- Mailing Lists
- in
- How Stripe Scaled to 5 Million Database Queries Per Second
Archives
- By thread 5189
-
By date
- June 2021 10
- July 2021 6
- August 2021 20
- September 2021 21
- October 2021 48
- November 2021 40
- December 2021 23
- January 2022 46
- February 2022 80
- March 2022 109
- April 2022 100
- May 2022 97
- June 2022 105
- July 2022 82
- August 2022 95
- September 2022 103
- October 2022 117
- November 2022 115
- December 2022 102
- January 2023 88
- February 2023 90
- March 2023 116
- April 2023 97
- May 2023 159
- June 2023 145
- July 2023 120
- August 2023 90
- September 2023 102
- October 2023 106
- November 2023 100
- December 2023 74
- January 2024 75
- February 2024 75
- March 2024 78
- April 2024 74
- May 2024 108
- June 2024 98
- July 2024 116
- August 2024 134
- September 2024 130
- October 2024 141
- November 2024 171
- December 2024 115
- January 2025 216
- February 2025 140
- March 2025 220
- April 2025 233
- May 2025 239
- June 2025 303
How can leaders effectively scale generative AI?
Your company needs a superpower. Do you have what it takes to build one?
How Stripe Scaled to 5 Million Database Queries Per Second
How Stripe Scaled to 5 Million Database Queries Per Second
WorkOS: modern identity platform for B2B SaaS (Sponsored)
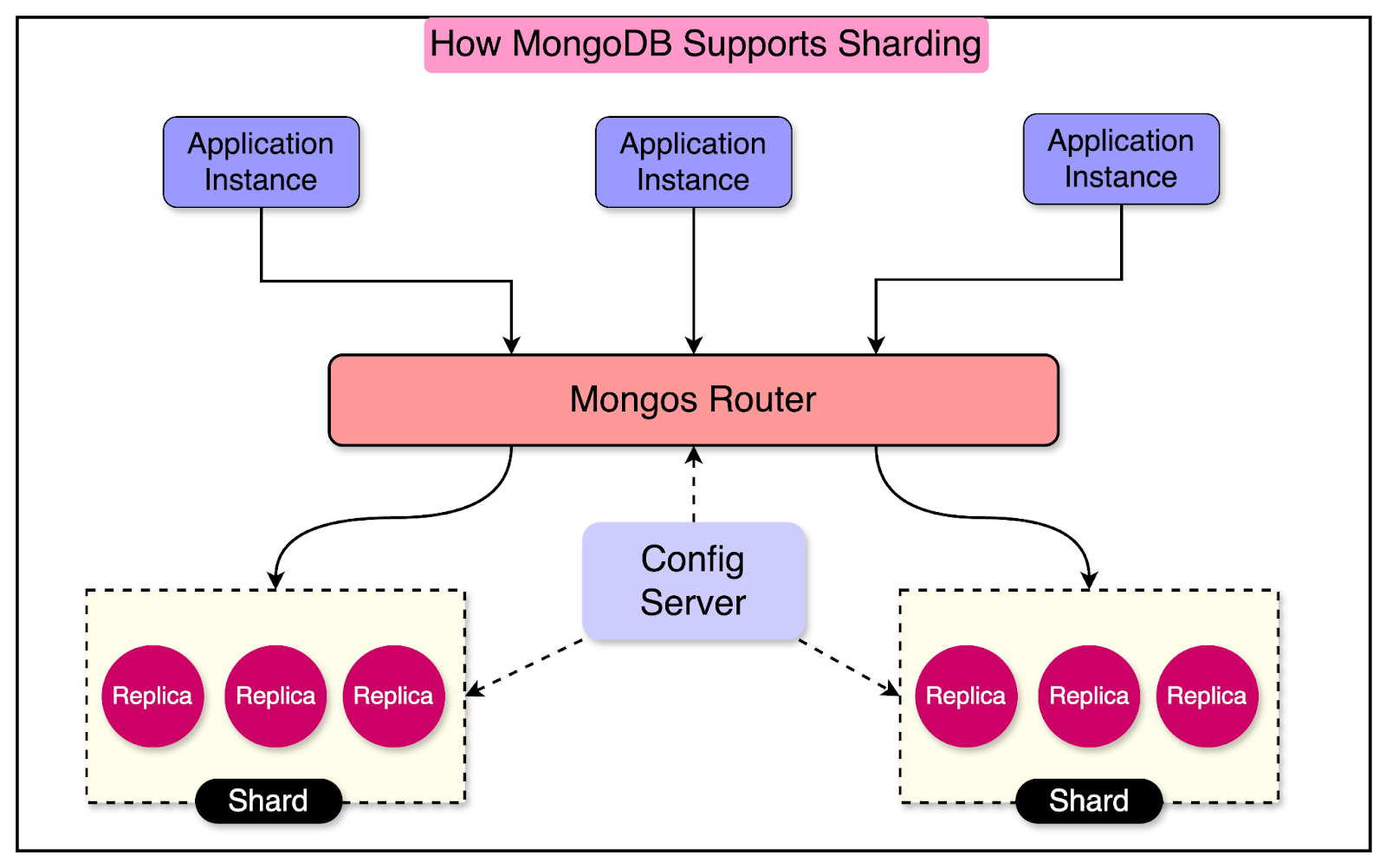
Start selling to enterprises with just a few lines of code. → WorkOS provides a complete User Management solution along with SSO, SCIM, RBAC, & FGA. → Unlike other auth providers that rely on user-centric models, WorkOS is designed for B2B SaaS with an org modeling approach. → The APIs are flexible, easy-to-use, and modular. Pick and choose what you need and integrate in minutes. → Best of all, User Management is free up to 1 million MAUs and comes standard with RBAC, bot protection, impersonation, MFA, & more. Disclaimer: The details in this post have been derived from the Stripe Engineering Blog. All credit for the architectural details goes to Stripe’s engineering team. The links to the original articles are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them. As of 2023, only 19 countries had a GDP surpassing $1 