- Mailing Lists
- in
- How PayPal Serves 350 Billion Daily Requests with JunoDB
Archives
- By thread 5315
-
By date
- June 2021 10
- July 2021 6
- August 2021 20
- September 2021 21
- October 2021 48
- November 2021 40
- December 2021 23
- January 2022 46
- February 2022 80
- March 2022 109
- April 2022 100
- May 2022 97
- June 2022 105
- July 2022 82
- August 2022 95
- September 2022 103
- October 2022 117
- November 2022 115
- December 2022 102
- January 2023 88
- February 2023 90
- March 2023 116
- April 2023 97
- May 2023 159
- June 2023 145
- July 2023 120
- August 2023 90
- September 2023 102
- October 2023 106
- November 2023 100
- December 2023 74
- January 2024 75
- February 2024 75
- March 2024 78
- April 2024 74
- May 2024 108
- June 2024 98
- July 2024 116
- August 2024 134
- September 2024 130
- October 2024 141
- November 2024 171
- December 2024 115
- January 2025 216
- February 2025 140
- March 2025 220
- April 2025 233
- May 2025 239
- June 2025 303
- July 2025 127
How PayPal Serves 350 Billion Daily Requests with JunoDB
How PayPal Serves 350 Billion Daily Requests with JunoDB
Stop releasing bugs with fully automated end-to-end test coverage (Sponsored)
Bugs sneak out when less than 80% of user flows are tested before shipping. But how do you get that kind of coverage? You either spend years scaling in-house QA — or you get there in just 4 months with QA Wolf. How's QA Wolf different?
Have you ever seen a database that fails and comes up again in the blink of an eye? PayPal’s JunoDB is a database capable of doing so. As per PayPal’s claim, JunoDB can run at 6 nines of availability (99.9999%). This comes to just 86.40 milliseconds of downtime per day. For reference, our average eye blink takes around 100-150 milliseconds. While the statistics are certainly amazing, it also means that there are many interesting things to pick up from JunoDB’s architecture and design. In this post, we will cover the following topics:
Key Facts about JunoDBBefore we go further, here are some key facts about JunoDB that can help us develop a better understanding of it.
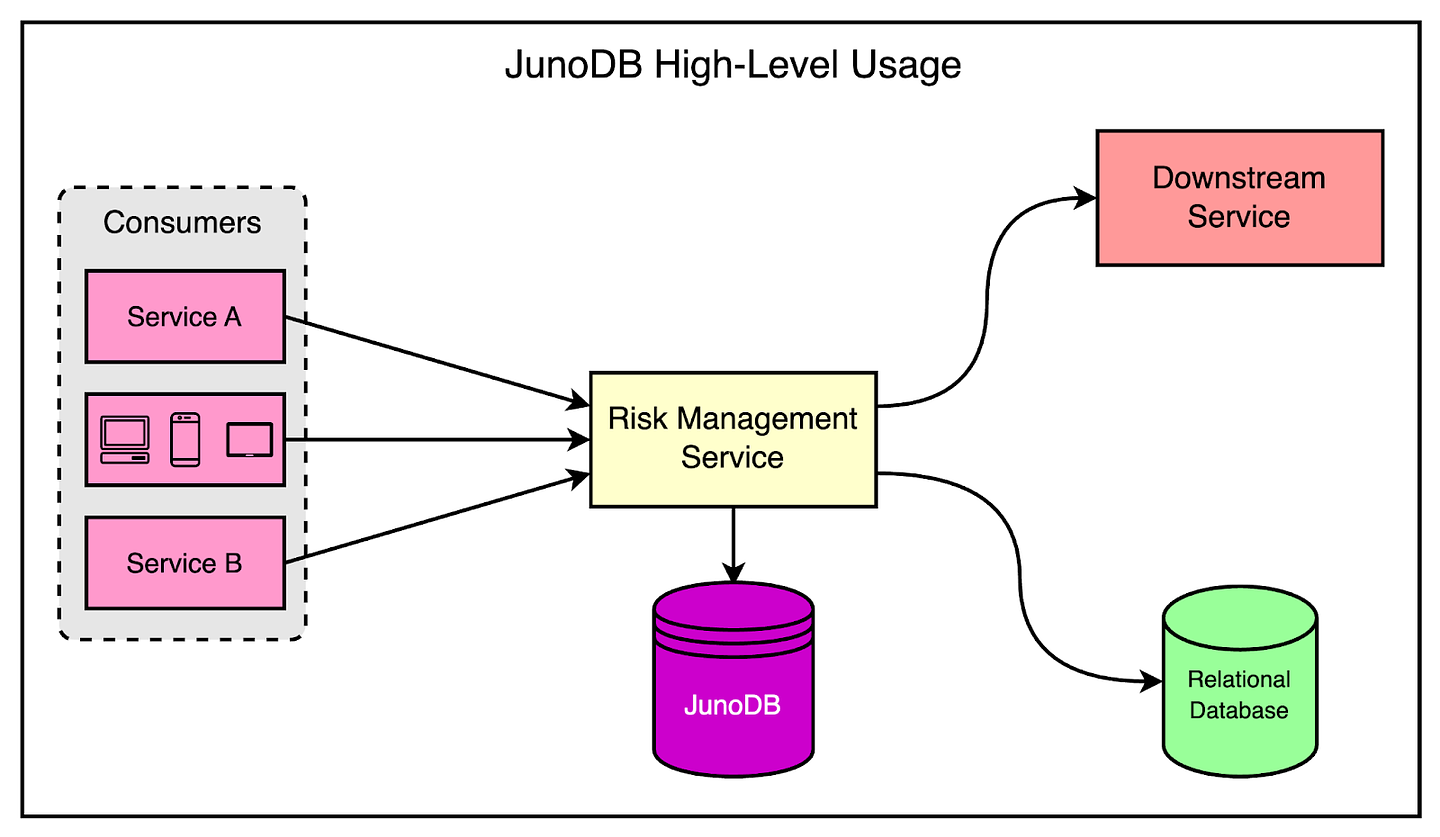
The diagram shows how JunoDB fits into the overall scheme of things at PayPal.
