Archives
- By thread 5360
-
By date
- June 2021 10
- July 2021 6
- August 2021 20
- September 2021 21
- October 2021 48
- November 2021 40
- December 2021 23
- January 2022 46
- February 2022 80
- March 2022 109
- April 2022 100
- May 2022 97
- June 2022 105
- July 2022 82
- August 2022 95
- September 2022 103
- October 2022 117
- November 2022 115
- December 2022 102
- January 2023 88
- February 2023 90
- March 2023 116
- April 2023 97
- May 2023 159
- June 2023 145
- July 2023 120
- August 2023 90
- September 2023 102
- October 2023 106
- November 2023 100
- December 2023 74
- January 2024 75
- February 2024 75
- March 2024 78
- April 2024 74
- May 2024 108
- June 2024 98
- July 2024 116
- August 2024 134
- September 2024 130
- October 2024 141
- November 2024 171
- December 2024 115
- January 2025 216
- February 2025 140
- March 2025 220
- April 2025 233
- May 2025 239
- June 2025 303
- July 2025 173
-
Elevate Your Security Strategy with Sumo Logic at the AWS Summit London
Sumo Logic
Join us at Stand S20 for insights on AI in defense strategies.

 Dear Mohammad,
Dear Mohammad,
Don't miss out on the chance to connect with Sumo Logic at the AWS Summit London on the 24th of April at the ExCel London.
Swing by Stand B36 to delve into the future of defense strategies in the age of AI.
Let's explore and discuss the Applications of AI in a modern defense strategy, providing insights on defending against AI-enabled adversaries and crafting an AI strategy to empower your Security Operations teams.
Discover how to adapt to new threats and navigate the ever-changing cyber landscape. At our booth you can also enter a prize draw with a chance to win a remarkable2.
Join us at Stand B36 and elevate your security game. We look forward to seeing you there!
Best regards,
Sumo Logic
About Sumo Logic
Sumo Logic is the pioneer in continuous intelligence, a new category of software to address the data challenges presented by digital transformation, modern applications, and cloud computing.Sumo Logic, Aviation House, 125 Kingsway, London WC2B 6NH, UK
© 2024 Sumo Logic, All rights reserved.Unsubscribe 


by "Sumo Logic" <marketing-info@sumologic.com> - 06:01 - 17 Apr 2024 -
How do business leaders view the world economy?
On Point
A fast-rising risk to growth Brought to you by Liz Hilton Segel, chief client officer and managing partner, global industry practices, & Homayoun Hatami, managing partner, global client capabilities
—Edited by Belinda Yu, editor, Atlanta
This email contains information about McKinsey's research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this newsletter because you subscribed to the Only McKinsey newsletter, formerly called On Point.
Copyright © 2024 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "Only McKinsey" <publishing@email.mckinsey.com> - 11:06 - 16 Apr 2024 -
How PayPal Serves 350 Billion Daily Requests with JunoDB
How PayPal Serves 350 Billion Daily Requests with JunoDB
Stop releasing bugs with fully automated end-to-end test coverage (Sponsored) Bugs sneak out when less than 80% of user flows are tested before shipping. But how do you get that kind of coverage? You either spend years scaling in-house QA — or you get there in just 4 months with QA Wolf͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ Forwarded this email? Subscribe here for moreStop releasing bugs with fully automated end-to-end test coverage (Sponsored)