trillion. Also, in 2023, Stripe alone processed $1 trillion in total payment value. To make the achievement even more remarkable, they managed these numbers while supporting 5 million database queries per second at five-nines (99.999%) of availability. What was behind the success of Stripe’s infrastructure? The secret lies in the horizontal scaling capabilities of their database. Stripe’s database infrastructure team built an internal database-as-a-service (DBaaS) offering called DocDB. It was created as an extension of MongoDB’s community edition because of MongoDB’s flexibility and ability to handle a massive volume of real-time data at scale. In this post, we’ll explore how DocDB works and the various features it provides that allow Stripe to operate at such an incredible scale. Why the Need for DocDB?The first question while looking at DocDB is this: what forced Stripe to build a DBaaS offering? Stripe launched in 2011. At the time, they chose MongoDB as the online database because its schema-less approach made it more productive for developers than standard relational databases. MongoDB also supports horizontal scaling through its robust sharding architecture, which is shown in the diagram below:
However, to unlock the best developer experience, Stripe needed a database service that could work like a product for the development teams. MongoDB Atlas didn’t exist in 2011 and they couldn’t find an off-the-shelf DBaaS that met key requirements such as:
The solution was to build DocDB with MongoDB as the underlying storage engine. The DocDB deployment was also highly customized to provide low latency and diverse access. Some interesting stats related to DocDB are as follows:
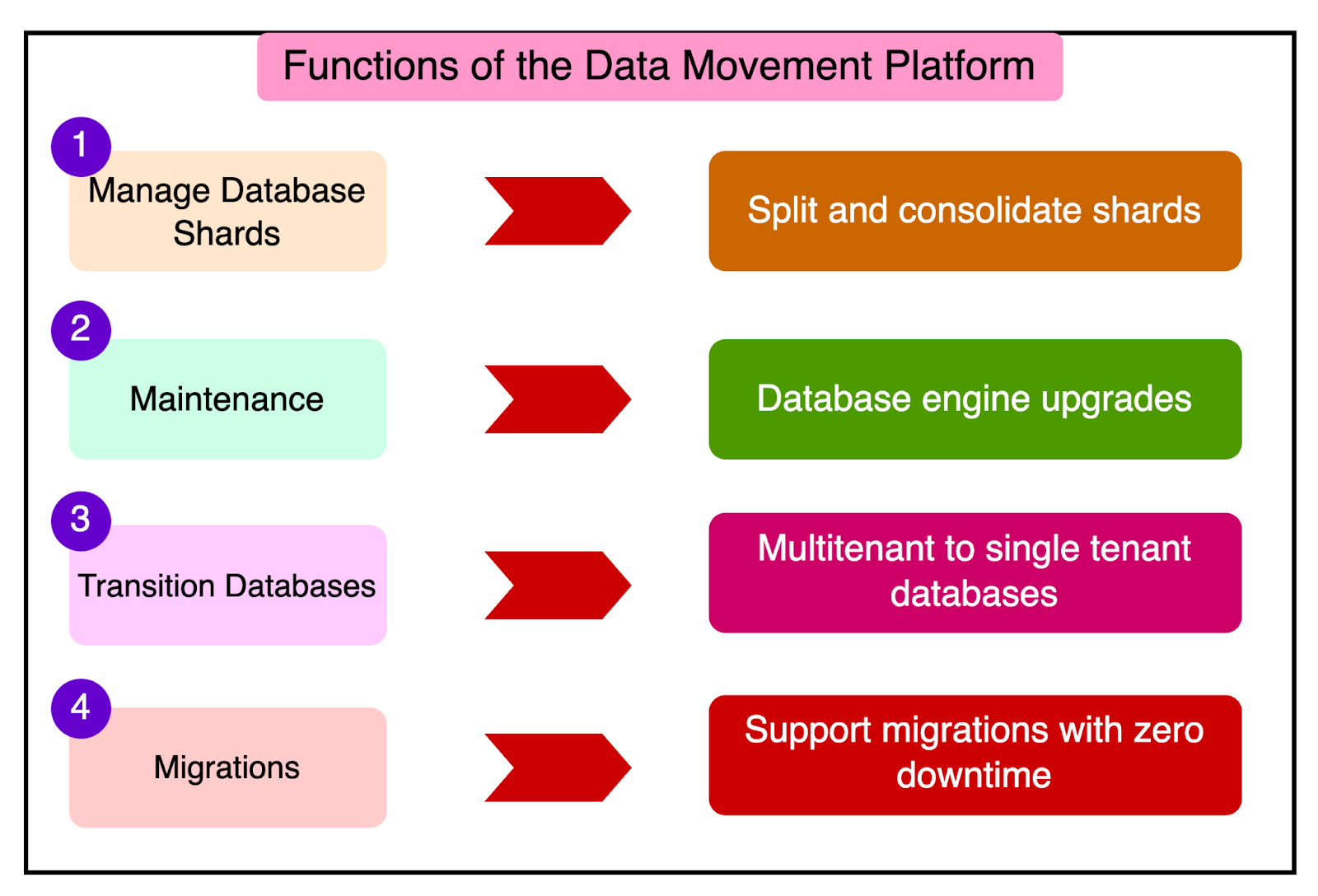
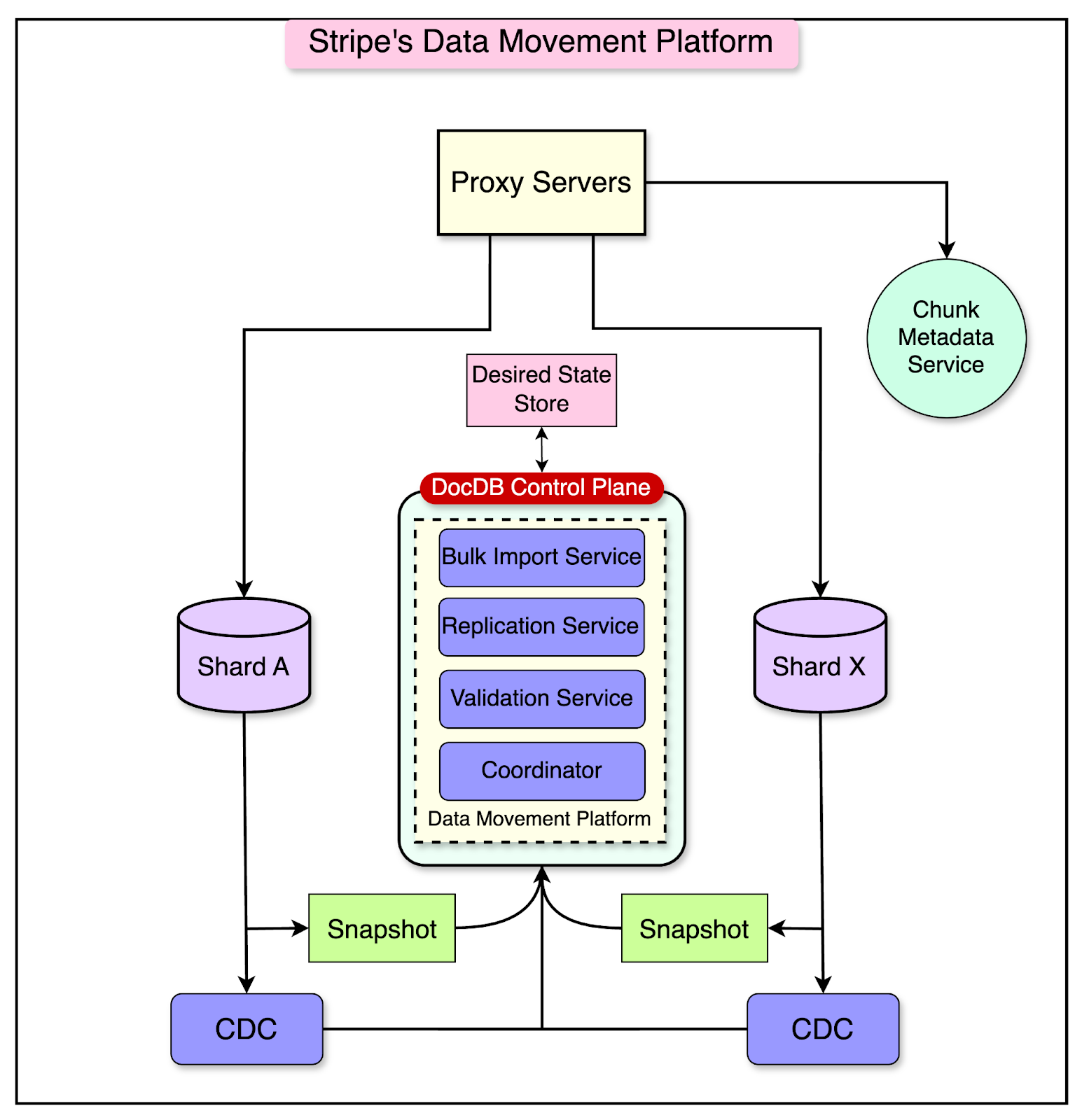
At the heart of DocDB is the Data Movement Platform. It was originally built as a horizontal scaling solution to overcome the vertical scaling limits of MongoDB. The Data Movement Platform made it possible to transition from running a small number of database shards (each storing tens of terabytes of data) to thousands of database shards (each with a fraction of the original data).
