- Mailing Lists
- in
- How to Execute End-to-End Tests at Scale
Archives
- By thread 5332
-
By date
- June 2021 10
- July 2021 6
- August 2021 20
- September 2021 21
- October 2021 48
- November 2021 40
- December 2021 23
- January 2022 46
- February 2022 80
- March 2022 109
- April 2022 100
- May 2022 97
- June 2022 105
- July 2022 82
- August 2022 95
- September 2022 103
- October 2022 117
- November 2022 115
- December 2022 102
- January 2023 88
- February 2023 90
- March 2023 116
- April 2023 97
- May 2023 159
- June 2023 145
- July 2023 120
- August 2023 90
- September 2023 102
- October 2023 106
- November 2023 100
- December 2023 74
- January 2024 75
- February 2024 75
- March 2024 78
- April 2024 74
- May 2024 108
- June 2024 98
- July 2024 116
- August 2024 134
- September 2024 130
- October 2024 141
- November 2024 171
- December 2024 115
- January 2025 216
- February 2025 140
- March 2025 220
- April 2025 233
- May 2025 239
- June 2025 303
- July 2025 144
Join me on Thursday for troubleshooting applications and back end performance with APM 360
How can US manufacturing and construction address skilled-worker shortages?
How to Execute End-to-End Tests at Scale
How to Execute End-to-End Tests at Scale
Running E2E tests reliably and efficiently is a critical piece of the puzzle for any software organization. There are mainly two expectations software teams have when it comes to testing:
In today’s issue, we are fortunate to host guest author John Gluck, Principal Testing Advocate at QA Wolf. He’ll be sharing insights into QA Wolf’s specialized infrastructure capable of running thousands of concurrent E2E tests in just a few minutes and meeting the expectations of their customers. QA Wolf is a full-service solution for mid-to-large product teams who want to speed up their QA cycles and reduce the cost of building, running, and maintaining comprehensive regression test coverage. Also, Mufav Onus of QA Wolf spoke at Kubecon 2024 in Paris about how they automatically resume pods on spot instances after unexpected shutdowns. Take a look. The