Archives
- By thread 5224
-
By date
- June 2021 10
- July 2021 6
- August 2021 20
- September 2021 21
- October 2021 48
- November 2021 40
- December 2021 23
- January 2022 46
- February 2022 80
- March 2022 109
- April 2022 100
- May 2022 97
- June 2022 105
- July 2022 82
- August 2022 95
- September 2022 103
- October 2022 117
- November 2022 115
- December 2022 102
- January 2023 88
- February 2023 90
- March 2023 116
- April 2023 97
- May 2023 159
- June 2023 145
- July 2023 120
- August 2023 90
- September 2023 102
- October 2023 106
- November 2023 100
- December 2023 74
- January 2024 75
- February 2024 75
- March 2024 78
- April 2024 74
- May 2024 108
- June 2024 98
- July 2024 116
- August 2024 134
- September 2024 130
- October 2024 141
- November 2024 171
- December 2024 115
- January 2025 216
- February 2025 140
- March 2025 220
- April 2025 233
- May 2025 239
- June 2025 303
- July 2025 36
-
EP129: The Ultimate Walkthrough of the Generative AI Landscape
EP129: The Ultimate Walkthrough of the Generative AI Landscape
This week’s system design refresher:͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ Forwarded this email? Subscribe here for moreThis week’s system design refresher:
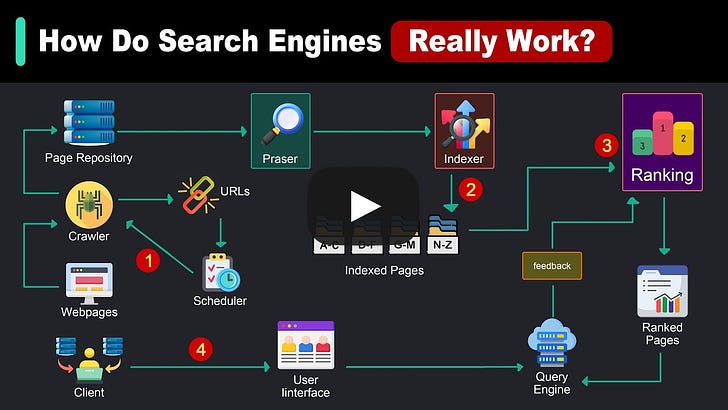
How Search Really Works (Youtube Video)
The Ultimate Walkthrough of the Generative AI Landscape
Cheatsheet on Relational Database Design
My Favorite 10 Soft Skill Books that Can Help You Become a Better Developer
SPONSOR US
How Search Really Works
The Ultimate Walkthrough of the Generative AI Landscape
Generative AI and LLMs are fast becoming a game-changer in the business world. Everyone wants to learn more about it.

The landscape covers the following points:
What is GenAI?
Foundational Models and LLMs
“Attention is All You Need” and its impact
GenAI vs Traditional AI
How to train a foundation model?
The GenAI Development Stack (LLMs, Frameworks, Programming Languages, etc.)
GenAI Applications
Designing a simple GenAI application
The AI Engineer Job Role
Over to you: What else would you add to the GenAI landscape?
Latest articles
If you’re not a paid subscriber, here’s what you missed.
To receive all the full articles and support ByteByteGo, consider subscribing:
Cheatsheet on Relational Database Design
A relational database is a type of database that organizes data into structured tables, also known as relations. These tables consist of rows (records) and columns (fields).

Some key points to know about Relational Database Design
SQL
SQL is the standard programming language used to interact with relational databases. It supports fundamental operations for data manipulation, data definition, and data control.Fundamental RDBMS Concepts
There are some fundamental RDBMS concepts such as table, row, column, primary key, foreign key, join, index, and view.Keys in Relational Databases
Different types of keys are as follows:
Primary Key: A column or combination of columns uniquely identifying each record in a table.
Surrogate Key: Artificial key generated by the database system or a globally unique identifier that has no inherent meaning to the data.
Foreign Key: A column or a combination of columns in one table that references the primary key of another table.Relation Types
Relationships between tables play a key role in defining how data is connected. Three main types of relationships are:One-to-One Relationship: A record in one table is associated with one record in another table.
One-to-Many Relationship: A record in one table is associated with multiple records in another table
Many-to-Many Relationship: Records in both tables can have multiple records in the other table.
Joins
Joins act as bridges, connecting different tables based on their relationship. They are extremely useful when you need to retrieve data from multiple tables. There are 3 main types of joins:Inner Join
Right Outer Join
Left Outer Join
Over to you: What else should you know about relational database design?
My Favorite 10 Soft Skill Books that Can Help You Become a Better Developer

Productivity & Personal Development
Deep Work by Cal Newport
Atomic Habits by James Clear
The Effective Executive by Peter Drucker
Communication Skills
Crucial Conversations by Kerry Patterson et al.
How to Win Friends and Influence People by Dale Carnegie
Leadership & Team Dynamics
Extreme Ownership by Jocko Willink and Leif Babin
The Five Dysfunctions of a Team by Patrick Lencioni
Start with Why by Simon Sinek
Design & Craftsmanship
The Clean Coder by Robert Martin
The Design of Everyday Things by Dan Norman
Over to you: What is your favorite book?
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com
Like
Comment
Restack
© 2024 ByteByteGo
548 Market Street PMB 72296, San Francisco, CA 94104
Unsubscribe

by "ByteByteGo" <bytebytego@substack.com> - 11:35 - 14 Sep 2024 -
Las reglas cambiantes de la salud organizacional
Además, abordar la integración de la IA generativa de manera holística
by "Destacados de McKinsey" <publishing@email.mckinsey.com> - 08:55 - 14 Sep 2024 -
Dear friend
I trust this message finds you well.
I am Jeffery, representing Hongocean, a trusted freight forwarding company based in China.
I'm excited to share with you our current market situation, which are highly competitive and designed to cater to your shipping needs. Please find the details below:
1. YT/SH/NB/XM to LA O/F:$4000/40HQ
2. YT/SH/NB/XM to NY O/F: $4100/40HQ
we can realeased the space to your supplier right now
Validity time is 20TH Sep 2024
Should you require any additional information, have queries, or wish to make a booking, please don't hesitate to reach out to me directly.
I look forward to the prospect of working with you.
by "Jeffery" <azemin88@cargofreightusaa.com> - 11:46 - 13 Sep 2024 -
Re: Need reliable agent in Indonesia
Dear Logistics partner,
This is Joy from GLA network. Hope this email finds you well!
Our team has invited you to attend our Thailand conference on Nov 22nd-25th as GLA member, I wonder whether your team is still interested in joining GLA Membership/GLA Conference?
Now we have increasing inquires to/from Indonesia, so it is urgent for us to find one more reliable partner in there to cooperate with our GLA members
For more details, please check it from our website: www.glafamily.com
Now we have special advertisement opportunity in Thailand conference:
Thank you.
Any interesting, keep us posted.
Conference register: http://www.glafamily.com/meeting/registration/Joy
Joy Jiang
GLA Overseas department
Mobile:
(86) 153 6164 8088
Email:
Company:
GLA Co.,Ltd
Website:
Address:
No. 2109, 21st Floor, HongChang, Plaza, No. 2001, Road Shenzhen, China
by "GLA Joy" <member321@glafamily.com> - 03:24 - 13 Sep 2024 -
How much value could generative AI agents deliver for enterprises?
Only McKinsey Perspectives
Opportunities with generative AI agents Brought to you by Alex Panas, global leader of industries, & Axel Karlsson, global leader of functional practices and growth platforms
Welcome to the latest edition of Only McKinsey Perspectives. We hope you find our insights useful. Let us know what you think at Alex_Panas@McKinsey.com and Axel_Karlsson@McKinsey.com.
—Alex and Axel
•
Generative AI agents. Generative AI (gen AI) agents are software entities that can plan and perform tasks or aid humans by delivering specific services on their behalf. They are well on the way to automating a wide range of tasks in many service functions while also improving service quality, McKinsey senior partners Jorge Amar and Lari Hämäläinen and partner Nicolai von Bismarck share. Gen AI agents hold the promise of accelerating workflow automation. And as such agents become more proficient, they could also improve customer satisfaction and generate revenue.
—Edited by Aarushi Jain, editor, Atlanta
This email contains information about McKinsey's research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this email because you subscribed to the Only McKinsey Perspectives newsletter, formerly known as Only McKinsey.