Why the Need for JunoDB?One common question surrounding the creation of something like JunoDB is this:
The reason is PayPal wanted multi-core support for the database and Redis is not designed to benefit from multiple CPU cores. It is single-threaded in nature and utilizes only one core. Typically, you need to launch several Redis instances to scale out on several cores if needed. Incidentally, JunoDB started as a single-threaded C++ program and the initial goal was to use it as an in-memory short TTL data store. For reference, TTL stands for Time to Live. It specifies the maximum duration a piece of data should be retained or the maximum time it is considered valid. However, the goals for JunoDB evolved with time.
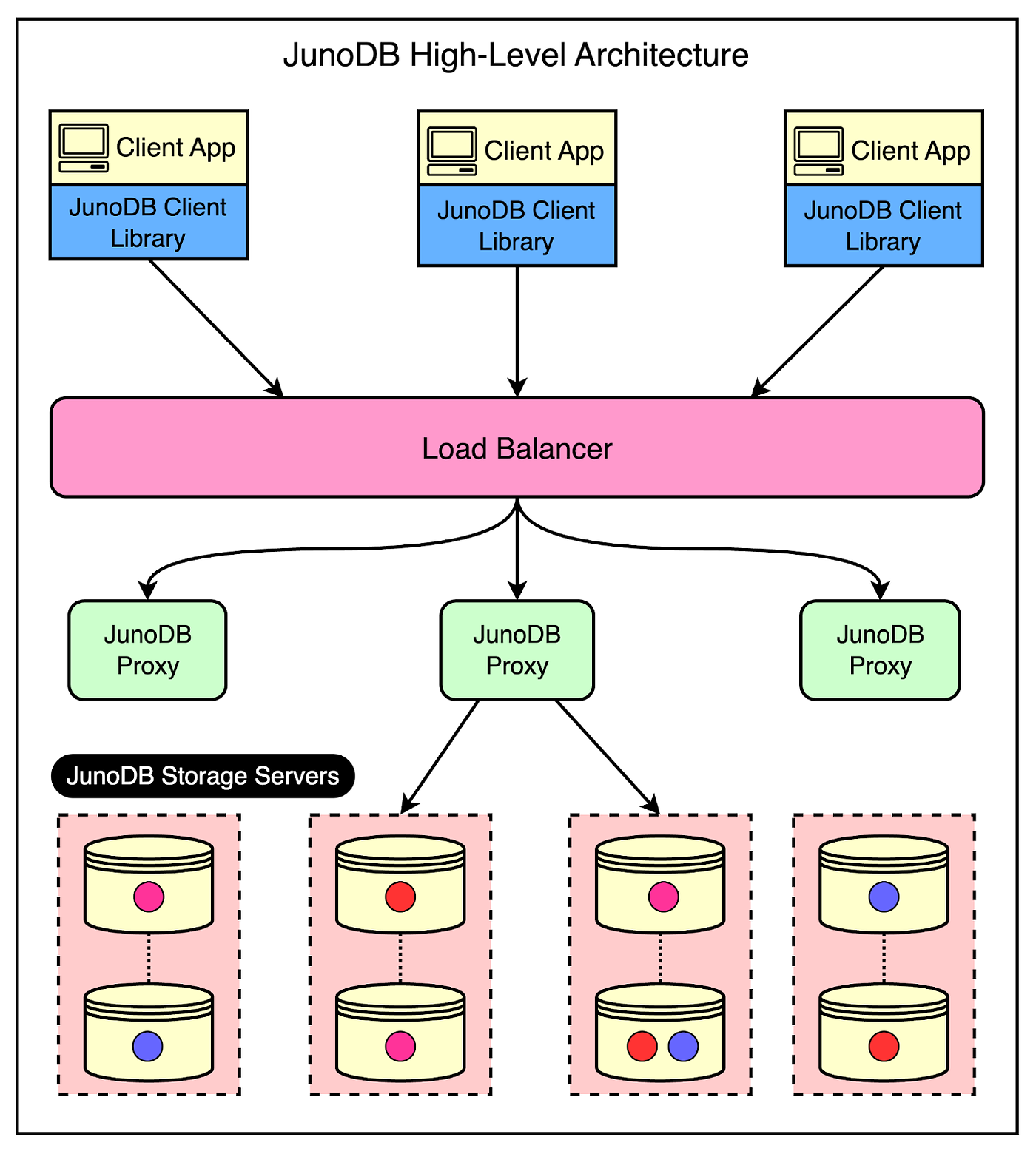
These goals meant that JunoDB had to be CPU-bound rather than memory-bound. For reference, “memory-bound” and “CPU-bound” refer to different performance aspects in computer programs. As the name suggests, the performance of memory-bound programs is limited by the amount of available memory. On the other hand, CPU-bound programs depend on the processing power of the CPU. For example, Redis is memory-bound. It primarily stores the data in RAM and everything about it is optimized for quick in-memory access. The limiting factor for the performance of Redis is memory rather than CPU. However, requirements like encryption are CPU-intensive because many cryptographic algorithms require raw processing power to carry out complex mathematical calculations. As a result, PayPal decided to rewrite the earlier version of JunoDB in Go to make it multi-core friendly and support high concurrency. The Architecture of JunoDBThe below diagram shows the high-level architecture of JunoDB.