Challenge of Running E2E TestsRunning E2E tests efficiently is challenging for any organization. The runners tend to cause resource spikes, which cause tests and applications to behave unpredictably. That’s why it’s fairly common for large product teams to strategically schedule their test runs. As the number of tests and the number of runs increases, the challenges become exponentially more difficult to overcome. While the largest companies in the world may run 10,000 end-to-end tests each month, and a handful run 100,000, QA Wolf runs more than 2 million. At our scale, to support the number of customers that we do, our infrastructure has to address three major concerns:
For better or worse, StackOverflow didn’t have blueprints for the kind of test-running infrastructure we needed to build. Success came from lots of experimentation and constant refinement. In this post, we discuss the problems we faced and the decisions we made so that we could solve them through experimentation. The Tech Stack Breakdown
To set the stage, we are completely cloud-native and built our infrastructure on the Google Cloud Platform (GCP). We went with GCP for its GKE (Kubernetes) implementation and cluster autoscaling capabilities, which are critical for handling the demand for test execution nodes. There are similar tools out there, but our engineers also had previous experience with GCP, which helped us get started. We adopted a GitOps approach so we could run lots of configuration experiments on our infrastructure quickly and safely without disrupting ongoing operations. Argo CD was a good choice because of its support for GitOps and Kubernetes. A combination of Helm and Argo Workflows helps make the deployment process consistent and organized. We used Argo CD Application Sets and App of Apps patterns which are considered best practices. For IaC, we chose Pulumi because it’s open source, and unlike Terraform, it doesn’t force developers to adopt another DSL (Domain-Specific Language) Lastly, we used Typescript to write the tests. Our customers look at the test code written for them, and Typescript makes it easy to understand. We chose Playwright as the test executor and test framework for multiple reasons, such as:
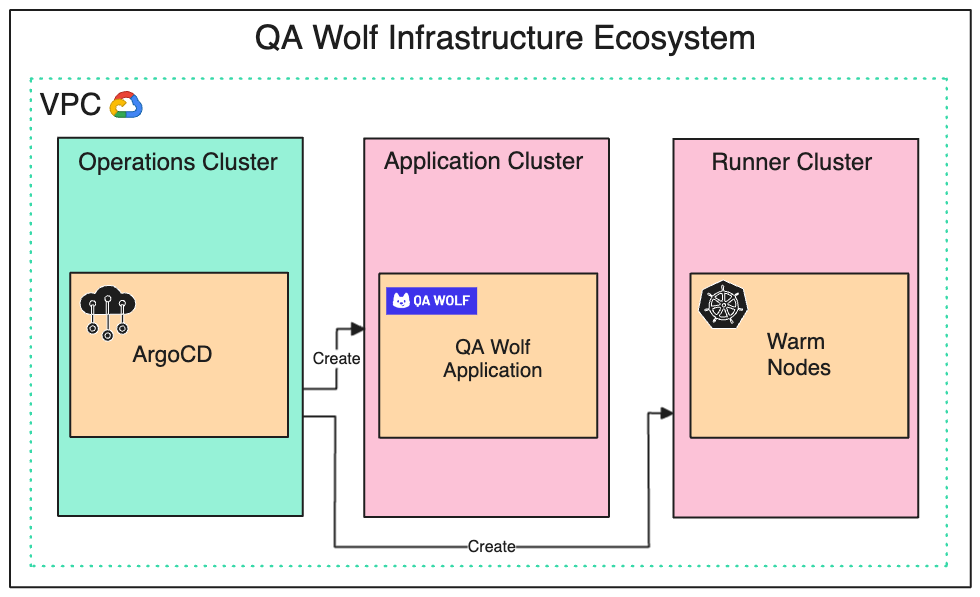
The EcosystemFor the infrastructure ecosystem, we went with one VPC and three main application clusters. Each of the three clusters has a specific role:
The operations cluster is the primary cluster and manages the other two clusters. Argo CD runs within this cluster. See the diagram below that shows this arrangement.
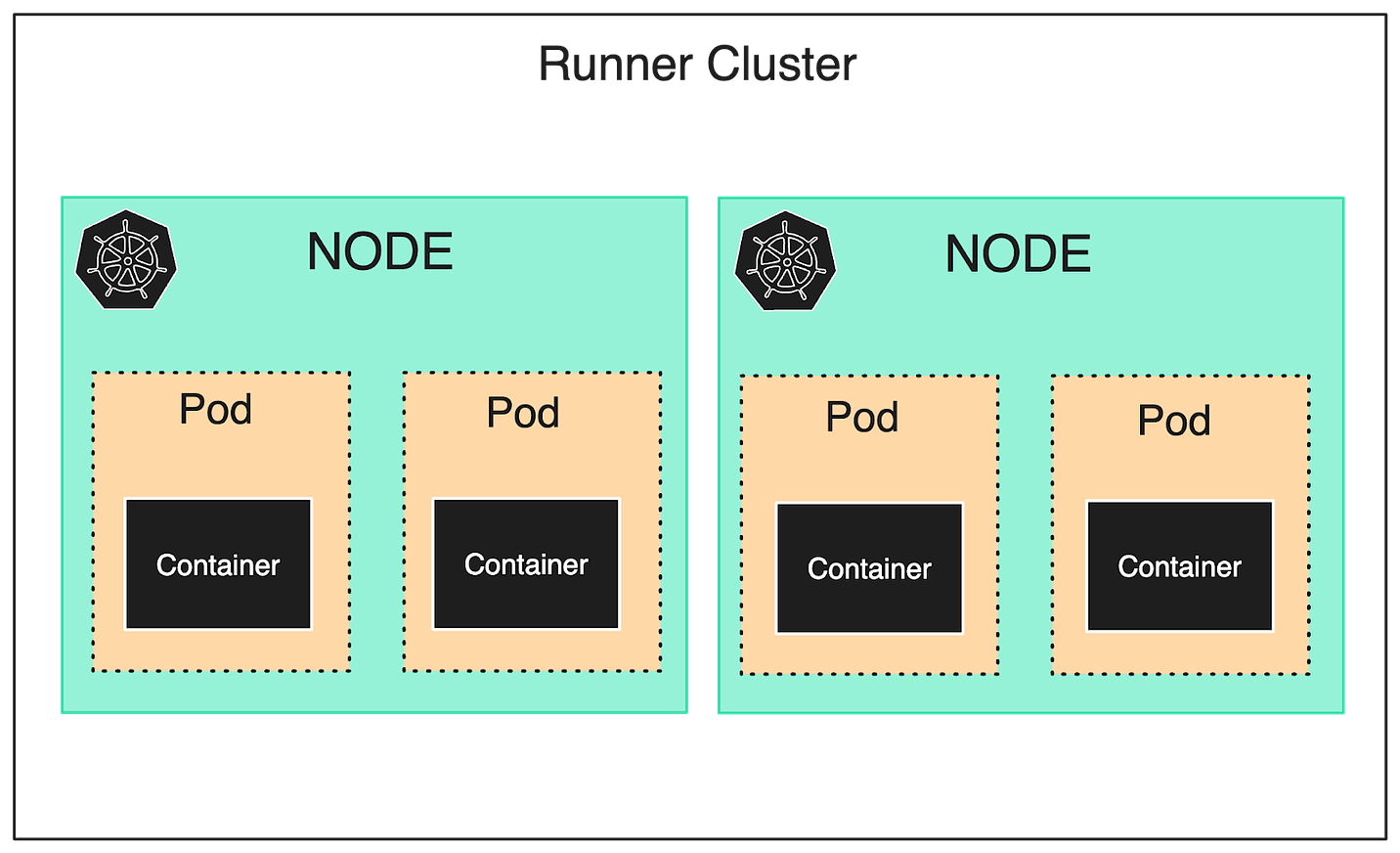
At the time of startup, the operations cluster creates both the application and runner clusters. It provisions warm nodes on the runner cluster, each containing two pods, and each pod is built on a single container image. See the diagram below for reference:
This structure is fully expendable. Our developers can tear down the entire system and rebuild it from scratch with the touch of a button, which increases predictability for developers and is also great for supporting disaster recovery. GKE’s cluster autoscaler scales the warm nodes on the runner cluster up and down based on demand. Latest articlesIf you’re not a paid subscriber, here’s what you missed.
To receive all the full articles and support ByteByteGo, consider subscribing: The Customer-Facing ApplicationThe customer-facing application is a specialized IDE where our QA engineers can write, run, and maintain Playwright tests. It has views for managing configuration and third-party integrations with visualization dashboards.
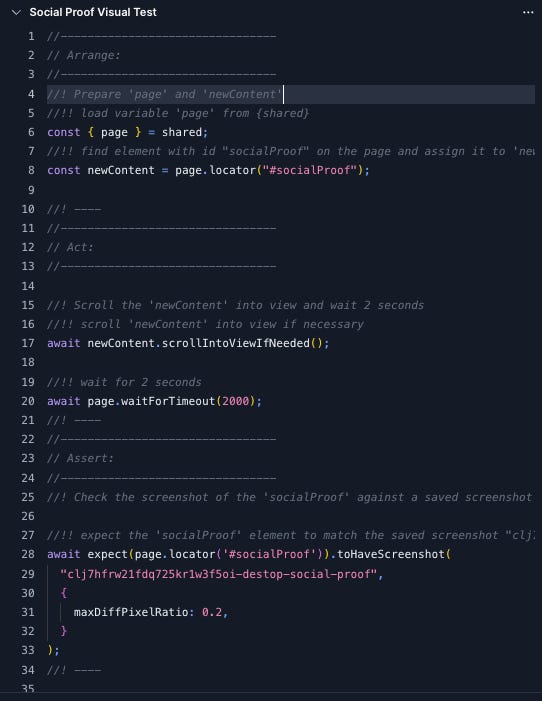
Writing TestsThe tests built and maintained by our in-house QA engineers are autonomous, isolated, idempotent, and atomic, so they can run predictably in a fully parallelized context. When a QA engineer saves a test, the application persists the code for the test onto GCS with its corresponding helpers and any associated parsed configuration needed to run it in Playwright. This is the Run Data File for the test. In case you don’t know, GCS is the GCP equivalent of AWS S3.
