- Mailing Lists
- in
- How Tinder Recommends To 75 Million Users with Geosharding
Archives
- By thread 5353
-
By date
- June 2021 10
- July 2021 6
- August 2021 20
- September 2021 21
- October 2021 48
- November 2021 40
- December 2021 23
- January 2022 46
- February 2022 80
- March 2022 109
- April 2022 100
- May 2022 97
- June 2022 105
- July 2022 82
- August 2022 95
- September 2022 103
- October 2022 117
- November 2022 115
- December 2022 102
- January 2023 88
- February 2023 90
- March 2023 116
- April 2023 97
- May 2023 159
- June 2023 145
- July 2023 120
- August 2023 90
- September 2023 102
- October 2023 106
- November 2023 100
- December 2023 74
- January 2024 75
- February 2024 75
- March 2024 78
- April 2024 74
- May 2024 108
- June 2024 98
- July 2024 116
- August 2024 134
- September 2024 130
- October 2024 141
- November 2024 171
- December 2024 115
- January 2025 216
- February 2025 140
- March 2025 220
- April 2025 233
- May 2025 239
- June 2025 303
- July 2025 166
How Tinder Recommends To 75 Million Users with Geosharding
How Tinder Recommends To 75 Million Users with Geosharding
Building AI Apps on Postgres? Start with pgai (Sponsored)
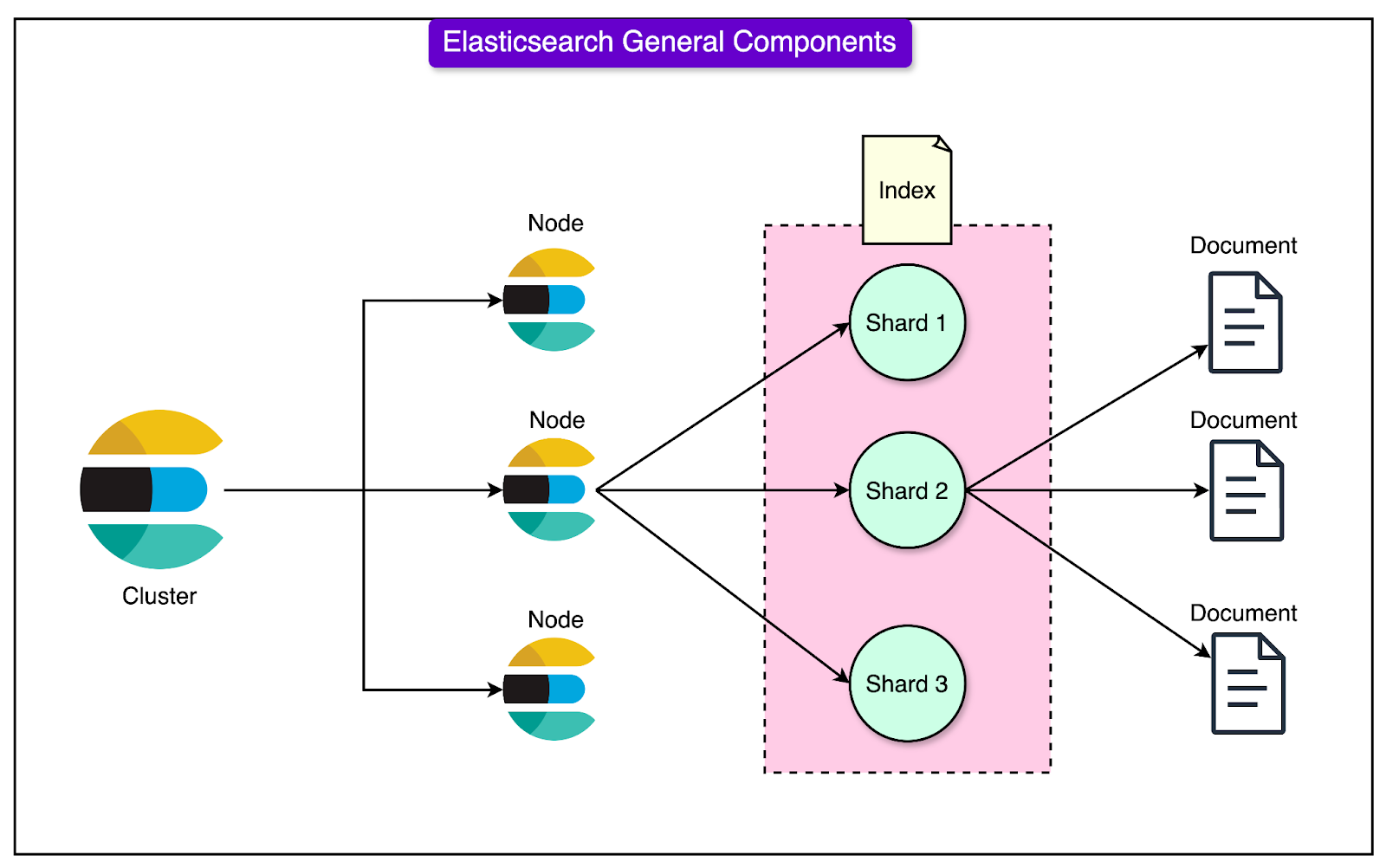
pgai is a PostgreSQL extension that brings more AI workflows to PostgreSQL, like embedding creation and model completion. pgai empowers developers with AI superpowers, making it easier to build search and retrieval-augmented generation (RAG) applications. Automates embedding creation with pgai Vectorizer, keeping your embeddings up to date as your data changes—no manual syncing required. Available free on GitHub or fully managed in Timescale Cloud. Disclaimer: The details in this post have been derived from the Tinder Technical