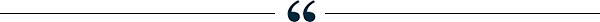Archives
- By thread 5224
-
By date
- June 2021 10
- July 2021 6
- August 2021 20
- September 2021 21
- October 2021 48
- November 2021 40
- December 2021 23
- January 2022 46
- February 2022 80
- March 2022 109
- April 2022 100
- May 2022 97
- June 2022 105
- July 2022 82
- August 2022 95
- September 2022 103
- October 2022 117
- November 2022 115
- December 2022 102
- January 2023 88
- February 2023 90
- March 2023 116
- April 2023 97
- May 2023 159
- June 2023 145
- July 2023 120
- August 2023 90
- September 2023 102
- October 2023 106
- November 2023 100
- December 2023 74
- January 2024 75
- February 2024 75
- March 2024 78
- April 2024 74
- May 2024 108
- June 2024 98
- July 2024 116
- August 2024 134
- September 2024 130
- October 2024 141
- November 2024 171
- December 2024 115
- January 2025 216
- February 2025 140
- March 2025 220
- April 2025 233
- May 2025 239
- June 2025 303
- July 2025 36
-
How Facebook served billions of requests per second Using Memcached
How Facebook served billions of requests per second Using Memcached
Creating stronger passwords with AuthKit (Sponsored) A common cause of data breaches and account hijacking is customers using weak or common passwords. One way to mitigate this risk is to inform new users about the strength of their passwords as they create them.͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ Forwarded this email? Subscribe here for moreCreating stronger passwords with AuthKit (Sponsored)

A common cause of data breaches and account hijacking is customers using weak or common passwords.
One way to mitigate this risk is to inform new users about the strength of their passwords as they create them.
To solve this problem, Dropbox created zxcvbn, an open-source library that calculates password strength based on factors like entropy, dictionary checks, and pattern recognition.
If you want an easy way to implement user password security in your app, check out AuthKit, an open-source login box that incorporates zxcvbn and other best practices to provide a much more secure onboarding experience for new users.There are two absolute truths about running a social network at the scale of Facebook:
First, it cannot go down.
Second, it cannot run slow.
These two factors determine whether people are going to stay on your social network or not.
Even a few people leaving impacts the entire user base because the users are interconnected. Most people are online because their friends or relatives are online and there’s a domino effect at play. If one user drops off due to issues, there are chances that other users will also leave.
Facebook had to deal with these issues early on because of its popularity. At any point in time, millions of people were accessing Facebook from all over the world.
In terms of software design, this meant a few important requirements:
Facebook had to support real-time communication.
They had to build capabilities for on-the-fly content aggregation.
Scale to handle billions of user requests.
Store trillions of items across multiple geographic locations.
To achieve these goals, Facebook took up the open-source version of Memcached and enhanced it to build a distributed key-value store.
This enhanced version was known as Memcache.
In this post, we will look at how Facebook solved the multiple challenges in scaling memcached to serve billions of requests per second.
Introduction to Memcached
Memcached is an in-memory key-value store that supports a simple set of operations such as set, get, and delete.
The open-source version provided a single-machine in-memory hash table. The engineers at Facebook took up this version as a basic building block to create a distributed key-value store known as Memcache.
In other words, “Memcached” is the source code or the running binary whereas “Memcache” stands for the distributed system behind it.
Technically, Facebook used Memcache in two main ways:
Query Cache
The job of the query cache was to reduce the load on the primary source-of-truth databases.
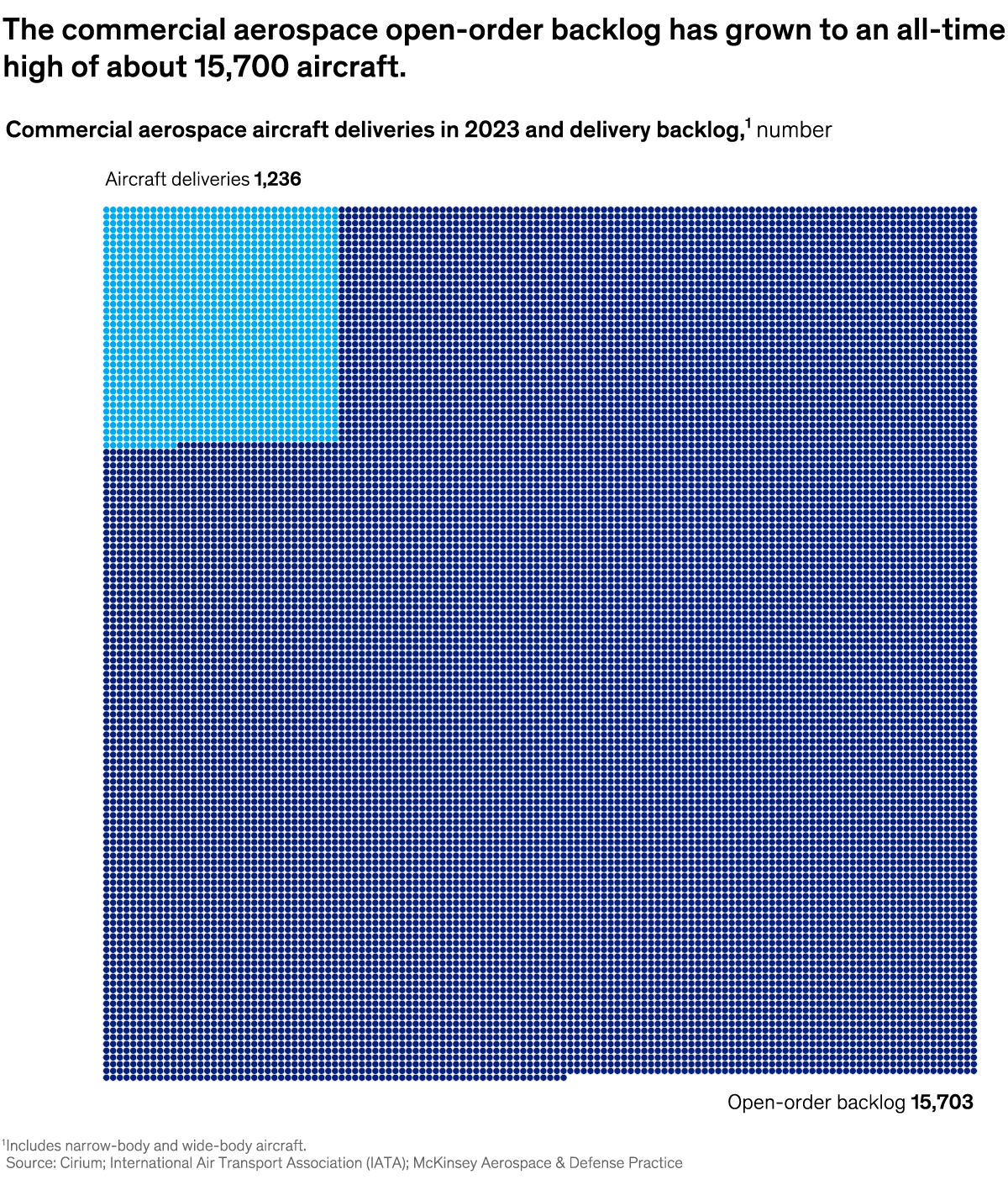
In this mode, Facebook used Memcache as a demand-filled look-aside cache. You may have also heard about it as the cache-aside pattern.
The below diagram shows how the look-aside cache pattern works for the read and write path.
The read path utilizes a cache that is filled on-demand. This means that data is only loaded into the cache when a client specifically requests it.
Before serving the request, the client first checks the cache. If the desired data is not found in the cache (a cache miss), the client retrieves the data from the database and also updates the cache.
The write path takes a more interesting approach to updating data.
After a particular key is updated in the database, the system doesn’t directly update the corresponding value in the cache. Instead, it removes the data for that key from the cache entirely. This process is known as cache invalidation.
By invalidating the cache entry, the system ensures that the next time a client requests data for that key, it will experience a cache miss and be forced to retrieve the most up-to-date value directly from the database. This approach helps maintain data consistency between the cache and the database.
Generic Cache
Facebook also leverages Memcache as a general-purpose key-value store. This allows different teams within the organization to utilize Memcache for storing pre-computed results generated from computationally expensive machine learning algorithms.
By storing these pre-computed ML results in Memcache, other applications can quickly and easily access them whenever needed.
This approach offers several benefits such as improved performance and resource optimization.
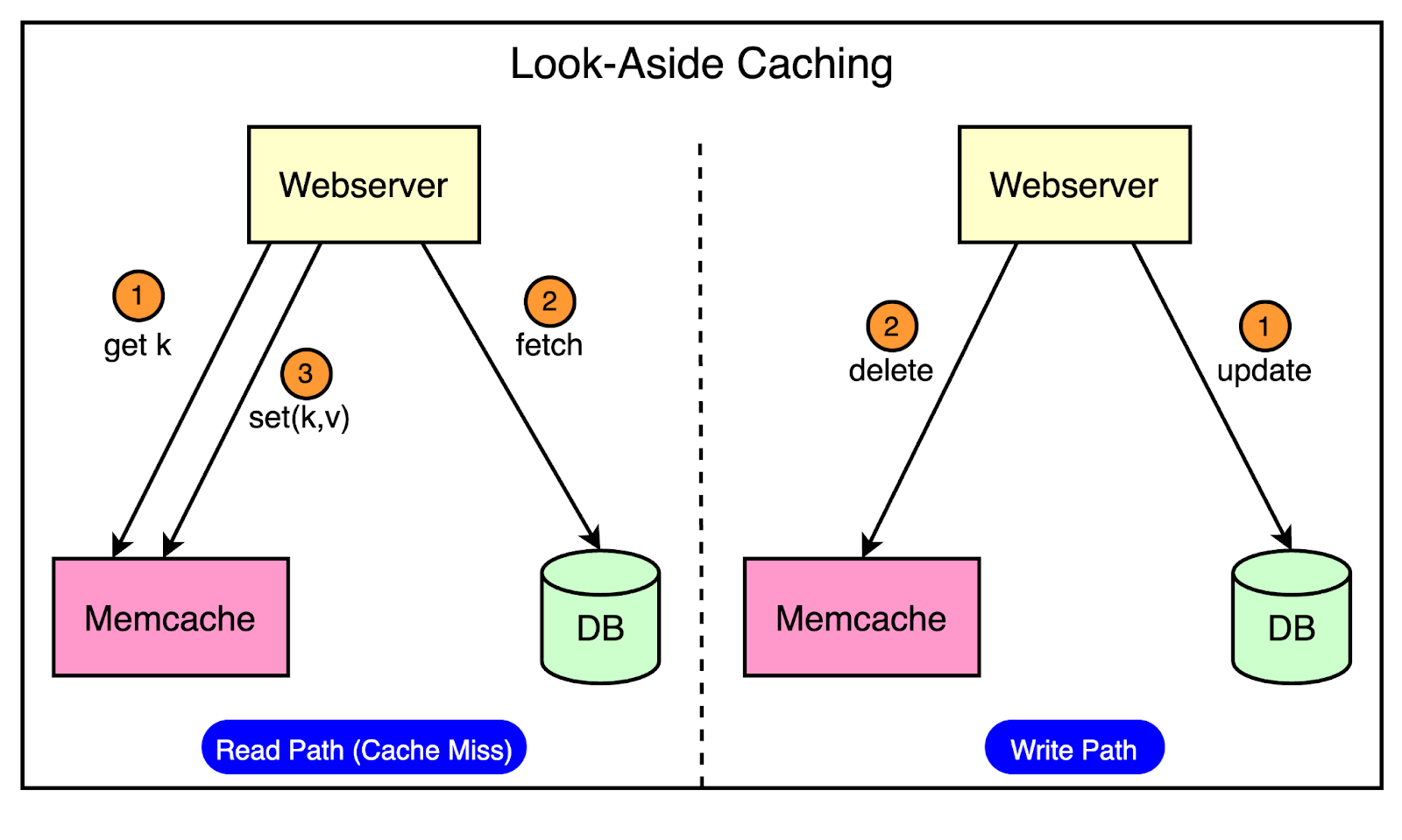
High-Level Architecture of Facebook
Facebook’s architecture is built to handle the massive scale and global reach of its platform.
At the time of their Memcached adoption, Facebook’s high-level architecture consisted of three key components:
1 - Regions
Facebook strategically places its servers in various locations worldwide, known as regions. These regions are classified into two types:
Primary Region: The primary region is responsible for handling the majority of user traffic and data management.
Secondary Region: Multiple secondary regions are distributed globally to provide redundancy, load balancing, and improved performance for users in different geographical areas.
Each region, whether primary or secondary, contains multiple frontend clusters and a single storage cluster.
2 - Frontend Clusters
Within each region, Facebook employs frontend clusters to handle user requests and serve content. A frontend cluster consists of two main components:
Web Servers: These servers are responsible for processing user requests, rendering pages, and delivering content to the users.
Memcache Servers: Memcache servers act as a distributed caching layer, storing frequently accessed data in memory for quick retrieval.
The frontend clusters are designed to scale horizontally based on demand. As user traffic increases, additional web and Memcache servers can be added to the cluster to handle the increased load.
3 - Storage Cluster
At the core of each region lies the storage cluster. This cluster contains the source-of-truth database, which stores the authoritative copy of every data item within Facebook’s system.
The storage cluster takes care of data consistency, durability, and reliability.
By replicating data across multiple regions and employing a primary-secondary architecture, Facebook achieves high availability and fault tolerance.
The below diagram shows the high-level view of this architecture:
One major philosophy that Facebook adopted was a willingness to expose slightly stale data instead of allowing excessive load on the backend.
Rather than striving for perfect data consistency at all times, Facebook accepted that users may sometimes see outdated information in their feeds. This approach allowed them to handle high traffic loads without crumbling under excessive strain on the backend infrastructure.
To make this architecture work at an unprecedented scale of billions of requests every day, Facebook had to solve multiple challenges such as:
Managing latency and failures within a cluster.
Managing data replication within a region.
Managing data consistency across regions.
In the next few sections, we will look at how Facebook handled each of these challenges.
Within Cluster Challenges
There were three important goals for the within-cluster operations:
Reducing latency
Reducing the load on the database
Handling failures
1 - Reducing Latency
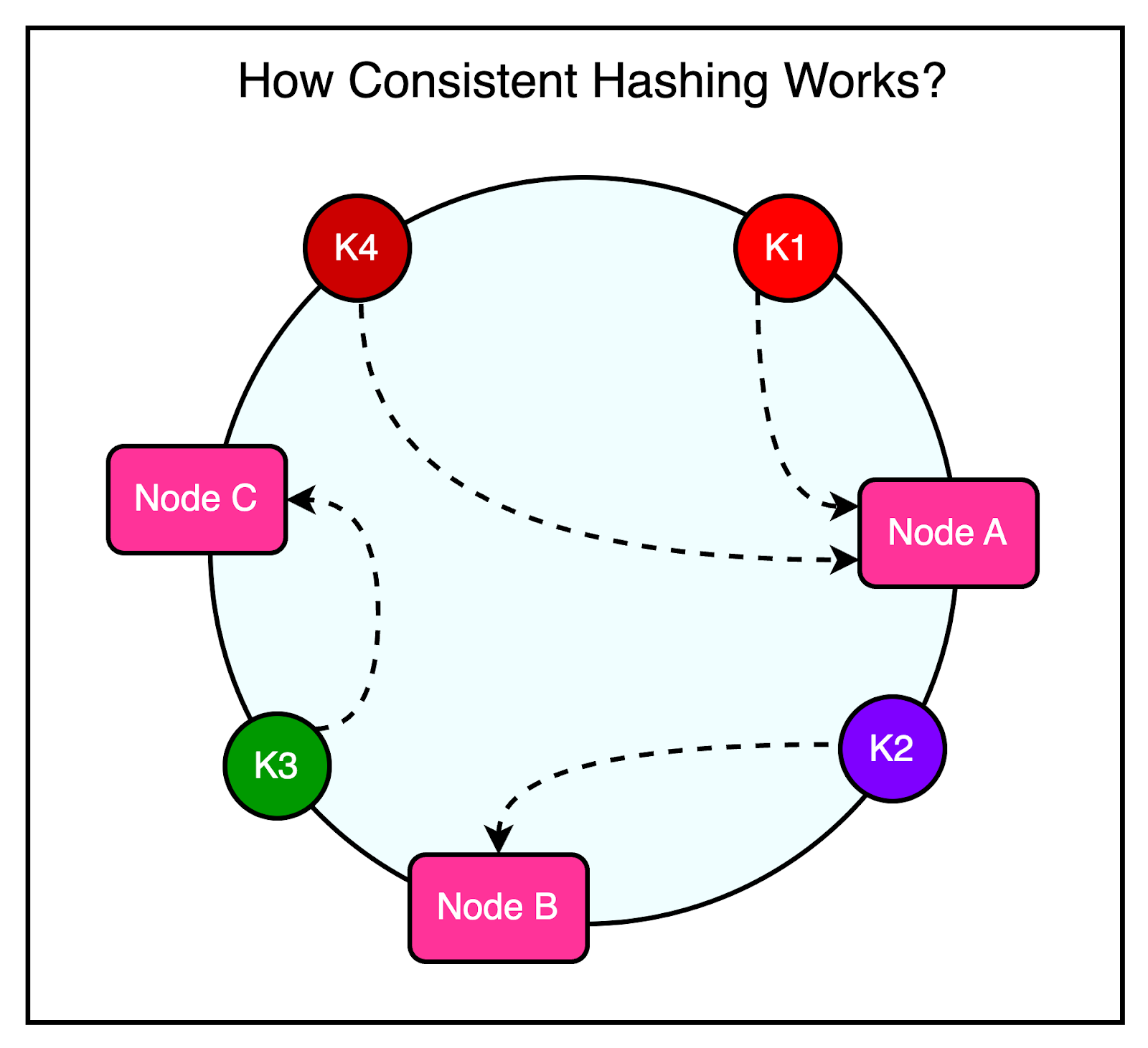
As mentioned earlier, every frontend cluster contains hundreds of Memcached servers, and items are distributed across these servers using techniques like Consistent Hashing.
For reference, Consistent Hashing is a technique that allows the distribution of a set of keys across multiple nodes in a way that minimizes the impact of node failures or additions. When a node goes down or a new node is introduced, Consistent Hashing ensures that only a small subset of keys needs to be redistributed, rather than requiring a complete reshuffling of data.
The diagram illustrates the concept of Consistent Hashing where keys are mapped to a circular hash space, and nodes are assigned positions on the circle. Each key is assigned to the node that falls closest to it in a clockwise direction.
At Facebook's scale, a single web request can trigger hundreds of fetch requests to retrieve data from Memcached servers. Consider a scenario where a user loads a popular page containing numerous posts and comments.
Even a single request can require the web servers to communicate with multiple Memcached servers in a short timeframe to populate the necessary data.
This high-volume data fetching occurs not only in cache hit situations but also when there’s a cache miss. The implication is that a single Memcached server can turn into a bottleneck for many web servers, leading to increased latency and degraded performance for the end user.
To reduce the possibility of such a scenario, Facebook uses a couple of important tricks visualized in the diagram.