The platform performs multiple functions such as:
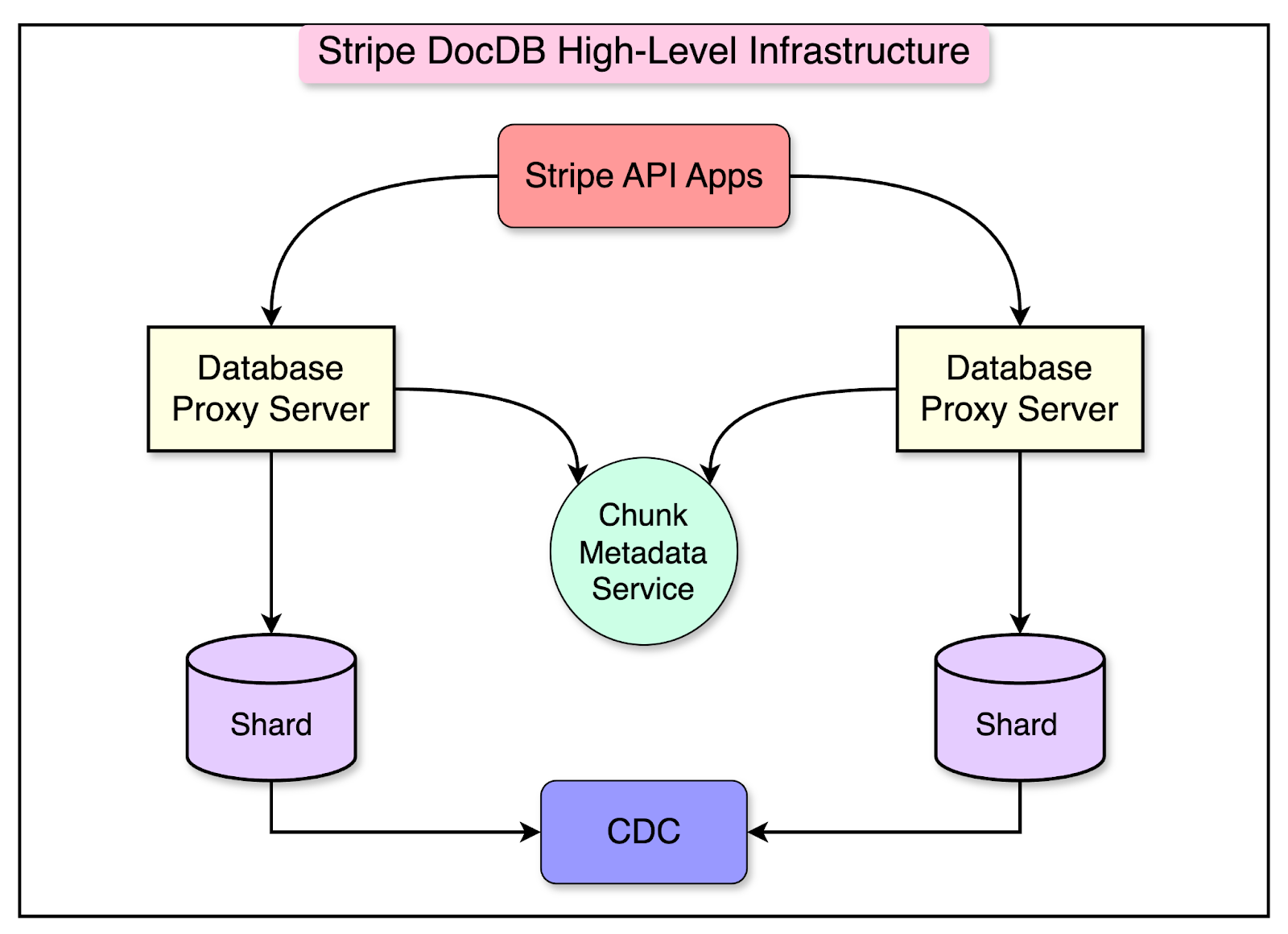
For reference, bin packing is an optimization problem where the goal is to pack a set of objects (in this case, data) into a minimum number of bins (database shards) of a fixed capacity. The objective is to minimize the number of bins used while ensuring that the total size or weight of the objects in each bin does not exceed its capacity. How Applications Access DocDB?DocDB leverages sharding to achieve horizontal scalability for its database infrastructure. With thousands of database shards distributed across Stripe’s product applications, sharding enables efficient data distribution and parallel processing. However, the use of database sharding introduces a challenge for applications when determining the appropriate destination shard for their queries. To address this issue, Stripe’s database infrastructure team developed a fleet of database proxy servers implemented in Golang. These proxy servers handle the task of routing queries to the correct shard. The diagram shows DocDB’s high-level infrastructure overview.