Let’s look at the main components of the overall design. 1 - JunoDB Client LibraryThe client library is part of the client application and provides an API for storing and retrieving data via the JunoDB proxy. It is implemented in several programming languages such as Java, C++, Python, and Golang to make it easy to use across different application stacks. For developers, it’s just a matter of picking the library for their respective programming language and including it in the application to carry out the various operations. 2 - JunoDB Proxy with Load BalancerJunoDB utilizes a proxy-based design where the proxy connects to all JunoDB storage server instances. This design has a few important advantages:
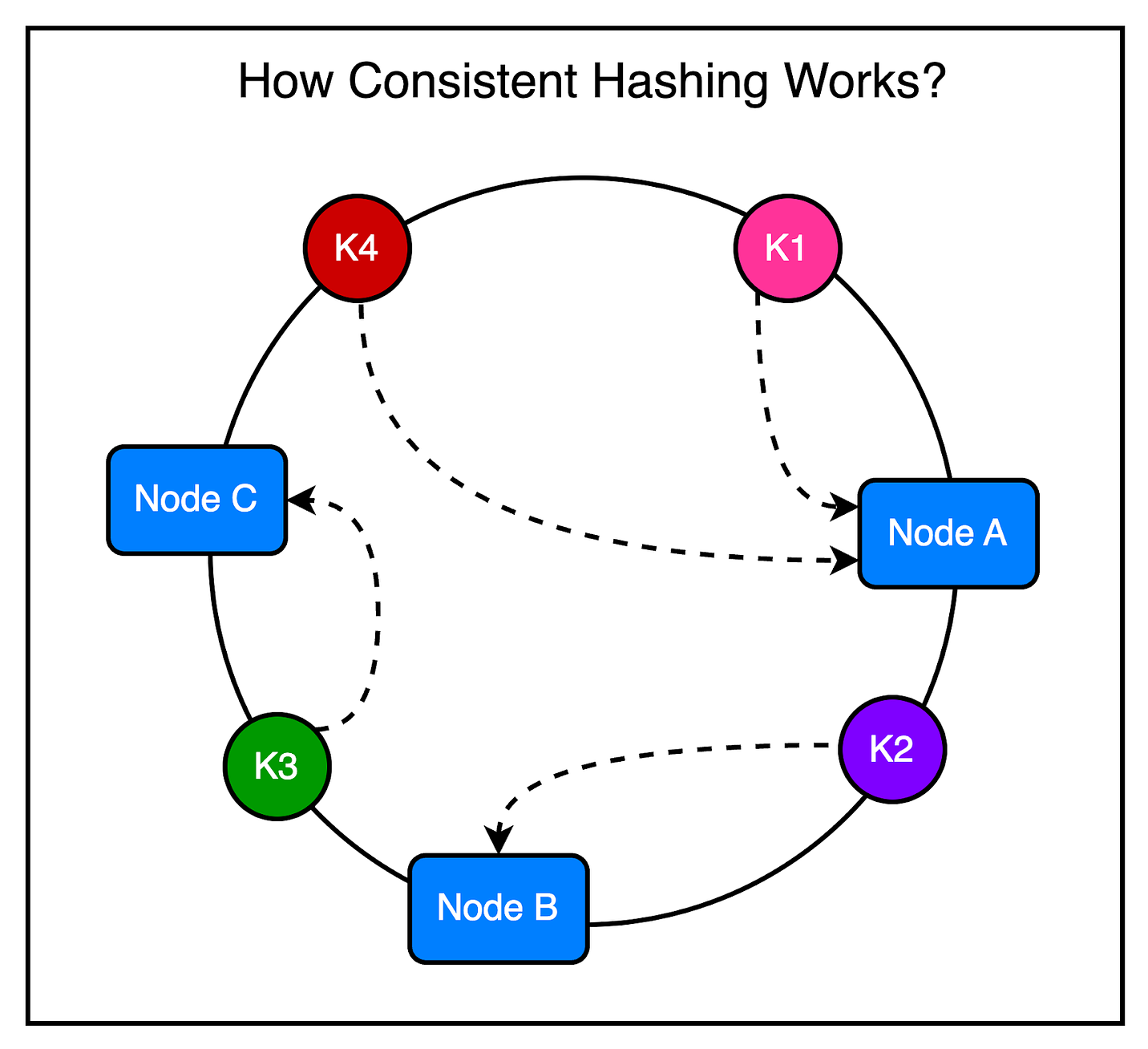
But can the JunoDB proxy turn into a single point of failure? To prevent this possibility, the proxy runs on multiple instances downstream to a load balancer. The load balancer receives incoming requests from the client applications and routes the requests to the appropriate proxy instance. 3 - JunoDB Storage ServersThe last major component in the JunoDB architecture is the storage servers. These are instances that accept the operation requests from the proxy and store data in the memory or persistent storage. Each storage server is responsible for a set of partitions or shards for an efficient distribution of data. Internally, JunoDB uses RocksDB as the storage engine. Using an off-the-shelf storage engine like RocksDB is common in the database world to avoid building everything from the ground up. For reference, RocksDB is an embedded key-value storage engine that is optimized for high read and write throughput. Key Priorities of JunoDBNow that we have looked at the overall design and architecture of JunoDB, it’s time to understand a few key priorities for JunoDB and how it achieves them. ScalabilitySeveral years ago, PayPal transitioned to a horizontally scalable microservice-based architecture to support the rapid growth in active customers and payment rates. While microservices solve many problems for them, they also have some drawbacks. One important drawback is the increased number of persistent connections to key-value stores due to scaling out the application tier. JunoDB handles this scaling requirement in two primary ways. 1 - Scaling for Client ConnectionsAs discussed earlier, JunoDB uses a proxy-based architecture. If client connections to the database reach a limit, additional proxies can be added to support more connections. There is an acceptable trade-off with latency in this case. 2 - Scaling for Data Volume and ThroughputThe second type of scaling requirement is related to the growth in data size. To ensure efficient storage and data fetching, JunoDB supports partitioning based on the consistent hashing algorithm. Partitions (or shards) are distributed to physical storage nodes using a shard map. Consistent hashing is very useful in this case because when the nodes in a cluster change due to additions or removals, only a minimal number of shards require reassignment to different storage nodes.