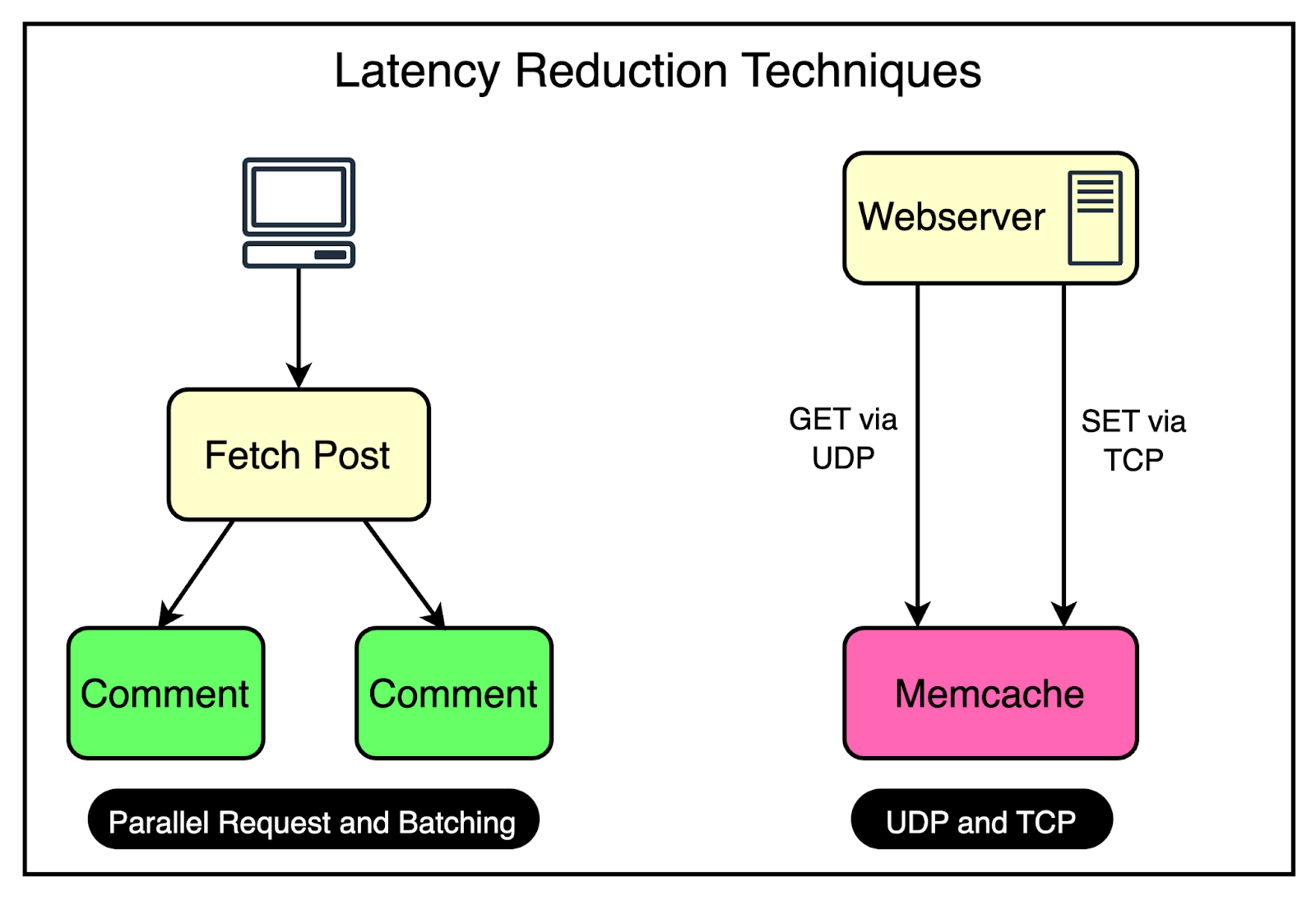
Parallel Requests and Batching
To understand the concept of parallel requests and batching, consider a simple analogy.
Imagine going to the supermarket every time you need an item. It would be incredibly time-consuming and inefficient to make multiple trips for individual items. Instead, it’s much more effective to plan your shopping trip and purchase a bunch of items together in a single visit.
The same optimization principle applies to data retrieval in Facebook's frontend clusters.
To maximize the efficiency of data retrieval, Facebook constructs a Directed Acyclic Graph (DAG) that represents the dependencies between different data items.
The DAG provides a clear understanding of which data items can be fetched concurrently and which items depend on others.
By analyzing the DAG, the web server can determine the optimal order and grouping of data fetches. It identifies data items that can be retrieved in parallel, without any dependencies, and groups them in a single batch request.
Using UDP
Facebook employed a clever strategy to optimize network communication between the web servers and the Memcache server.
For fetch requests, Facebook configured the clients to use UDP instead of TCP.
As you may know, UDP is a connectionless protocol and much faster than TCP. By using UDP, the clients can send fetch requests to the Memcache servers with less network overhead, resulting in faster request processing and reduced latency.
However, UDP has a drawback: it doesn’t guarantee the delivery of packets. If a packet is lost during transmission, UDP doesn’t have a built-in mechanism to retransmit it.
To handle such cases, they treated UDP packet loss as a cache miss on the client side. If a response isn’t received within a specific timeframe, the client assumes that the data is not available in the cache and proceeds to fetch it from the primary data source.
For update and delete operations, Facebook still used TCP since it provided a reliable communication channel that ensured the delivery of packets in the correct order. It removed the need for adding a specific retry mechanism, which is important when dealing with update and delete operations.
All these requests go through a special proxy known as mcrouter that runs on the same machine as the webserver. Think of the mcrouter as a middleman that performs multiple duties such as data serialization, compression, routing, batching, and error handling. We will look at mcrouter in a later section.
2 - Reducing Load
The most important goal for Memcache is to reduce the load on the database by reducing the frequency of data fetching from the database.
Using Memcache as a look-aside cache solves this problem significantly. But at Facebook’s scale, two caching-related issues can easily appear.
Stale Set: This happens when the cache is set with outdated data and there’s no easy way of invalidating it.
Thundering Herd: This problem occurs in a highly concurrent environment when a cache miss triggers a thundering herd of requests to the database.
The below diagram visualizes both of these issues.
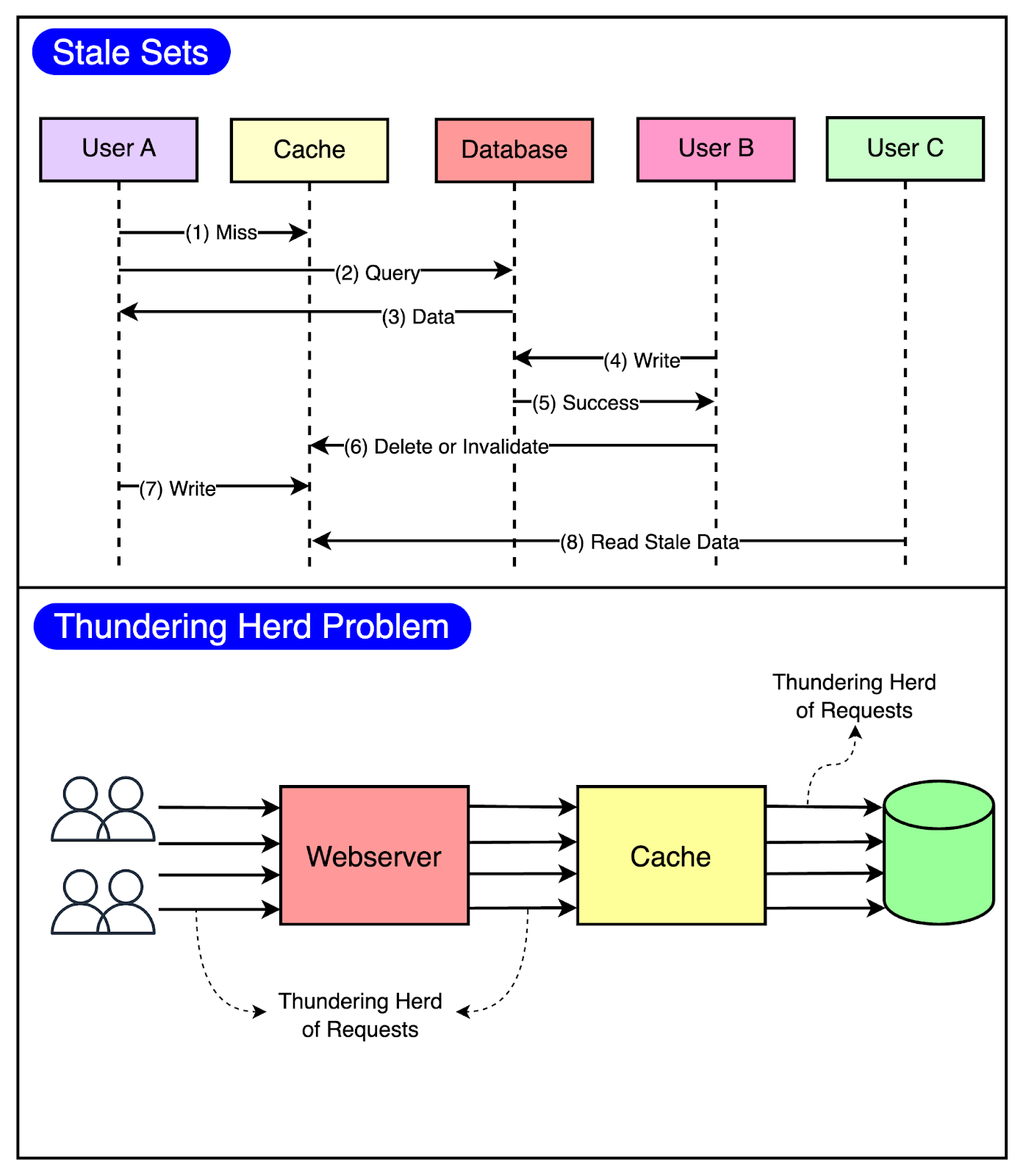
To minimize the probability of these two critical issues, Facebook used a technique known as leasing.
Leasing helped solve both stale sets and thundering herds, helping Facebook reduce peak DB query rates from 17K/second to 1.3K/second.
Stale Sets
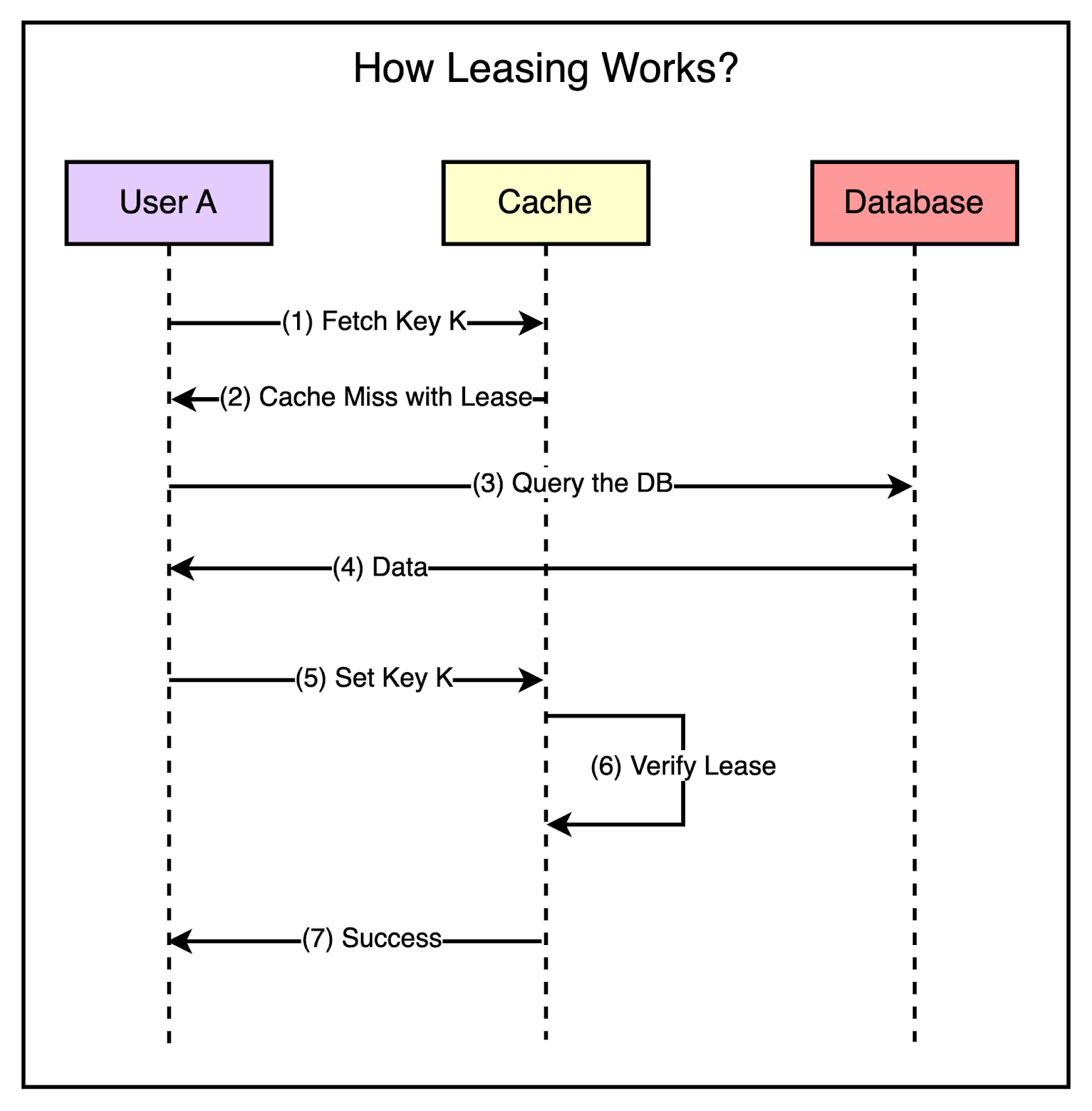
Consider that a client requests memcache for a particular key and it results in a cache miss.
Now, it’s the client’s responsibility to fetch the data from the database and also update memcache so that future requests for the same key don’t result in a cache miss.
This works fine most of the time but in a highly concurrent environment, the data being set by the client may get outdated by the time it gets updated in the cache.
Leasing prevents this from happening.
With leasing, Memcache hands over a lease (a 64-bit token bound to a specific key) to a particular client to set data into the cache whenever there’s a cache miss.
The client has to provide this token when setting the value in the cache and memcache can verify whether the data should be stored by verifying the token. If the item was already invalidated by the time the client tried to update, Memcache will invalidate the lease token and reject the request.
The below diagram shows the concept of leasing in a much better manner.
Thundering Herds
A slight modification to the leasing technique also helps solve the thundering herd issue.
In this modification, Memcache regulates the rate of issuing the lease tokens. For example, it may return a token once every 5 seconds per key.
For any requests for the key within 5 seconds of the lease token being issued, Memcache sends a special response requesting the client to wait and retry so that these requests don’t hit the database needlessly. This is because there’s a high probability that the client holding the lease token will soon update the cache and the waiting clients will get a cache hit when they retry.
Latest articles
If you’re not a paid subscriber, here’s what you missed.
To receive all the full articles and support ByteByteGo, consider subscribing:
3 - Handling Failures
In a massive-scale system like Facebook, failures are an inevitable reality.
With millions of users using the platform, any disruption in data retrieval from Memcache can have severe consequences. If clients are unable to fetch data from Memcache, it places an excessive load on the backend servers, potentially leading to cascading failures in downstream services.
Two Levels of Failure
Facebook faced two primary levels of failures when it comes to Memcache:
Small-Scale Outages: A small number of hosts may become inaccessible due to network issues or other localized problems. While these outages are limited in scope, they can still impact the overall system performance.
Widespread Outages: In more severe cases, an entire cluster may go down, affecting a significant percentage of the Memcache hosts. Such widespread outages create a greater threat to the stability and availability of the system.
Handling Widespread Outages
To mitigate the impact of a cluster going down, Facebook diverts web requests to other functional clusters.
By redistributing the load, Facebook ensures that the problematic cluster is relieved of its responsibilities until it can be restored to health.
Automated Remediation for Small Outages
For small-scale outages, Facebook relies on an automated remediation system that automatically detects and responds to host-level issues by bringing up new instances to replace the affected ones.
However, the remediation process is not instantaneous and can take some time to complete. During this time window, the backend services may experience a surge in requests as clients attempt to fetch data from the unavailable Memcache hosts.
The common way of handling this is to rehash keys and distribute them among the remaining servers.
However, Facebook’s engineering team realized that this approach was still prone to cascading failures. In their system, many keys can account for a significant portion of the requests (almost 20%) to a single server. Moving these high-traffic keys to another server during a failure scenario could result in overload and further instability.
To mitigate this risk, Facebook went with the approach of using Gutter machines. Within each cluster, they allocate a pool of machines (typically 1% of the Memcache servers) specifically designated as Gutter machines. These machines are designed to take over the responsibilities of the affected Memcache servers during an outage.
Here’s how they work:
If a Memcache client receives no response (not even a cache miss), the client assumes that the server has failed and issues a request to the Gutter pool.
If the request to the Gutter pool returns a cache miss, the client queries the database and inserts the data into the Gutter pool so that subsequent requests can be served from Memcache.
Gutter entries expire quickly to remove the need for invalidations.
The below diagram shows how the Gutter pool works:
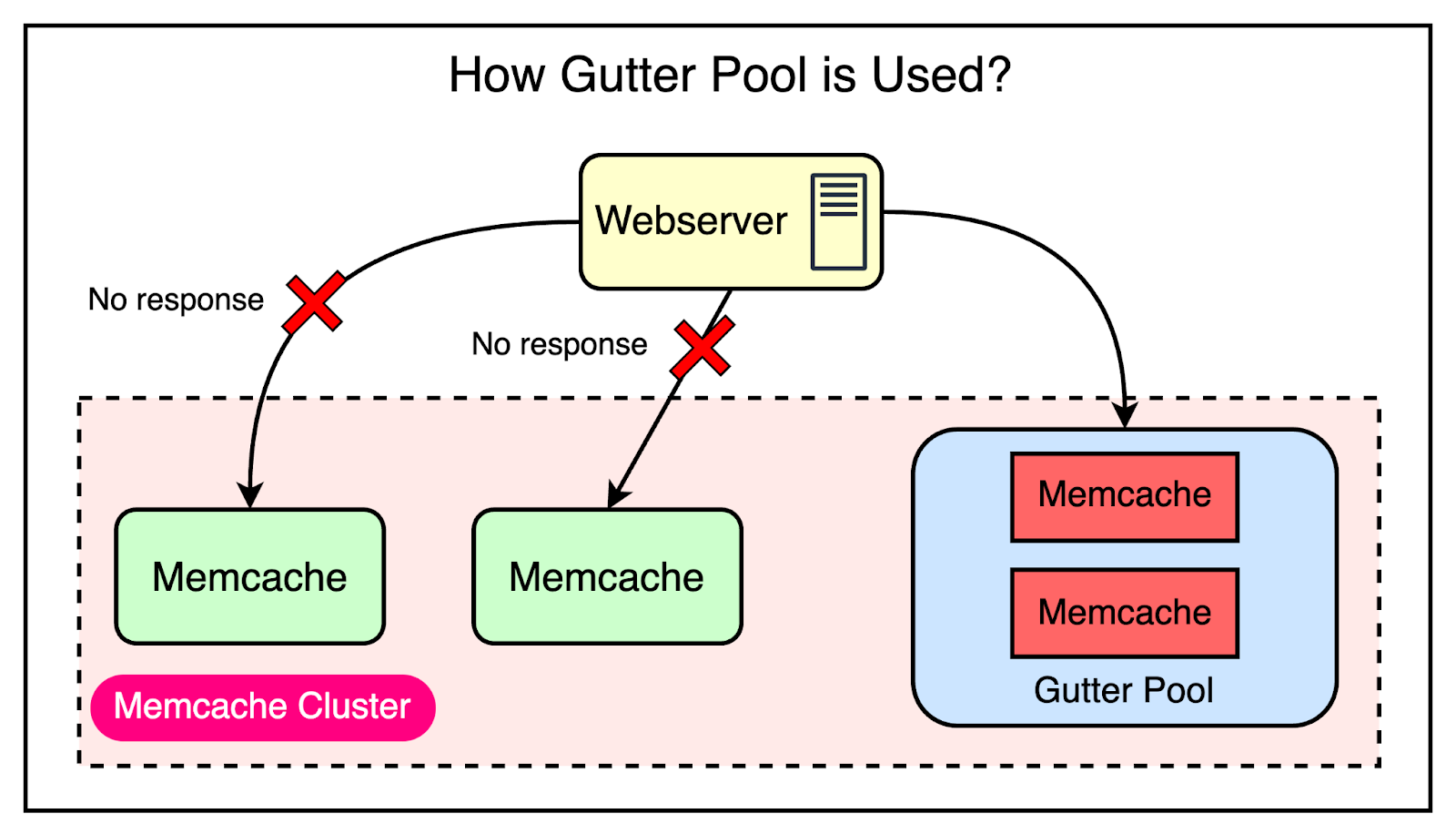
Though there are chances of serving stale data, the backend is protected. Remember that this was an acceptable trade-off for them when compared to availability.
Region Level Challenges
At the region level, there were multiple frontend clusters to deal with and the main challenge was handling Memcache invalidations across all of them.
Depending on the load balancer, users can connect to different front-end clusters when requesting data. This results in caching a particular piece of data in multiple clusters.
