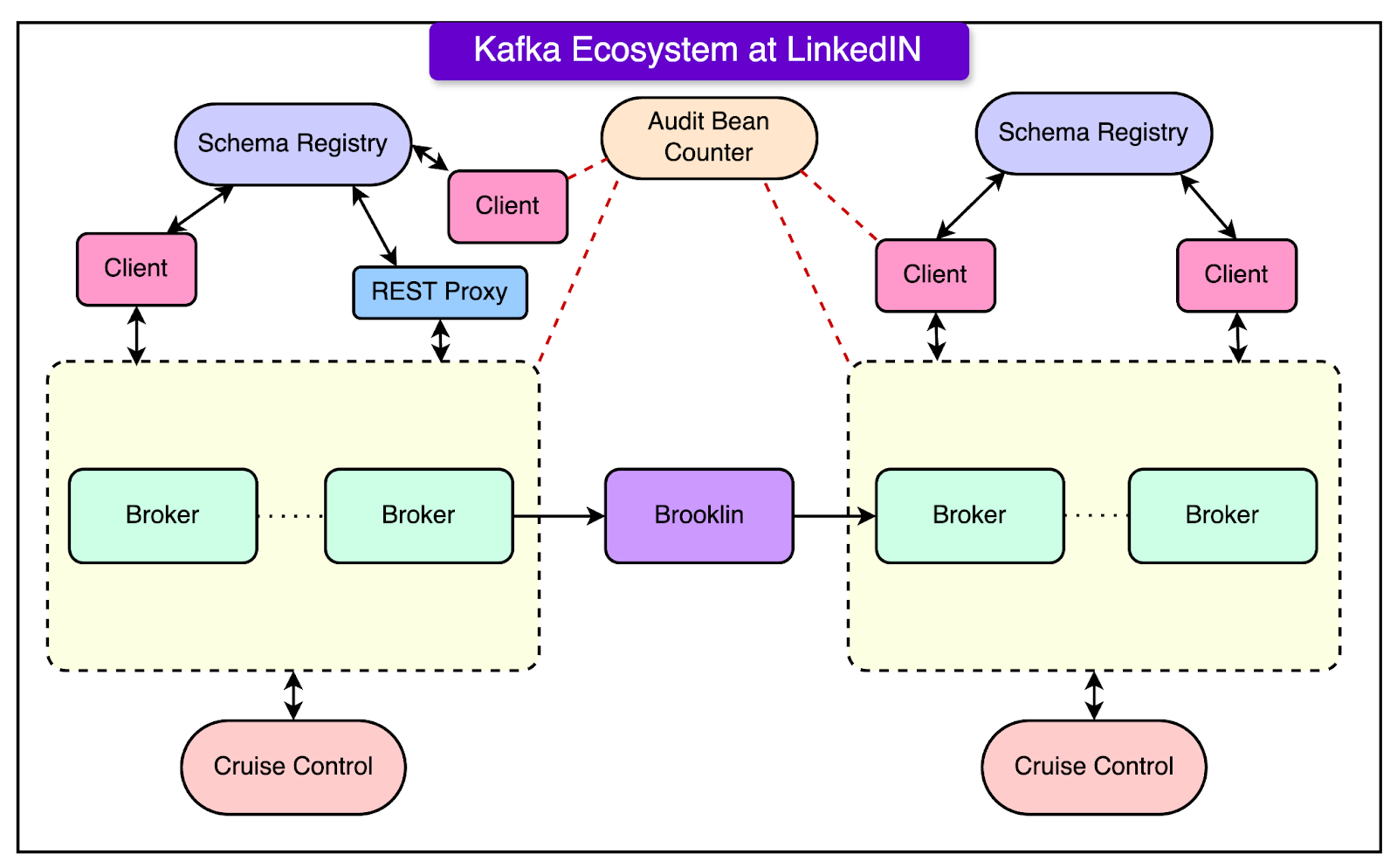
They have over 100 Kafka clusters with more than 4,000 servers (called brokers), handling over 100,000 topics and 7 million partitions. In total, LinkedIn's Kafka system processes more than 7 trillion messages every day. Operating Kafka at this huge scale creates challenges in terms of scalability and operability. To tackle these issues, LinkedIn maintains its version of Kafka, specifically tailored for their production needs and scale. This includes LinkedIn-specific release branches that contain patches for their production requirements and feature needs. In this post, we’ll look at how LinkedIn manages its Kafka releases running in production and how it develops new patches to improve Kafka for the community and internal usage. LinkedIn’s Kafka EcosystemLet us first take a high-level look at LinkedIn’s Kafka ecosystem. LinkedIn's Kafka ecosystem is a crucial part of its technology stack, enabling it to handle an immense volume of messages - around 7 trillion per day. The ecosystem consists of several key components that work together to ensure smooth operation and scalability. See the diagram below:
Here are the details about the various components:
All these components work together to form LinkedIn’s robust and scalable Kafka ecosystem. The ecosystem enables LinkedIn to handle the massive volume of real-time data generated by its users and systems while maintaining high performance and reliability. LinkedIn engineering team continuously improves and customizes its Kafka deployment to meet specific needs. They also contribute many enhancements back to the open-source Apache Kafka project. Latest articlesIf you’re not a subscriber, here’s what you missed this month.