Blog. All credit for the technical details goes to the Tinder engineering team. The links to the original articles are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them. Tinder is a dating app that handles billions of swipes daily, matching over 75 million users worldwide. Their recommendation engine must deliver matches with speed and precision. However, managing a global user base and ensuring seamless performance isn’t easy, especially when searches involve massive amounts of data spread across different regions. To overcome the challenge, Tinder adopted Geosharding: a method of dividing user data into geographically bound "shards." This approach enabled the recommendation engine to focus searches only on relevant data, dramatically improving performance and scalability. The system now handles 20 times more computations than before while maintaining low latency and delivering matches faster than ever. In this post, we’ll explore how Geosharding works, the architecture behind it, and the techniques Tinder uses to ensure data consistency. The Initial Single-Index ApproachWhen Tinder started using Elasticsearch to manage its recommendation system, it stored all user data in a single "index".
Think of this index as one massive database holding information about every Tinder user worldwide. While this worked fine when the platform was smaller, it caused significant problems as Tinder grew. Some major problems were as follows:
The MOST Hands-On Training on AI Tools you’ll ever attend, for free (Sponsored)The biggest MYTH about AI is that it is for people in tech. Or people who can code. In reality, AI can be game-changing for you whether you are a curious 11 year old kid wanting to research or a 50 year old professional who is willing to stay relevant in 2024. Join the 3 hour AI Tools Training (usually $399) but free for the first 100 readers.
