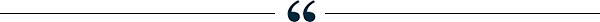Archives
- By thread 5224
-
By date
- June 2021 10
- July 2021 6
- August 2021 20
- September 2021 21
- October 2021 48
- November 2021 40
- December 2021 23
- January 2022 46
- February 2022 80
- March 2022 109
- April 2022 100
- May 2022 97
- June 2022 105
- July 2022 82
- August 2022 95
- September 2022 103
- October 2022 117
- November 2022 115
- December 2022 102
- January 2023 88
- February 2023 90
- March 2023 116
- April 2023 97
- May 2023 159
- June 2023 145
- July 2023 120
- August 2023 90
- September 2023 102
- October 2023 106
- November 2023 100
- December 2023 74
- January 2024 75
- February 2024 75
- March 2024 78
- April 2024 74
- May 2024 108
- June 2024 98
- July 2024 116
- August 2024 134
- September 2024 130
- October 2024 141
- November 2024 171
- December 2024 115
- January 2025 216
- February 2025 140
- March 2025 220
- April 2025 233
- May 2025 239
- June 2025 303
- July 2025 36
-
How to foster a healthier, happier, and more productive workplace
Re:think
Making a difference in employee mental health
by "McKinsey Quarterly" <publishing@email.mckinsey.com> - 03:07 - 29 May 2024 -
Rejoignez-moi au Meetup des utilisateurs New Relic : Paris
Bonjour MD,
Rejoignez-nous à notre prochaine rencontre des utilisateurs, le mercredi 19 juin entre 14h00 et 17h30 pour un après-midi gourmand et bien sûr une conversation sur les données à L'Equiria de Paris ! Nous vous avons concocté un programme bien rempli où vous aurez l'occasion d'entendre nos ingénieurs locaux et de brillants clients.
Vous découvrirez les nouveautés de New Relic dont Mobile User Journeys, Session Replay, AI Monitoring et New Relic AI. Et nous vous donnerons également un avant-goût de nos prochains aperçus limités, ainsi que notre feuille de route de ce que nous appelons la troisième phase de l'observabilité, Observability 3.0.
Nous plongerons ensuite dans une série de conférences éclair sur :
- Sidekick - l'enregistrement de scripts synthétiques
- Les toutes dernières nouveautés de CodeStream
- Le paramétrage des cookies dans les contrôles Synthetics
- La présentation des visualisations personnalisées
- Un zoom sur NRQL
Pour terminer l'après-midi, nous remonterons le temps jusqu'en 2013 avec notre version du classique jeu électronique, « Flappy-Birds », animé par New Relic Browser, APM et Logs. Vous pourrez jouer sur votre appareil mobile et les scores s'afficheront en direct sur un tableau de classement. Les meilleurs scores seront récompensés.
Nous terminerons la journée par une session de networking suivie d'une petite restauration et boissons.
Réservez votre place dès maintenant.
N'oubliez pas d'apporter votre ordinateur portable. Nous avons hâte de vous retrouver !
Cordialement,
Harry
Harry Kimpel
Ingénieur principal des relations avec les développeurs - EMEA

View this online · Unsubscribe
This email was sent to info@learn.odoo.com. If you no longer wish to receive these emails, click on the following link: Unsubscribe
by "Harry Kimpel" <emeamarketing@newrelic.com> - 05:19 - 29 May 2024 -
How cities are faring postpandemic
Only McKinsey
Living in a hybrid world Brought to you by Liz Hilton Segel, chief client officer and managing partner, global industry practices, & Homayoun Hatami, managing partner, global client capabilities
•
Empty desks. After the COVID-19 pandemic, cities with a glut of office space could see continued declines in the commercial-real-estate market as companies reduce their footprints or relocate to lower-cost areas. But cities can avoid an “urban doom loop” because property tax rates are variable, Harvard University economist Ed Glaeser says in an episode of the McKinsey Global Institute’s podcast Forward Thinking, cohosted by McKinsey partner Michael Chui.
—Edited by Jana Zabkova, senior editor, New York
This email contains information about McKinsey's research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this newsletter because you subscribed to the Only McKinsey newsletter, formerly called On Point.
Copyright © 2024 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "Only McKinsey" <publishing@email.mckinsey.com> - 01:24 - 29 May 2024 -
Tire Pressure Monitoring System - Keep Your Fleet Safe on the Road.
Tire Pressure Monitoring System - Keep Your Fleet Safe on the Road.
TPMS software provides analytics to enhance vehicle performance and prevent accidents.
Eliminate the need for manual tire pressure checks. Know tire health and escalate safety.
Find out what makes our software stand out from the crowd
Compatible with any TPMS
sensor
Our software is flexible to work with any type of tire pressure monitoring sensor. Let your clients have the comfort of choosing the sensor according to their needs.

Tire Pressure Monitoring
Fleet managers can ensure that their vehicles always run on properly inflated tires, reducing the risk of accidents caused by underinflated or over-inflated tires.

Tire Temperature Monitoring
Fleet managers can identify tires that are operating at high temperatures and take corrective action to reduce heat buildup, thus extending tire life and reducing costs.

Real-time monitoring
TPMS constantly monitors tire pressure and temperature and sends real-time alerts if the pressure or temperature drops or rises below a certain threshold.

Empower your Clients with an Advanced Tire Pressure Monitoring System


Uffizio Technologies Pvt. Ltd., 4th Floor, Metropolis, Opp. S.T Workshop, Valsad, Gujarat, 396001, India





by "Sunny Thakur" <sunny.thakur@uffizio.com> - 08:00 - 28 May 2024 -
Are you using gen AI to create real value?
Intersection
Get your briefing 
Companies gearing up for a gen AI reset first need to determine their strategy for implementing gen AI. Choosing the right archetype can help create a competitive edge, say McKinsey’s Alex Singla, Alexander Sukharevsky, Eric Lamarre, and Rodney Zemmel. To learn how to take your gen AI capabilities to the next level, check out the latest edition of the Five Fifty.
Share these insights
Did you enjoy this newsletter? Forward it to colleagues and friends so they can subscribe too. Was this issue forwarded to you? Sign up for it and sample our 40+ other free email subscriptions here.
This email contains information about McKinsey’s research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this email because you subscribed to our McKinsey Quarterly Five Fifty alert list.
Copyright © 2024 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "McKinsey Quarterly Five Fifty" <publishing@email.mckinsey.com> - 05:00 - 28 May 2024 -
The Scaling Journey of LinkedIn
The Scaling Journey of LinkedIn
10 Insights On Real-World Container Usage (Sponsored) As organizations have scaled their containerized environments, many are now exploring the next technology frontier of containers by building next-gen applications, enhancing developer productivity, and optimizing costs.͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ Forwarded this email? Subscribe here for more10 Insights On Real-World Container Usage (Sponsored)

