- Mailing Lists
- in
- How Uber Scaled Cassandra for Tens of Millions of Queries Per Second?
Archives
- By thread 5229
-
By date
- June 2021 10
- July 2021 6
- August 2021 20
- September 2021 21
- October 2021 48
- November 2021 40
- December 2021 23
- January 2022 46
- February 2022 80
- March 2022 109
- April 2022 100
- May 2022 97
- June 2022 105
- July 2022 82
- August 2022 95
- September 2022 103
- October 2022 117
- November 2022 115
- December 2022 102
- January 2023 88
- February 2023 90
- March 2023 116
- April 2023 97
- May 2023 159
- June 2023 145
- July 2023 120
- August 2023 90
- September 2023 102
- October 2023 106
- November 2023 100
- December 2023 74
- January 2024 75
- February 2024 75
- March 2024 78
- April 2024 74
- May 2024 108
- June 2024 98
- July 2024 116
- August 2024 134
- September 2024 130
- October 2024 141
- November 2024 171
- December 2024 115
- January 2025 216
- February 2025 140
- March 2025 220
- April 2025 233
- May 2025 239
- June 2025 303
- July 2025 41
Re: Synter Resource Group, LLC Attempting to contact - UPS 15753937
You're invited! Join us for a McKinsey Live event on the lived experiences of Black residents
How Uber Scaled Cassandra for Tens of Millions of Queries Per Second?
How Uber Scaled Cassandra for Tens of Millions of Queries Per Second?
✂️Cut your QA cycles down to minutes with QA Wolf (Sponsored)
If slow QA processes bottleneck you or your software engineering team and you’re releasing slower because of it — you need to check out QA Wolf. Their AI-native approach gets engineering teams to 80% automated end-to-end test coverage and helps them ship 5x faster by reducing QA cycles from hours to minutes. QA Wolf takes testing off your plate. They can get you:
The benefit? No more manual E2E testing. No more slow QA cycles. No more bugs reaching production. With QA Wolf, Drata’s team of 80+ engineers achieved 4x more test cases and 86% faster QA cycles. Disclaimer: The details in this post have been derived from the Uber Engineering Blog. All credit for the technical details goes to the Uber engineering team. The links to the original articles are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them. Uber’s app is a wonderful piece of engineering, enabling the movement of millions of people around the world and tens of millions of food and grocery deliveries. One common thing across each trip and delivery is the need for low-latency and highly reliable database interactions. Uber made this a reality with their Cassandra database as a service platform. Supporting a multitude of Uber’s mission-critical OLTP workloads for more than six years, the Cassandra database as a service has achieved some amazing stats:
However, this scale wasn’t achieved overnight. Over the years, the Uber engineering team faced numerous operational challenges. In this post, we’ll pull back the curtains from the architecture of Uber’s Cassandra setup and the multiple problems they solved to reach the desired scale. The Cassandra Team ResponsibilitiesAs mentioned, Uber runs Cassandra as a managed service. A dedicated team takes care of the platform's day-to-day operations. Here are the responsibilities of the team:
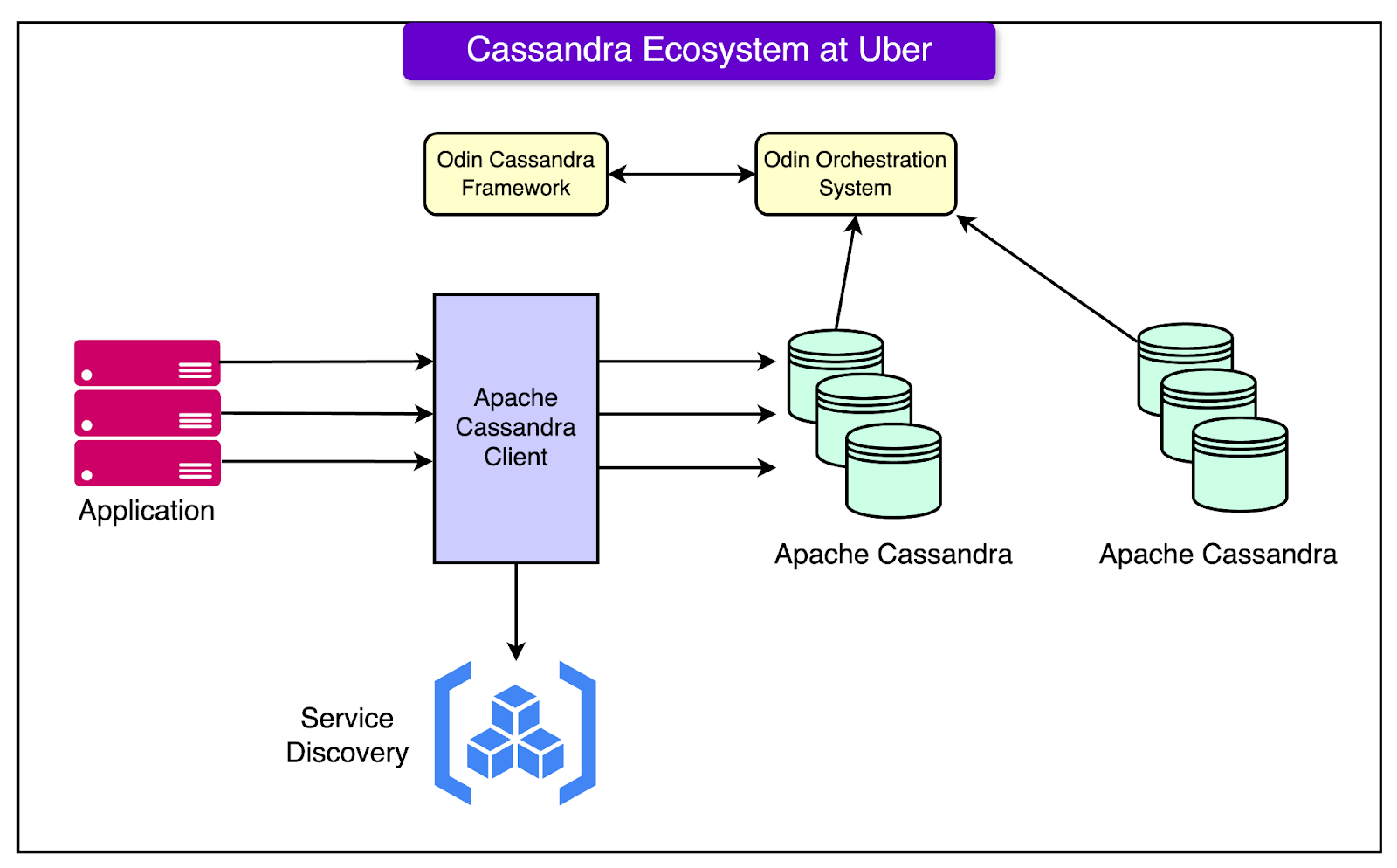
Architecture of Uber’s Cassandra SetupThe diagram below shows the overall Cassandra ecosystem at Uber.