Bugs sneak out when less than 80% of user flows are tested before shipping. But how do you get that kind of coverage? You either spend years scaling in-house QA — or you get there in just 4 months with QA Wolf.
How's QA Wolf different?
They don't charge hourly.
They guarantee results.
They provide all of the tooling and (parallel run) infrastructure needed to run a 15-minute QA cycle.
Have you ever seen a database that fails and comes up again in the blink of an eye?
PayPal’s JunoDB is a database capable of doing so. As per PayPal’s claim, JunoDB can run at 6 nines of availability (99.9999%). This comes to just 86.40 milliseconds of downtime per day.
For reference, our average eye blink takes around 100-150 milliseconds.
While the statistics are certainly amazing, it also means that there are many interesting things to pick up from JunoDB’s architecture and design.
In this post, we will cover the following topics:
JunoDB’s Architecture Breakdown
How JunoDB achieves scalability, availability, performance, and security
Use cases of JunoDB
Key Facts about JunoDB
Before we go further, here are some key facts about JunoDB that can help us develop a better understanding of it.
JunoDB is a distributed key-value store. Think of a key-value store as a dictionary where you look up a word (the “key”) to find its definition (the “value”).
JunoDB leverages a highly concurrent architecture implemented in Go to efficiently handle hundreds of thousands of connections.
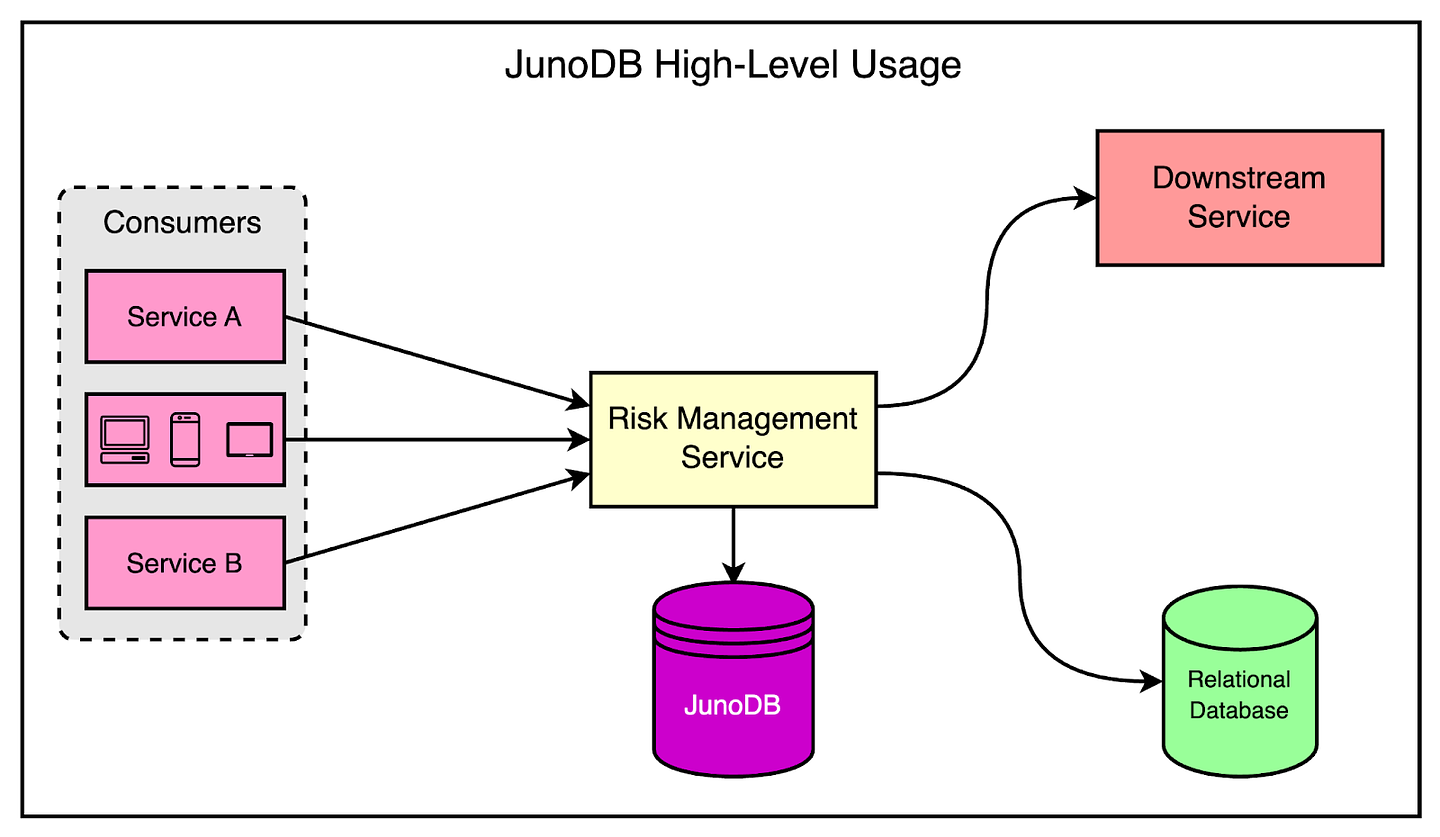
At PayPal, JunoDB serves almost 350 billion daily requests and is used in every core backend service, including critical functionalities like login, risk management, and transaction processing.
PayPal primarily uses JunoDB for caching to reduce the load on the main source-of-truth database. However, there are also other use cases that we will discuss in a later section.
The diagram shows how JunoDB fits into the overall scheme of things at PayPal.
Why the Need for JunoDB?
One common question surrounding the creation of something like JunoDB is this:
“Why couldn’t PayPal just use something off-the-shelf like Redis?”
The reason is PayPal wanted multi-core support for the database and Redis is not designed to benefit from multiple CPU cores. It is single-threaded in nature and utilizes only one core. Typically, you need to launch several Redis instances to scale out on several cores if needed.
Incidentally, JunoDB started as a single-threaded C++ program and the initial goal was to use it as an in-memory short TTL data store.
For reference, TTL stands for Time to Live. It specifies the maximum duration a piece of data should be retained or the maximum time it is considered valid.
However, the goals for JunoDB evolved with time.
First, PayPal wanted JunoDB to work as a persistent data store supporting long TTLs.
Second, JunoDB was also expected to provide improved data security via on-disk encryption and TLS in transit by default.
These goals meant that JunoDB had to be CPU-bound rather than memory-bound.
For reference, “memory-bound” and “CPU-bound” refer to different performance aspects in computer programs. As the name suggests, the performance of memory-bound programs is limited by the amount of available memory. On the other hand, CPU-bound programs depend on the processing power of the CPU.
For example, Redis is memory-bound. It primarily stores the data in RAM and everything about it is optimized for quick in-memory access. The limiting factor for the performance of Redis is memory rather than CPU.
However, requirements like encryption are CPU-intensive because many cryptographic algorithms require raw processing power to carry out complex mathematical calculations.
As a result, PayPal decided to rewrite the earlier version of JunoDB in Go to make it multi-core friendly and support high concurrency.
The Architecture of JunoDB
The below diagram shows the high-level architecture of JunoDB.
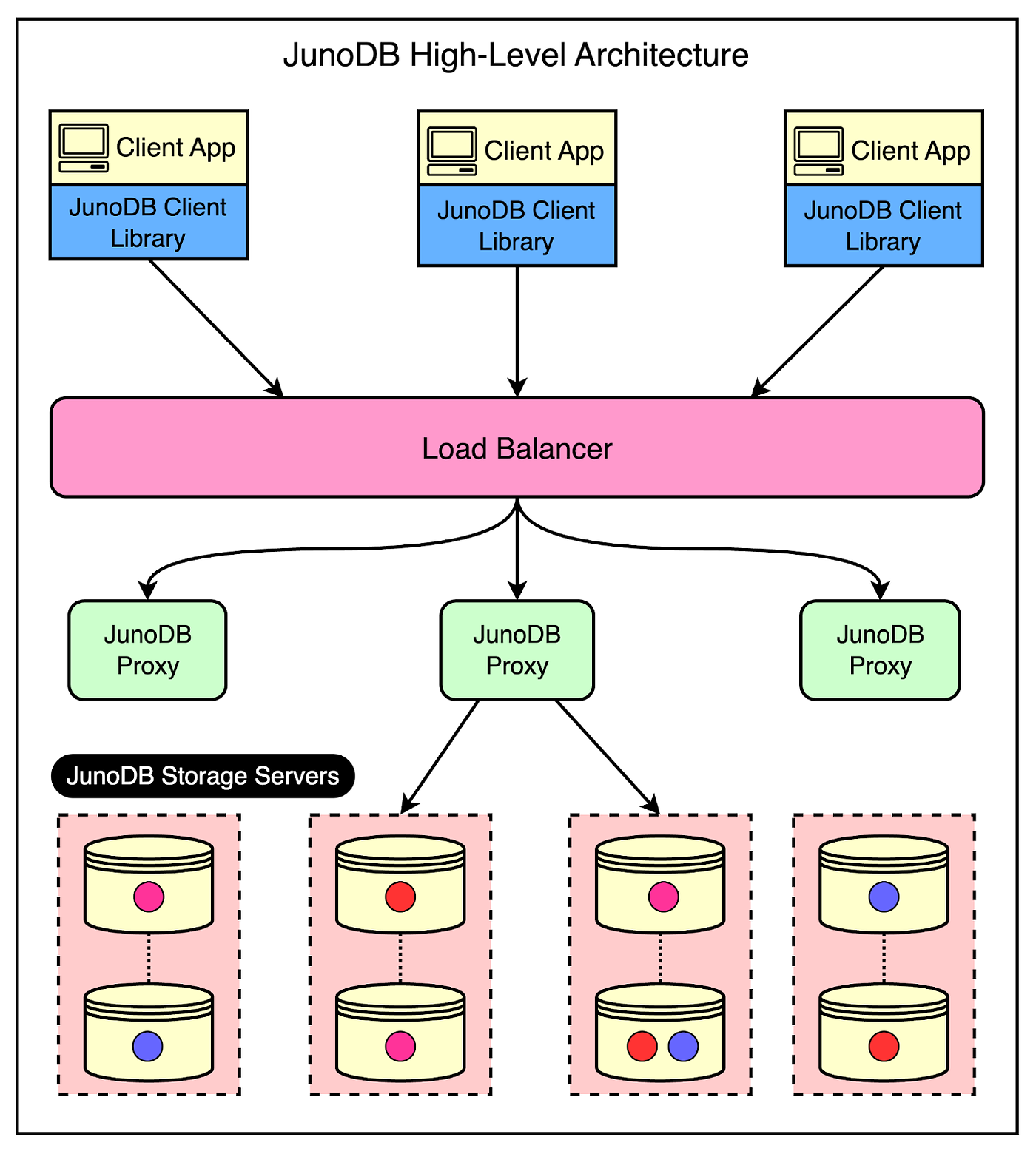
Let’s look at the main components of the overall design.
1 - JunoDB Client Library
The client library is part of the client application and provides an API for storing and retrieving data via the JunoDB proxy.
It is implemented in several programming languages such as Java, C++, Python, and Golang to make it easy to use across different application stacks.
For developers, it’s just a matter of picking the library for their respective programming language and including it in the application to carry out the various operations.
2 - JunoDB Proxy with Load Balancer
JunoDB utilizes a proxy-based design where the proxy connects to all JunoDB storage server instances.
This design has a few important advantages:
The complexity of determining which storage server should handle a query is kept out of the client libraries. Since JunoDB is a distributed data store, the data is spread across multiple servers. The proxy handles the job of directing the requests to the correct server.
The proxy is also aware of the JunoDB cluster configuration (such as shard mappings) stored in the ETCD key-value store.
But can the JunoDB proxy turn into a single point of failure?
To prevent this possibility, the proxy runs on multiple instances downstream to a load balancer. The load balancer receives incoming requests from the client applications and routes the requests to the appropriate proxy instance.
3 - JunoDB Storage Servers
The last major component in the JunoDB architecture is the storage servers.
These are instances that accept the operation requests from the proxy and store data in the memory or persistent storage.
Each storage server is responsible for a set of partitions or shards for an efficient distribution of data.
Internally, JunoDB uses RocksDB as the storage engine. Using an off-the-shelf storage engine like RocksDB is common in the database world to avoid building everything from the ground up. For reference, RocksDB is an embedded key-value storage engine that is optimized for high read and write throughput.
Key Priorities of JunoDB
Now that we have looked at the overall design and architecture of JunoDB, it’s time to understand a few key priorities for JunoDB and how it achieves them.
Scalability
Several years ago, PayPal transitioned to a horizontally scalable microservice-based architecture to support the rapid growth in active customers and payment rates.
While microservices solve many problems for them, they also have some drawbacks.
One important drawback is the increased number of persistent connections to key-value stores due to scaling out the application tier. JunoDB handles this scaling requirement in two primary ways.
1 - Scaling for Client Connections
As discussed earlier, JunoDB uses a proxy-based architecture.
If client connections to the database reach a limit, additional proxies can be added to support more connections.
There is an acceptable trade-off with latency in this case.
2 - Scaling for Data Volume and Throughput
The second type of scaling requirement is related to the growth in data size.
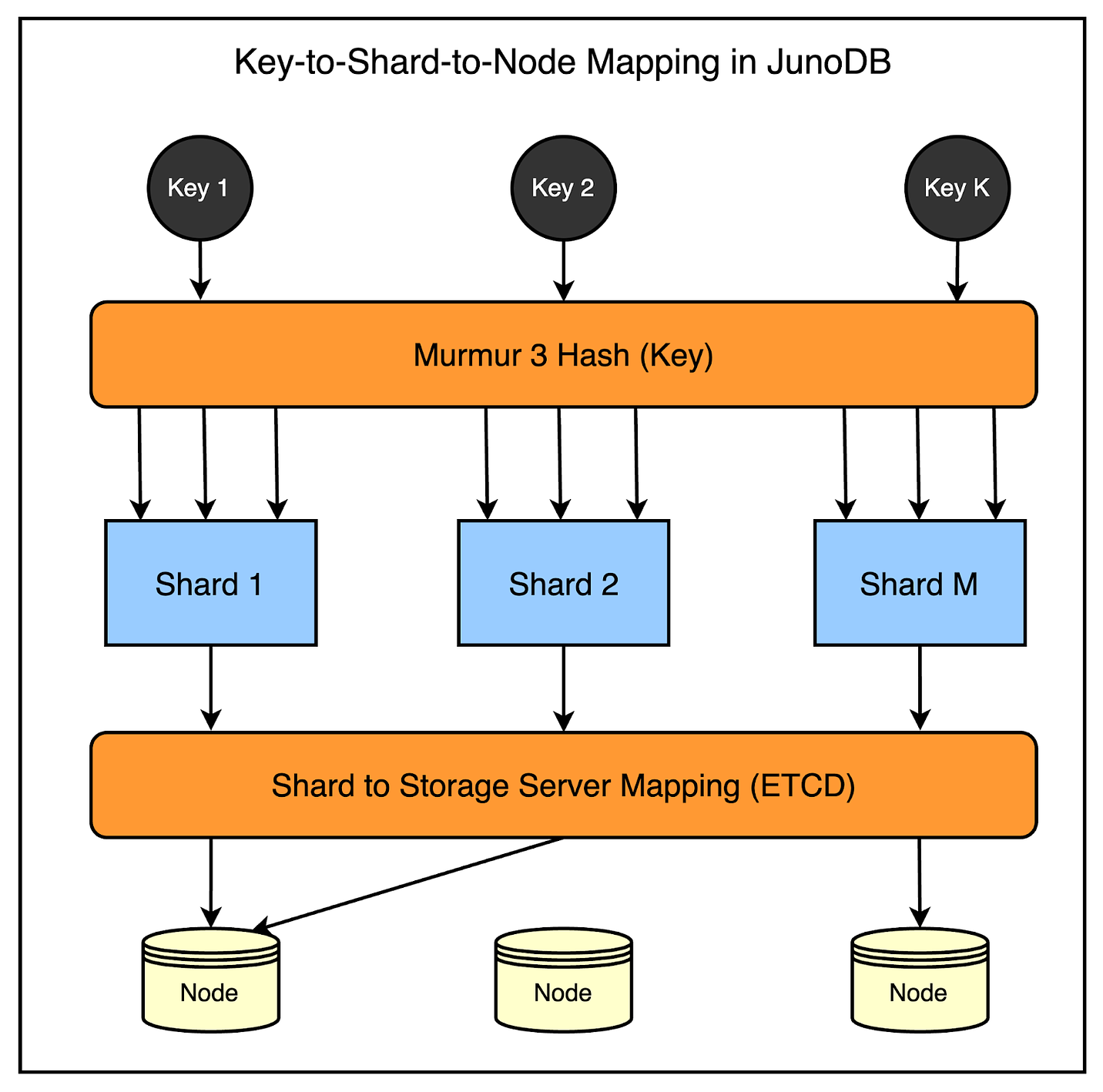
To ensure efficient storage and data fetching, JunoDB supports partitioning based on the consistent hashing algorithm. Partitions (or shards) are distributed to physical storage nodes using a shard map.
Consistent hashing is very useful in this case because when the nodes in a cluster change due to additions or removals, only a minimal number of shards require reassignment to different storage nodes.
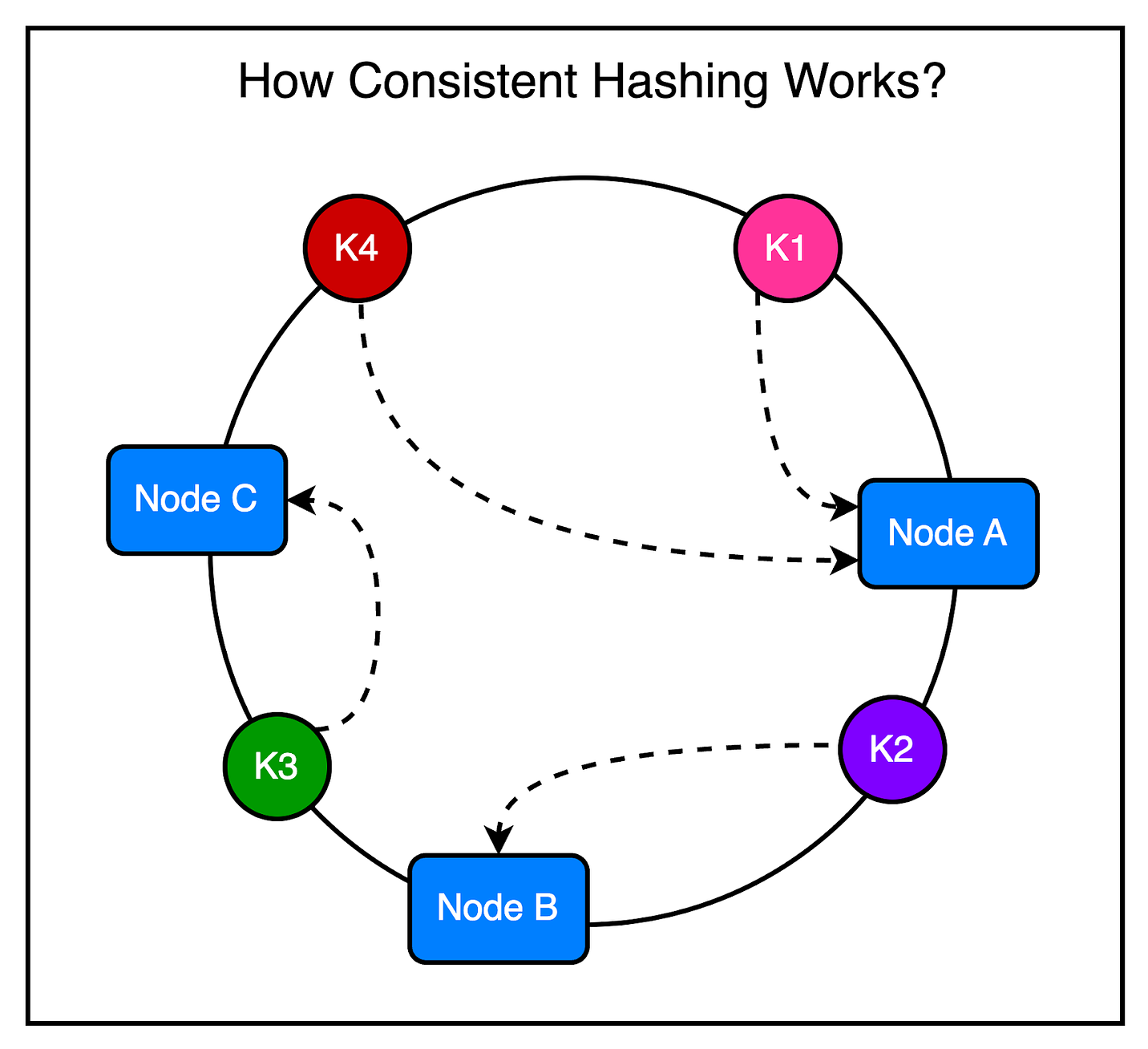
PayPal uses a fixed number of shards (1024 shards, to be precise), and the shard map is pre-generated and stored in ETCD storage.
Any change to the shard mapping triggers an automatic data redistribution process, making it easy to scale your JunoDB cluster depending on the need.
The below diagram shows the process in more detail.
Availability
High availability is critical for PayPal. You can’t have a global payment platform going down without a big loss of reputation.
However, outages can and will occur due to various reasons such as software bugs, hardware failures, power outages, and even human error. Failures can lead to data loss, slow response times, or complete unavailability.
To mitigate these challenges, JunoDB relies on replication and failover strategies.
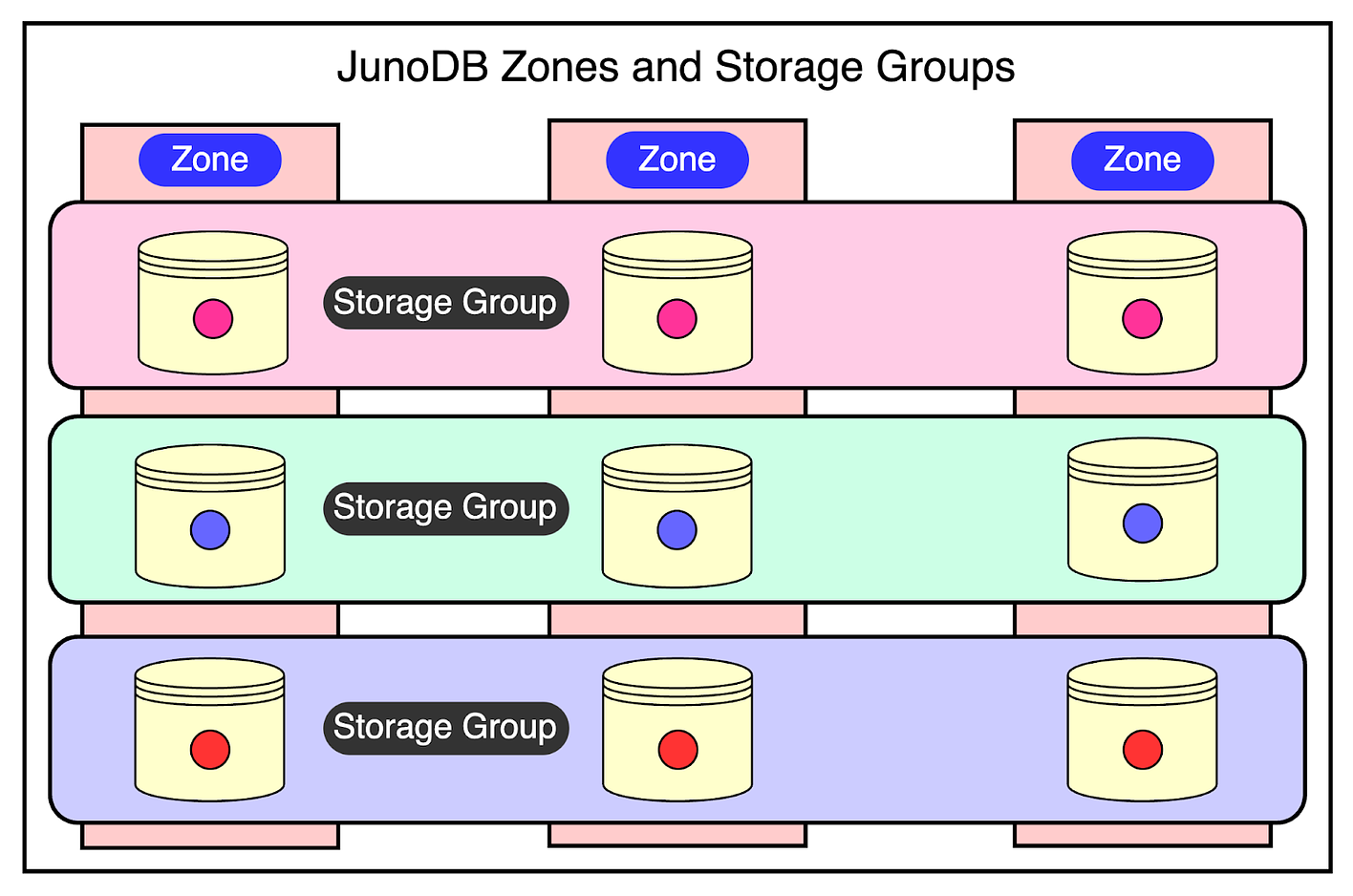
1 - Within-Cluster Replication
In a cluster, JunoDB storage nodes are logically organized into a grid. Each column represents a zone, and each row signifies a storage group.
Data is partitioned into shards and assigned to storage groups. Within a storage group, each shard is synchronously replicated across various zones based on the quorum protocol.
The quorum-based protocol is the key to reaching a consensus on a value within a distributed database. You’ve two quorums:
The Read Quorum: When a client wants to read data, it needs to receive responses from a certain number of zones (known as the read quorum). This is to make sure that it gets the most up-to-date data.
The Write Quorum: When the client wants to write data, it must receive acknowledgment from a certain number of zones to make sure that the data is written to a majority of the zones.
There are two important rules when it comes to quorum.
The sum of the read quorum and write quorum must be greater than the number of zones. If that’s not the case, the client may end up reading outdated data. For example, if there are 5 zones with read quorum as 2 and write quorum as 3, a client can write data to 3 zones but another client may read from the 2 zones that have not yet received the updated data.
The write quorum must be more than half the number of zones to prevent two concurrent write operations on the same key. For example, if there is a JunoDB cluster with 5 zones and a write quorum of 2, client A may write value X to key K and is considered successful when 2 zones acknowledge the request. Similarly, client B may write value Y to the same key K and is also successful when two different zones acknowledge the request. Ultimately, the data for key K is in an inconsistent state.
In production, PayPal has a configuration with 5 zones, a read quorum of 3, and a write quorum of 3.
Lastly, the failover process in JunoDB is automatic and instantaneous without any need for leader re-election or data redistribution. Proxies can know about a node failure through a lost connection or a read request that has timed out.
2 - Cross-data center replication
Cross-data center replication is implemented by asynchronously replicating data between the proxies of each cluster across different data centers.
This is important to make sure that the system continues to operate even if there’s a catastrophic failure at one data center.
Performance
One of the critical goals of JunoDB is to deliver high performance at scale.
This translates to maintaining single-digit millisecond response times while providing a great user experience.
The below graphs shared by PayPal show the benchmark results demonstrating JunoDB’s performance in the case of persistent connections and high throughput.
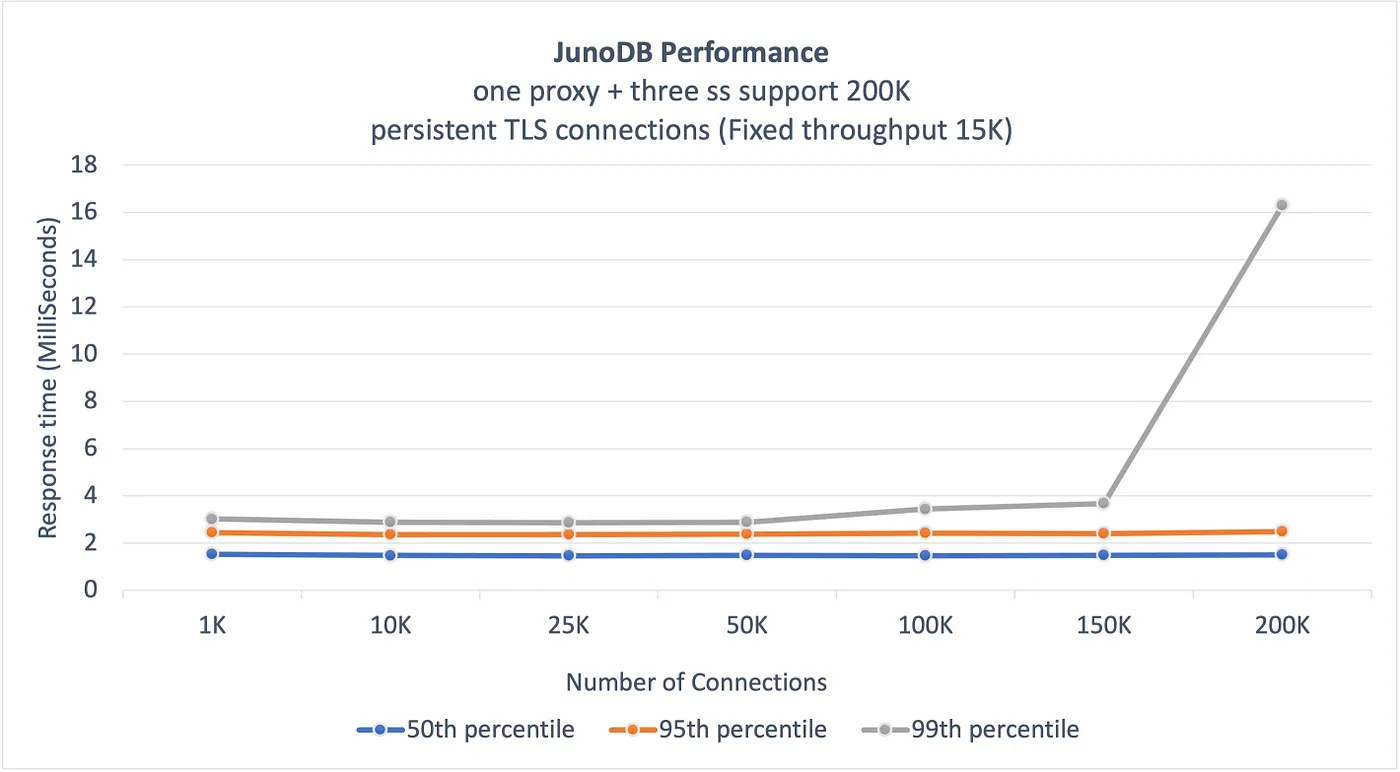
Source: PayPal Engineering Blog 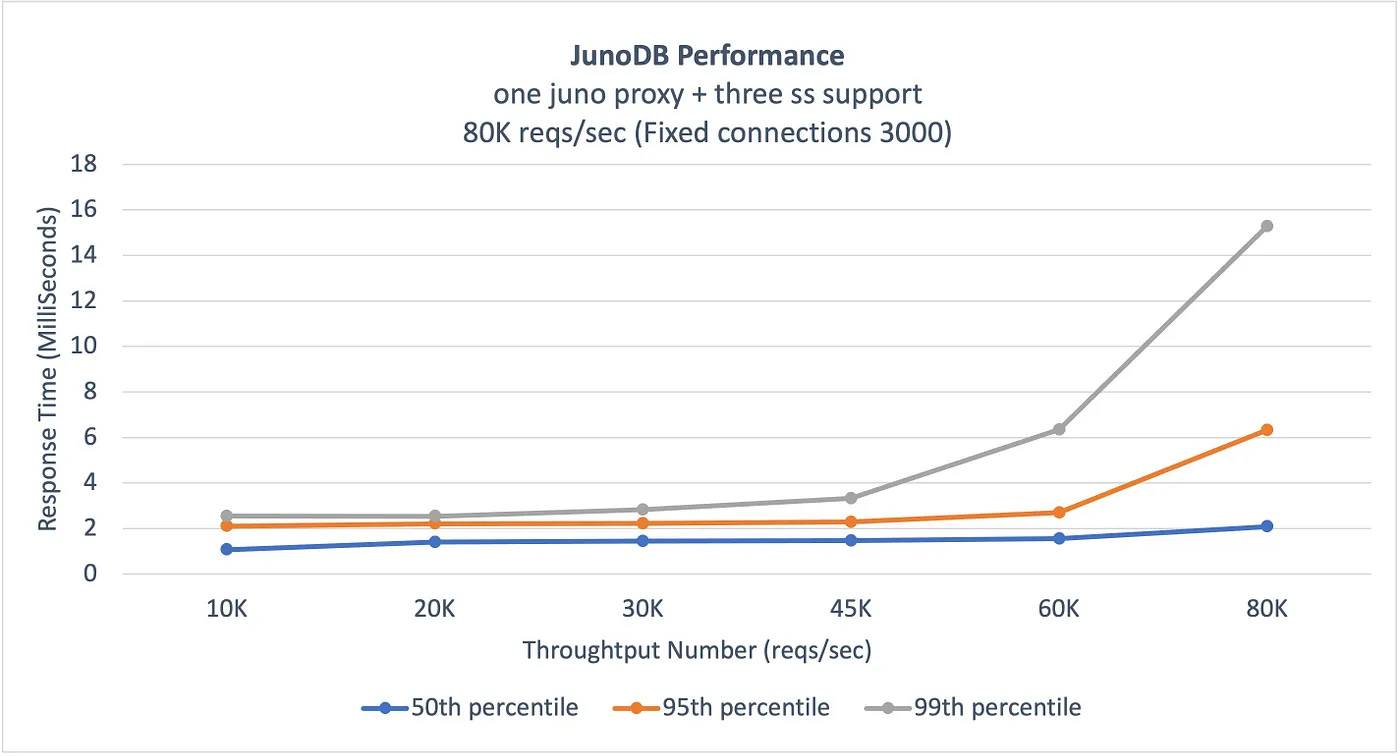
Source: PayPal Engineering Blog Security
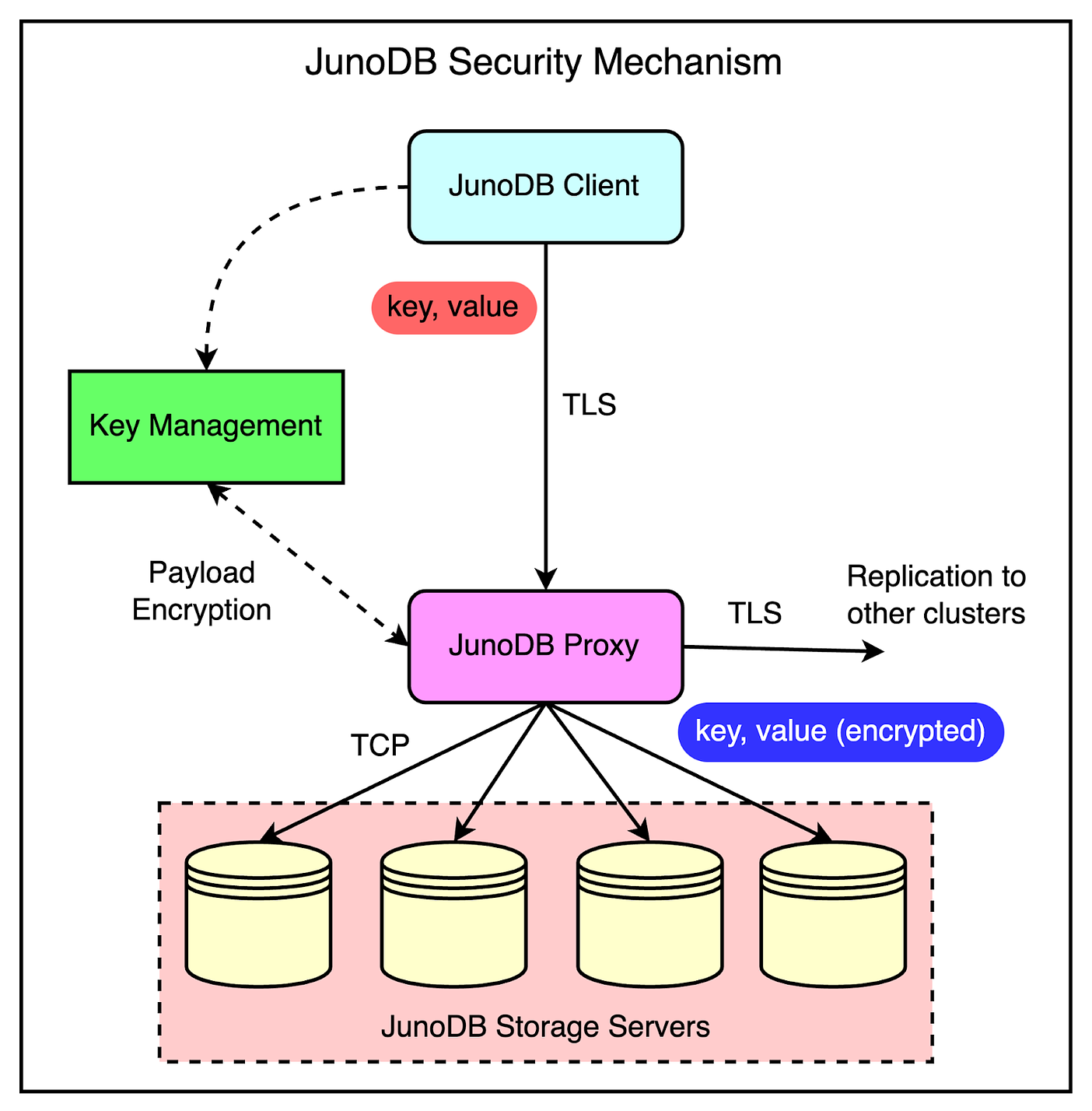
Being a trusted payment processor, security is paramount for PayPal.
Therefore, it’s no surprise that JunoDB has been designed to secure data both in transit and at rest.
For transmission security, TLS is enabled between the client and proxy as well as proxies in different data centers used for replication.
Payload encryption is performed at the client or proxy level to prevent multiple encryptions of the same data. The ideal approach is to encrypt the data on the client side but if it’s not done, the proxy figures it out through a metadata flag and carries out the encryption.
All data received by the storage server and stored in the engine are also encrypted to maintain security at rest.
A key management module is used to manage certificates for TLS, sessions, and the distribution of encryption keys to facilitate key rotation,
The below diagram shows JunoDB’s security setup in more detail.
Use Cases of JunoDB
With PayPal having made JunoDB open-source, it’s possible that you can also use it within your projects.
There are various use cases where JunoDB can help. Let’s look at a few important ones:
1 - Caching
You can use JunoDB as a temporary cache to store data that doesn’t change frequently.
Since JunoDB supports both short and long-lived TTLs, you can store data from a few seconds to a few days. For example, a use case is to store short-lived tokens in JunoDB instead of fetching them from the database.
Other items you can cache in JunoDB are user preferences, account details, and API responses.
2 - Idempotency
You can also use JunoDB to implement idempotency.
An operation is idempotent when it produces the same result even when applied multiple times. With idempotency, repeating the operation is safe and you don’t need to be worried about things like duplicate payments getting applied.
PayPal uses JunoDB to ensure they don’t process a particular payment multiple times due to retries. JunoDB’s high availability makes it an ideal data store to keep track of processing details without overloading the main database.
3 - Counters
Let’s say you’ve certain resources that aren’t available for some reason or they have an access limit to their usage. For example, these resources can be database connections, API rate limits, or user authentication attempts.
You can use JunoDB to store counters for these resources and track whether their usage exceeds the threshold.
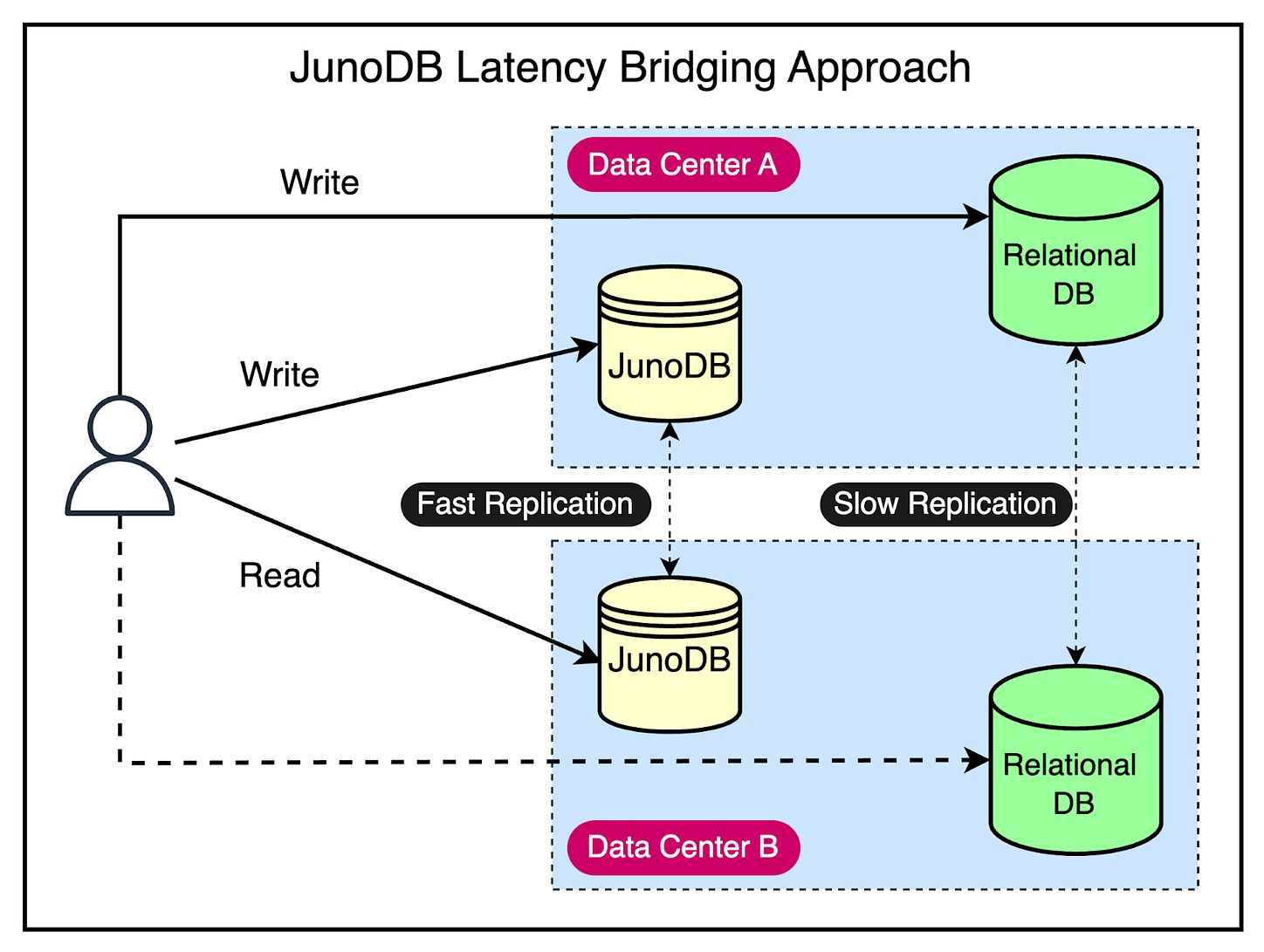
4 - Latency Bridging
As we discussed earlier, JunoDB provides fast inter-cluster replication. This can help you deal with slow replication in a more traditional setup.
For example, in PayPal’s case, they run Oracle in Active-Active mode, but the replication usually isn’t as fast as they would like for their requirement.
It means there are chances of inconsistent reads if records written in one data center are not replicated in the second data center and the first data center goes down.
JunoDB can help bridge the latency where you can write to Data Center A (both Oracle and JunoDB) and even if it goes down, you can read the updates consistently from the JunoDB instance in Data Center B.
See the below diagram for a better understanding of this concept.
Conclusion
JunoDB is a distributed key-value store playing a crucial role in various PayPal applications. It provides efficient data storage for fast access to reduce the load on costly database solutions.
While doing so, it also fulfills critical requirements such as scalability, high availability with performance, consistency, and security.
Due to its advantages, PayPal has started using JunoDB in multiple use cases and patterns. For us, it provides a great opportunity to learn about an exciting new database system.
References:
Like
Comment
Restack
© 2024 ByteByteGo
548 Market Street PMB 72296, San Francisco, CA 94104
Unsubscribe