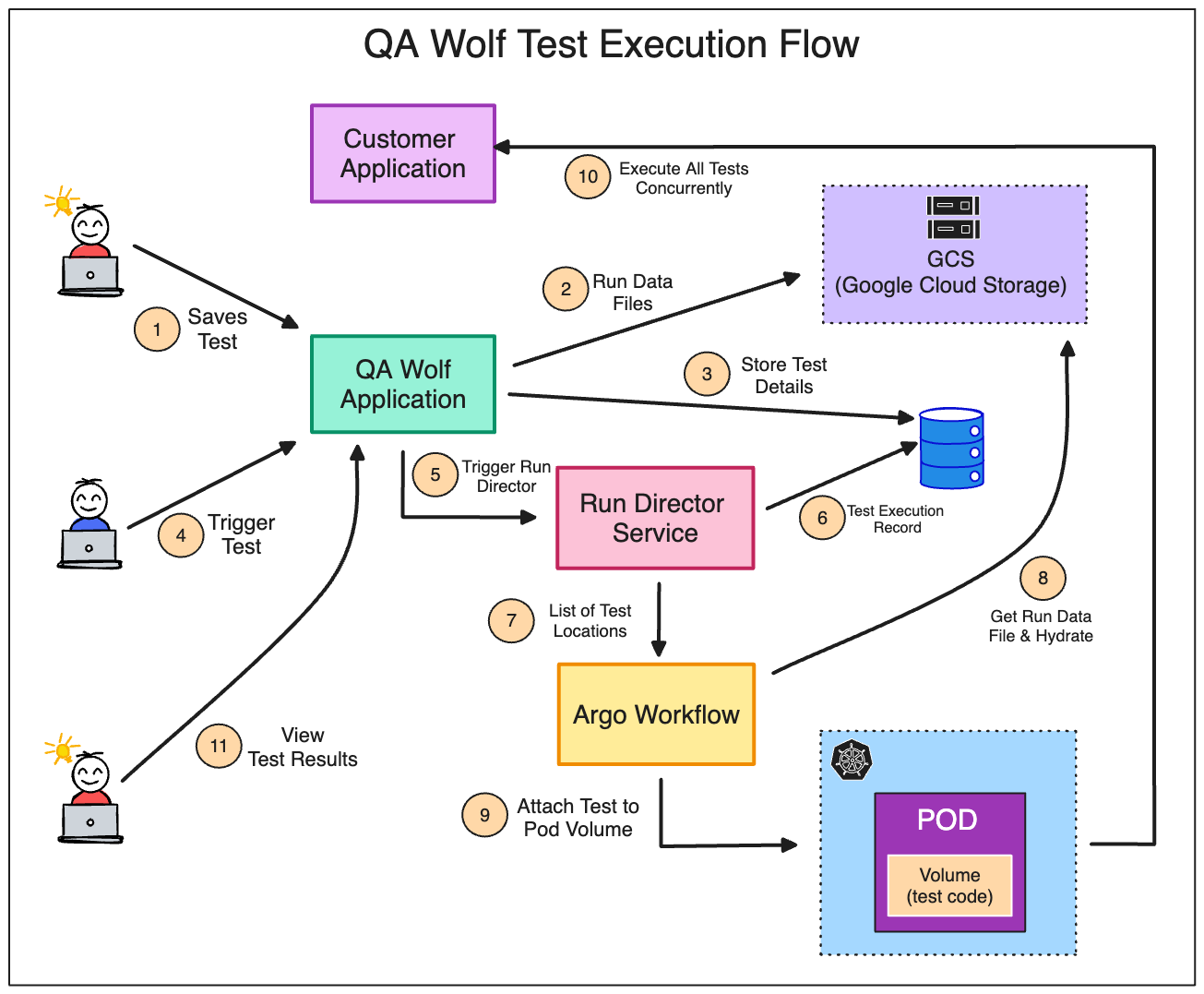
In the initial implementation, we tried passing the Run Data File as a payload in HTML, but the payload containing the test code for all tests in a run was too large for Kubernetes etcd. To get around this, we took the path of least resistance by writing all the code to a central file and giving the client a reference to the file location to pass back to the application. The Execution FlowAs mentioned earlier, we orchestrate runs with Argo Workflows because it can run on a Kubernetes cluster without external dependencies. Customers or QA engineers can use a scheduler in the application or an API call to start a test run. When a test run is triggered, the application gathers the locations of all necessary Run Data Files. It also creates a new database record for each test run, including a unique build number that acts as an identifier for the test run request. The application uses the build number later to associate system logs and video locations. Lastly, it passes the Run Data file locations list to the Run Director service. The below diagram depicts the entire execution flow at a high level.
