- Mailing Lists
- in
- How Netflix Warms Petabytes of Cache Data
Archives
- By thread 5234
-
By date
- June 2021 10
- July 2021 6
- August 2021 20
- September 2021 21
- October 2021 48
- November 2021 40
- December 2021 23
- January 2022 46
- February 2022 80
- March 2022 109
- April 2022 100
- May 2022 97
- June 2022 105
- July 2022 82
- August 2022 95
- September 2022 103
- October 2022 117
- November 2022 115
- December 2022 102
- January 2023 88
- February 2023 90
- March 2023 116
- April 2023 97
- May 2023 159
- June 2023 145
- July 2023 120
- August 2023 90
- September 2023 102
- October 2023 106
- November 2023 100
- December 2023 74
- January 2024 75
- February 2024 75
- March 2024 78
- April 2024 74
- May 2024 108
- June 2024 98
- July 2024 116
- August 2024 134
- September 2024 130
- October 2024 141
- November 2024 171
- December 2024 115
- January 2025 216
- February 2025 140
- March 2025 220
- April 2025 233
- May 2025 239
- June 2025 303
- July 2025 46
How Netflix Warms Petabytes of Cache Data
How Netflix Warms Petabytes of Cache Data
Free tickets to P99 CONF — 60+ low-latency engineering talks (Sponsored)
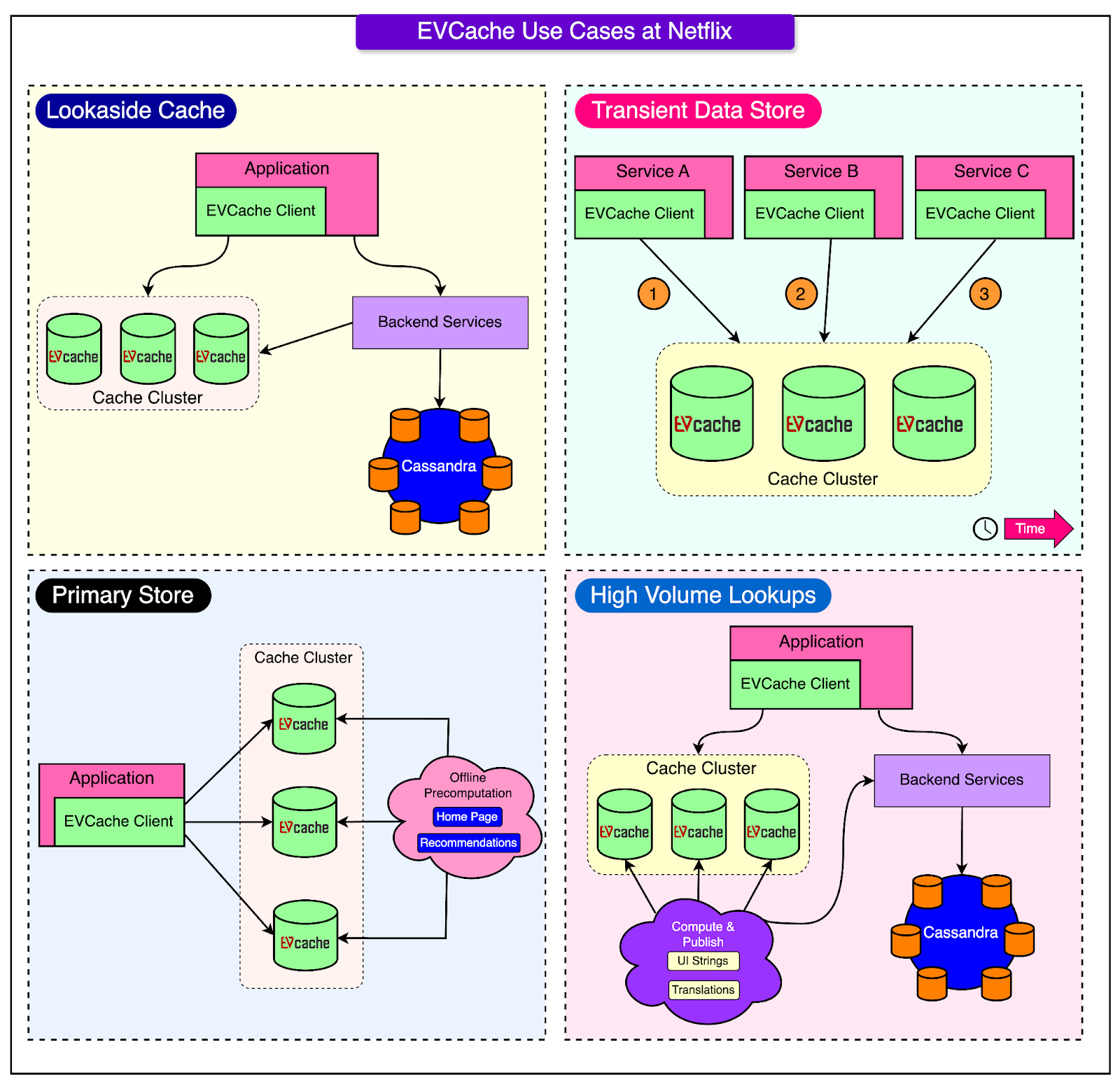