by "ByteByteGo" <bytebytego@substack.com> - 11:36 - 16 Apr 2024 -
What’s on CEO agendas as 2024 unfolds?
On Point
The issues that matter most Brought to you by Liz Hilton Segel, chief client officer and managing partner, global industry practices, & Homayoun Hatami, managing partner, global client capabilities
•
Building geopolitical muscle. An endless series of disruptions are making it much harder to lead, Homayoun Hatami, McKinsey’s managing partner for client capabilities, reflects on a recent episode of The McKinsey Podcast. What should leaders focus on as 2024 unfolds? As geopolitical risks rise, leaders must strengthen their abilities to address issues such as investing in new markets. They should also consider establishing processes and systems that enable geopolitically informed decision making, McKinsey’s chief client officer Liz Hilton Segel says.
—Edited by Belinda Yu, editor, Atlanta
This email contains information about McKinsey's research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this newsletter because you subscribed to the Only McKinsey newsletter, formerly called On Point.
Copyright © 2024 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "Only McKinsey" <publishing@email.mckinsey.com> - 01:25 - 16 Apr 2024 -
A leader’s guide to digital virtualization
The real thing Brought to you by Liz Hilton Segel, chief client officer and managing partner, global industry practices, & Homayoun Hatami, managing partner, global client capabilities
“You stay in Wonderland, and I show you how deep the rabbit hole goes,” says the character Morpheus in the classic sci-fi thriller The Matrix, which showcases the extent to which the lines between the virtual and the real can blur. Today, digital technologies have enabled organizations to simulate, experiment, and innovate in imaginative ways and at speeds that would be almost impossible in a solely physical environment. This week, join us as we go down the rabbit hole—to a world where fantasy and reality can meet.

“The line between the digital and the physical has dissolved completely” for some companies, according to McKinsey senior partner Kimberly Borden and colleagues in a new article on digital innovation. “It’s now possible to create digital representations of components, products, and processes that precisely replicate the behavior of their real-world counterparts,” they note. For example, by creating virtual prototypes to simulate thousands of different racing conditions, a sailboat team won two major competitions; a heart pump maker deployed high-performance virtualization to reduce design optimization time by over a factor of 1,000. To be successful at digital virtualization, “build it to a code that verifiably matches digital results to the physical world, within an acceptable error range,” suggest the authors. “At that point, the virtualization can be trusted as authoritative and safe to use.”
That’s the potential size of the opportunity for the virtual travel industry by 2030, McKinsey research shows. The metaverse—a collective space where physical and digital worlds converge to deliver immersive, interactive user experiences—is already transforming many sectors: “You can attend concerts, shop, test products, visit attractions, and take workshops, all without physically traveling anywhere,” observe McKinsey partner Margaux Constantin and colleagues. To gain first-mover advantage in the metaverse, travel companies may need to focus on four key steps, including finding the right talent. “Developing any offer will likely require new skills—not just to make your immersive world look good but to ensure that it’s smooth and exhilarating to use,” say the McKinsey experts.
That’s Camille Kroely, chief metaverse and Web3 officer at L’Oréal, on how the global cosmetics company trains its own executives to become proficient in digital skills. L’Oréal has launched several initiatives to blend the physical, digital, and virtual worlds in its product marketing—for example, by working with avatar developers to offer virtual makeup looks. “Upskilling is now part of our road map,” says Kroely. “One of the first things that we did with our executive committee members was to train and upskill them so that they can keep learning by themselves—such as opening their own wallets, customizing their avatars, testing the platform, and going on [the online game platform] Roblox.”

Creating a dedicated digital unit can sometimes be the most efficient way to quickly spread innovative digital practices throughout the organization. That strategy has worked for Saudi Arabia’s Alinma Bank, according to chief digital officer Sami Al-Rowaithey. Recently, the bank established a “digital factory,” says Al-Rowaithey in a conversation with McKinsey partner Sonia Wedrychowicz. “It’s responsible for managing the entire digital structure and its associated strategies, business development, product innovation, experience management, performance management, and digital profitability,” he says. While that may seem like a daunting task, it helps to act fast, adds Al-Rowaithey. “The first thing I would say is to not spend a lot of time trying to figure out all the details of the journey. It’s important to start quick, learn as you go, be flexible, modify, and move on.”

