- Mailing Lists
- in
- How Uber Manages Petabytes of Real-Time Data
Archives
- By thread 5220
-
By date
- June 2021 10
- July 2021 6
- August 2021 20
- September 2021 21
- October 2021 48
- November 2021 40
- December 2021 23
- January 2022 46
- February 2022 80
- March 2022 109
- April 2022 100
- May 2022 97
- June 2022 105
- July 2022 82
- August 2022 95
- September 2022 103
- October 2022 117
- November 2022 115
- December 2022 102
- January 2023 88
- February 2023 90
- March 2023 116
- April 2023 97
- May 2023 159
- June 2023 145
- July 2023 120
- August 2023 90
- September 2023 102
- October 2023 106
- November 2023 100
- December 2023 74
- January 2024 75
- February 2024 75
- March 2024 78
- April 2024 74
- May 2024 108
- June 2024 98
- July 2024 116
- August 2024 134
- September 2024 130
- October 2024 141
- November 2024 171
- December 2024 115
- January 2025 216
- February 2025 140
- March 2025 220
- April 2025 233
- May 2025 239
- June 2025 303
- July 2025 32
How can institutions affect economic prosperity?
2024 Nobel Prize winner Daron Acemoglu on how inclusive institutions can drive growth
How Uber Manages Petabytes of Real-Time Data
How Uber Manages Petabytes of Real-Time Data
Stop renting auth. Make it yours instead.(Sponsored)
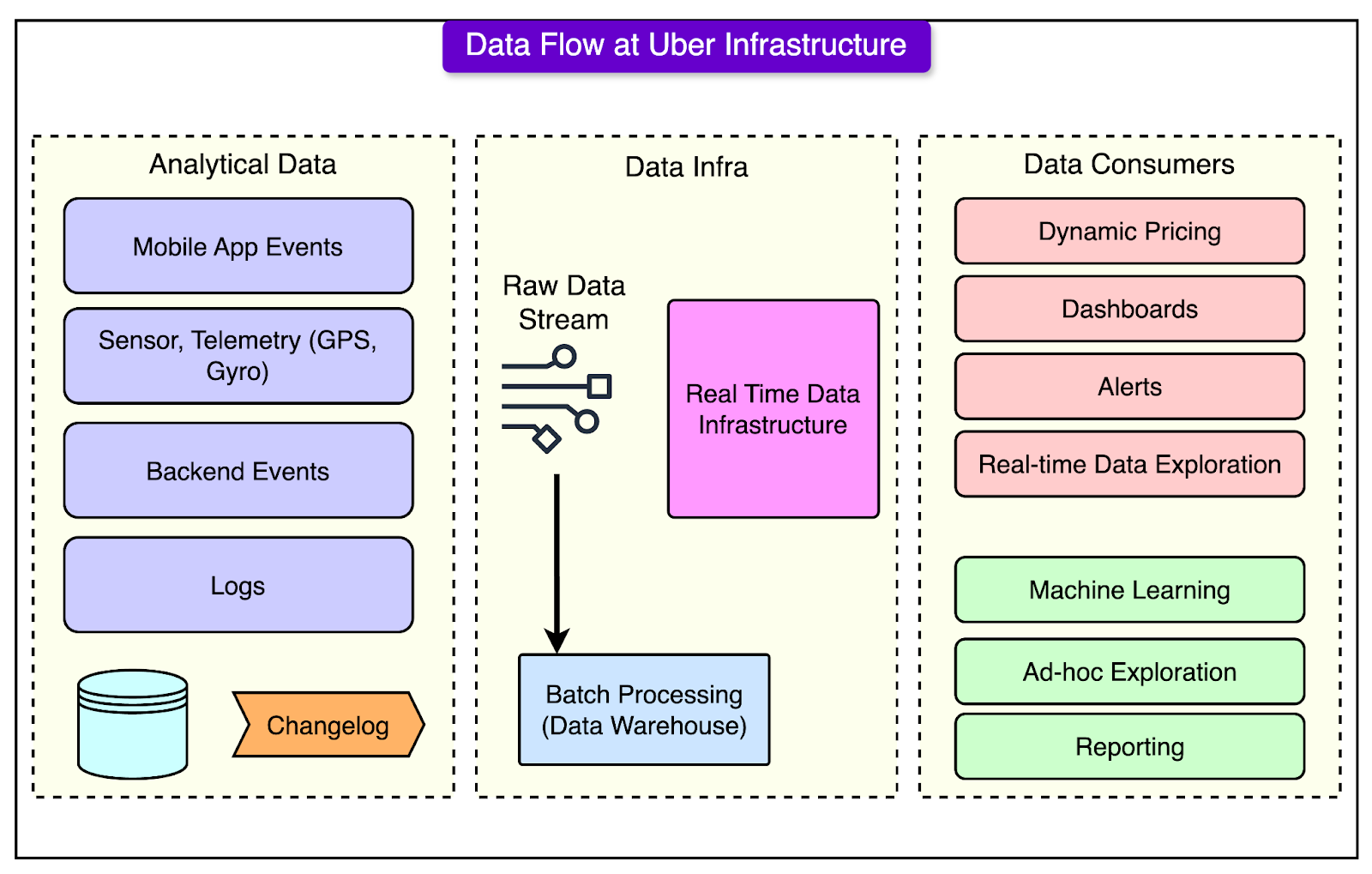
FusionAuth is a complete auth & user platform that has 15M+ downloads and is trusted by industry leaders. Disclaimer: The details in this post have been derived from the Uber Research Paper and Engineering Blog. All credit for the technical details goes to the Uber engineering team. The links to the original articles are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them. Uber's real-time data infrastructure is a cornerstone of its business operations, processing massive amounts of data every day. From drivers and riders to restaurants and back-end systems, Uber collects petabytes of data to power important features such as customer incentives, fraud detection, and predictions made by machine learning models. To manage this vast flow of information, Uber relies on a sophisticated system that handles three key components:
Each element plays a crucial role in ensuring that data is processed and analyzed quickly, allowing Uber to respond to real-time events like ride requests, price changes, and more.