Copyright © 2024 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "Only McKinsey Perspectives" <publishing@email.mckinsey.com> - 01:47 - 13 Sep 2024 -
New: Manage HR contracts and documents in Remote!
New: Manage HR contracts and documents in Remote!


Hi MD,
Remote is all about bringing your HR data and processes into a unified platform, eliminating the need for extra tools, effort, and costs.
Now all HR Management users can easily create, send, sign, and store contracts and documents for their employees and contractors without the need for third-party software or manual messiness.
Whether it’s an offer letter for an operations manager, an NDA for a nurse, or an equity agreement for an engineer, you can handle every aspect from start to finish within Remote.
All the best,
Your team at Remote
Take the next step toward simplification
Talk with one of experts and delve into how Remote can specifically address your global HR challenges.







You received this email because you are subscribed to
Remote Resources from Remote Europe Holding B.V
Update your email preferences to choose the types of emails you receive.
Unsubscribe from all future emailsRemote Europe Holding B.V
Copyright © 2024 Remote Europe Holding B.V All rights reserved.
Kraijenhoffstraat 137A 1018RG Amsterdam The Netherlands
by "Remote" <hello@remote-comms.com> - 10:16 - 12 Sep 2024 -
ERPNext Asset Management Confirmation
Hi MD Abul Khayer, Thank you for registering for ERPNext Asset Management. You can find information about this webinar below. ERPNext Asset Management Date & Time Sep 25, 2024 04:30 PM Bangkok Webinar ID 878 7735 2988 Add to:  Google Calendar
Google Calendar
 Outlook Calendar(.ICS)
Outlook Calendar(.ICS)
 Yahoo Calendar
Yahoo Calendar
To edit or cancel your registration details, click here. You can cancel your registration before Sep 25, 2024 04:30 PM. Please submit any questions to: revenue-team@frappe.io Thank you! WAYS TO JOIN THIS WEBINAR - Join from PC, Mac, iPad, or Android
If the button above does not work, paste this into your browser: https://us02web.zoom.us/w/87877352988?tk=1N51-hTt-hW9Y2WjNRKyuOFigsMlTTsOi281NYInwig.DQcAAAAUdeX-HBZ3ZEFWaGZOM1RKZTZ0RFA5X2x1dmd3AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA&uuid=WN_yPEAy72ZRiGIqTJvi-15Rw To keep this webinar secure, do not share this link publicly. - Join via audio
US: +17193594580,,87877352988# or +19292056099,,87877352988# Or, dial: US: +1 719 359 4580 or +1 929 205 6099 or +1 253 205 0468 or +1 253 215 8782 or +1 301 715 8592 or +1 305 224 1968 or +1 309 205 3325 or +1 312 626 6799 or +1 346 248 7799 or +1 360 209 5623 or +1 386 347 5053 or +1 507 473 4847 or +1 564 217 2000 or +1 646 931 3860 or +1 669 444 9171 or +1 669 900 6833 or +1 689 278 1000
More International numbersWebinar ID: 878 7735 2988 


+1.888.799.9666 Copyright ©2024 Zoom Video Communications, Inc.
Visit Zoom.us
55 Almaden Blvd
San Jose, CA 95113
by "Zoom" <no-reply@zoom.us> - 10:03 - 12 Sep 2024 -
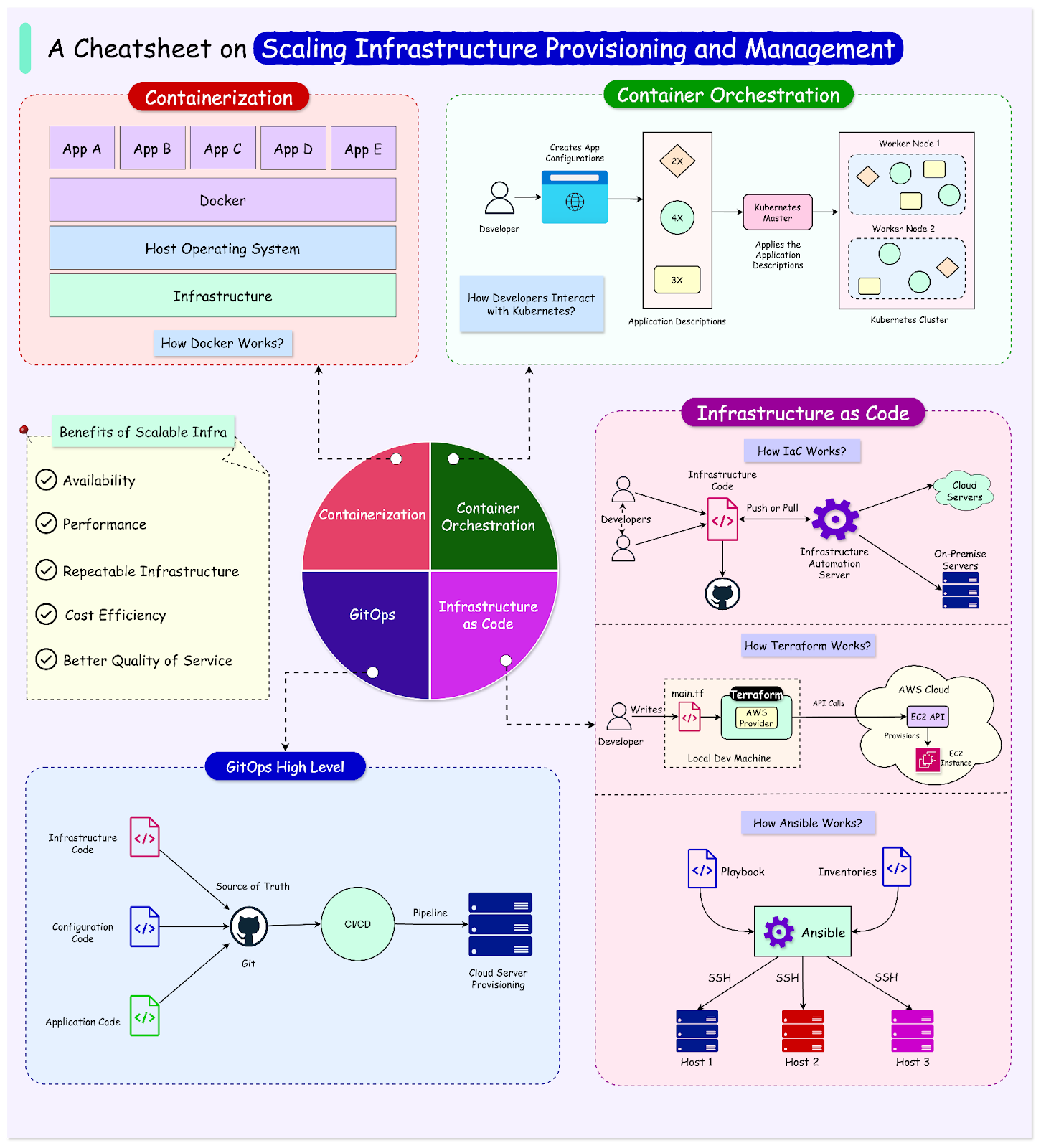
Infrastructure as Code
Infrastructure as Code
It is difficult to imagine modern businesses operating without a scalable process to provision and manage the infrastructure.͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ Forwarded this email? Subscribe here for moreLatest articles
If you’re not a subscriber, here’s what you missed this month.

To receive all the full articles and support ByteByteGo, consider subscribing:
It is difficult to imagine modern businesses operating without a scalable process to provision and manage the infrastructure.
Scalable infrastructure management is critical for businesses to adapt quickly to fluctuating workloads and user demands without compromising performance or incurring excessive costs. It offers several key benefits from multiple perspectives:
Availability: Scalable infrastructure management ensures that the application remains up and running at all times. It minimizes downtime and enables continuous service availability by dynamically adjusting resources based on demand.
Application Performance: Scalable infrastructure ensures that application performance is not affected by changes in workload. It allows for the seamless addition or removal of resources to maintain optimal performance levels, even during peak periods.
Better Quality of Service: By enhancing availability and application performance, scalable infrastructure management allows businesses to offer better service quality to their customers. This improved service quality can lead to higher customer satisfaction and loyalty.
Cost Efficiency: Scalable infrastructure management provides opportunities for cost optimization by scaling down resources during idle times.
Modern cloud-based infrastructure is particularly adept at scaling to support millions of users.
However, while it may seem effortless, managing scalability beyond simple autoscaling groups and load balancers can become complex.