In other words, you can have a scenario where a particular key is cached in the Memcached servers of multiple clusters within the region. The below diagram shows this scenario:
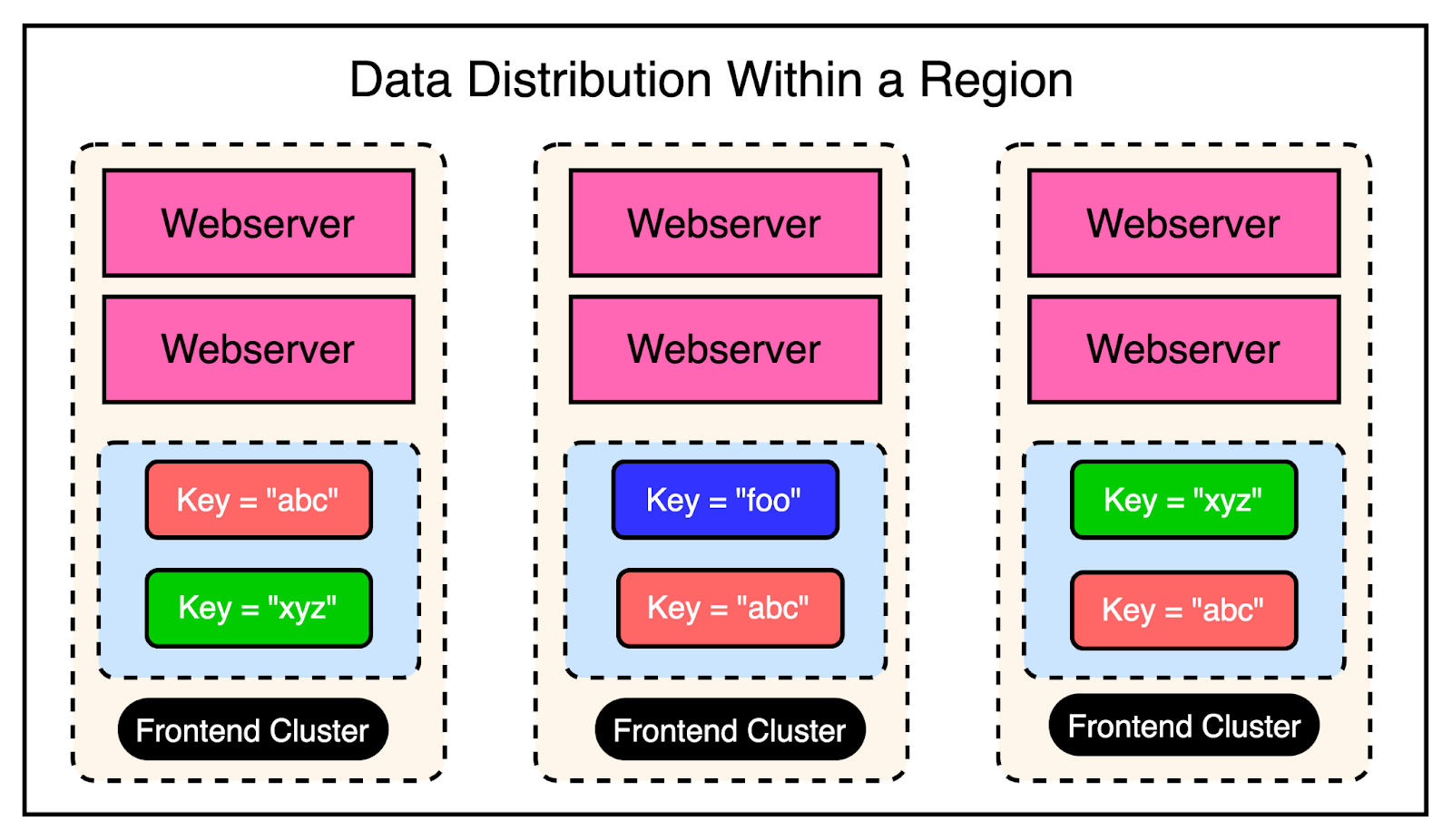
As an example, the keys “abc” and “xyz” are present in multiple frontend clusters within a region and need to be invalidated in case of an update to their values.
Cluster Level Invalidation
Invalidating this data at the cluster level is reasonably simpler. Any web server that modifies the data is responsible for invalidating the data in that cluster. This provides read-after-write consistency for the user who made the request. It also reduces the lifetime of the stale data within the cluster.
For reference, read-after-write consistency is a guarantee that if a user makes some updates, he/she should always see those updates when they reload the page.
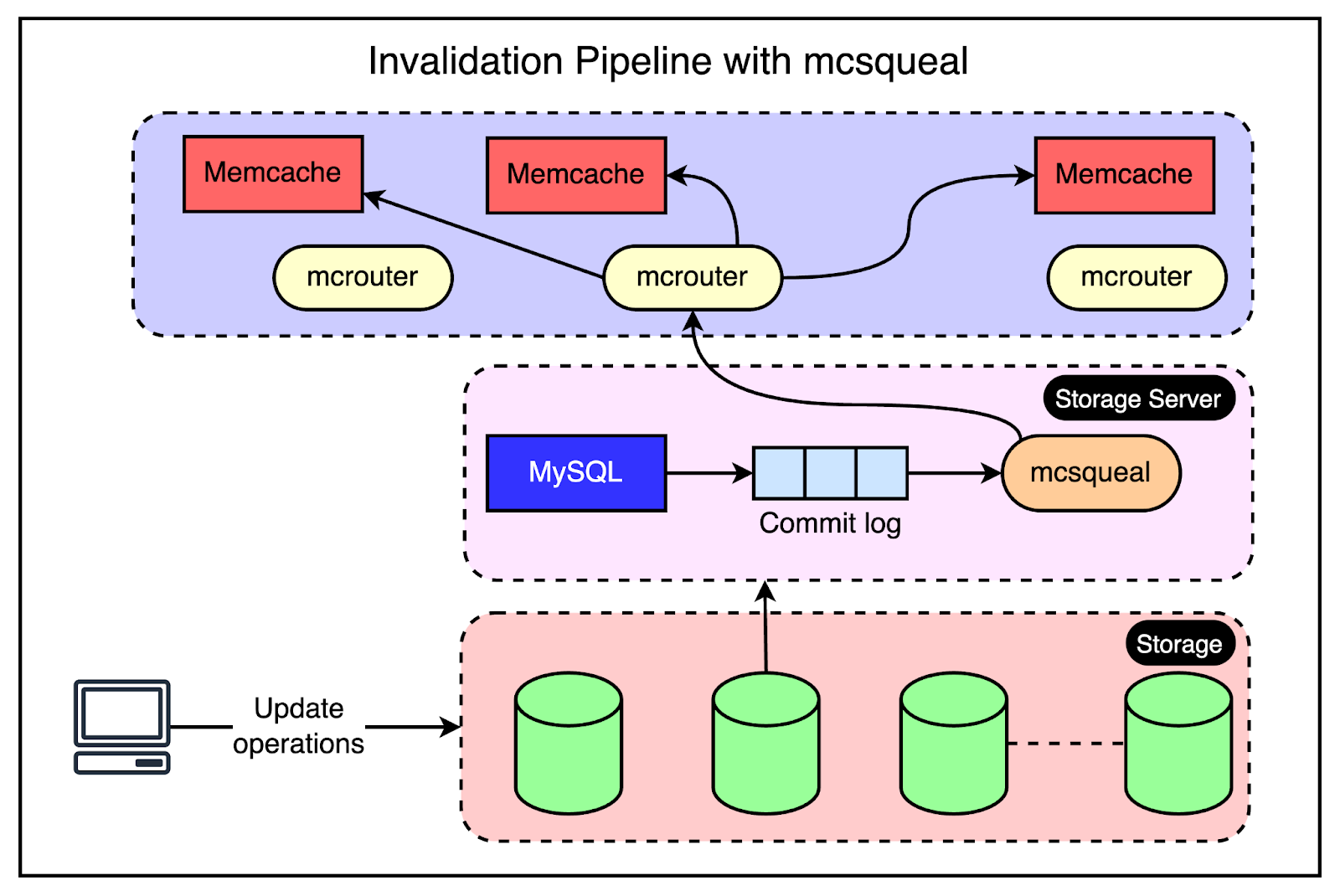
Region Level Invalidation
For region-level invalidation, the invalidation process is a little more complex and the webserver doesn’t handle it.
Instead, Facebook created an invalidation pipeline that works like this:
An invalidation daemon known as mcsqueal runs on every database server within the storage cluster.
This daemon inspects the commit log, extracts any deletes, and broadcasts them to the Memcache deployments in every frontend cluster within the region.
For better performance, mcsqueal batches these deletes into fewer packets and sends them to dedicated servers running mcrouter instances in each cluster.
The mcrouter instance iterates over the individual deletes within the batch and routes them to the correct Memcache server.
The below diagram explains this process.
Challenges with Global Regions
Operating at the scale of Facebook requires them to run and maintain data centers globally.
However, expanding to multiple regions also creates multiple challenges. The biggest one is maintaining consistency between the data in Memcache and the persistent storage across the regions.
In Facebook’s region setup, one region holds the primary databases while other geographic regions contain read-only replicas. The replicas are kept in sync with the primary using MySQL’s replication mechanism.
However, when replication is involved, there is bound to be some replication lag. In other words, the replica databases can fall behind the primary database.
There are two main cases to consider when it comes to consistency here:
Writes from the Primary Region
Let’s say a web server in the primary region (US) receives a request from the user to update their profile picture.
To maintain consistency, this change needs to be propagated to other regions as well.
The replica databases have to be updated.
Also, the Memcache instances in the secondary regions need to be invalidated.
The tricky part is managing the invalidation along with the replication.
If the invalidation arrives in the secondary region (Europe) before the actual change is replicated to the database in the region, there are chances of a race condition as follows:
Someone in the Europe region tries to view the profile picture.
The system fetches the information from the cache but it has been invalidated.
Data is fetched from the read-only database in the region, which is still lagging. This means that the fetch request gets the old picture and sets it within the cache.
Eventually, the replication is successful but the cache is already set with stale data and future requests will continue fetching this stale data from the cache.
The below diagram shows this scenario:
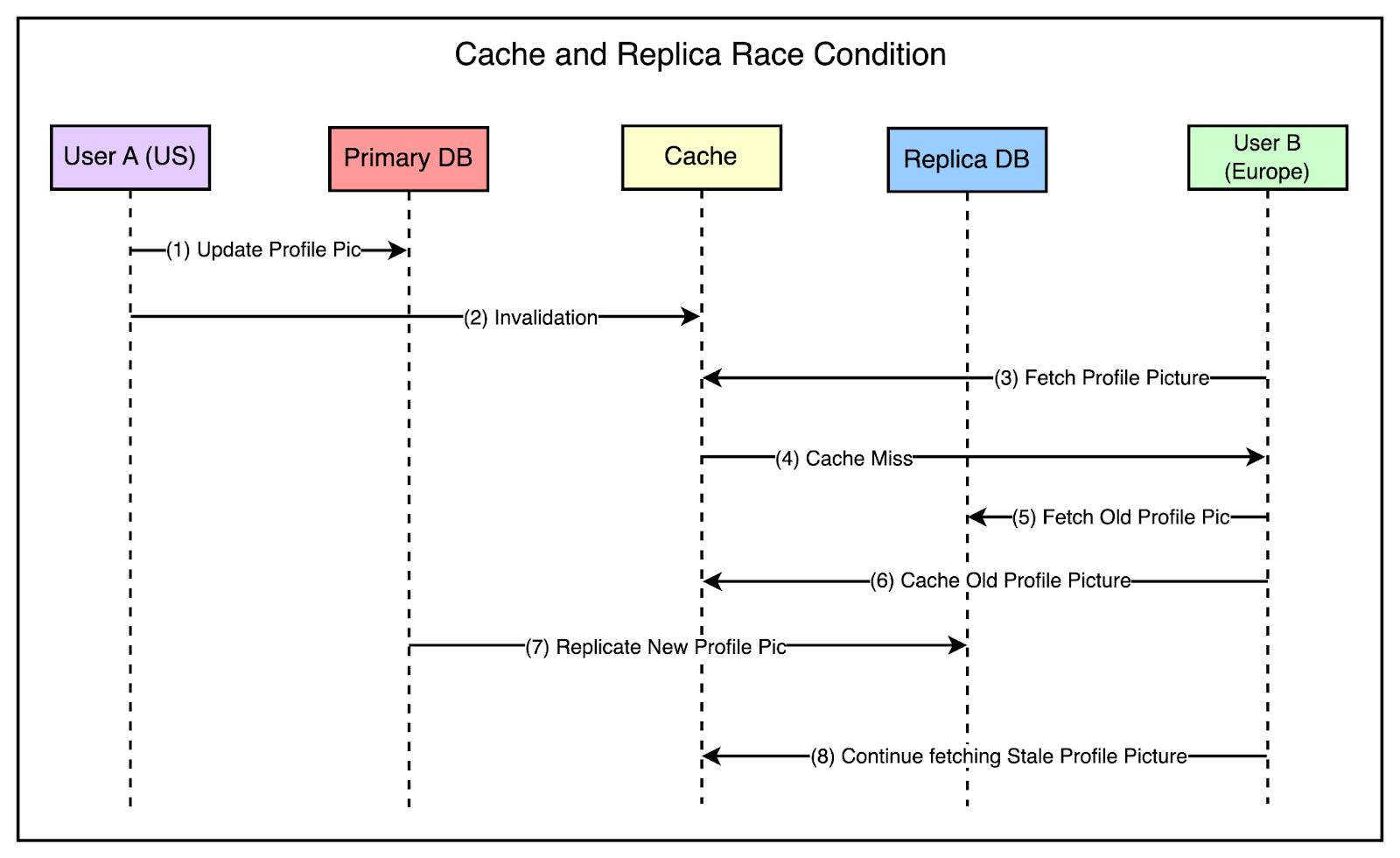
To avoid such race conditions, Facebook implemented a solution where the storage cluster having the most up-to-date information is responsible for sending invalidations within a region. It uses the same mcsqueal setup we talked about in the previous section.
This approach ensures that invalidations don’t get sent prematurely to the replica regions before the change has been fully replicated in the databases.
Writes from the Non-Primary Region
When dealing with writes originating from non-primary regions, the sequence of events is as follows:
User updates their profile picture from a secondary region. While reads are served from the replica or secondary regions, the writes go to the primary region.
After the writes are successful, the changes also need to be replicated in the secondary region as well.
However, there’s a risk that before the replication catches up, a read request on the replica region may fetch and cache stale data in Memcache.
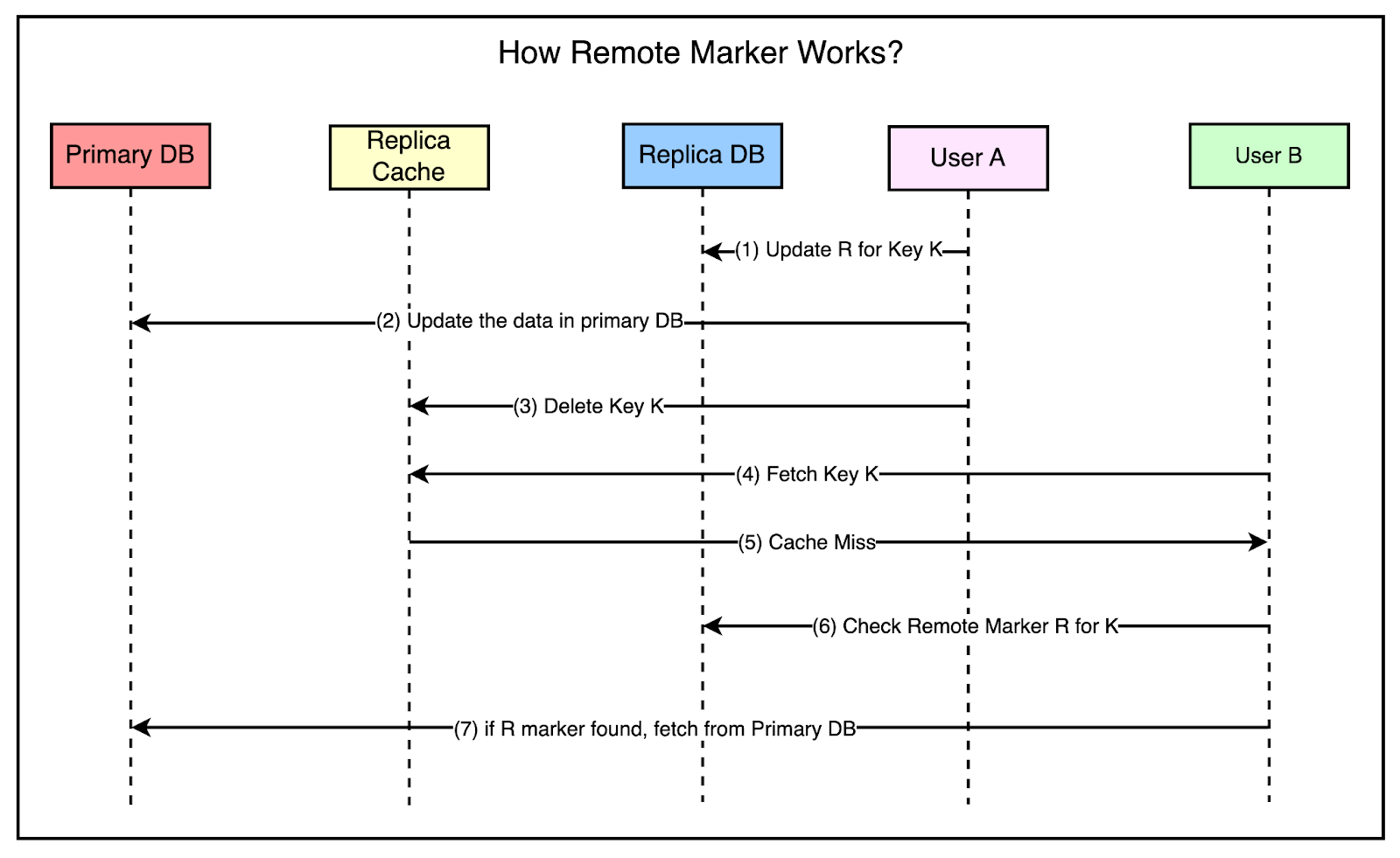
To solve this problem, Facebook used the concept of a remote marker.
The remote marker is used to indicate whether the data in the local replica is potentially stale and it should be queried from the primary region.
It works as follows:
When a client web server requests to update the data for key K, it sets a remote marker R for that key in the replica region.
Next, it performs the write to the primary region.
Also, the key K is deleted from the replica region’s Memcache servers.
A read request comes along for K in the replica region but the webserver would get a cache miss.
It checks whether the remote marker R exists and if found, the query is directed to the primary region.
The below diagram shows all the steps in more detail.
At this point, you may think that this approach is inefficient because they are first checking the cache, then the remote marker, and then making the query to the primary region.
In this scenario, Facebook chose to trade off latency for a cache miss in exchange for a reduced probability of reading stale data.
Single Server Optimizations
As you can see, Facebook implemented some big architectural decisions to scale Memcached for their requirements. However, they also spent a significant time optimizing the performance of individual Memcache servers.
While the scope of these improvements may seem small in isolation, their cumulative impact at Facebook’s scale was significant.
Here are a few important optimizations that they made:
Automatic Hash Table Expansion
As the number of stored items grows, the time complexity of lookups in a hash table can degrade to O(n) if the table size remains fixed. This reduces the performance.
Facebook implemented an automatic expansion mechanism for the hash table. When the number of items reaches a certain threshold, the hash table automatically doubles in size, ensuring that the time complexity of the lookups remains constant even as the dataset grows.
Multi-Threaded Server Architecture
Serving a high volume of requests on a single thread can result in increased latency and reduced throughput.
To deal with this, they enhanced the Memcache server to support multiple threads and handle requests concurrently.
Dedicated UDP Port for Each Thread
When multiple threads share the same UDP port, contentions can occur and lead to performance problems.
They implemented support for each thread to have its own dedicated UDP port so that the threads can operate more efficiently.
Adaptive Slab Allocator
Inefficient memory allocation and management can lead to fragmentation and suboptimal utilization of system resources.
Facebook implemented an Adaptive Slab Allocator to optimize memory organization within each Memcache server. The slab allocator divides the available memory into fixed-size chunks called slabs. Each slab is further divided into smaller units of a specific size.