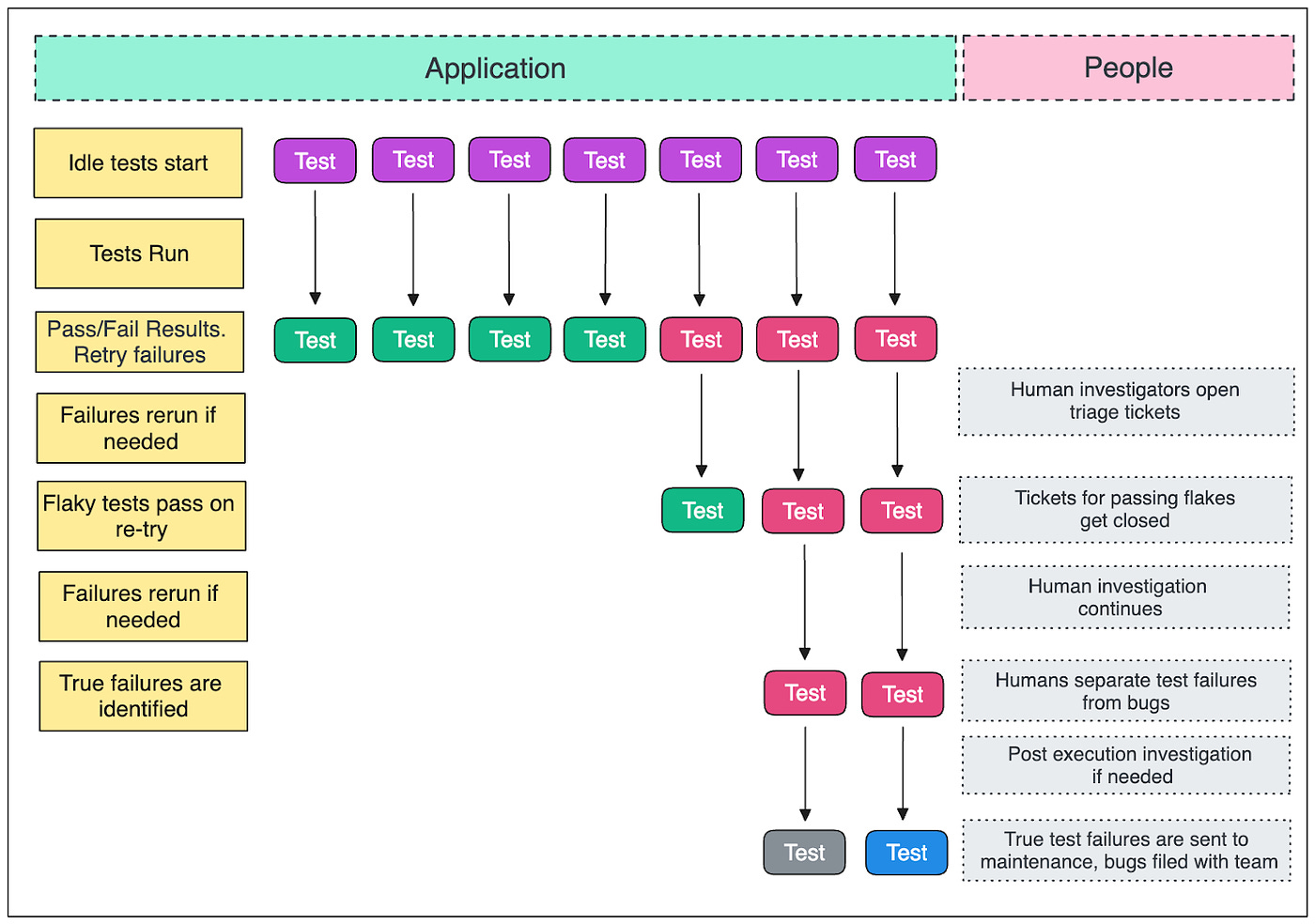
The Run DirectorThe Run Director is a simple, long-living, horizontally-scalable HTTP service. When invoked, the Run Director reports the initial test run status to the application via a webhook and the build number. For each location in the list, the Run Director invokes an Argo Workflows template and hydrates it with the Run Data file at that location. By performing both actions simultaneously, individual test runs can be started faster so that all the tests in the run can finish more quickly. The Argo Workflow then provisions a Kubernetes pod for each test run requested from the available warm nodes. It attaches the code for each test to a volume on a corresponding container on the pod. This approach allows us to use the same container build for every test execution. If there aren’t enough pods for the run on warm nodes, GKE uses cluster autoscaling to meet demand. Each test runs in its own pod and container, which isolates the tests and makes it easier for the developers to troubleshoot them. Running tests like this also confines resource consumption issues to the node where the specific tests are having trouble. The test code runs from the container entry point. Argo Workflow drives the provisioning process and starts each container with the help of Kubernetes The application runs all the tests in headed browsers. This is important because the container is destroyed after the test finishes, and the headed browser makes it possible to capture videos of tests. The videos are an essential debugging tool to know about what happened at the moment, especially in cases where it’s difficult to recreate a particular failure. Due to the high standard for test authorship and the infrastructure reliability, the primary cause of test failure is when the system-under-test (SUT) is not optimized for testing. It makes sense when you think about it. The slower the SUT, the more the test is required to poll, increasing the demand on the processor running the test. Though we can’t tell the customer how to build their application to improve test performance, we can isolate each test’s resource consumption to prevent it from impacting other tests. The Flake DetectionWe maintain a very high standard of test authorship, which allows us to make certain assumptions. Since the tests are expected to pass, we can safely assume that a test failure or error is due to an anomaly, such as a temporarily unavailable SUT. The application schedules such failures for automatic retry. It flags any other failure – such as a suspected infrastructure problem – for investigation and doesn’t retry. Argo Workflows will attempt to re-run a failed test three times.