As the codebase grows due to the involvement of numerous engineers, the potential for mistakes also increases. While minor issues like syntax errors or forgotten comments can be mitigated quickly, more serious mistakes such as leaked security keys, improper storage security settings, or open security groups can have disastrous consequences.
Therefore, it is crucial to formulate effective ways to manage and provision the infrastructure.
In this post, we’ll explore the most important ways of scaling the provisioning and management of modern application infrastructure.
What is Non-Scalable Infrastructure?...

Unlock this post for free, courtesy of Alex Xu.
© 2024 ByteByteGo
548 Market Street PMB 72296, San Francisco, CA 94104
Unsubscribe
by "ByteByteGo" <bytebytego@substack.com> - 11:35 - 12 Sep 2024 -
Activate your Mailchimp account
Activate your Mailchimp account
You're almost ready to get started! 
We're glad you're here,
info@learn.odoo.com.Activate Account (Just confirming you're you.)
© 2001-2024 Mailchimp® All Rights Reserved
Contact Us • Terms of Use • Privacy Policy
405 N. Angier Ave. NE, Atlanta, GA 30312 USA
by "Mailchimp Client Services" <clientservices@mailchimp.com> - 04:52 - 12 Sep 2024 -
Want to know what makes organizations healthy?
Only McKinsey Perspectives
New rules of organizational health Brought to you by Alex Panas, global leader of industries, & Axel Karlsson, global leader of functional practices and growth platforms
Welcome to the latest edition of Only McKinsey Perspectives. We hope you find our insights useful. Let us know what you think at Alex_Panas@McKinsey.com and Axel_Karlsson@McKinsey.com.
—Alex and Axel
•
Improved engagement. Earlier this year, engagement among US workers dipped to its lowest point in more than a decade, partially due to staffers feeling less connected to their organizations’ purpose, according to Gallup. Since then, the share of employees who are fully engaged has increased slightly to 32 percent in April through May, up from 30 percent in the first quarter of 2024, Inc. reports. Engagement improved the most among fully remote workers and those who are younger. [Inc.]
•
Practices that propel health. McKinsey’s Organizational Health Index (OHI) consistently shows that the best predictor of long-term performance is organizational health. For the latest OHI upgrade, McKinsey senior partner Aaron De Smet and coauthors spent the better part of a year collecting data and testing numerous hypotheses. A number of new practices now drive organizational health, including updating leadership styles, pursuing social responsibility, and using technology to create value.
—Edited by Belinda Yu, editor, Atlanta
This email contains information about McKinsey's research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this email because you subscribed to the Only McKinsey Perspectives newsletter, formerly known as Only McKinsey.
Copyright © 2024 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "Only McKinsey Perspectives" <publishing@email.mckinsey.com> - 01:45 - 12 Sep 2024 -
The CIO’s Guide to Data and Analytics Innovation
Workday
Read the guide. &n bsp; View as Web Page 
guide A better way to plan, execute, and analyze? Read Guide  How are you putting your data to work? As other companies struggle, you have a chance to double down on analytics—tapping into this valuable organizational asset in new and powerful ways.
How are you putting your data to work? As other companies struggle, you have a chance to double down on analytics—tapping into this valuable organizational asset in new and powerful ways.
Read this guide to learn how Workday, with one source for all your people and finance enterprise data, can help.Read Guide Follow Workday





©2007– 2024 Workday, Inc. • Unsubscribe
1 Wallich Street, #08-02 Guoco Tower | Singapore 078881, Singapore
by "Workday" <corp.email@workday.com> - 10:05 - 11 Sep 2024 -
Charting a path to the data- and AI-driven enterprise of 2030
7 priorities New from McKinsey Quarterly

This email contains information about McKinsey’s research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this email because you subscribed to our McKinsey Quarterly alert list.
Copyright © 2024 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "McKinsey & Company" <publishing@email.mckinsey.com> - 10:33 - 11 Sep 2024 -
Advantageous opportunity for info@learn.odoo.com.
Hello info,
I’m Noel Dosi, I know this is an unconventional way of reaching out but I hope I'm able to capture your attention because this is purposeful.
There is a business opportunity I'd like to introduce to you, do feel free to get back to me if you wish to know more or kindly ignore me if you feel this is not for you.
Appreciate your time thus far.
Best regards,
Noel Dosi
by "Dosi, N" <inquiry_response@agemarin-com.pw> - 06:18 - 11 Sep 2024 -
Birchwood Golf Club is one of the finest venues in the Warrington area
Birchwood Golf Club is one of the finest venues in the Warrington area
Hi there,
Birchwood Golf Club is one of the finest venues in the Warrington area and the opportunity to promote Your Telecoms Consultant on the My Caddie Golf Platform featuring this club does not come around often.
Golf enthusiasts often include local business owners professionals and high net worth individuals. This partnership allows you to showcase your produts and services and gain access to a wealth of potential new clients.
The partnership package we have put together for Telecommunication Companies includes the following unique benefits:
1) Complimentary golf for you to entertain clients, colleagues and guests.
2) Exposure on the members and visitors Android app.
3) Your branding on the flyovers on one of the holes on our Birchwood Golf Club web flyovers which is trackable and targeted to your demographic within the local area.
4) Providing you with exposure on the members and visitors iPhone app.
5) Exclusivity for your sector.
6) Access to our networking groups between all partners and plus ones.
All of this costs equivalent of just £26 per week for a 2-year partnership + £399 Artwork (one-off, optional) + VAT.
I am excited about discussing how this partnership can seamlessly integrate with your company's objectives and create new avenues for customer engagement. I'd be delighted to arrange a meeting to delve deeper into the details.
Best wishes,
Jack StevensAccount Manager0330 0436 463
We have sent this email to info@learn.odoo.com having found your company contact details online. If you don't want to get any more emails from us you can stop them here.
West 1 Group UK Limited, registered in England and Wales under company number 07574948. Our registered office is Unit 1 Airport West, Lancaster Way, Yeadon, Leeds, West Yorkshire, LS19 7ZA.
Disclaimer: Our app operates independently. While we provide authentic and accurate hole-by-hole guides, we do not have a direct association with Birchwood Golf Club or claim any endorsement from them. We aim to offer golfers a reliable guide as they navigate their favourite courses. As a value-add for our advertisers, we offer free tee times at Birchwood Golf Club which we procure as any customer would, directly from the venue. We also host networking events, which may be held a various local venues as well as online sessions.Furthermore, advertisers have the unique opportunity to be featured in our flyovers of each golf hole. All offerings are subject to availability and terms.
by "Jack Stevens" <jack@w1g.biz> - 03:24 - 11 Sep 2024 -
What do you know about deep learning?
Only McKinsey Perspectives
Deep learning’s business use cases Brought to you by Alex Panas, global leader of industries, & Axel Karlsson, global leader of functional practices and growth platforms
Welcome to the latest edition of Only McKinsey Perspectives. We hope you find our insights useful. Let us know what you think at Alex_Panas@McKinsey.com and Axel_Karlsson@McKinsey.com.
—Alex and Axel
•
How it works. Deep learning utilizes neural networks, inspired by neuron interactions in the human brain, to take in and process data through multiple neuron layers that identify complex data features, McKinsey Global Institute partner Michael Chui and coauthors share. Three types of neural networks are used in deep learning: feed-forward, convolutional, and recurrent. Each type has its own strengths in processing different types of data. Read our McKinsey Explainer on deep learning to uncover specific use cases of deep learning that cut across several business sectors.
—Edited by Jordyn Libow, editor, Atlanta
This email contains information about McKinsey's research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this email because you subscribed to the Only McKinsey Perspectives newsletter, formerly known as Only McKinsey.
Copyright © 2024 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "Only McKinsey Perspectives" <publishing@email.mckinsey.com> - 01:13 - 11 Sep 2024 -
Meet in Bangkok, Join for Success
Dear Logistics Partner,
This is Joy from GLA network, hope this email finds you well!Join us on our mission to make a difference from November 22 to November 25 !Location: Centara Grand & Bangkok Convention Centre at Central World, Bangkok, ThailandNow we have special advertisement opportunity provided:1. Advertisement Opportunity At Aisle Column & Backdrop2. Registration Advertisement Board3. One-on-One Meeting Area Advertisement4. Circular LED Screen SponsorshipDon't miss out! Register now at http://www.glafamily.com/meeting/registration/JoyPlease do not hesitate to reach out to me if you need more information.