As organizations have scaled their containerized environments, many are now exploring the next technology frontier of containers by building next-gen applications, enhancing developer productivity, and optimizing costs.
Datadog analyzed telemetry data from over 2.4 billion containers to understand the present container landscape, with key insights into:
Trends in adoption for technologies such as serverless containers and GPU-based compute on containers
How organizations are managing container costs and resources through ARM-based compute and horizontal pod autoscaling
Popular workload categories and languages for containers
LinkedIn is one of the biggest social networks in the world with almost a billion members.
But the platform had humble beginnings.
The idea of LinkedIn was conceived in Reid Hoffman’s living room in 2002 and it was officially launched in May 2003. There were 11 other co-founders from Paypal and Socialnet who collaborated closely with Reid Hoffman on this project.
The initial start was slow and after the first month of operation, LinkedIn had just around 4300 members. Most of them came through personal invitations by the founding members.
However, LinkedIn’s user base grew exponentially over time and so did the content hosted on the platform. In a few years, LinkedIn was serving tens of thousands of web pages every second of every day to users all over the world.
This unprecedented growth had one major implication.
LinkedIn had to take on some extraordinary challenges to scale its application to meet the growing demand. While it would’ve been tough for the developers involved in the multiple projects, it’s a gold mine of lessons for any developer.
In this article, we will look at the various tools and techniques LinkedIn adopted to scale the platform.
Humble Beginning with Leo
Like many startups, LinkedIn also began life with a monolithic architecture.
There was one big application that took care of all the functionality needed for the website. It hosted web servlets for the various pages, handled business logic, and also connected to the database layer.
This monolithic application was internally known as Leo. Yes, it was as magnificent as MGM’s Leo the Lion.
The below diagram represents the concept of Leo on a high level.
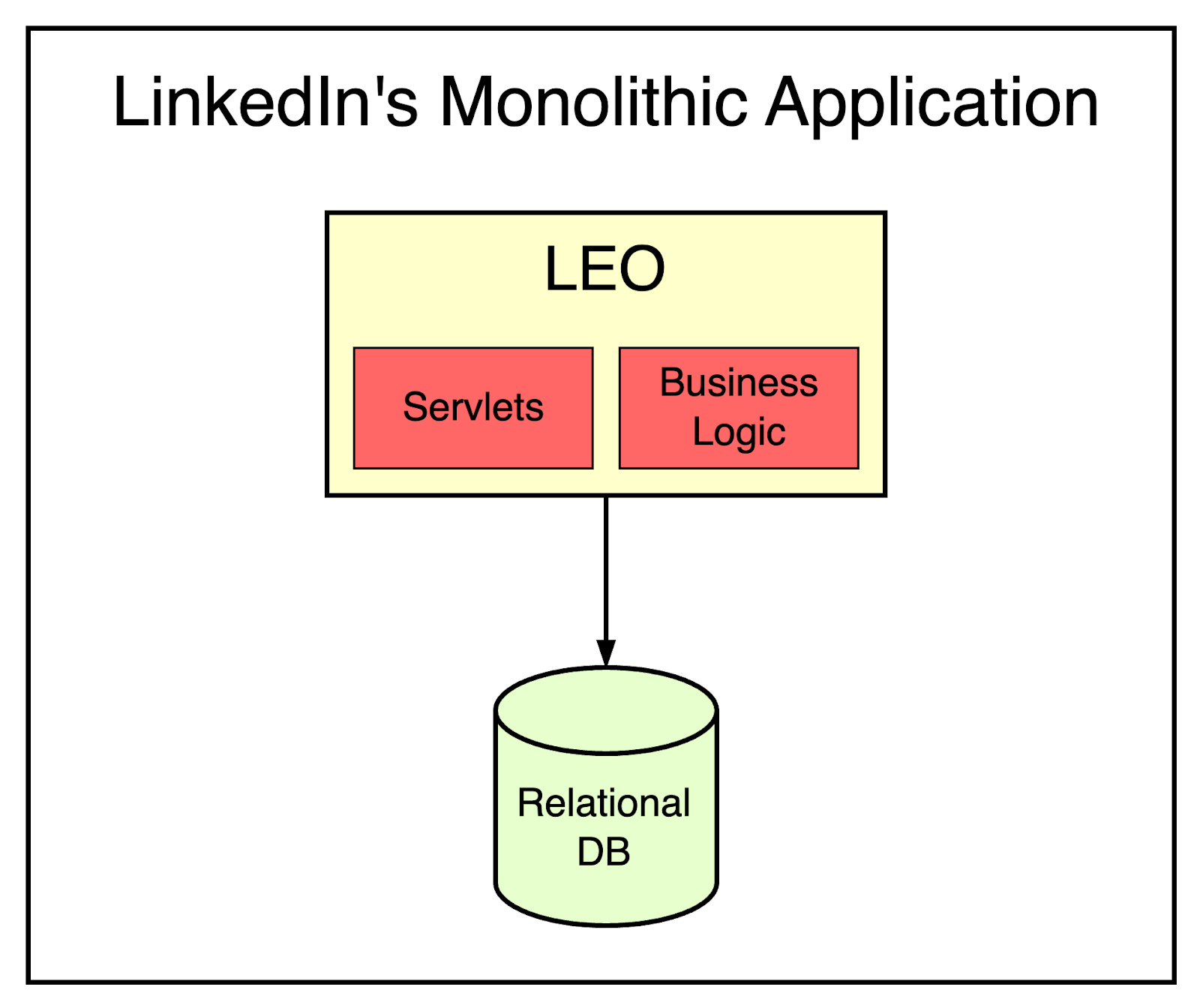
However, as the platform grew in terms of functionality and complexity, the monolith wasn’t enough.
The First Need of Scaling
The first pinch point came in the form of two important requirements:
Managing member-to-member connections
Search capabilities
Let’s look at both.
Member Graph Service
A social network depends on connections between people.
Therefore, it was critical for LinkedIn to effectively manage member to member connections. For example, LinkedIn shows the graph distance and common connections whenever we view a user profile on the site.
To display this small piece of data, they needed to perform low-latency graph computations, creating the need for a system that can query connection data using in-memory graph traversals. The in-memory requirement is key to realizing the performance goals of the system.
Such a system had a completely different usage profile and scaling need as compared to Leo.
Therefore, the engineers at LinkedIn built a distributed and partitioned graph system that can store millions of members and their connections. It could also handle hundreds of thousands of queries per second (QPS).
The system was called Cloud and it happened to be the first service at LinkedIn. It consisted of three major subcomponents:
GraphDB - a partitioned graph database that was also replicated for high availability and durability
Network Cache Service - a distributed cache that stores a member’s network and serves queries requiring second-degree knowledge
API Layer - the access point for the front end to query the data.
The below diagram shows the high-level architecture of the member graph service.
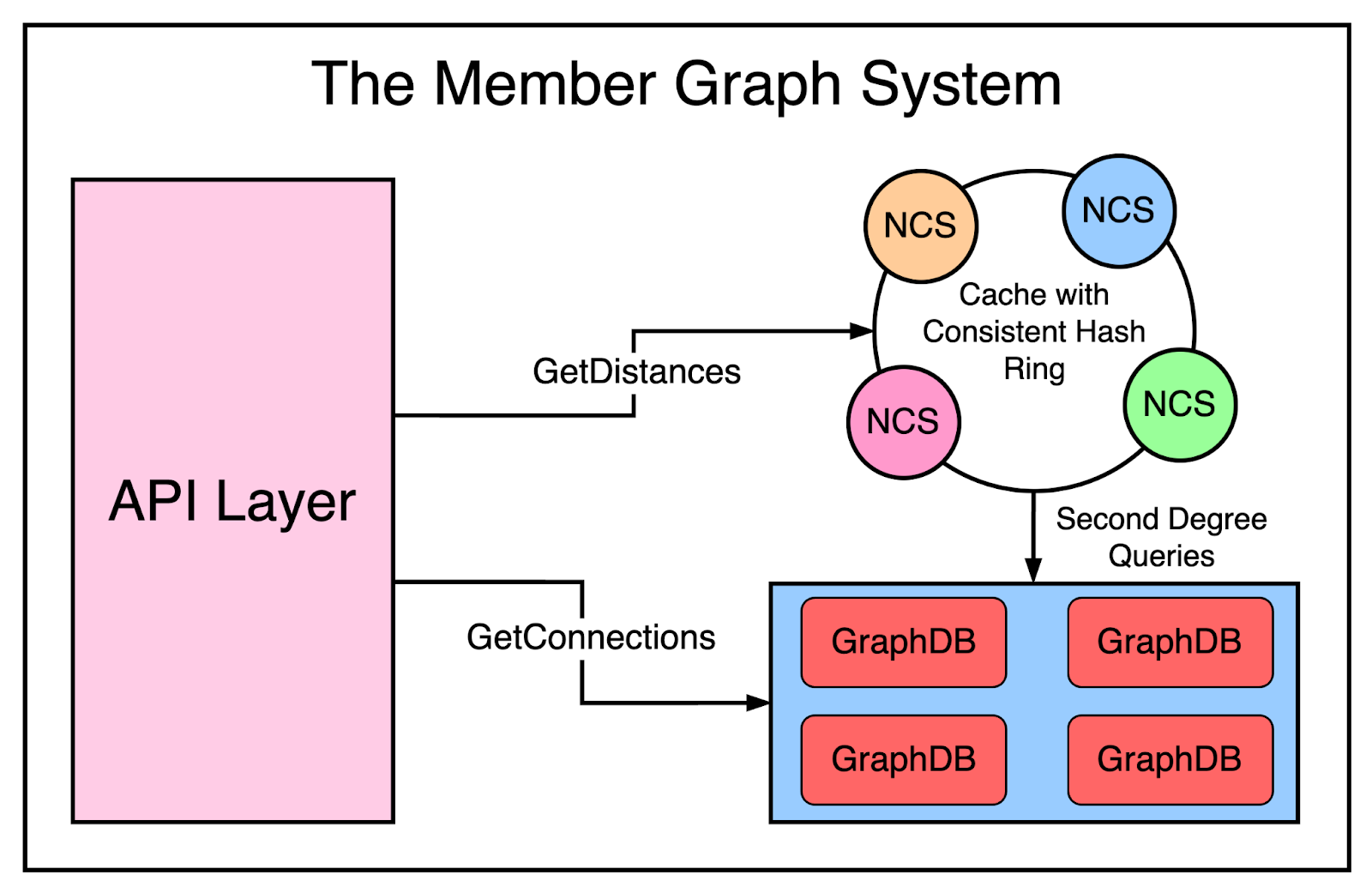
To keep it separate from Leo, LinkedIn utilized Java RPC for communication between the monolith and the graph service.
Search Service
Around the same time, LinkedIn needed to support another critical functionality - the capability to search people and topics.
It is a core feature for LinkedIn where members can use the platform to search for people, jobs, companies, and other professional resources. Also, this search feature should aim to provide deeply personalized search results based on a member’s identity and relationships.
To support this requirement, a new search service was built using Lucene.
Lucene is an open-source library that provides three functionalities:
Building a search index
Searching the index for matching entities
Determining the importance of these entities through relevant scores
Once the search service was built, both the monolith and the new member graph service started feeding data into this service.
While the building of these services solved key requirements, the continued growth in traffic on the main website meant that Leo also had to scale.
Let’s look at how that was achieved.
Scaling Leo
As LinkedIn grew in popularity, the website grew and Leo’s roles and responsibilities also increased. Naturally, the once-simple web application became more complex.
So - how was Leo scaled?
One straightforward method was to spin up multiple instances of Leo and run them behind a Load Balancer that routes traffic to these instances.
It was a nice solution but it only involved the application layer of Leo and not the database. However, the increased workload was negatively impacting the performance of LinkedIn’s most critical system - its member profile database that stored the personal information of every registered user. Needless to say, this was the heart of LinkedIn.
A quick and easy fix for this was going for classic vertical scaling by throwing additional compute capacity and memory for running the database. It’s a good approach to buy some time and get some breathing space for the team to think about a long-term solution to scaling the database.
The member profile database had one major issue. It handled both read and write traffic, resulting in a heavy load.
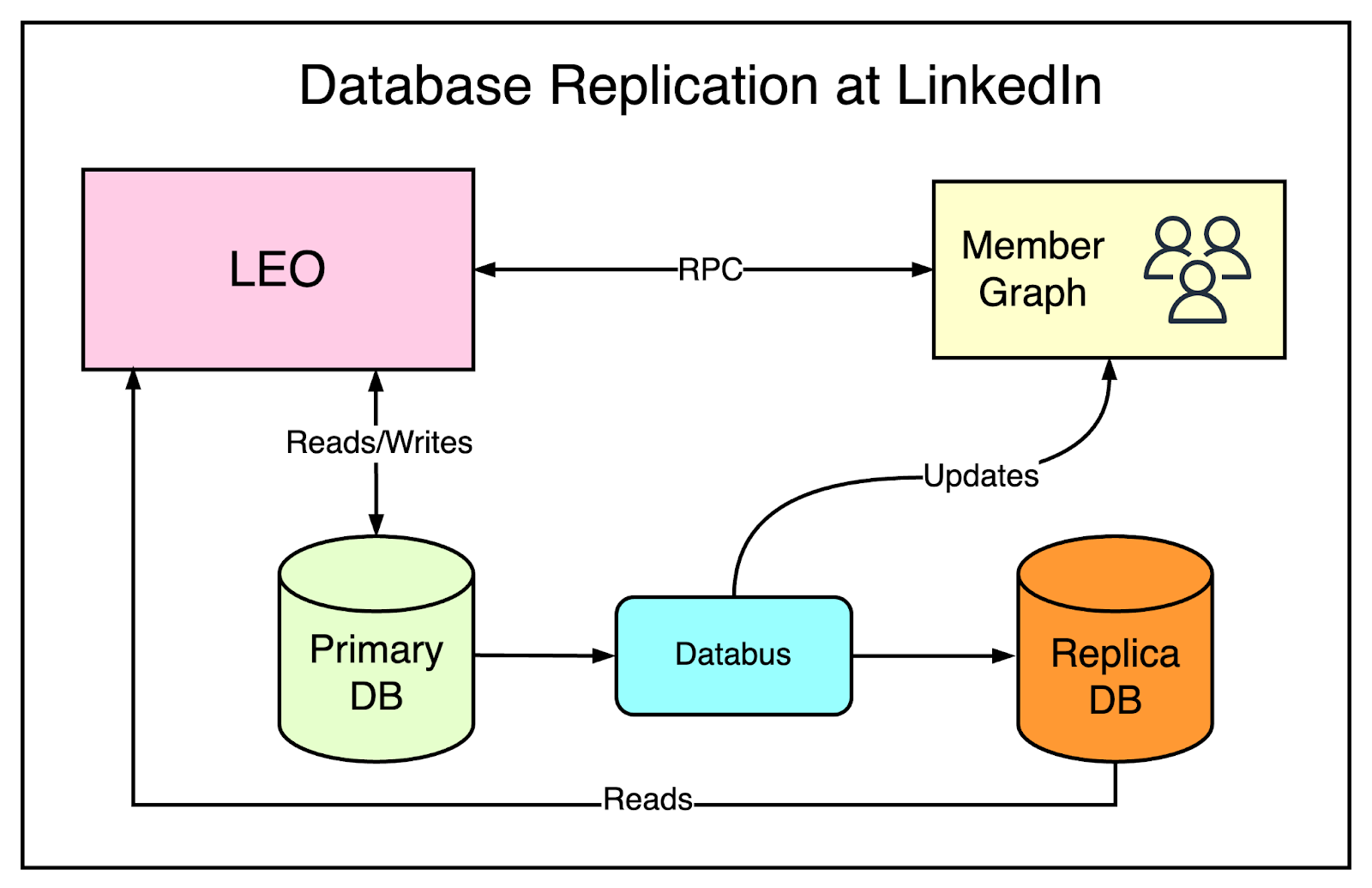
To scale it out, the team turned to database replication.
New replica databases were created. These replicas were a copy of the primary database and stayed in sync with the primary using Databus. While writes were still handled by the primary database, the trick was to send the majority of read requests to the replica databases.
However, data replication always results in some amount of replication lag. If a request reads from the primary database and the replica database at the same time, it can get different results because the replication may not have completed. A classic example is a user updating her profile information and not able to see the updated data on accessing the profile just after the update.
To deal with issues like this, special logic was built to decide when it was safe or consistent to read from the replica database versus the primary database.
The below diagram tries to represent the architecture of LinkedIn along with database replication
While replication solved a major scaling challenge for LinkedIn, the website began to see more and more traffic. Also, from a product point of view, LinkedIn was evolving rapidly.
It created two major challenges:
Leo was often going down in production and it was becoming more difficult to recover from failures
Releasing new features became tough due to the complexity of the monolithic application
High availability is a critical requirement for LinkedIn. A social network being down can create serious ripple effects for user adoption. It soon became obvious that they had to kill Leo and break apart the monolithic application into more manageable pieces.
Latest articles
If you’re not a paid subscriber, here’s what you missed.
To receive all the full articles and support ByteByteGo, consider subscribing:
Killing Leo with Service-Oriented Architecture
While it sounds easy to break apart the monolithic application, it’s not easy to achieve in practice.
You want to perform the migration in a seamless manner without impacting the existing functionality. Think of it as changing a car’s tires while it is moving on the highway at 60 miles per hour.
The engineers at LinkedIn started to extract functionalities from the monolith in their own separate services. Each service contained APIs and business logic specific to a particular functionality.
Next, services to handle the presentation layer were built such as public profiles or recruiter products. For any new product, brand-new services were created completely outside of Leo.
Over time, the effort towards SOA led to the emergence of vertical slices where each slice handled a specific functional area.
The frontend servers fetched data from different domains and handled the presentation logic to build the HTML via JSPs.
The mid-tier services provided API access to data models.
The backend data services provided consistent access to the database.
By 2010, LinkedIn had already built over 150 separate services and by 2015, they had over 750 services.
The below diagram represents a glimpse of the SOA-based design at LinkedIn:
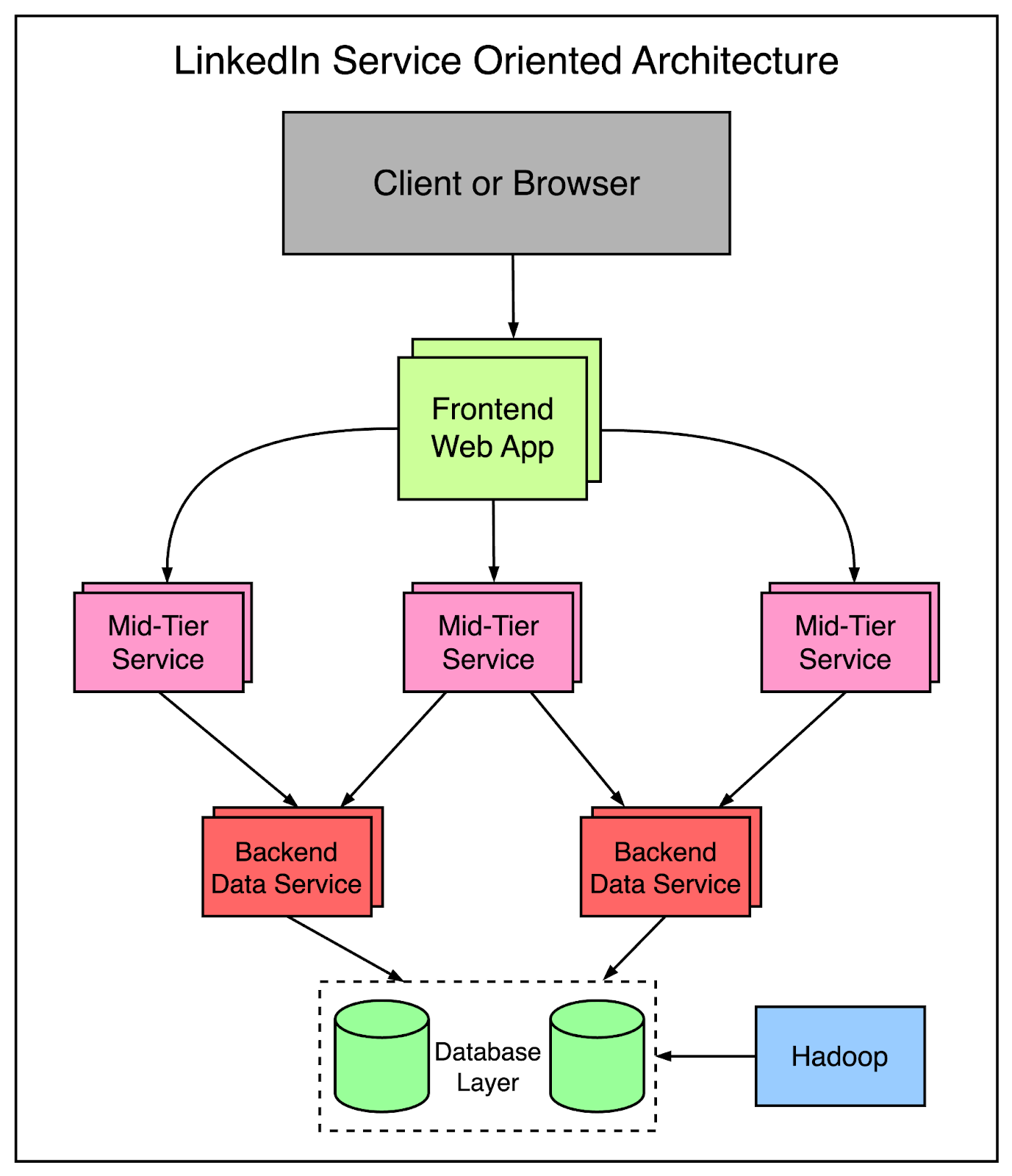
At this point, you may wonder what was the benefit of this massive change.
First, these services were built in a stateless manner. Scaling can be achieved by spinning up new instances of a service and putting them behind a load balancer. Such an approach is known as horizontal scaling and it was more cost-effective compared to scaling the monolithic application.
Second, each service was expected to define how much load it could take and the engineering team was able to build out early provisioning and performance monitoring capabilities to support any deviations.
Managing Hypergrowth with Caching
It’s always a good thing for a business owner to achieve an exponential amount of growth.
Of course, it does create a bunch of problems. Happy problems but still problems that must be solved.
Despite moving to service-oriented architecture and going for replicated databases, LinkedIn had to scale even further.
This led to the adoption of caching.
Many applications started to introduce mid-tier caching layers like memcached or couchbase. These caches were storing derived data from multiple domains. Also, they added caches to the data layers by using Voldemort to store precomputed results when appropriate.
However, if you’ve worked with caching, you would know that caching brings along with it a bunch of new challenges in terms of invalidations, managing consistency, and performance.
Over time, the LinkedIn team got rid of many of the mid-tier caches.
Caches were kept close to the data store in order to reduce the latency and support horizontal scalability without the cognitive load of maintaining multiple caching layers.
Data Collection with Kafka
As LinkedIn’s footprint grew, it also found itself managing a huge amount of data.
Naturally, when any company acquires a lot of data, it wants to put that data to good use for growing the business and offering more valuable services to the users. However, to make meaningful conclusions from the data, they have to collect the data and bring it in one place such as a data warehouse.
LinkedIn started developing many custom data pipelines for streaming and queuing data from one system to another.
Some of the applications were as follows:
Aggregating logs from every service
Collecting data regarding tracking events such as pageviews
Queuing of emails for LinkedIn’s inMail messaging system
Keeping the search system up to date whenever someone updates their profile
As LinkedIn grew, it needed more of these custom pipelines and each individual pipeline also had to scale to keep up with the load.
Something had to be done to support this requirement.
This led to the development of Kafka, a distributed pub-sub messaging platform. It was built around the concept of a commit log and its main goal was to enable speed and scalability.
Kafka became a universal data pipeline at LinkedIn and enabled near real-time access to any data source. It empowered the various Hadoop jobs and allowed LinkedIn to build real-time analytics, and improve site monitoring and alerting.
See the below diagram that shows the role of Kafka at LinkedIn.
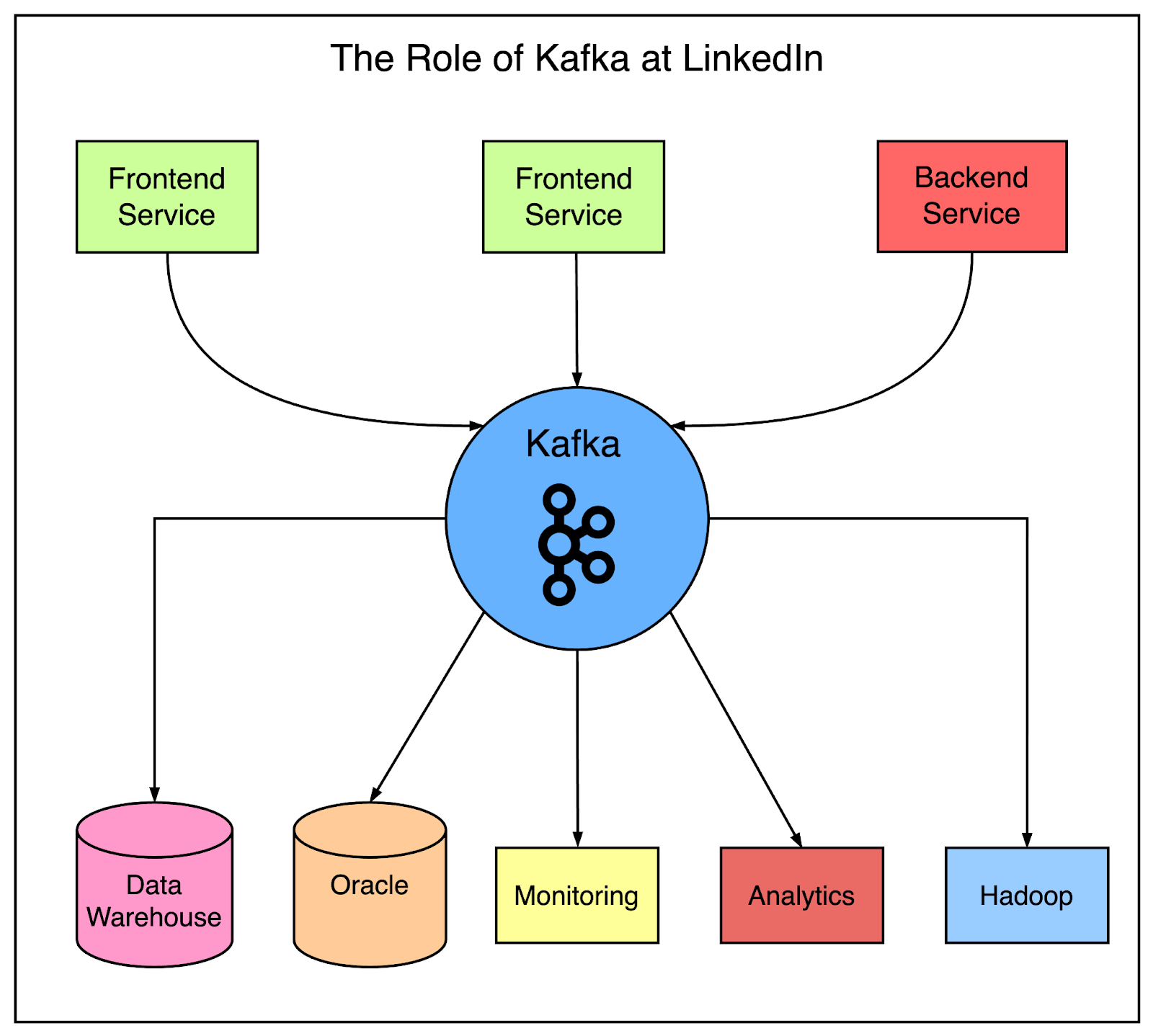
Over time, Kafka became an integral part of LinkedIn’s architecture. Some latest facts about Kafka adoption at LinkedIn are as follows:
Over 100 Kafka clusters with more than 4000 brokers
100K topics and 7 million partitions
7 trillion messages handled per day
Scaling the Organization with Inversion
While scaling is often thought of as a software concern, LinkedIn realized very soon that this is not true.
At some time, you also need to scale up at an organizational level.
At LinkedIn, the organizational scaling was carried out via an internal initiative called Inversion.
Inversion put a pause on feature development and allowed the entire engineering organization to focus on improving the tooling and deployment, infrastructure and developer productivity. In other words, they decided to focus on improving the developer experience.
The goal of Inversion was to increase the engineering capability of the development teams so that new scalable products for the future could be built efficiently and in a cost-effective way.
Let’s look at a few significant tools that were built as part of this initiative:
Rest.li
During the transformation from Leo to a service-oriented architecture, the extracted APIs were based on Java-based RPC.
Java-based RPC made sense in the early days but it was no longer sufficient as LinkedIn’s systems evolved into a polyglot ecosystem with services being written in Java, Node.js, Python, Ruby and so on. For example, it was becoming hard for mobile services written in Node.js to communicate with Java object-based RPC services.
Also, the earlier APIs were tightly coupled with the presentation layer, making it difficult to make changes.
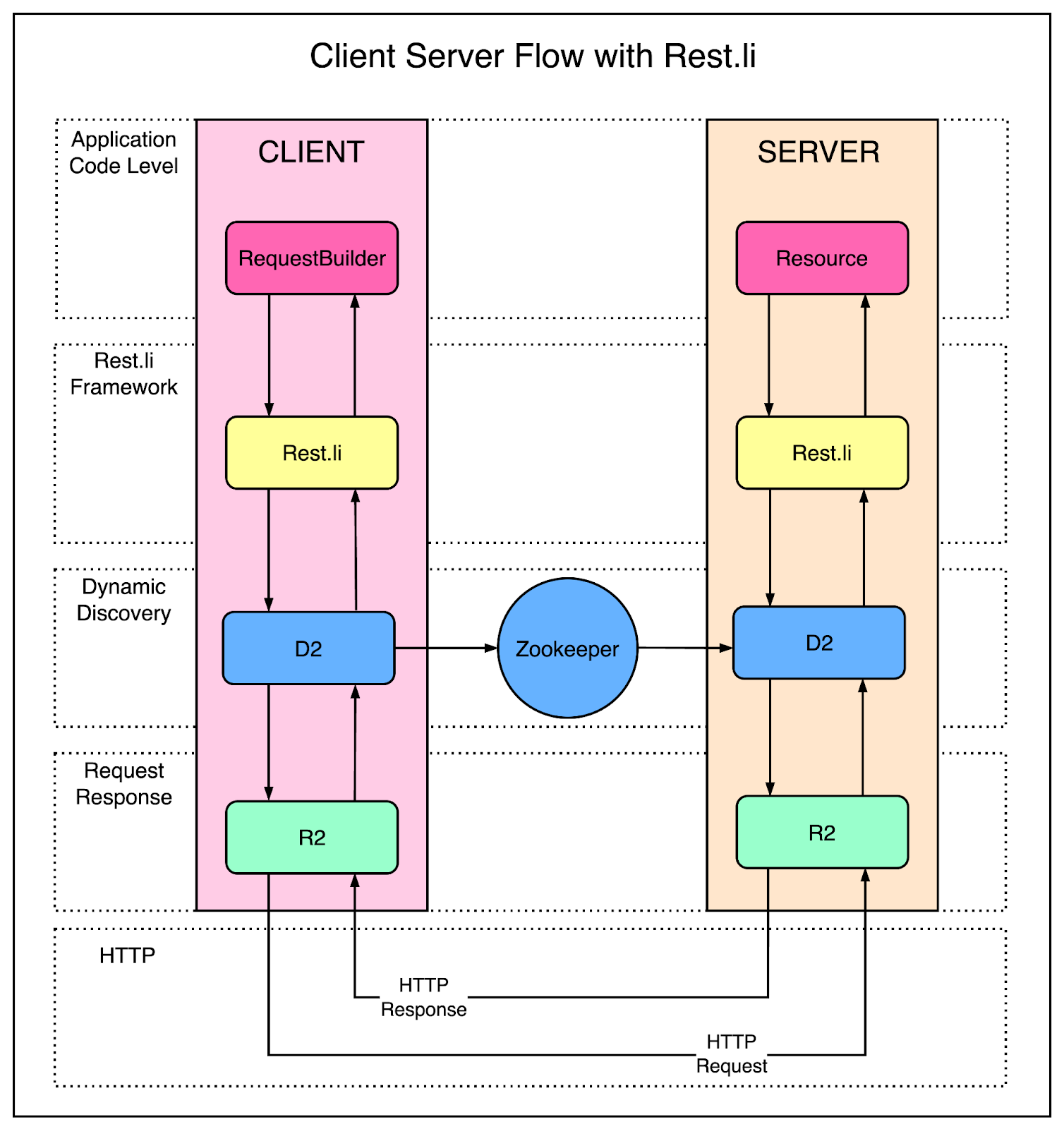
To deal with this, the LinkedIn engineers created a new API model called Rest.li.
What made Rest.li so special?
Rest.li was a framework for developing RESTful APIs at scale. It used simple JSON over HTTP, making it easy for non-Java-based clients to communicate with Java-based APIs.
Also, Rest.li was a step towards a data-model-based architecture that brought a consistent API model across the organization.
To make things even more easy for developers, they started using Dynamic Discovery (D2) with Rest.li services. With D2, there was no need to configure URLs for each service that you need to talk to. It provides multiple features such as client-based load balancing, service discovery and scalability.
The below diagram shows the use of Rest.li along with Dynamic Discovery.
Super Blocks
A service-oriented architecture is great for decoupling domains and scale out services independently.
However, there are also downsides.
Many of the applications at LinkedIn depend on data from multiple sources. For example, any request for a user’s profile page not only fetches the profile data but includes other details such as photos, connections, groups, subscription information, following info, long-form blog posts and so on.
In a service-oriented architecture, it means making hundreds of calls to fetch all the needed data.
This is typically known as the “call graph” and you can see that this call graph can become difficult to manage as more and more services are created.
To mitigate this issue, LinkedIn introduced the concept of a super block.
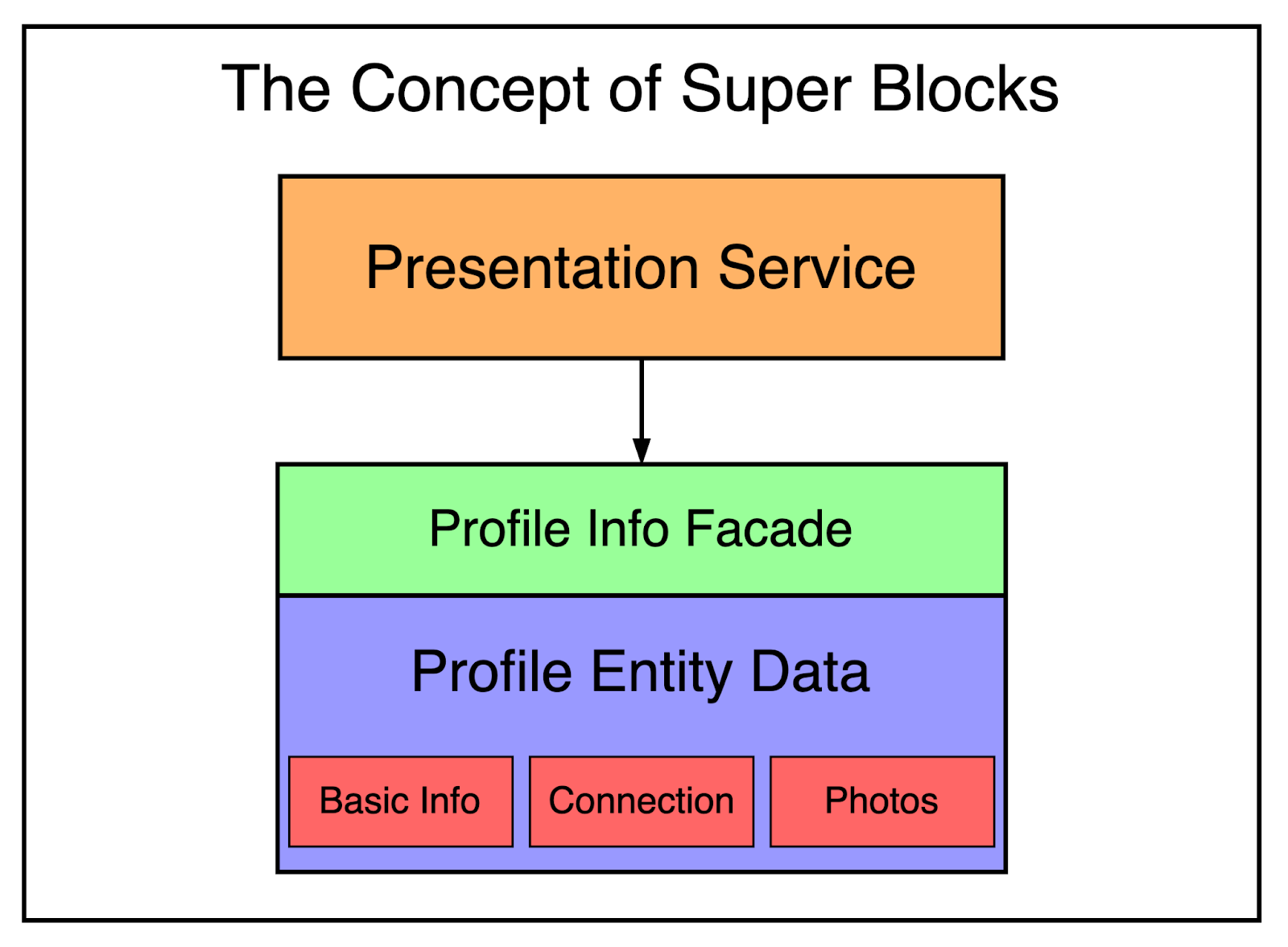
A super block is a grouping of related backend services with a single access API.
This allows teams to create optimized interfaces for a bunch of services and keep the call graph in check. You can think of the super block as the implementation of the facade pattern.