The allocator dynamically adapts the slab sizes based on the observed request patterns to maximize memory utilization.
Conclusion
Facebook’s journey in scaling Memcached serves as a fantastic case study for developers and engineers. It highlights the challenges that come up when building a globally distributed social network that needs to handle massive amounts of data and serve billions of users.
With their implementation and optimization of Memcache, Facebook demonstrates the importance of tackling scalability challenges at multiple levels. From high-level architectural decisions to low-level server optimizations, every aspect plays an important role in ensuring the performance, reliability, and efficiency of the system.
Three key learning points to take away from this study are as follows:
Embracing eventual consistency is the key to performance and availability. However, every decision has to be taken based on a good understanding of the trade-offs.
Failures are inevitable and it’s critical to design your system for failures.
Optimization can be done at multiple levels.
References:
SPONSOR US
Get your product in front of more than 500,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing hi@bytebytego.com
Like
Comment
Restack
© 2024 ByteByteGo
548 Market Street PMB 72296, San Francisco, CA 94104
Unsubscribe

by "ByteByteGo" <bytebytego@substack.com> - 11:35 - 14 May 2024 -
How can tokenization be used to speed up financial transactions?
On Point
4 steps to asset tokenization
by "Only McKinsey" <publishing@email.mckinsey.com> - 01:37 - 14 May 2024 -
Challenge Accepted - Gartner Magic Quadrant for SIEM
Sumo Logic
Gartner Magic Quadrant for SIEM 2024
 Hi Mohammad,
Hi Mohammad,
We’re excited to announce that Sumo Logic was recognized as 'a Challenger' in the 2024 Gartner® Magic Quadrant™ for Security Information and Event Management.
With a true cloud-native offering, we lead in the Cloud SIEM market, delivering agility, scalability, and performance.
Highlights from the recent Gartner SIEM report include:
- How SIEM solutions are evaluated for the report
- How Sumo Logic is positioned as 'a Challenger'
Sumo Logic, Aviation House, 125 Kingsway, London WC2B 6NH, UK
© 2024 Sumo Logic, All rights reserved.Unsubscribe 


by "Sumo Logic" <marketing-info@sumologic.com> - 03:03 - 13 May 2024 -
It’s not just about the money: A leader’s guide to the CFO role
On the money Brought to you by Liz Hilton Segel, chief client officer and managing partner, global industry practices, & Homayoun Hatami, managing partner, global client capabilities
Like almost every other leadership role, the job of CFO has undergone profound changes in the past few years. Our research shows that a growing number of functions report to the finance chief, who may also be at the forefront of digitization and, increasingly, at the hub of value creation. Finance leaders are also playing prominent roles in talent development, innovation, and capability building. This week, we explore what’s new about the CFO role and how both new and experienced leaders can tackle its many complexities.
If you’ve been a finance leader for a few years, you may be in danger of falling into complacency. That’s why it’s critical for midtenure CFOs to become prime movers of change, suggest McKinsey senior partners Cristina Catania and John Kelleher and colleagues in an article. “Midtenure is when the best finance leaders get bold,” the authors say. In their interviews with eight former CFOs, four priorities emerge; an essential one may be to expand your horizons beyond finance. For example, some executives recommend joining the board of a noncompeting company to understand how other leaders manage digitizations, expansions, or transformations. Or you may try breaking down silos between corporate functions and business units in your own organization. One executive spoke up when he saw issues in other functions. “When we saw problems with R&D budgets, for example, I met with the CTO [chief technology officer] once a month, just the two of us,” he says. “We made sure that we were aligned and not fighting against each other.”
That’s the increase in the amount of time that today’s finance leaders spend on value-added activities compared with the average company ten years ago. As a proportion of total finance time, business partnering and financial planning and analysis are up by 9 percent; time spent on other value-added functions such as tax, treasury, and policy setting has increased by 36 percent. “Finance leaders deliver far more than core financial skills: their work guides the functioning of the entire organization every day,” note McKinsey partners Ankur Agrawal and Steven Eklund and colleagues. They cite four imperatives for finance departments in the next decade, including looking beyond transactional activities and helping define the primary data strategy for the enterprise.
That’s McKinsey senior partners Michael Birshan and Andy West and colleagues in an article on the seven key mindsets and practices that new CFOs can adopt right from the start. Being proactive about risk is a critical practice to consider: “While no one can predict the future, it is essential to recognize the elements of your business that are most at stake should major disruptions arise,” note the authors. During the financial crisis of 2008, the most effective CFOs focused on cutting costs but did not lose sight of growth—with their organizations becoming more resilient as a result. “Being proactive before and through the downturn helped put their companies in the lead as the economy recovered,” the McKinsey experts say.
“The CFO has become the pivot point for understanding what stakeholders are looking for and how to deliver it,” says Palo Alto Networks CFO Dipak Golechha. In a discussion with McKinsey senior partner and CFO Eric Kutcher, Golechha describes how the finance function has evolved—“[it] has a much broader mandate now than it had before”—and why finance leaders need to be agile, flexible, and perhaps most important, well versed in corporate cybersecurity. “Technology has become the foundation of how every company operates, innovates, and differentiates,” he says. “CFOs, in their stewardship role, have oversight over cybersecurity from an audit and ERM [enterprise risk management] perspective, so I would recommend that if you are not an expert on cybersecurity, get trained.”
You’re excited about your new, high-profile finance role, but do your clothes look the part? It may be time for a wardrobe makeover. The rigid corporate dress codes of yesteryear—think suits—may be out, but you may not want to show up at the C-suite in your pandemic gear of sweatpants and hoodies. In conservative professions such as law, politics, or finance, it can be hard to decide when and where to push the limits of fashion. But whether you opt for full-on bling or just a subtle upgrade or two, there are many ways to elevate your look. And to stay au courant, check out our The State of Fashion 2024 report.
Lead with financial savvy.
— Edited by Rama Ramaswami, senior editor, New York
Share these insights
Did you enjoy this newsletter? Forward it to colleagues and friends so they can subscribe too. Was this issue forwarded to you? Sign up for it and sample our 40+ other free email subscriptions here.
This email contains information about McKinsey’s research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this email because you subscribed to the Leading Off newsletter.
Copyright © 2024 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "McKinsey Leading Off" <publishing@email.mckinsey.com> - 04:51 - 13 May 2024 -
US farmers seek operational and financial help for sustainable agriculture
On Point
Environmental benefits, positive ROI Brought to you by Liz Hilton Segel, chief client officer and managing partner, global industry practices, & Homayoun Hatami, managing partner, global client capabilities
•
Eye on sustainability. To limit emissions from agriculture, US farmers need to change their behaviors, but typically, those who use sustainable-farming practices do so on just a fraction of their land—often less than 30%. The transition to greener agriculture depends on farmers being fairly compensated for their investments in sustainable farming and having access to reliable information on expected ROI, according to McKinsey senior partner David Fiocco and coauthors.
—Edited by Jana Zabkova, senior editor, New York
This email contains information about McKinsey's research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this newsletter because you subscribed to the Only McKinsey newsletter, formerly called On Point.
Copyright © 2024 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "Only McKinsey" <publishing@email.mckinsey.com> - 01:25 - 13 May 2024 -
The week in charts
The Week in Charts
Worker productivity, sustainable agriculture, and more Share these insights
Did you enjoy this newsletter? Forward it to colleagues and friends so they can subscribe too. Was this issue forwarded to you? Sign up for it and sample our 40+ other free email subscriptions here.
This email contains information about McKinsey's research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this email because you subscribed to The Week in Charts newsletter.
Copyright © 2024 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "McKinsey Week in Charts" <publishing@email.mckinsey.com> - 03:20 - 11 May 2024 -
EP111: My Favorite 10 Books for Software Developers
EP111: My Favorite 10 Books for Software Developers
This week’s system design refresher: 10 Coding Principles Explained in 5 Minutes (Youtube video) My Favorite 10 Books for Software Developers 25 Papers That Completely Transformed the Computer World Change Data Capture: Key to Leverage Real-time Data͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ Forwarded this email? Subscribe here for moreThis week’s system design refresher:
10 Coding Principles Explained in 5 Minutes (Youtube video)
My Favorite 10 Books for Software Developers
25 Papers That Completely Transformed the Computer World
Change Data Capture: Key to Leverage Real-time Data
IPv4 vs. IPv6, what are the differences?
SPONSOR US
Latest articles
If you’re not a paid subscriber, here’s what you missed.
To receive all the full articles and support ByteByteGo, consider subscribing:
10 Coding Principles Explained in 5 Minutes
My Favorite 10 Books for Software Developers

General Advice
The Pragmatic Programmer by Andrew Hunt and David Thomas
Code Complete by Steve McConnell: Often considered a bible for software developers, this comprehensive book covers all aspects of software development, from design and coding to testing and maintenance.
Coding
Clean Code by Robert C. Martin
Refactoring by Martin Fowler
Software Architecture
Designing Data-Intensive Applications by Martin Kleppmann
System Design Interview (our own book :))
Design Patterns
Design Patterns by Eric Gamma and Others
Domain-Driven Design by Eric Evans
Data Structures and Algorithms
Introduction to Algorithms by Cormen, Leiserson, Rivest, and Stein
Cracking the Coding Interview by Gayle Laakmann McDowell
Over to you: What is your favorite book?
25 Papers That Completely Transformed the Computer World

Google File System: Insights into a highly scalable file system
Scaling Memcached at Facebook: A look at the complexities of Caching
BigTable: The design principles behind a distributed storage system
Cassandra: A look at the design and architecture of a distributed NoSQL database
Attention Is All You Need: Into a new deep learning architecture known as the transformer
Kafka: Internals of the distributed messaging platform
FoundationDB: A look at how a distributed database
Amazon Aurora: To learn how Amazon provides high-availability and performance
Spanner: Design and architecture of Google’s globally distributed databas
MapReduce: A detailed look at how MapReduce enables parallel processing of massive volumes of data
Shard Manager: Understanding the generic shard management framework
Dapper: Insights into Google’s distributed systems tracing infrastructure
Flink: A detailed look at the unified architecture of stream and batch processing
Zanzibar: A look at the design, implementation and deployment of a global system for managing access control lists at Google
Monarch: Architecture of Google’s in-memory time series database
Thrift: Explore the design choices behind Facebook’s code-generation tool
Bitcoin: The ground-breaking introduction to the peer-to-peer electronic cash system
WTF - Who to Follow Service at Twitter: Twitter’s (now X) user recommendation system
Raft Consensus Algorithm: To learn about the more understandable consensus algorithm
Time Clocks and Ordering of Events: The extremely important paper that explains the concept of time and event ordering in a distributed system
Over to you: I’m sure we missed many important papers. Which ones do you think should be included?
Change Data Capture: Key to Leverage Real-time Data
90% of the world’s data was created in the last two years and this growth will only get faster.

However, the biggest challenge is to leverage this data in real-time. Constant data changes make databases, data lakes, and data warehouses out of sync.
CDC or Change Data Capture can help you overcome this challenge.
CDC identifies and captures changes made to the data in a database, allowing you to replicate and sync data across multiple systems.
So, how does Change Data Capture work? Here's a step-by-step breakdown:
1 - Data Modification: A change is made to the data in the source database. It could be an insert, update, or delete operation on a table.
2 - Change Capture: A CDC tool monitors the database transaction logs to capture the modifications. It uses the source connector to connect to the database and read the logs.
3 - Change Processing: The captured changes are processed and transformed into a format suitable for the downstream systems.
4 - Change Propagation: The processed changes are published to a message queue and propagated to the target systems, such as data warehouses, analytics platforms, distributed caches like Redis, and so on.
5 - Real-Time Integration: The CDC tool uses its sink connector to consume the log and update the target systems. The changes are received in real time, allowing for conflict-free data analysis and decision-making.
Users only need to take care of step 1 while all other steps are transparent.
A popular CDC solution uses Debezium with Kafka Connect to stream data changes from the source to target systems using Kafka as the broker. Debezium has connectors for most databases such as MySQL, PostgreSQL, Oracle, etc.
Over to you: have you leveraged CDC in your application before?IPv4 vs. IPv6, what are the differences?
The transition from Internet Protocol version 4 (IPv4) to Internet Protocol version 6 (IPv6) is primarily driven by the need for more internet addresses, alongside the desire to streamline certain aspects of network management.

Format and Length
IPv4 uses a 32-bit address format, which is typically displayed as four decimal numbers separated by dots (e.g., 192.168.0. 12). The 32-bit format allows for approximately 4.3 billion unique addresses, a number that is rapidly proving insufficient due to the explosion of internet-connected devices.
In contrast, IPv6 utilizes a 128-bit address format, represented by eight groups of four hexadecimal digits separated by colons (e.g., 50B3:F200:0211:AB00:0123:4321:6571:B000). This expansion allows for approximately much more addresses, ensuring the internet's growth can continue unabated.Header
The IPv4 header is more complex and includes fields such as the header length, service type, total length, identification, flags, fragment offset, time to live (TTL), protocol, header checksum, source and destination IP addresses, and options.
IPv6 headers are designed to be simpler and more efficient. The fixed header size is 40 bytes and includes less frequently used fields in optional extension headers. The main fields include version, traffic class, flow label, payload length, next header, hop limit, and source and destination addresses. This simplification helps improve packet processing speeds.Translation between IPv4 and IPv6
As the internet transitions from IPv4 to IPv6, mechanisms to allow these protocols to coexist have become essential:
- Dual Stack: This technique involves running IPv4 and IPv6 simultaneously on the same network devices. It allows seamless communication in both protocols, depending on the destination address availability and compatibility. The dual stack is considered one of the best approaches for the smooth transition from IPv4 to IPv6.SPONSOR US
Get your product in front of more than 500,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing hi@bytebytego.com
© 2024 ByteByteGo
548 Market Street PMB 72296, San Francisco, CA 94104
Unsubscribe
by "ByteByteGo" <bytebytego@substack.com> - 11:37 - 11 May 2024 -
Prioridades del CEO para 2024
Además, cómo la fabricación está capturando todo el valor de la IA Comparte este email

Los CEOs tienen mucho que hacer. ¿A qué deberían dar prioridad en 2024? En nuestro artículo destacado, Homayoun Hatami y Liz Hilton Segel, socios senior de McKinsey, analizan qué es lo que más les importa a los directores ejecutivos este año y cómo pueden sortear la incertidumbre geopolítica, los efectos de la IA generativa en sus organizaciones, la transición energética y más. Otros temas relevantes son:
•
cómo se ve la IA en la vanguardia de la manufactura actual
•
cómo los CFOs pueden lograr un impacto estratégico real y crear valor a gran escala
•
cómo los gestores de adquisiciones de capital privado pueden maximizar la creación de valor operativo
•
la continua relevancia del libro CEO Excellence
La selección de nuestros editores
LOS DESTACADOS DE ESTE MES

Cómo los faros de la industria manufacturera están capturando todo el valor de la IA
La IA está definiendo la Cuarta Revolución Industrial, y los pioneros de la producción están encontrando un impacto significativo en toda la fábrica, la red de manufactura y la cadena de suministro.
Ilumine su camino
Seis maneras de que los CFOs encuentren tiempo para liberar todo su potencial
Es difícil crear valor a gran escala cuando hay que gestionar las exigencias diarias y a menudo urgentes de la función financiera. Pero algunos directores financieros están a la altura del desafío.
Acepte el reto
Reducir la brecha en la creación de valor del capital privado
En un contexto de ralentización de las operaciones, los gestores de adquisiciones de capital privado pueden adaptar su enfoque a la creación de valor y, como primer paso, hacer hincapié en las mejoras de la eficiencia operativa.
Impulse la eficiencia operativa
Por qué los estrategas deberían aceptar la imperfección
En un mundo de cambios rápidos, buscar la certeza puede ocultar las oportunidades. Dar pasos más pequeños pero audaces, proporciona un camino más seguro a través de la incertidumbre.
Cambie su enfoque
Impactando audiencias de todo el mundo: Una revisión de CEO Excellence
En esta retrospectiva final, los socios senior de McKinsey y autores del best-seller comparten las ideas de su libro, discuten el “ciclo de vida de un CEO” y hablan de los avances en sus investigaciones en curso.
Atrévase a liderar
Solo para miembros: Ofrecer mayor valor a través de la fidelización y la fijación de precios
Las empresas orientadas al consumidor tienen la oportunidad de desbloquear el valor holístico. Al integrar mejor sus programas de lealtad con las estrategias de fijación de precios, pueden impulsar el crecimiento en un panorama económico confuso.
Conozca 3 niveles de oportunidadEsperamos que disfrute de los artículos en español que seleccionamos este mes y lo invitamos a explorar también los siguientes artículos en inglés.

McKinsey Explainers
Find direct answers to complex questions, backed by McKinsey’s expert insights.
Learn more
McKinsey Themes
Browse our essential reading on the topics that matter.
Get up to speed
McKinsey on Books
Explore this month’s best-selling business books prepared exclusively for McKinsey Publishing by Circana.
See the lists
McKinsey Chart of the Day
See our daily chart that helps explain a changing world—as we strive for sustainable, inclusive growth.
Dive in
McKinsey Classics
New research suggests that the secret to developing effective leaders is to encourage four types of behavior. Read our 2015 classic “Decoding leadership: What really matters” to learn more.
Rewind
The Daily Read
Our Daily Read newsletter highlights an article a day, picked by our editors.
Subscribe now— Edited by Joyce Yoo, editor, New York
COMPARTA ESTAS IDEAS
¿Disfrutó este boletín? Reenvíelo a colegas y amigos para que ellos también puedan suscribirse. ¿Se le remitió este articulo? Regístrese y pruebe nuestras más de 40 suscripciones gratuitas por correo electrónico aquí.
Este correo electrónico contiene información sobre la investigación , los conocimientos, los servicios o los eventos de McKinsey. Al abrir nuestros correos electrónicos o hacer clic en los enlaces, acepta nuestro uso de cookies y tecnología de seguimiento web. Para obtener más información sobre cómo usamos y protegemos su información, consulte nuestra política de privacidad.
Recibió este correo electrónico porque es un miembro registrado de nuestro boletín informativo Destacados.
Copyright © 2024 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "Destacados de McKinsey" <publishing@email.mckinsey.com> - 08:55 - 11 May 2024 -
Helping small businesses get more done
Small but mighty Brought to you by Sven Smit, chair of insights and ecosystems and of the McKinsey Global Institute, & Tracy Francis, chief marketing officer
This week’s headline findings
Do these insights resonate with you? What else should we be writing about now? Tell us by emailing insightstoimpact@mckinsey.com.
With McKinsey, it’s never just tech. Find out how we apply strategy, deep domain expertise, and more to help clients outcompete with technology and transform their companies.From laundromats to dental practices, micro-, small, and medium-size enterprises (MSMEs) account for two-thirds of employment in advanced economies and nearly four-fifths in emerging markets. However, their productivity significantly lags behind that of larger companies, particularly in emerging countries. Closing this productivity gap could boost global GDP by 5–10 percent, say McKinsey Global Institute director Olivia White and coauthors. Drawing from their granular analysis of 16 economies across various sectors, the authors recommend that MSMEs collaborate with large firms to enhance R&D and technology capabilities, cooperate for knowledge and resource sharing, and use government policy support to access technology, new markets, and financing. They argue that improving MSME productivity benefits both MSMEs and large enterprises, as their productivity moves in tandem in most subsectors.
Gen Z could be the answer to the US manufacturing labor shortage, wherein barely six in ten vacancies have been filled since 2020. Although Gen Z has demonstrated a greater interest in manufacturing careers than previous generations have, and more comfort with its technologies, they also value meaningful work, career development, flexibility, and caring leadership, according to research by senior partner Fernando Perez and coauthors. To attract and retain these younger workers, manufacturers could offer flexible work arrangements, provide skills-based training that empowers them to solve operational issues, and connect their work to a broader sense of purpose. But leaders should act swiftly to engage their Gen Z workforce, the authors say, given that 48 percent of them intend to leave their positions within three to six months.