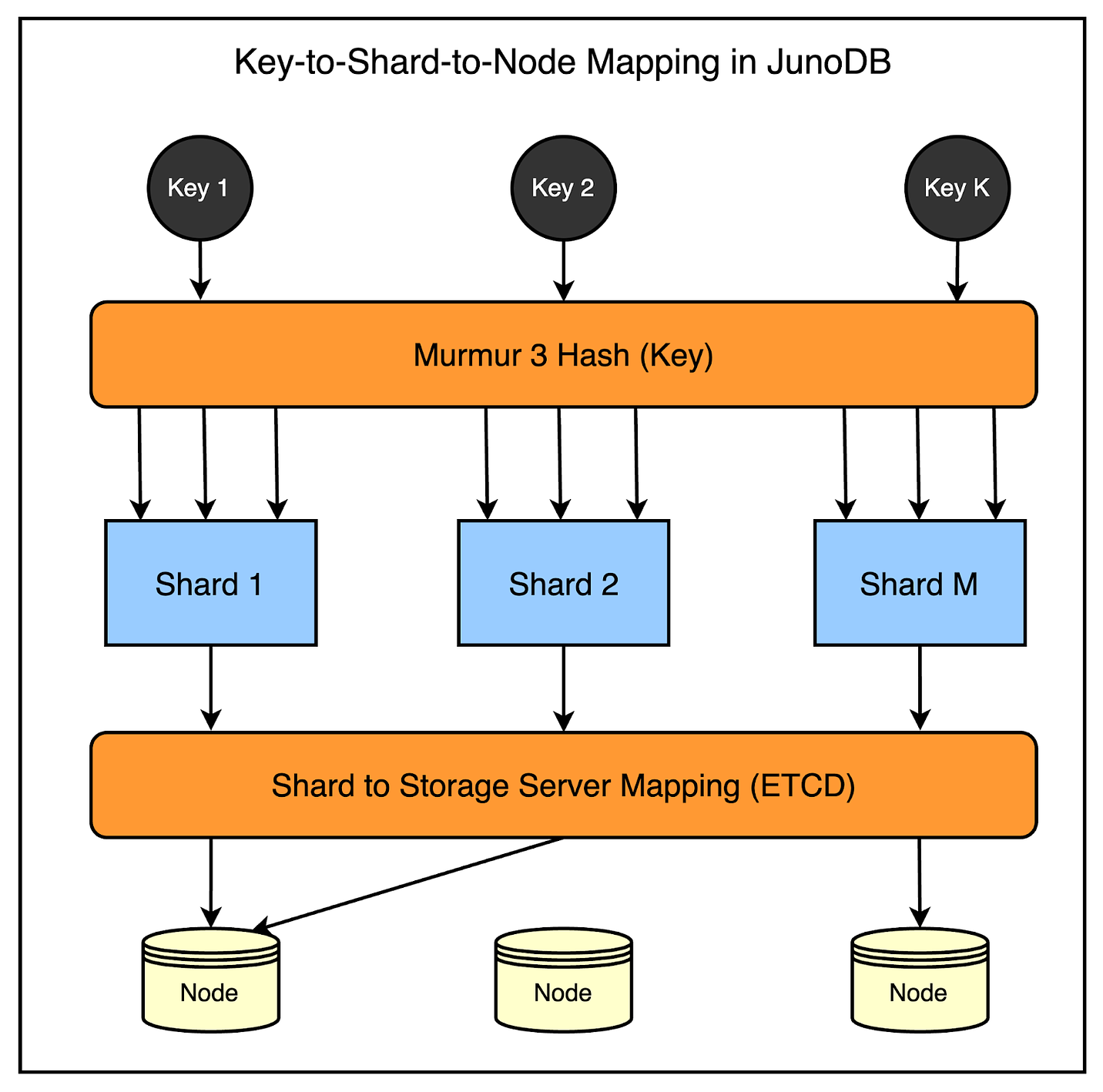
PayPal uses a fixed number of shards (1024 shards, to be precise), and the shard map is pre-generated and stored in ETCD storage. Any change to the shard mapping triggers an automatic data redistribution process, making it easy to scale your JunoDB cluster depending on the need. The below diagram shows the process in more detail.