However, maintaining this real-time infrastructure isn't easy. As Uber continues to grow, so do the challenges. The company needs to scale its systems to handle more data, support new use cases, and accommodate a growing number of users. At the same time, they must ensure that the data is always fresh, latency is kept low, and the entire system remains highly available. In short, Uber's real-time data system is essential to its ability to make split-second decisions, and the company has built an advanced architecture to keep everything running smoothly, even as demand grows. Critical Requirements of Uber’s Real-Time DataUber's real-time data system has some critical requirements to ensure it operates smoothly and efficiently, especially given its massive scale. These requirements handle everything from ride pricing to food delivery, ensuring users get the best possible experience.
In short, Uber's real-time data infrastructure is designed to be consistent, available, fast, scalable, and cost-effective, ensuring the company's services run smoothly at all times. Tutorial: Build a RAG AI Application with external contextual data in 3 days (Sponsored)
There are two parts to building any gen-AI application.
Most AI companies are racing to build a knowledge copilot to solve that first problem. But building an AI copilot/feature that ingests, stores, and retrieves contextual data from dozens of data sources (ie. Google Drive, Notion, Slack, etc.) can get complex very quickly. That said, with the right tech stack and architecture, your team could ship production-ready RAG systems and AI features much faster. This RAG tutorial series covers the step-by-step process (repo included) of building a multi-tenant RAG AI chatbot application that:
Key Technologies Used By UberUber's real-time data infrastructure is powered by a combination of advanced open-source technologies, each customized to handle the company’s massive data needs. The diagram below shows the overall landscape.
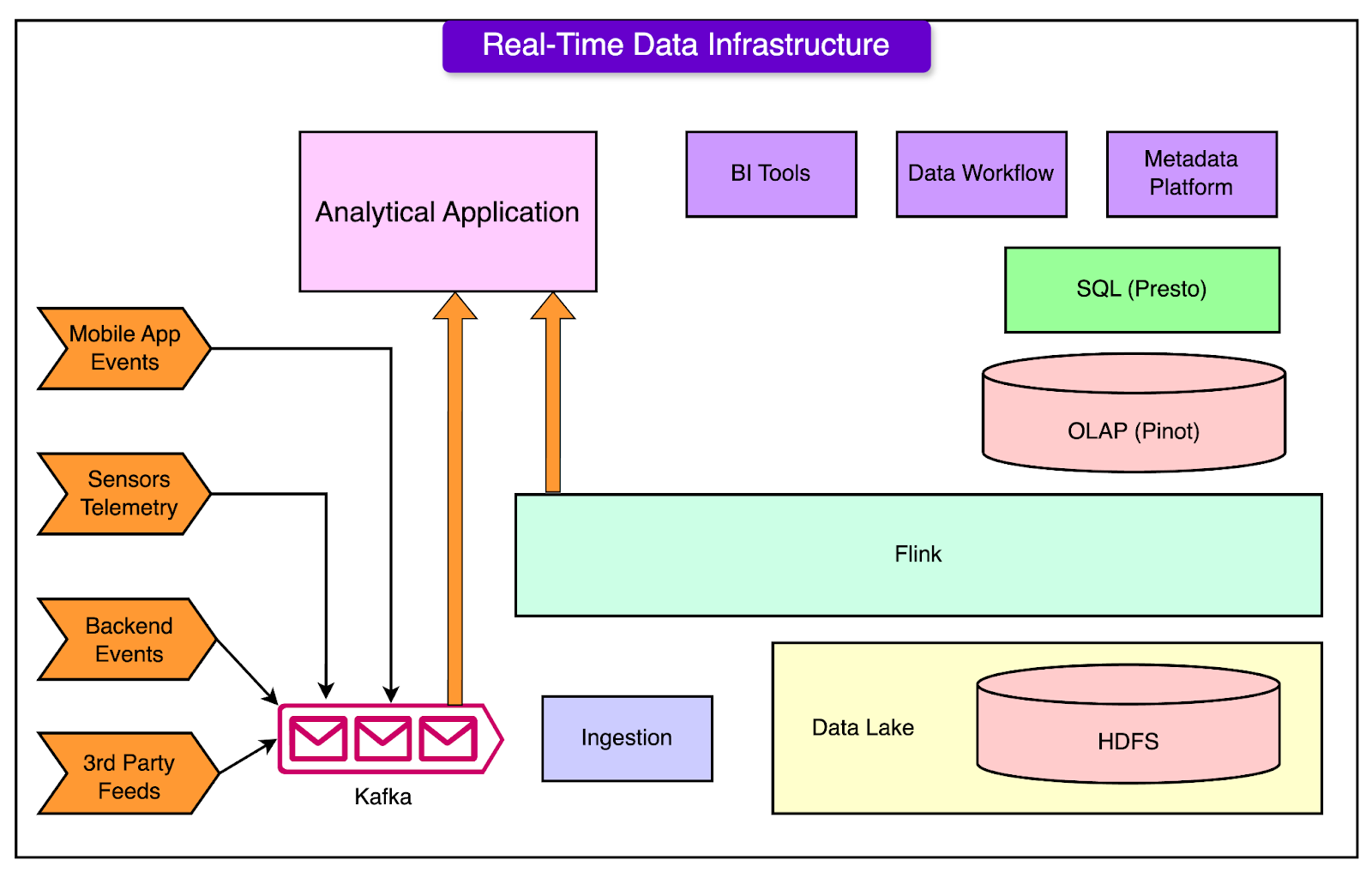
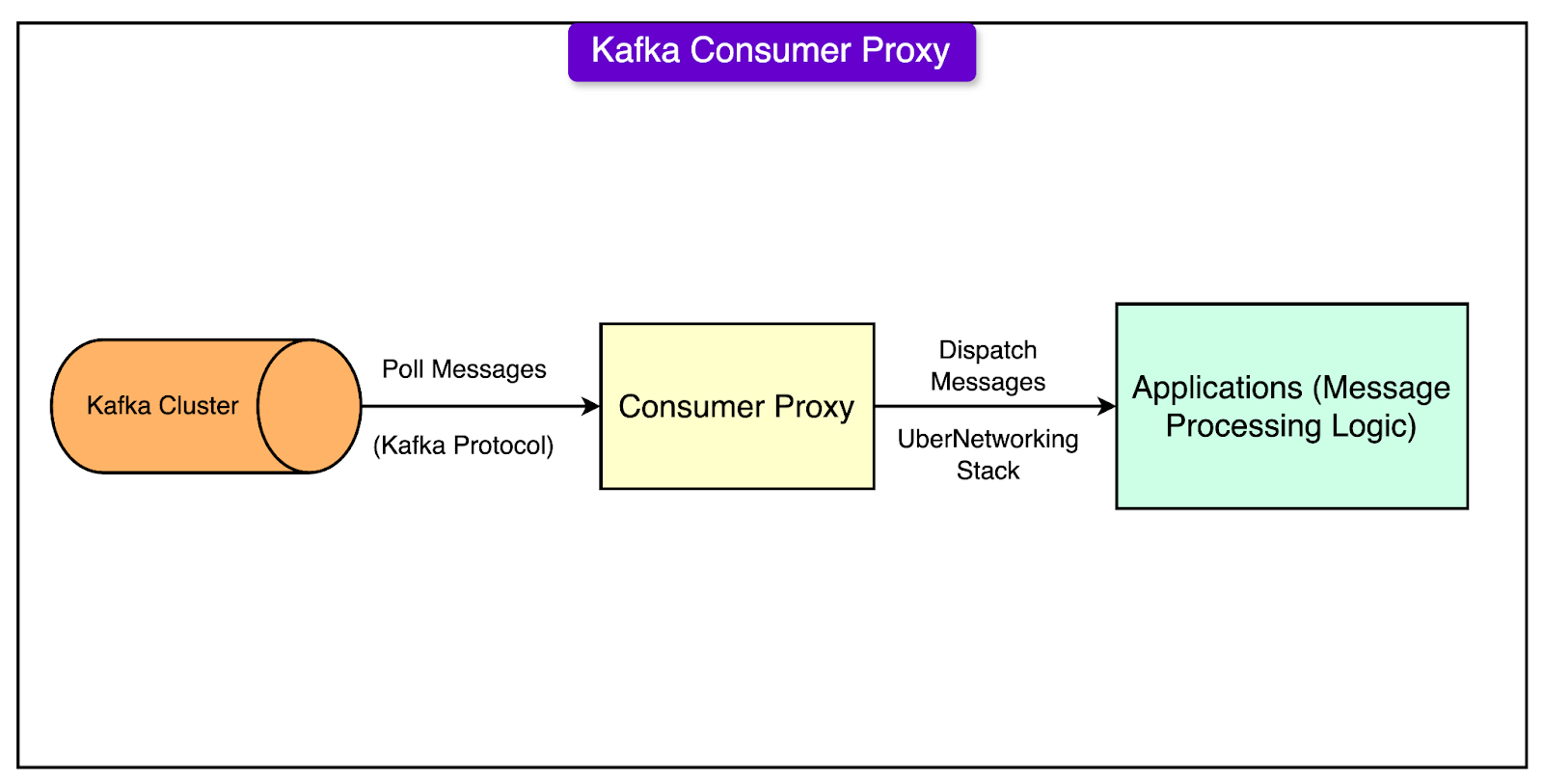
