- Mailing Lists
- in
- How LinkedIn Scaled User Restriction System to 5 Million Queries Per Second
Archives
- By thread 5457
-
By date
- June 2021 10
- July 2021 6
- August 2021 20
- September 2021 21
- October 2021 48
- November 2021 40
- December 2021 23
- January 2022 46
- February 2022 80
- March 2022 109
- April 2022 100
- May 2022 97
- June 2022 105
- July 2022 82
- August 2022 95
- September 2022 103
- October 2022 117
- November 2022 115
- December 2022 102
- January 2023 88
- February 2023 90
- March 2023 116
- April 2023 97
- May 2023 159
- June 2023 145
- July 2023 120
- August 2023 90
- September 2023 102
- October 2023 106
- November 2023 100
- December 2023 74
- January 2024 75
- February 2024 75
- March 2024 78
- April 2024 74
- May 2024 108
- June 2024 98
- July 2024 116
- August 2024 134
- September 2024 130
- October 2024 141
- November 2024 171
- December 2024 115
- January 2025 216
- February 2025 140
- March 2025 220
- April 2025 233
- May 2025 239
- June 2025 303
- July 2025 265
- August 2025 6
GEOMETRIC DIMENSIONING AND TOLERANCING (GD&T) 17 & 18 Feb 2025
Thank you for supporting ByteByteGo Newsletter
How LinkedIn Scaled User Restriction System to 5 Million Queries Per Second
How LinkedIn Scaled User Restriction System to 5 Million Queries Per Second
Level Up Your Business Observability with Custom Metrics (Sponsored)
