- Mailing Lists
- in
- How to Choose a Message Queue? Kafka vs. RabbitMQ
Archives
- By thread 5240
-
By date
- June 2021 10
- July 2021 6
- August 2021 20
- September 2021 21
- October 2021 48
- November 2021 40
- December 2021 23
- January 2022 46
- February 2022 80
- March 2022 109
- April 2022 100
- May 2022 97
- June 2022 105
- July 2022 82
- August 2022 95
- September 2022 103
- October 2022 117
- November 2022 115
- December 2022 102
- January 2023 88
- February 2023 90
- March 2023 116
- April 2023 97
- May 2023 159
- June 2023 145
- July 2023 120
- August 2023 90
- September 2023 102
- October 2023 106
- November 2023 100
- December 2023 74
- January 2024 75
- February 2024 75
- March 2024 78
- April 2024 74
- May 2024 108
- June 2024 98
- July 2024 116
- August 2024 134
- September 2024 130
- October 2024 141
- November 2024 171
- December 2024 115
- January 2025 216
- February 2025 140
- March 2025 220
- April 2025 233
- May 2025 239
- June 2025 303
- July 2025 52
Forward Thinking on the recipe for Asia’s success story with Justin Yifu Lin
Electrification for two-wheelers, the recipe for Asia’s success story, building a closer relationship to the planet, and more: The Daily Read weekender
How to Choose a Message Queue? Kafka vs. RabbitMQ
How to Choose a Message Queue? Kafka vs. RabbitMQ
This is a sneak peek of today’s paid newsletter for our premium subscribers. Get access to this issue and all future issues - by subscribing today. Latest articlesIf you’re not a subscriber, here’s what you missed this month.
To receive all the full articles and support ByteByteGo, consider subscribing: In the last issue, we discussed the benefits of using a message queue. Then we went through the history of message queue products. It seems that nowadays Kafka is the go-to product when we need to use a message queue in a project. However, it's not always the best choice when we consider specific requirements. Database-Backed QueueLet’s use our Starbucks example again. The two most important requirements are:
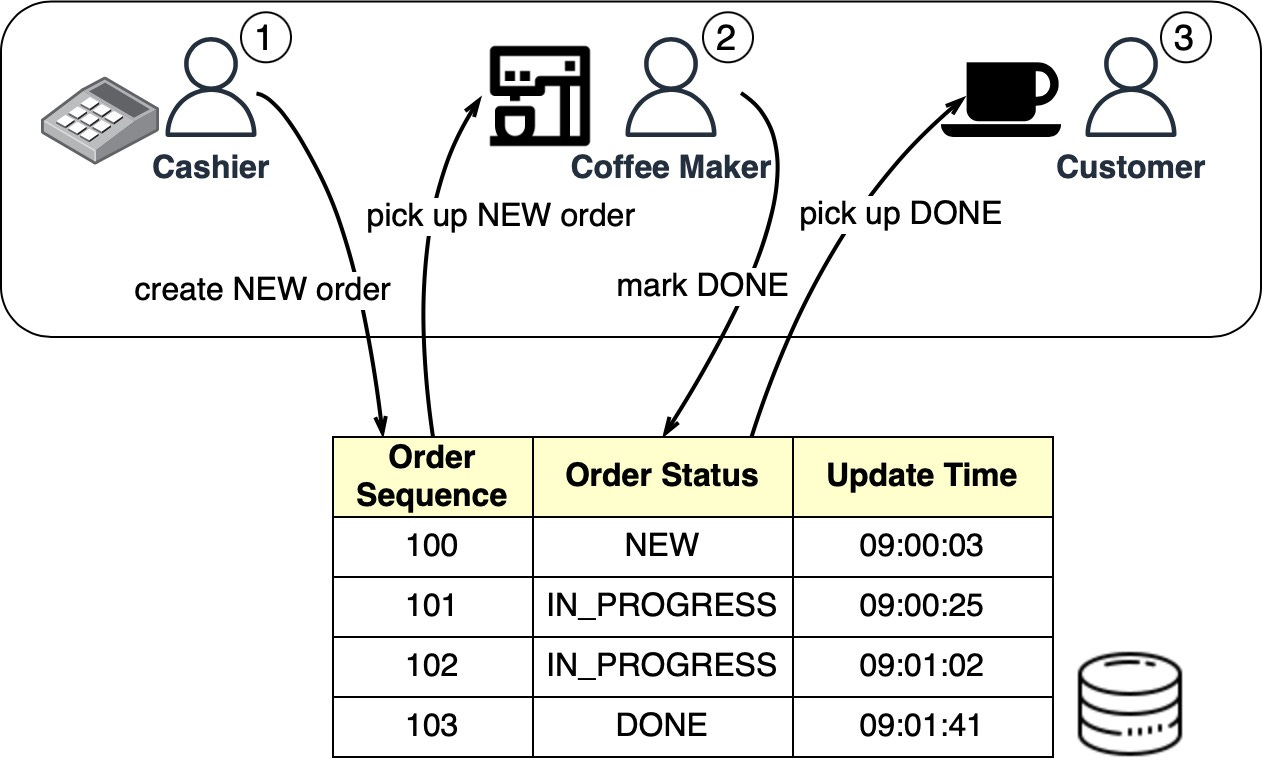
Message ordering doesn’t matter much here because the coffee makers often make batches of the same drink. Scalability is not as important either since queues are restricted to each Starbucks location. The Starbucks queues can be implemented in a database table. The diagram below shows how it works:
When the cashier takes an order, a new order is created in the database-backed queue. The cashier can then take another order while the coffee maker picks up new orders in batches. Once an order is complete, the coffee maker marks it done in the database. The customer then picks up their coffee at the counter. A housekeeping job can run at the end of each day to delete complete orders (that is, those with the “DONE status). For Starbucks’ use case, a simple database queue meets the requirements without needing Kafka. An order table with