Let’s take a closer look at the key technologies Uber relies on, how they work, and the unique tweaks that make them fit Uber's requirements. Apache Kafka for Streaming DataKafka is the backbone of Uber’s data streaming. It handles trillions of messages and petabytes of data daily, helping to transport information from user apps (like driver and rider apps) and microservices. Kafka’s key role is to move this streaming data to batch and real-time systems.
At Uber, Kafka was heavily customized to meet its large-scale needs. Some of the key features are as follows:
Apache Flink for Stream ProcessingApache Flink is another critical component of Uber’s infrastructure, used for processing data streams in real-time. Flink can handle complex workloads, scale efficiently, and manage backlogs of millions of messages without slowing down. Here’s how Uber improved Flink for their environment:
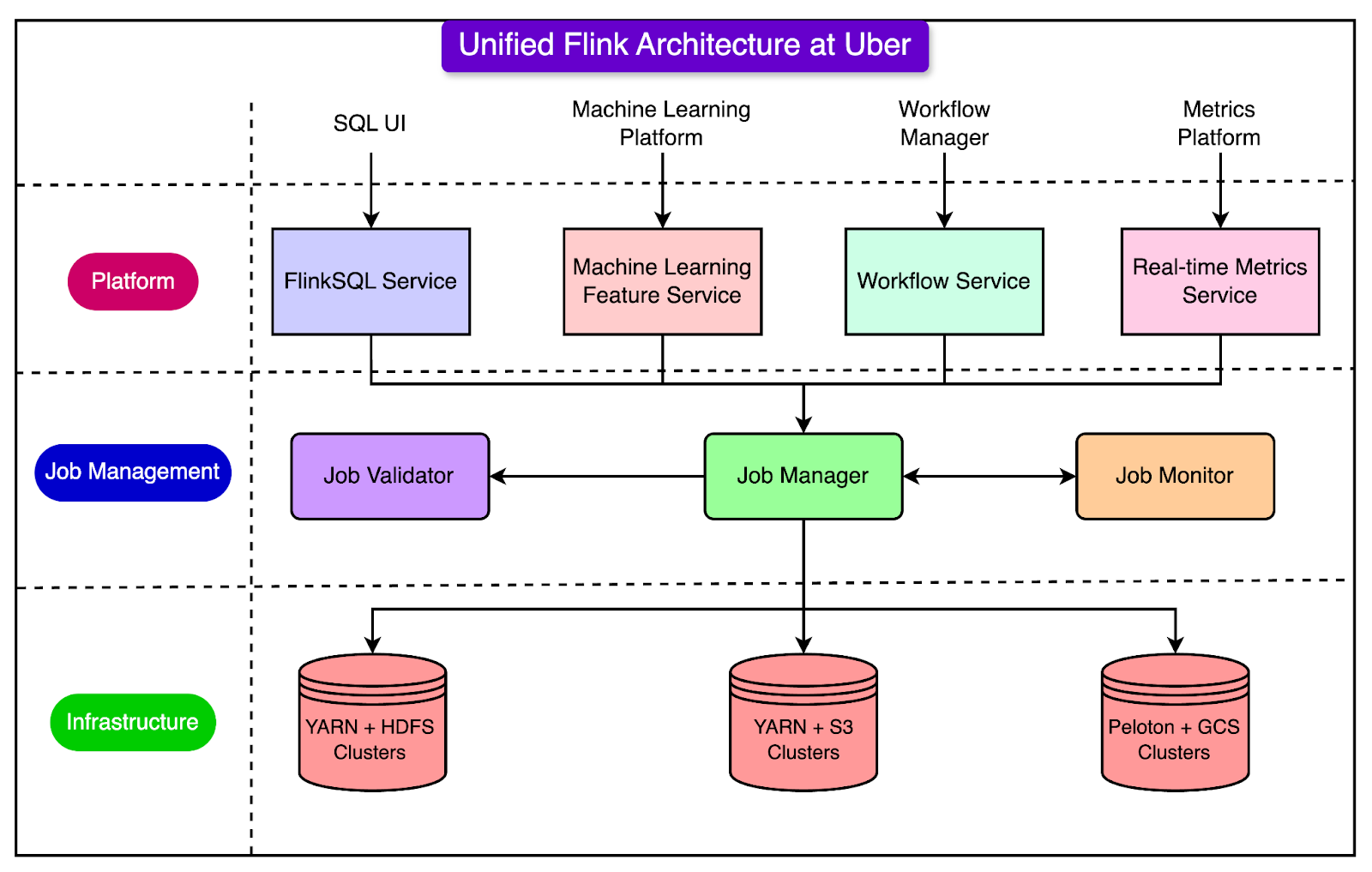
By implementing these changes, Uber has made Flink more reliable and easier to use at scale, allowing thousands of real-time data processing jobs to run efficiently. See the diagram below that shows the Unified Flink Architecture at Uber.