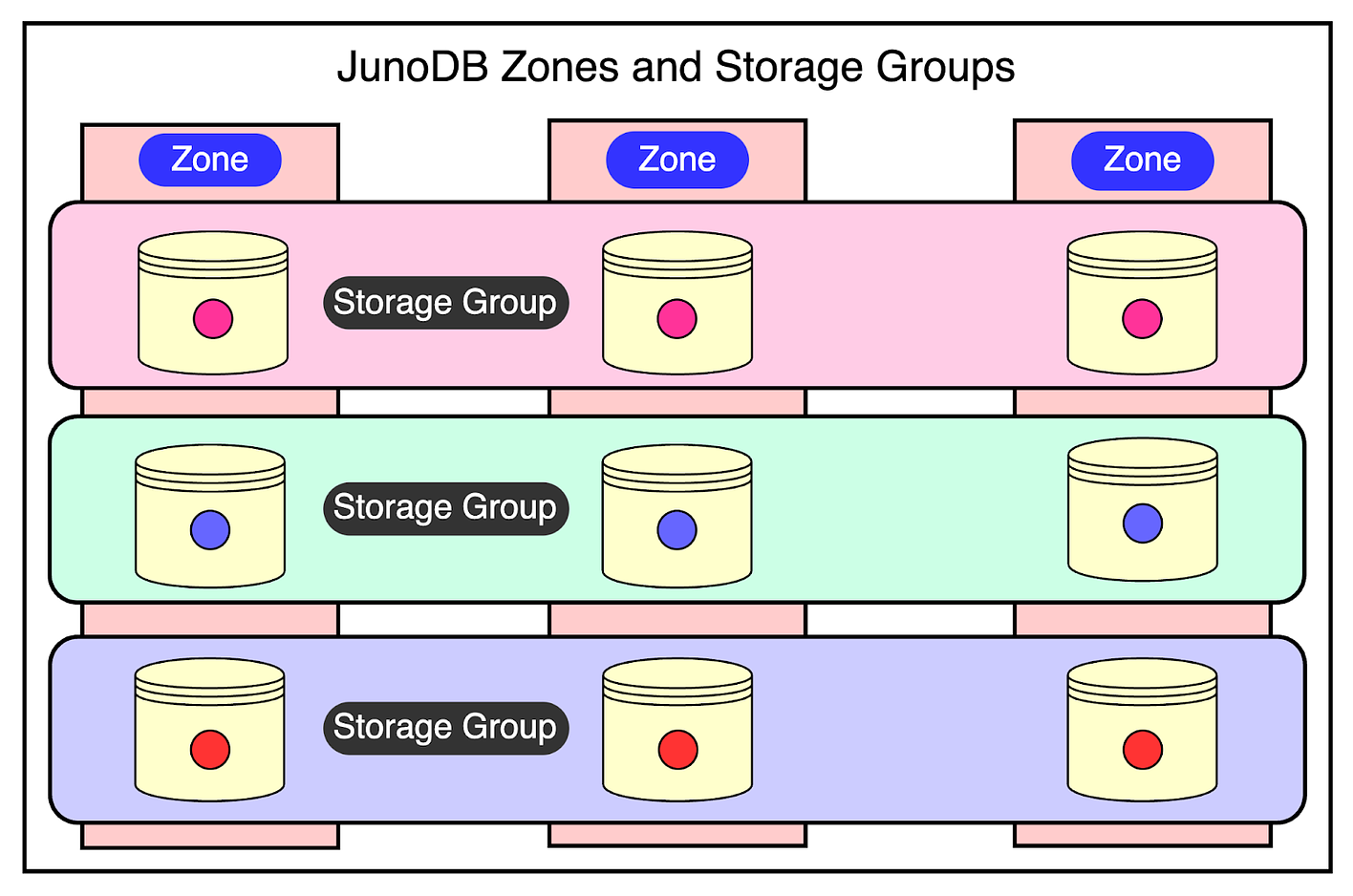
AvailabilityHigh availability is critical for PayPal. You can’t have a global payment platform going down without a big loss of reputation. However, outages can and will occur due to various reasons such as software bugs, hardware failures, power outages, and even human error. Failures can lead to data loss, slow response times, or complete unavailability. To mitigate these challenges, JunoDB relies on replication and failover strategies. 1 - Within-Cluster ReplicationIn a cluster, JunoDB storage nodes are logically organized into a grid. Each column represents a zone, and each row signifies a storage group. Data is partitioned into shards and assigned to storage groups. Within a storage group, each shard is synchronously replicated across various zones based on the quorum protocol.
The quorum-based protocol is the key to reaching a consensus on a value within a distributed database. You’ve two quorums:
There are two important rules when it comes to quorum.