By the way, here’s sneak peek into what’s inside the workshop:
And a lot more that you’re not ready for, just 3 hours! 🤯 1.5 Million people are already RAVING about this hands-on Training on AI Tools. Don’t take our word for it? Attend for yourself and see. (first 100 people get it for free + $500 bonus) 🎁 The Geosharding SolutionGeosharding was the method Tinder adopted to address the inefficiencies of using a single large index for its recommendation system. The idea was to divide the global user base into smaller, localized groups, or "shards," based on location. Each shard contains data for users in a specific region, allowing the system to focus its searches only on the most relevant data for a particular query. How Geosharding Works?Imagine Tinder’s user base as a map of the world. Instead of putting all user data into one massive database (like a single, global shelf), the map is divided into smaller sections or shards. Each shard corresponds to a geographic region. For example:
By organizing users this way, the system can search only the shard that matches a user’s location, avoiding the need to sift through irrelevant data. And all of this was made possible through Geosharding. Geosharding improves query performance in the following ways:
Optimizing Shard SizeDespite the obvious benefits of sharding, finding the "right" size for a shard was crucial for maintaining system efficiency. Several factors were considered in determining this balance:
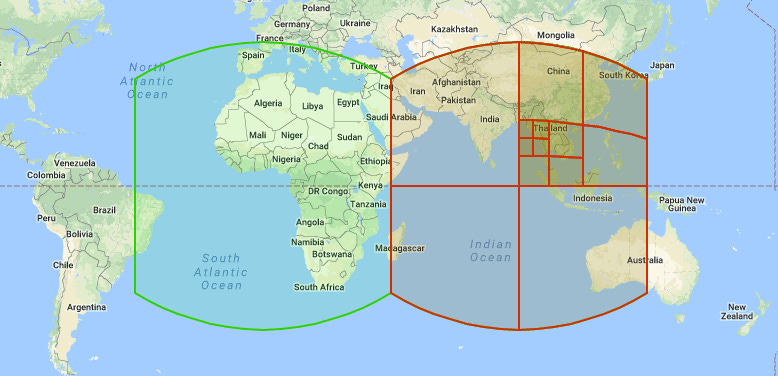