Cash may soon lose its luster in Latin America, where many people still receive wages and make purchases exclusively in cash. That’s because the region is rapidly undergoing “bancarization,” the expansion of financial services, including online banking, to the unbanked population. A 2023 survey by partner Jesús Moreno and coauthors reveals that 70 percent of Spanish-speaking Latin American consumers prefer noncash payments, such as debit cards, credit cards, and mobile payments, compared with just 41 percent in their 2021 survey. The authors suggest that this trend presents opportunities for banks and financial-services companies in the region to innovate and customize payment solutions that improve customer experiences. They can make their offerings more appealing to specific customer segments that favor one digital payment method over another; 17 percent of millennials in Latin America, for example, prefer mobile payments, while only 12 percent of Gen Z consumers do.OTHER FINDINGS OF NOTE
•
In a recent episode of the McKinsey Talks Talent podcast, psychologist Dr. Tomas Chamorro-Premuzic shares his research findings with McKinsey partners Bryan Hancock and Brooke Weddle, explaining how toxic traits like narcissism and overconfidence propel some men into leadership roles, while high-EQ traits like empathy, self-awareness, and humility make for more competent leaders, regardless of gender.
•
Senior partners Cristina Catania and John Kelleher and their coauthors share priorities for midtenure CFOs, including revitalizing the finance function and collaborating with the CEO on a new strategic aspiration.
•
In a recent conversation with senior partners Stéphane Bout and Eric Hazan, Arthur Mensch, CEO and cofounder of Mistral AI, explains how his company quickly became a unicorn by using open-source strategies and discusses AI’s role in augmenting workplace productivity, freeing humans up to invent new ideas and manage human relationships.
WHAT WE’RE READING
A recent edition of Author Talks, exclusive to the McKinsey Insights app, features writer, facilitator, and speaker Elaine Lin Hering discussing her new book, Unlearning Silence: How to Speak Your Mind, Unleash Talent, and Live More Fully (Penguin Random House, March 2024). Hering highlights the pervasive culture of learned silence in the workplace, particularly how it suppresses minority voices, and suggests strategies that leaders can use to break it, such as normalizing dissent and sharing positive stories of colleagues speaking up and being rewarded for doing so.
The case study collection Rewired in Action illuminates companies that have launched digital transformations to build value. Supported by technical and industry expertise from McKinsey, these organizations have changed their trajectories through the integration of digital and AI.
— Edited by Jermey Matthews, editor, Boston
Subscribe to Insights to Impact with one click to make sure you keep receiving it, and forward this issue to friends or colleagues who might be interested. Our rolling weekly updates can also be found online.
This email contains information about McKinsey's research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this email because you subscribed to our McKinsey Global Institute alert list.
Copyright © 2024 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "McKinsey Insights to Impact" <publishing@email.mckinsey.com> - 12:52 - 10 May 2024 -
How can companies get the CEO–CMO partnership right?
On Point
Closing the C-suite gap Brought to you by Liz Hilton Segel, chief client officer and managing partner, global industry practices, & Homayoun Hatami, managing partner, global client capabilities
•
Excluded from C-suite planning. CEOs who place marketing at the core of their growth strategies are twice as likely as their peers to have greater than 5% annual growth, finds a recent McKinsey survey conducted with input from the Association of National Advertisers. But instead of having a seat at the decision-making table, “CMOs [are] being moved to executors of the strategy,” McKinsey partner Robert Tas shares in an episode of The McKinsey Podcast. CMOs need to both shape strategy and execute it, Tas says.
—Edited by Belinda Yu, editor, Atlanta
This email contains information about McKinsey's research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this newsletter because you subscribed to the Only McKinsey newsletter, formerly called On Point.
Copyright © 2024 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "Only McKinsey" <publishing@email.mckinsey.com> - 01:12 - 10 May 2024 -
"Get Published: Guest Blogging Opportunity"
Hello
I hope you are doing well. I'm Outreach Manager, We have high quality sites for sponsored guest posting or link insertions.
Please check my sponsored guest posting sites.Please select these sites for guest posting or link insertions. All websites have different quality and different pricing. I will send you pricing after selecting these sites.Question?
1) Please select these sites for sponsored guest posting ? I would recommend the price website again.
2) Can you let me know if you will send me the articles for the post or we will write it?
I can publish one article with two do-follow backlinks.
If you have further questions kindly let me know, I'm here always to assist our clients.
Waiting for your good news.
by "Alex Aleksandr" <alekmarking@gmail.com> - 12:59 - 9 May 2024 -
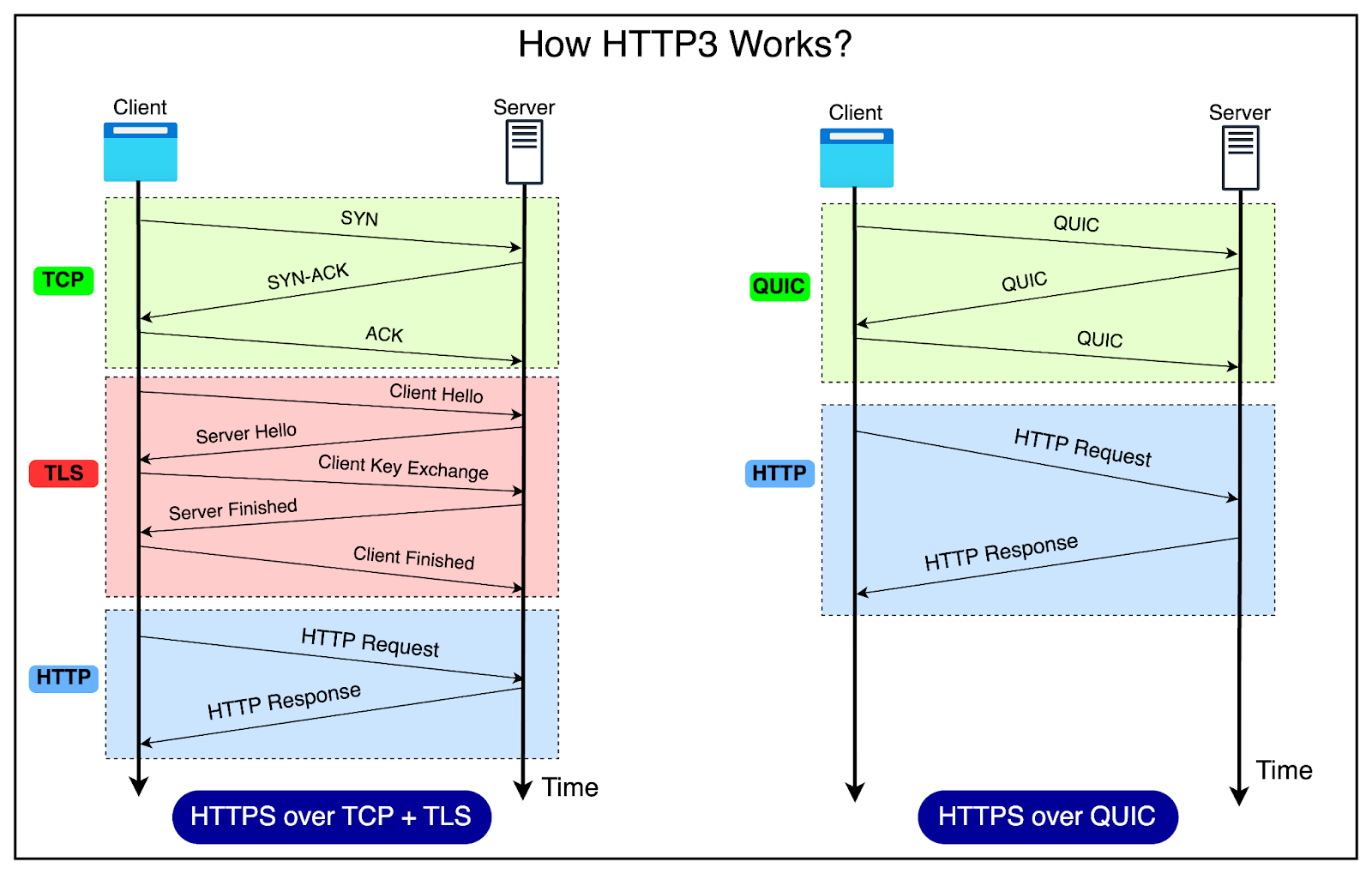
HTTP1 vs HTTP2 vs HTTP3 - A Deep Dive
HTTP1 vs HTTP2 vs HTTP3 - A Deep Dive
What has powered the incredible growth of the World Wide Web? There are several factors, but HTTP or Hypertext Transfer Protocol has played a fundamental role. Once upon a time, the name may have sounded like a perfect choice. After all, the initial goal of HTTP was to transfer hypertext documents. These are documents that contain links to other documents.͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ Forwarded this email? Subscribe here for moreLatest articles
If you’re not a subscriber, here’s what you missed this month.
To receive all the full articles and support ByteByteGo, consider subscribing:
What has powered the incredible growth of the World Wide Web?
There are several factors, but HTTP or Hypertext Transfer Protocol has played a fundamental role.
Once upon a time, the name may have sounded like a perfect choice. After all, the initial goal of HTTP was to transfer hypertext documents. These are documents that contain links to other documents.
However, developers soon realized that HTTP can also help transfer other content types, such as images and videos. Over the years, HTTP has become critical to the existence and growth of the web.
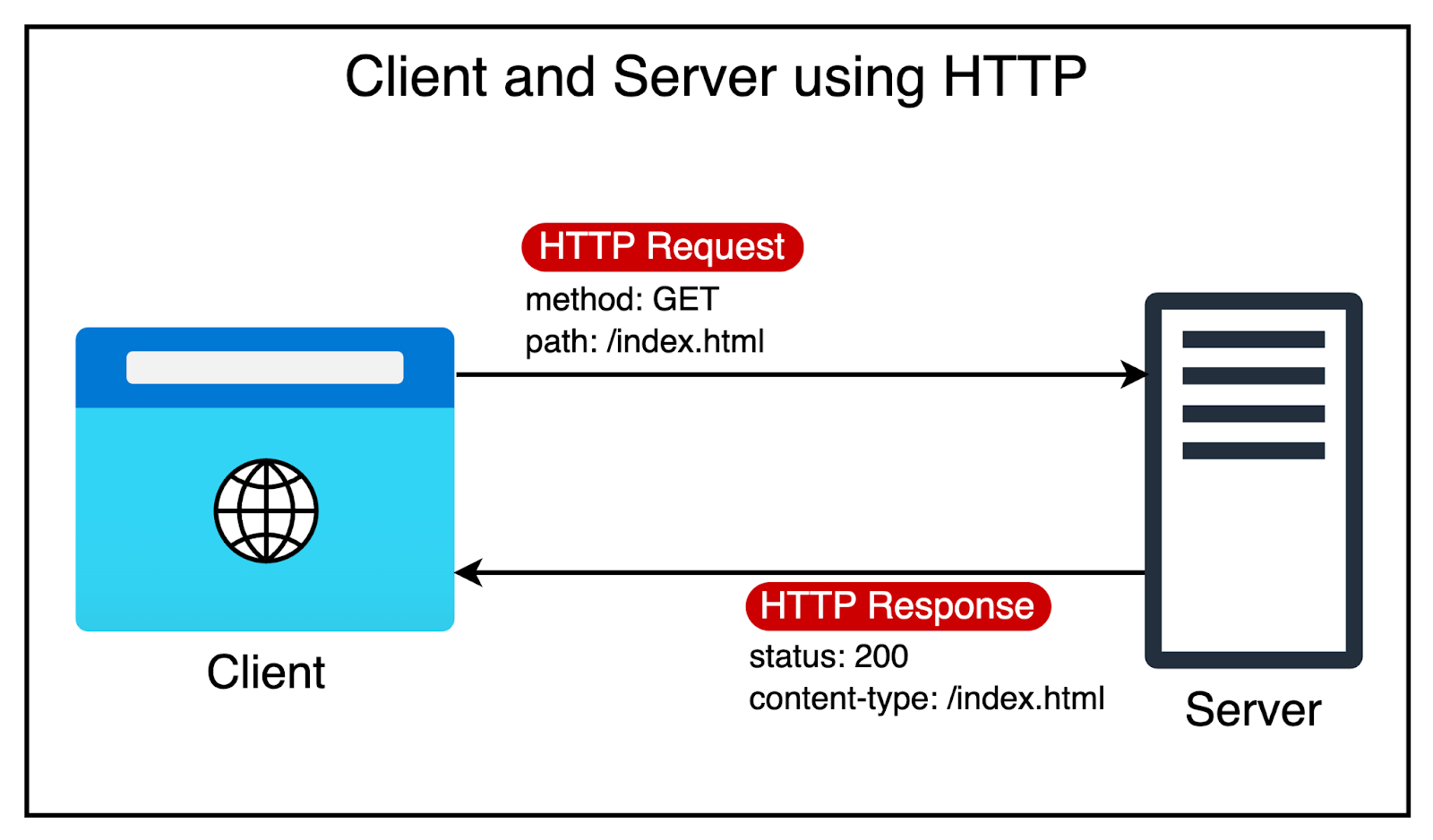
In today’s deep dive, we’ll unravel the evolution of HTTP, from its humble beginnings with HTTP1 to the latest advancements of HTTP2 and HTTP3. We’ll look at how each version addressed the limitations of its predecessor, improving performance, security, and user experience.
By the end of this article, you’ll have a solid understanding of the key differences between HTTP1, HTTP2, and HTTP3, helping you make informed decisions when designing web applications.
HTTP1 - The Foundation
HTTP/1 was introduced in 1996. Before that, there was HTTP/0.9, a simple protocol that only supported the GET method and had no headers. Only HTML files were included in HTTP responses. There were no HTTP headers and no HTTP status codes.
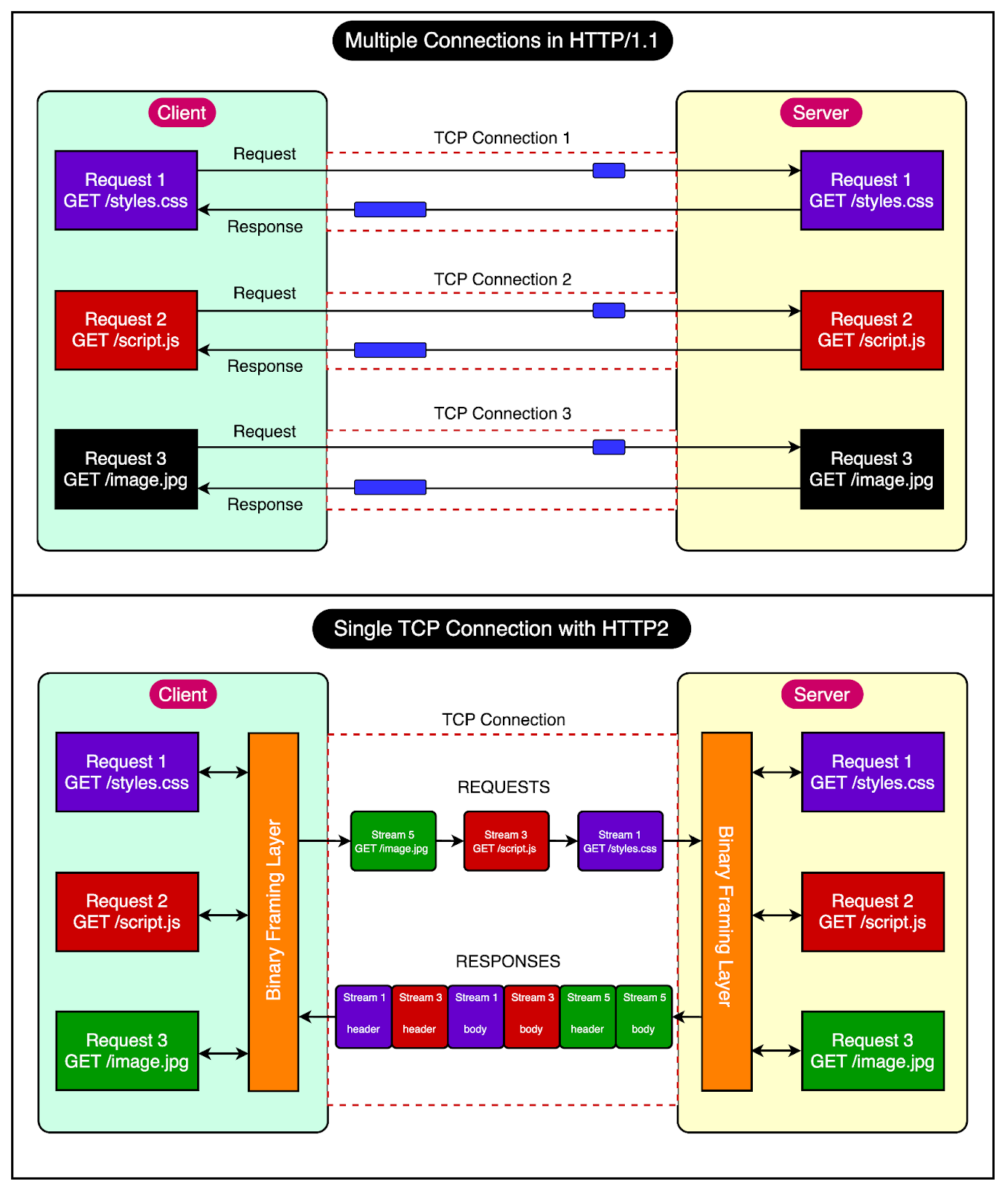
HTTP/1.0 added headers, status codes, and additional methods such as POST and HEAD. However, HTTP/1 still had limitations. For example, each request-response pair needed a new TCP connection
In 1997, HTTP/1.1 was released to address the limitations of HTTP/1. Generally speaking, HTTP/1.1 is the definitive version of HTTP1. This version powered the growth of the World Wide Web and is still used heavily despite being over 25 years old.
What contributed to its incredible longevity?
There were a few important features that made it so successful.
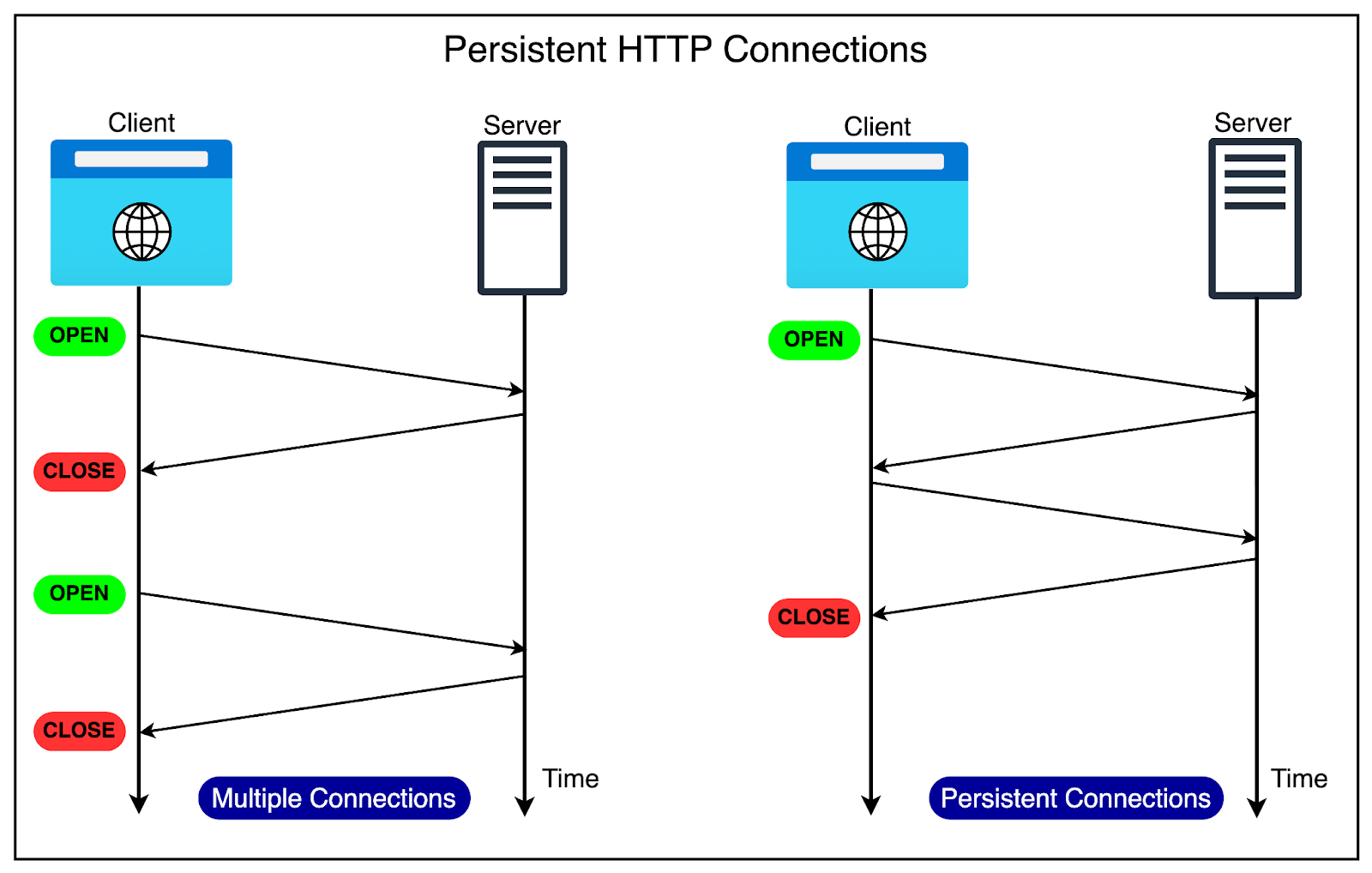
1 - Persistent Connections
As mentioned, HTTP started as a single request-response protocol.