Apache Pinot for Real-Time OLAPFor quick, low-latency data analysis, Uber uses Apache Pinot. Pinot allows real-time analytics on terabytes of data, making it ideal for Uber’s dashboards and operational insights, like tracking ride demand or Uber Eats orders in real-time. Uber enhanced Pinot in several ways:
HDFS for Long-Term StorageUber uses HDFS (Hadoop Distributed File System) as the foundation for its long-term data storage. HDFS stores data from Kafka streams and converts it into more efficient formats, like Parquet, for long-term use. The data stored in HDFS is used for:
Presto for Interactive QueriesPresto is Uber’s go-to query engine for exploring large datasets in real-time. It’s designed to provide fast, distributed SQL queries across multiple data sources, including Pinot, Hive, and others. At Uber, Presto plays a critical role in:
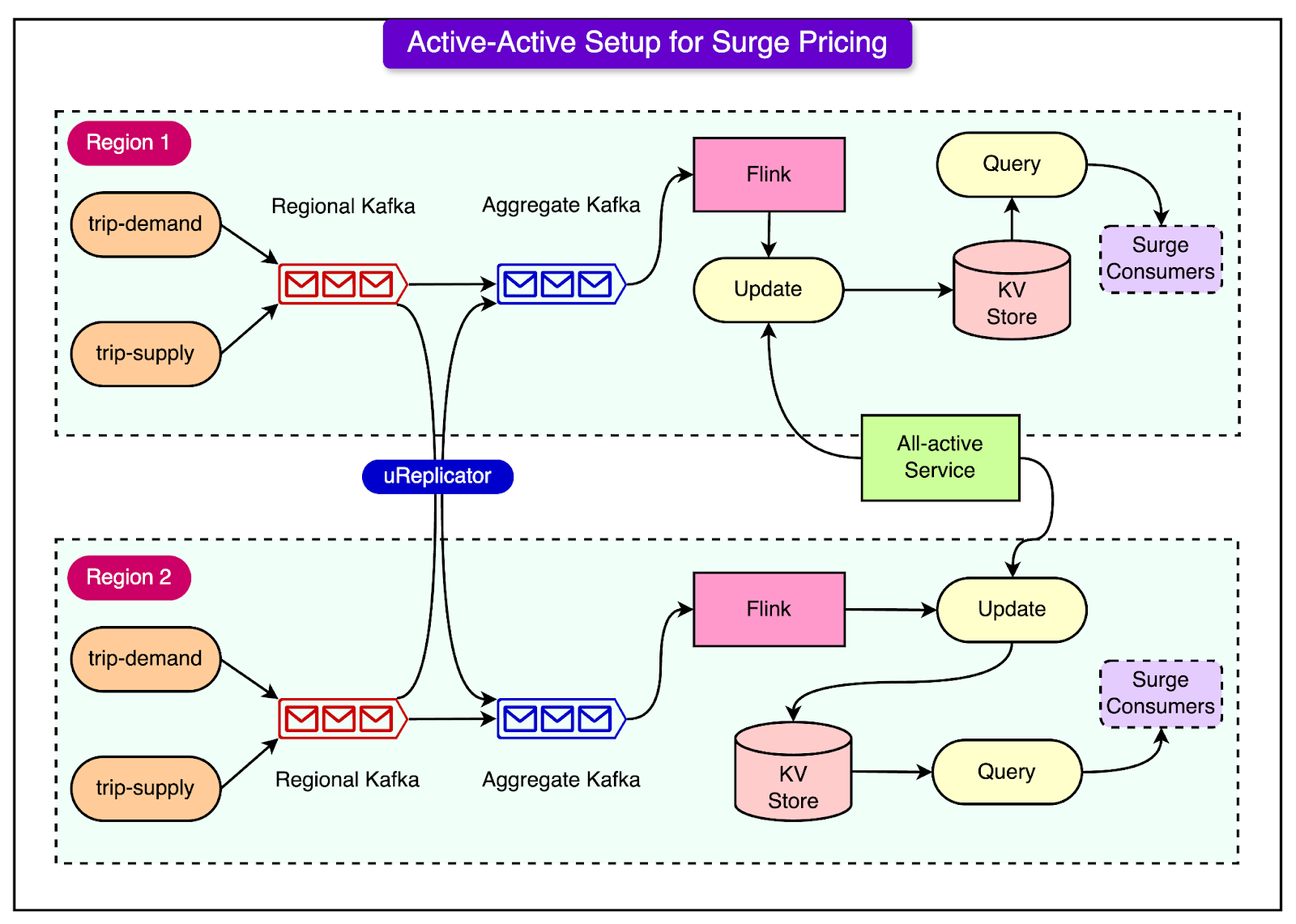
Use CasesUber's real-time data infrastructure powers a variety of critical use cases, from surge pricing to real-time analytics for Uber Eats. Let’s look at some of the most important use cases supported by Uber’s data infrastructure. 1 - Surge PricingOne of Uber’s most well-known features is surge pricing, which adjusts fares based on real-time demand and supply conditions in a given area. To make this happen, Uber uses a data pipeline powered by Kafka and Flink. Kafka ingests streaming data from ride requests and driver availability, while Flink processes this information in real-time to calculate pricing multipliers for each area. The surge pricing pipeline prioritizes data freshness and availability over strict consistency, meaning the system focuses on making quick pricing decisions rather than ensuring every single message is perfectly consistent across all regions. This approach allows Uber to respond to changes in demand within seconds, keeping the marketplace balanced while maximizing driver availability. 2 - UberEats Restaurant ManagerFor restaurant partners, Uber provides a dashboard called the UberEats Restaurant Manager, which offers real-time insights into order trends, sales, and service performance. This dashboard is powered by Apache Pinot, a real-time OLAP system designed to handle large datasets with low-latency queries. Pinot enables fast