Clones may seem creepy in science fiction, but they can be highly practical in the real world. Digital twins—virtual replicas of physical objects, systems, or processes—are increasingly popular in product development and manufacturing. “Interacting with or modifying a product in a virtual space can be quicker, easier, and safer than doing so in the real world,” note McKinsey partners Roberto Argolini and Johannes Deichmann and colleagues. For example, a factory digital twin can model floor layouts, optimize the footprint, and estimate inventory size. “Eventually, we may see the emergence of digital twins capable of learning from their own experiences, identifying opportunities and offering product improvement suggestions entirely autonomously,” say the McKinsey experts.
Lead by virtualizing.
– Edited by Rama Ramaswami, senior editor, New York
Share these insights
Did you enjoy this newsletter? Forward it to colleagues and friends so they can subscribe too. Was this issue forwarded to you? Sign up for it and sample our 40+ other free email subscriptions here.
This email contains information about McKinsey’s research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this email because you subscribed to the Leading Off newsletter.
Copyright © 2024 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "McKinsey Leading Off" <publishing@email.mckinsey.com> - 04:41 - 15 Apr 2024 -
Do you know how healthy your organization is?
On Point
New measures of organizational health Brought to you by Liz Hilton Segel, chief client officer and managing partner, global industry practices, & Homayoun Hatami, managing partner, global client capabilities
•
Power practices. “The research is very clear: organizational health propels long-term performance,” McKinsey partner Brooke Weddle shares on a recent episode of McKinsey Talks Talent. To support organizational health, companies have to get four power practices right, adds partner Bryan Hancock, who joined Weddle on the podcast. These are strategic clarity—which means having clear and measurable goals—role clarity, personal ownership, and competitive insights (that is, understanding where businesses fit in versus the competition).
•
Decisive leadership. As leaders grapple with disruptions such as generative AI and persistent economic uncertainty, they’re discovering the need to be both decisive and empowering. McKinsey’s recently updated Organizational Health Index highlights decisive leadership as one of the best predictors of organizational health. Decisive leaders are able to quickly make and follow through on decisions, rather than leaning on their authority to get things done, Weddle says. Explore new measures of organizational health and three steps leaders can take to get started.
—Edited by Belinda Yu, editor, Atlanta
This email contains information about McKinsey's research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this newsletter because you subscribed to the Only McKinsey newsletter, formerly called On Point.
Copyright © 2024 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "Only McKinsey" <publishing@email.mckinsey.com> - 01:08 - 15 Apr 2024 -
The week in charts
The Week in Charts
Latino representation in Hollywood, gen AI risk assessments, and more 
Share these insights
Did you enjoy this newsletter? Forward it to colleagues and friends so they can subscribe too. Was this issue forwarded to you? Sign up for it and sample our 40+ other free email subscriptions here.
This email contains information about McKinsey's research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this email because you subscribed to The Week in Charts newsletter.
Copyright © 2024 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "McKinsey Week in Charts" <publishing@email.mckinsey.com> - 03:38 - 13 Apr 2024 -
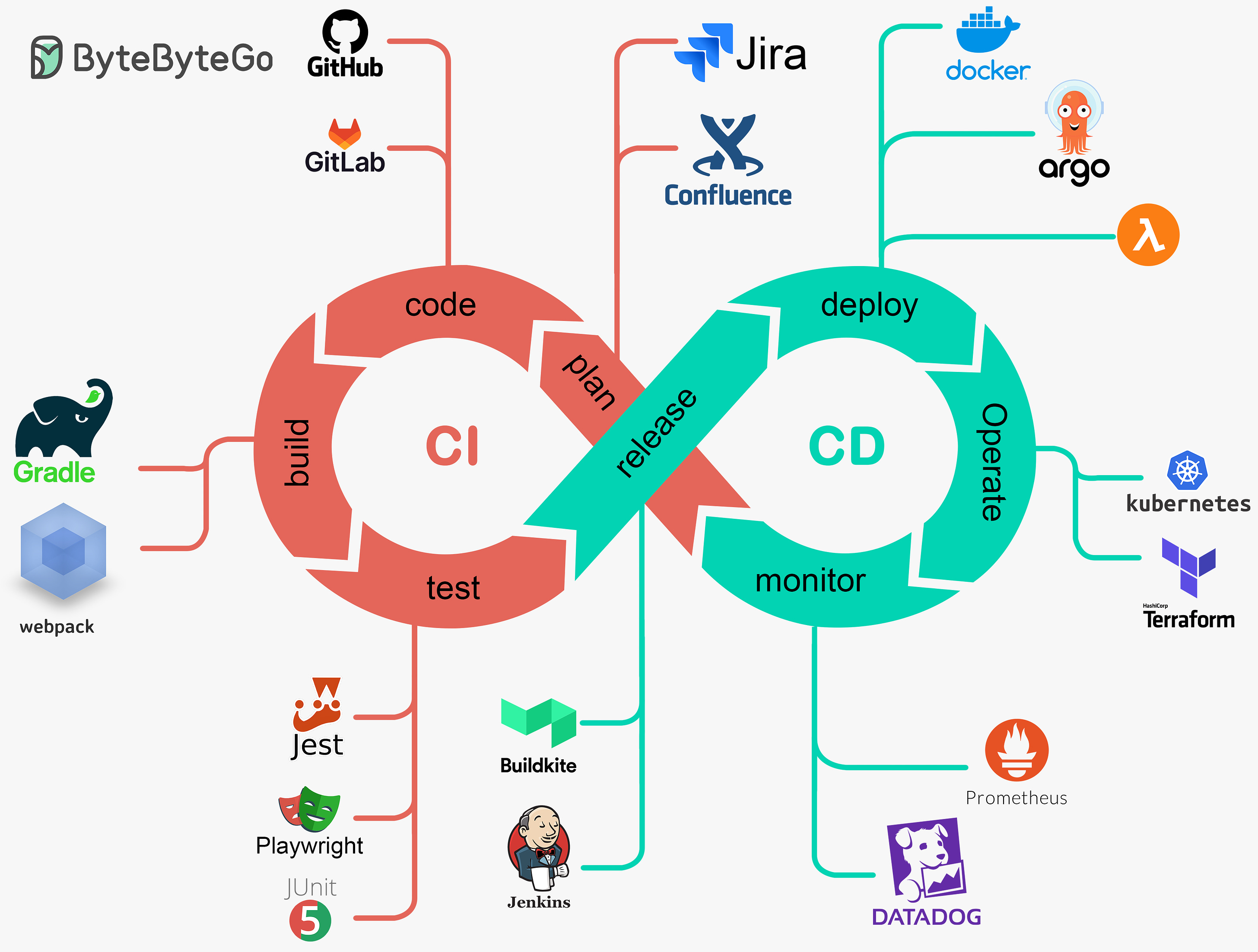
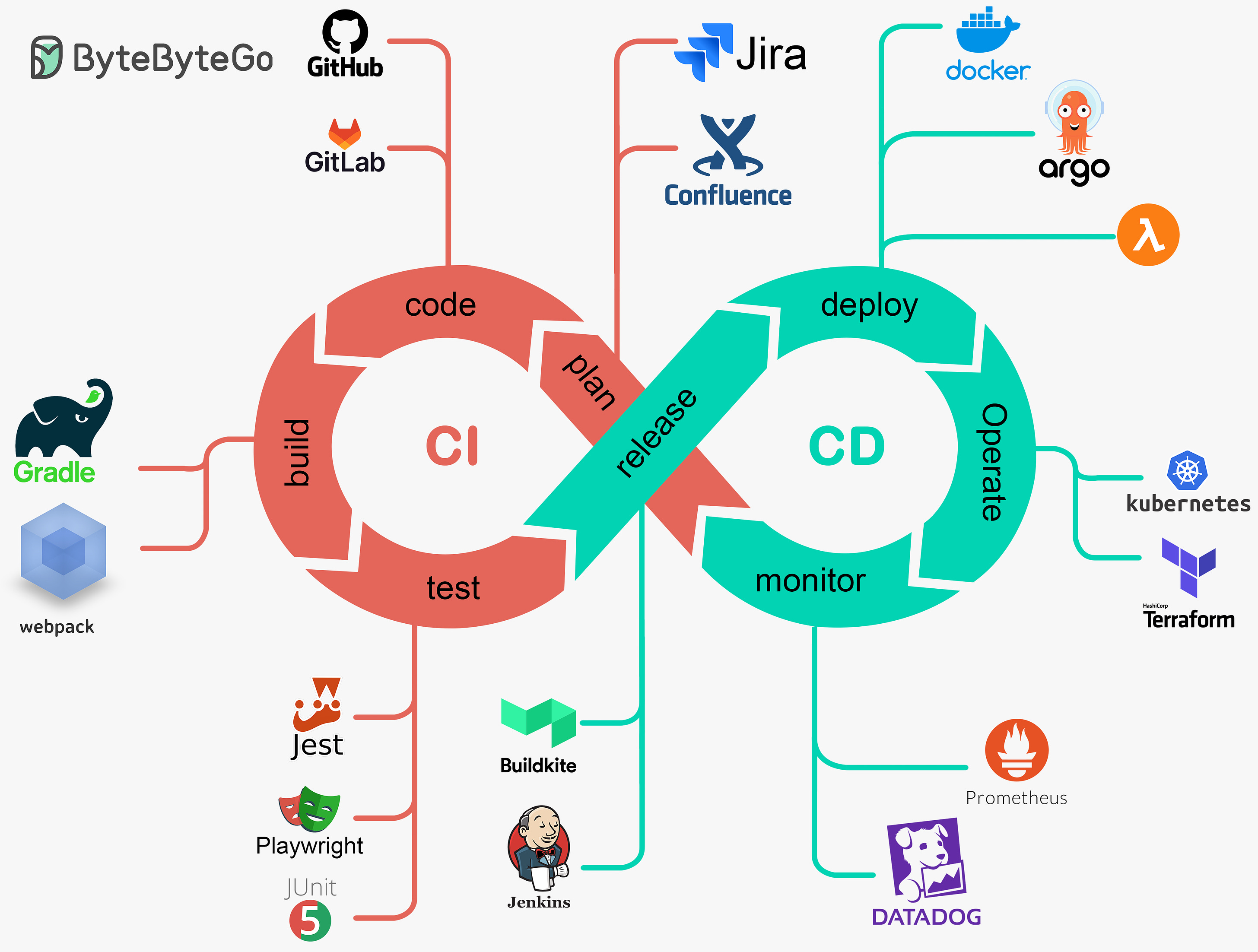
EP107: Top 9 Architectural Patterns for Data and Communication Flow
EP107: Top 9 Architectural Patterns for Data and Communication Flow
This week’s system de sign refresher: Top 9 Architectural Patterns for Data and Communication Flow How Netflix Really Uses Java? Top 6 Cloud Messaging Patterns What Are the Most Important AWS Services To Learn? SPONSOR US Register for POST/CON 24 | Save 20% Off (Sponsored)͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ Forwarded this email? Subscribe here for moreThis week’s system de sign refresher:
Top 9 Architectural Patterns for Data and Communication Flow
How Netflix Really Uses Java?
Top 6 Cloud Messaging Patterns
What Are the Most Important AWS Services To Learn?
SPONSOR US
Register for POST/CON 24 | Save 20% Off (Sponsored)

Postman’s annual user conference will be one of 2024’s biggest developer events and it features a great mix of high-level talks from tech executives and hands-on training from some of the best developers in the world.
Learn: Get first-hand knowledge from Postman experts and global tech leaders.
Level up: Attend 8-hour workshops to leave with new skills (and badges!)
Become the first to know: See the latest API platform innovations, including advancements in AI.
Help shape the future of Postman: Give direct feedback to the Postman leadership team.
Network with fellow API practitioners and global tech leaders — including speakers from OpenAI, Heroku, and more.
Have fun: Enjoy cocktails, dinner, 360° views of the city, and a live performance from multi-platinum recording artist T-Pain!
Use code PCBYTEBYTEGO20 and save 20% off your ticket!
Top 9 Architectural Patterns for Data and Communication Flow

Peer-to-Peer
The Peer-to-Peer pattern involves direct communication between two components without the need for a central coordinator.API Gateway
An API Gateway acts as a single entry point for all client requests to the backend services of an application.Pub-Sub
The Pub-Sub pattern decouples the producers of messages (publishers) from the consumers of messages (subscribers) through a message broker.Request-Response
This is one of the most fundamental integration patterns, where a client sends a request to a server and waits for a response.Event Sourcing
Event Sourcing involves storing the state changes of an application as a sequence of events.ETL
ETL is a data integration pattern used to gather data from multiple sources, transform it into a structured format, and load it into a destination database.Batching
Batching involves accumulating data over a period or until a certain threshold is met before processing it as a single group.Streaming Processing
Streaming Processing allows for the continuous ingestion, processing, and analysis of data streams in real-time.Orchestration
Orchestration involves a central coordinator (an orchestrator) managing the interactions between distributed components or services to achieve a workflow or business process.
Latest articles
If you’re not a paid subscriber, here’s what you missed.

To receive all the full articles and support ByteByteGo, consider subscribing:
How Netflix Really Uses Java?
Netflix is predominantly a Java shop.
Every backend application (including internal apps, streaming, and movie production apps) at Netflix is a Java application.
However, the Java stack is not static and has gone through multiple iterations over the years.
Here are the details of those iterations:
API Gateway
Netflix follows a microservices architecture. Every piece of functionality and data is owned by a microservice built using Java (initially version 8)
This means that rendering one screen (such as the List of List of Movies or LOLOMO) involved fetching data from 10s of microservices. But making all these calls from the client created a performance problem.
Netflix initially used the API Gateway pattern using Zuul to handle the orchestration.BFFs with Groovy & RxJava
Using a single gateway for multiple clients was a problem for Netflix because each client (such as TV, mobile apps, or web browser) had subtle differences.
To handle this, Netflix used the Backend-for-Frontend (BFF) pattern. Zuul was moved to the role of a proxy
In this pattern, every frontend or UI gets its own mini backend that performs the request fanout and orchestration for multiple services.
The BFFs were built using Groovy scripts and the service fanout was done using RxJava for thread management.GraphQL Federation
The Groovy and RxJava approach required more work from the UI developers in creating the Groovy scripts. Also, reactive programming is generally hard.
Recently, Netflix moved to GraphQL Federation. With GraphQL, a client can specify exactly what set of fields it needs, thereby solving the problem of overfetching and underfetching with REST APIs.
The GraphQL Federation takes care of calling the necessary microservices to fetch the data.
These microservices are called Domain Graph Service (DGS) and are built using Java 17, Spring Boot 3, and Spring Boot Netflix OSS packages. The move from Java 8 to Java 17 resulted in 20% CPU gains.
More recently, Netflix has started to migrate to Java 21 to take advantage of features like virtual threads.
Top 6 Cloud Messaging Patterns
How do services communicate with each other? The diagram below shows 6 cloud messaging patterns.

🔹 Asynchronous Request-Reply
This pattern aims at providing determinism for long-running backend tasks. It decouples backend processing from frontend clients.
In the diagram below, the client makes a synchronous call to the API, triggering a long-running operation on the backend. The API returns an HTTP 202 (Accepted) status code, acknowledging that the request has been received for processing.
🔹 Publisher-Subscriber
This pattern targets decoupling senders from consumers, and avoiding blocking the sender to wait for a response.
🔹 Claim Check
This pattern solves the transmision of large messages. It stores the whole message payload into a database and transmits only the reference to the message, which will be used later to retrieve the payload from the database.
🔹 Priority Queue
This pattern prioritizes requests sent to services so that requests with a higher priority are received and processed more quickly than those with a lower priority.
🔹 Saga
Saga is used to manage data consistency across multiple services in distributed systems, especially in microservices architectures where each service manages its own database.
The saga pattern addresses the challenge of maintaining data consistency without relying on distributed transactions, which are difficult to scale and can negatively impact system performance.
🔹 Competing Consumers
This pattern enables multiple concurrent consumers to process messages received on the same messaging channel. There is no need to configure complex coordination between the consumers. However, this pattern cannot guarantee message ordering.
Reference: Azure Messaging patternsWhat Are the Most Important AWS Services To Learn?
Since its inception in 2006, AWS has rapidly evolved from simple offerings like S3 and EC2 to an expansive, versatile cloud ecosystem.

Today, AWS provides a highly reliable, scalable infrastructure platform with over 200 services in the cloud, powering hundreds of thousands of businesses in 190 countries around the world.
For both newcomers and seasoned professionals, navigating the broad set of AWS services is no small feat.
From computing power, storage options, and networking capabilities to database management, analytics, and machine learning, AWS provides a wide array of tools that can be daunting to understand and master.
Each service is tailored to specific needs and use cases, requiring a deep understanding of not just the services themselves, but also how they interact and integrate within an IT ecosystem.
This attached illustration can serve as both a starting point and a quick reference for anyone looking to demystify AWS and focus their efforts on the services that matter most.
It provides a visual roadmap, outlining the foundational services that underpin cloud computing essentials, as well as advanced services catering to specific needs like serverless architectures, DevOps, and machine learning.
Over to you: What has your journey been like with AWS so far?SPONSOR US
Get your product in front of more than 500,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing hi@bytebytego.com.
© 2024 ByteByteGo
548 Market Street PMB 72296, San Francisco, CA 94104
Unsubscribe
by "ByteByteGo" <bytebytego@substack.com> - 11:35 - 13 Apr 2024 -
Embarcarse en un reinicio de la IA generativa
Además, el papel de la IA generativa en el diseño creativo de productos físicos Comparte este email

Aunque la IA generativa ha sido uno de los temas principales de la agenda de muchas empresas este último año, capturar su valor es más difícil de lo esperado. 2024 es el año para que la IA generativa demuestre su valor, lo que requerirá que las empresas realicen cambios fundamentales y reconfiguren el negocio, escriben Eric Lamarre, Alex Singla, Alexander Sukharevsky y Rodney Zemmel en nuestro artículo destacado. Otros temas relevantes son:
•
el valor aún sin explotar de ofrecer más oportunidades al talento latino en Hollywood
•
el poder de la colaboración entre el CEO y el CMO
•
cómo aprovechar todo el potencial de la IA generativa en el diseño de productos físicos
•
cómo las instituciones financieras pueden prepararse para el futuro frente a los crecientes riesgos cibernéticos
La selección de nuestros editores
LOS DESTACADOS DE ESTE MES

Latinos en Hollywood: Amplificando voces, ampliando horizontes
Mejorar la representación de los latinos, sus historias y su cultura delante y detrás de cámaras podría generar miles de millones de dólares en nuevos ingresos para la industria, según un nuevo estudio de McKinsey.
Cierre la brecha
Análisis de la relación CEO-CMO y su efecto en el crecimiento
Los CEOs reconocen la experiencia y la importancia de los directores de marketing, así como su papel en el crecimiento de la empresa, pero aún existe una desconexión estratégica en la alta dirección. He aquí cómo cerrar la brecha.
Adopte un enfoque holístico
La IA generativa impulsa el diseño creativo de productos físicos, pero no es una varita mágica
Las herramientas de IA generativa pueden acortar significativamente los ciclos de vida del diseño de productos físicos y estimular la innovación, pero son necesarios los conocimientos y la discreción de los expertos en diseño para mitigar los posibles obstáculos.
Desbloquee la creatividad
Cómo la IA generativa puede ayudar a los bancos a gestionar el riesgo y el cumplimiento normativo
En los próximos cinco años, la IA generativa podría cambiar fundamentalmente la gestión de riesgos de las instituciones financieras al automatizar, acelerar y mejorar todo, desde el cumplimiento normativo hasta el control del riesgo climático.
Estrategias ganadoras para la IA generativa
El reloj cibernético no se detiene: Reducir el riesgo de las tecnologías emergentes en los servicios financieros
A medida que las instituciones financieras adoptan activamente las tecnologías emergentes, deberían actuar ahora con el fin de prepararse para el futuro frente a los crecientes riesgos cibernéticos.
Actúe
La creciente complejidad de ser miembro de un consejo de administración
Expertos en consejos de administración explican cómo sus miembros pueden hacer frente a las exigencias de unas agendas cada vez más apretadas.
Equilibre responsabilidadesEsperamos que disfrute de los artículos en español que seleccionamos este mes y lo invitamos a explorar también los siguientes artículos en inglés.