CRUD (Create-Read-Update-Delete) operations works fine. Redis-Backed QueueA database-backed message queue still requires development work to create the queue table and read/write from it. For a small startup on a budget that already uses Redis for caching, Redis can also serve as the message queue. There are 3 ways to use Redis as a message queue:
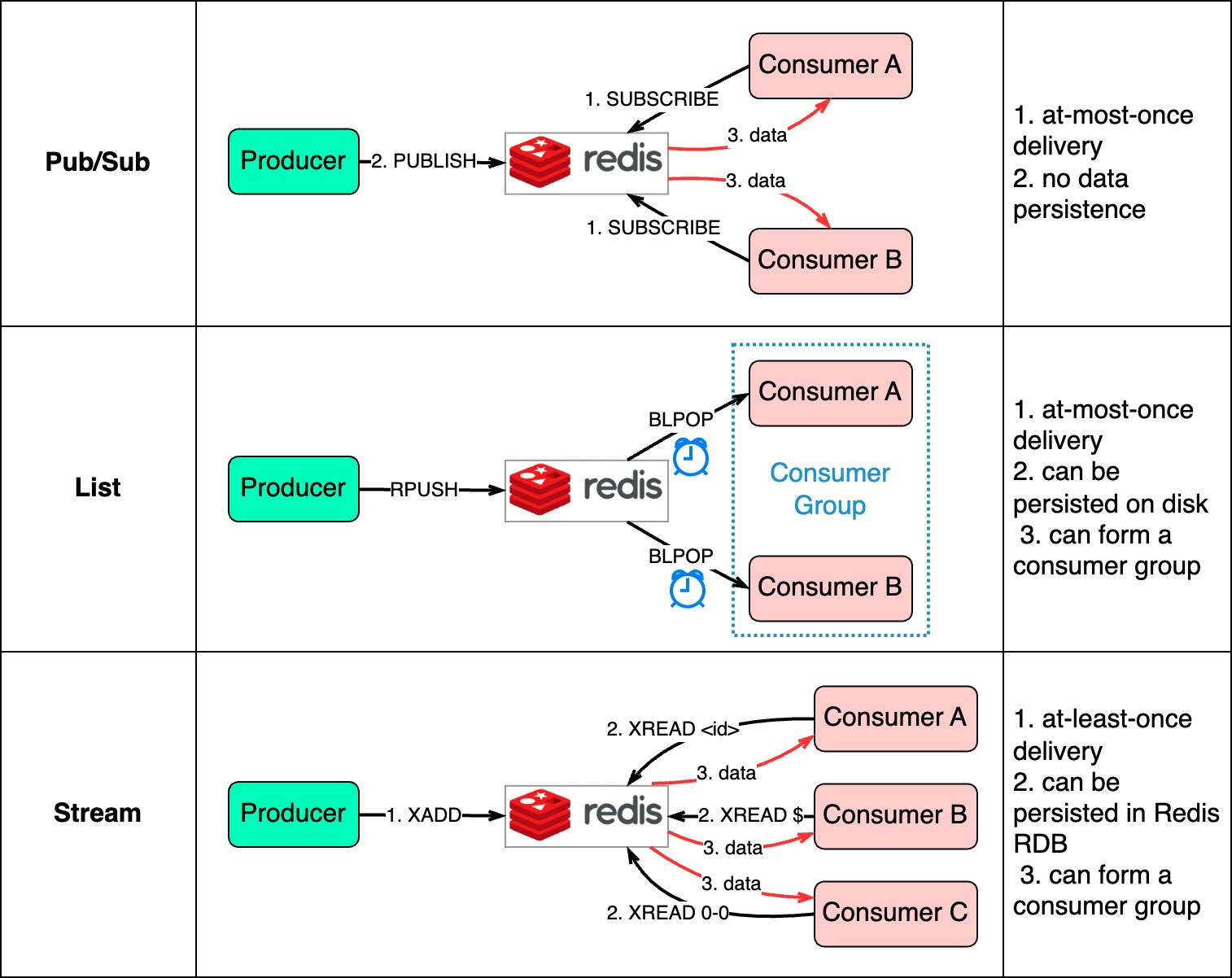
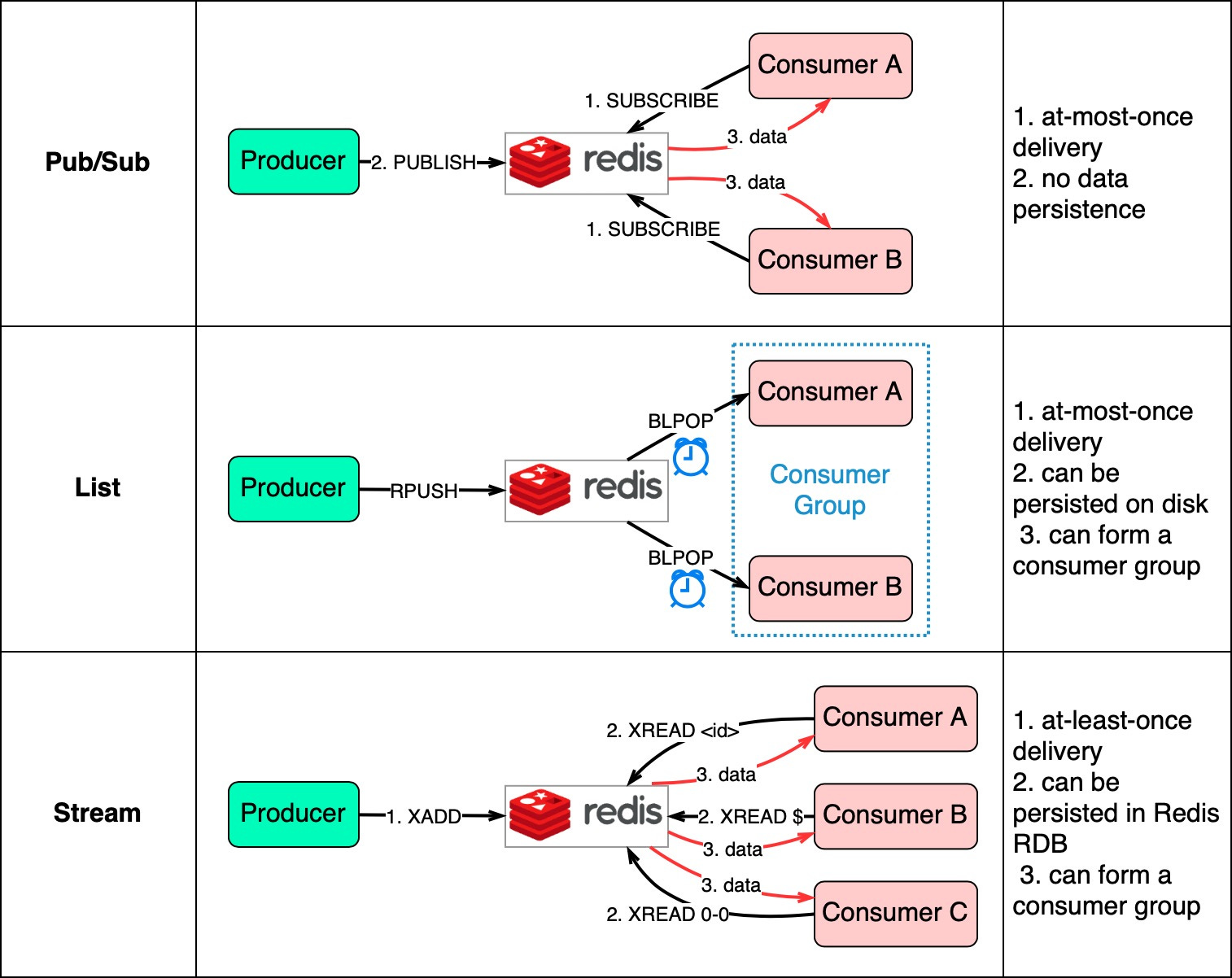
The diagram below shows how they work.
Pub/Sub is convenient but has some delivery restrictions. The consumer subscribes to a key and receives the data when a producer publishes data to the same key. The restriction is that the data is delivered at most once. If a consumer was down and didn’t receive the published data, that data is lost. Also, the data is not persisted on disk. If Redis goes down, all Pub/Sub data is lost. Pub/Sub is suitable for metrics monitoring where some data loss is acceptable. The List data structure in Redis can