querying by using pre-aggregated data, meaning that instead of running a complex query every time, certain metrics (like popular menu items or sales figures) are pre-calculated and stored, allowing for quick responses when the restaurant manager requests information. This setup ensures that restaurant owners get real-time feedback, helping them make informed decisions about their business. 3 - Real-Time Prediction MonitoringTo ensure the quality of its machine-learning models, Uber has a system in place for real-time prediction monitoring. This system uses Flink to aggregate predictions from models and compare them against actual outcomes in real-time. With thousands of machine learning models deployed across Uber’s services, monitoring their performance is critical. The system processes millions of data points per second to detect any deviations or inaccuracies in model predictions. By continuously aggregating and analyzing this data, Uber ensures that its models are performing as expected and can quickly identify any issues that need attention. 4 - Ops AutomationDuring the pandemic, Uber needed a way to respond quickly to operational needs, such as limiting the number of customers at restaurants to comply with health regulations. The Ops Automation system for Uber Eats was designed to provide this flexibility. This system uses Presto and Pinot to allow for ad hoc exploration of real-time data, enabling Uber’s operations team to run custom queries on current data about restaurant orders, couriers, and customer activity. For example, if a restaurant was nearing its capacity limit, the system could automatically trigger alerts or actions, such as temporarily pausing orders or notifying couriers to wait outside. This combination of real-time data and flexible querying made it possible for Uber Eats to adapt to fast-changing regulations, helping restaurants stay open while keeping customers and couriers safe. Scaling StrategiesTo handle the massive scale of its operations, Uber has developed several key strategies for ensuring its data systems are highly available, reliable, and able to handle real-time and historical data processing. Three of the most important strategies include the Active-Active Kafka setup, Active-Passive Kafka setup, and