Multi-Data Center
In a few years after launch, LinkedIn became a global company with users joining from all over the world.
They had to scale beyond serving traffic from just one data center. Multiple data centers are incredibly important to maintain high availability and avoid any single point of failure. Moreover, this wasn’t needed just for a single service but the entire website.
The first move was to start serving public profiles out of two data centers (Los Angeles and Chicago).
Once it was proven that things work, they enhanced all other services to support the below features:
Data replication
Callbacks from different origins
One-way data replication events
Pinning users to geographically-close data centers
As LinkedIn has continued to grow, they have migrated the edge infrastructure to Azure Front Door (AFD). For those who don’t know, AFD is Microsoft’s global application and content delivery network and migrating to it provided some great benefits in terms of latency and resilience.
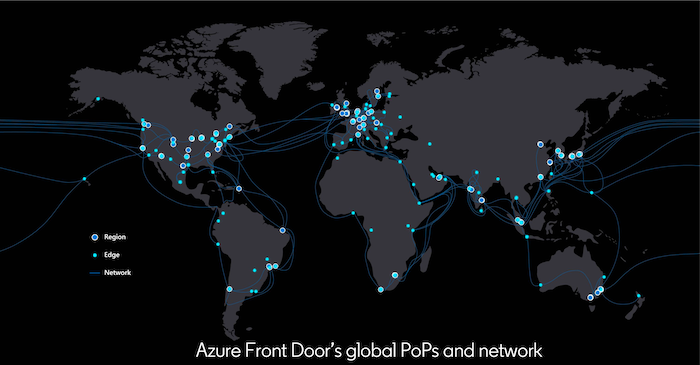
Image Source: Scaling LinkedIn’s Edge with Azure Front Door This move scaled them up to 165+ Points of Presence (PoPs) and helped improve median page load times by up to 25 percent.
The edge infrastructure is basically how our devices connect to LinkedIn today. Data from our device traverses the internet to the closest PoP that houses HTTP proxies that forward those requests to an application server in one of the LinkedIn data centers.
Advanced Developments Around Scalability
Running an application as complex and evolving as LinkedIn requires the engineering team to keep investing into building scalable solutions.
In this section, we will look at some of the more recent developments LinkedIn has undergone.
Real Time Analytics with Pinot
A few years ago, the LinkedIn engineering team hit a wall with regards to analytics
The scale of data at LinkedIn was growing far beyond what they could analyze. The analytics functionality was built using generic storage systems like Oracle and Voldemort. However, these systems were not specialized for OLAP needs and the data volume at LinkedIn was growing in both breadth and depth.
At this point, you might be wondering about the need for real-time analytics at LinkedIn.
Here are three very important use-cases:
The Who’s Viewed Your Profile is LinkedIn’s flagship analytics product that allows members to see who has viewed their profile in real-time. To provide this data, the product needs to run complex queries on large volumes of profile view data to identify interesting insights.
Company Page Analytics is another premium product offered by LinkedIn. The data provided by this product enables company admins to understand the demographic of the people following their page.
LinkedIn also heavily uses analytics internally to support critical requirements such as A/B testing.
To support these key analytics products and many others at scale, the engineering team created Pinot.
Pinot is a web-scale real-time analytics engine designed and built at LinkedIn.
It allows them to slice, dice and scan through massive quantities of data coming from a wide variety of products in real-time.
But how does Pinot solve the problem?
The below diagram shows a comparison between the pre-Pinot and post-Pinot setup.
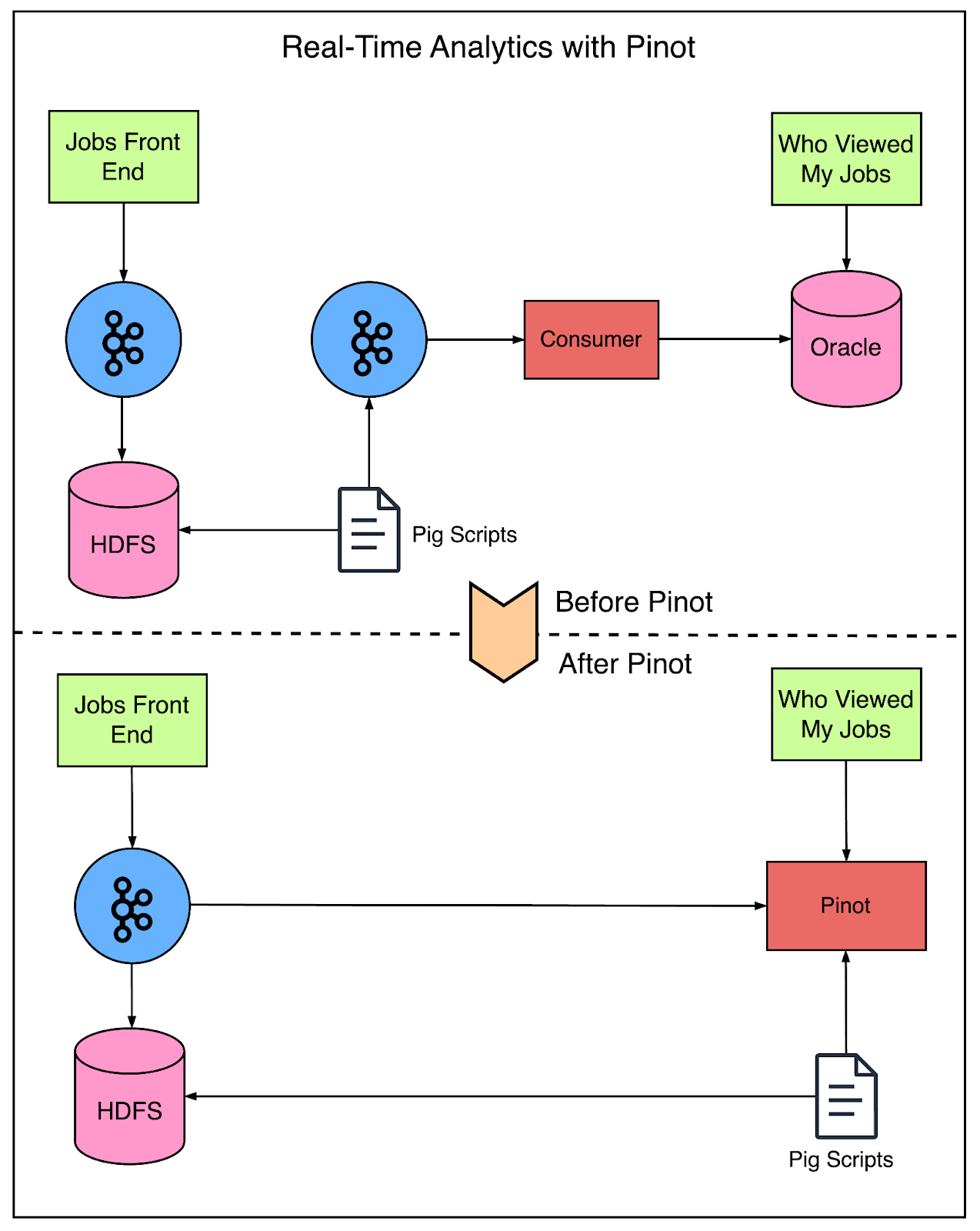
As you can see, Pinot supports real-time data indexing from Kafka and Hadoop, thereby simplifying the entire process.
Some of the other benefits of Pinot are as follows:
Pinot supports low latency and high QPS OLAP queries. For example, it’s capable of serving thousands of Who’s Viewed My Profile requests while maintaining SLA in the order of 10s of milliseconds
Pinot also simplifies operational aspects like cluster rebalancing, adding or removing nodes, and re-bootstrapping
Lastly, Pinot has been future-proofed to handle new data dimensions without worrying about scale
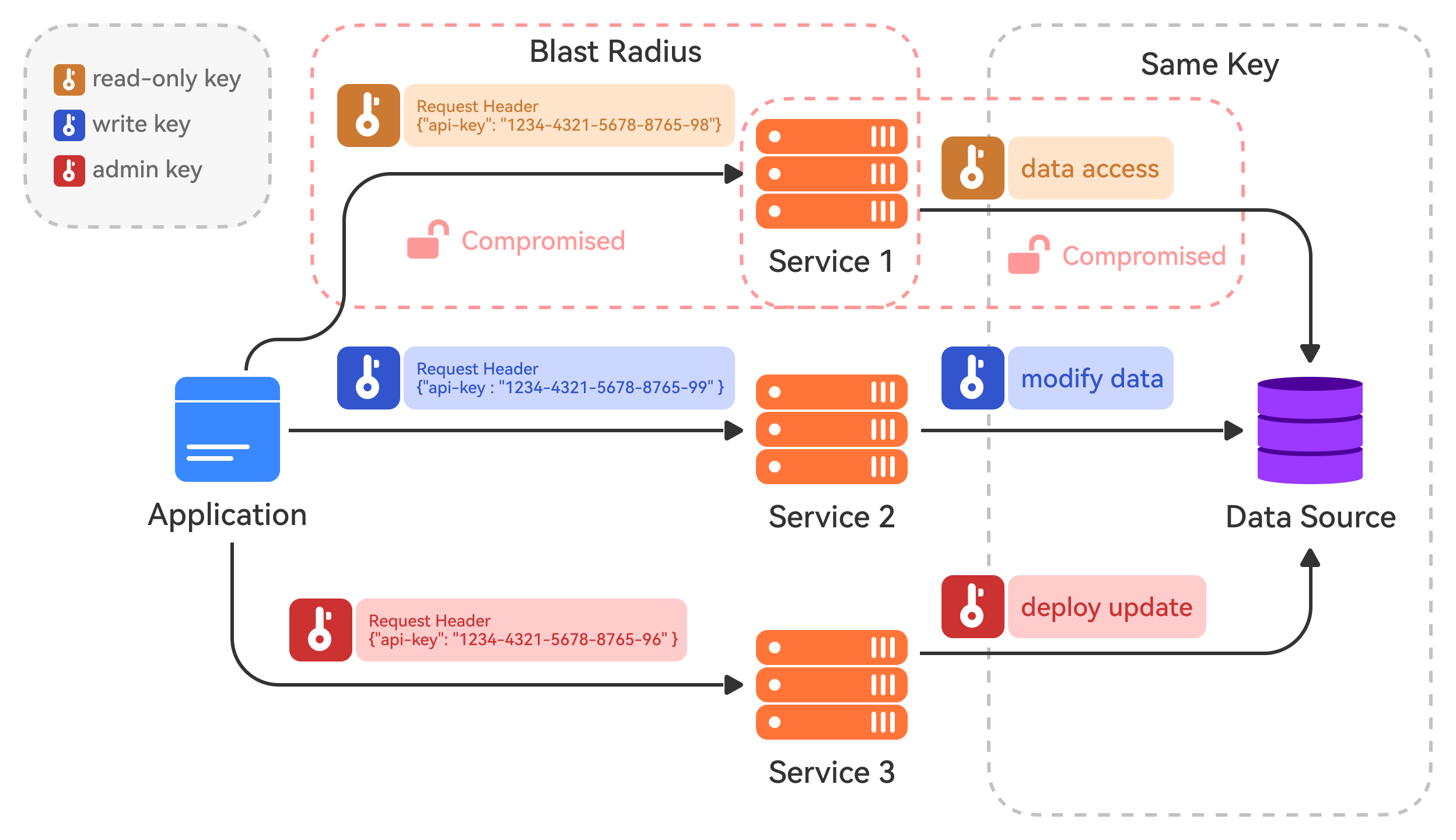
Authorization at LinkedIn Scale
Users entrust LinkedIn with their personal data and it was extremely important for them to maintain that trust.
After the SOA transformation, LinkedIn runs a microservice architecture where each microservice retrieves data from other sources and serves it to the clients. Their philosophy is that a microservice can only access data with a valid business use case. It prevents the unnecessary spreading of data and minimizes the damage if an internal service gets compromised.
A common industry solution to manage the authorization is to define Access Control Lists (ACLs). An ACL contains a list of entities that are either allowed or denied access to a particular resource.
For example, let’s say there is a Rest.li resource to manage greetings. The ACL for this resource can look something like this.
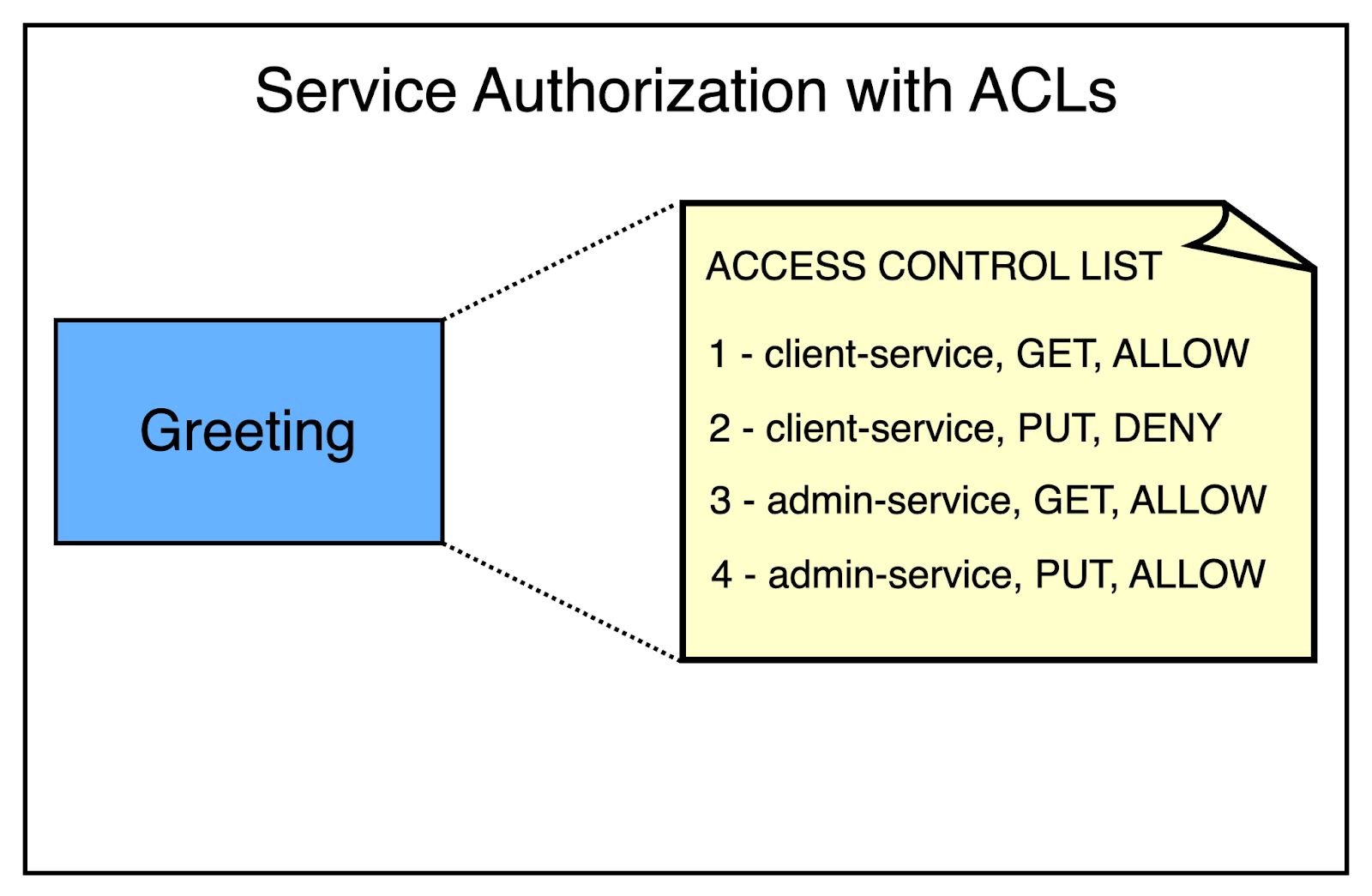
In this case, the client-service can read but not write whereas the admin-service can both read and write to greetings.
While the concept of an ACL-based authorization is quite simple, it’s a challenge to maintain at scale. LinkedIn has over 700 services that communicate at an average rate of tens of millions of calls per second. Moreover, this figure is only growing.
Therefore, the team had to devise a solution to handle ACLs at scale. Mainly, there were three critical requirements:
Check authorization quickly
Deliver ACL changes quickly
Track and manage a large number of ACLs
The below diagram shows a high-level view of how LinkedIn manages authorization between services.
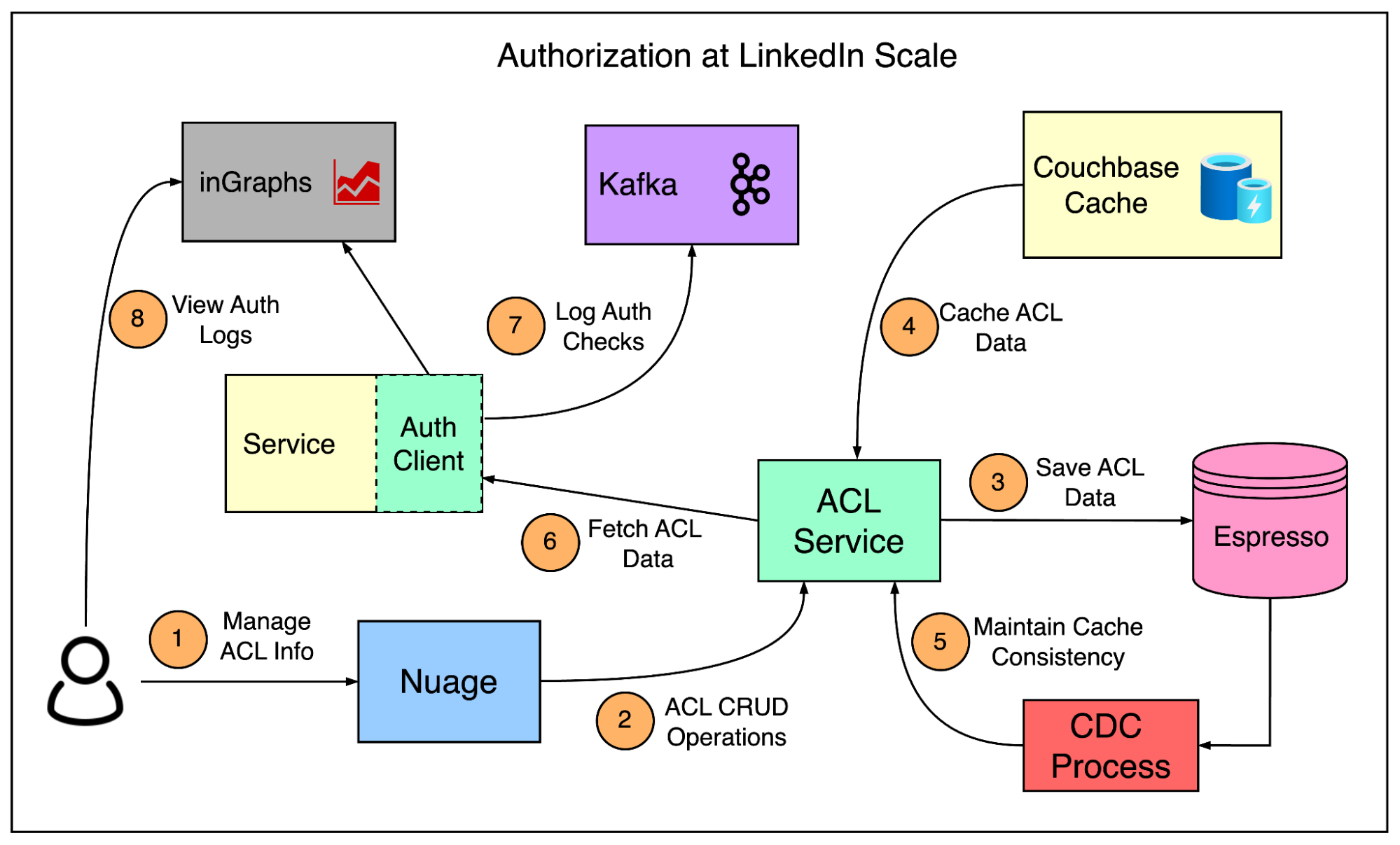
Some key points to consider over here are as follows:
To make authorization checks quick, they built an authorization client module that runs on every service at LinkedIn. This module decides whether an action should be allowed or denied. New services pick up this client by default as part of the basic service architecture.
Latency is a critical factor during an authorization check and making a network call every time is not acceptable. Therefore, all relevant ACL data is kept in memory by the service.
To keep the ACL data fresh, every client reaches out to the server at fixed intervals and updates its in-memory copy. This is done at a fast enough cadence for any ACL changes to be realized quickly.
All ACLs are stored in LinkedIn’s Espresso database. It’s a fault-tolerant distributed NoSQL database that provides a simple interface.
To manage latency and scalability, they also keep a Couchbase cache in front of Espresso. This means even on the server side, the data is served from memory. To deal with stale data in the Couchbase, they use a Change Data Capture system based on LinkedIn’s Brooklin to notify the service when an ACL has changed so that the cache can be cleared.
Every authorization check is logged in the background. This is necessary for debugging and traffic analysis. LinkedIn uses Kafka for asynchronous, high-scale logging. Engineers can check the data in a separate monitoring system known as inGraphs.
Conclusion
In this post, we’ve taken a brief look at the scaling journey of LinkedIn.
From its simple beginnings as a standalone monolithic system serving a few thousand users, LinkedIn has come a long way. It is one of the largest social networks in the world for professionals and companies, allowing seamless connection between individuals across the globe.
To support the growing demands, LinkedIn had to undertake bold transformations at multiple steps.
In the process, they’ve provided a lot of learnings for the wider developer community that can help you in your own projects.
References:
How LinkedIn customizes Apache Kafka for 7 trillion messages per day
Using Set Cover Algorithm to optimize query latency for a large-scale distributed graph
SPONSOR US
Get your product in front of more than 500,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing hi@bytebytego.com
Like
Comment
Restack
© 2024 ByteByteGo
548 Market Street PMB 72296, San Francisco, CA 94104
Unsubscribe