McKinsey Explainers
Find direct answers to complex questions, backed by McKinsey’s expert insights.
Learn more
McKinsey Themes
Browse our essential reading on the topics that matter.
Get up to speed
McKinsey on Books
Explore this month’s best-selling business books prepared exclusively for McKinsey Publishing by Circana.
See the lists
McKinsey Chart of the Day
See our daily chart that helps explain a changing world—as we strive for sustainable, inclusive growth.
Dive in
McKinsey Classics
Significant improvements in risk management can be gained quickly through selective digitization—but capabilities must be test hardened before release. Read our 2017 classic “Digital risk: Transforming risk management for the 2020s” to learn more.
Rewind
Leading Off
Our Leading Off newsletter features revealing research and inspiring interviews to empower you—and those you lead.
Subscribe now— Edited by Joyce Yoo, editor, New York
COMPARTA ESTAS IDEAS
¿Disfrutó este boletín? Reenvíelo a colegas y amigos para que ellos también puedan suscribirse. ¿Se le remitió este articulo? Regístrese y pruebe nuestras más de 40 suscripciones gratuitas por correo electrónico aquí.
Este correo electrónico contiene información sobre la investigación , los conocimientos, los servicios o los eventos de McKinsey. Al abrir nuestros correos electrónicos o hacer clic en los enlaces, acepta nuestro uso de cookies y tecnología de seguimiento web. Para obtener más información sobre cómo usamos y protegemos su información, consulte nuestra política de privacidad.
Recibió este correo electrónico porque es un miembro registrado de nuestro boletín informativo Destacados.
Copyright © 2024 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "Destacados de McKinsey" <publishing@email.mckinsey.com> - 08:19 - 13 Apr 2024 -
RE: Seeking for the agent in Saudi Arabia
Dear agent,
Trust you are doing great.
I sincerely invite you to join GLA platform and cover the increasing request ex Saudi Arabia from our GLA members.
Now is the best time to join GLA Family in the beginning of 2024.
Last but not the least, I wish you, your family and your company a prosperous 2024! See you in GLA Dubai Conference for a great talk if possible!
I am looking forward to your cooperative feedback regarding your GLA Membership Application.
Best regards,
Ella Liu
GLA Overseas Department
Mobile:
(86) 199 2879 7478
Email:
Company:
GLA Co.,Ltd
Website:
Address:
No. 2109, 21st Floor, HongChang, Plaza, No. 2001, Road Shenzhen, China
Ø The 10th GLA Global Logistics Conference will be held at 29th April–2nd May 2024 in Dubai, UAE.
Registration Link: https://www.glafamily.com/meeting/registration/Ella
Ø The 8th GLA Conference in Bangkok Thailand, online album: https://live.photoplus.cn/live/76884709?accessFrom=qrcode&userType=null&state=STATE
Ø The 9th GLA Conference in Hainan China, online album: https://live.photoplus.cn/live/61916679?accessFrom=qrcode&userType=null&state=STATE&code=0717A0200FZ46R10fJ200EJbI337A02u#/live
【Notice Agreement No 7】
7. GLA president reserves the right to cancel or reject membership or application.
company shall cease to be a member of GLA if:
a) the Member does not adhere to GLA terms and conditions
b) the Member gives notice of resignation in writing to the GLA.
c) No good reputation in the market.
d) Have bad debt records in the GLA platform or in the market
by "Ella Liu" <member139@glafamily.com> - 02:08 - 12 Apr 2024 -
Want to know how much the space sector could be worth by 2035?
On Point
A new WEF–McKinsey report Brought to you by Liz Hilton Segel, chief client officer and managing partner, global industry practices, & Homayoun Hatami, managing partner, global client capabilities
•
Space economy boom. Activity in space is accelerating. In 2023, “backbone” applications for space (such as satellites and services like GPS) made up $330 billion of the global space economy. “Reach” applications, which describe space technologies that companies across industries use to help generate revenues, represented another $300 billion. Over the next decade, space applications are expected to grow at an annual rate that is double the projected rate of GDP growth, McKinsey senior partner Ryan Brukardt and coauthors reveal.
•
Four key findings. To learn what will shape the future space economy, the World Economic Forum and McKinsey spoke with more than 60 leaders and experts across the globe. The team also used market forecasts and other data to develop original estimates for the size of each part of the space economy, including commercial services and state-sponsored civil and defense applications. To read our key findings on the space economy, download the full report, Space: The $1.8 trillion opportunity for economic growth.
—Edited by Belinda Yu, editor, Atlanta
This email contains information about McKinsey's research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this newsletter because you subscribed to the Only McKinsey newsletter, formerly called On Point.
Copyright © 2024 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "Only McKinsey" <publishing@email.mckinsey.com> - 01:13 - 12 Apr 2024 -
White Label Fuel Monitoring Software
White Label Fuel Monitoring Software
A versatile fuel monitoring system that can be tailored to fit any brand or company's fuel sensor, regardless of type or model..png?width=1200&upscale=true&name=White%20label%20fuel%20monitoring%20(1).png)
A versatile fuel monitoring system that can be tailored to fit any brand or company's fuel sensor, regardless of type or model.
Catch a glimpse of what our software has to offer
.png?width=1200&upscale=true&name=Frame%201237760%20(1).png)
Uffizio Technologies Pvt. Ltd., 4th Floor, Metropolis, Opp. S.T Workshop, Valsad, Gujarat, 396001, India





by "Sunny Thakur" <sunny.thakur@uffizio.com> - 08:00 - 11 Apr 2024 -
Embracing Chaos to Improve System Resilience: Chaos Engineering
Embracing Chaos to Improve System Resilience: Chaos Engineering
Imagine it's the early 2000s, and you're a developer with a bold idea. You want to test your software not in a safe, controlled environment but right where the action is: the production environment. This is where real users interact with your system. Back then, suggesting something like this might have gotten you some strange looks from your bosses. But now, testing in the real world is not just okay; it's often recommended.͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ Forwarded this email? Subscribe here for moreLatest articles
If you’re not a subscriber, here’s what you missed this month.
To receive all the full articles and support ByteByteGo, consider subscribing:
Imagine it's the early 2000s, and you're a developer with a bold idea. You want to test your software not in a safe, controlled environment but right where the action is: the production environment. This is where real users interact with your system. Back then, suggesting something like this might have gotten you some strange looks from your bosses. But now, testing in the real world is not just okay; it's often recommended.
Why the big change? A few reasons stand out. Systems today are more complex than ever, pushing us to innovate faster and ensure our services are both reliable and strong. The rise of cloud technology, microservices, and distributed systems has changed the game. We've had to adapt our methods and mindsets accordingly.
Our goal now is to make systems that can handle anything—be it a slowdown or a full-blown outage. Enter Chaos Engineering.
In this issue, we dive into what chaos engineering is all about. We'll break down its key principles, how it's practiced, and examples from the real world. You'll learn how causing a bit of controlled chaos can actually help find and fix weaknesses before they become major problems.
Prepare to see how embracing chaos can lead to stronger, more reliable systems. Let's get started!

What is Chaos Engineering?
So, what exactly is chaos engineering? It's a way to deal with unexpected issues in software development and keep systems up and running. Some folks might think that a server running an app will continue without a hitch forever. Others believe that problems are just part of the deal and that downtime is inevitable.
Chaos engineering strikes a balance between these views. It recognizes that things can go wrong but asserts that we can take steps to prevent these issues from impacting our systems and the performance of our apps.
This approach involves experimenting on our live, production systems to identify weak spots and areas that aren't as reliable as they should be. It's about measuring how much we trust our system's resilience and working to boost that confidence
However, it's important to understand that being 100% sure nothing will go wrong is unrealistic. Through chaos engineering, we intentionally introduce unexpected events to uncover vulnerabilities. These events can vary widely, such as taking down a server randomly, disrupting a data center, or tampering with load balancers and application replicas.
In short, chaos engineering is about designing experiments that rigorously test our systems' robustness.
Defining Chaos Engineering
There are many ways to describe chaos engineering, but here's a definition that captures its essence well, sourced from https://principlesofchaos.org/.
“Chaos Engineering is the discipline of experimenting on a system in order to build confidence in the system’s capability to withstand turbulent conditions in production.”
This definition highlights the core objective of chaos engineering: to ensure our systems can handle the unpredictable nature of real-world operations.
Performance Engineering vs. Chaos Engineering
When we talk about ensuring our systems run smoothly, two concepts often come up: performance engineering and chaos engineering. Let's discuss what sets these two apart and how they might overlap.
Many developers are already familiar with performance engineering, which is in the same family as DevOps. It involves using a combination of tools, processes, and technologies to monitor our system's performance and make continuous improvements. This includes conducting various types of testing, such as load, stress, and endurance tests, all aimed at boosting the performance of our applications.
On the flip side, chaos engineering is about intentionally breaking things. Yes, this includes stress testing, but it's more about observing how systems respond under unexpected stress. Stress testing could be seen as a form of chaos experiment. So, one way to look at it is to consider performance engineering as a subset of chaos engineering or the other way around, depending on how you apply these practices.
Another way to view these two is as distinct disciplines within an organization. One team might focus solely on conducting chaos experiments and learning from the failures, while another might immerse itself in performance engineering tasks like testing and monitoring. Depending on the structure of the organization, the skill sets of the team, and various other factors, we might have separate teams for each discipline or one team that tackles both.
Chaos Engineering in Practice
Let's consider an example to better understand chaos engineering. Imagine we have a system with a load balancer that directs requests to web servers. These servers then connect to a payment service, which, in turn, interacts with a third-party API and a cache service, all located in Availability Zone A. If the payment service fails to communicate with the third-party API or the cache, requests need to be rerouted to Availability Zone B to maintain high availability.
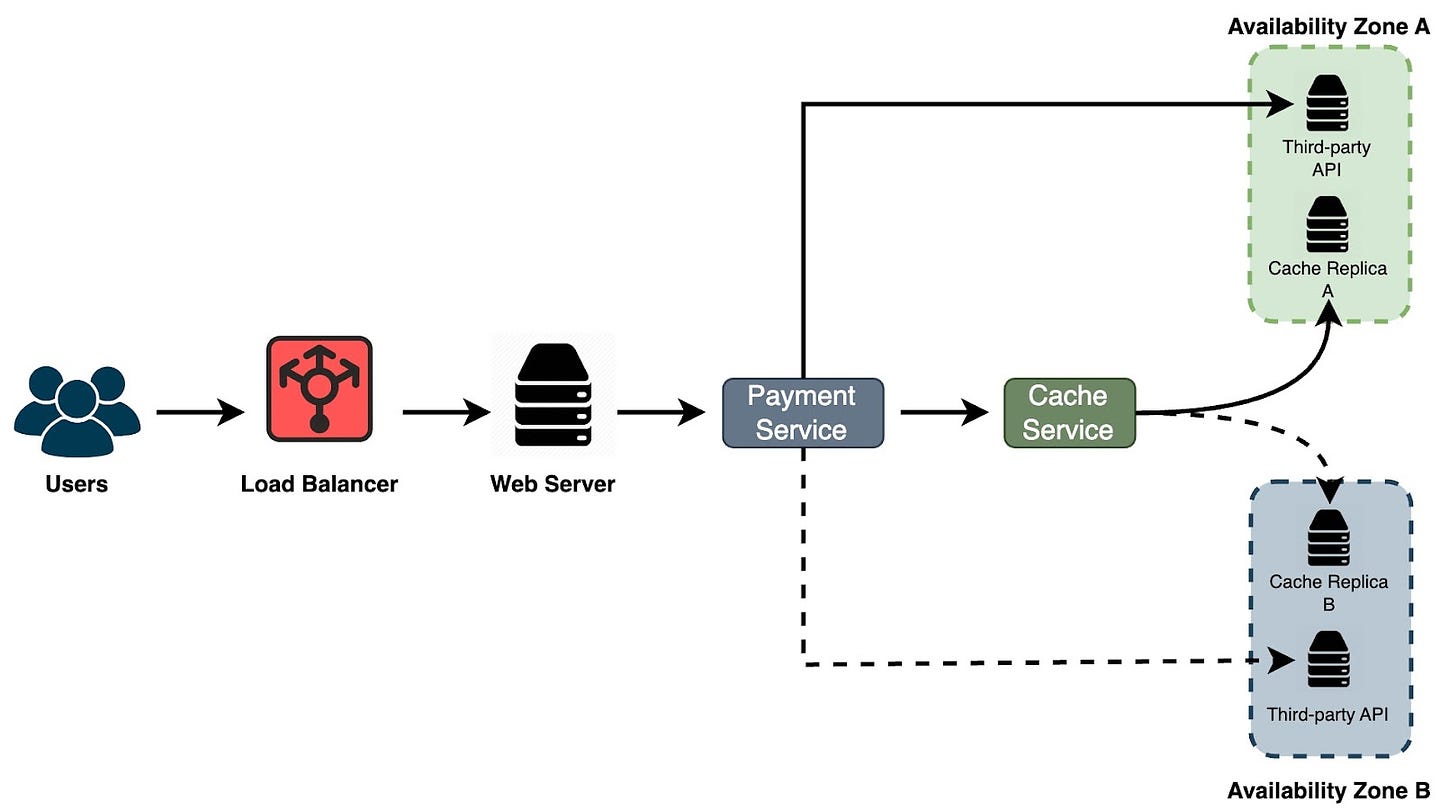

Continue reading this post for free, courtesy of Alex Xu.
A subscription gets you:
An extra deep dive on Thursdays Full archive Many expense it with team's learning budget © 2024 ByteByteGo
548 Market Street PMB 72296, San Francisco, CA 94104
Unsubscribe
by "ByteByteGo" <bytebytego@substack.com> - 11:37 - 11 Apr 2024 -
Maximise ROI: Insights from the 2023 Observability Forecast Report
New Relic

 Our latest report unveils pivotal insights for businesses considering observability. The 2023 Observability Forecast, with data collected from 1,700 technology professionals across 15 countries, dives into observability practices and their impacts on costs and revenue.
Our latest report unveils pivotal insights for businesses considering observability. The 2023 Observability Forecast, with data collected from 1,700 technology professionals across 15 countries, dives into observability practices and their impacts on costs and revenue.
The report highlights the ROI of observability according to respondents, including driving business efficiency, security, and profitability.
Access the blog now that rounds up key insights to understand the potential impact of observability on your business.
Read Now Need help? Let's get in touch.



This email is sent from an account used for sending messages only. Please do not reply to this email to contact us—we will not get your response.
This email was sent to info@learn.odoo.com Update your email preferences.
For information about our privacy practices, see our Privacy Policy.
Need to contact New Relic? You can chat or call us at +44 20 3859 9190.
Strand Bridge House, 138-142 Strand, London WC2R 1HH
© 2024 New Relic, Inc. All rights reserved. New Relic logo are trademarks of New Relic, Inc


by "New Relic" <emeamarketing@newrelic.com> - 07:11 - 11 Apr 2024 -
How can the world jump-start productivity?
On Point
Why economies need productivity growth Brought to you by Liz Hilton Segel, chief client officer and managing partner, global industry practices, & Homayoun Hatami, managing partner, global client capabilities
•
Productivity slowdown. Over the past 25 years, strong growth in productivity has helped raise the world’s living standards, with median economy productivity jumping sixfold, McKinsey Global Institute chair Sven Smit and coauthors reveal. More recently, though, productivity growth has faded, with a near-universal slowdown since the 2008 global financial crisis. In advanced economies, productivity growth fell to less than 1% in the decade between 2012 and 2022. Over the same period, productivity growth also fell in emerging economies.
—Edited by Belinda Yu, editor, Atlanta
This email contains information about McKinsey's research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this newsletter because you subscribed to the Only McKinsey newsletter, formerly called On Point.
Copyright © 2024 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "Only McKinsey" <publishing@email.mckinsey.com> - 11:05 - 10 Apr 2024 -
Unlock Data Transformation at Sumo Logic's Booth - AWS Summit London
Sumo Logic
Experience our cutting-edge solutions at Booth B36
Dear Mohammad,
I'm thrilled to extend an invitation for you to visit the Sumo Logic booth at the AWS Summit London on the 24th of April at the ExCel London.
Discover how Sumo Logic can transform your approach to data management, ensuring security, scalability, and efficiency. Our experts will showcase our latest innovations and discuss tailored solutions to address your specific needs.
Here are compelling reasons to visit Booth B36:
- Find out how you can power DevSecOps from only one cloud native platform
- Learn more about our $0 data ingest approach
- Explore configuration management and compliance reporting
- Discover how we leverage AI/ML to uncover and mitigate threats
Claim your free entry ticket using this link.
We eagerly anticipate your presence at Booth B36!
Best regards,
Sumo Logic
About Sumo Logic
Sumo Logic is the pioneer in continuous intelligence, a new category of software to address the data challenges presented by digital transformation, modern applications, and cloud computing.Sumo Logic, Aviation House, 125 Kingsway, London WC2B 6NH, UK
© 2024 Sumo Logic, All rights reserved.Unsubscribe
by "Sumo Logic" <marketing-info@sumologic.com> - 06:01 - 10 Apr 2024 -
What does it take to become a CFO?
On Point
5 priorities for CFO hopefuls Brought to you by Liz Hilton Segel, chief client officer and managing partner, global industry practices, & Homayoun Hatami, managing partner, global client capabilities
•
Take career risks. What matters most for securing the CFO job? To find out, McKinsey senior partner Andy West and coauthors spoke with former CFOs, such as Arun Nayar, Tyco International’s former EVP and CFO and PepsiCo’s former CFO of global operations. Earlier in his career, Nayar realized that to rise higher, he would need to gain operational know-how. After obtaining a role overseeing finance in PepsiCo’s global operations division, an area he knew nothing about, he formed the No Fear Club, through which he mentors others in finance roles.
—Edited by Belinda Yu, editor, Atlanta
This email contains information about McKinsey's research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this newsletter because you subscribed to the Only McKinsey newsletter, formerly called On Point.
Copyright © 2024 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "Only McKinsey" <publishing@email.mckinsey.com> - 01:11 - 10 Apr 2024 -
Reddit's Architecture: The Evolutionary Journey
Reddit's Architecture: The Evolutionary Journey
The comprehensive developer resource for B2B User Management (Sponsored) Building an enterprise-ready, resilient B2B auth is one of the more complex tasks developers face these days. Today, even smaller startups are demanding security features like SSO that used to be the purview of the Fortune 500.͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ Forwarded this email? Subscribe here for moreThe comprehensive developer resource for B2B User Management (Sponsored)