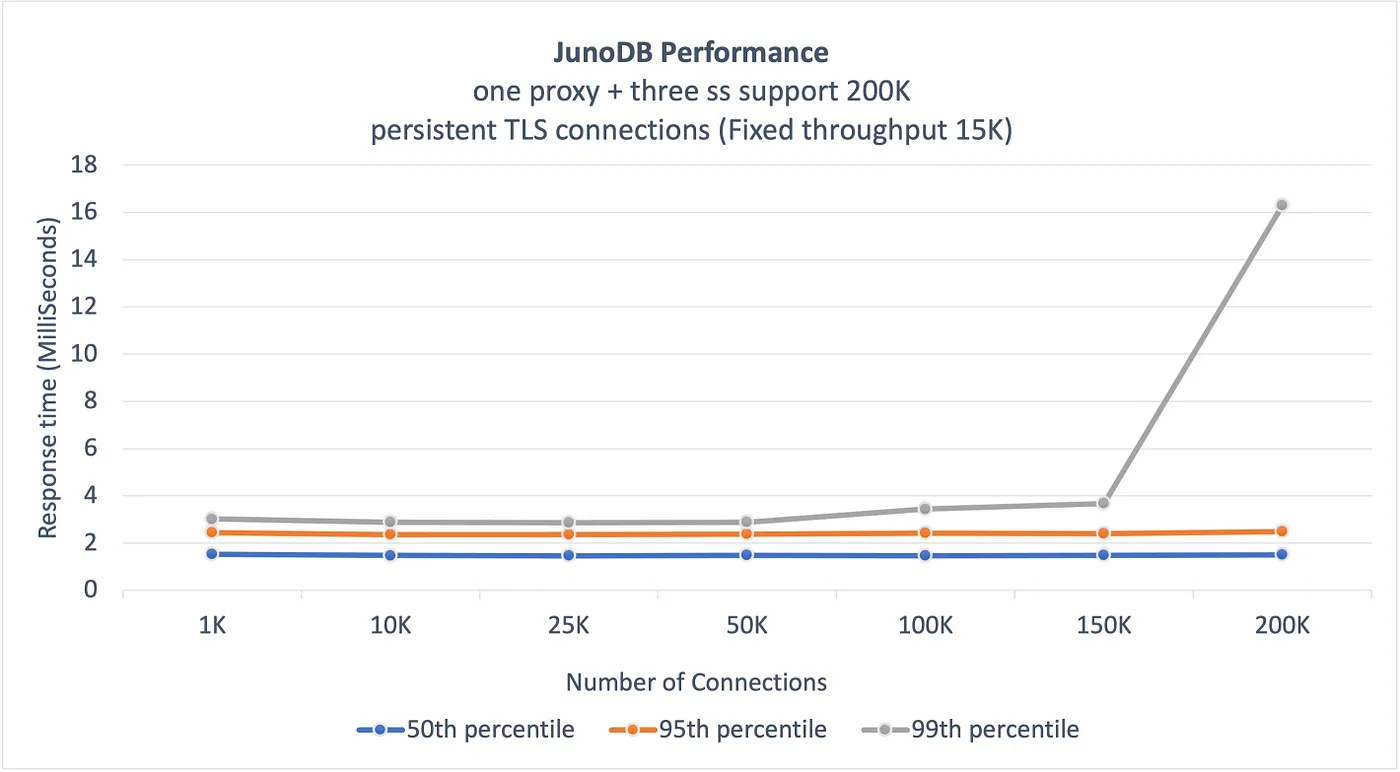
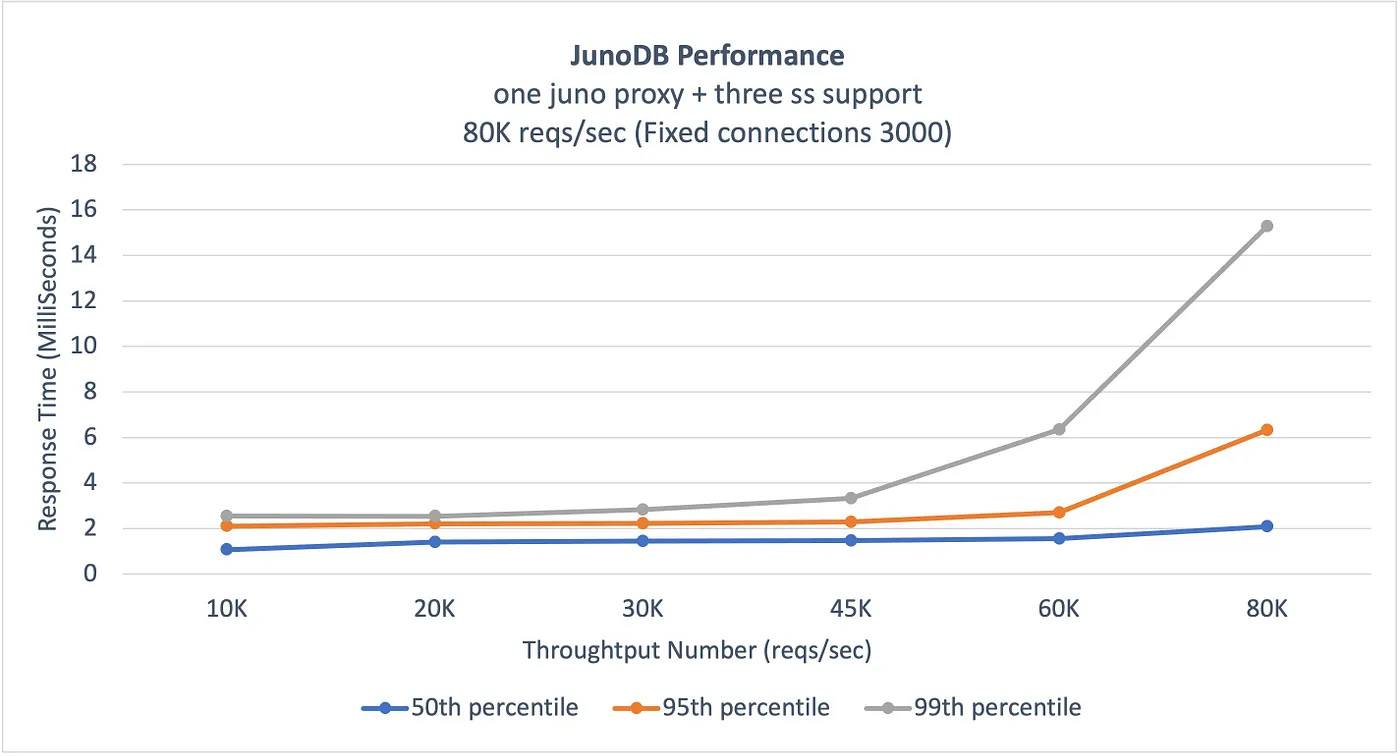
In production, PayPal has a configuration with 5 zones, a read quorum of 3, and a write quorum of 3. Lastly, the failover process in JunoDB is automatic and instantaneous without any need for leader re-election or data redistribution. Proxies can know about a node failure through a lost connection or a read request that has timed out. 2 - Cross-data center replicationCross-data center replication is implemented by asynchronously replicating data between the proxies of each cluster across different data centers. This is important to make sure that the system continues to operate even if there’s a catastrophic failure at one data center. PerformanceOne of the critical goals of JunoDB is to deliver high performance at scale. This translates to maintaining single-digit millisecond response times while providing a great user experience. The below graphs shared by PayPal show the benchmark results demonstrating JunoDB’s performance in the case of persistent connections and high throughput.