by "ByteByteGo" <bytebytego@substack.com> - 11:37 - 28 May 2024 -
cost estimate
Hi sir,
We provide residential & commercial estimates & take-offs.
Do you have any projects for estimation? Send me the plans/drawings for a quote.
If you are interested then I can share some samples for your review and a better understanding of our format. Thanks.Best Regards,Theo dore
by "Theodore hamestimate" <dore.hamestimate@gmail.com> - 11:03 - 28 May 2024 -
Join me on Thursday for maximising performance with integrated APM and infrastructure monitoring
Hi MD,
It's Liam Hurrell, Manager of Customer Training at New Relic University, here.
Have you considered the importance of APM and infrastructure monitoring in ensuring the optimal performance and reliability of your applications?
Join our 90 minute workshop “Maximising performance with integrated APM and infrastructure monitoring” I'll be hosting on 30 May at 10 AM BST / 11am CEST to explore how APM and Infrastructure Monitoring can be powerful tools for extracting valuable insights from your application and system data. This webinar will delve into the integration of APM and Infrastructure Monitoring data to enhance operational visibility, mitigate risks, and achieve strategic business goals.
You can find the full agenda on the registration page here. While we recommend attending the hands-on workshop live, you can also register to receive the recording.
I hope to see you then.
Liam HurrellManager, Customer TrainingNew Relic
This email was sent to info@learn.odoo.com as a result of subscribing or providing consent to receive marketing communications from New Relic. You can tailor your email preferences at any time here.Privacy Policy © 2008-23 New Relic, Inc. All rights reserved
by "Liam Hurrell, New Relic" <emeamarketing@newrelic.com> - 05:03 - 28 May 2024 -
What does it take to engage employees?
Only McKinsey
How empathy makes a difference Brought to you by Liz Hilton Segel, chief client officer and managing partner, global industry practices, & Homayoun Hatami, managing partner, global client capabilities
•
Dissatisfied workers. Many workers are disengaged, which may destroy productivity and value. How can employers help boost morale and motivate employees? One way to start is by identifying where they fall on a satisfaction spectrum, McKinsey senior partner Aaron De Smet and coauthors explain. A McKinsey survey of more than 14,000 individuals found that, in any given organization, workers fall into six categories based on how satisfied they are. They range from the thriving stars who create value to the quitters who intend to leave.
•
Pursuing purpose. An authentic corporate purpose can improve engagement. Employees whose sense of purpose connects with their companies’ are five times more likely than their peers to feel fulfilled at work, a McKinsey survey has shown. Empathetic leadership can also strengthen worker well-being and morale and help reduce burnout. See the McKinsey Quarterly Five Fifty for six factors that, if prioritized, could help companies reengage workers and recapture millions of dollars in potential lost value each year.
—Edited by Belinda Yu, editor, Atlanta
This email contains information about McKinsey's research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this newsletter because you subscribed to the Only McKinsey newsletter, formerly called On Point.
Copyright © 2024 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "Only McKinsey" <publishing@email.mckinsey.com> - 01:12 - 28 May 2024 -
Re: Weekly update Shipping information fm China
Good day dear
Feel free to let me know if you need rates
My email: overseas.12@winsaillogistics.com
My Tel/whatsapp number:+86 13660987349
by "Yori" <overseas10@gz-logistics.cn> - 05:42 - 27 May 2024 -
The new productivity paradigm: A leader’s guide
Do more with less Brought to you by Liz Hilton Segel, chief client officer and managing partner, global industry practices, & Homayoun Hatami, managing partner, global client capabilities
With only so many hours in a day to juggle work, life, and everything in between, we’re always seeking ways to be more productive: to get more from our own work and to make meaningful investments in the future growth of our businesses and economies. The world economy has made huge gains in productivity over the past two and a half decades, despite a global financial crisis and a pandemic. Yet many countries are at risk of getting left behind. That threatens the potential prosperity of individuals, businesses, and economies. This week, we assess the ways leaders can foster productivity within their businesses and the economies where they operate.
In the past 25 years, global productivity has seen a meteoric rise and has helped raise living standards around the world. This is especially true in some emerging economies, whose productivity improvements could put them at the level of advanced economies 25 years from now. What do these economies (including China, Ethiopia, India, and Poland) have in common? According to senior partners Chris Bradley, Olivia White, and Sven Smit and their colleagues, they’ve made meaningful investments in areas that increase productivity, such as urbanization, infrastructure, education, and services. Such investments are more critical than ever to economic prosperity, as productivity levels have declined in some parts of the world, particularly in advanced economies. To help reverse the slowdown, businesses can make a critical impact by investing in the adoption of new technologies; in reskilling employees, especially those who are closer to retirement; and in hybrid working arrangements that work best for their people.
That’s how many of the world’s businesses are micro-, small, or medium-size enterprises (MSMEs). MSMEs are vital to growth and job creation: they account for almost half of global GDP and for much of the business employment in advanced and emerging economies. But the productivity of these companies lags behind that of their larger counterparts. McKinsey’s Anu Madgavkar, Jan Mischke, Marco Piccitto, Olivia White, and colleagues propose several strategies for improving MSME productivity and helping all economic boats rise. Policy makers, large companies, and other stakeholders, for instance, can create an environment that’s friendlier to small businesses (by improving access to technology, credit, and employee training); large and small businesses can pursue more opportunities for partnership, including mergers; and MSMEs can collaborate to strengthen their respective networks and capabilities.
That’s McKinsey’s Aaron De Smet, Patrick Simon, and colleagues describing the productivity paradox of the remote-work age. Employees have myriad tools at their fingertips for connecting with colleagues, no matter where they sit, yet the quality of those connections is on the decline. To turn the page on trivial interactions and actually get things done, the authors point to three types of “collaborative” interactions in the workplace. First is decision making, which relies on clear decisions right from the start. Second is creative solutions and coordination: empowering employees to come up with their own ways of solving problems. Third is information sharing. If leaders and companies develop a deliberate approach to when and why meetings are needed, they can alleviate interaction fatigue and enhance employee productivity.
What postpandemic talent trend may be even more counterproductive for companies than high employee turnover? According to senior partner Aaron De Smet, it’s the large number of people who are disengaged from their work but choose to stay. In an interview with The McKinsey Podcast, he spoke about his team’s research on employee productivity, which points to six types of employees. These include quiet quitters, who are doing the bare minimum and can be hard to spot in a hybrid working world. De Smet suggests that open dialogue, especially with quiet quitters, is an important place to start. “Have an authentic conversation where you ask, ‘How are you doing? Are you productive? Are you satisfied?’” he says. “In a few cases, people will not give you the honest answer. But in many other cases, if you really listen, the answer will be there.”
Generative AI’s (gen AI’s) promise to increase worker productivity is huge, with trillions of dollars of economic value at stake. McKinsey research suggests that nearly nine in ten workers using gen AI at work are in nontechnical roles, and there is a growing suite of productivity tools to try. In practice, though, the AI agents supporting today’s employees are very much works in progress. Whether they’re rescheduling ten meetings in someone’s calendar (instead of one, as the user requested) or booking a flight with five layovers to save a few dollars, even the most sophisticated chatbots still have room to increase their productivity.
Lead by investing in productivity.
— Edited by Daniella Seiler, executive editor, Washington, DC
Share these insights
Did you enjoy this newsletter? Forward it to colleagues and friends so they can subscribe too. Was this issue forwarded to you? Sign up for it and sample our 40+ other free email subscriptions here.
This email contains information about McKinsey’s research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this email because you subscribed to the Leading Off newsletter.
Copyright © 2024 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "McKinsey Leading Off" <publishing@email.mckinsey.com> - 04:51 - 27 May 2024 -
Re: Cosmetics and Personal Care Industry Professionals List
Would you be interested in acquiring Cosmetics and Personal Care Industry Professionals List with Email across North America, UK, Europe and Global?
We maintain a database of 135,000+ Confirmed Contacts of Cosmetics and Personal Care Industry Professionals with complete contact information including opt-emails across North America, UK, Europe and Global.
The list includes Name, Company, Title, Employee & Revenue Size, Industry, SIC Code, Fax, Website, Physical Address, Phone Number and Verified Email Address.
Ø Guaranteed 95% on email deliverability and 100% on all other information.
Ø Delivered in excel or csv format with complete ownership rights.
Please send me your target audience and geographical area, so that I can give you more information, Counts and Pricing just for your review.
The Pricing depends on the volume of the data you acquire, more the volume less will be the cost and vice-versa.
Looking forward to hearing from you.
Regards,
Joan Tamez | Online Marketing Executive
P We have a responsibility to the environment
Before printing this e-mail or any other document, let's ask ourselves whether we need a hard copy
If you don't wish to receive our newsletters, reply back with "EXCLUDE ME" in the subject line.
by "Joan Tamez" <joan.tamez@reachsmedia.com> - 12:27 - 27 May 2024 -
"Unlock New Perspectives: Guest Post Partnership Proposal"
Hello
I hope you are doing well. I'm Outreach Manager, We have high quality sites for sponsored guest posting or link insertions.
Please check my sponsored guest posting sites.
https://digimagazine.co.ukDo you need websitesI am waiting for your replyTHANKS
Sent with Mailsuite · Unsubscribe
05/26/24, 10:34:07 AM 
by "Luna Henry" <lunahenry067@gmail.com> - 01:34 - 26 May 2024 -
🌟 Exclusive Offer: Permanent Do-Follow Backlinks/Guest Post Opportunity 🚀
Hello
I hope you are doing well. I'm Outreach Manager, We have high quality sites for sponsored guest posting or link insertions.
Please check my sponsored guest posting sites.
https://digimagazine.co.ukDo you need websitesI am waiting for your replyTHANKS
Sent with Mailsuite · Unsubscribe
05/26/24, 10:33:30 AM 
by "Luna Henry" <lunahenry067@gmail.com> - 01:33 - 26 May 2024 -
The week in charts
The Week in Charts
Gen Z spirituality, midtenure CFOs, and more Share these insights
Did you enjoy this newsletter? Forward it to colleagues and friends so they can subscribe too. Was this issue forwarded to you? Sign up for it and sample our 40+ other free email subscriptions here.
This email contains information about McKinsey's research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this email because you subscribed to The Week in Charts newsletter.
Copyright © 2024 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "McKinsey Week in Charts" <publishing@email.mckinsey.com> - 03:36 - 25 May 2024 -
EP113: AWS Services Cheat Sheet
EP113: AWS Services Cheat Sheet
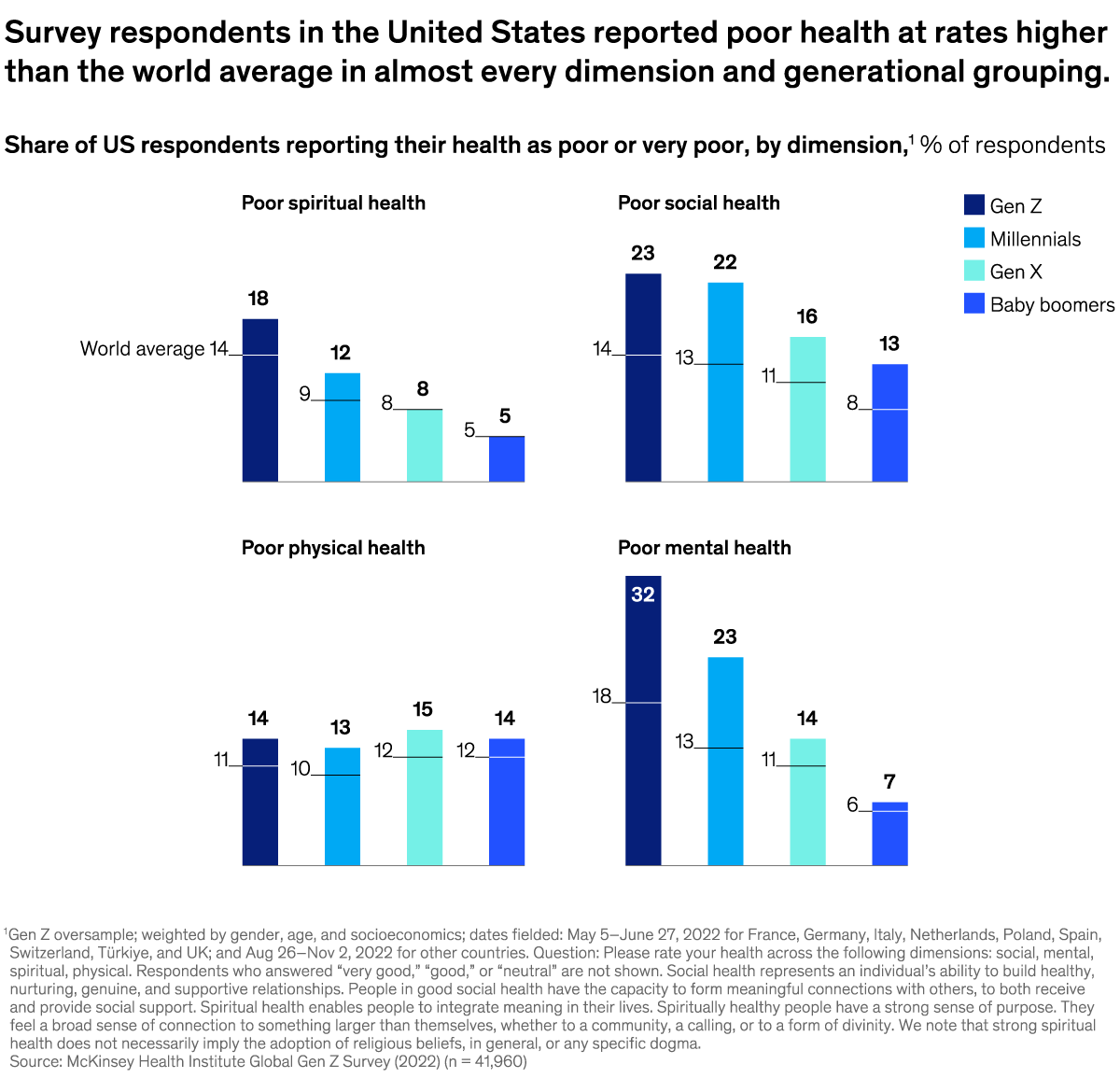
This week’s system design refresher: Do You Know How Mobile Apps Are Released? (Youtube video) AWS Services Cheat Sheet A cheat sheet for API designs Azure Services Cheat Sheet How do computer programs run? SPONSOR US Collaborating on APIs is Easier With Postman (Sponsored)͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ Forwarded this email? Subscribe here for moreThis week’s system design refresher:
Do You Know How Mobile Apps Are Released? (Youtube video)
AWS Services Cheat Sheet
A cheat sheet for API designs
Azure Services Cheat Sheet
How do computer programs run?
SPONSOR US
Collaborating on APIs is Easier With Postman (Sponsored)
Whether you’re a team of four or 40,000, development teams need to collaborate on APIs. API Collaboration improves developer productivity by empowering both API producers and consumers to share, discover, and reuse high-quality API assets.
Postman revolutionizes the experience of collaborative API development with Collections and Workspaces. Used together, they enable API design, testing, and documentation, providing a shared canvas for collaborating on API assets.
Learn how Postman is giving teams of all sizes and functions the ability to rapidly iterate on API development, elevate the quality of their APIs, and extend their API workflows for large-scale initiatives.
Do You Know How Mobile Apps Are Released?
AWS Services Cheat Sheet