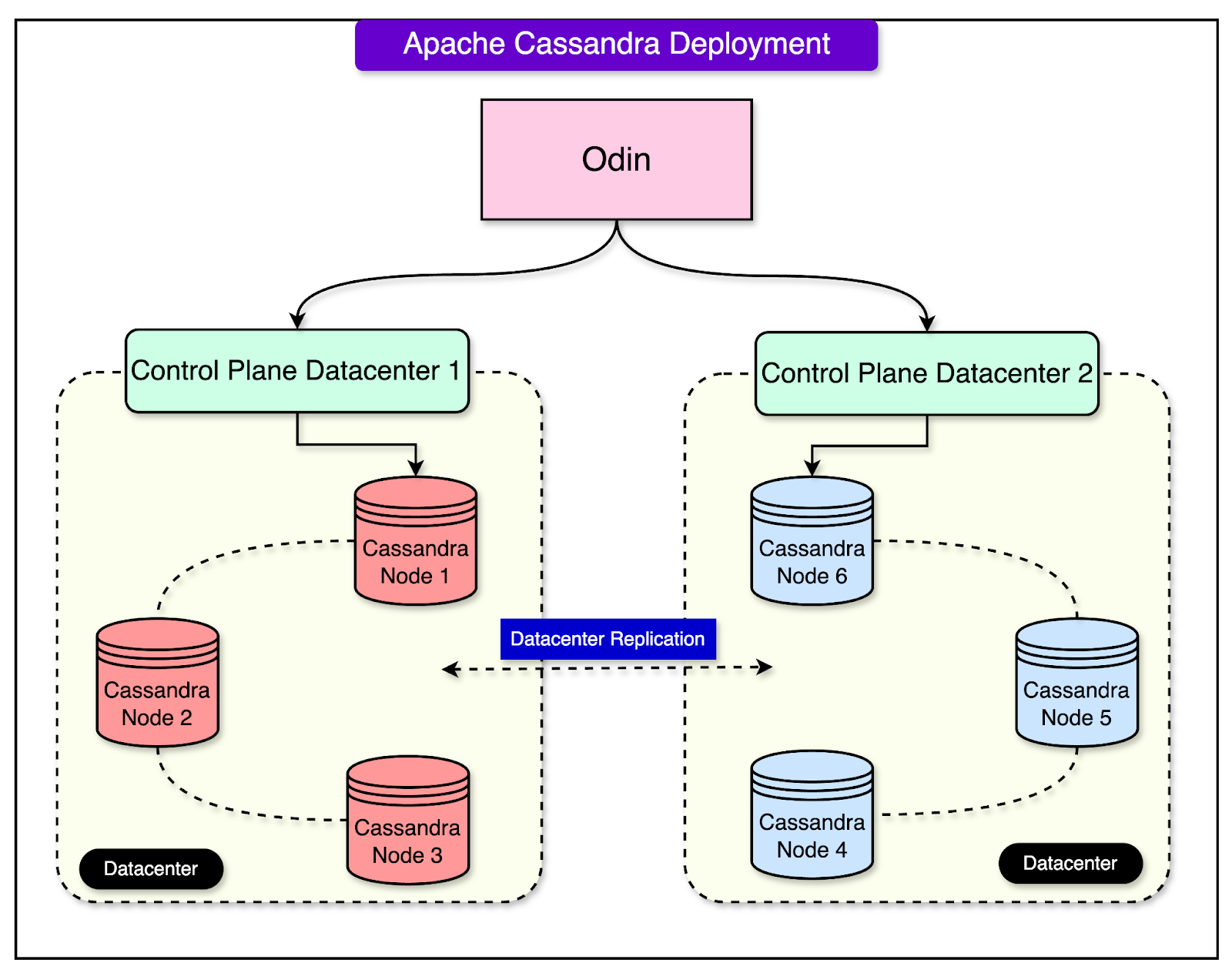
On a high level, the Cassandra cluster spans across regions with the data replicated between them. Uber’s in-house stateful management system Odin handles the configuration and orchestration of thousands of clusters. Together this forms the Cassandra Managed Service that powers different types of workloads, ranging from read-skewed to mixed to write-skewed. See the diagram below to understand Odin’s role:
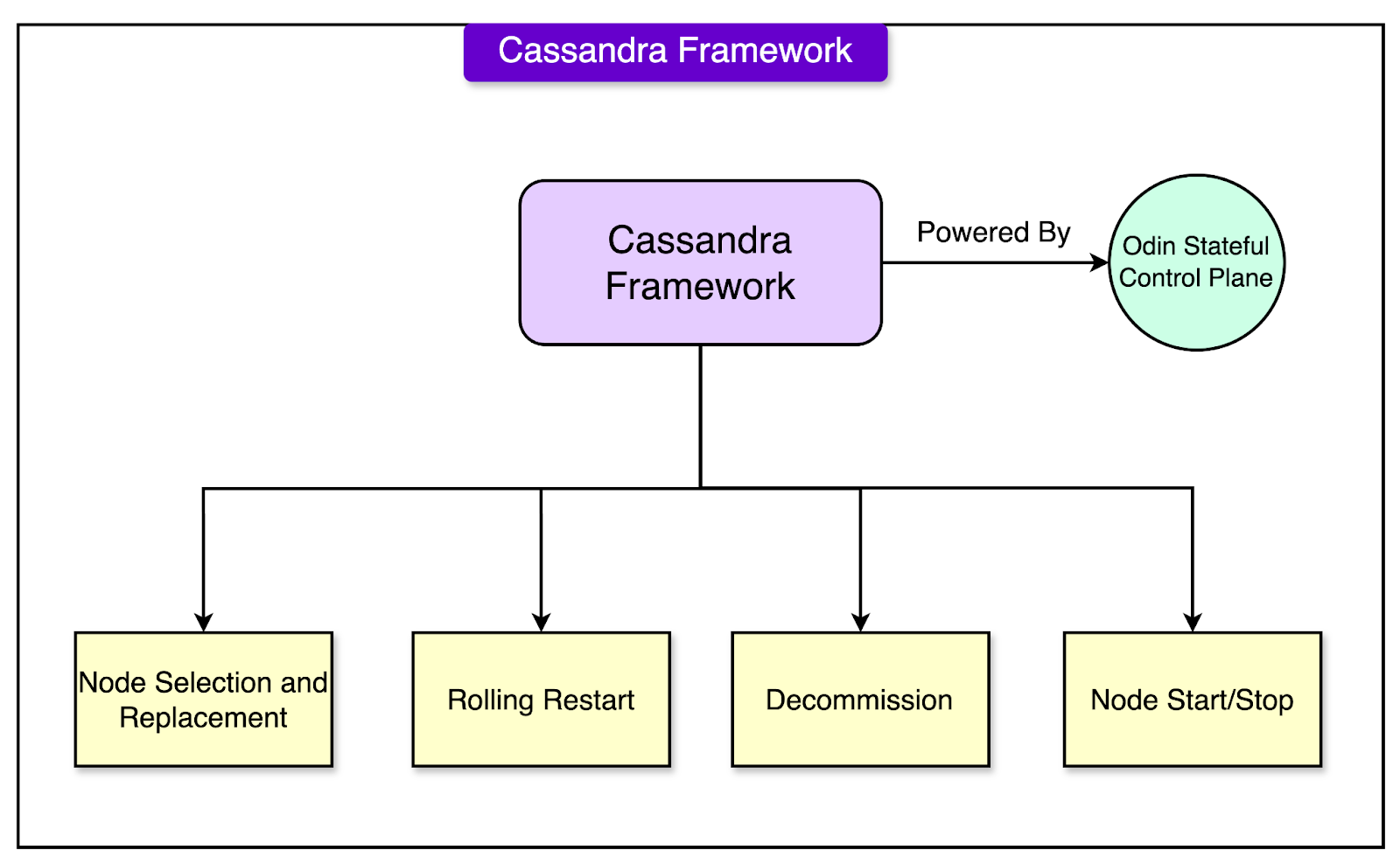
Let’s now look at the major components of the Cassandra database as a service architecture: Cassandra FrameworkThis is an in-house framework developed by Uber and is responsible for the lifecycle of running Cassandra in Uber’s production environment. The framework is powered by Uber’s stateful control plane Odin. It adheres to Odin’s standards and abstracts the complexity of Cassandra’s various functionalities such as:
Cassandra ClientThe Cassandra client is the interface between the applications and the Cassandra clusters. Uber forked the Go and Java open-source Cassandra clients and adapted them to work in Uber’s ecosystem. These clients use the service discovery mechanism to find the initial nodes to connect. This way there’s no need to hardcode the Cassandra endpoints in the application layer. Some of the enhancements made by Uber within these clients are around additional observability features such as:
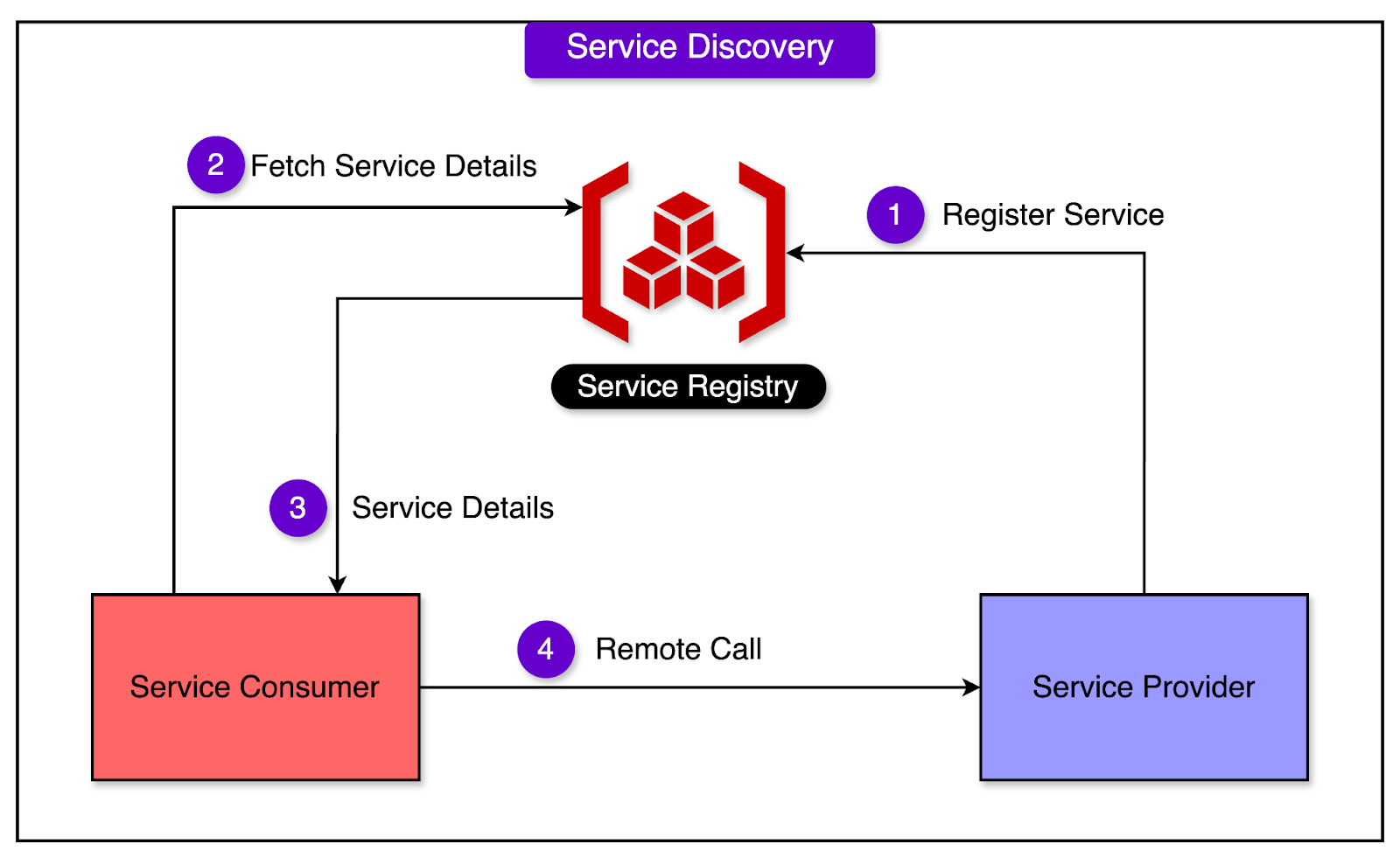
Service DiscoveryService discovery is a critical piece of large-scale distributed systems. It helps discover service instances on the fly, preventing hard coding and unnecessary configurations. See the diagram below that shows the concept of service discovery:
At Uber, each Cassandra cluster is uniquely identified and their nodes can be discovered in real time. Whenever a Cassandra node changes its status (Up, Down, or Decommission), the framework notifies the service discovery about the change. Applications (or service consumers) use the service discovery as the first contact point to connect to a Cassandra node. As the nodes change their status, the service discovery adjusts the list. Challenges of Scaling Uber’s Cassandra ServiceSince the inception of Cassandra’s service at Uber, it has continued to grow every year and more critical use cases have been added. The service was hit with significant reliability challenges. Let’s look at some of the most important ones in more detail. 1 - Unreliable Node ReplacementNode replacement is a critical part of any large-scale fleet. There are multiple reasons for node replacement:
Cassandra provides a graceful node replacement approach that decommissions the existing node and adds a new node. But there were a few hiccups such as:
Every node replacement does not face these issues, but even a small percentage has the potential to impact the entire fleet. It adds operational overhead to teams. For example, even a 95% success rate means 5 failures out of 100 node replacements. In case 500 nodes are replaced every day, 25 failures may easily engage 2 engineers just recovering from these failures. It was important to fix the root problem and that was Cassandra not cleaning up hint files for orphan nodes. Think of it like this: You have a big family message board at home. When a family member moves out, everyone keeps their old sticky notes about them on the board. When you decide to get a new message board, you carefully copy all these notes to the new board. The same was the case with Cassandra. A legit node N1 may store hint files locally for its peer node that was part of the Cassandra ring. However, even when the peer node is not part of the ring, node N1 does not purge the hint files. When N1 decommissions, it transfers all the orphan hint files to its next successor. Over time, the hint files keep growing, resulting in terabytes of garbage hint files. Transferring such a big file could take multiple days. The team made a few changes in Cassandra:
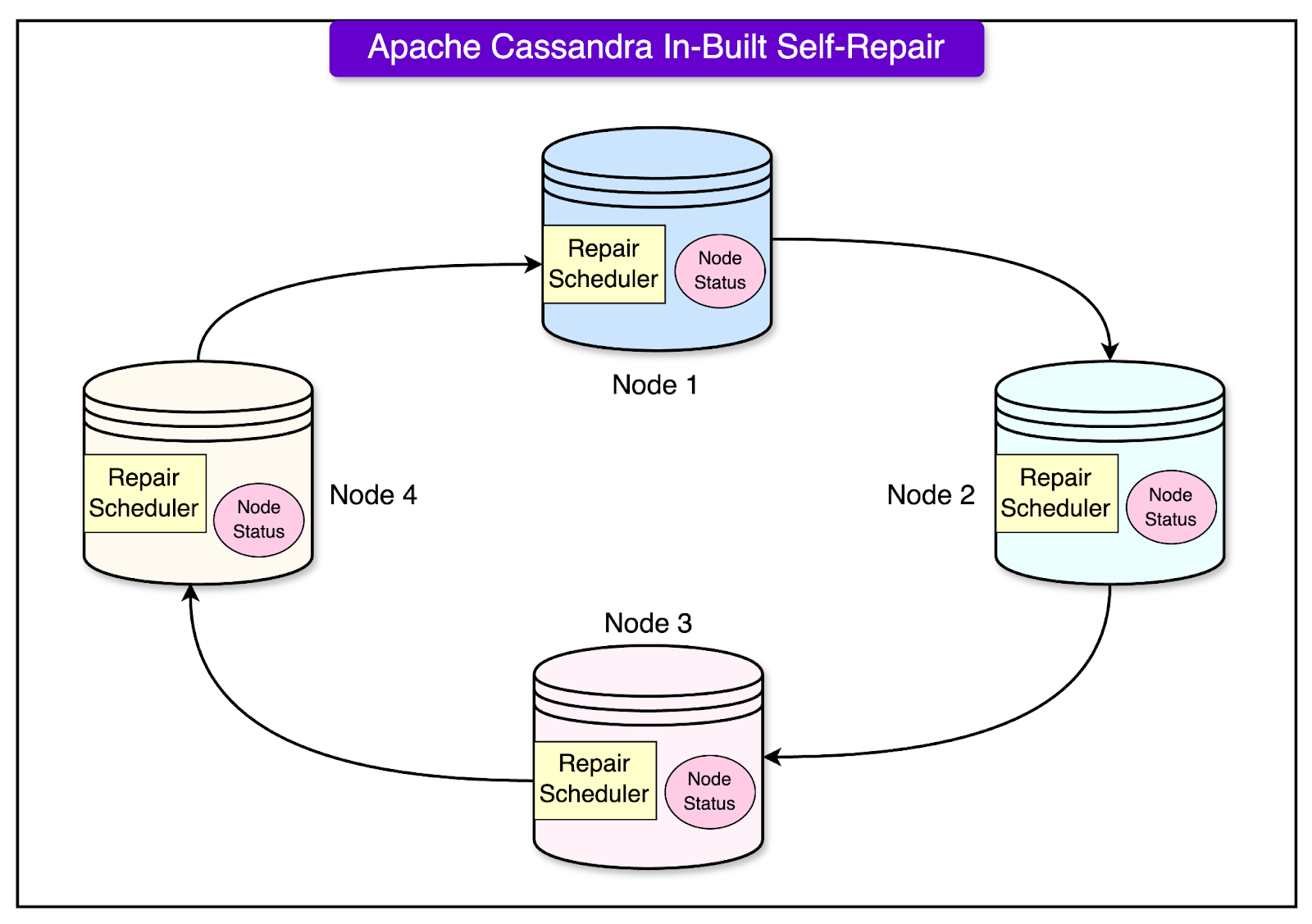