A client opens a connection to the server, makes a request, and gets the response. The connection is then closed. If there’s a second request, the cycle repeats. The same cycle repeats for subsequent requests.
It’s like a busy restaurant where a single waiter handles all orders. For each customer, the waiter takes the order, goes to the kitchen, prepares the food, and then delivers it to the customer’s table. Only then does the waiter move on to the next customer.
As the web became more media-oriented, closing the connection constantly after every response proved wasteful. If a web page contains multiple resources that have to be fetched, you would have to open and close the connection multiple times.
Since HTTP/1 was built on top of TCP (Transmission Control Protocol), every new connection meant going through the 3-way handshake process.
HTTP/1.1 got rid of this extra overhead by supporting persistent connections. It assumed that a TCP connection must be kept open unless directly told to close. This meant:
No closing of the connection after every request
No multiple TCP handshakes.
The diagram below shows the difference between multiple connections and persistent connections.
2 - Pipelining
HTTP/1.1 also introduced the concept of pipelining.
The idea was to allow clients to send multiple requests over a single TCP connection without waiting for corresponding responses. For example, when the browser sees that it needs two images to render a web page, it can request them one after the other.
The below diagram explains the concept of pipelining in more detail.
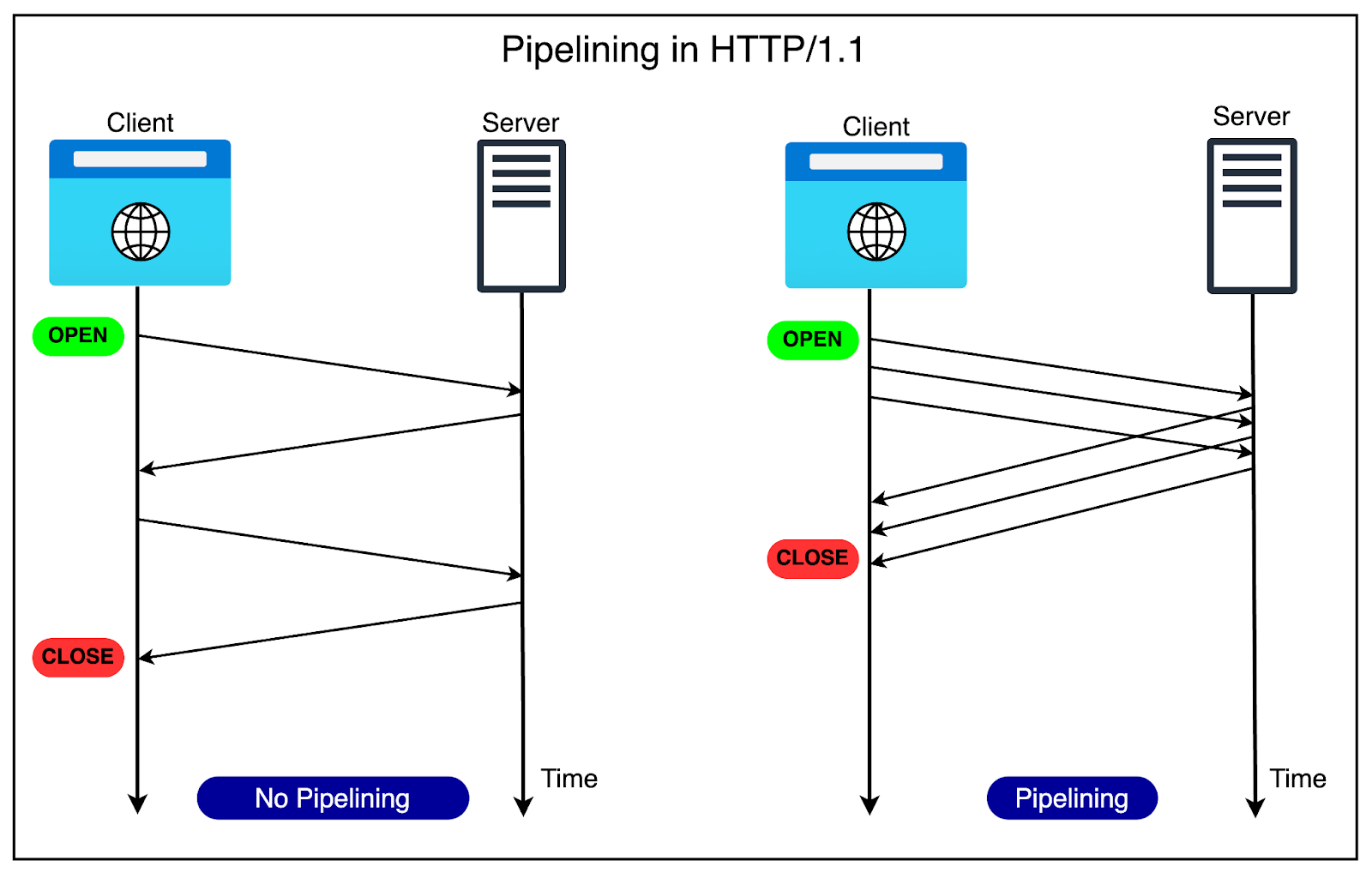
Pipelining further improved performance by reducing the latency for each response before sending the next request. However, pipelining had some limitations around head-of-line blocking that we will discuss shortly.
3 - Chunked Transfer Encoding
HTTP/1.1 introduced chunked transfer encoding that allowed servers to send responses in smaller chunks rather than waiting for the entire response to be generated.
This enabled faster initial page rendering and improved the user experience, particularly for large or dynamically generated content.
4 - Caching and Conditional Requests
HTTP/1.1 introduced sophisticated caching mechanisms and conditional requests.
It added headers like Cache-Control and ETag, which allowed clients and servers to better manage cached content and reduce unnecessary data transfers.
Conditional requests, using headers like If-Modified-Since and If-None-Match, enabled clients to request resources only if they had been modified since a previous request, saving bandwidth and improving performance.
The Problem with HTTP/1.1
There’s no doubt that HTTP/1.1 was game-changing and enabled the amazing growth trajectory of the web over the last 20+ years.
However, the web has also evolved considerably since the time HTTP/1.1 was launched.
Websites have grown in size, with more resources to download and more data to be transferred over the network. According to the HTTP Archive, the average website these days requests around 80 to 90 resources and downloads nearly 2 MB of data.
The next graph shows the steady growth of website size over the last 10+ years.
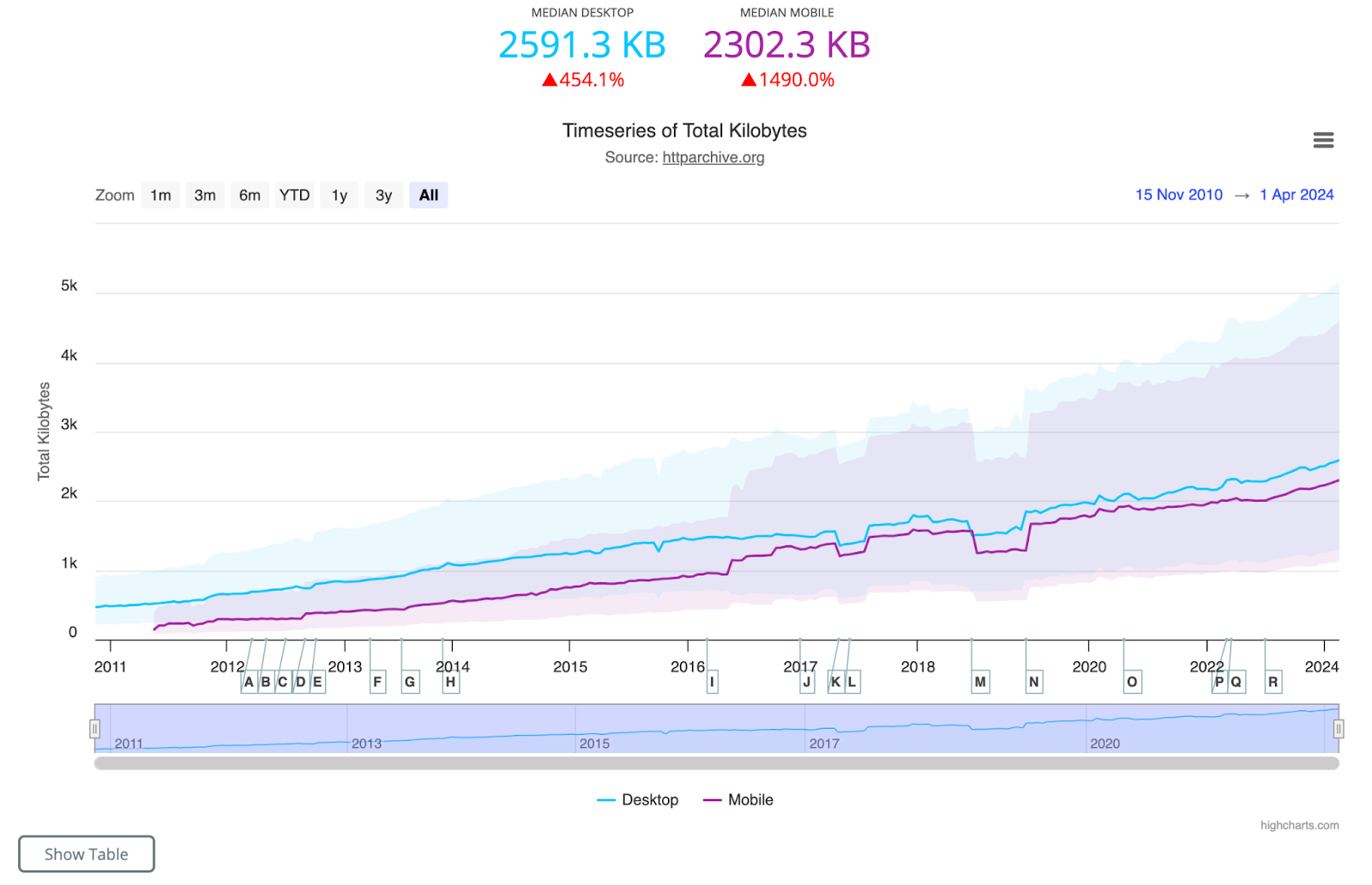
Source: HTTP Archive State of the Web This growth exposed a fundamental performance problem with HTTP/1.1.
The diagram below explains the problem visually.
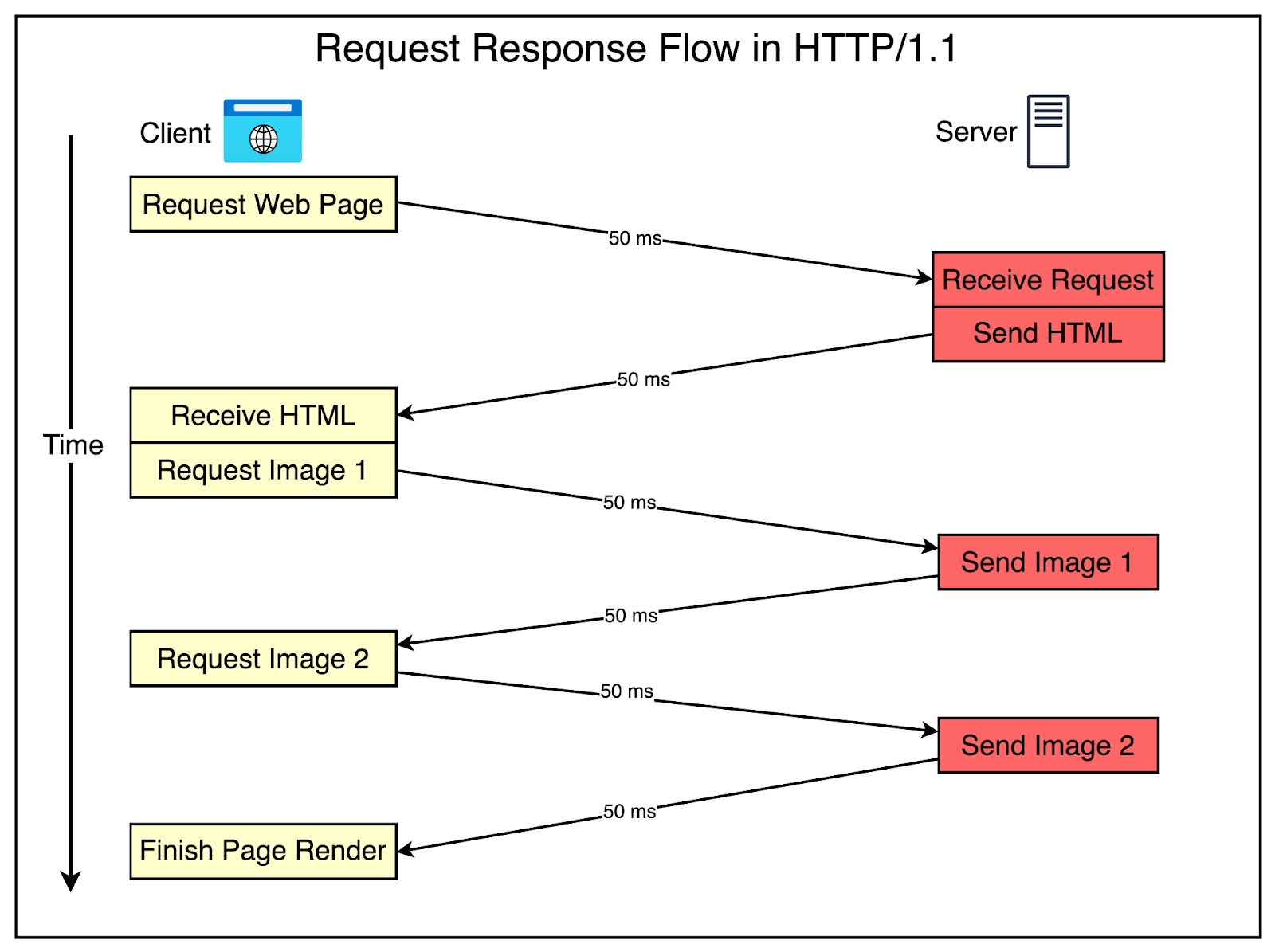

Continue reading this post for free, courtesy of Alex Xu.
A subscription gets you:
An extra deep dive on Thursdays Full archive Many expense it with team's learning budget © 2024 ByteByteGo
548 Market Street PMB 72296, San Francisco, CA 94104
Unsubscribe
by "ByteByteGo" <bytebytego@substack.com> - 11:37 - 9 May 2024 -
What are some recent trends in quantum-technology funding?
On Point
Breakthroughs in quantum technology Brought to you by Liz Hilton Segel, chief client officer and managing partner, global industry practices, & Homayoun Hatami, managing partner, global client capabilities
•
Trillions in value. A year of strong investments coupled with sturdy underlying fundamentals and significant technological advances reflected strong momentum in quantum technology. Updated McKinsey analysis for the third annual Quantum Technology Monitor reveals that four sectors—chemicals, finance, life sciences, and mobility—are likely to see the earliest impact from quantum computing and could gain up to $2 trillion by 2035, say Rodney Zemmel, McKinsey senior partner and global leader of McKinsey Digital, and coauthors.
—Edited by Belinda Yu, editor, Atlanta
This email contains information about McKinsey's research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this newsletter because you subscribed to the Only McKinsey newsletter, formerly called On Point.
Copyright © 2024 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "Only McKinsey" <publishing@email.mckinsey.com> - 01:23 - 9 May 2024 -
Samsung reduces data costs by 30% - Case Study Inside! 🚀
Sumo Logic
From best practices to key features


Scalable log management and analytics: Spend more time innovating and less time troubleshooting.
Powerful log analytics and cost savings of 30% with data tiering? Absolutely.
It takes an enormous amount of data to run Bixby (Samsung’s answer to Siri) – even more so with Galaxy AI integration. But, Samsung’s data growth wasn’t sustainable given their budget.
With Sumo Logic, Samsung:- Reduced data costs by 30% - while maintaining their data growth trajectory
- Improved customer service and response times
- Reduced overhead

Since this case study, we've launched an industry-leading, analytics-based pricing model, including unlimited log ingestion and indexing at $0 with unlimited full-access users.
Introducing analytics-based Flex Pricing.Sumo Logic, Aviation House, 125 Kingsway, London WC2B 6NH, UK
© 2024 Sumo Logic, All rights reserved.Unsubscribe
by "Sumo Logic" <marketing-info@sumologic.com> - 09:01 - 8 May 2024 -
What is generative AI?
On Point
Gen AI’s benefits and risks Brought to you by Liz Hilton Segel, chief client officer and managing partner, global industry practices, & Homayoun Hatami, managing partner, global client capabilities
•
Growing adoption of AI. Gen AI, a form of AI that uses algorithms to create content, has come a long way since ChatGPT burst on the scene in 2022. Given the potential of gen AI to dramatically change how a range of jobs are performed, organizations of all stripes have raced to incorporate the technology. Over the past five years, AI adoption has more than doubled, according to a 2022 survey by McKinsey senior partners Alex Singla and Alexander Sukharevsky, global leaders of QuantumBlack, AI by McKinsey, and their coauthors.
•
AI’s limitations. Developing a bespoke gen AI model is highly resource intensive and therefore out of reach for most companies today. Instead, organizations typically either use gen AI out of the box or fine-tune the technology using proprietary data to help perform specific tasks. Because gen AI models are so new, the long-tail effects are still unknown, which means there are risks involved in using these models. Understand some of the limitations of gen AI, and visit McKinsey Digital to see how companies are using technology to create real value.
—Edited by Belinda Yu, editor, Atlanta
This email contains information about McKinsey's research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this newsletter because you subscribed to the Only McKinsey newsletter, formerly called On Point.
Copyright © 2024 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "Only McKinsey" <publishing@email.mckinsey.com> - 01:30 - 8 May 2024 -
100X Scaling: How Figma Scaled its Databases
100X Scaling: How Figma Scaled its Databases
😘 Kiss bugs goodbye with fully automated end-to-end test coverage (Sponsored) Bugs sneak out when less than 80% of user flows are tested before shipping. But getting that kind of coverage — and staying there — is hard and pricey for any sized team.͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ Forwarded this email? Subscribe here for more😘 Kiss bugs goodbye with fully automated end-to-end test coverage (Sponsored)

Bugs sneak out when less than 80% of user flows are tested before shipping. But getting that kind of coverage — and staying there — is hard and pricey for any sized team.
QA Wolf takes testing off your plate:
→ Get to 80% test coverage in just 4 months.
→ Stay bug-free with 24-hour maintenance and on-demand test creation.
→ Get unlimited parallel test runs
→ Zero Flakes guaranteed
QA Wolf has generated amazing results for companies like Salesloft, AutoTrader, Mailchimp, and Bubble.
🌟 Rated 4.5/5 on G2
Learn more about their 90-day pilot
Figma, a collaborative design platform, has been on a wild growth ride for the last few years. Its user base has grown by almost 200% since 2018, attracting around 3 million monthly users.
As more and more users have hopped on board, the infrastructure team found themselves in a spot. They needed a quick way to scale their databases to keep up with the increasing demand.
The database stack is like the backbone of Figma. It stores and manages all the important metadata, like permissions, file info, and comments. And it ended up growing a whopping 100x since 2020!