Best regards,
Conference register: http://www.glafamily.com/meeting/registration/Joy

(Notice: If you would not like to receive email blush, please inform us timely. We will delete your data from the database)
Joy Jiang
Overseas Dept
M: +86 153 6164 8088;
( Whatsapp & Wechat)
A:GLA Co.,Limited
HongChang Plaza, 2001,Shennan Dong Road,Shenzhen
518000,China
by "GLA-Yakult" <member836@glafamily.com> - 12:09 - 11 Sep 2024 -
How Shopify Manages its Petabyte Scale MySQL Database
How Shopify Manages its Petabyte Scale MySQL Database
Generate Handwritten SDKs (Sponsored)͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ Forwarded this email? Subscribe here for moreGenerate Handwritten SDKs (Sponsored)

Invest hundreds of hours your team doesn't have in maintaining SDKs by hand or generate crappy SDKs that leave a bad taste in your users' mouths. That's two bad options. Fortunately, you can now use Speakeasy to generate ergonomic type-safe SDKs in over 10 languages. We've worked with language experts to create a generator that gets the details right. With Speakeasy you can build SDKs that your team is proud of.
Disclaimer: The details in this post have been derived from the article originally published on the Shopify Engineering Blog. All credit for the details about Shopify’s architecture goes to their engineering team. The links to the original articles are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
Shopify has revolutionized the e-commerce landscape by empowering small business owners to establish and grow their online presence.
With millions of merchants relying on their platform globally, Shopify’s infrastructure has evolved to handle the ever-increasing demands of their user base.
At the heart of Shopify’s infrastructure lies their MySQL database, which has grown to an impressive petabyte scale. Managing a database of this magnitude presents significant challenges, especially when considering Shopify’s commitment to providing a zero-downtime service.
Their direct customers are business owners, who depend on their online stores to generate revenue and sustain their livelihoods. Any downtime or service disruption can have severe consequences for these merchants, potentially leading to lost sales and damaged customer relationships.
In this post, we will look at how Shopify manages its critical MySQL database in three major areas:
Shard balancing with zero downtime
Maintaining read consistency with database replication
Database backup and restore
Each area is critical for operating a database at Shopify’s scale. For us, it’s a great opportunity to derive some key learnings.
Shard Balancing with Zero Downtime
Shopify runs a large fleet of MySQL database instances.
These instances are internally known as shards and are hosted within pods.
Each shard can store the data for one or more shops. See the diagram below where the MySQL shard within pod 1 contains the data for shop ABC and FOO.
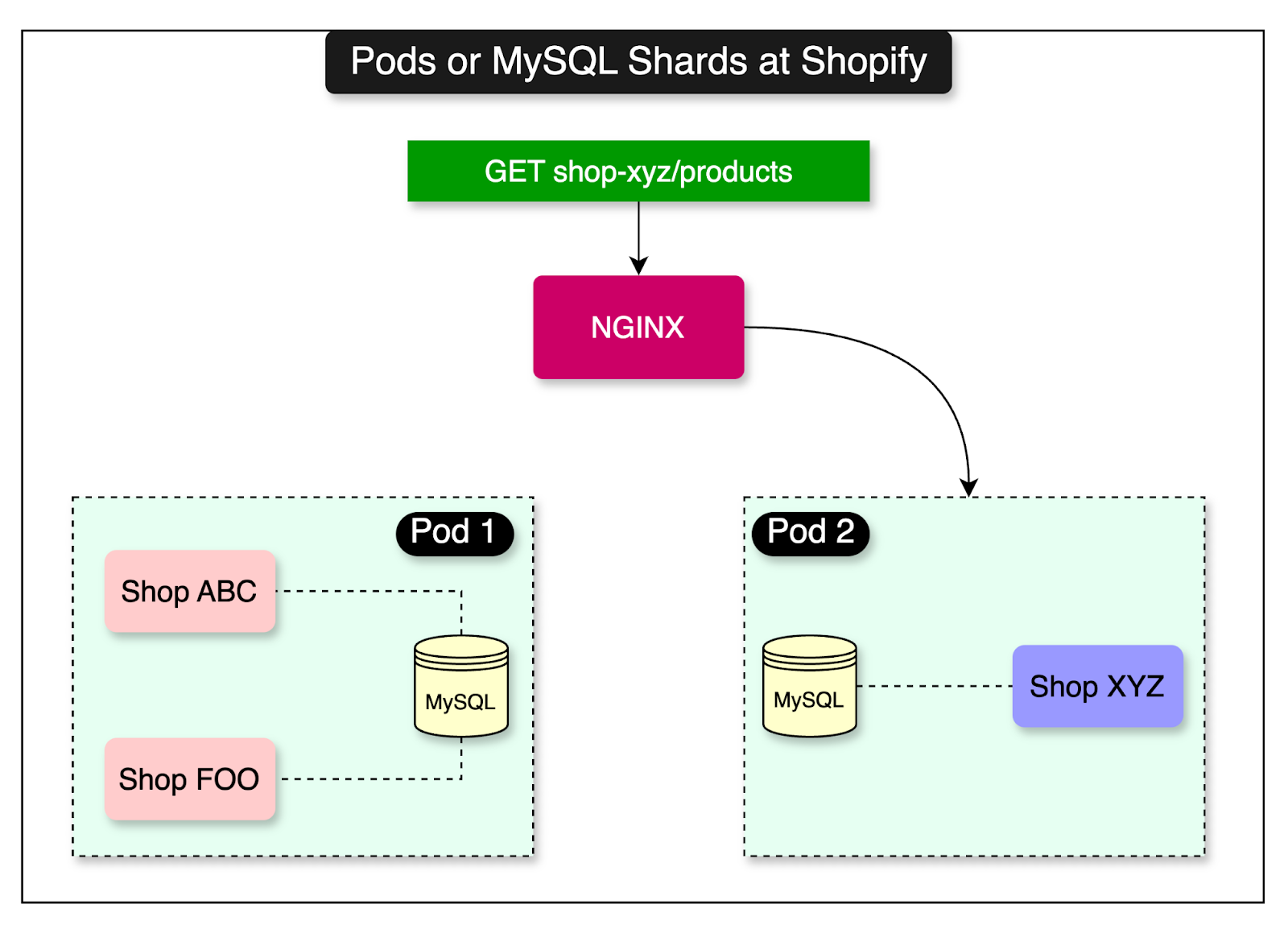
As traffic patterns for individual shops change, certain database shards become unbalanced in their resource utilization and load.
For example, if both shop ABC and shop FOO launch a mega sale simultaneously, it will result in a surge of traffic causing the database server to struggle. To deal with this, Shopify moves one of the shop’s data to another shard.
This process is known as shard balancing and it’s important for multiple reasons such as:
Mitigating the risk of database failure
Improving the productivity of the infrastructure
Guaranteeing that buyers can always access their favorite shops (no downtime)
An interesting takeaway from these reasons is how successful companies are focused on the customer experience even when dealing with largely technical concerns. A well-balanced shard is not directly visible to the end user. However, an unbalanced shard can indirectly impact the user experience negatively.
The second takeaway is a strong focus on cost. This is evident from the idea of improving the infrastructure’s productivity, which ultimately translates to savings.
Let’s now investigate how Shopify runs the shard rebalancing process.
The Concept of Pods
Shopify’s infrastructure is composed of many pods.
Each pod is an isolated instance of the core Shopify application and a MySQL database shard. There are other data stores such as Redis and Memcached but we are not concerned about them right now.
A pod houses the data for one or more shops. Web requests for shops arrive at the Nginx load balancer that consults a routing table and forwards the request to the correct pod based on the shop.
The concept of pods in Shopify’s case is quite similar to cells in a cell-based architecture.