a backfill support solution for historical data processing. Let’s look at each in more detail: 1 - Active-Active Kafka SetupFor critical services like surge pricing, ensuring high availability and redundancy is a top priority at Uber. To meet this need, Uber uses an Active-Active Kafka setup across multiple regions. This means that Kafka clusters are deployed in different geographic regions, allowing data to be processed and synchronized across these regions in real-time. The Active-Active setup ensures that if one region experiences a failure—whether due to a network issue or a server problem—Uber’s systems can continue to function smoothly from another region. For example, surge pricing calculations, which depend on real-time supply and demand data, are too important to fail. If the primary region fails, another region can immediately take over and continue processing the data without missing a beat. See the diagram below:
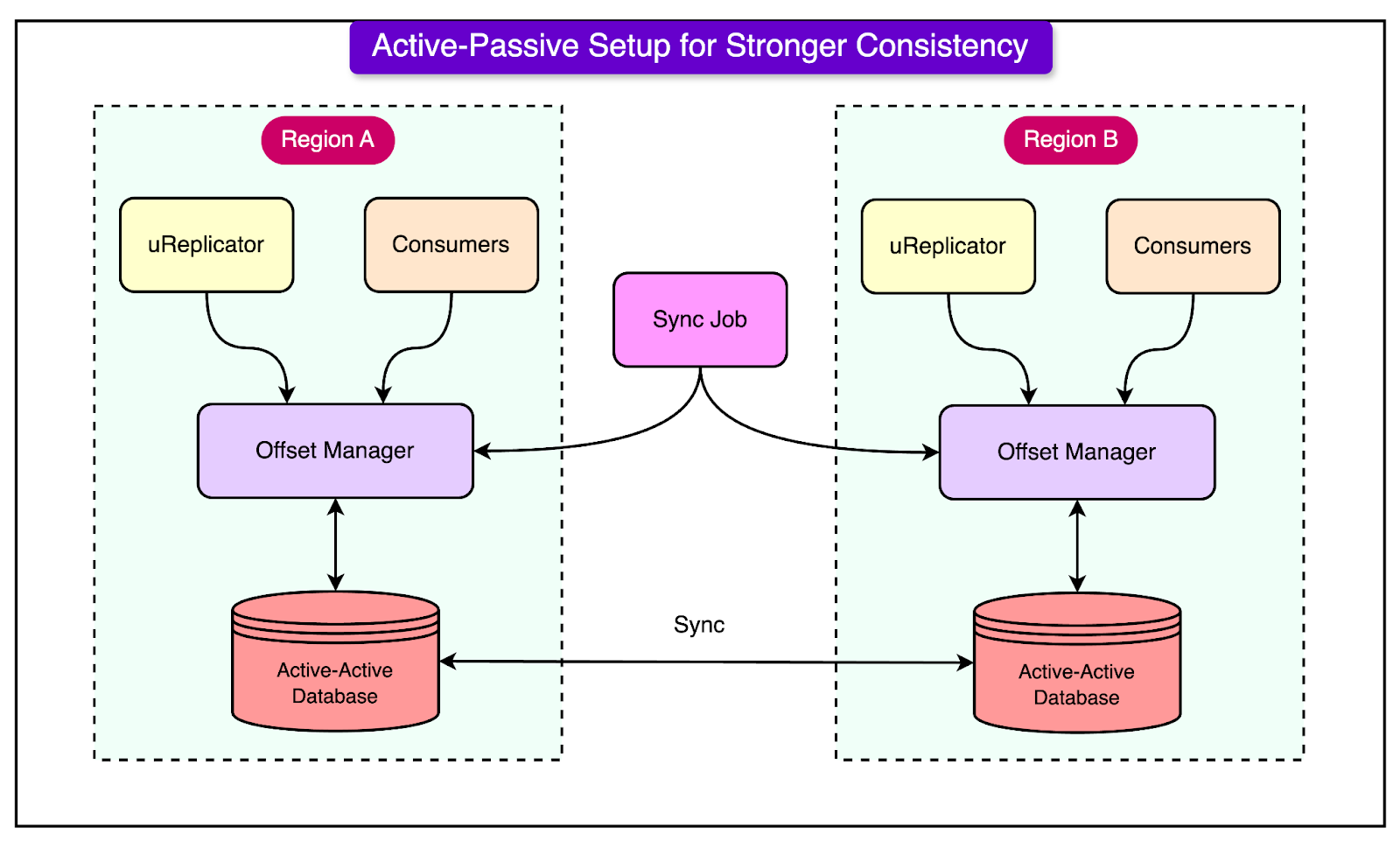
This setup requires careful synchronization of data between regions. Uber uses uReplicator, a tool they developed to replicate Kafka messages across clusters, ensuring the system remains redundant and reliable. Even if one region goes down, the data is preserved and can be quickly restored in the backup region, minimizing disruption to the service. 2 - Active-Passive Kafka SetupIn addition to Uber's Active-Active Kafka setup, the company also employs an Active-Passive Kafka setup for certain services where strong data consistency is critical. While the Active-Active approach prioritizes availability and redundancy, the Active-Passive strategy is designed for use cases that cannot tolerate any data loss and require more stringent consistency guarantees, such as payment processing or auditing. In an Active-Passive Kafka setup, only one consumer (in a specific region, called the primary region) is allowed to process messages from Kafka at any given time. If the primary region fails, the system fails over to a backup (passive) region, which then resumes processing from the same point where the primary left off. This ensures that no data is lost during the failover, preserving message order and maintaining data integrity. See the diagram below that shows the Active-Passive setup.