construct a FIFO (First-In-First-Out) queue. The consumer uses BLPOP to wait for messages in blocking mode, so a timeout should be applied. Consumers waiting on the same List form a consumer group where each message is consumed by only one consumer. As a Redis data structure, List can be persisted to disk. Stream solves the restrictions of the above two methods. Consumers choose where to read messages from - “$” for new messages, “<id>” for a specific message id, or “0-0” for reading from the start. In summary, database-backed and Redis-backed message queues are easy to maintain. If they can't satisfy our needs, dedicated message queue products are better. We'll compare two popular options next. RabbitMQ vs. KafkaFor large companies that need reliable, scalable, and maintainable systems, evaluate message queue products on the following:
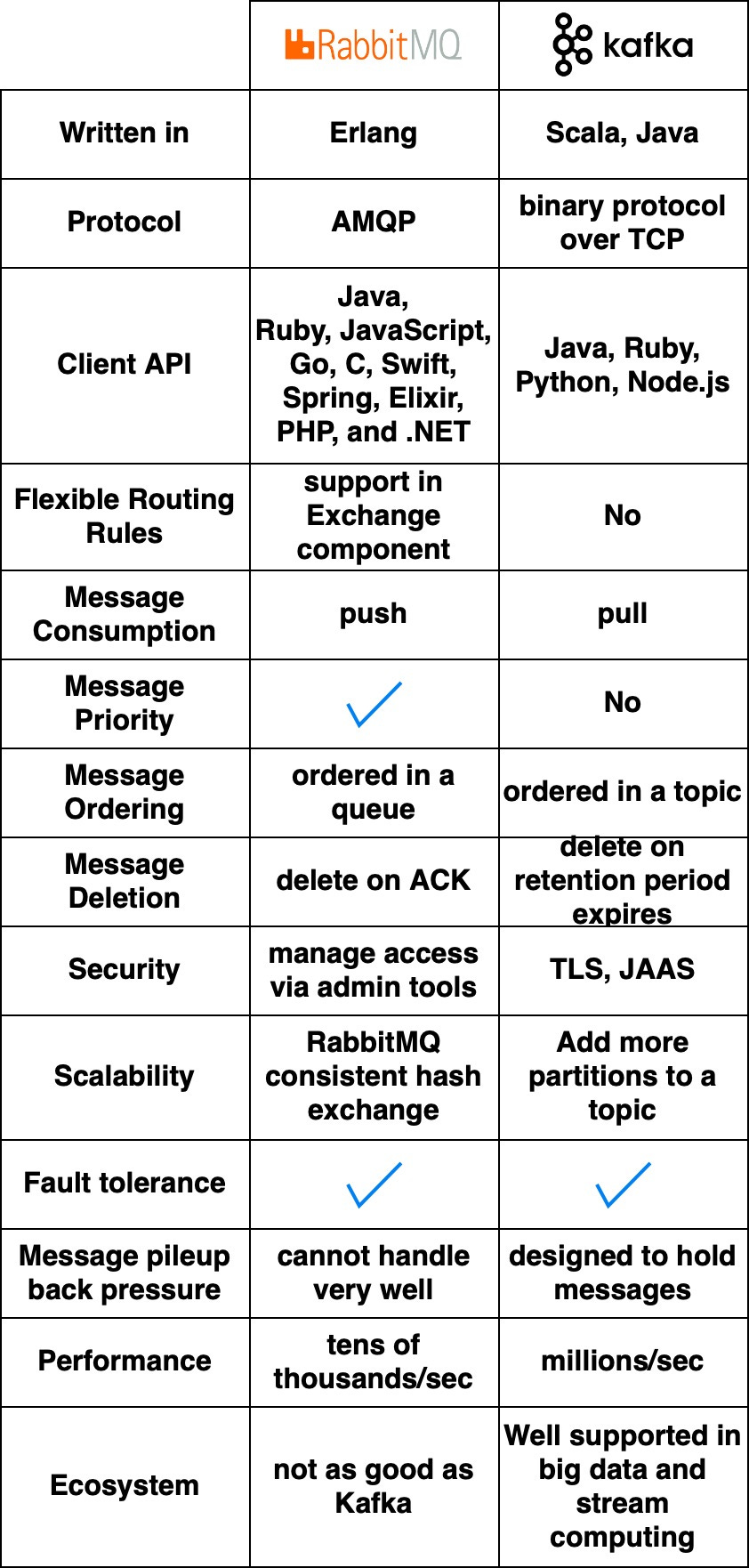
The diagram below compares two typical message queue products: RabbitMQ and Kafka.
