- Mailing Lists
- in
- How Slack Supports Billions of Daily Messages
Archives
- By thread 5369
-
By date
- June 2021 10
- July 2021 6
- August 2021 20
- September 2021 21
- October 2021 48
- November 2021 40
- December 2021 23
- January 2022 46
- February 2022 80
- March 2022 109
- April 2022 100
- May 2022 97
- June 2022 105
- July 2022 82
- August 2022 95
- September 2022 103
- October 2022 117
- November 2022 115
- December 2022 102
- January 2023 88
- February 2023 90
- March 2023 116
- April 2023 97
- May 2023 159
- June 2023 145
- July 2023 120
- August 2023 90
- September 2023 102
- October 2023 106
- November 2023 100
- December 2023 74
- January 2024 75
- February 2024 75
- March 2024 78
- April 2024 74
- May 2024 108
- June 2024 98
- July 2024 116
- August 2024 134
- September 2024 130
- October 2024 141
- November 2024 171
- December 2024 115
- January 2025 216
- February 2025 140
- March 2025 220
- April 2025 233
- May 2025 239
- June 2025 303
- July 2025 182
How Slack Supports Billions of Daily Messages
How Slack Supports Billions of Daily Messages
Generate your MCP server with Speakeasy (Sponsored)
Like it or not, your API has a new user: AI agents. Make accessing your API services easy for them with an MCP (Model Context Protocol) server. Speakeasy uses your OpenAPI spec to generate an MCP server with tools for all your API operations to make building agentic workflows easy. Once you've generated your server, use the Speakeasy platform to develop evals, prompts and custom toolsets to take your AI developer platform to the next level. Disclaimer: The details in this post have been derived from the articles/videos shared online by the Slack engineering team. All credit for the technical details goes to the Slack Engineering Team. The links to the original articles and videos are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them. Most people think of Slack as a messaging app. It is technically accurate, but from a systems perspective, it's more like a real-time, multiplayer collaboration platform with millions of concurrent users, thousands of messages per second, and an architecture that evolved under some unusual constraints. At peak weekday hours, Slack maintains over five million simultaneous WebSocket sessions. That’s not just a metric, but a serious architectural challenge. Each session represents a live, long-running connection, often pushing out typing indicators, presence updates, and messages in milliseconds. Delivering this kind of interactivity on a global scale is hard. Doing it reliably with high performance is even harder. One interesting trivia is that the team that built Slack was originally building a video game named Glitch: a browser-based MMORPG. While Glitch had a small but passionate audience, it struggled to become financially sustainable. During the development of Glitch, the team created an internal communication tool that would later become Slack. When Glitch shut down, the team recognized the potential of the internal communication tool and began to develop it into a bigger product for business use. The backend for this internal tool became the skeleton of what would become Slack.