P99 CONF is the technical conference for anyone who obsesses over high-performance, low-latency applications. Engineers from Disney, Shopify, LinkedIn, Netflix, Google, Meta, Uber + more will be sharing 60+ talks on topics like Rust, Go, Zig, distributed data systems, Kubernetes, and AI/ML. Join 20K of your peers for an unprecedented opportunity to learn from experts like Michael Stonebraker, Bryan Cantrill, Avi Kivity, Liz Rice & Gunnar Morling & more – for free, from anywhere. Bonus: Registrants are eligible to enter to win 1 of 300 free swag packs, get 30-day access to the complete O’Reilly library & learning platform, plus free digital books. Disclaimer: The details in this post have been derived from the Netflix Tech Blog. All credit for the technical details goes to the Netflix engineering team. The links to the original articles are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them. The goal of Netflix is to keep users streaming for as long as possible. However, a user’s typical attention span is just 90 seconds. If the streaming application is not responding fast enough, there is a high chance that the user will drop off. EVCache is one tool that helps Netflix reduce latency on their streaming app by supporting multiple use cases such as:
The diagram below shows the various use cases in more detail.
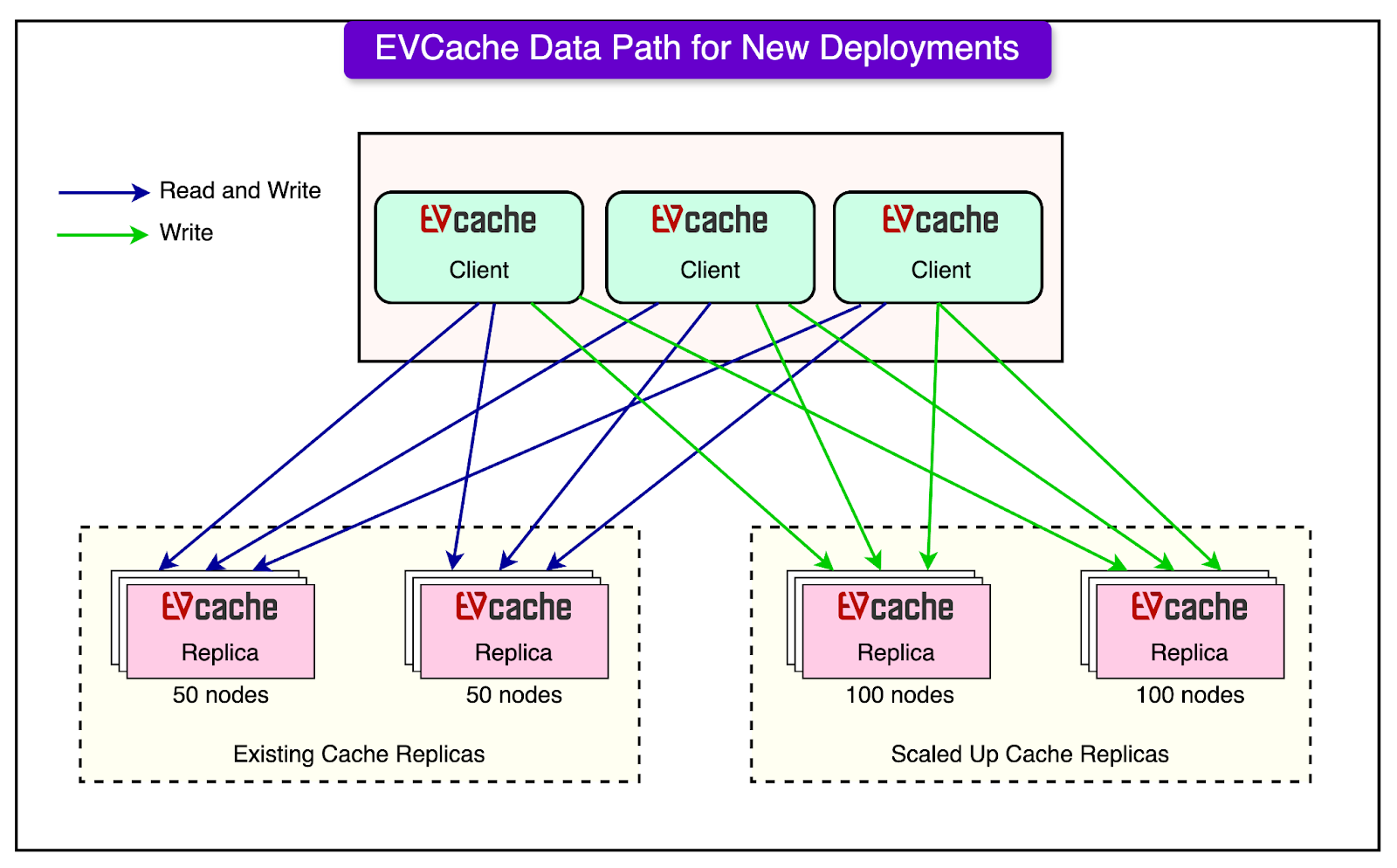
Netflix uses EVCache as a tier-1 cache. For reference, it is a distributed in-memory caching solution based on memcached that is integrated with Netflix OSS and AWS EC2 infrastructure. At Netflix, EVCache holds petabytes of data comprising thousands of nodes and hundreds of clusters in production. These clusters are routinely scaled up due to the increasing growth of the Netflix user base and the user data generated. The earlier process to make the cache bigger followed the below steps:
FusionAuth: Auth. Built for Devs, by Devs. (Sponsored)
FusionAuth is a complete auth & user platform that has 10M+ downloads and is trusted by industry leaders! See the diagram below for reference:
This approach worked, but it was expensive because they had to run two systems simultaneously for a while. Also, this solution had a few more problems:
To fix these problems, Netflix created a new tool called the cache warmer. This tool had two main features:
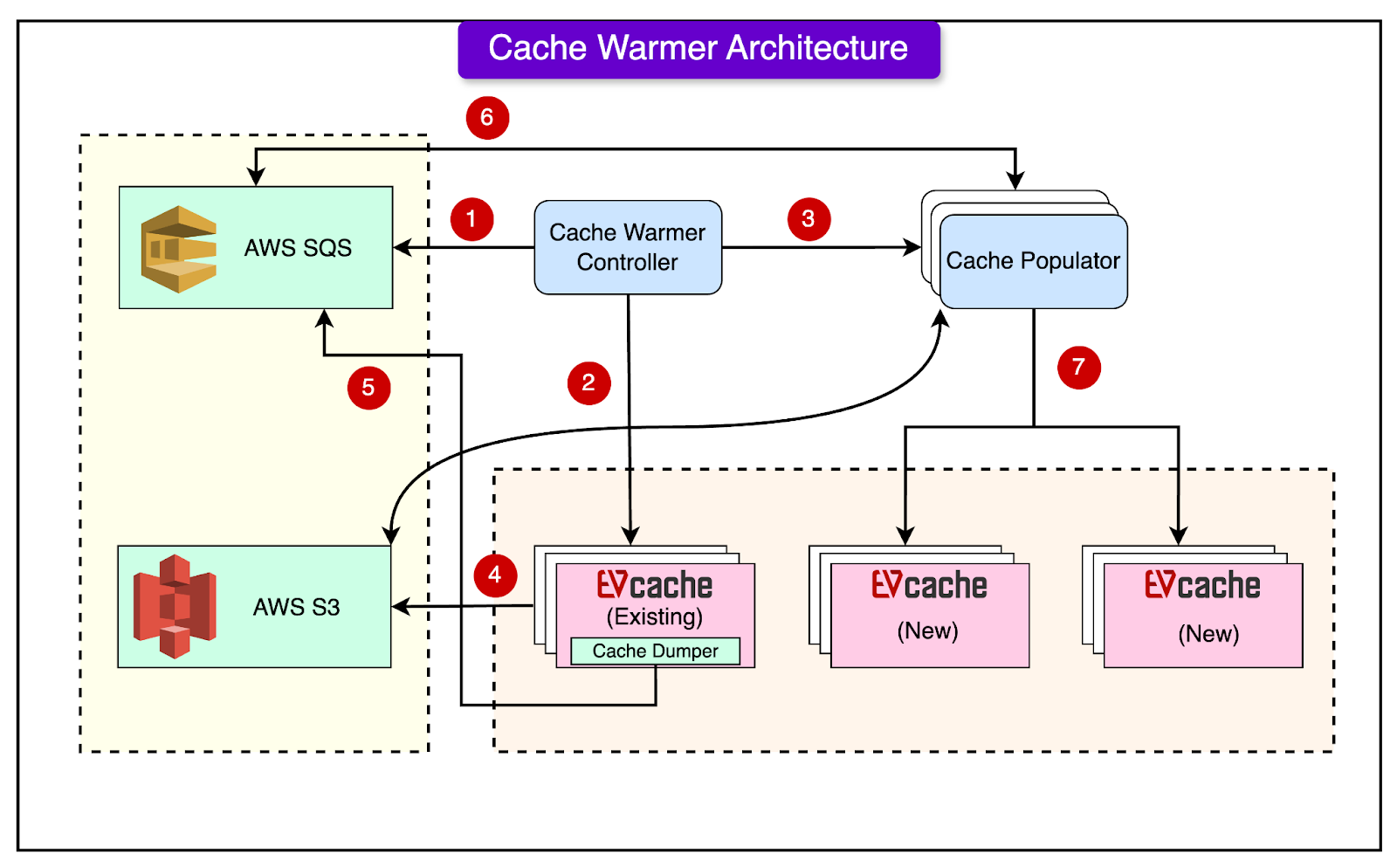