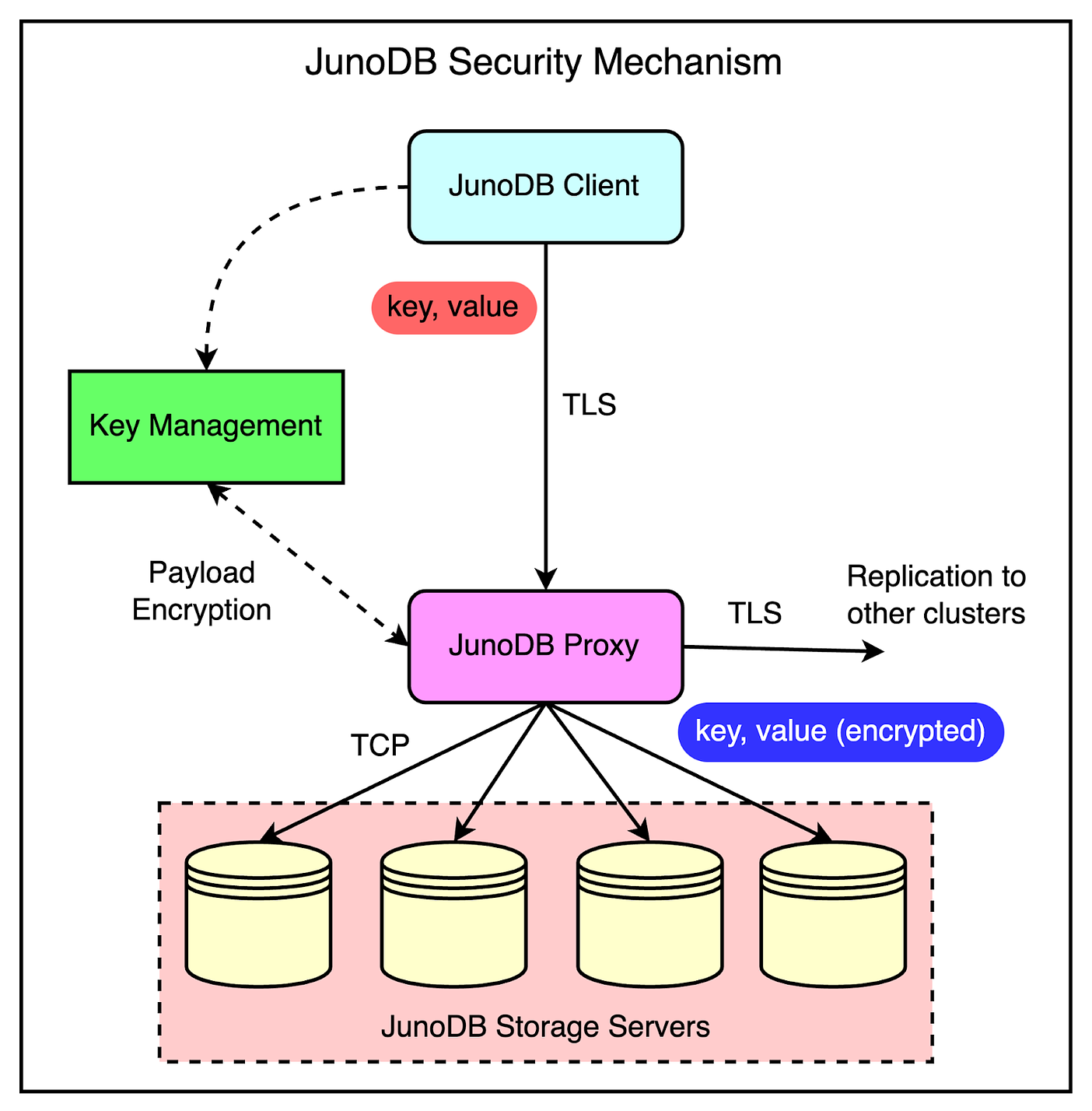
SecurityBeing a trusted payment processor, security is paramount for PayPal. Therefore, it’s no surprise that JunoDB has been designed to secure data both in transit and at rest.
A key management module is used to manage certificates for TLS, sessions, and the distribution of encryption keys to facilitate key rotation, The below diagram shows JunoDB’s security setup in more detail.