Algorithm and Tools Used For GeoshardingTo implement Geosharding effectively, Tinder needed tools and algorithms that could efficiently divide the world into geographic shards while ensuring these shards were balanced in terms of user activity. Two key components made this possible: Google’s S2 Library and a container-based load balancing method. Let’s look at them both in more detail. The S2 Library: Mapping the Globe Into CellsThe S2 Library is a powerful tool developed by Google for spatial mapping. It divides the Earth’s surface into a hierarchical system of cells, which are smaller regions used for geographic calculations.
Here’s how it works and why it’s ideal for Geosharding:
The main advantages of S2 for Tinder’s use case were as follows:
Load Balancing: Evenly Distributing Users Across GeoshardsOnce the world was divided into S2 cells, the next challenge was to balance the "load" across these cells. Load refers to the activity or number of users within each shard. Without proper balancing, some shards could become "hot" (overloaded with users), while others remained underutilized. To solve this, Tinder used a container-based load-balancing approach which involved the following aspects:
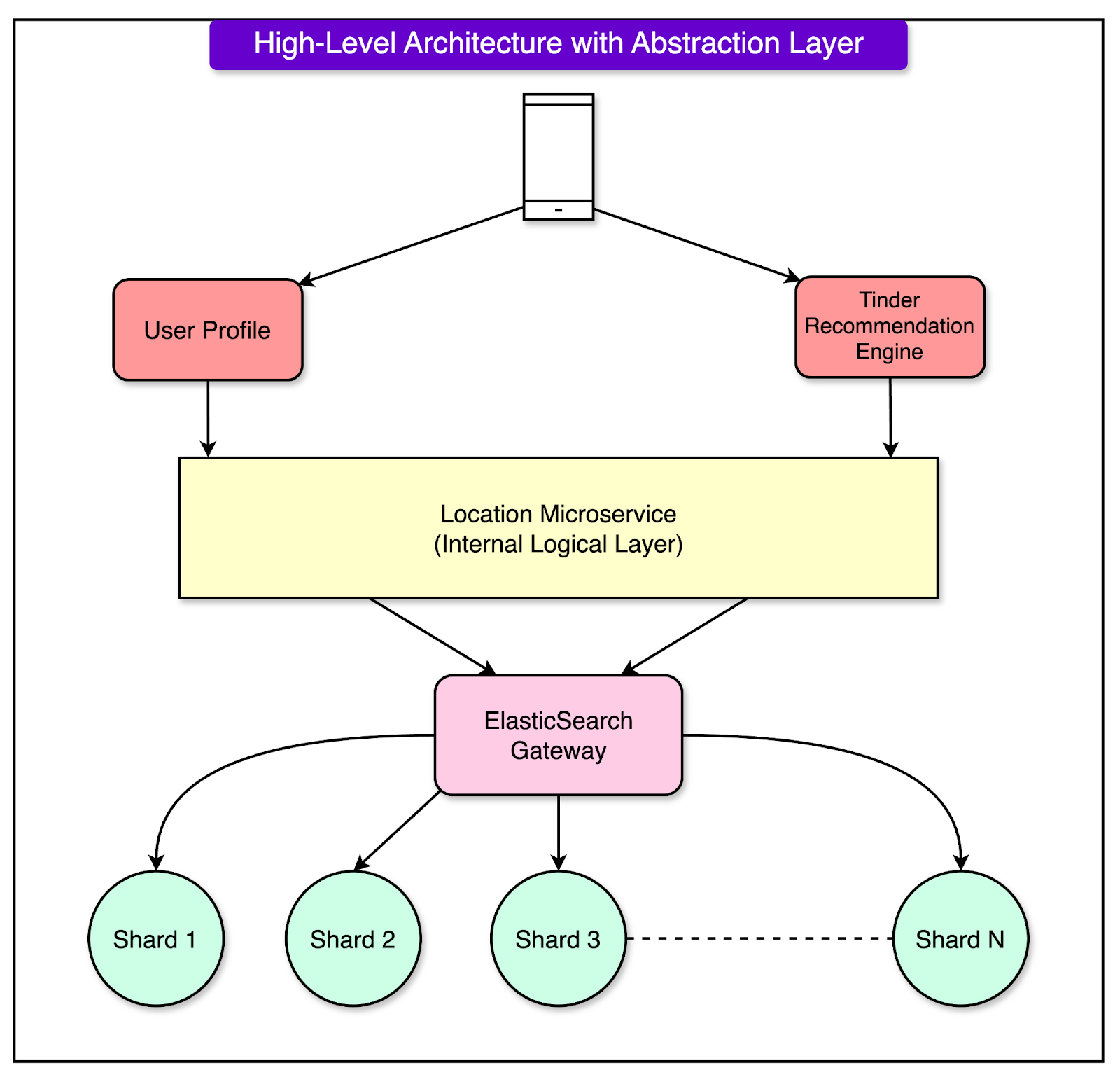
The Abstraction LayerAfter finalizing the Geosharding algorithm, Tinder designed a scalable and efficient architecture that relies on an abstraction layer to handle user data seamlessly across Geoshards. This layer simplifies interactions between the application, the recommendation system, and the geosharded Elasticsearch cluster. See the diagram below:
Here’s how the setup works:
Multi-Index vs Multi-ClusterWhen building the Geosharded recommendation system, Tinder had to decide how to organize its data infrastructure to manage the geographically separated shards efficiently. This led to a choice between two approaches: multi-index and multi-cluster. Each approach had pros and cons, but Tinder ultimately chose the multi-index approach. Let’s break it down in simple terms. What is the Multi-Index Approach?In the multi-index setup:
The alternative was a multi-cluster setup that involved creating separate Elasticsearch clusters for each geoshard. While this approach has some advantages, it wasn’t the right fit for Tinder due to a lack of native support for cross-cluster queries and higher maintenance overhead. To overcome the limitations of the multi-index setup, particularly the risk of uneven load distribution, Tinder implemented appropriate load balancing techniques. Some of the details about these techniques are as follows:
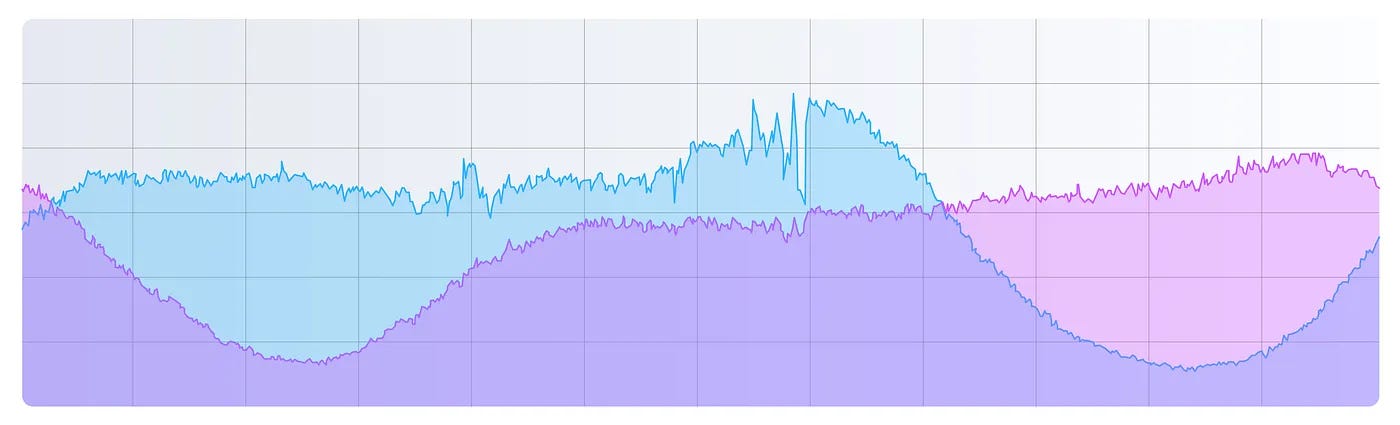
Handling Time Zones: Balancing Traffic Across GeoshardsOne of the key challenges Tinder faced with Geosharding was the variation in traffic patterns across Geoshards due to time zones. See the diagram below that shows the traffic pattern of two Geoshards during a 24-hour time span:
Users within the same geoshard are typically in the same or adjacent time zones, meaning their active hours tend to overlap. For example:
If shards were assigned directly to physical servers without considering time zone effects, some servers would be overloaded during peak hours for one shard, while others would remain idle. To solve this problem, Tinder implemented a randomized distribution of shards and replicas across physical nodes in the Elasticsearch cluster. Here’s how it works and why it helps:
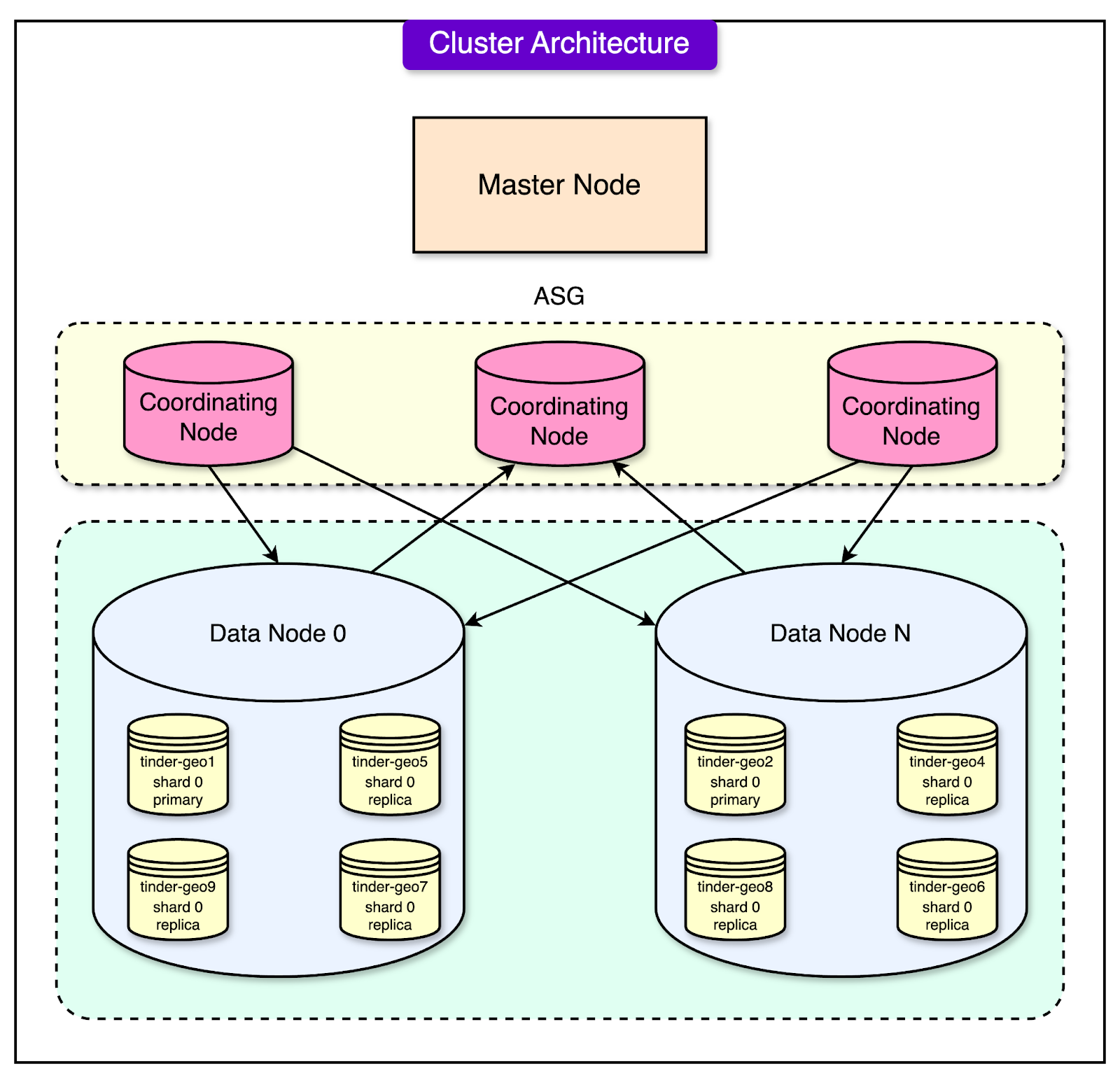