AWS grew from an in-house project to the market leader in cloud services, offering so many different services that even experts can find it a lot to take in.
The platform not only caters to foundational cloud needs but also stays at the forefront of emerging technologies such as machine learning and IoT, establishing itself as a bedrock for cutting-edge innovation. AWS continuously refines its array of services, ensuring advanced capabilities for security, scalability, and operational efficiency are available.
For those navigating the complex array of options, this AWS Services Guide is a helpful visual aid.
It simplifies the exploration of AWS's expansive landscape, making it accessible for users to identify and leverage the right tools for their cloud-based endeavors.
Over to you: What improvements would you like to see in AWS services based on your usage?Latest articles
If you’re not a paid subscriber, here’s what you missed.
To receive all the full articles and support ByteByteGo, consider subscribing:
A cheat sheet for API designs
APIs expose business logic and data to external systems, so designing them securely and efficiently is important.

API key generation
We normally generate one unique app ID for each client and generate different pairs of public key (access key) and private key (secret key) to cater to different authorizations. For example, we can generate one pair of keys for read-only access and another pair for read-write access.Signature generation
Signatures are used to verify the authenticity and integrity of API requests. They are generated using the secret key and typically involve the following steps:
- Collect parameters
- Create a string to sign
- Hash the string: Use a cryptographic hash function, like HMAC (Hash-based Message Authentication Code) in combination with SHA-256, to hash the string using the secret key.Send the requests
When designing an API, deciding what should be included in HTTP request parameters is crucial. Include the following in the request parameters:
- Authentication Credentials
- Timestamp: To prevent replay attacks.
- Request-specific Data: Necessary to process the request, such as user IDs, transaction details, or search queries.
- Nonces: Randomly generated strings included in each request to ensure that each request is unique and to prevent replay attacks.Security guidelines
To safeguard APIs against common vulnerabilities and threats, adhere to these security guidelines.
Azure Services Cheat Sheet
Launching in 2010, Microsoft Azure has quickly grown to hold the No. 2 position in market share by evolving from basic offerings to a comprehensive, flexible cloud ecosystem.