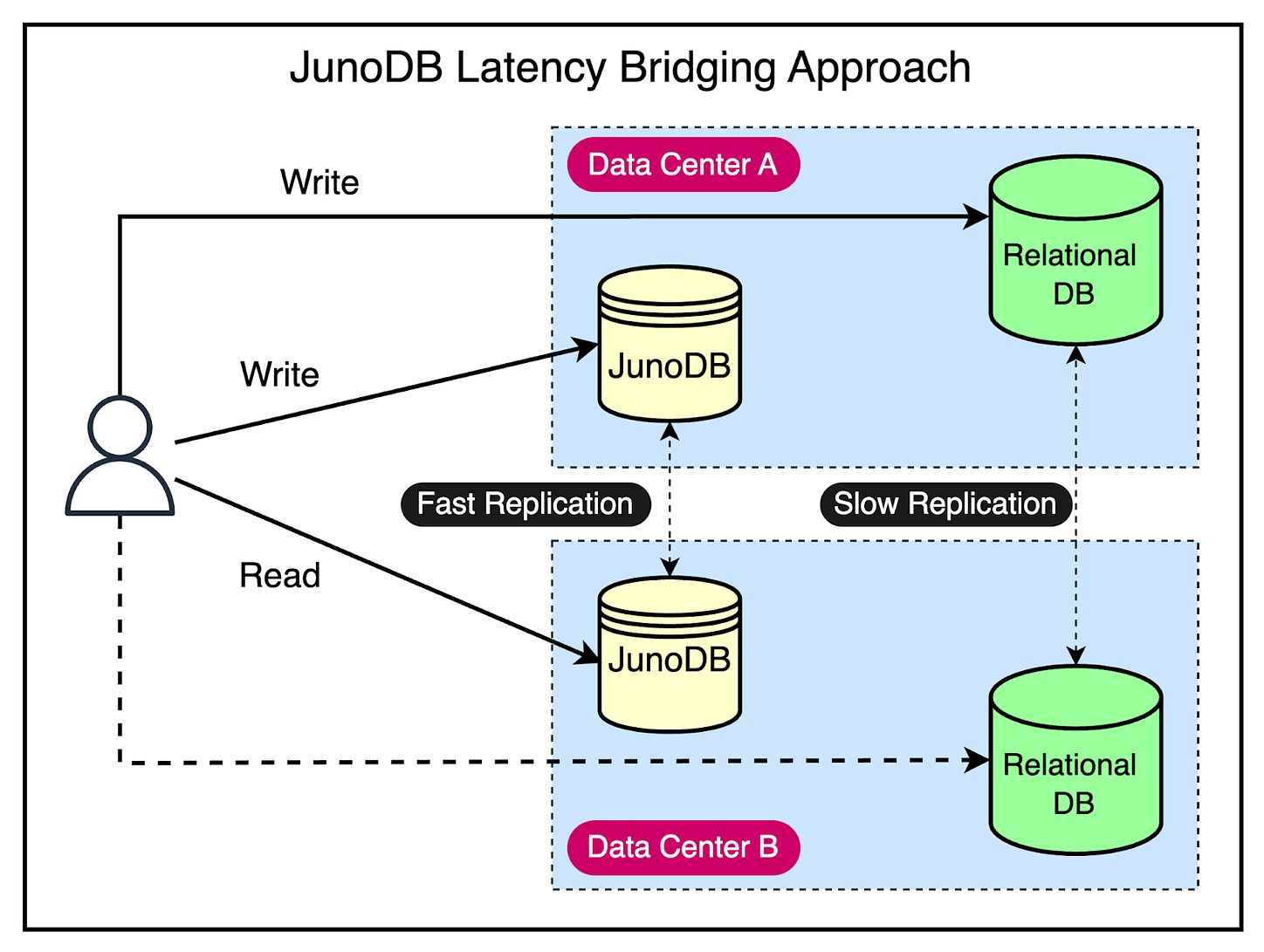
Use Cases of JunoDBWith PayPal having made JunoDB open-source, it’s possible that you can also use it within your projects. There are various use cases where JunoDB can help. Let’s look at a few important ones: 1 - CachingYou can use JunoDB as a temporary cache to store data that doesn’t change frequently. Since JunoDB supports both short and long-lived TTLs, you can store data from a few seconds to a few days. For example, a use case is to store short-lived tokens in JunoDB instead of fetching them from the database. Other items you can cache in JunoDB are user preferences, account details, and API responses. 2 - IdempotencyYou can also use JunoDB to implement idempotency. An operation is idempotent when it produces the same result even when applied multiple times. With idempotency, repeating the operation is safe and you don’t need to be worried about things like duplicate payments getting applied. PayPal uses JunoDB to ensure they don’t process a particular payment multiple times due to retries. JunoDB’s high availability makes it an ideal data store to keep track of processing details without overloading the main database. 3 - CountersLet’s say you’ve certain resources that aren’t available for some reason or they have an access limit to their usage. For example, these resources can be database connections, API rate limits, or user authentication attempts. You can use JunoDB to store counters for these resources and track whether their usage exceeds the threshold. 4 - Latency BridgingAs we discussed earlier, JunoDB provides fast inter-cluster replication. This can help you deal with slow replication in a more traditional setup. For example, in PayPal’s case, they run Oracle in Active-Active mode, but the replication usually isn’t as fast as they would like for their requirement. It means there are chances of inconsistent reads if records written in one data center are not replicated in the second data center and the first data center goes down. JunoDB can help bridge the latency where you can write to Data Center A (both Oracle and JunoDB) and even if it goes down, you can read the updates consistently from the JunoDB instance in Data Center B. See the below diagram for a better understanding of this concept.
ConclusionJunoDB is a distributed key-value store playing a crucial role in various PayPal applications. It provides efficient data storage for fast access to reduce the load on costly database solutions. While doing so, it also fulfills critical requirements such as scalability, high availability with performance, consistency, and security. Due to its advantages, PayPal has started using JunoDB in multiple use cases and patterns. For us, it provides a great opportunity to learn about an exciting new database system. References: © 2024 ByteByteGo
|

by "ByteByteGo" <bytebytego@substack.com> - 11:36 - 16 Apr 2024