When an application sends a query to a database proxy server, it performs the following steps:
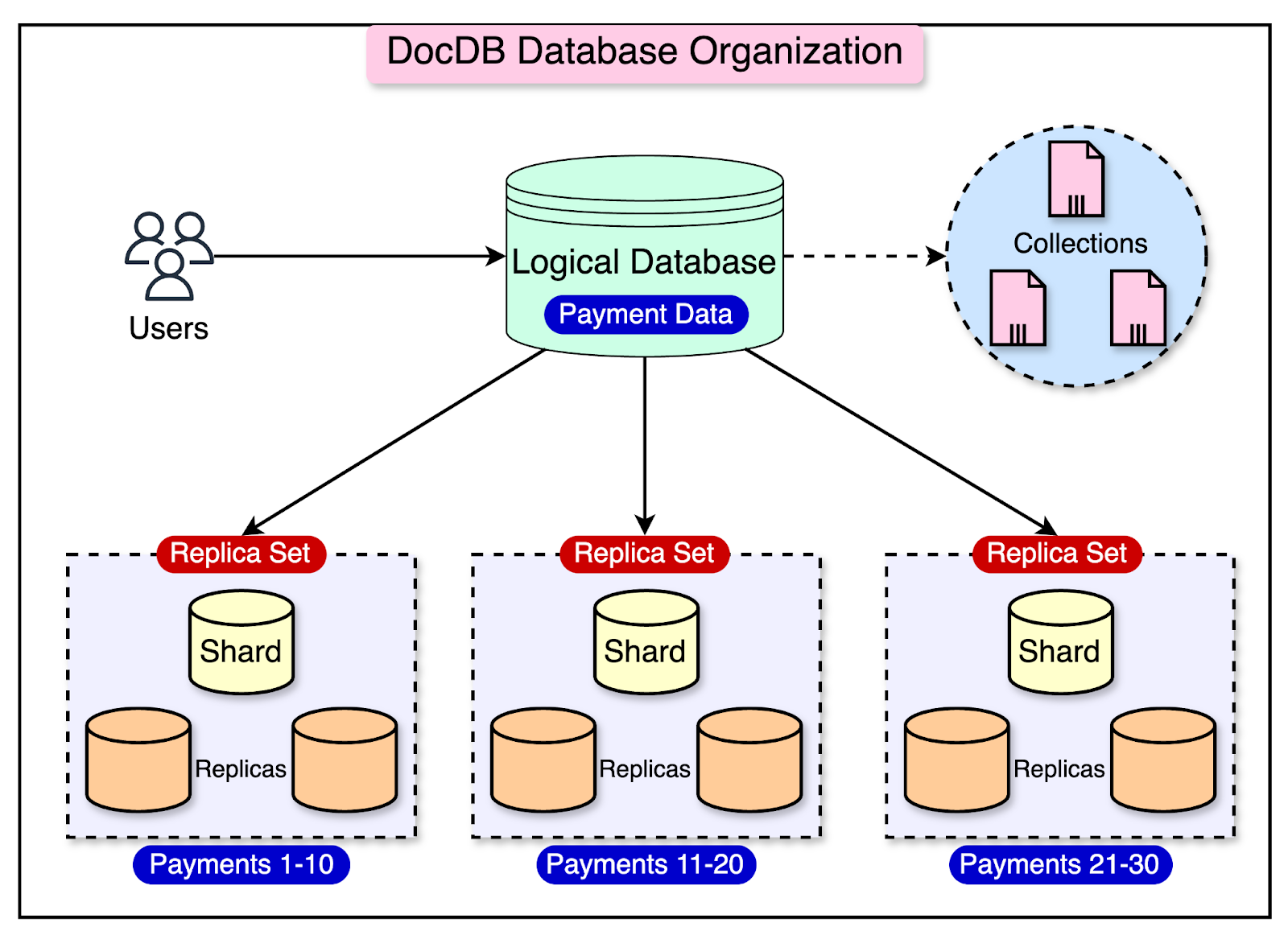
But how do database proxy servers make the routing decisions? The database proxy servers rely on the chunk metadata service to make routing decisions. A chunk represents a small subset of data within a larger collection. Each shard contains a fraction of the total data, and these fractions are referred to as chunks. For example, consider that Stripe has a large collection called “Transactions” that contains millions of documents representing financial transactions. To scale this collection horizontally, they might split the data into chunks based on a sharding key, such as customer ID or the transaction timestamp. Each chunk would then be assigned to a specific database shard. The chunk metadata service manages the mapping between these chunks and their corresponding shards. It keeps track of which chunk resides on which shard, allowing the proxy servers to route queries and requests to the appropriate shard. Data Organization in DocDBAt Stripe, product teams use an in-house tool called the document database control plane to create and manage their databases. When a team provisions a new database using this tool, they are creating a “logical database.” A logical database is like a virtual container holding one or more data collections known as DocDB collections. Each DocDB collection contains related documents that serve a specific purpose for the product team. Even though a logical database appears as a single entity to the product team, the data within the collections is spread across multiple physical databases behind the scenes. These physical databases are the actual databases running on Stripe’s infrastructure. The diagram below shows this arrangement:
Each physical database contains a small portion (or “chunk”) of the data from the DocDB collection and is deployed on a shard. The shard consists of a primary database node and several secondary database nodes. These nodes work together as a replica set. The primary node handles all the write operations and replicates the data to the secondary nodes. If the primary node fails, one of the secondary nodes automatically takes over as the new primary, ensuring continuous operation and availability. The diagram below shows a different representation of the database hierarchy