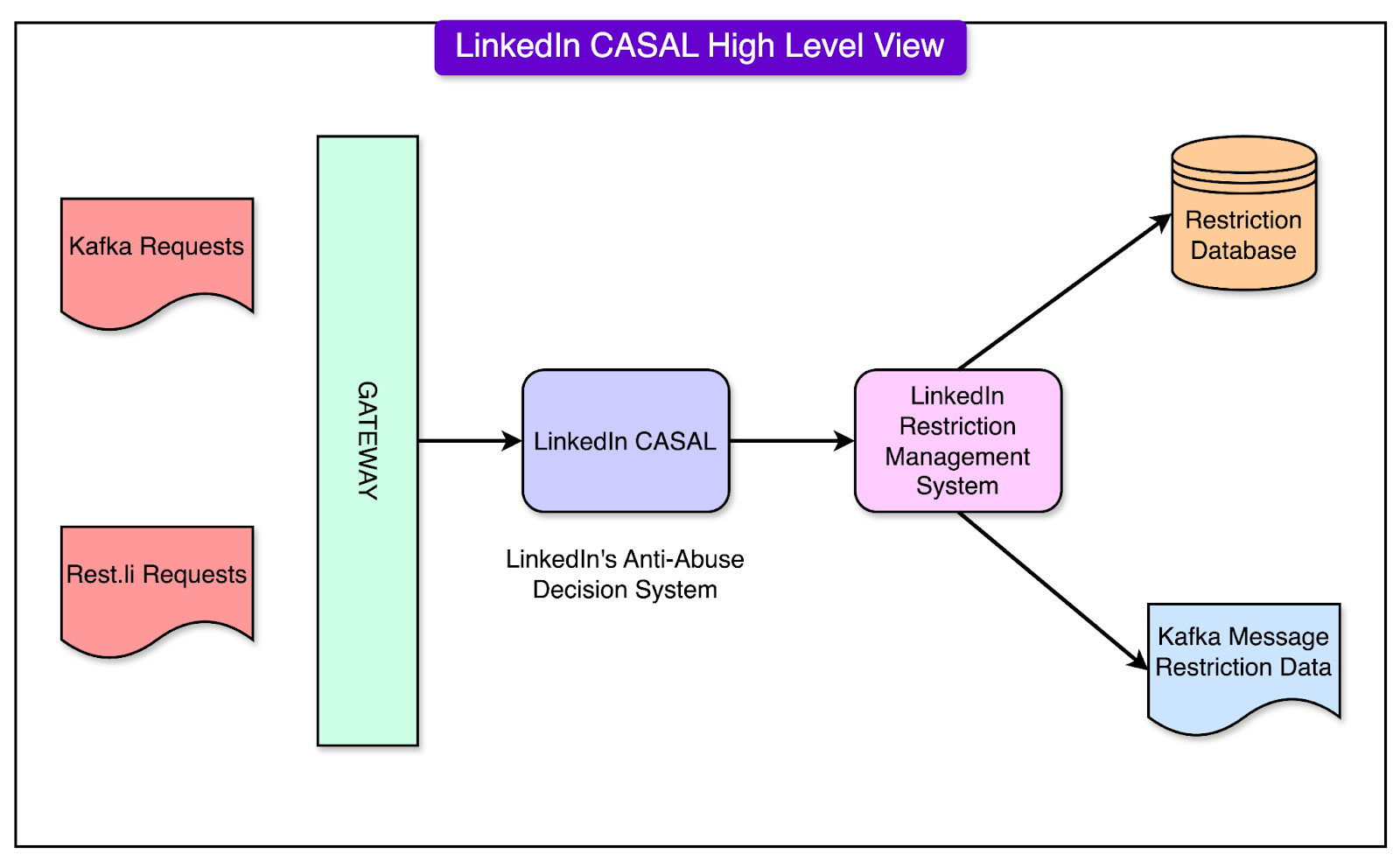
Business observability offers a centralized view of organizations' telemetry enriched with business context, enabling them to make data-driven decisions. Disclaimer: The details in this post have been derived from the LinkedIn Engineering Blog. All credit for the technical details goes to the LinkedIn engineering team. The links to the original articles are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them. One of the primary goals of LinkedIn is to provide a safe and professional environment for its members. At the heart of this effort lies a system called CASAL. CASAL stands for Community Abuse and Safety Application Layer. This platform is the first line of defense against bad actors and adversarial attacks. It combines technology and human expertise to identify and prevent harmful activities. The various aspects of this system are as follows:
Together, these tools form a multi-layered shield, protecting LinkedIn’s community from abuse while maintaining a professional and trusted space for networking. In this article, we’ll look at the design and evolution of LinkedIn’s enforcement infrastructure in detail.
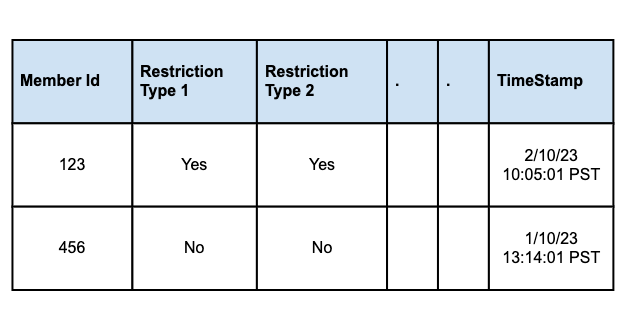