That's a good problem to have, but it also meant the team had to get creative.
In this article, we'll dive into Figma's database scaling journey. We'll explore the challenges they faced, the decisions they made, and the innovative solutions they came up with. By the end, you'll better understand what it takes to scale databases for a rapidly growing company like Figma.
The Initial State of Figma’s Database Stack
In 2020, Figma still used a single, large Amazon RDS database to persist most of the metadata. While it handled things quite well, one machine had its limits.
During peak traffic, the CPU utilization was above 65% resulting in unpredictable database latencies.
While complete saturation was far away, the infrastructure team at Figma wanted to proactively identify and fix any scalability issues. They started with a few tactical fixes such as:
Upgrade the database to the largest instance available (from r5.12xlarge to r5.24xlarge).
Create multiple read replicas to scale read traffic.
Establish new databases for new use cases to limit the growth of the original database.
Add PgBouncer as a connection pooler to limit the impact of a growing number of connections.
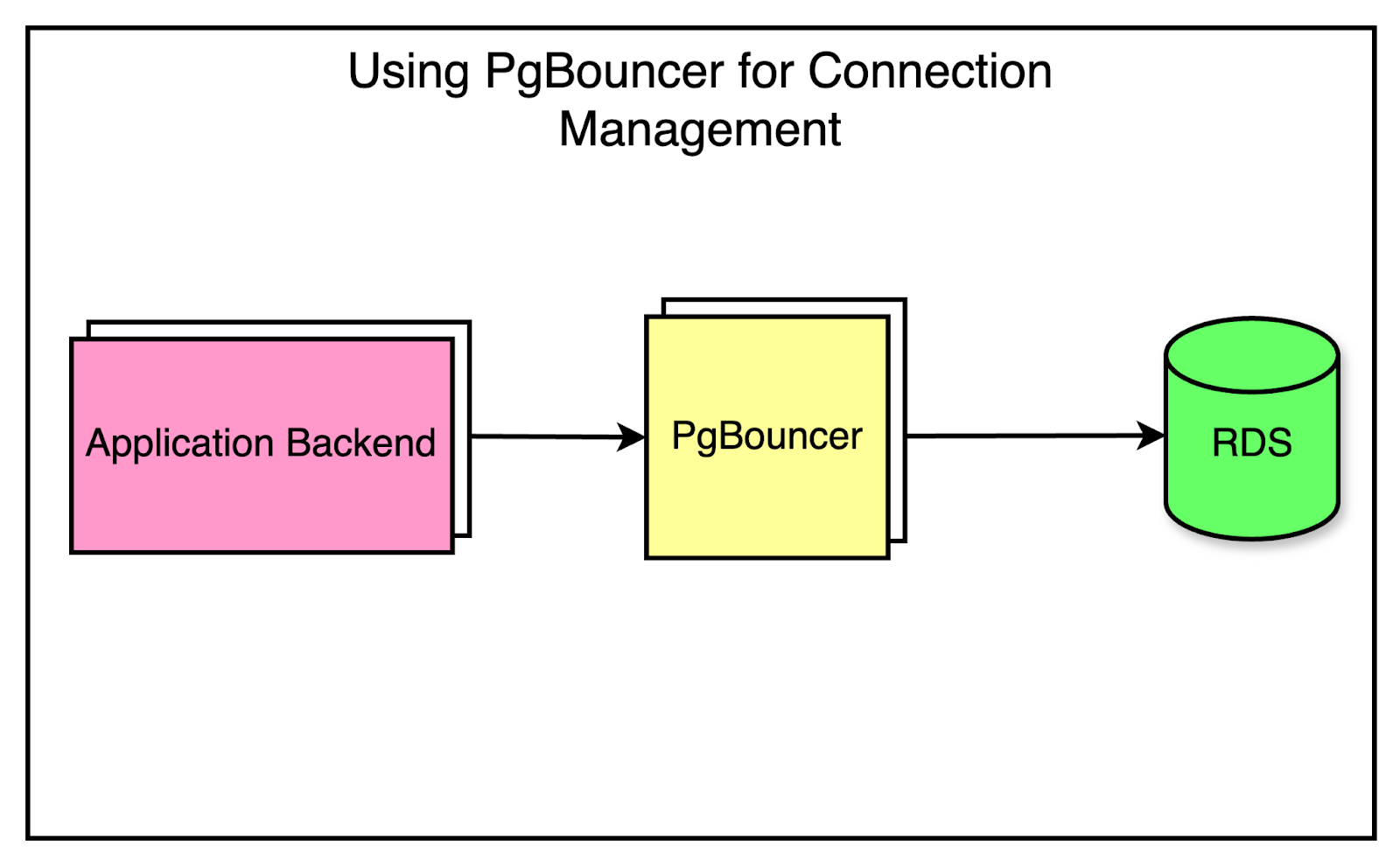
These fixes gave them an additional year of runway but there were still limitations:
Based on the database traffic, they learned that write operations contributed a major portion of the overall utilization.
All read operations could not be moved to replicas because certain use cases were sensitive to the impact of replication lag.
It was clear that they needed a longer-term solution.
The First Step: Vertical Partitioning
When Figma's infrastructure team realized they needed to scale their databases, they couldn't just shut everything down and start from scratch. They needed a solution to keep Figma running smoothly while they worked on the problem.
That's where vertical partitioning came in.
Think of vertical partitioning as reorganizing your wardrobe. Instead of having one big pile of mess, you split things into separate sections. In database terms, it means moving certain tables to separate databases.
For Figma, vertical partitioning was a lifesaver. It allowed them to move high-traffic, related tables like those for “Figma Files” and “Organizations” into their separate databases. This provided some much-needed breathing room.
To identify the tables for partitioning, Figma considered two factors:
Impact: Moving the tables should move a significant portion of the workload.
Isolation: The tables should not be strongly connected to other tables.
For measuring impact, they looked at average active sessions (AAS) for queries. This stat describes the average number of active threads dedicated to a given query at a certain point in time.
Measuring isolation was a little more tricky. They used runtime validators that hooked into ActiveRecord, their Ruby ORM. The validators sent production query and transaction information to Snowflake for analysis, helping them identify tables that were ideal for partitioning based on query patterns and table relationships.
Once the tables were identified, Figma needed to migrate them between databases without downtime. They set the following goals for their migration solution:
Limit potential availability impact to less than 1 minute.
Automate the procedure so it is easily repeatable.
Have the ability to undo a recent partition.
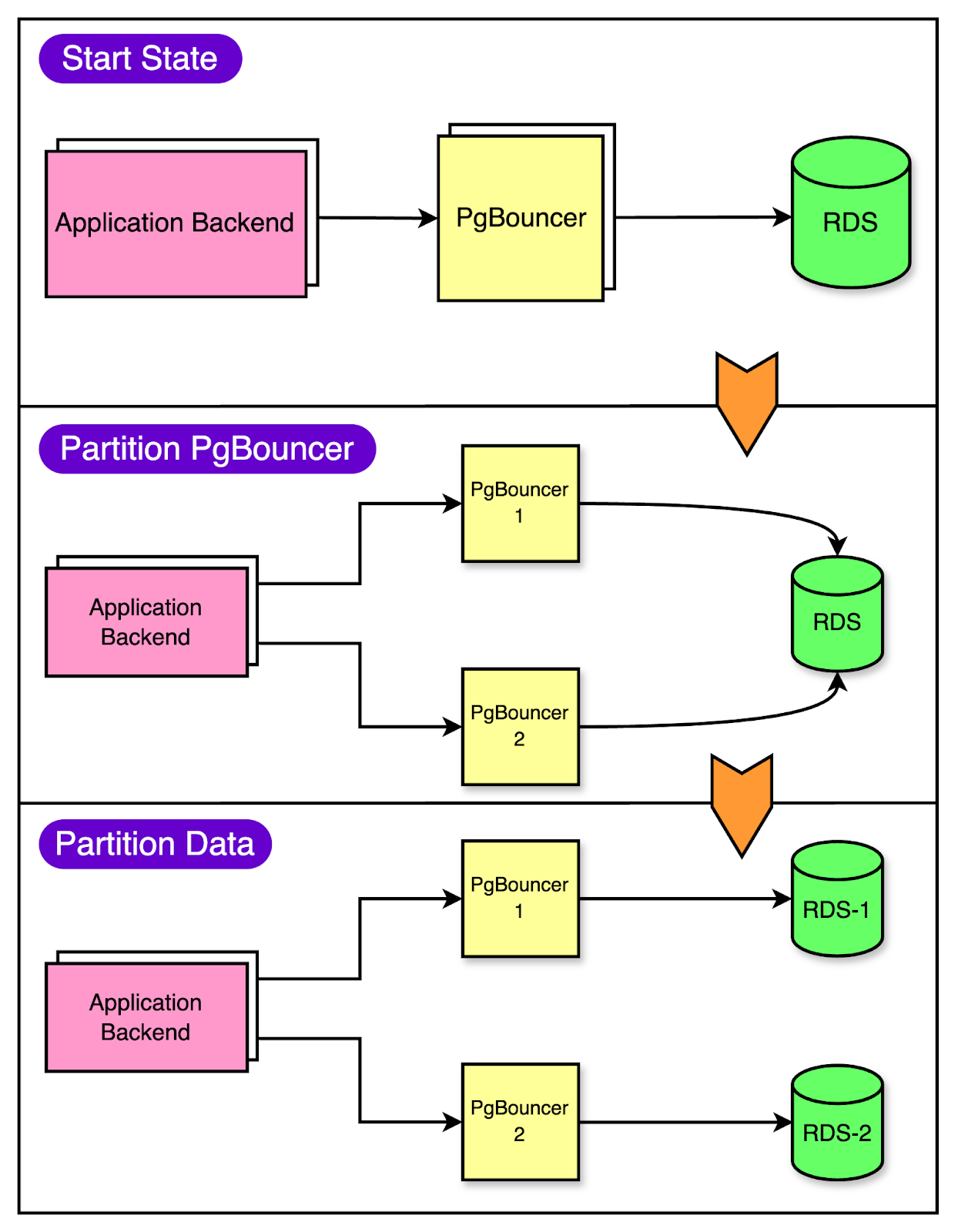
Since they couldn’t find a pre-built solution that could meet these requirements, Figma built an in-house solution. At a high level, it worked as follows:
Prepared client applications to query from multiple database partitions.
Replicated tables from the original database to a new database until the replication lag was near 0.
Paused activity on the original database.
Waited for databases to synchronize.
Rerouted query traffic to the new database.
Resumed activity.
To make the migration to partitioned databases smoother, they created separate PgBouncer services to split the traffic virtually. Security groups were implemented to ensure that only PgBouncers could directly access the database.
Partitioning the PgBouncer layer first gave some cushion to the clients to route the queries incorrectly since all PgBouncer instances initially had the same target database. During this time, the team could also detect the routing mismatches and make the necessary corrections.
The below diagram shows this process of migration.
Latest articles
If you’re not a paid subscriber, here’s what you missed.
To receive all the full articles and support ByteByteGo, consider subscribing:
Implementing Replication
Data replication is a great way to scale the read operations for your database. When it came to replicating data for vertical partitioning, Figma had two options in Postgres: streaming replication or logical replication.
They chose logical replication for 3 main reasons:
Logical replication allowed them to port over a subset of tables so that they could start with a much smaller storage footprint in the destination database.
It enabled them to replicate data into a database running a different Postgres major version.
Lastly, it allowed them to set up reverse replication to roll back the operation if needed.
However, logical replication was slow. The initial data copy could take days or even weeks to complete.
Figma desperately wanted to avoid this lengthy process, not only to minimize the window for replication failure but also to reduce the cost of restarting if something went wrong.
But what made the process so slow?
The culprit was how Postgres maintains indexes in the destination database. While the replication process copies rows in bulk, it also updates the indexes one row at a time. By removing indexes in the destination database and rebuilding them after the data copy, Figma reduced the copy time to a matter of hours.
Need for Horizontal Scaling
As Figma's user base and feature set grew, so did the demands on their databases.
Despite their best efforts, vertical partitioning had limitations, especially for Figma’s largest tables. Some tables contained several terabytes of data and billions of rows, making them too large for a single database.
A couple of problems were especially prominent:
Postgres Vacuum Issue: Vacuuming is an essential background process in Postgres that reclaims storage occupied by deleted or obsolete rows. Without regular vacuuming, the database would eventually run out of transaction IDs and grind to a halt. However, vacuuming large tables can be resource-intensive and cause performance issues and downtime.
Max IO Operations Per Second: Figma’s highest write tables were growing so quickly that they would soon exceed the max IOPS limit of Amazon’s RDS.
For a better perspective, imagine a library with a rapidly growing collection of books. Initially, the library might cope by adding more shelves (vertical partitioning). But eventually, the building itself will run out of space. No matter how efficiently you arrange the shelves, you can’t fit an infinite number of books in a single building. That’s when you need to start thinking about opening branch libraries.
This is the approach of horizontal sharding.
For Figma, horizontal sharding was a way to split large tables across multiple physical databases, allowing them to scale beyond the limits of a single machine.
The below diagram shows this approach:
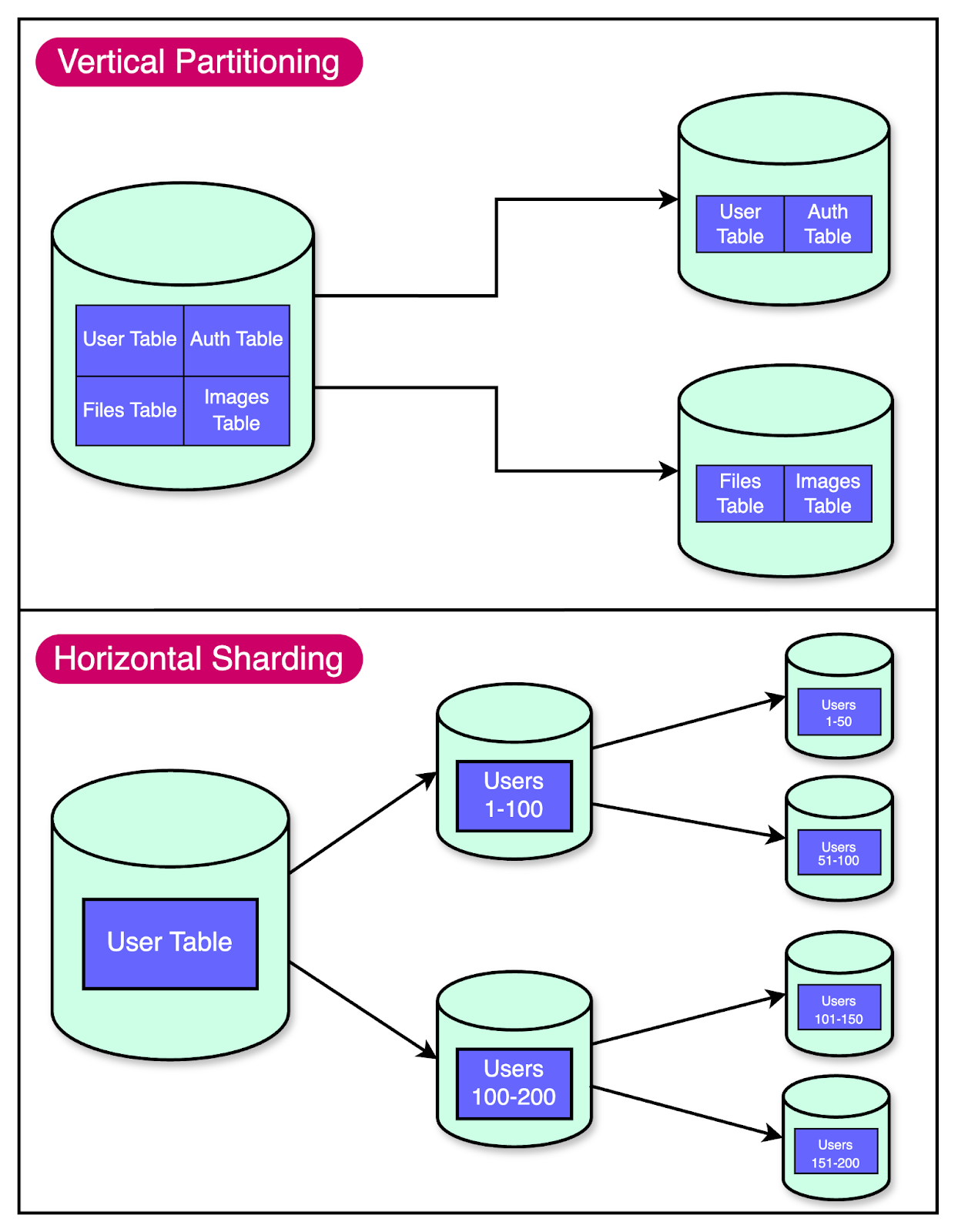
However, horizontal sharding is a complex process that comes with its own set of challenges:
Some SQL queries become inefficient to support.
Application code must be updated to route queries efficiently to the correct shard.
Schema changes must be coordinated across all shards.
Postgres can no longer enforce foreign keys and globally unique indexes.
Transactions span multiple shards, which means Postgres cannot be used to enforce transactionality.
Exploring Alternative Solutions
The engineering team at Figma evaluated alternative SQL options such as CockroachDB, TiDB, Spanner, and Vitess as well as NoSQL databases.
Eventually, however, they decided to build a horizontally sharded solution on top of their existing vertically partitioned RDS Postgres infrastructure.
There were multiple reasons for taking this decision:
They could leverage their existing expertise with RDS Postgres, which they had been running reliably for years.
They could tailor the solution to Figma’s specific needs, rather than adapting their application to fit a generic sharding solution.
In case of any issues, they could easily roll back to their unsharded Postgres databases.
They did not need to change their complex relational data model built on top of Postgres architecture to a new approach like NoSQL. This allowed the teams to continue building new features.
Figma’s Unique Sharding Implementation
Figma’s approach to horizontal sharding was tailored to their specific needs as well as the existing architecture. They made some unusual design choices that set their implementation apart from other common solutions.
Let’s look at the key components of Figma’s sharding approach:
Colos (Colocations) for Grouping Related Tables
Figma introduced the concept of “colos” or colocations, which are a group of related tables that share the same sharding key and physical sharding layout.
To create the colos, they selected a handful of sharding keys like UserId, FileId, or OrgID. Almost every table at Figma could be sharded using one of these keys.
This provides a friendly abstraction for developers to interact with horizontally sharded tables.
Tables within a colo support cross-table joins and full transactions when restricted to a single sharding key. Most application code already interacted with the database in a similar way, which minimized the work required by applications to make a table ready for horizontal sharding.