The key challenge in Active-Passive setups is offset synchronization—ensuring that the consumer in the backup region starts processing from the same point as the primary region. To achieve this, Uber developed a sophisticated offset management service. This service synchronizes offsets between the active and passive regions, using the uReplicator to replicate Kafka messages across clusters and periodically checkpoint the offset mappings between the regions. 3 - Backfill Support with Kappa+ ArchitectureWhile real-time data processing is critical, there are times when Uber needs to reprocess historical data—whether for testing new data pipelines, training machine learning models, or fixing issues after a bug has been discovered. This is where Uber’s backfill support comes in, allowing them to reprocess data streams without causing significant delays or overhead. Uber uses a solution called Kappa+ architecture, which builds on the idea of processing real-time and historical data streams using the same logic. Kappa+ allows Uber to reprocess archived data (stored in systems like Hive or HDFS) while using the same stream-processing framework they use for real-time data—Apache Flink. This eliminates the need for separate systems to handle real-time and batch data, simplifying operations and making the system more efficient. The backfill process also includes optimizations to handle the high throughput of historical data. For example, Uber uses larger memory buffers and fine-tunes Flink jobs to handle out-of-order data or throttling. This ensures that even when processing large volumes of past data, the system performs smoothly without overwhelming resources. Key LessonsUber's journey in building its real-time data infrastructure is packed with valuable lessons. Here are the key ones to keep in mind: 1 - Open-Source AdoptionUber’s decision to adopt open-source technologies was essential for building its infrastructure quickly and scaling effectively. Tools like Kafka, Flink, and Pinot provided solid foundations. However, scaling them to meet Uber’s massive data needs required significant customizations. For example, Uber added features like Kafka cluster federation, FlinkSQL, and Pinot upserts to handle their unique requirements for high availability, low-latency queries, and real-time data streaming. While open-source adoption allowed Uber to innovate fast, they also had to invest heavily in adapting these technologies to fit their system’s scale and complexity. 2 - Rapid System DevelopmentTo keep pace with their evolving business needs, Uber focused on enabling rapid system development. One way they achieved this was through client standardization. By ensuring a consistent interface for interacting with systems, Uber reduced the risk of breaking connections when making updates. Additionally, the use of thin client models (simplified client software that offloads much of the processing to centralized servers) allowed Uber to streamline updates and reduce maintenance overhead. A strong CI/CD (Continuous Integration/Continuous Deployment) framework was also critical. This framework allowed Uber to test, integrate, and deploy updates automatically, reducing the risk of bugs and ensuring that new features could be quickly rolled out without affecting the system’s stability. 3 - Operational AutomationManaging Uber’s massive data infrastructure manually would be impossible, so operational automation became a key priority. Uber emphasized automation for tasks like scaling infrastructure, managing clusters, and deploying new services. This minimized the need for manual intervention, helping the system scale efficiently even as the company grew. In addition to automation, Uber implemented robust monitoring and alerting systems. These systems allow the engineering teams to keep track of the health of the infrastructure in real-time, alerting them to any issues so they can be addressed quickly before they impact critical services like surge pricing or Uber Eats operations. 4 - User Onboarding and DebuggingWith so many engineers, data scientists, and operational teams interacting with Uber’s data infrastructure, automated onboarding was crucial. Uber developed processes that allowed new users to quickly access data, create Kafka topics, and launch Flink jobs without needing deep technical knowledge. Additionally, automated data discovery and auditing tools helped users find the data they needed and ensured that the data flowing through the system was accurate and reliable. By automating these processes, Uber reduced the workload for their core engineering teams and enabled more users to interact with the data systems independently. ConclusionUber's real-time data infrastructure is a vital part of its business operations, supporting everything from surge pricing and UberEats dashboards to real-time machine learning predictions. By leveraging a combination of open-source technologies like Apache Kafka, Flink, Pinot, and Presto, Uber has built a highly scalable and reliable system that processes trillions of messages and petabytes of data every day. Key innovations, such as the Active-Active Kafka setup for high availability and the Kappa+ architecture for seamless backfill support, allow Uber to maintain real-time and historical data processing with minimal disruption. The infrastructure’s success also stems from Uber’s emphasis on customization, rapid development with thin client models, and extensive operational automation. As Uber continues to scale, these technologies and strategies provide the foundation for further innovation, enabling it to respond to new challenges while maintaining the high-performance standards required to serve millions of users globally. Uber's journey highlights the importance of combining open-source solutions with tailored engineering efforts to meet the needs of a fast-growing, data-driven organization. References: SPONSOR USGet your product in front of more than 1,000,000 tech professionals. Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases. Space Fills Up Fast - Reserve Today Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com © 2024 ByteByteGo
|

by "ByteByteGo" <bytebytego@substack.com> - 11:38 - 15 Oct 2024