If the tests pass on retry, the application resumes as usual and assumes the failure was anomalous. In case all retries fail, the system creates a defect report, and a QA engineer investigates to confirm whether the failure is due to a bug in the application or some other issue. The Run Shard ClustersOne of the most significant advantages of the Run Director service is the concept of Run Shard Clusters. The sharding strategy allows us to spread the various test runs across clusters located worldwide. We have a GCP global VPC with a bunch of different subnets in different regions. This makes it possible to provision sharding clusters in different regions that can be accessed privately via the Run Director service. Shard clusters provide several advantages, such as:
Reporting
Of course, our customers also want to see test results, so we needed to create a reliable system that allowed them to do so. Once the test finishes running and retrying (if needed), the Argo Workflow template uploads any run artifacts saved by Playwright back to GCS using the build number. Some of this information will be aggregated and appear on our application’s dashboard. Other pieces of information from these artifacts are displayed at the test level, such as logs and run history.
On the infrastructure side, the Argo Workflow triggers Kubernetes to shut down the container and detach the volume, ensuring that the system doesn’t leave unnecessary resources running. This helps keep down operational costs. ConclusionOur unique approach was developed to meet customer needs for speed, availability, and reliability. We are one of the few companies running e2e tests at this scale, so we needed to discover how to create a system to support that through trial and error; therefore, we designed our system to also support fast iteration. Our cost-efficient, full parallel test execution is the backbone of our application and we see it delivering value for our customers on a daily basis. If you’d like to learn more about QA Wolf’s test run infrastructure or how it can help you ship faster with fewer escapes, visit their website to schedule a demo. Related Links SPONSOR USGet your product in front of more than 500,000 tech professionals. Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases. Space Fills Up Fast - Reserve Today Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing hi@bytebytego.com. © 2024 ByteByteGo
|

by "ByteByteGo" <bytebytego@substack.com> - 12:29 - 30 Apr 2024