Building an enterprise-ready, resilient B2B auth is one of the more complex tasks developers face these days. Today, even smaller startups are demanding security features like SSO that used to be the purview of the Fortune 500.
The latest guide from WorkOS covers the essentials of modern day user management for B2B apps — from 101 topics to more advanced concepts that include:
→ SSO, MFA, and sessions
→ Bot policies, org auth policies, and UI considerations
→ Identity linking, email verification, and just-in-time provisioningThis resource also presents an easier alternative for supporting user management.
Reddit's Architecture: The Evolutionary Journey
Reddit was founded in 2005 with the vision to become “the front page of the Internet”.
Over the years, it has evolved into one of the most popular social networks on the planet fostering tens of thousands of communities built around the passions and interests of its members. With over a billion monthly users, Reddit is where people come to participate in conversations on a vast array of topics.
Some interesting numbers that convey Reddit’s incredible popularity are as follows:
Reddit has 1.2 billion unique monthly visitors, turning it into a virtual town square.
Reddit’s monthly active user base has exploded by 366% since 2018, demonstrating the need for online communities.
In 2023 alone, an astonishing 469 million posts flooded Reddit’s servers resulting in 2.84 billion comments and interactions.
Reddit ranked as the 18th most visited website globally in 2023, raking in $804 million in revenue.
Looking at the stats, it’s no surprise that their recent IPO launch was a huge success, propelling Reddit to a valuation of around $6.4 billion.
While the monetary success might be attributed to the leadership team, it wouldn’t have been possible without the fascinating journey of architectural evolution that helped Reddit achieve such popularity.
In this post, we will go through this journey and look at some key architectural steps that have transformed Reddit.
The Early Days of Reddit
Reddit was originally written in Lisp but was rewritten in Python in December 2005.
Lisp was great but the main issue at the time was the lack of widely used and tested libraries. There was rarely more than one library choice for any task and the libraries were not properly documented.
Steve Huffman (one of the founders of Reddit) expressed this problem in his blog:
“Since we're building a site largely by standing on the shoulders of others, this made things a little tougher. There just aren't as many shoulders on which to stand.”
When it came to Python, they initially used a web framework named web.py that was developed by Swartz (another co-founder of Reddit). Later in 2009, Reddit started to use Pylons as its web framework.
The Core Components of Reddit’s Architecture
The below diagram shows the core components of Reddit’s high-level architecture.
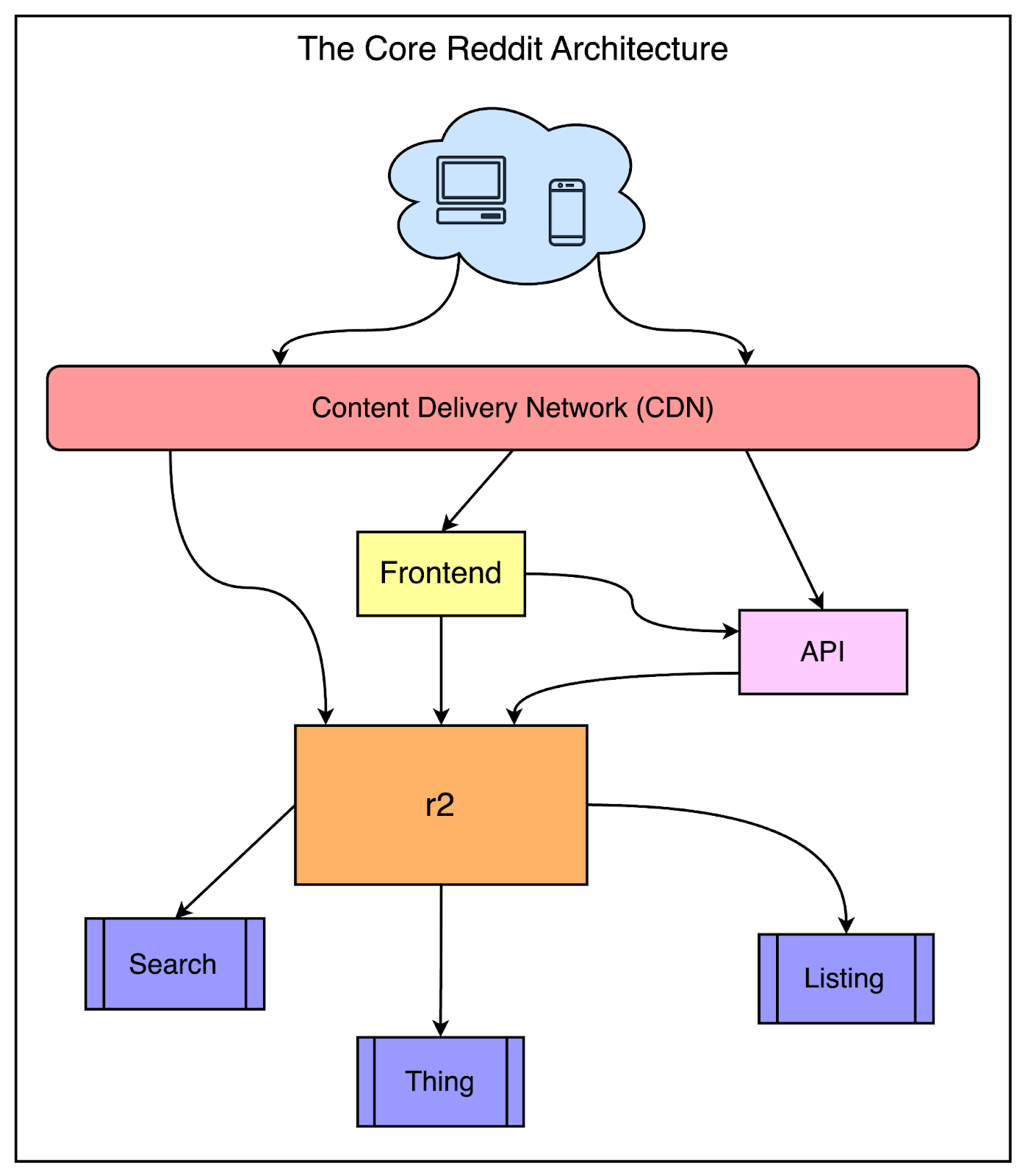
While Reddit has many moving parts and things have also evolved over the years, this diagram represents the overall scaffolding that supports Reddit.
The main components are as follows:
Content Delivery Network: Reddit uses a CDN from Fastly as a front for the application. The CDN handles a lot of decision logic at the edge to figure out how a particular request will be routed based on the domain and path.
Front-End Applications: Reddit started using jQuery in early 2009. Later on, they also started using Typescript to redesign their UI and moved to Node.js-based frameworks to embrace a modern web development approach.
The R2 Monolith: In the middle is the giant box known as r2. This is the original monolithic application built using Python and consists of functionalities like Search and entities such as Things and Listings. We will look at the architecture of R2 in more detail in the next section.
From an infrastructure point of view, Reddit decommissioned the last of its physical servers in 2009 and moved the entire website to AWS. They had been one of the early adopters of S3 and were using it to host thumbnails and store logs for quite some time.
However, in 2008, they decided to move batch processing to AWS EC2 to free up more machines to work as application servers. The system worked quite well and in 2009 they completely migrated to EC2.
R2 Deep Dive
As mentioned earlier, r2 is the core of Reddit.
It is a giant monolithic application and has its own internal architecture as shown below:
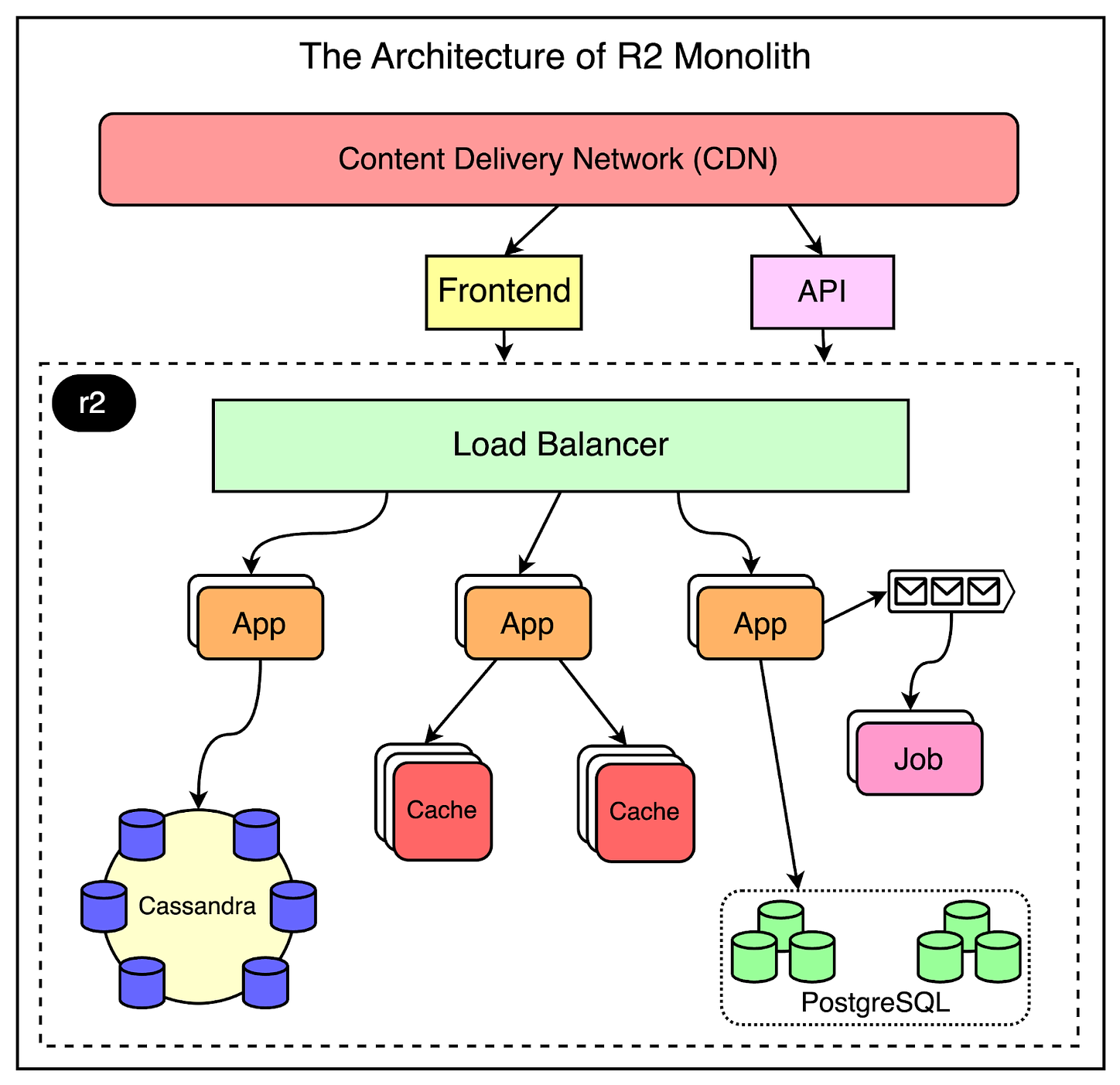
For scalability reasons, the same application code is deployed and run on multiple servers.
The load balancer sits in the front and performs the task of routing the request to the appropriate server pool. This makes it possible to route different request paths such as comments, the front page, or the user profile.
Expensive operations such as a user voting or submitting a link are deferred to an asynchronous job queue via Rabbit MQ. The messages are placed in the queue by the application servers and are handled by the job processors.
From a data storage point of view, Reddit relies on Postgres for its core data model. To reduce the load on the database, they place memcache clusters in front of Postgres. Also, they use Cassandra quite heavily for new features mainly because of its resiliency and availability properties.
Latest articles
If you’re not a paid subscriber, here’s what you missed.
To receive all the full articles and support ByteByteGo, consider subscribing:
The Expansion Phase
As Reddit has grown in popularity, its user base has skyrocketed. To keep the users engaged, Reddit has added a lot of new features. Also, the scale of the application and its complexity has gone up.
These changes have created a need to evolve the design in multiple areas. While design and architecture is an ever-changing process and small changes continue to occur daily, there have been concrete developments in several key areas.
Let’s look at them in more detail to understand the direction Reddit has taken when it comes to architecture.
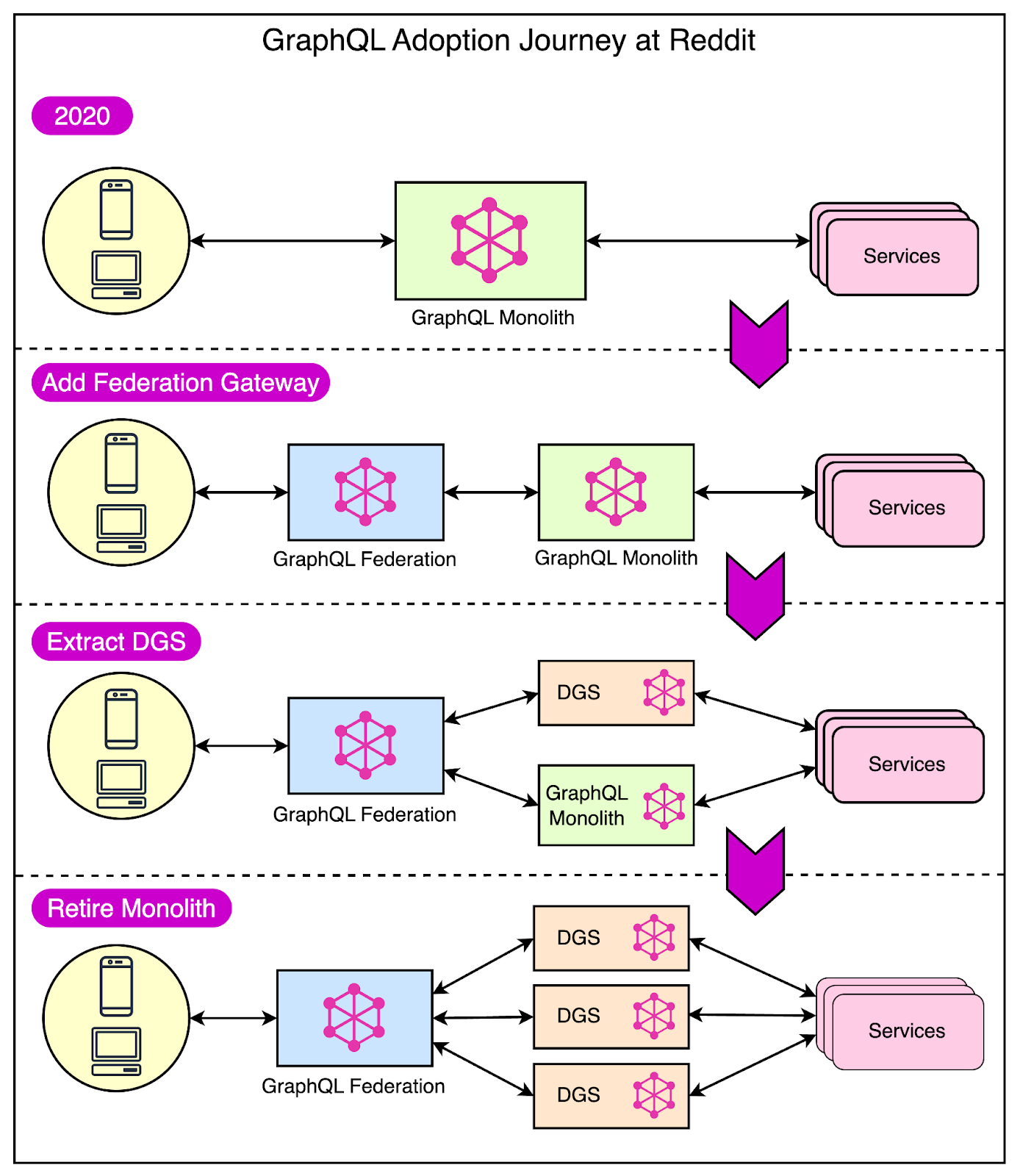
GraphQL Federation with Golang Microservices
Reddit started its GraphQL journey in 2017. Within 4 years, the clients of the monolithic application had fully adopted GraphQL.
GraphQL is an API specification that allows clients to request only the data they want. This makes it a great choice for a multi-client system where each client has slightly different data needs.
In early 2021, they also started moving to GraphQL Federation with a few major goals:
Retiring the monolith
Improving concurrency
Encouraging separation of concerns
GraphQL Federation is a way to combine multiple smaller GraphQL APIs (also known as subgraphs) into a single, large GraphQL API (called the supergraph). The supergraph acts as a central point for client applications to send queries and receive data.
When a client sends a query to the supergraph, the supergraph figures out which subgraphs have the data needed to answer that query. It routes the relevant parts of the query to those subgraphs, collects the responses, and sends the combined response back to the client.
In 2022, the GraphQL team at Reddit added several new Go subgraphs for core Reddit entities like Subreddits and Comments. These subgraphs took over ownership of existing parts of the overall schema.
During the transition phase, the Python monolith and new Go subgraphs work together to fulfill queries. As more and more functionalities are extracted to individual Go subgraphs, the monolith can be eventually retired.
The below diagram shows this gradual transition.
One major requirement for Reddit was to handle the migration of functionality from the monolith to a new Go subgraph incrementally.
They want to ramp up traffic gradually to evaluate error rates and latencies while having the ability to switch back to the monolith in case of any issues.
Unfortunately, the GraphQL Federation specification doesn’t offer a way to support this gradual migration of traffic. Therefore, Reddit went for a Blue/Green subgraph deployment as shown below:
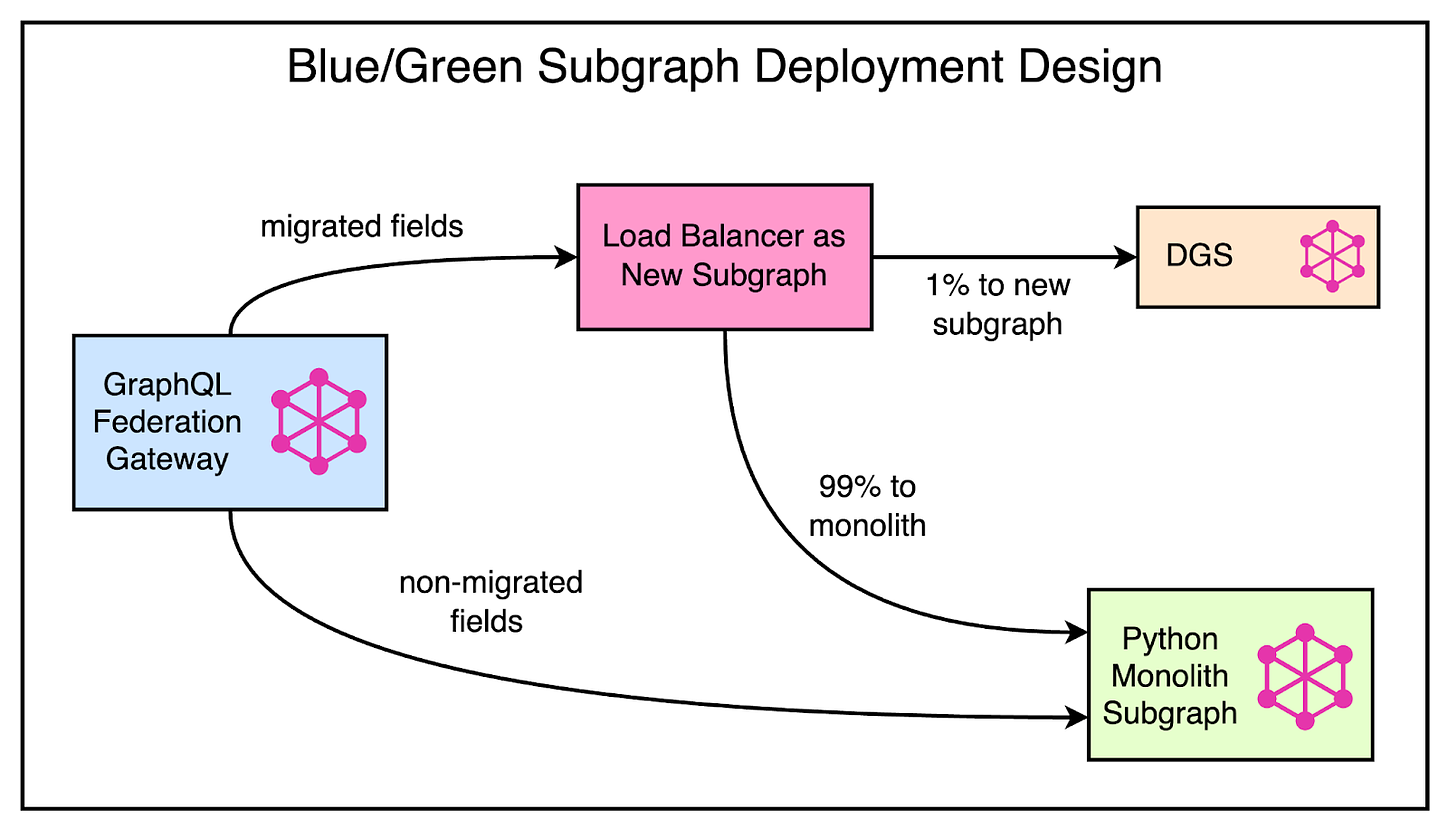
In this approach, the Python monolith and Go subgraph share ownership of the schema. A load balancer sits between the gateway and the subgraphs to send traffic to the new subgraph or the monolith based on a configuration.
With this setup, they could also control the percentage of traffic handled by the monolith or the new subgraph, resulting in better stability of Reddit during the migration journey.
As of the last update, the migration is still ongoing with minimal disruption to the Reddit experience.
Data Replication with CDC and Debezium
In the early stages, Reddit supported data replication for their databases using WAL segments created by the primary database.
WAL or write-ahead log is a file that records all changes made to a database before they are committed. It ensures that if there’s a failure during a write operation, the changes can be recovered from the log.
To prevent this replication from bogging down the primary database, Reddit used a special tool to continuously archive PostgreSQL WAL files to S3 from where the replica could read the data.
However, there were a few issues with this approach:
Since the daily snapshots ran at night, there were inconsistencies in the data during the day.
Frequent schema changes to databases caused issues with snapshotting the database and replication.
The primary and replica databases ran on EC2 instances, making the replication process fragile. There were multiple failure points such as a failing backup to S3 or the primary node going down.
To make data replication more reliable, Reddit decided to use a streaming Change Data Capture (CDC) solution using Debezium and Kafka Connect.
Debezium is an open-source project that provides a low-latency data streaming platform for CDC.
Whenever a row is added, deleted, or modified in Postgres, Debezium listens to these changes and writes them to a Kafka topic. A downstream connector reads from the Kafka topic and updates the destination table with the changes.
The below diagram shows this process.
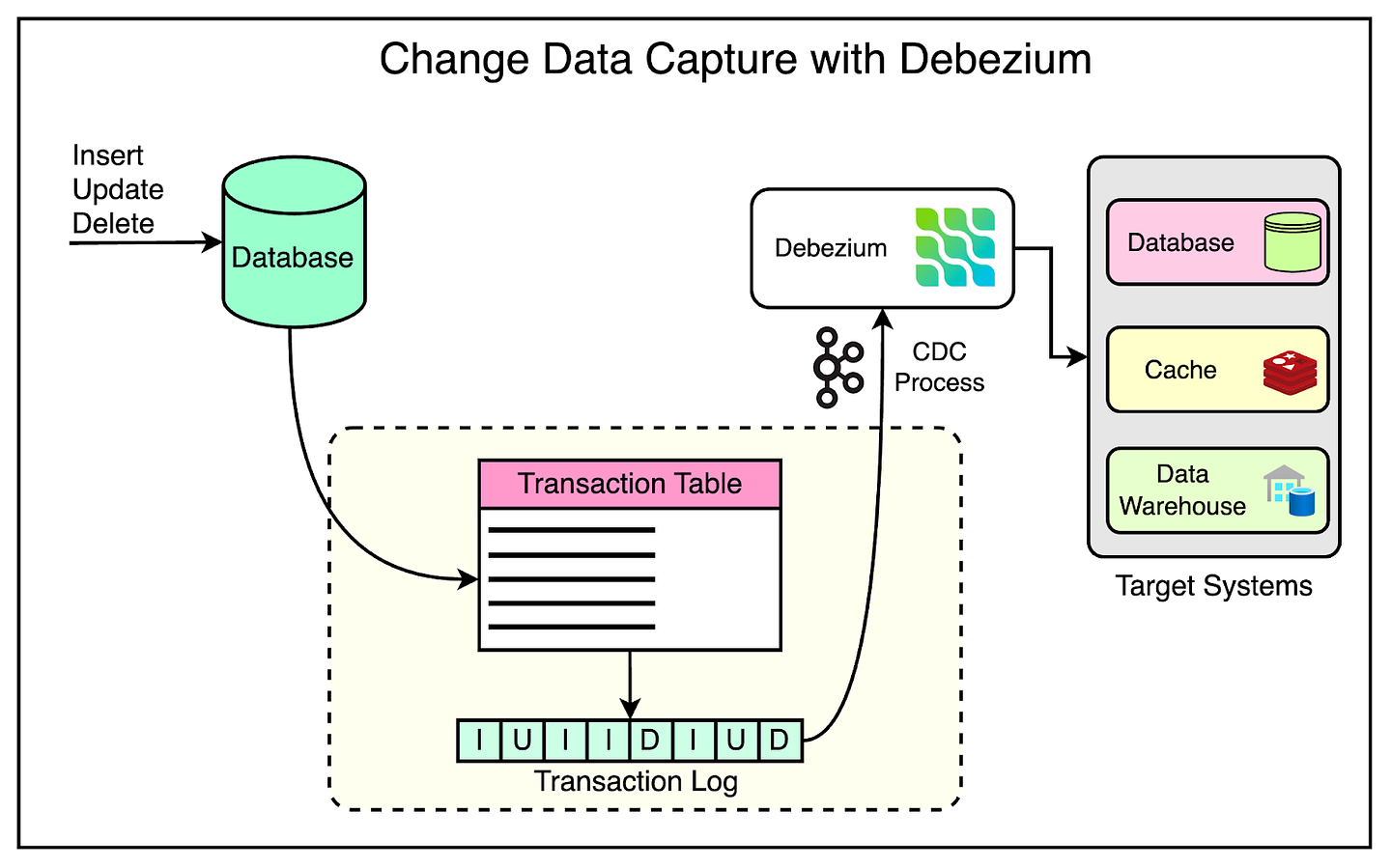
Moving to CDC with Debezium has been a great move for Reddit since they can now perform real-time replication of data to multiple target systems.
Also, instead of bulky EC2 instances, the entire process can be managed by lightweight Debezium pods.
Managing Media Metadata at Scale
Reddit hosts billions of posts containing various media content such as images, videos, gifs, and embedded third-party media.
Over the years, users have been uploading media content at an accelerating pace. Therefore, media metadata became crucial for enhancing searchability and organization for these assets.
There were multiple challenges with Reddit’s old approach to managing media metadata:
The data was distributed and scattered across multiple systems.
There were inconsistent storage formats and varying query patterns for different asset types. In some cases, they were even querying S3 buckets for the metadata information which is extremely inefficient at Reddit scale.
No proper mechanism for auditing changes, analyzing content, and categorizing metadata.
To overcome these challenges, Reddit built a brand new media metadata store with some high-level requirements:
Move all existing media metadata from different systems under a common roof.
Support data retrieval at the scale of 100K read requests per second with less than 50 ms latency.
Support data creation and updates.
The choice of the data store was between Postgres and Cassandra. Reddit finally went with AWS Aurora Postgres due to the challenges with ad-hoc queries for debugging in Cassandra and the potential risk of some data not being denormalized and unsearchable.
The below diagram shows a simplified overview of Reddit’s media metadata storage system.
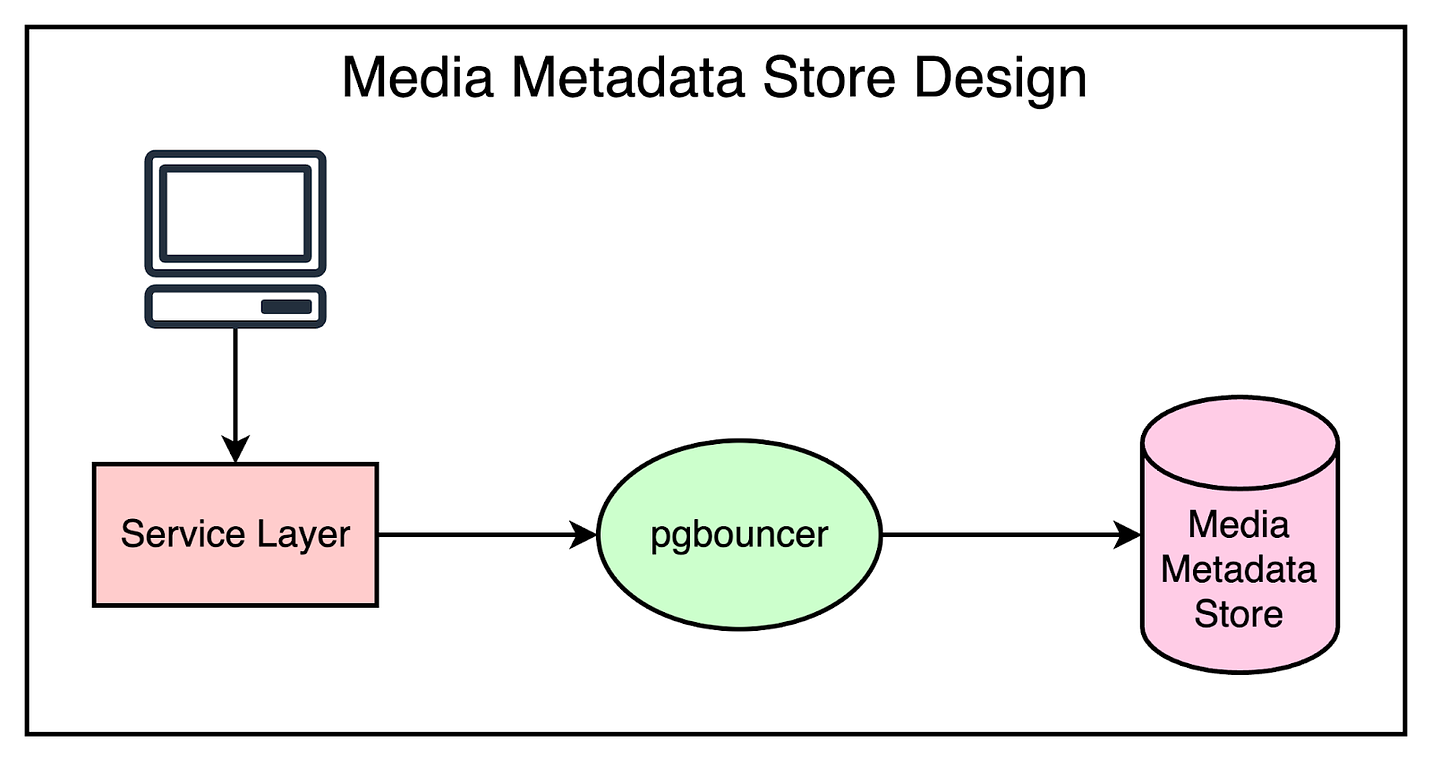
As you can see, there’s just a simple service interfacing with the database, handling reads and writes through APIs.
Though the design was not complicated, the challenge lay in transferring several terabytes of data from various sources to the new database while ensuring that the system continued to operate correctly.
The migration process consisted of multiple steps:
Enable dual writes into the metadata APIs from clients of media metadata.
Backfill data from older databases to the new metadata store.
Enable dual reads on media metadata from the service clients.
Monitor data comparison for every read request and fix any data issues.
Ramp up read traffic to the new metadata store.