The Overall Cluster DesignTinder’s Geosharded recommendation system was built using a carefully designed cluster architecture to handle billions of daily swipes while maintaining speed, reliability, and scalability. The cluster architecture divides the responsibilities among different types of nodes, each playing a specific role in ensuring the system’s performance and fault tolerance. See the diagram below:
The key components of the cluster are as follows: Master NodesThese are the managers of the cluster, responsible for overall health and coordination. They keep track of which shards are stored on which data nodes. They also monitor the status of the nodes and redistribute shards if a node fails. Master nodes don’t handle user queries directly. Their role is to manage the system and ensure everything runs smoothly. Coordinating NodesThe coordinating nodes act as the traffic controllers of the system. When a user performs a search or swipe, their request goes to a coordinating node. This node determines:
Once the results are collected from the data nodes, the coordinating node aggregates them and sends the final response back to the user. Data NodesThese are the workers of the cluster, responsible for storing the actual data and processing queries. Data nodes execute the search queries sent by coordinating nodes and return the results. Each data node holds multiple Geoshards and their replicas as follows:
Consistency ChallengesMaintaining data consistency was another significant challenge in Tinder’s Geosharded system. This complexity arises because users frequently move between locations, and their data must be dynamically shifted between Geoshards. Without proper handling, these transitions could lead to inconsistencies, such as failed writes, outdated information, or mismatches between data locations. The key challenges are as follows:
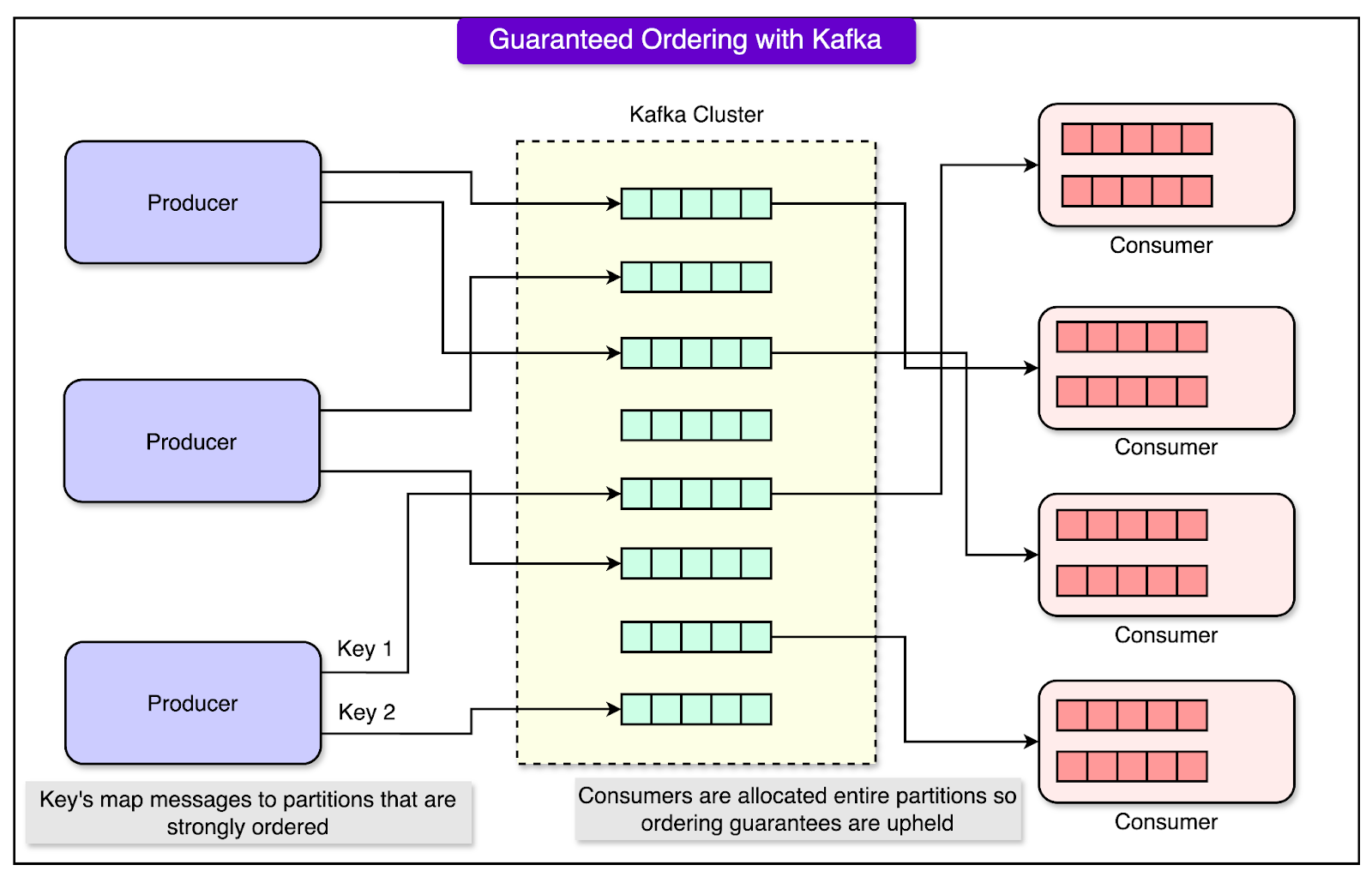
Tinder implemented a combination of strategies to address these issues and ensure consistent, reliable data handling across Geoshards. Let’s look at a few of those techniques in detail. 1 - Guaranteed Write Ordering with Apache KafkaWhen multiple updates occur for the same user data, ensuring they are processed in the correct order is critical to avoid inconsistencies. Apache Kafka was used as the backbone for managing data updates because it guarantees that messages within a partition are delivered in the same order they were sent. Tinder assigns each user a unique key (for example, their user ID) and uses consistent hashing to map updates for that user to a specific Kafka partition. This means all updates for a particular user are sent to the same partition, ensuring they are processed in the order they are produced. See the diagram below:
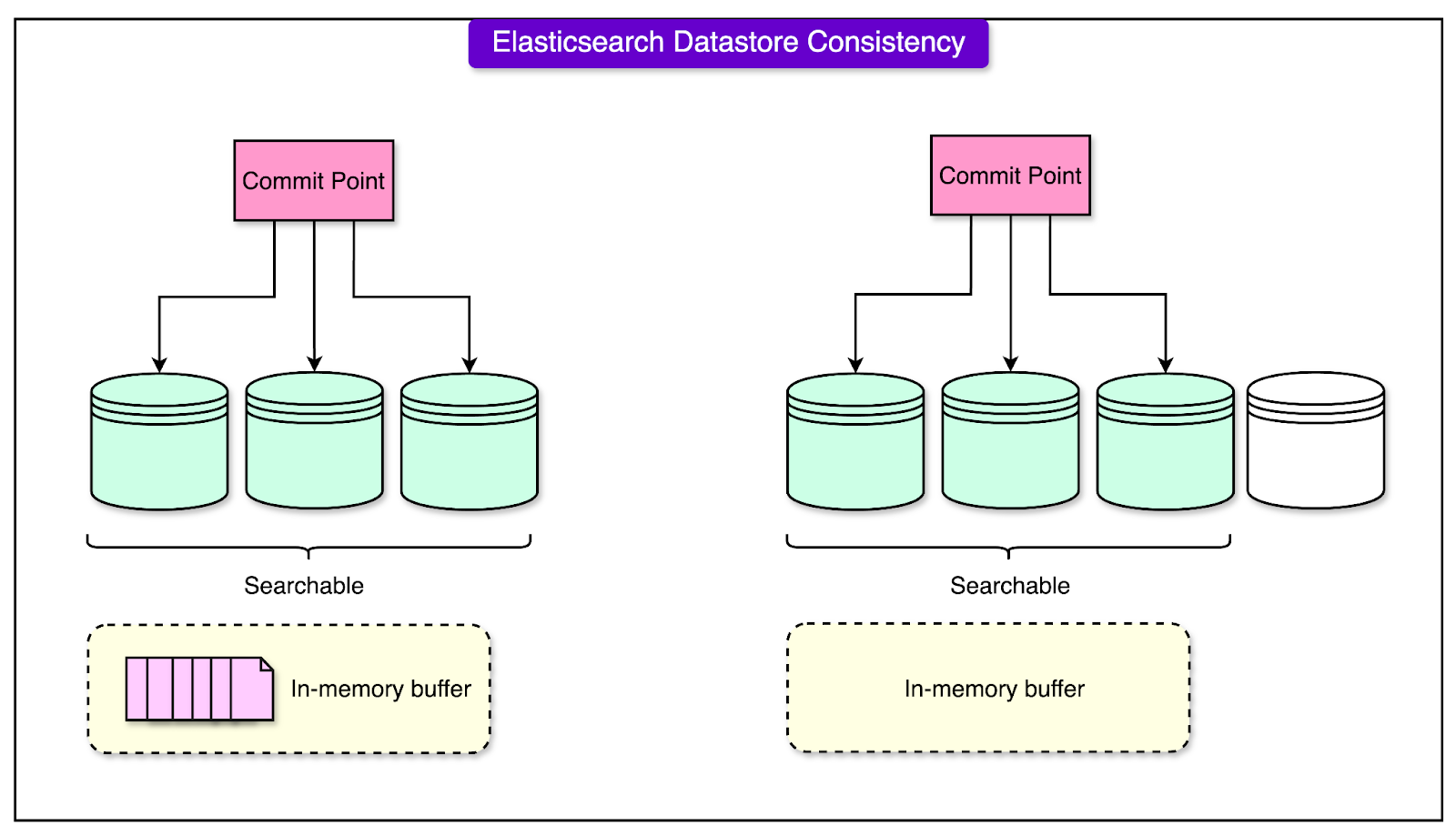
The consumers (parts of the system that read and process messages) read updates sequentially from the partitions, ensuring that no updates are skipped or processed out of order. This guarantees that the latest update always reflects the most recent user activity. 2 - Strongly Consistent Reads with the Elasticsearch Get APIElasticsearch is a "near real-time" search engine, meaning recently written data may not be immediately available for queries. This delay can lead to inconsistencies when trying to retrieve or update data.
Tinder, however, leveraged Elasticsearch’s Get API, which forces the index to refresh before retrieving data. This ensures that any pending updates are applied before the data is accessed. Reindexing and Refeeding:In cases where data inconsistencies occurred due to upstream