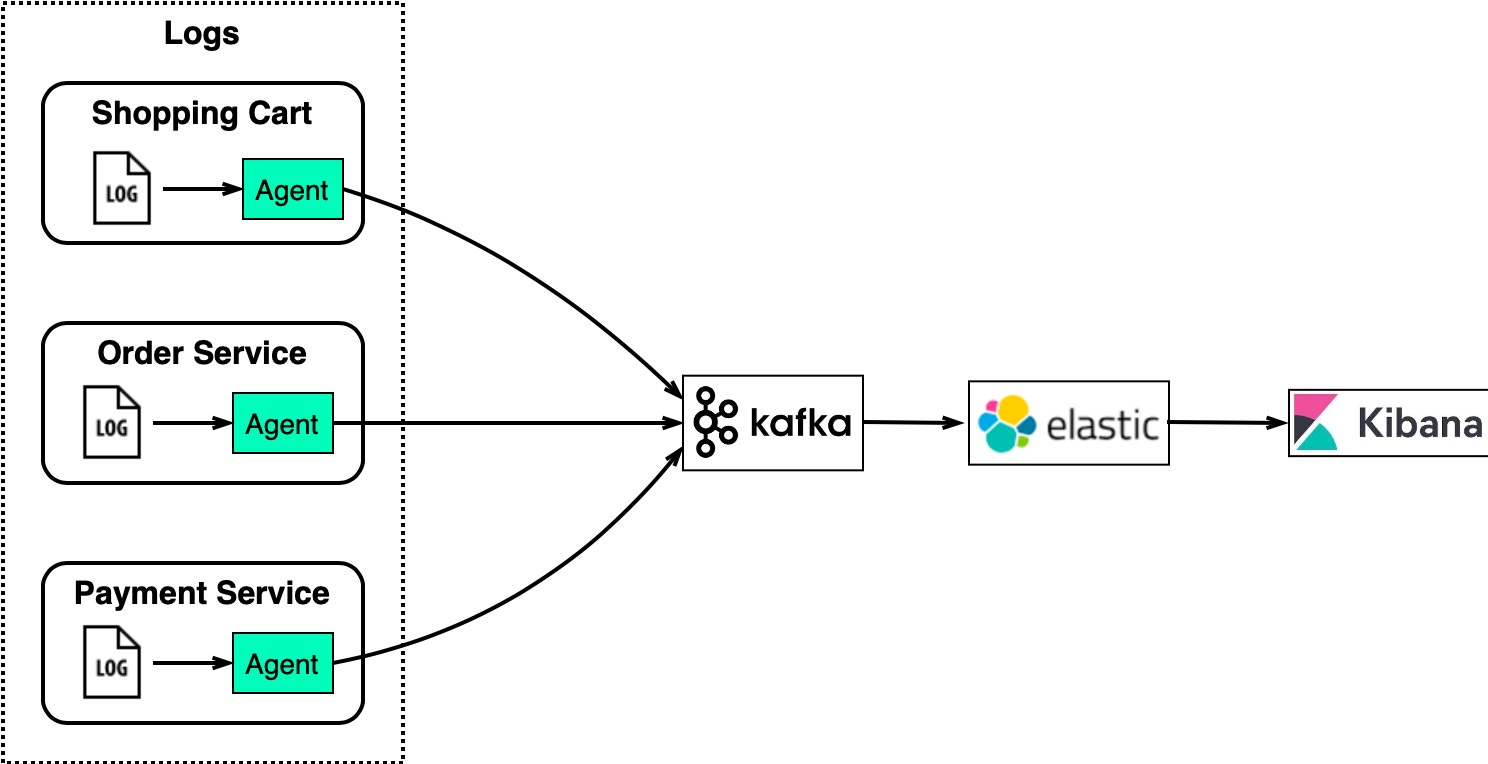
How They WorkRabbitMQ works like a messaging middleware - it pushes messages to consumers then deletes them upon acknowledgment. This avoids message pileups which RabbitMQ sees as problematic. Kafka was originally built for massive log processing. It retains messages until expiration and lets consumers pull messages at their own pace. Languages and APIsRabbitMQ is written in Erlang which makes modifying the core code challenging. However, it offers very rich client API and library support. Kafka uses Scala and Java but also has client libraries and APIs for popular languages like Python, Ruby, and Node.js. Performance and ScalabilityRabbitMQ handles tens of thousands of messages per second. Even on better hardware, throughput doesn’t go much higher. Kafka can handle millions of messages per second with high scalability. EcosystemMany modern big data and streaming applications integrate Kafka by default. This makes it a natural fit for these use cases. Message Queue Use CasesNow that we’ve covered the features of different message queues, let’s look at some examples of how to choose the right product. Log Processing and AnalysisFor an eCommerce site with services like shopping cart, orders, and payments, we need to analyze logs to investigate customer orders. The diagram below shows a typical architecture uses the “ELK” stack:
Keep reading with a 7-day free trialSubscribe to ByteByteGo Newsletter to keep reading this post and get 7 days of free access to the full post archives.A subscription gets you:
© 2023 ByteByteGo
|
by "ByteByteGo" <bytebytego@substack.com> - 12:50 - 17 Aug 2023