Nginx acts as the cell router and the application layer is the same across all pods. It has access to a routing table that maps a shop to a particular shard. See the diagram below:
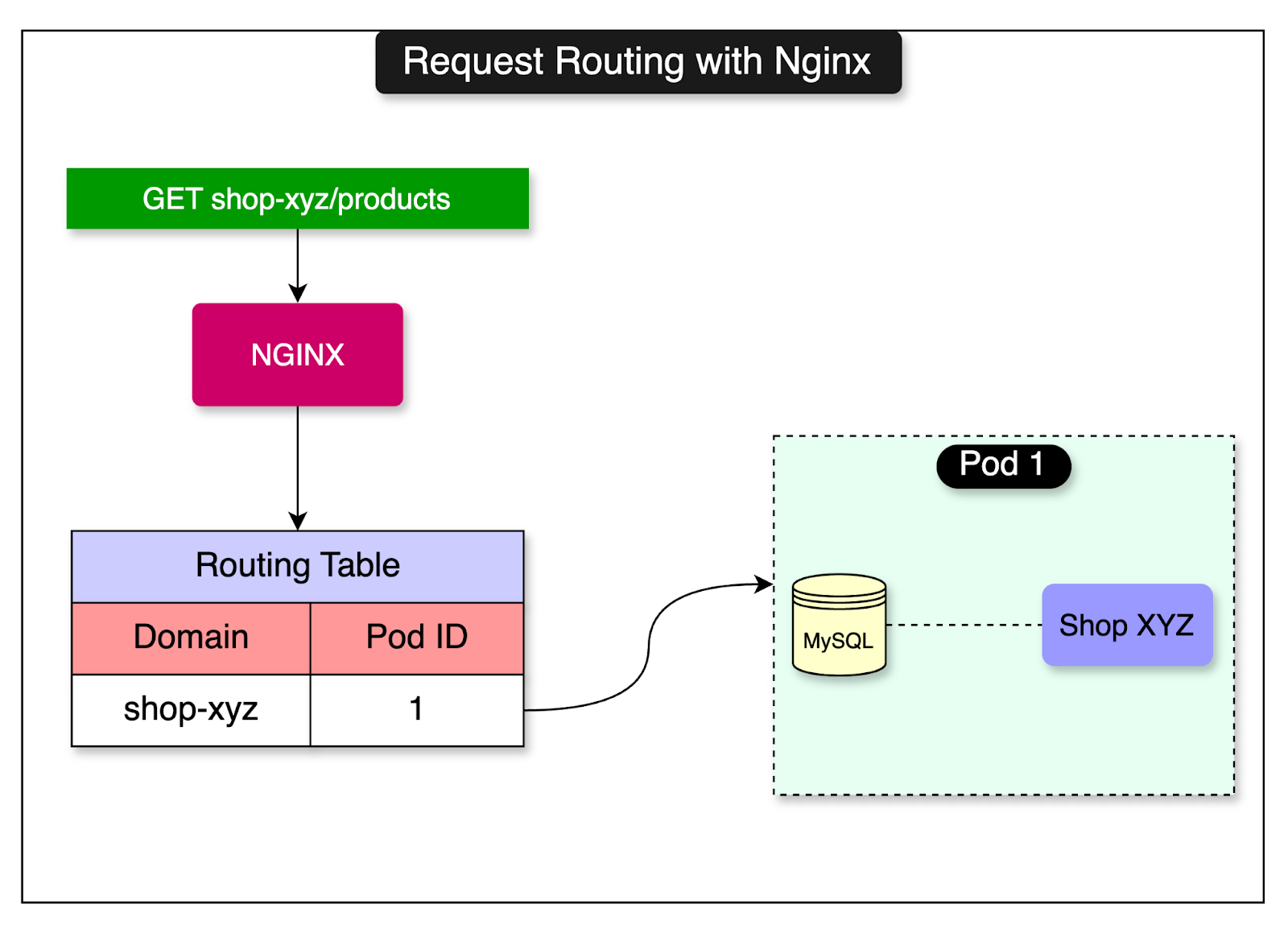
However, there is also a slight difference from cell-based architecture. The data in each pod varies depending on the shops hosted in a pod’s database instance.
As discussed earlier, each pod consists of a shard or a partition of the data.
Shopify’s data model works well with this topology since “shop” is an identifier for most tables. The shop acts as a natural partition between data belonging to different customers. They can attach a shop_id field to all shop-owned tables and use it as a sharding key.
The trouble starts when multiple shops living on the same pod become too big, resulting in higher database usage for some shards and lower usage for others. There are two problems when this happens:
The high-traffic shards are at an increased risk of failure due to over-utilization.
Shards with low database usage are not used productively resulting in a higher cost of operation.
The graph below highlights the variation in database usage per shard that developed over time as merchants came on board and grew. Each line represents the database usage for a unique shard on a given day.
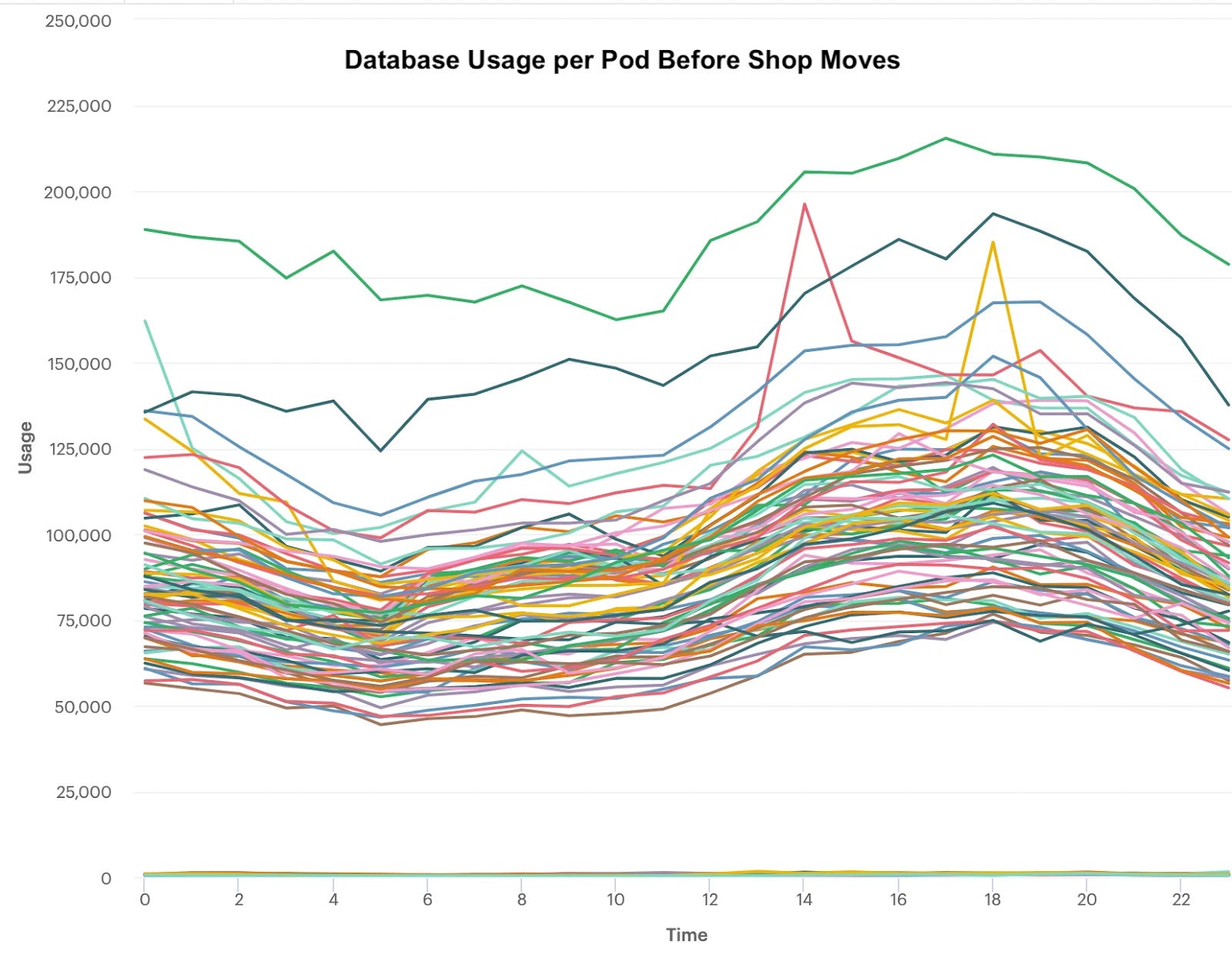
Source: Shopify Engineering Blog Balancing the Shards
Shopify faces two key challenges when it comes to rebalancing shards for optimal resource utilization:
Which shops should live on which shards?
How to move a shop from one shard to another with minimal downtime?
A simplistic approach of evenly distributing shops across shards is not effective due to the varying data sizes and resource requirements of each shop. Some shops may consume a disproportionate amount of resources, leading to an imbalanced shard utilization.
Instead, Shopify employs a data-driven approach to shard rebalancing.
They analyze historical database utilization and traffic data for each shard to identify usage patterns and classify shops based on their resource requirements. The analysis takes into account factors such as:
Shop size
Time required to move the shop
Occurrence of flash sales
Other relevant metrics
Nevertheless, this is an ongoing process that requires continuous optimization. Shopify also uses data analysis and machine learning algorithms to make better decisions.