Today, Azure not only supports traditional cloud applications but also caters to emerging technologies such as AI, IoT, and blockchain, making it a crucial platform for innovation and development.
As it evolves, Azure continues to enhance its capabilities to provide advanced solutions for security, scalability, and efficiency, meeting the demands of modern enterprises and startups alike. This expansion allows organizations to adapt and thrive in a rapidly changing digital landscape.
The attached illustration can serve as both an introduction and a quick reference for anyone aiming to understand Azure.
Over to you: How does your experience with Azure compare to that with AWS?
Over to you: Does the card network charge the same interchange fee for big merchants as for small merchants?How do computer programs run?
The diagram shows the steps.

User interaction and command initiation
By double-clicking a program, a user is instructing the operating system to launch an application via the graphical user interface.Program Preloading
Once the execution request has been initiated, the operating system first retrieves the program's executable file.
The operating system locates this file through the file system and loads it into memory in preparation for execution.Dependency resolution and loading
Most modern applications rely on a number of shared libraries, such as dynamic link libraries (DLLs).Allocating memory space
The operating system is responsible for allocating space in memory.
Initializing the Runtime Environment
After allocating memory, the operating system and execution environment (e.g., Java's JVM or the .NET Framework) will initialize various resources needed to run the program.System Calls and Resource Management
The entry point of a program (usually a function named `main`) is called to begin execution of the code written by the programmer.Von Neumann Architecture
In the Von Neumann architecture, the CPU executes instructions stored in memory.Program termination
Eventually, when the program has completed its task, or the user actively terminates the application, the program will begin a cleanup phase. This includes closing open file descriptors, freeing up network resources, and returning memory to the system.
SPONSOR US
Get your product in front of more than 500,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing hi@bytebytego.com
© 2024 ByteByteGo
548 Market Street PMB 72296, San Francisco, CA 94104
Unsubscribe
by "ByteByteGo" <bytebytego@substack.com> - 11:35 - 25 May 2024 -
What does it take to be courageous?
Readers & Leaders
Embrace your fears THIS MONTH’S PAGE-TURNERS ON BUSINESS AND BEYOND
When you hear the word “courage,” what image comes to mind? Perhaps you see a soldier in a combat zone or a firefighter rushing into a burning building. Courage is that, of course, but it isn’t confined to extreme situations. Courage is also about embracing vulnerability. It’s about tuning in to that voice inside that tells us to shake things up or hold our ground on tough issues. It’s daring to step away from what’s comfortable, whether that’s quitting your nine-to-five job to start a new business or speaking up in a meeting when you normally wouldn’t.
This edition of Readers & Leaders explores courage in its many forms. New York Times columnist and Pulitzer Prize winner Nicholas D. Kristof recounts his path from a small-town farm to every corner of the world to report on protests, massacres, civil wars, genocides, addiction, and despair; Marine Corps veteran Nate Boaz shares how he’s conquered danger head-on; Alison Taylor helps organizations discern when they should lend their voice to a contentious issue; Elaine Lin Hering shares how to build the confidence to find the voice you’ve learned to bury; and teenagers Jason Liaw and Fenley Scurlock offer a road map for aspiring entrepreneurs of all ages.
Want early access to interviews? Download the McKinsey Insights app to read the latest Author Talks now.it bears repeating