Evolution of Enforcement InfrastructureThere have been three major generations of LinkedIn’s restriction enforcement system. Let’s look at each generation in detail. First GenerationInitially, LinkedIn used a relational database (Oracle) to store and manage restriction data. Restrictions were stored in Oracle tables, with different types of restrictions isolated into separate tables for better organization and manageability. CRUD (Create, Read, Update, Delete) workflows were designed to handle the lifecycle of restriction records, ensuring proper updates and removal when necessary. See the diagram below:
However, this approach posed a few challenges:
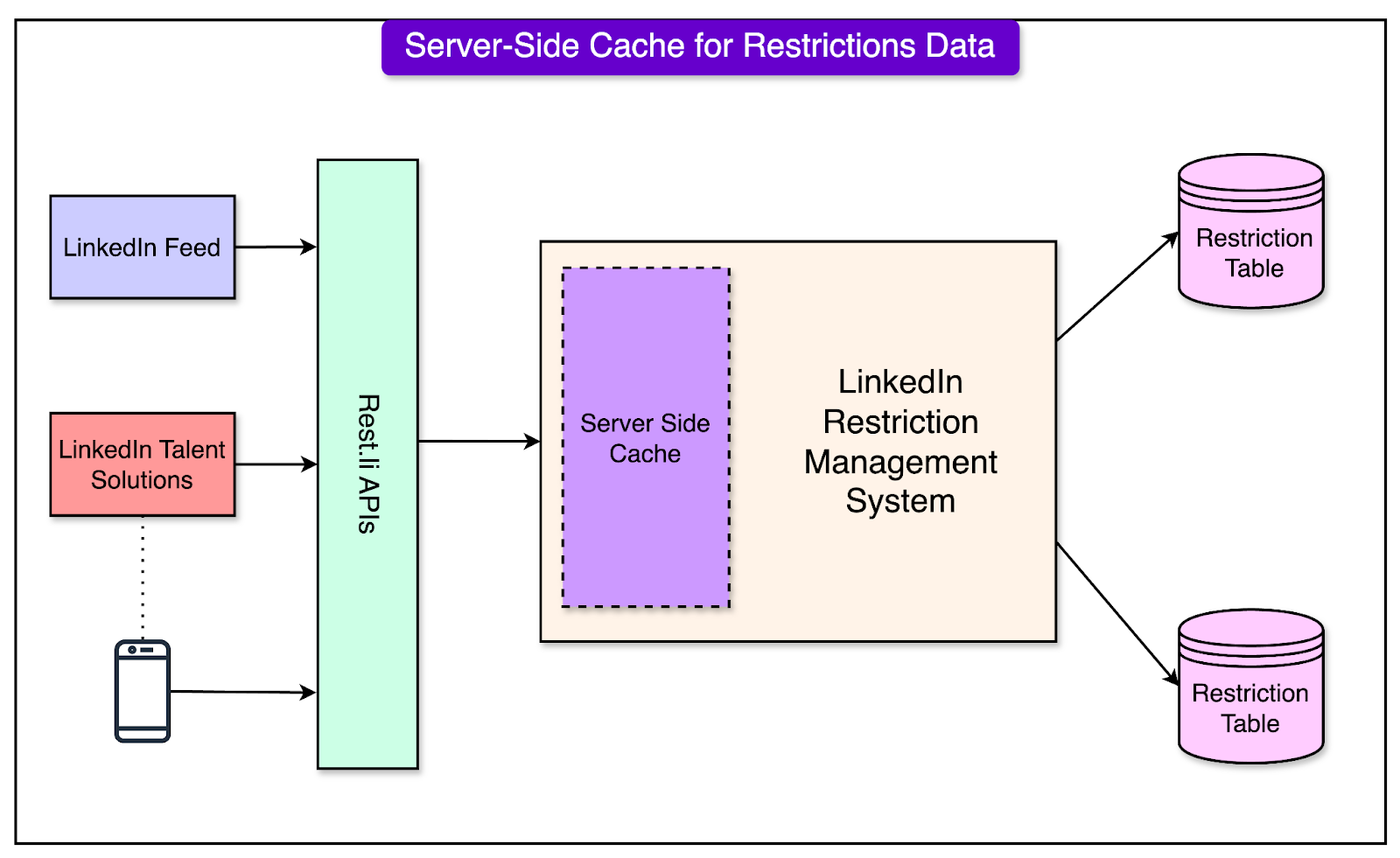
Server-Side Cache ImplementationTo address the scaling challenges, the team introduced server-side caching. This significantly reduced latency by minimizing the need for frequent database queries. A cache-aside strategy was employed that worked as follows:
See the diagram below that shows the server-side cache approach:
Restrictions were assigned predefined TTL (Time-to-Live) values, ensuring the cached data was refreshed periodically. There were also shortcomings with this approach:
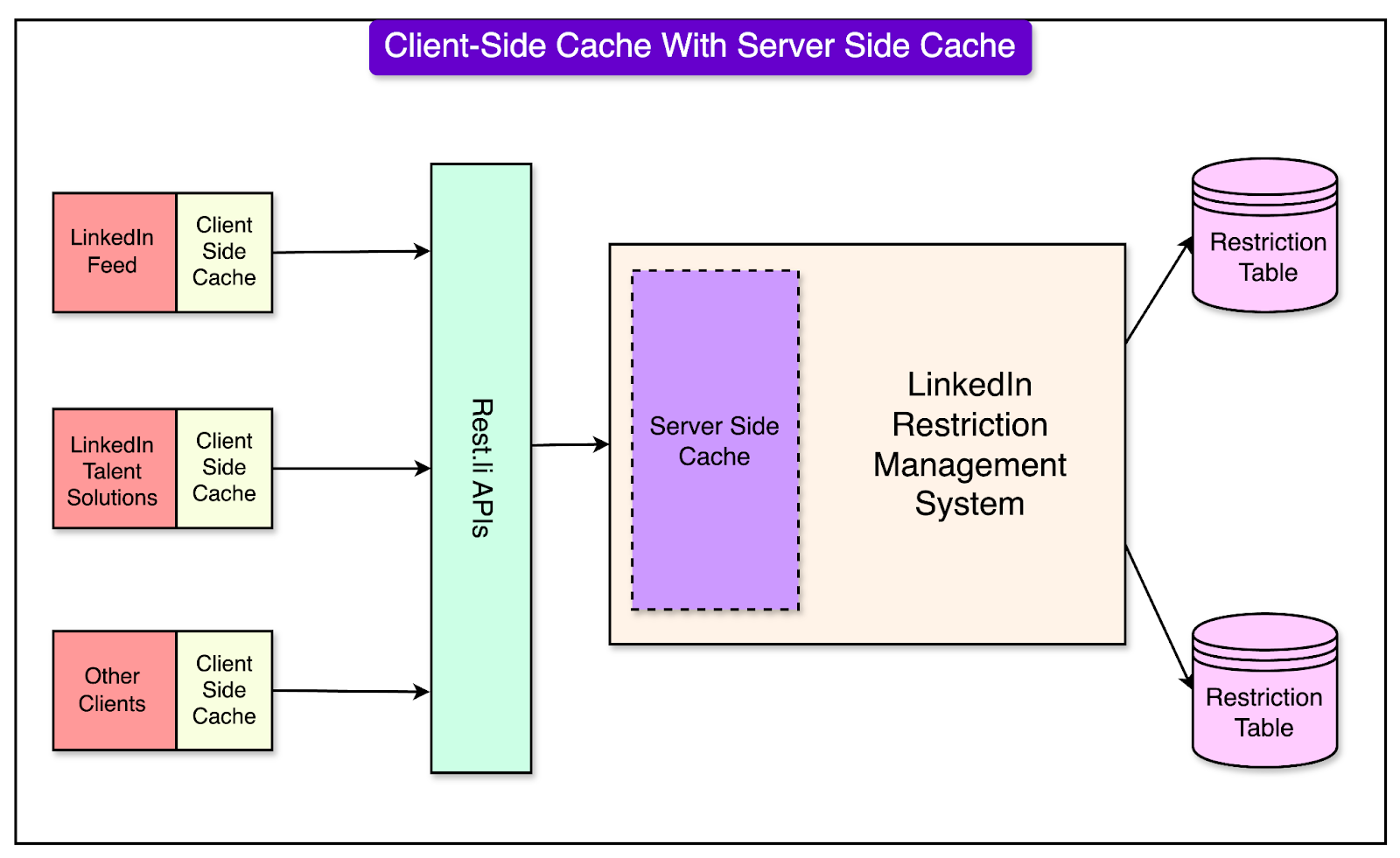
Client-Side Cache AdditionBuilding on the server-side cache, LinkedIn introduced client-side caching to enhance performance further. This approach enabled upstream applications (like LinkedIn Feed and Talent Solutions) to maintain their local caches. See the diagram below:
To facilitate this, a client-side library was developed to cache the restriction data directly on application hosts, reducing the dependency on server-side caches. Even this approach had some challenges as follows:
Full Refresh-Ahead CacheTo overcome some of the challenges with client-side caching, the team adopted a full refresh-ahead cache model for the system. In this approach, each client stored all restriction data in its local memory, eliminating the need for frequent database queries. A polling mechanism regularly checked for updates to maintain cache freshness. This led to a remarkable improvement in latencies, primarily because all member data was readily available on the client side. There was no need for network calls. However, the approach also had some limitations and trade-offs:
Bloom FiltersTo address scalability and efficiency challenges, LinkedIn implemented Bloom Filters. Bloom Filter is a probabilistic data structure designed to handle large datasets efficiently. Instead of storing the full dataset, it used a compact, memory-efficient encoding to determine whether a restriction record existed in the system. If a query matched a record in the Bloom Filter, the system would proceed to apply the restriction. The main advantage of using Bloom Filter was to conserve valuable resources. It reduced the memory footprint compared to traditional caching mechanisms. Also, queries were processed rapidly, improving system responsiveness. However, Bloom Filters also had some trade-offs:
Second GenerationAs LinkedIn grew and its platform became more complex, the engineering team recognized the limitations of its first-generation system, which relied heavily on relational databases and caching strategies. To keep up with the demands of a billion-member platform, the second generation of LinkedIn’s restriction enforcement system was designed. The second-generation system had several important goals such as:
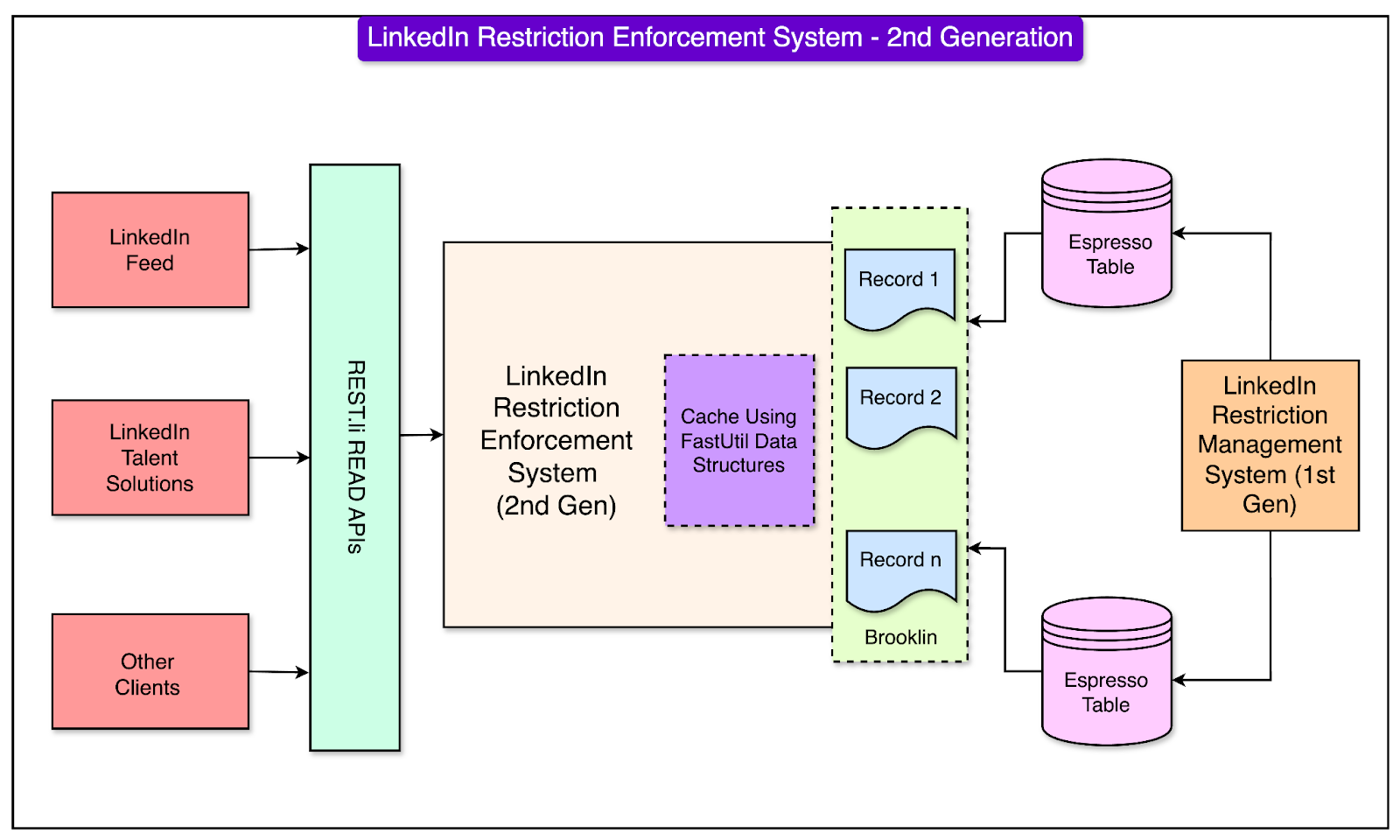
Adoption of NoSQL Distributed SystemsOne of the key innovations in this generation was the migration of restriction data management to LinkedIn’s Espresso, a custom-built distributed NoSQL document store. This is because relational databases like Oracle struggled with the high query throughput and latency requirements of LinkedIn’s growing platform. Espresso, being a distributed NoSQL system, provided better scalability and performance while maintaining data consistency. Espresso was tightly integrated with Kafka, LinkedIn’s real-time data streaming platform. Every time a new restriction record was created, Espresso would emit