Check out the below diagram that shows this setup in more detail.
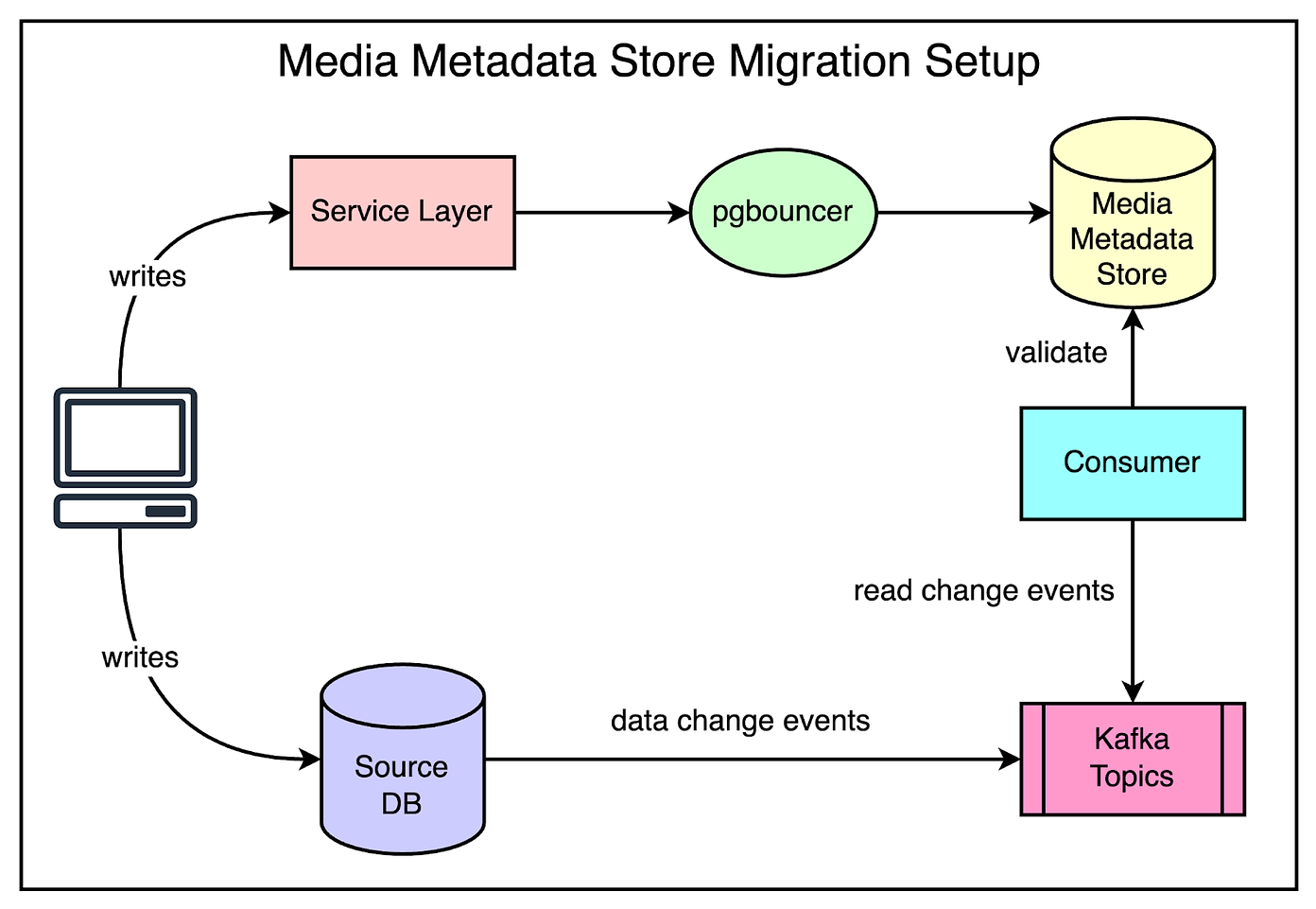
After the migration was successful, Reddit adopted some scaling strategies for the media metadata store.
Table partitioning using range-based partitioning.
Serving reads from a denormalized JSONB field in Postgres.
Ultimately, they achieved an impressive read latency of 2.6 ms at p50, 4.7 ms at p90, and 17 ms at p99. Also, the data store was generally more available and 50% faster than the previous data system.
Just-in-time Image Optimization
Within the media space, Reddit also serves billions of images per day.
Users upload images for their posts, comments, and profiles. Since these images are consumed on different types of devices, they need to be available in several resolutions and formats. Therefore, Reddit transforms these images for different use cases such as post previews, thumbnails, and so on.
Since 2015, Reddit has relied on third-party vendors to perform just-in-time image optimization. Image handling wasn’t their core competency and therefore, this approach served them well over the years.
However, with an increasing user base and traffic, they decided to move this functionality in-house to manage costs and control the end-to-end user experience.
The below diagram shows the high-level architecture for image optimization setup.
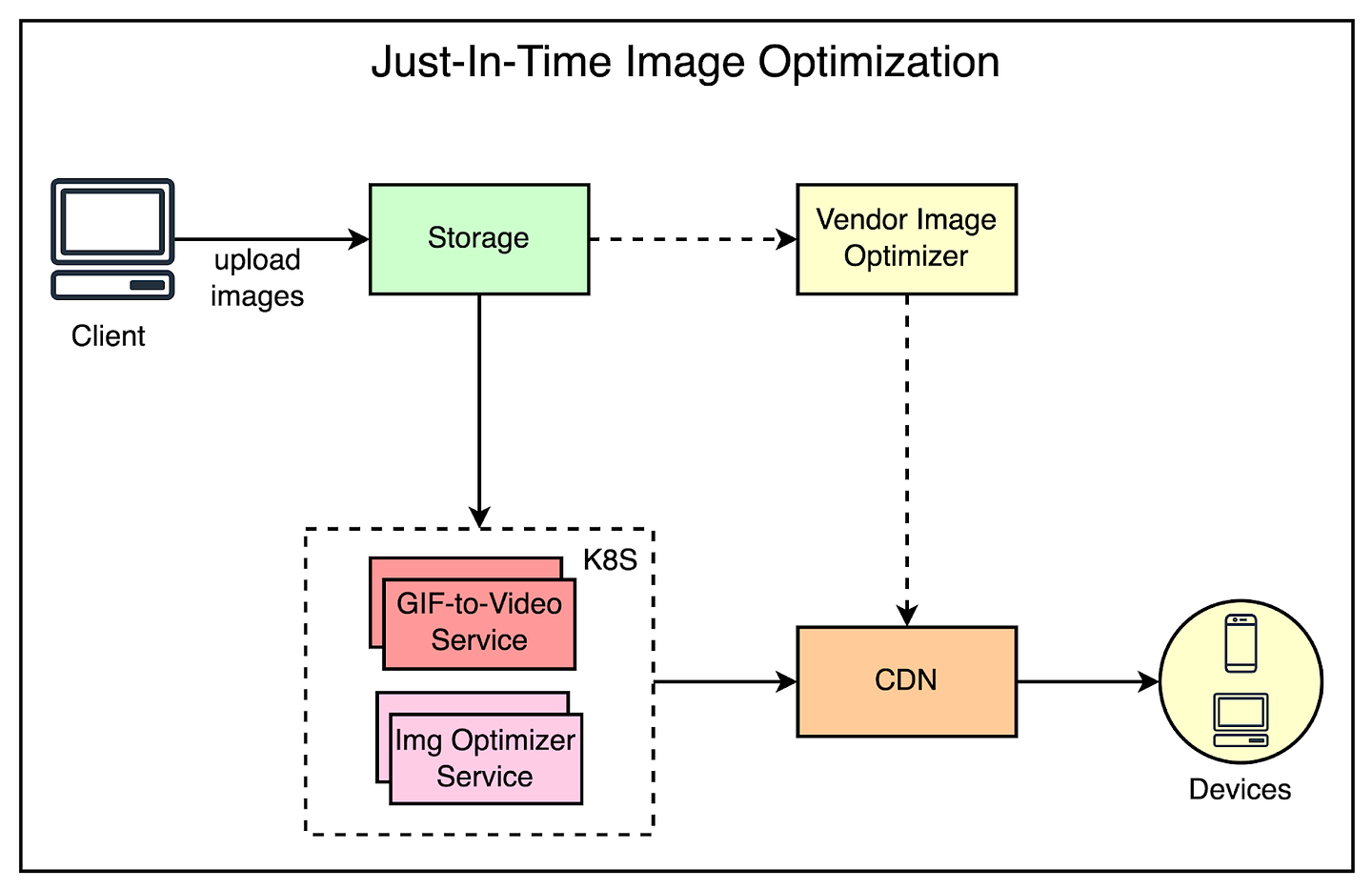
They built two backend services for transforming the images:
The Gif2Vid service resizes and transcodes GIFs to MP4s on-the-fly. Though users love the GIF format, it’s an inefficient choice for animated assets due to its larger file sizes and higher computational resource demands.
The image optimizer service deals with all other image types. It uses govips which is a wrapper around the libvips image manipulation library. The service handles the majority of cache-miss traffic and handles image transformations like blurring, cropping, resizing, overlaying images, and format conversions.
Overall, moving the image optimization in-house was quite successful:
Costs for Gif2Vid conversion were reduced to a mere 0.9% of the original cost.
The p99 cache-miss latency for encoding animated GIFs was down from 20s to 4s.
The bytes served for static images were down by approximately 20%.
Real-Time Protection for Users at Reddit’s Scale
A critical functionality for Reddit is moderating content that violates the policies of the platform. This is essential to keep Reddit safe as a website for the billions of users who see it as a community.
In 2016, they developed a rules engine named Rule-Executor-V1 (REV1) to curb policy-violating content on the site in real time. REV1 enabled the safety team to create rules that would automatically take action based on activities like users posting new content or leaving comments.
For reference, a rule is just a Lua script that is triggered on specific configured events. In practice, this can be a simple piece of code shown below:
In this example, the rule checks whether a post’s text body matches a string “some bad text”. If yes, it performs an asynchronous action on the user by publishing an action to an output Kafka topic.
However, REV1 needed some major improvements:
It ran on a legacy infrastructure of raw EC2 instances. This wasn’t in line with all modern services on Reddit that were running on Kubernetes.
Each rule ran as a separate process in a REV1 node and required vertical scaling as more rules were launched. Beyond a certain point, vertical scaling became expensive and unsustainable.
REV1 used Python 2.7 which was deprecated.
Rules weren’t version-controlled and it was difficult to understand the history of changes.
Lack of staging environment to test out the rules in a sandboxed manner.
In 2021, the Safety Engineering team within Reddit developed a new streaming infrastructure called Snooron. It was built on top of Flink Stateful Functions to modernize REV1’s architecture. The new system was known as REV2.
The below diagram shows both REV1 and REV2.
Some of the key differences between REV1 and REV2 are as follows:
In REV1, all configuration of rules was done via a web interface. With REV2, the configuration primarily happens through code. However, there are UI utilities to make the process simpler.
In REV1, they use Zookeeper as a store for rules. With REV2, rules are stored in Github for better version control and are also persisted to S3 for backup and periodic updates.
In REV1, each rule had its own process that would load the latest code when triggered. However, this caused performance issues when too many rules were running at the same time. REV2 follows a different approach that uses Flink Stateful Functions for handling the stream of events and a separate Baseplate application that executes the Lua code.
In REV1, the actions triggered by rules were handled by the main R2 application. However, REV2 works differently. When a rule is triggered, it sends out structured Protobuf actions to multiple action topics. A new application called the Safety Actioning Worker, built using Flink Statefun, receives and processes these instructions to carry out the actions.
Reddit’s Feed Architecture
Feeds are the backbone of social media and community-based websites.
Millions of people use Reddit’s feeds every day and it’s a critical component of the website’s overall usability. There were some key goals when it came to developing the feed architecture:
The architecture should support a high development velocity and support scalability. Since many teams integrate with the feeds, they need to have the ability to understand, build, and test them quickly.
TTI (Time to Interactive) and scroll performance should be satisfactory since they are critical to user engagement and the overall Reddit experience.
Feeds should be consistent across different platforms such as iOS, Android, and the website.
To support these goals, Reddit built an entirely new, server-driven feeds platform. Some major changes were made in the backend architecture for feeds.
Earlier, each post was represented by a Post object that contained all the information a post may have. It was like sending the kitchen sink over the wire and with new post types, the Post object got quite big over time.
This was also a burden on the client. Each client app contained a bunch of cumbersome logic to determine what should be shown on the UI. Most of the time, this logic was out of sync across platforms.
With the changes to the architecture, they moved away from the big object and instead sent only the description of the exact UI elements the client will render. The backend controlled the type of elements and their order. This approach is also known as Server-Driven UI.
For example, the post unit is represented by a generic Group object that contains an array of Cell objects. The below image shows the change in response structure for the Announcement item and the first post in the feed.
Reddit’s Move from Thrift to gRPC
In the initial days, Reddit had adopted Thrift to build its microservices.
Thrift enables developers to define a common interface (or API) that enables different services to communicate with each other, even if they are written in different programming languages. Thrift takes the language-independent interface and generates code bindings for each specific language.
This way, developers can make API calls from their code using syntax that looks natural for their programming language, without having to worry about the underlying cross-language communication details.
Over the years, the engineering teams at Reddit built hundreds of Thrift-based microservices, and though it served them quite well, Reddit’s growing needs made it costly to continue using Thrift.
gRPC came on the scene in 2016 and achieved significant adoption within the Cloud-native ecosystem.
Some of the advantages of gRPC are as follows:
It provided native support for HTTP2 as a transport protocol
There was native support for gRPC in several service mesh technologies such as Istio and Linkerd
Public cloud providers also support gRPC-native load balancers
While gRPC had several benefits, the cost of switching was non-trivial. However, it was a one-time cost whereas building feature parity in Thrift would have been an ongoing maintenance activity.
Reddit decided to make the transition to gRPC. The below diagram shows the design they used to start the migration process:
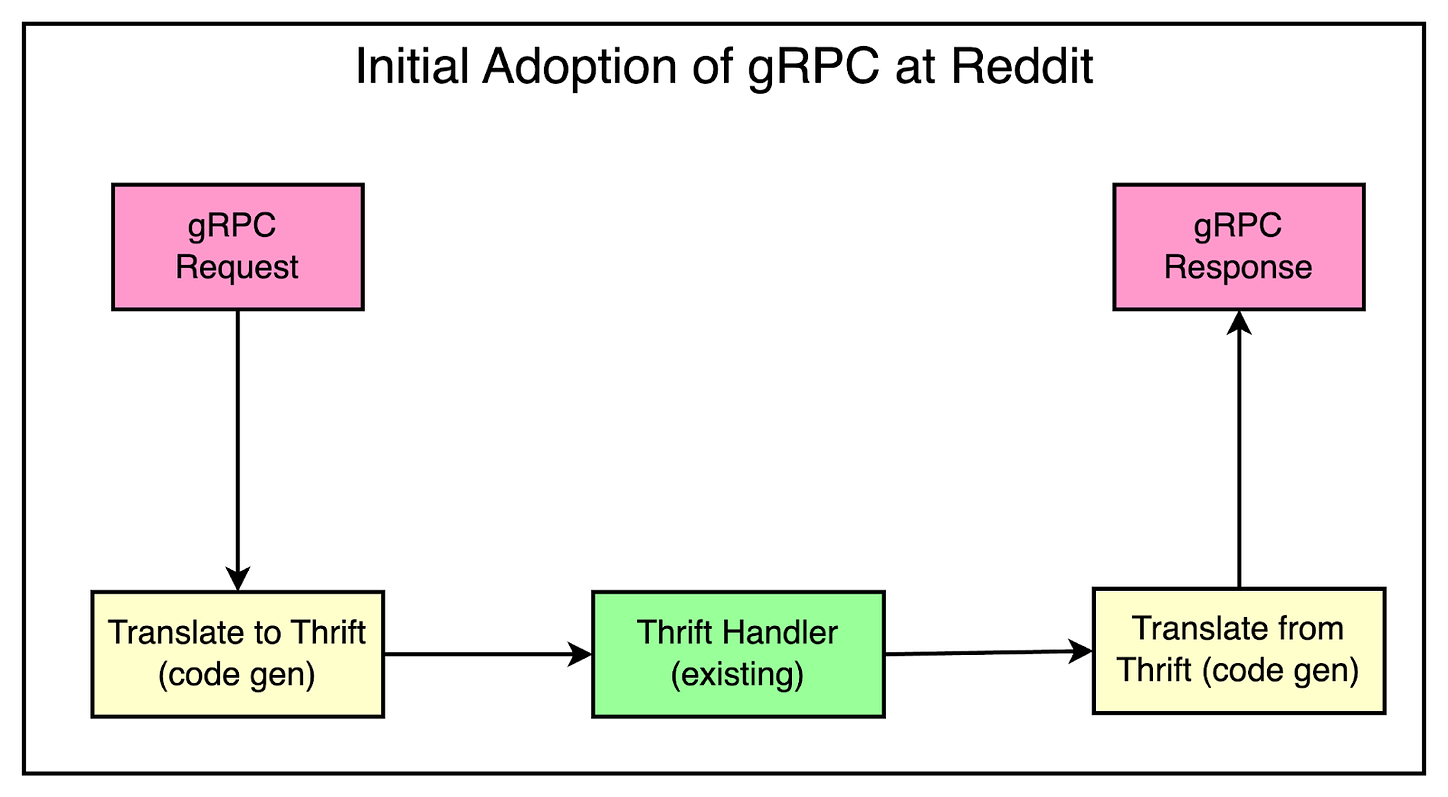
The main component is the Transitional Shim. Its job is to act as a bridge between the new gRPC protocol and the existing Thrift-based services.
When a gRPC request comes in, the shim converts it into an equivalent Thrift message format and passes it on to the existing code just like native Thrift. When the service returns a response object, the shim converts it back into the gRPC format.
There are three main parts to this design:
The interface definition language (IDL) converter that translates the Thrift service definitions into the corresponding gRPC interface. This component also takes care of adapting framework idioms and differences as appropriate.
A code-generated gRPC servicer that handles the message conversions for incoming and outgoing messages between Thrift and gRPC.
A pluggable module for the services to support both Thrift and gRPC.
This design allowed Reddit to gradually transition to gRPC by reusing its existing Thrift-based service code while controlling the costs and effort required for the migration.
Conclusion
Reddit’s architectural journey has been one of continual evolution, driven by its meteoric growth and changing needs over the years. What began as a monolithic Lisp application was rewritten in Python, but this monolithic approach couldn’t keep pace as Reddit’s popularity exploded.
The company went on an ambitious transition to a service-based architecture. Each new feature and issue they faced prompted a change in the overall design in various areas such as user protection, media metadata management, communication channels, data replication, API management, and so on.
In this post, we’ve attempted to capture the evolution of Reddit’s architecture from the early days to the latest changes based on the available information.
References:
SPONSOR US
Get your product in front of more than 500,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing hi@bytebytego.com.
© 2024 ByteByteGo
548 Market Street PMB 72296, San Francisco, CA 94104
Unsubscribe
by "ByteByteGo" <bytebytego@substack.com> - 11:35 - 9 Apr 2024 -
What’s the state of private markets around the world?
On Point
2024 Global Private Markets Review Brought to you by Liz Hilton Segel, chief client officer and managing partner, global industry practices, & Homayoun Hatami, managing partner, global client capabilities
•
Fundraising decline. Macroeconomic headwinds persisted throughout 2023, with rising financing costs and an uncertain growth outlook taking a toll on private markets. Last year, fundraising fell 22% across private market asset classes globally to just over $1 trillion, as of year-end reported data—the lowest total since 2017, McKinsey senior partner Fredrik Dahlqvist and coauthors reveal. As private market managers look to boost performance, a deeper focus on revenue growth and margin expansion will be needed now more than ever.
—Edited by Belinda Yu, editor, Atlanta
This email contains information about McKinsey's research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this newsletter because you subscribed to the Only McKinsey newsletter, formerly called On Point.
Copyright © 2024 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "Only McKinsey" <publishing@email.mckinsey.com> - 01:08 - 9 Apr 2024 -
Feeling good: A guide to empathetic leadership
I feel for you Brought to you by Liz Hilton Segel, chief client officer and managing partner, global industry practices, & Homayoun Hatami, managing partner, global client capabilities
An “empath” is defined as a person who is highly attuned to the feelings of others, often to the point of experiencing those emotions themselves. This may sound like a quality that’s more helpful in someone’s personal life than in their work life, where emotions should presumably be kept at bay. Yet it turns out that the opposite may be true: displaying empathy in appropriate ways can be a powerful component of effective leadership. And when it’s combined with other factors such as technology and innovation, it can lead to exceptional business performance, such as breakthroughs in customer service. This week, we explore some strategies for leaders to enhance their empathy quotient.