failures or mismatches between shards, a mechanism was needed to realign the datastore with the source of truth. Data from the source shard was copied to the target shard when a user moved between Geoshards. If inconsistencies were detected (e.g., missing data in a shard), the system periodically re-synced the search datastore with the source datastore using a background process. This ensured that even if temporary errors occurred, the system would self-correct over time. ConclusionTinder’s implementation of Geosharding demonstrates the complexities of scalability, performance, and data consistency in a global application. By dividing its user base into geographically bound shards, Tinder optimized its recommendation engine to handle billions of daily swipes while maintaining lightning-fast response times. Leveraging tools like the S2 Library and Apache Kafka, along with algorithms for load balancing and consistency, the platform transformed its infrastructure to support a seamless user experience across the globe. This architecture improved performance by handling 20 times more computations than the previous system. It also addressed challenges like traffic imbalances across time zones and potential data inconsistencies during shard migrations. With randomized shard distribution, dynamic replica adjustments, and intelligent reindexing, Tinder ensured reliability, fault tolerance, and scalability. References: SPONSOR USGet your product in front of more than 1,000,000 tech professionals. Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases. Space Fills Up Fast - Reserve Today Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com. © 2024 ByteByteGo
|


by "ByteByteGo" <bytebytego@substack.com> - 11:35 - 10 Dec 2024