IN CASE YOU MISSED IT
TURN BACK THE PAGE
Looking for more ways to become a more courageous version of yourself? Face your fears with these popular interviews.
1. Into the unknown
2. How to conquer fear, prepare for death, and embrace your power
3. Make anxiety your ally
4. Poet Maggie Smith on loss, creativity, and changeBUSINESS BESTSELLERS TOP
8
It’s time to stock up on your beach reads. Explore April’s business bestsellers, prepared exclusively for McKinsey by Circana. Check out the full selection on McKinsey on Books.
BUSINESS OVERALL
BUSINESS HARDCOVER
ECONOMICS
DECISION MAKING
ORGANIZATIONAL BEHAVIOR
WORKPLACE CULTURE
COMPUTERS & AI
SUSTAINABILITY
Beyond Shareholder Primacy: Remaking Capitalism for a Sustainable Future by Stuart L. Hart (Two Rivers Distribution)
BOOKMARK THIS

The Journey of Leadership: How CEOs Learn to Lead from the Inside Out
The Journey of Leadership (Portfolio/Penguin Group), McKinsey’s next major book, will publish in the United States and the United Kingdom on September 10. The book, by Dana Maor, Kurt Strovink, Ramesh Srinivasan, and senior partner emeritus Hans-Werner Kaas, is the first-ever explanation of McKinsey’s step-by-step approach to transforming leaders both professionally and personally, including revealing lessons from its legendary CEO leadership program, the “Bower Forum,” which has counseled 500-plus global CEOs over the past decade. It is a journey that helps leaders hone the psychological, emotional, and, ultimately, human attributes that result in success in today’s most demanding top job.
If you’d like to propose a book or author for #McKAuthorTalks, please email us at Author_Talks@McKinsey.com. Due to the high volume of requests, we will respond only to those being considered.
—Edited by Eleni Kostopoulos, managing editor, New York
Follow our thinking
SHARE THESE INSIGHTS
Did you enjoy this newsletter? Forward it to colleagues and friends so they can subscribe too. Was this issue forwarded to you? Sign up for it and sample our 40+ other free email subscriptions here.
This email contains information about McKinsey's research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this email because you subscribed to the Readers & Leaders newsletter.
Copyright © 2024 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "McKinsey Readers & Leaders" <publishing@email.mckinsey.com> - 09:07 - 25 May 2024 -
High Traffic websites Now available In reasonable price
Hi Dear !
"Boost your website's visibility with our guest posting services! We offer permanent, do-follow links on reputable sites.
please check websites
kemotech.co.uk
marketbusinessnews.com
newsbreak.com
urbansplatter.com
tripoto.com
techwinks.com.in
knowworldnow.com
techsslash.com
digimagazine.co.uk
Let us help increase your website traffic. Interested?
I am waiting for your reply
Thanks!
by "Eric jason" <ericjasonbarnard@gmail.com> - 05:26 - 25 May 2024 -
Re: What to do when there is no shipping space in the peak season?
Good day dear
Feel free to let me know if you need rates
My email: overseas.12@winsaillogistics.com
My Tel/whatsapp number:+86 13660987349
by "Yori" <overseas10@gz-logistics.cn> - 02:11 - 24 May 2024 -
How to help young people cope with mental health needs
Only McKinsey
Why children’s mental health matters Brought to you by Liz Hilton Segel, chief client officer and managing partner, global industry practices, & Homayoun Hatami, managing partner, global client capabilities
•
A universal right. About three-fourths of all mental disorders become apparent by age 24. Left untreated, these conditions can lead to adverse outcomes in physical health, learning, and future economic prospects. Zeinab Hijazi, UNICEF’s global lead on mental health, speaks about the issue with McKinsey partners Erica Coe and Kana Enomoto in a recent episode of the Conversations on Health series from McKinsey Health Institute. UNICEF considers mental health a universal right, Hijazi notes, and it has set out to collaborate with government agencies and invest in communities to support mental health in adolescents.
—Edited by Sarah Thuerk, editor, Atlanta
This email contains information about McKinsey's research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this newsletter because you subscribed to the Only McKinsey newsletter, formerly called On Point.
Copyright © 2024 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "Only McKinsey" <publishing@email.mckinsey.com> - 01:32 - 24 May 2024