“When I train leaders in empathy, one of the first hurdles I need to get over is this stereotype that empathy is too soft and squishy for the work environment,” says Stanford University research psychologist Jamil Zaki in an episode of our McKinsey Talks Talent podcast. Speaking with McKinsey partners Bryan Hancock and Brooke Weddle, Zaki suggests that, contrary to the stereotype, empathy can be a workplace superpower, helping to alleviate employee burnout and spurring greater productivity and creativity. Boosting managers’ empathetic skills is more important now than ever: “There’s evidence that during the time that social media has taken over so much of our lives, people’s empathy has also dropped,” says Zaki. Ways to improve leaders’ empathy in the workplace include infusing more empathy into regular conversations, rewarding empathic behavior, and automating some non-human-centric responsibilities so that managers can focus on mentorship.
That’s business strategist and author John Horn on why it’s important for leaders to try to understand the mindset of their competitors. “When people become more senior in business, they’ll need to think about competitors directly,” he says in a conversation with McKinsey on cognitive empathy. While it may not be possible to ask competitors about their strategies, technology such as AI, machine learning, and big data may be able to provide competitive-insight tools based on a predictive factor. “You could possibly use that data to look across various industries and learn [for example] what has been the response when prices were raised? That’s thinking about the likely behavior your competitors will have,” says Horn.
The qualities that make a leader empathetic can be found within oneself and in the situations of daily life. “Try to unlock the energy and the aspiration that lies within us,” suggests McKinsey senior partner and chief legal officer Pierre Gentin in a McKinsey Legal Podcast interview. What Gentin calls “arrows of inspiration”—whether they come from art, music, literature, or people—may be available to leaders every day. He believes that “a lot of this is just opening our eyes and really recognizing what’s in front of us and transitioning from the small gauge and the negative to the big gauge and the transformative.” For example, in an organizational context, people may need to look beyond short-term concerns and consider “what they can do outside of the four corners of the definition of their role,” he says. “How can we collaborate together to do creative things and to do exciting things and to do worthwhile things?”

There are times when empathy can be too much of a good thing, or leaders can show it in the wrong way. An obvious mistake is to pay lip service to the idea but take limited or no action. In one case, an IT group in a company worked overtime for many weeks during the pandemic. Leaders praised the group lavishly, but the only action they took was to buy everyone on the team a book on time management. Another error may to be to avoid forming the strong relationships that lead to good communication, understanding, and compassion. And empathy by itself—if it’s not balanced by other aspects of emotional intelligence such as self-regulation and composure—can actually derail leadership effectiveness.
Lead empathetically.
– Edited by Rama Ramaswami, senior editor, New York
Share these insights
Did you enjoy this newsletter? Forward it to colleagues and friends so they can subscribe too. Was this issue forwarded to you? Sign up for it and sample our 40+ other free email subscriptions here.
This email contains information about McKinsey’s research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this email because you subscribed to the Leading Off newsletter.
Copyright © 2024 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "McKinsey Leading Off" <publishing@email.mckinsey.com> - 04:37 - 8 Apr 2024


















%20(1).png?width=1200&upscale=true&name=Group%201000003436%20(2)%20(1).png)