Kafka messages containing the data and metadata of the record. These Kafka messages enabled real-time synchronization of restriction data across multiple servers and data centers, ensuring that the system always had the latest information. See the diagram below to understand the architecture of the 2nd generation restriction enforcement system.
Despite its many advancements, the second-generation system faced some operational challenges, particularly during specific scenarios:
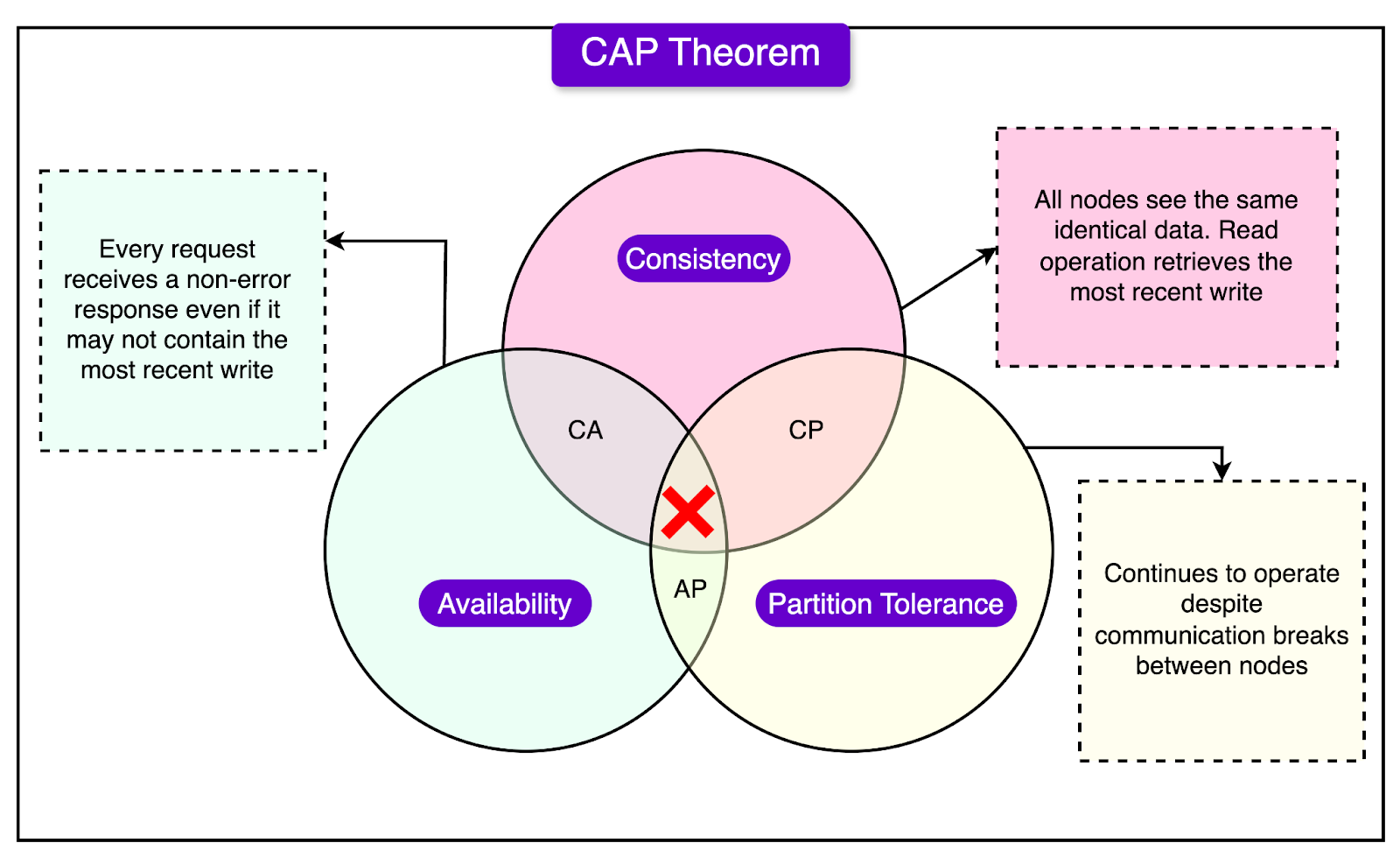
CAP TheoremLinkedIn had to make critical architectural choices concerning CAP Theorem trade-offs while designing the second-generation system. The CAP Theorem states that a system can only achieve two out of the following three guarantees at any given time:
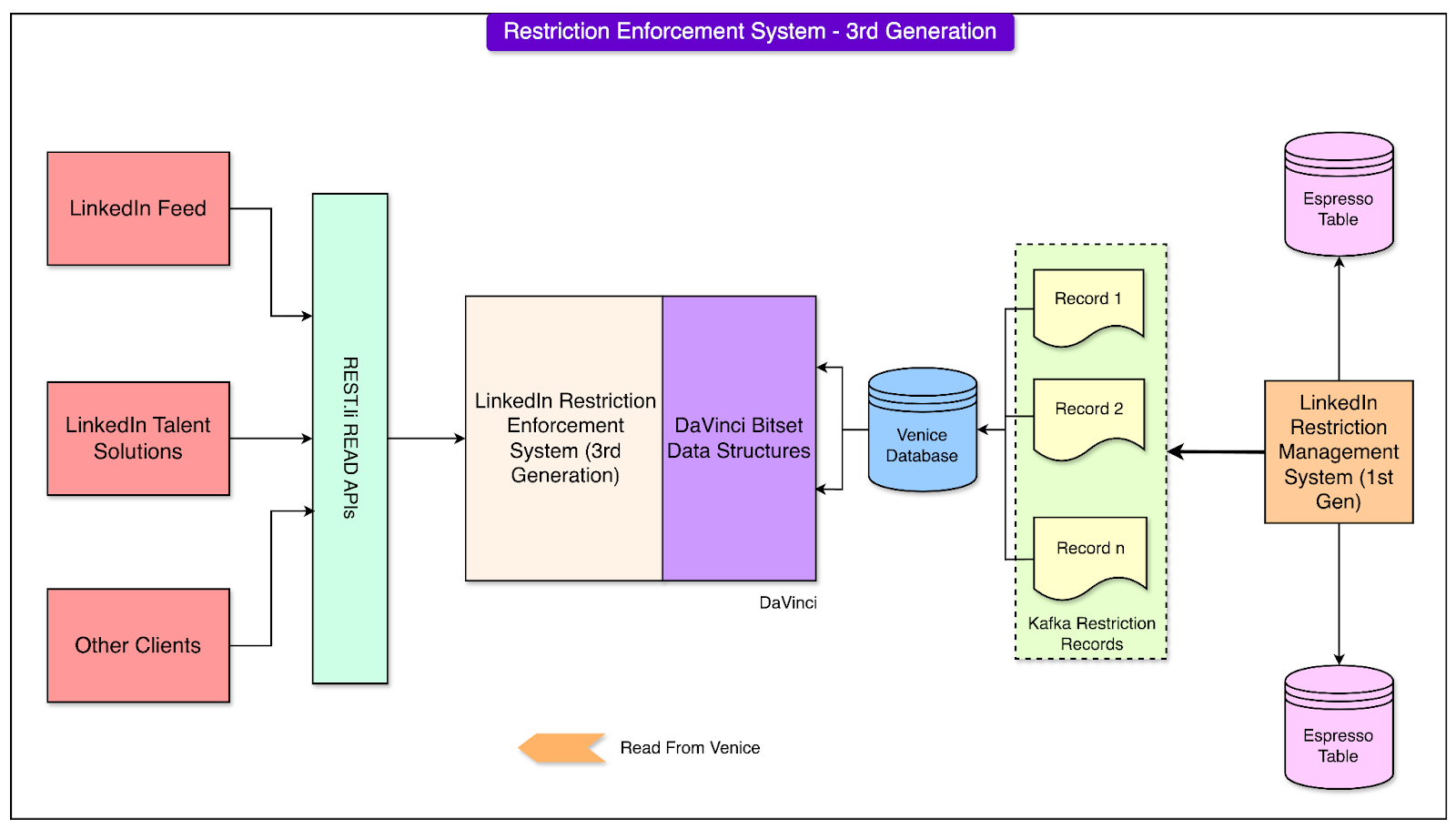
LinkedIn prioritized consistency (C) and availability (A) over partition tolerance (P). The decision was driven by their latency and reliability goals. The restriction enforcement system needed to provide accurate and up-to-date data across the platform. Incorrect or outdated restriction records could lead to security lapses or poor user experiences. Also, high availability was essential for ensuring that restrictions could be enforced seamlessly, even during peak activity periods. LinkedIn's previous experiences