For Instance Warmer, they copy data to the new empty node from another replica in the system. This is done because the other nodes in the system have continued to operate and update data while this node was down or being replaced. By choosing a replica that doesn’t include this node, they ensure they’re getting the most up-to-date data from nodes that have been continuously operational. Cache Warmer DesignThe diagram below shows the architectural overview of the cache warming system built by Netflix.
The cache warming system consists of three main components:
Let’s look at each component one by one. ControllerThe Controller is the manager of the entire cache warming process. It sets up the environment and creates a communication channel (SQS queue) between the Dumper and Populator. Some of the key functions performed by the controller are as follows:
DumperThe Dumper is part of the EVCache sidecar, which is a separate service running alongside the main cache (memcached instance) on each node. Its job is to extract data from the existing cache. The dumping process works as follows:
The Dumper supports configurable chunk sizes for flexibility. It is also capable of parallel processing of multiple key chunks. PopulatorThe Populator is responsible for filling the new cache with data from the Dumper. Here’s how it works:
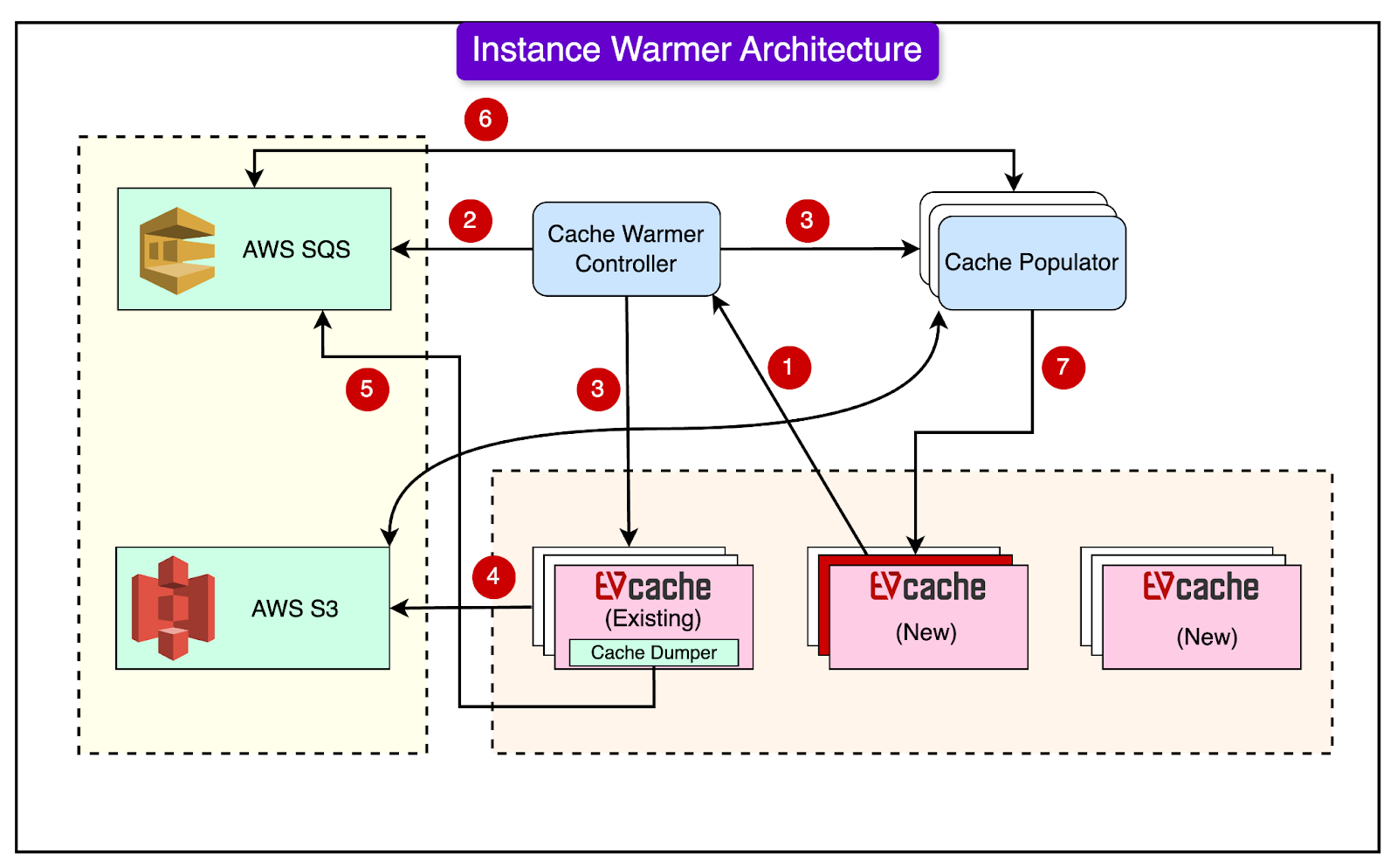