This inheritance shaped Slack’s architecture in two key ways:
This article explores how Slack’s architecture evolved to meet the demands of a system that makes real-time collaboration possible across organizations of 100,000+ people. Real-Time Code Reviews Powered by AI (Sponsored)
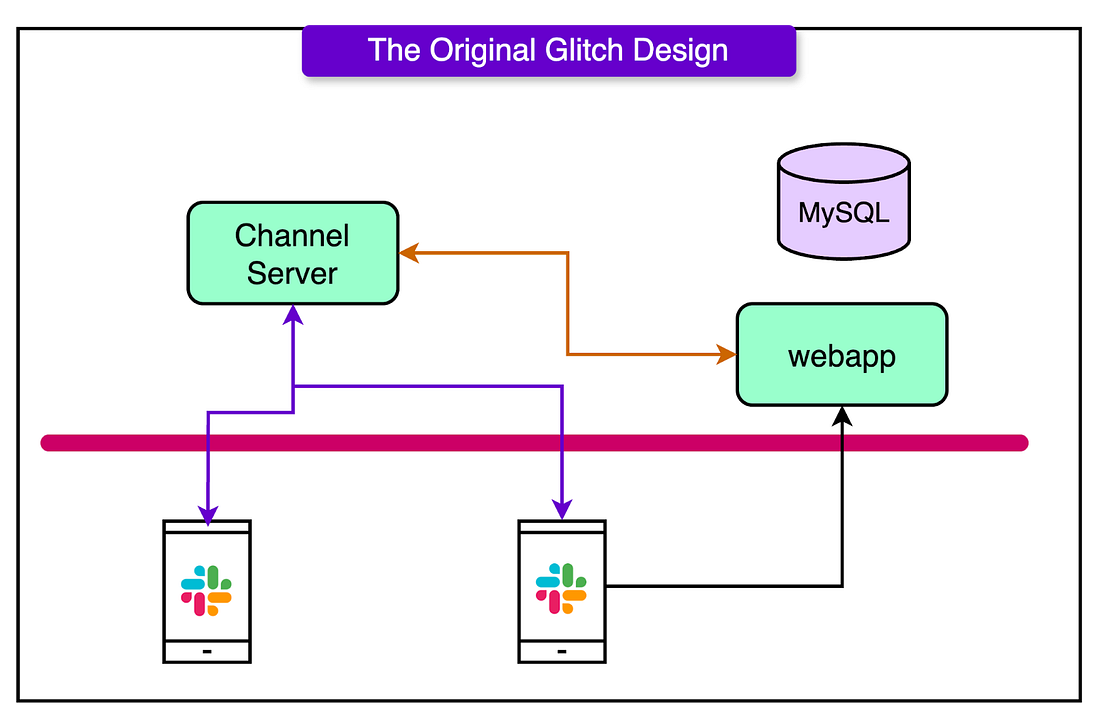
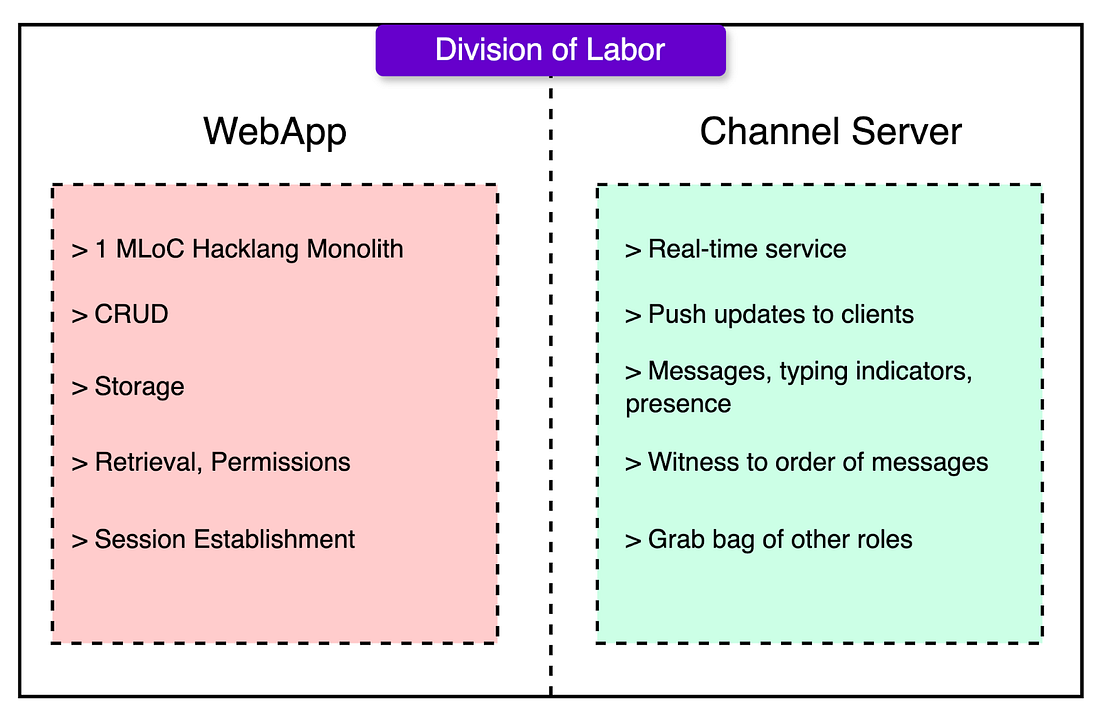
Slack made real-time collaboration seamless for teams. CodeRabbit brings that same spirit to code reviews. It analyzes every PR using context-aware AI that understands your codebase suggesting changes, catching bugs and even asking questions when something looks off. Perfect for fast-moving teams who want quality code reviews without slowing down. Integrated with GitHub, GitLab and it's like a senior engineer reviewing with you on every commit. Free for Open-source. Review Smarter with CodeRabbit Initial ArchitectureSlack’s early architecture was a traditional monolithic backend fused with a purpose-built, real-time message delivery system. The monolith, written in Hacklang, handled the application logic. Hacklang (Facebook’s typed dialect of PHP) offered a pragmatic path: move fast with a familiar scripting language, then gradually tighten things with types. For a product iterating quickly, that balance paid off. Slack’s backend handled everything from file permissions to session management to API endpoints. But the monolith didn’t touch messages in motion. That job belonged to a real-time message bus: the channel server, written in Java. The channel server pushed updates over long-lived WebSocket connections, broadcast messages to active clients, and arbitrated message order. When two users hit “send” at the same moment, it was the channel server that decided which message came first. Here’s how the division looked in terms of functionalities:
This split worked well when Slack served small teams and development moved fast. But over time, the costs surfaced:
The Core Abstraction: Persistent MessagingMessaging apps live or die by trust. When someone sends a message and sees it appear on screen, they expect it to stay there and to show up for everyone else. If that expectation breaks, the product loses credibility fast. In other words, persistence becomes a foundational feature. Slack’s design bakes this in from the start. Unlike Internet Relay Chat (IRC), where messages vanish the moment they scroll off-screen, Slack assumes every message matters, even the mundane ones. It doesn’t just aim to display messages in real-time. It aims to record them, index them, and replay them on demand. This shift from ephemeral to durable changes everything. IRC treats each message like a radio transmission, whereas Slack treats messages like emails. If the user missed something, they can always scroll up, search later, and re-read at a later date. This shift demands a system that guarantees:
Slack delivers that through what looks, at first glance, like a simple contract:
This is a textbook case of atomic broadcast. Atomic BroadcastAtomic broadcast is a classic problem in distributed systems. It's a formal model where multiple nodes (or users) receive the same messages in the same order, and every message comes from someone. It guarantees three core properties:
Slack implements a real-world approximation of atomic broadcast because it was essential for their functionality. Imagine a team seeing different sequences of edits, or comments that reference messages that “don’t exist” on someone else’s screen. But here’s the twist: in distributed systems, atomic broadcast is as hard as consensus. And consensus, under real-world failure modes, is provably impossible to guarantee. So Slack, like many production systems, takes the pragmatic path. It relaxes constraints, defers work, and recovers from inconsistency instead of trying to prevent it entirely. This tension between theoretical impossibility and practical necessity drives many of Slack’s architectural decisions. Old vs New Send FlowsIn real-time apps, low latency is a necessity. When a user hits “send,” the message should appear instantly. Anything slower breaks the illusion of conversation. But making that feel snappy while also