with partitioned databases revealed that partitions could introduce latencies that conflicted with their stringent performance requirements (for example, ultra-low latency of <5 ms). The use of Espresso allowed LinkedIn to handle consistency and availability more effectively within their system design. Integration with Kafka ensured that restriction records were synchronized across servers in real-time, maintaining consistency without significant delays. Third GenerationAs LinkedIn grew even further, the second-generation restriction enforcement system, though robust, began to show strain under the increasing volume of data and adversarial attacks. Therefore, the LinkedIn engineering team implemented a new generation of its restriction enforcement system. See the diagram below:
The third generation introduced innovations focused on optimizing memory usage, improving resilience, and accelerating the bootstrap process. 1 - Off-Heap Memory UtilizationOne of the major bottlenecks in the second-generation system was the reliance on in-heap memory for data storage. This approach led to challenges with Garbage Collection (GC) cycles, which caused latency spikes and degraded system performance. To address these issues, the third-generation system moved data storage to off-heap memory. Unlike in-heap memory (managed by the Java Virtual Machine), off-heap memory exists outside the JVM’s control. By shifting data storage to off-heap memory, the system reduced the frequency and intensity of GC events. Some benefits of this approach were as follows:
2 - Venice and DaVinci FrameworkTo further optimize the system, the LinkedIn engineering team introduced DaVinci, an advanced client library, and integrated it with Venice, a scalable derived data platform. Here’s how these tools work together:
The innovations in the third-generation system addressed many of the limitations of its predecessors. A couple of benefits were as follows:
ConclusionFrom the early reliance on relational databases to the adoption of advanced NoSQL systems like Espresso, and the integration of cutting-edge frameworks like DaVinci and Venice, every stage of development of the restriction enforcement system showcased LinkedIn's focus on innovation. However, this journey was not just about innovation. It was also guided by a clear set of principles such as:
References: SPONSOR USGet your product in front of more than 1,000,000 tech professionals. Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases. Space Fills Up Fast - Reserve Today Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com. © 2025 ByteByteGo
|
by "ByteByteGo" <bytebytego@substack.com> - 11:34 - 21 Jan 2025