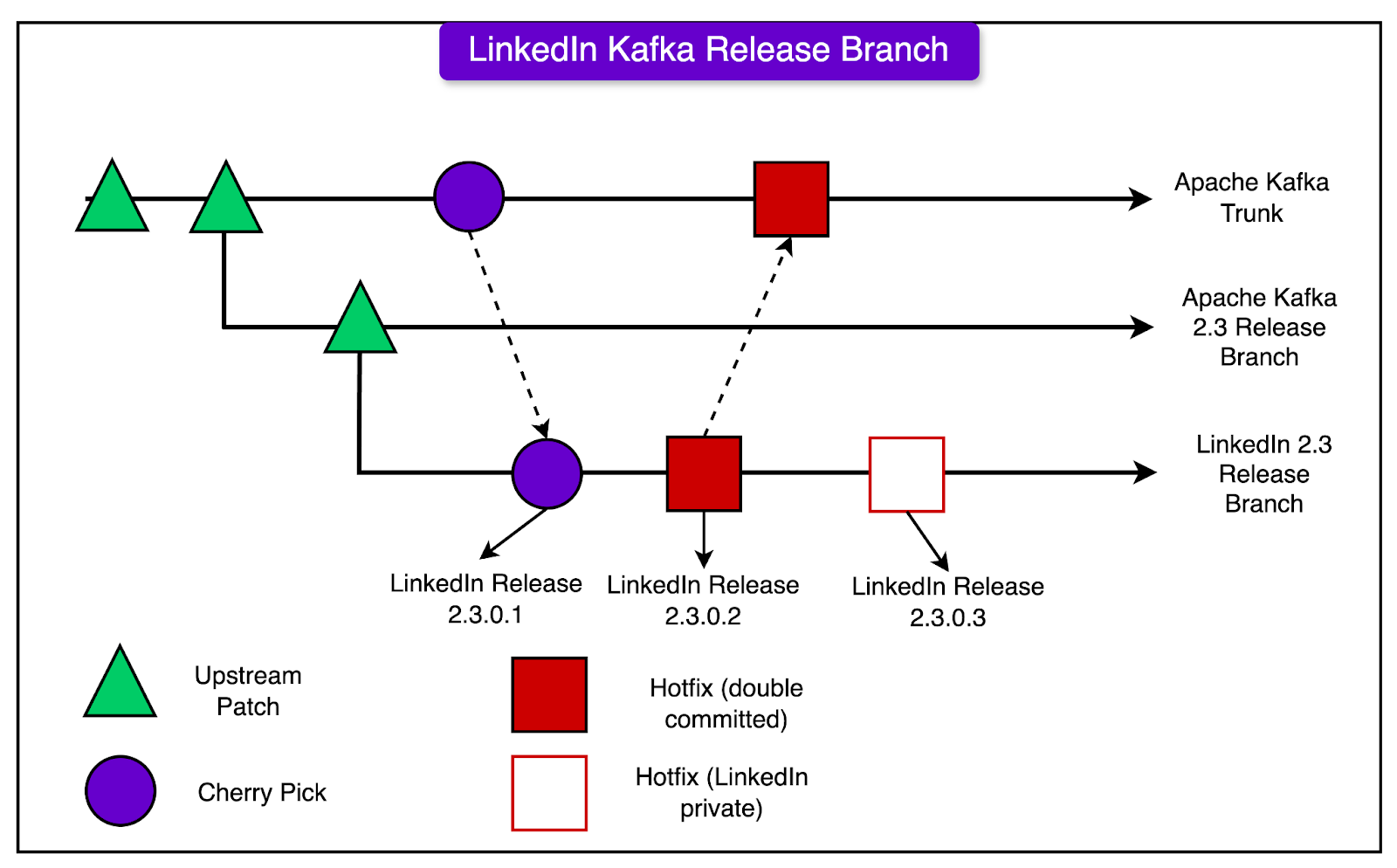
To receive all the full articles and support ByteByteGo, consider subscribing: LinkedIn’s Kafka Release BranchesLinkedIn maintains its special versions of Kafka, which are based on the official open-source Apache Kafka releases. These special versions are called LinkedIn Kafka Release Branches. Each LinkedIn Kafka Release Branch starts from a specific version of Apache Kafka. For example, they might create a branch called “LinkedIn Kafka 2.3.0.x”, which is based on the Apache Kafka 2.3.0 release. LinkedIn makes changes and adds extra code (called “patches”) to these branches to help Kafka work better for their specific needs. They have two main ways of adding these patches:
The diagram below shows the approach to managing the releases:
In the LinkedIn Kafka Release Branches, one can find a mix of different types of patches:
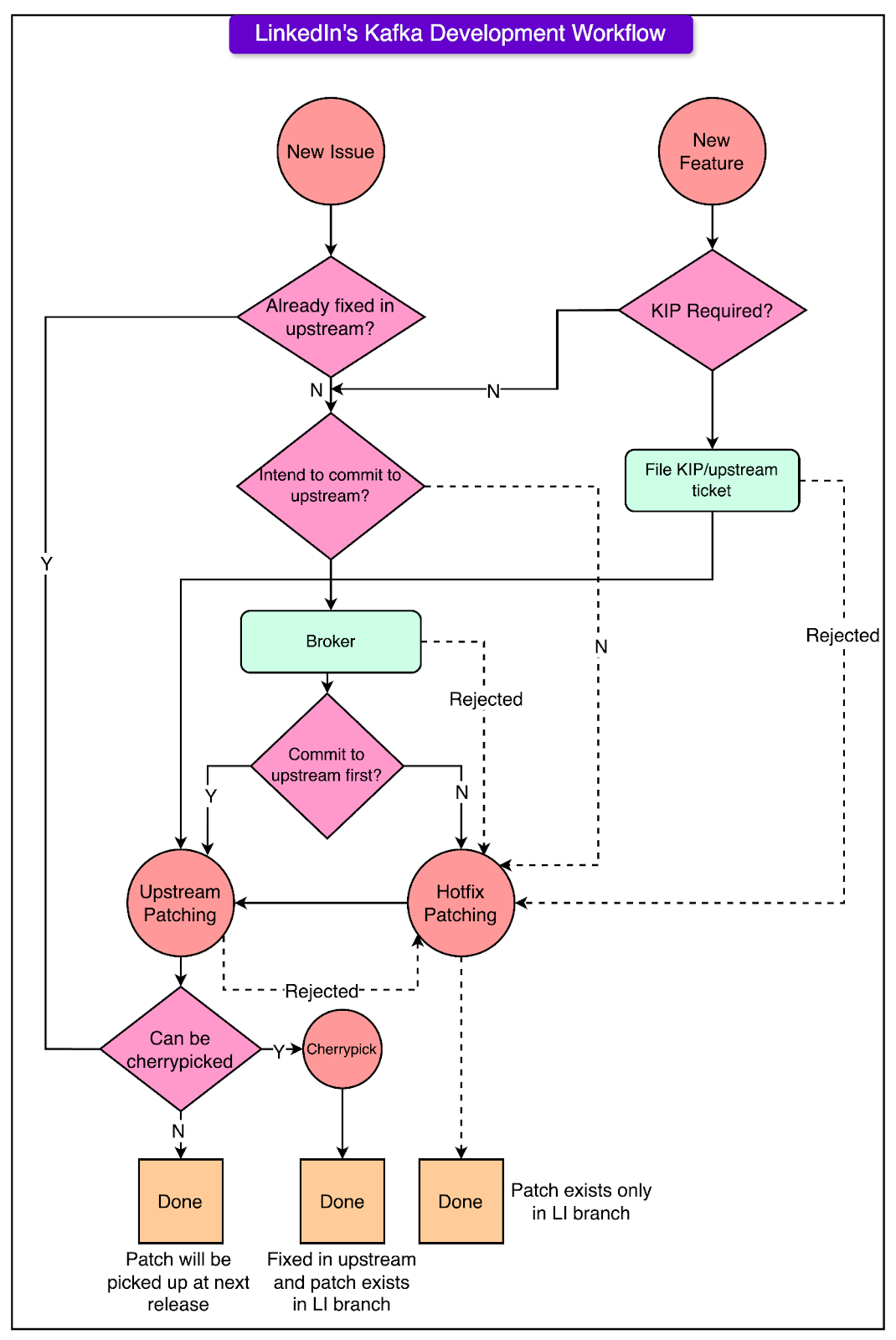
When LinkedIn creates a new Kafka Release Branch, it starts from the latest Apache Kafka release. Then, they look at their previous LinkedIn branch and bring over any of their patches that haven’t been added to the official Apache Kafka code yet. They use special notes in the code changes to keep track of which patches have been added to the official release and which are still just in the LinkedIn version. Also, they regularly check the Apache Kafka code and bring in new changes to keep their branch up to date. Finally, they