The Populator starts working as soon as data is available and doesn’t wait for the full dump. It can auto-scale based on the amount of data available to process. Instance WarmerIn a large EVCache deployment, individual nodes (servers) can sometimes be terminated or replaced due to hardware issues or other problems. This can cause:
To minimize these issues, the Netflix engineering team also developed an Instance Warmer that can quickly fill up replaced or restarted nodes with data. The diagram below shows the overall architecture of the Instance Warmer.
The Instance Warmer works as follows:
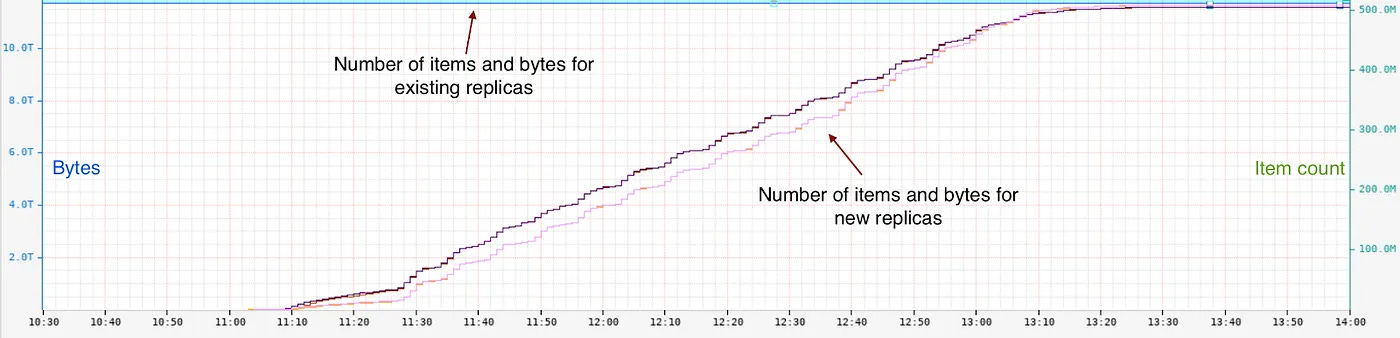
The instance warming process is more efficient than full replica warming because it deals with a smaller fraction of data on each node. Also, it is targeted to specific nodes rather than entire replicas. The Implementation ResultsNetflix is extensively using the cache warmer for scaling if the TTL is greater than a few hours. This has helped them handle the holiday traffic efficiently. The chart below shows the warming up of two new replicas from one of the two existing replicas. Existing replicas had about 500 million items and 12 Terabytes of data. The warm-up took around 2 hours to complete.