Moving the Shop
Moving a shop from one shard to another is straightforward: select all records from all tables having the required shop_id and copy them to another MySQL shard.
However, there are three main constraints Shopify has to deal with:
Availability: The shop move must be performed online without visible downtime or interruption to the merchant’s storefront. In other words, customers should be able to interact with the storefront throughout the process.
Data Integrity: No data must be lost or corrupted during the transition. Also, all writes to the source database during the migration should also get copied.
Throughput: The shop move should be completed in a reasonable amount of time.
As expected, availability is critical. Shopify doesn’t want any visible downtime. While there’s a possibility for some downtime, the end user should not feel the impact.
Also, data integrity is crucial. Imagine there was a sale that got wiped out because the shop was moving from one shard to another. This would be unacceptable for the business owner.
As you can notice, each technical requirement is driven by strong business drivers.
Let us now look at each step in the process:
Phase One: Batch Copying and Tailing the Binlog
To perform the data migration, Shopify uses Ghostferry. It’s an in-house tool written in Go.
Later on, Shopify made it open-source. At present, Ghostferry’s GitHub repository has around 690+ stars.
Let’s assume that Pod 1 has two shops - ABC and FOO. Both shops decided to run a sale and expect a surge of traffic. Based on Shopify’s rebalancing strategy, Shop ABC should be moved from Pod 1 to Pod 2 for better resource utilization.
The diagram below shows the initial state where the traffic for Shop ABC is served by Pod 1. However, the copy process has started.
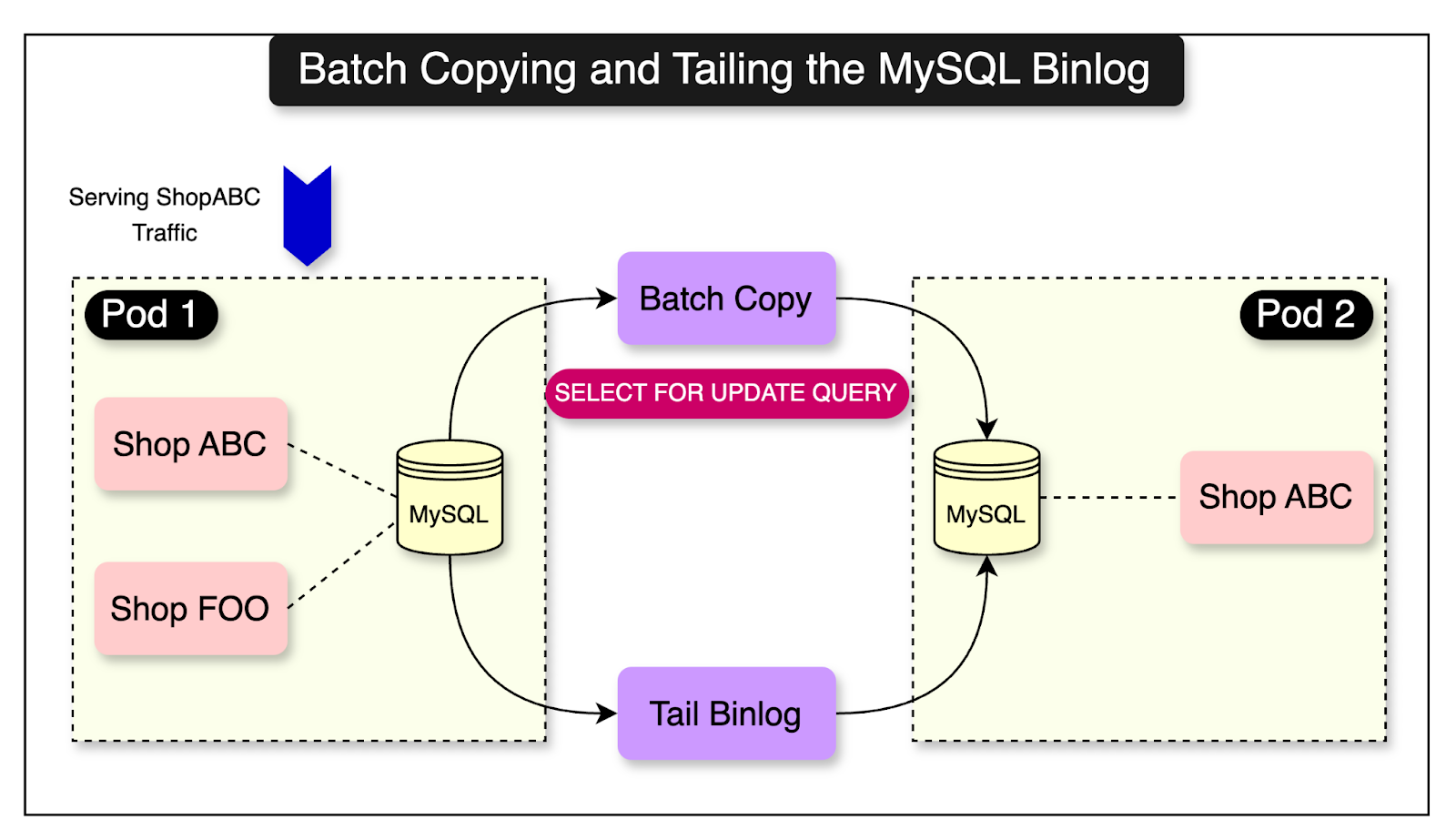
Ghostferry uses two main components to copy over data:
Batch copying
Tailing the binlog
In batch copying, Ghostferry iterates over the tables on the source shard, selects the relevant rows based on the shop’s ID, and writes these rows to the target shard. Each batch of writes is performed within a separate MySQL transaction to ensure data consistency.
To ensure that the rows being migrated are not modified on the source shard, Ghostferry uses MySQL’s SELECT…FOR UPDATE clause. This statement implements locking reads, which means that the selected rows from the source shard are write-locked for the duration of the transaction.
Ghostferry also starts tailing MySQL’s binlog to track and replicate changes that occur on the source shard to the target shard. The binlog serves as a sink for events that describe the modifications made to a database, making it the authoritative source of truth.
In essence, both batch copying and tailing the binlog take place together.
Phase Two: Entering Cutover
The only opportunity for downtime is during the cutover. Therefore, the cutover is designed to be a short process.