Latest articlesIf you’re not a paid subscriber, here’s what you missed. To receive all the full articles and support ByteByteGo, consider subscribing: The Data Movement PlatformWhat’s the most important ability required to build a DBaaS platform that is horizontally scalable and highly elastic? It’s the ability to migrate data across database shards with zero downtime and no impact on the client. Stripe achieved this ability with their Data Movement Platform. The platform had a few important requirements such as:
The diagram below shows the architecture of the Data Movement Platform:
The heart of the platform is the Coordinator component, which is responsible for orchestrating the various steps involved in online data migrations. Step 1: Chunk Migration RegistrationThe first step is registering a request to migrate database chunks from source shards to target shards. Once the request is created, indexes are built on the target shards. An index is a data structure that improves the speed of data retrieval operations on a database table or collection. Building the index first on the target shard has some advantages:50
Step 2: Bulk Data ImportThe next step involves using a snapshot of the chunks on the source shard at a specific point in time. This snapshot is used to load the data onto one or more target database shards. The service performing the bulk data import accepts data filters, allowing for the selective import of chunks that satisfy the specified filtering criteria. This step initially appeared straightforward. However, Stripe’s infra team encountered throughput limitations when they tried to bulk load data onto a DocDB shard. Efforts to address the issue by batching writes and adjusting DocDB engine parameters were not successful. A significant breakthrough came when the team explored methods to optimize the insertion order by using the fact that DocDB organizes its data using a B-tree data structure. By sorting the data based on the most common index attributes in the collections and inserting it in sorted order, the write proximity was enhanced, resulting in a 10X boost in write throughput. Step 3: Async ReplicationAfter the bulk data import step is completed, the next step ensures that any subsequent writes or mutations that occur on the source shard after time T are replicated to the target shard. This is where async replication comes into play. Stripe’s async replication systems rely on the Change Data Capture (CDC) mechanism to capture and replicate the mutations from the source shards to the target shards. Here’s how it works:
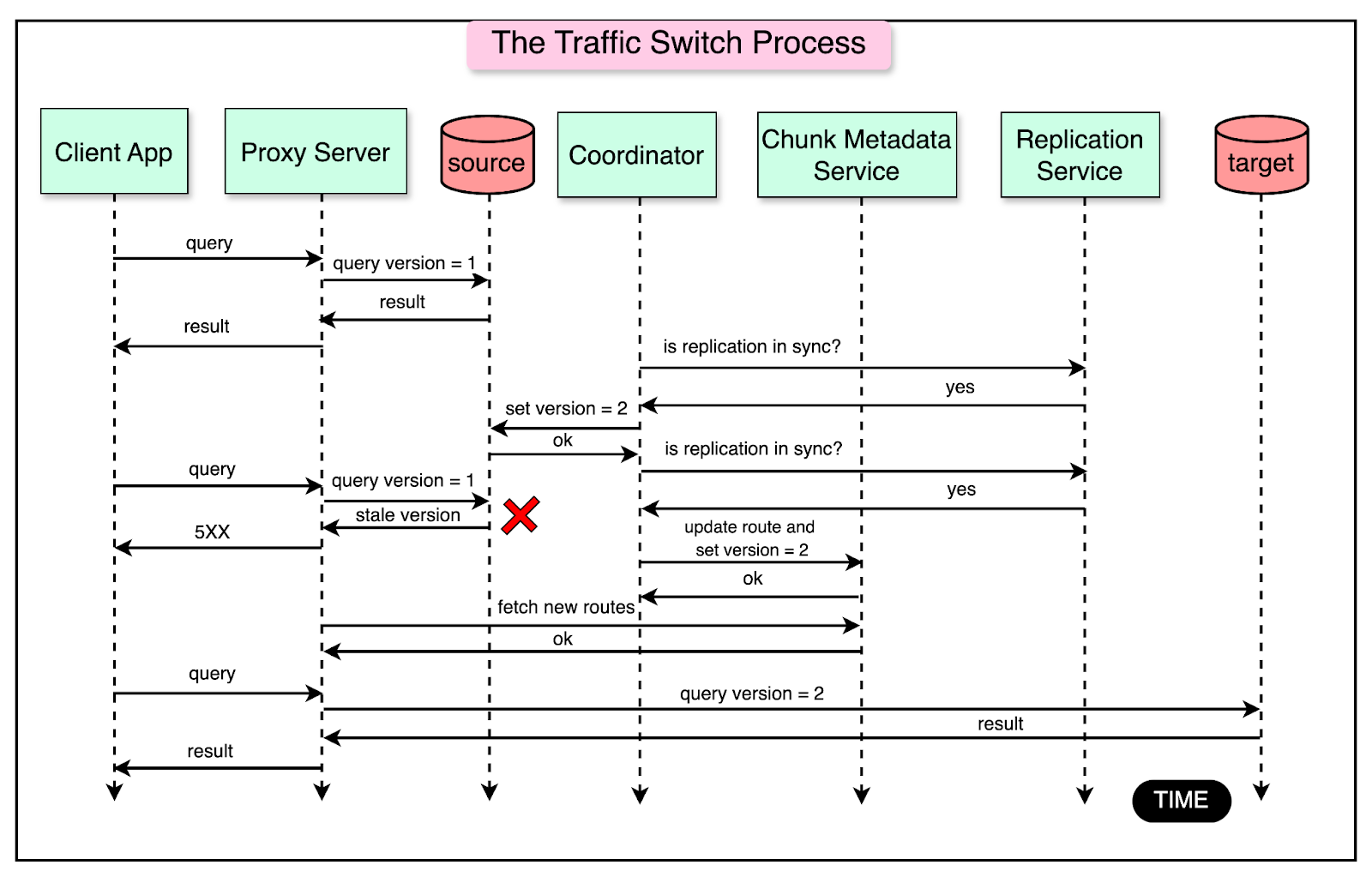
Step 4: Correctness CheckAfter the replication sync between the source and target shard, the Coordinator conducts a comprehensive check for data completeness and correctness. This is done by comparing point-in-time snapshots. It was a deliberate design choice to avoid impacting the shard’s throughput. Step 5: Traffic SwitchThe next step is to switch the traffic of incoming requests from the source shard to the target shard. The Coordinator orchestrates the traffic switch after the data is imported to the target shard and the mutations are replicated. The process consists of three steps:
The traffic switch protocol uses the concept of versioned gating. To support this, the infra team added a custom patch to MongoDB that allows a shard to enforce a version number check before serving a request. Each proxy server annotates requests to the DocDB shard with a version token number. The shard first checks the version token number and serves the request only if the token number is newer than the earlier one. The diagram below shows the detailed process flow for the traffic switch protocol:
Here’s how the process works:
The entire traffic switch protocol takes less than two seconds to execute. Any failed reads and writes to the source shard succeed on retries that go to the target shard. Step 6: Chunk Migration DeregistrationFinally, the migration process is concluded by marking the migration as complete in the chunk metadata service. Also, the chunk data is dropped from the source shard to reclaim the resources. ConclusionStripe’s custom-built database-as-a-service, DocDb, and its Data Movement Platform have been instrumental in achieving 99.999% uptime while enabling zero-downtime data migrations. Some key takeaways are as follows:
References: SPONSOR USGet your product in front of more than 1,000,000 tech professionals. Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases. Space Fills Up Fast - Reserve Today Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing hi@bytebytego.com © 2024 ByteByteGo
|

by "ByteByteGo" <bytebytego@substack.com> - 11:35 - 23 Jul 2024