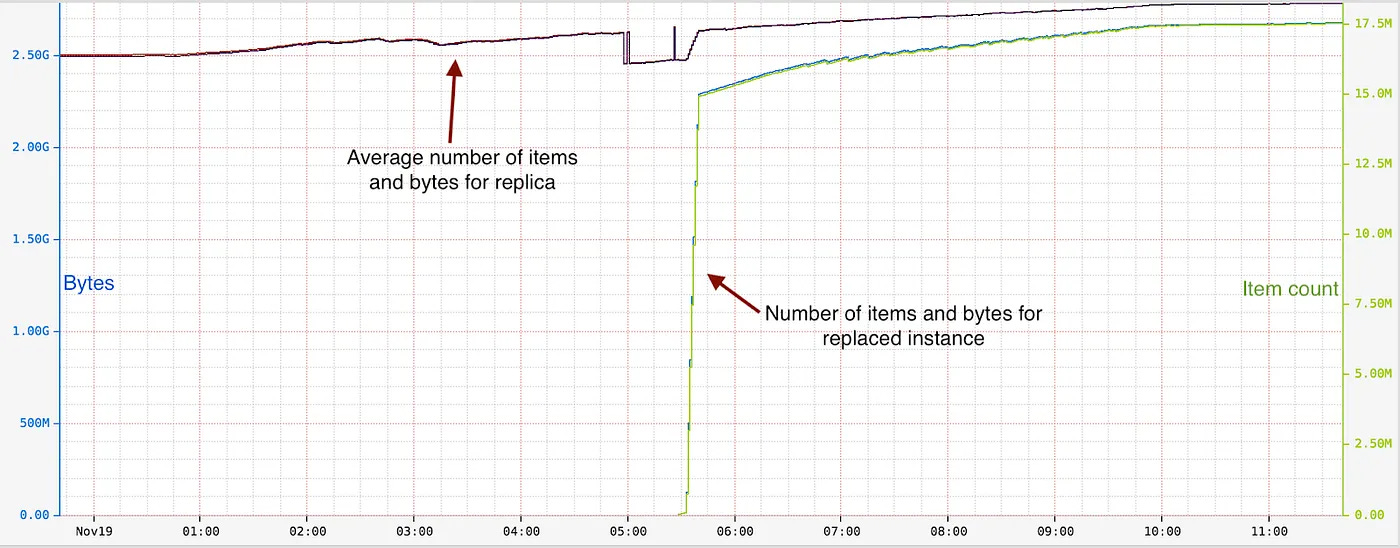
The Instance Warmer is also running in production and warming up a few instances every day. The chart below shows an instance getting replaced at around 5.27. It was warmed up in less than 15 minutes with about 2.2 GB of data and 15 million items.
ConclusionIn this post, we’ve looked at the cache-warming architecture implemented by Netflix in detail. This flexible cache-warming architecture has allowed Netflix to warm petabytes of cache data by copying it from existing replicas to one or more new replicas. Also, it has made it easy to warm specific nodes that were terminated or replaced due to hardware issues. One of the key takeaways is the cache warmer following a loosely coupled design where the Dumper and Populator are integrated through SQS. This shows how loosely coupled systems provide flexibility and extensibility in the long run as Netflix continues to enhance its system for greater efficiency. References: © 2024 ByteByteGo
|


by "ByteByteGo" <bytebytego@substack.com> - 11:36 - 17 Sep 2024