guaranteeing that the message is stored, ordered, and replayable? That’s where things get messy. Slack’s original message send flow prioritized responsiveness. The architecture puts the channel server (the real-time message bus) at the front of the flow. A message went from the client straight to the channel server, which then:
This gave users lightning-fast feedback. However, it also introduced a dangerous window: the server might crash after confirming the message but before persisting it. To the sender, the message looked “sent.” To everyone else, especially after a recovery, it might be gone. This flow worked, but it carried risk:
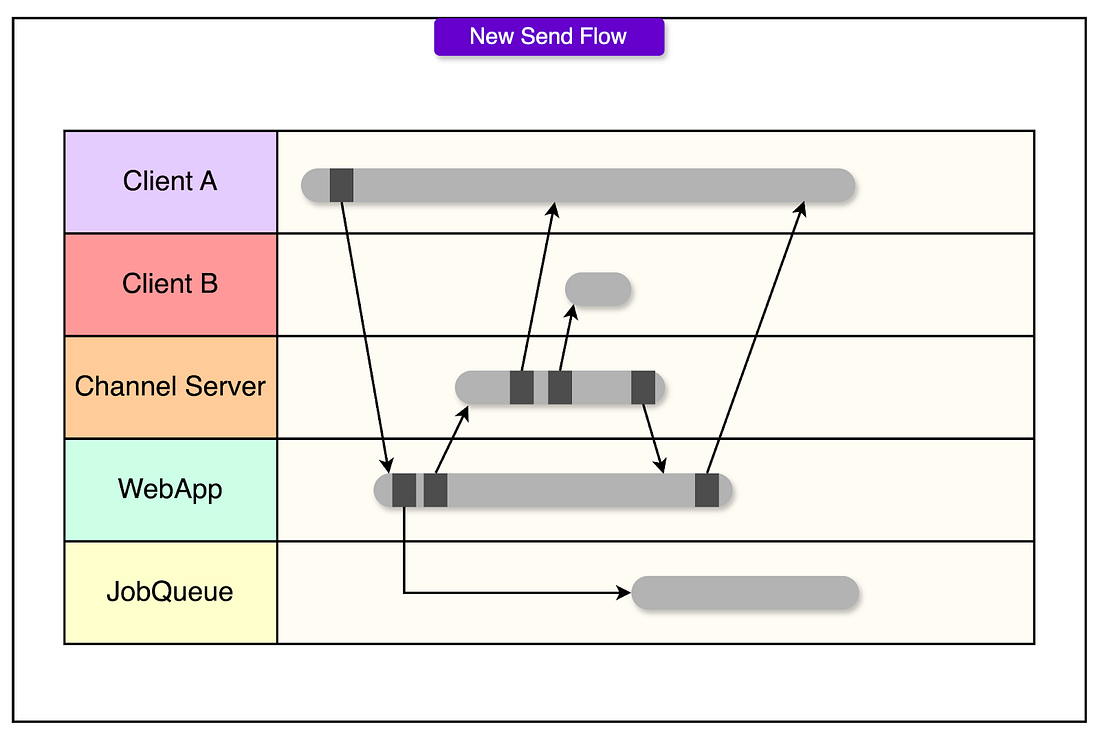
Slack patched around this with persistent buffers and retry loops. But the complexity was stacking up. The system was fast, but fragile. The Web App Takes the LeadAs Slack matured, and as outages and scale pushed the limits, the team reversed the flow. In the new send model, the web app comes first:
This change improves several things:
And one subtle benefit: the new flow doesn’t require a WebSocket connection to send a message. That’s a big deal for mobile clients responding to notifications, where setting up a full session just to reply was costly. The old system showed messages fast, but sometimes dropped them. The new one does more work up front, but makes a stronger promise in terms of persistence. Session Initialization and the Need for FlannelFor small teams, starting a Slack session looks simple. The client requests some data, connects to a WebSocket, and starts chatting. However, at enterprise scale, that “simple” startup becomes a serious architectural choke point. Originally, Slack used a method called RTM Start (Real-Time Messaging Start). When a client initiated a session, the web app assembled a giant JSON payload: user profiles, channel lists, membership maps, unread message counts, and a WebSocket URL. This was meant to be a keyframe: a complete snapshot of the team’s state, so the client could start cold and stay in sync via real-time deltas.
It worked until teams got big.