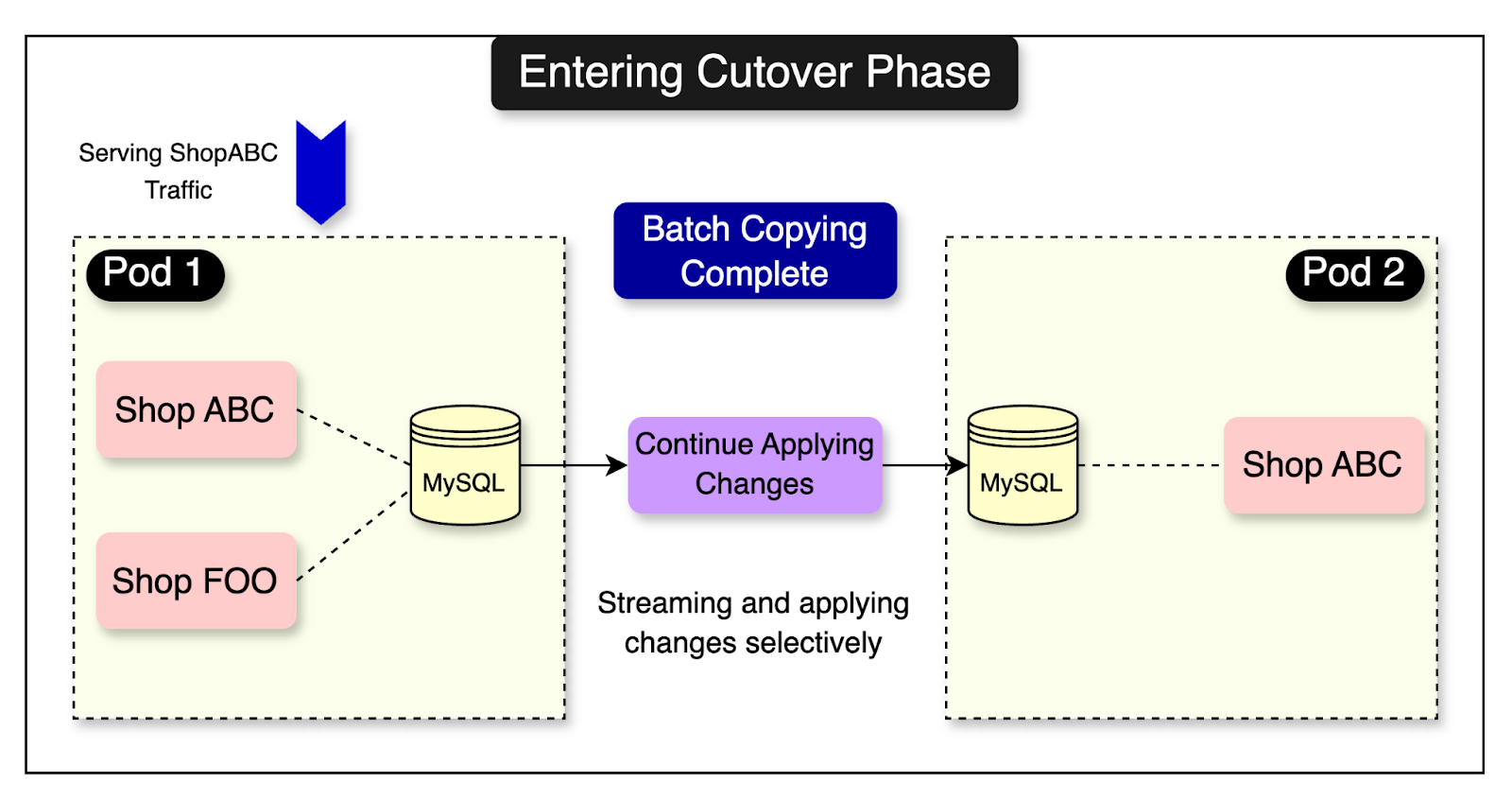
Here’s what happens during the cutover phase:
Ghostferry initiates the cutover phase when the queue of pending binlog events to be replayed on the target shard becomes small. The queue is considered small when the difference between the newly generated binlog events on the source shard and the events being replayed on the target shard is nearly real-time.
Once the cutover phase begins, all write operations on the source database are stopped. This ensures that no new binlog events are generated.
At this point, Ghostferry records the final binlog coordinate of the source database, which serves as the stopping coordinate.
Ghostferry then processes the remaining queue of binlog events until it reaches the stopping coordinate. When the stopping coordinate is reached, the copying process is complete, and the target shard is in sync with the source shard.
Phase Three: Switch Traffic and Prune Stale Data
In the last phase, the shop mover process updates the routing table to associate the shop with its new pod.
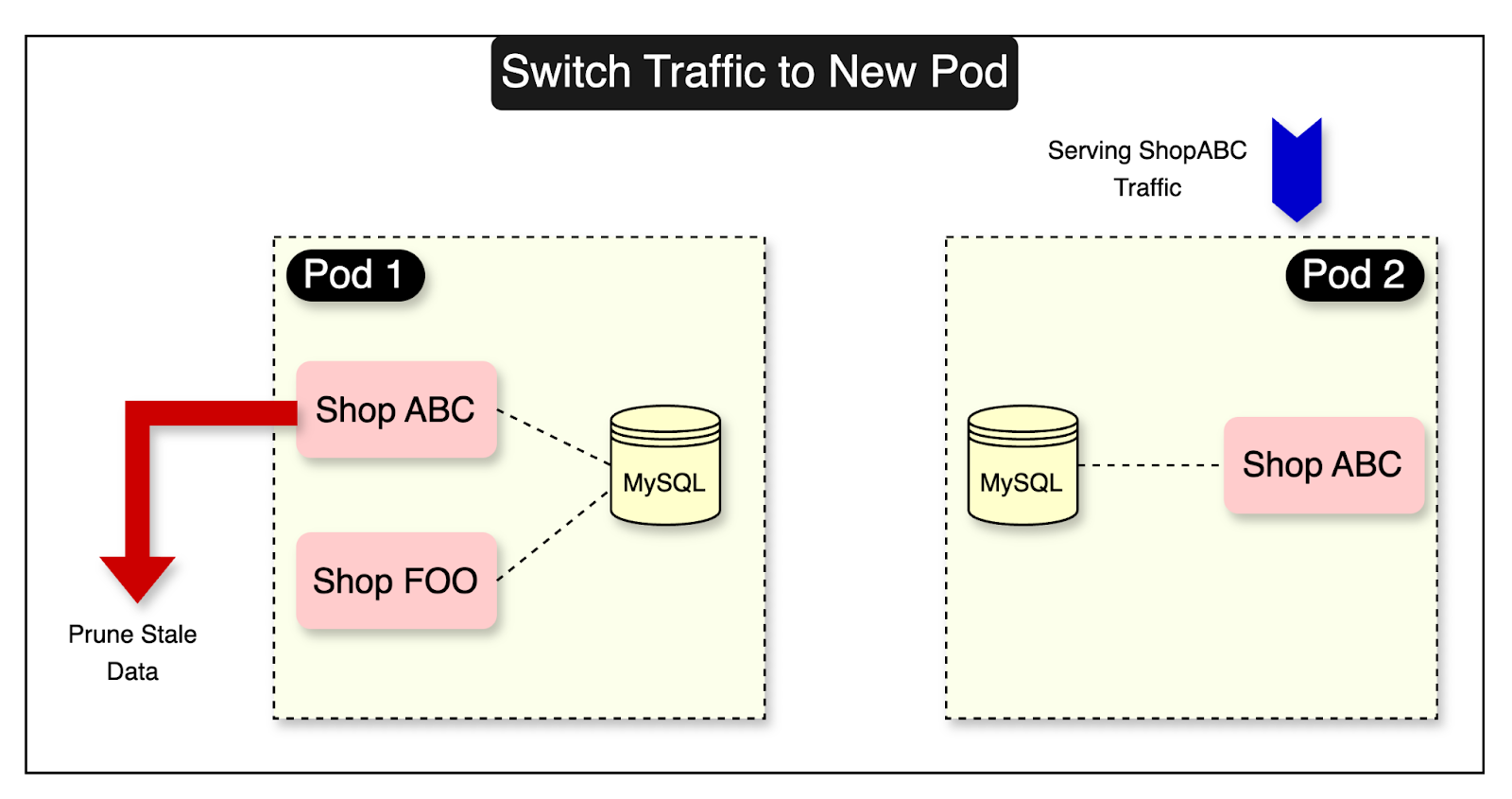
The shop is now served from the new pod. However, the old pod still contains the shop data.
They perform a verification to ensure that the movement is successful. If no issues are identified during the verification process, stale data of shop ABC on the old pod is deleted.
Read Consistency with Database Replication
The second major learning point from data management at Shopify’s scale is related to database replication.
Read replicas are copies of a primary database that are used to handle read-only queries. They help distribute the read workload across multiple servers, reducing the load on the primary database server. This allows the primary servers to be used for time-sensitive read/write operations.
An interesting point to note here is that read replicas don’t handle all the reads. Time-sensitive reads still go to the primary servers.
Why is this the case?
The unavoidable reason is the existence of replication lag.
Any database replication process will have some lag. The implication is that applications reading from a replica might end up reading stale data. However, this may not be acceptable for some specific reads. For example, a customer updating the profile information and not seeing the updates reflected on the profile page.
Also, reads are not always atomic. There can be a scenario where related pieces of data are assembled from the results of multiple queries.