perform intensive testing of their new LinkedIn Kafka Release Branch. They test it with real data and usage to ensure that it works well and performs fast, before using it for real work at LinkedIn. Kafka Development Workflow at LinkedInWhen LinkedIn engineers want to make a change or add a new feature to Kafka, they first have to decide whether to make the change in the official Apache Kafka code (called "upstream-first") or to make the change in LinkedIn's version of Kafka first (called "LinkedIn-first" or "hotfix approach"). Here’s what the decision-making process looks like on a high level:
The diagram below shows the entire flow in more detail.
So in summary, the decision between upstream-first and LinkedIn-first depends on factors like:
Patch Examples from LinkedInLinkedIn has made several changes (called “patches) to Kafka to help it work better for their specific needs. These patches fall into a few main categories: Scalability ImprovementsLinkedIn has some very large Kafka clusters, with over 140 brokers and millions of data copies in a single cluster. With clusters this big, they sometimes have problems with the central control server being slow or running out of memory. Also, many times brokers take a long time to start up or shut down. To fix these problems, LinkedIn made patches to:
Operational ImprovementsSometimes, LinkedIn needs to remove brokers from a cluster and add new brokers. When they remove a broker, they want to make sure all the data on that broker is copied to other brokers first, so no data is lost. However, this was hard to do, because even while they were trying to move data off a broker, new data was constantly being added to it. To solve this, they created a new mode called “maintenance mode” for brokers. When a broker is in maintenance mode, no new data is added to it. This makes it much easier to move all the data off the broker before shutting it down. New Features for Apache KafkaLinkedIn has added several brand new features to their version of Kafka such as:
The LinkedIn engineering team also contributed many improvements directly to the Apache Kafka project, so everyone can benefit from them. Some major examples include:
ConclusionTo summarize, LinkedIn customizes Kafka heavily to handle the immense scale at which it operates. It also contributes many improvements upstream while maintaining release branches to rapidly address issues. Their development workflow and release branching are designed to balance urgency with contributions going back to the open-source community. References: SPONSOR USGet your product in front of more than 1,000,000 tech professionals. Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases. Space Fills Up Fast - Reserve Today Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com. © 2024 ByteByteGo
|


by "ByteByteGo" <bytebytego@substack.com> - 11:36 - 3 Dec 2024