And it got worse:
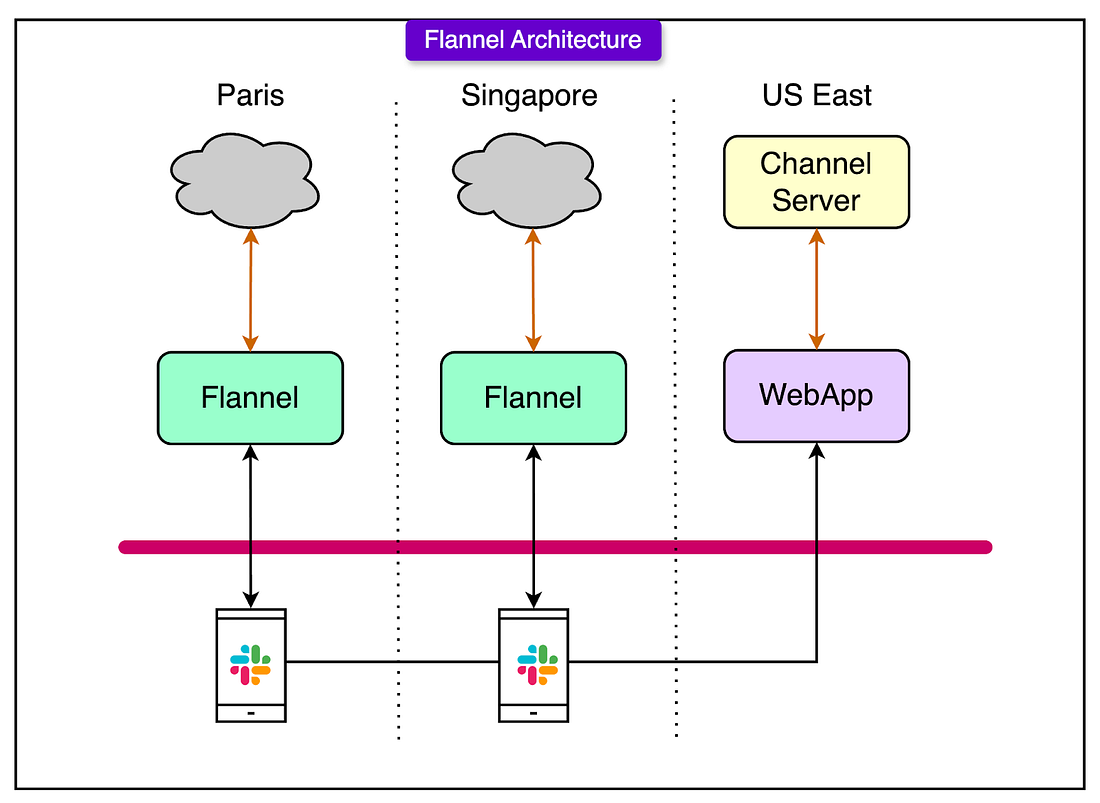
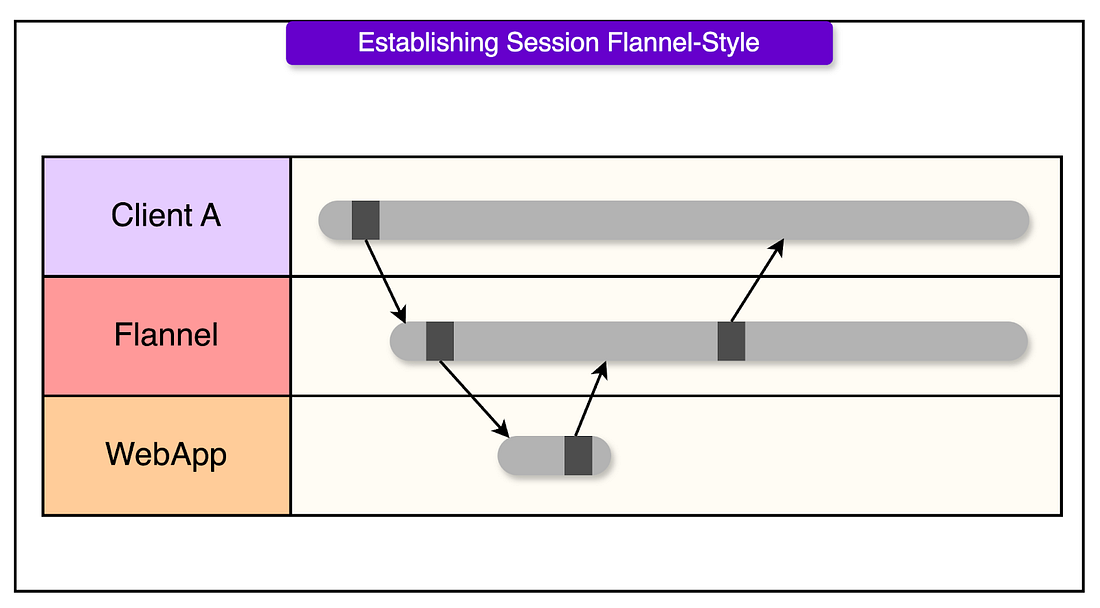
This wasn’t just slow. It was a vector for cascading failure. One bad deploy or dropped connection could take out Slack’s control plane under its load. Flannel: Cache the Cold StartTo fix this, Slack introduced Flannel, a purpose-built microservice that acts as a stateful, geo-distributed cache for session bootstrapping. Instead of rebuilding a fresh session snapshot for every client on demand, Flannel does a couple of things differently:
Here’s what changes in the flow:
This flips the cost model from compute-heavy startup to cache-heavy reuse. While it’s tempting to think that Flannel adds complexity. But Slack found that at scale, complexity that’s predictable and bounded is better than simplicity that breaks under pressure. Scaling Considerations and Trade-offsEvery system seems to work on the whiteboard. The real test comes when it’s live, overloaded, and something fails. At Slack’s scale, maintaining reliable real-time messaging isn’t just about handling more messages per second. It’s also about absorbing failure without breaking user expectations. One of the most visible symptoms at scale is message duplication. Sometimes a user sees their message posted twice. It’s not random. It’s a side effect of client retries. Here’s how it happens:
To survive this, Slack leans on idempotency. Each message includes a client-generated ID or salt. When the server sees the same message ID again, it knows it’s not a new send. This doesn’t eliminate all duplication, especially across devices, but it contains the damage. On the backend, retries and failures get more serious. A message might:
The system has to detect and recover from all of these without losing messages, breaking order guarantees, and flooding the user with confusing errors. This is where queueing architecture matters. Slack uses Kafka for durable message queuing and Redis for in-flight, fast-access job data. Kafka acts as the system’s ledger and Redis provides short-term memory. This separation balances:
ConclusionSlack’s architecture isn’t simple, and that’s by design. The system embraces complexity in the places where precision matters most: real-time messaging, session consistency, and user trust. These are the end-to-end paths where failure is visible, consequences are immediate, and user perception can shift in a heartbeat. The architecture reflects a principle that shows up in high-performing systems again and again: push complexity to the edge, keep the core fast and clear. Channel servers, Flannel caches, and job queues each exist to protect a smooth user experience from the messiness of distributed systems, partial failures, and global scale. At the same time, the parts of the system that don’t need complexity, like storage coordination or REST API responses, stay lean and conventional. Ultimately, no architecture stands still. Every scaling milestone, every user complaint, every edge case pushes the system to adapt. Slack’s evolution from monolith-plus-bus to globally distributed microservices wasn’t planned in a vacuum. It came from running into real limits, then designing around them. The lesson isn’t to copy Slack’s architecture. It’s to respect the trade-offs it reveals:
References: SPONSOR USGet your product in front of more than 1,000,000 tech professionals. Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases. Space Fills Up Fast - Reserve Today Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com. © 2025 ByteByteGo
|

by "ByteByteGo" <bytebytego@substack.com> - 11:38 - 13 May 2025