Another fix was related to the node decommission step erroring out due to parallel activity, such as rolling restart due to fleet upgrades. The control plane wasn’t able to probe Cassandra about the decommissioned state. To handle this, they improved Cassandra's bootstrap and decommission path by exposing the state so the control plane could get the current status and take necessary action. See the snippet below that explains the approximate change: Source: Uber’s Engineering Blog After these changes, the node replacement became 99.99% reliable. 2 - Cassandra’s Lightweight Transactions Error RateFew business use cases relied on Cassandra’s Lightweight Transactions at scale. However, these cases suffered higher error rates every other week. It was a general belief that Cassandra’s Lightweight Transactions were unreliable. One of the errors was due to pending range due to multiple simultaneous node replacements. It’s similar to a mismanaged library where too many librarians are replaced at once and tracking books becomes quite difficult. When a new node N2 replaces an old node N1, the Gossip code path on N2 continues pointing to N1’s IP address, resulting in a DNS resolution error. Ultimately, N2 could not function as expected, and restarting it was the only option. Uber’s engineering team improved the error handling inside the Gossip protocol, making Cassandra Lightweight Transactions more robust. 3 - Data Inconsistency IssuesAnother problem was related to data inconsistency due to sluggish Cassandra repairs. Cassandra repairs are an important activity for every Cassandra cluster to fix data inconsistencies. While there are open-source solutions to trigger the repair, Uber did not want a control-plane-based solution. In their view, the repair should be an integral part of Cassandra similar to compaction. With this goal, the Uber Cassandra team implemented the repair orchestration inside Cassandra itself. See the diagram below:
On a high level, they assigned a dedicated thread pool to the repair scheduler. The repair scheduler inside Cassandra maintains a new replicated table for the node status and repair history. The scheduler picks the node that ran the repair first and continues orchestration to ensure each table and all ranges are repaired. Since the implementation of a fully automated repair scheduler inside Cassandra, there has been no dependency on the control plane, which reduced the operational overhead significantly. ConclusionUber’s Cassandra setup is a testament to the importance of incremental changes to build a large-scale fleet. In this post, we’ve taken a deep look at the architecture of Uber’s Cassandra setup and the design of the managed service. We also looked at multiple challenges the engineering team overcame to make the Cassandra database service more reliable at scale. Reference: © 2024 ByteByteGo
|

by "ByteByteGo" <bytebytego@substack.com> - 11:36 - 24 Sep 2024