The below diagram shows the concept of colos:
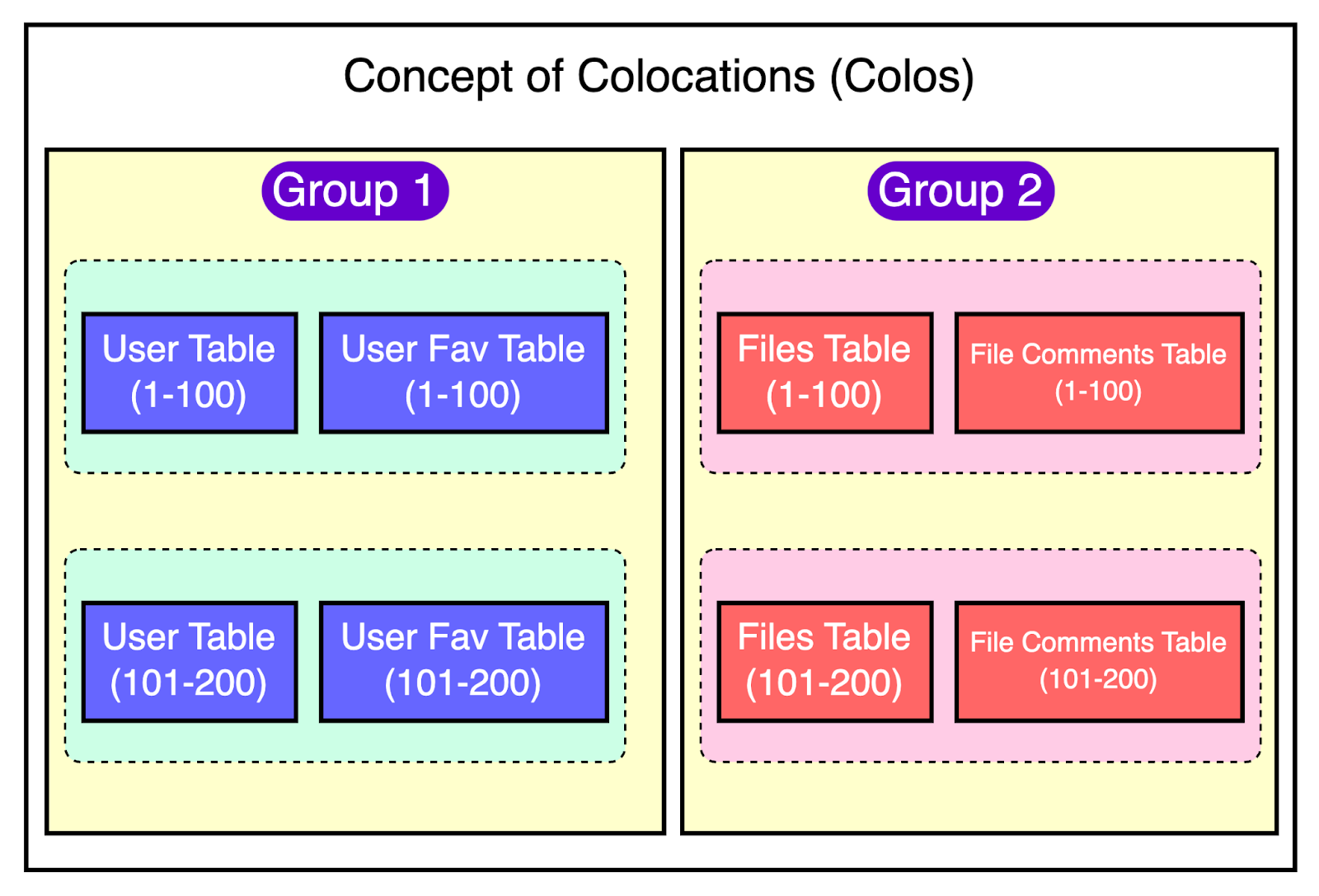
Logical Sharding vs Physical Sharding
Figma separated the concept of “logical sharding” at the application layer from “physical sharding” at the Postgres layer.
Logical sharding involves creating multiple views per table, each corresponding to a subset of data in a given shard. All reads and writes to the table are sent through these views, making the table appear horizontally sharded even though the data is physically located on a single database host.
This separation allowed Figma to decouple the two parts of their migration and implement them independently. They could perform a safer and lower-risk logical sharding rollout before executing the riskier distributed physical sharding.
Rolling back logical sharding was a simple configuration change, whereas rolling back physical shard operations would require more complex coordination to ensure data consistency.
DBProxy Query Engine for Routing and Query Execution
To support horizontal sharding, the Figma engineering team built a new service named DBProxy that sits between the application and connection pooling layers such as the PGBouncer.
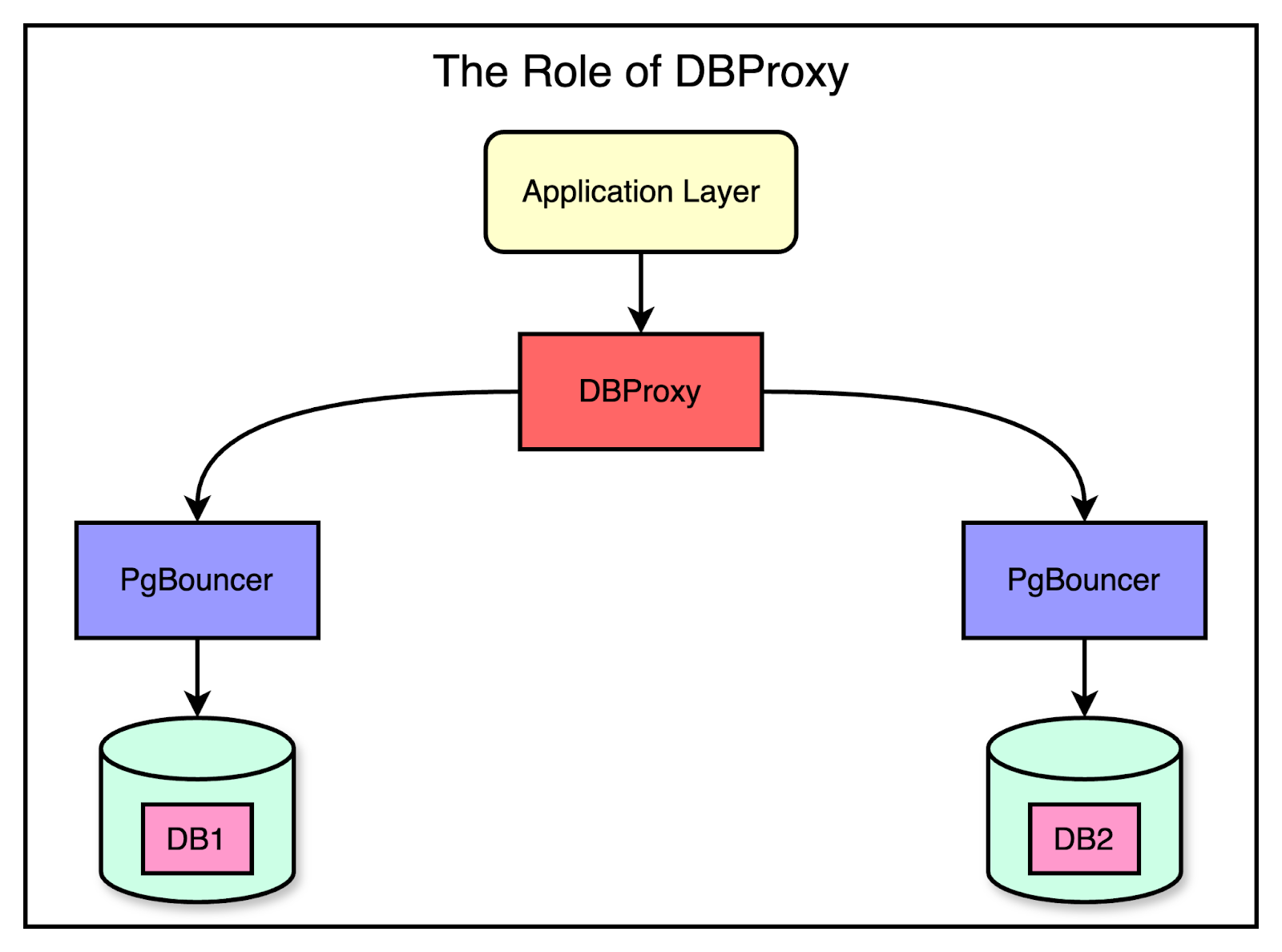
DBProxy includes a lightweight query engine capable of parsing and executing horizontally sharded queries. It consists of three main components:
A query parser that reads the SQL sent by the application and transforms it into an Abstract Syntax Tree (AST).
A logical planner that parses the AST, extracts the query type (insert, update, etc.), and logical shard IDs from the query plan.
A physical planner that maps the query from logical shard IDs to physical databases and rewrites queries to execute on the appropriate physical shard.
The below diagram shows the practical use of these three components within the query processing workflow.
There are always trade-offs when it comes to queries in a horizontally sharded world. Queries for a single shard key are relatively easy to implement. The query engine just needs to extract the shard key and route the query to the appropriate physical database.
However, if the query does not contain a sharding key, the query engine has to perform a more complex “scatter-gather” operation. This operation is similar to a hide-and-seek game where you send the query to every shard (scatter), and then piece together answers from each shard (gather).
The below diagram shows how single-shard queries work when compared to scatter-gather queries.
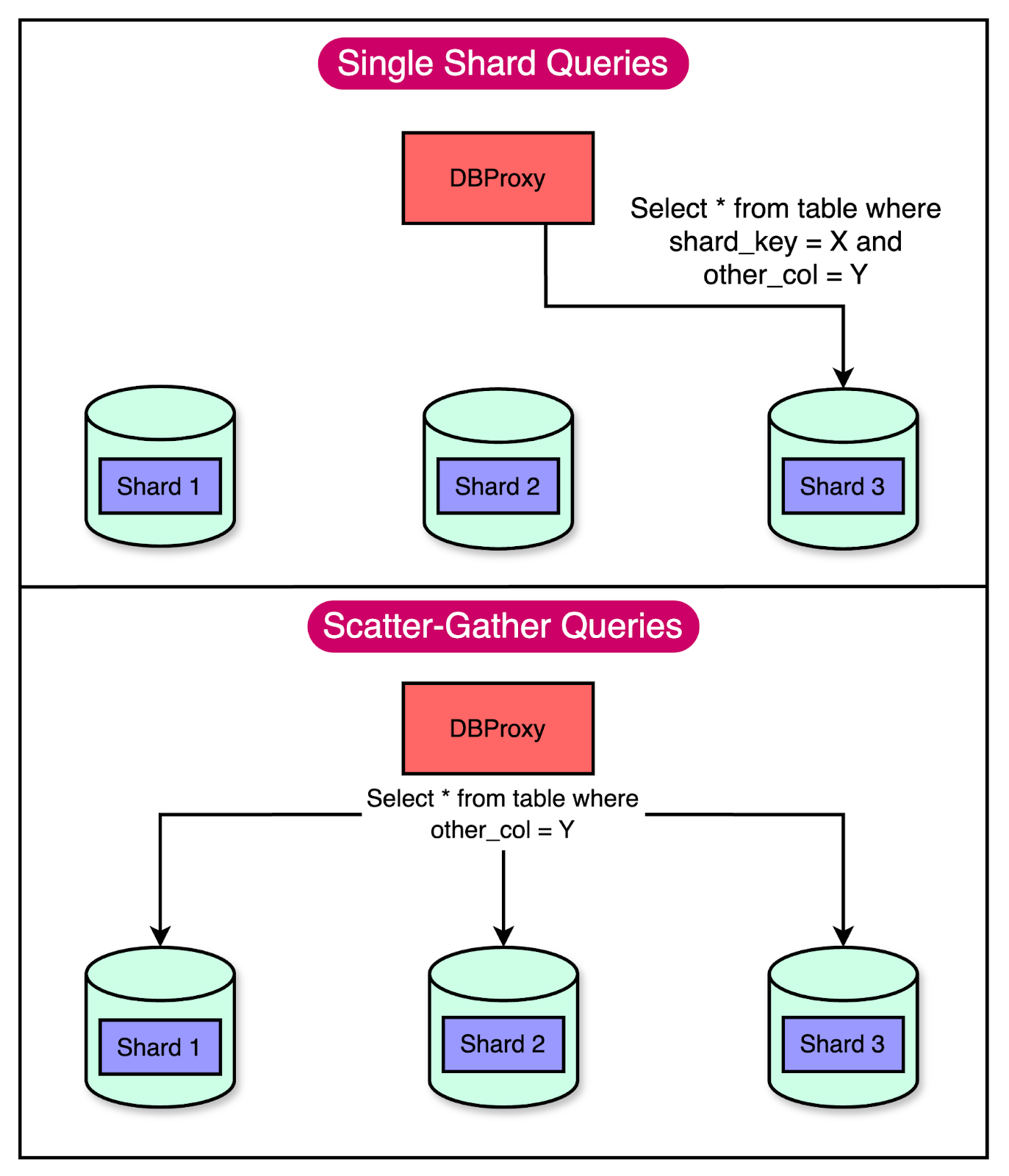
As you can see, this increases the load on the database, and having too many scatter-gather queries can hurt horizontal scalability.
To manage things better, DBProxy handles load-shedding, transaction support, database topology management, and improved observability.
Shadow Application Readiness Framework
Figma added a “shadow application readiness” framework capable of predicting how live production traffic would behave under different potential sharding keys.
This framework helped them keep the DBProxy simple while reducing the work required for the application developers in rewriting unsupported queries.
All the queries and associated plans are logged to a Snowflake database, where they can run offline analysis. Based on the data collected, they were able to pick a query language that supported the most common 90% of queries while avoiding the worst-case complexity in the query engine.
Conclusion
Figma’s infrastructure team shipped their first horizontally sharded table in September 2023, marking a significant milestone in their database scaling journey.
It was a successful implementation with minimal impact on availability. Also, the team observed no regressions in latency or availability after the sharding operation.
Figma’s ultimate goal is to horizontally shard every table in their database and achieve near-infinite scalability. They have identified several challenges that need to be solved such as:
Supporting horizontally sharded schema updates
Generating globally unique IDs for horizontally sharded primary keys
Implementing atomic cross-shard transactions for business-critical use cases.
Enabling distributed globally unique indexes.
Developing an ORM model to improve developer velocity
Automatic reshard operations to enable shard splits at the click of a button.
Lastly, after achieving a sufficient runway, they also plan to reassess their current approach of using in-house RDS horizontal sharding versus switching to an open-source or managed alternative in the future.
References:
SPONSOR US
Get your product in front of more than 500,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing hi@bytebytego.com.
© 2024 ByteByteGo
548 Market Street PMB 72296, San Francisco, CA 94104
Unsubscribe
by "ByteByteGo" <bytebytego@substack.com> - 11:36 - 7 May 2024 -
Do you know what inflation is?
On Point
A new McKinsey Explainer Brought to you by Liz Hilton Segel, chief client officer and managing partner, global industry practices, & Homayoun Hatami, managing partner, global client capabilities
•
The upside of inflation. Inflation, a broad rise in the prices of goods and services across the economy over time, has been top of mind for many. High inflation can erode purchasing power for consumers and businesses. But inflation isn’t all bad. In a healthy economy, annual inflation is usually about two percentage points. That can stimulate spending and boost economies. Inflation may be declining in many areas, but there’s still uncertainty ahead: without a surge in productivity, Western economies may be headed for a period of sustained inflation or major economic reset, McKinsey Global Institute chair Sven Smit and coauthors find.
•
Causes of inflation. One type of short-term inflation is demand-pull inflation, which occurs when demand for goods and services exceeds the economy’s ability to produce them. For example, when demand for new cars recovered more quickly than anticipated from its sharp dip at the start of the COVID-19 pandemic, an intervening shortage in the supply of semiconductors made it hard for the auto industry to keep up with this renewed demand, McKinsey senior partner Ondrej Burkacky and coauthors share. See our recent McKinsey Explainer “What is inflation?” to explore five steps companies can take to address inflation.
—Edited by Belinda Yu, editor, Atlanta
This email contains information about McKinsey's research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this newsletter because you subscribed to the Only McKinsey newsletter, formerly called On Point.
Copyright © 2024 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "Only McKinsey" <publishing@email.mckinsey.com> - 01:06 - 7 May 2024 -
Are you making the most of the cloud? A leader’s guide
The sky’s the limit Brought to you by Liz Hilton Segel, chief client officer and managing partner, global industry practices, & Homayoun Hatami, managing partner, global client capabilities
The tale of cloud computing follows a familiar plotline. As with many other new technologies, there’s lots of excitement about the potential value to gain and then lots of growing pains and entrenched mindsets that make adoption feel more than arduous. But 15 years into the journey, cloud seems to be at an inflection point. McKinsey research projects that cloud could generate up to $3 trillion in value by 2030. Generative AI (gen AI) also has the potential to accelerate cloud use, and the returns a company sees from it, in unprecedented ways. This week, we look at cloud’s growing upsides and how companies can make good on its promise.
Cloud’s potential to transform a business isn’t unique to one industry or region. Still, companies in different geographies face varying conditions and obstacles. McKinsey’s Bernhard Mühlreiter and coauthors look closely at the state of cloud in Europe. There, adoption rates and ambitions are high, while efforts to scale cloud leave room for improvement. So far, European companies have tended to pursue IT-led or IT-focused migrations to the cloud and measure the impact in IT-specific terms. Yet the real value from cloud, in Europe and beyond, comes from opportunities to increase revenue and save costs in a company’s business operations. How companies measure cloud’s impact matters, too. Rather than migrating as many workloads to the cloud as possible, Mühlreiter and other experts stress the importance of focusing on ROI and being intentional about why and where in the business cloud is adopted.
That’s how many percentage points of incremental ROI could be added to a company’s cloud program if it’s also using gen AI. According to senior partner William Forrest and colleagues, the adoption of both gen AI and cloud technologies is mutually beneficial and potentially transformative. To name a few benefits: cloud can support the complex scaling up of gen AI initiatives across an enterprise, just as gen AI capabilities can speed up the cloud migration process. Other gen AI–related advantages include reduced migration costs and higher productivity for development and infrastructure teams that are working on cloud.
That’s Mark Oh, director of infrastructure and user services group at the US Centers for Medicare & Medicaid Services (CMS), on the importance of a people-centered move to the cloud. Oh, along with Rajiv Uppal, chief information officer (CIO) at CMS and the incoming CIO of the Internal Revenue Service, spoke with senior partner Naufal Khan and colleagues about the agency’s cloud migration and why it was important to understand the business, and the people running it, every step of the way. One tactic for achieving broad buy-in was enabling change rather than mandating it. “A lot of the success can be attributed to the ‘community of practice’ we established, where we involved the entire stakeholder community to help shape solutions,” Uppal says. “This community was instrumental in sharing best practices so we could all benefit.”
Even with all of the value cloud promises, the challenges to developing a successful program persist. In an interview with The McKinsey Podcast, McKinsey’s Mark Gu and James Kaplan describe the key components of cloud success that many firms have yet to address: identifying the biggest sources of business value, establishing foundational capabilities, and reimagining the technology operating model and skill needs. As with other types of tech, the business case for cloud can be complicated. “In many cases, the benefits and the investments are happening in two different parts of the income statement or the organization,” Kaplan says. But companies (and leaders) must be patient in their quest for cloud-based value, which goes far beyond cost savings. “You can’t make the case on IT cost by itself,” according to Kaplan. “The reason you go to cloud is because of the business value it enables, through agility, scalability, innovation, and flexibility.”
What does cloud technology share with its meteorological cousin, the polar stratospheric cloud (or “PSC” for short)? Both are invisible, for starters, and both are major players in the planet’s climate change story. Cloud technology has the potential to accelerate the implementation of critical decarbonization initiatives. On the other hand, largely imperceptible PSCs have formed at the Earth’s poles, contributing to their warming more quickly than climate models can account for. Scientists say that learning more about how PSCs and other cloud types influence these trends will be critical to the field of climate science. So, too, could the use of cloud-based tools such as AI and machine learning.
Lead by laying a foundation for cloud success.
— Edited by Daniella Seiler, executive editor, Washington, DC
Share these insights
Did you enjoy this newsletter? Forward it to colleagues and friends so they can subscribe too. Was this issue forwarded to you? Sign up for it and sample our 40+ other free email subscriptions here.
This email contains information about McKinsey’s research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this email because you subscribed to the Leading Off newsletter.
Copyright © 2024 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "McKinsey Leading Off" <publishing@email.mckinsey.com> - 04:25 - 6 May 2024 -
The benefits of strengthening cross-tenure nurse relationships
On Point
Closing the experience gap Brought to you by Liz Hilton Segel, chief client officer and managing partner, global industry practices, & Homayoun Hatami, managing partner, global client capabilities
•
Career continuum complexities. Nurses are still reeling from the aftershocks of the COVID-19 pandemic, which exacerbated existing challenges in healthcare delivery. Healthcare organizations have been trying to better understand how to attract nurses to the workforce and improve retention. There’s been considerable attention given to the four generations in the workplace, but when it comes to nursing, tenure adds a dimension to the discussion. It may be one of the more defining characteristics of employee experience, point out McKinsey senior partner Gretchen Berlin and coauthors.
—Edited by Querida Anderson, senior editor, New York
This email contains information about McKinsey's research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this newsletter because you subscribed to the Only McKinsey newsletter, formerly called On Point.
Copyright © 2024 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "Only McKinsey" <publishing@email.mckinsey.com> - 01:18 - 6 May 2024 -
The week in charts
The Week in Charts
Aircraft backlogs, real estate deal volume, and more Share these insights
Did you enjoy this newsletter? Forward it to colleagues and friends so they can subscribe too. Was this issue forwarded to you? Sign up for it and sample our 40+ other free email subscriptions here.
This email contains information about McKinsey's research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this email because you subscribed to The Week in Charts newsletter.
Copyright © 2024 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "McKinsey Week in Charts" <publishing@email.mckinsey.com> - 03:38 - 4 May 2024