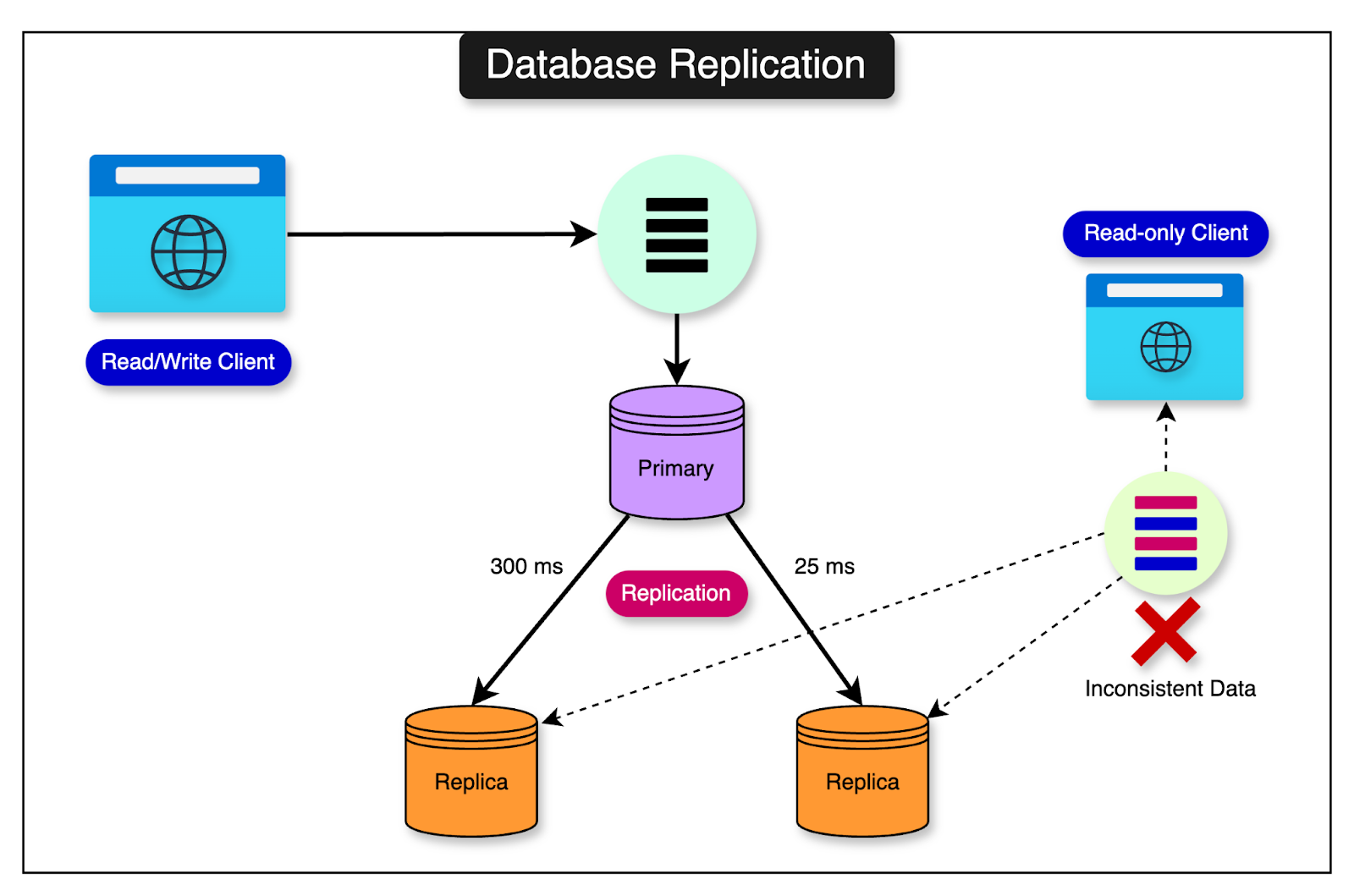
For example, consider the below sequence of events:
The customer places an order for two items: Item A and Item B.
The order processing system sends a query to read replica 1 to check the inventory for Item A.
At the same time, it sends another query to read replica 2 to check the inventory for Item B.
Imagine that between steps 2 and 3, the inventory for Item B gets updated on the master and the item is sold out. However, replica 2 has a higher replication lag compared to replica 1. This means that while replica 1 returns the updated inventory, replica 2 returns the outdated inventory for Item B.
This can create inconsistency within the application.
The diagram below shows this scenario:
To use replication effectively, Shopify had to solve this issue:
There were two potential solutions Shopify considered but did not use:
Tight Consistency: One way was to enforce tight consistency to deal with variable lag. This means all replicas are guaranteed to be up to date with the primary server. However, this solution negates the benefits of using replica and also reduces the overall availability of write operations. Even if one of the replicas is down, the write operation can fail.
Causal Consistency: Another approach was causal consistency based on a global transaction identifier (GTID). Each transaction in the primary server will have a GTID, which will be preserved during replication. The disadvantage of this approach was the need to implement special software on each replica that would report its GTID back to the proxy that makes the server selection.
Finally, Shopify settled on a solution to implement monotonic read consistency. In this approach, successive reads should follow a consistent timeline even if the data read is not real-time.
This can be ensured by routing a series of related reads to the same server so that successive reads fetch a consistent state even if it’s not the latest state. See the diagram below for reference:
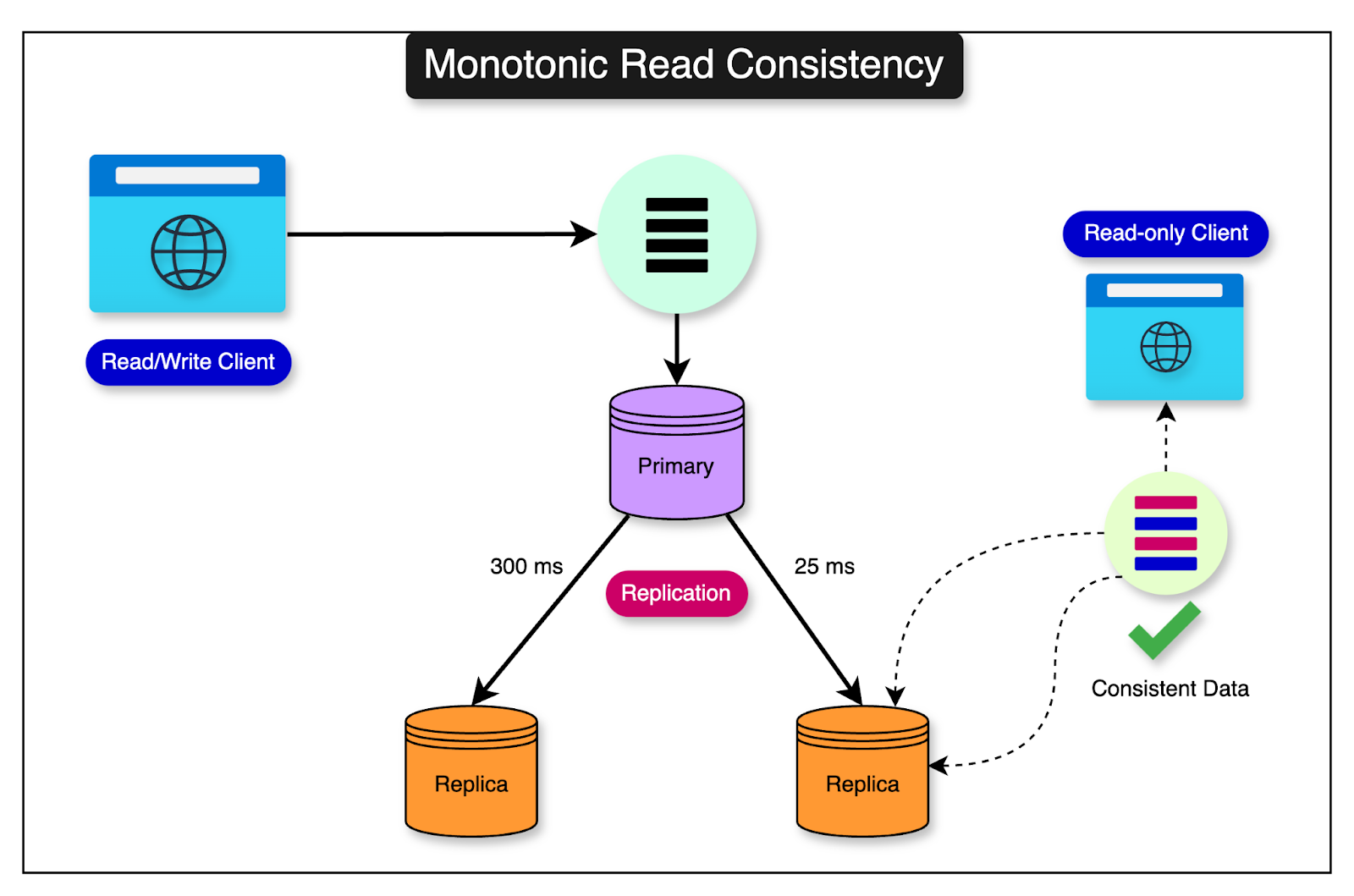
To implement this technically, Shopify had to take care of two points:
Determine if a request is related to another request.
Determine the server where the request should go.
Any application that requires read consistency within a series of requests supplies a unique identifier common to those requests. This identifier is passed within query comments as a key-value pair.
The diagram below shows the complete process:
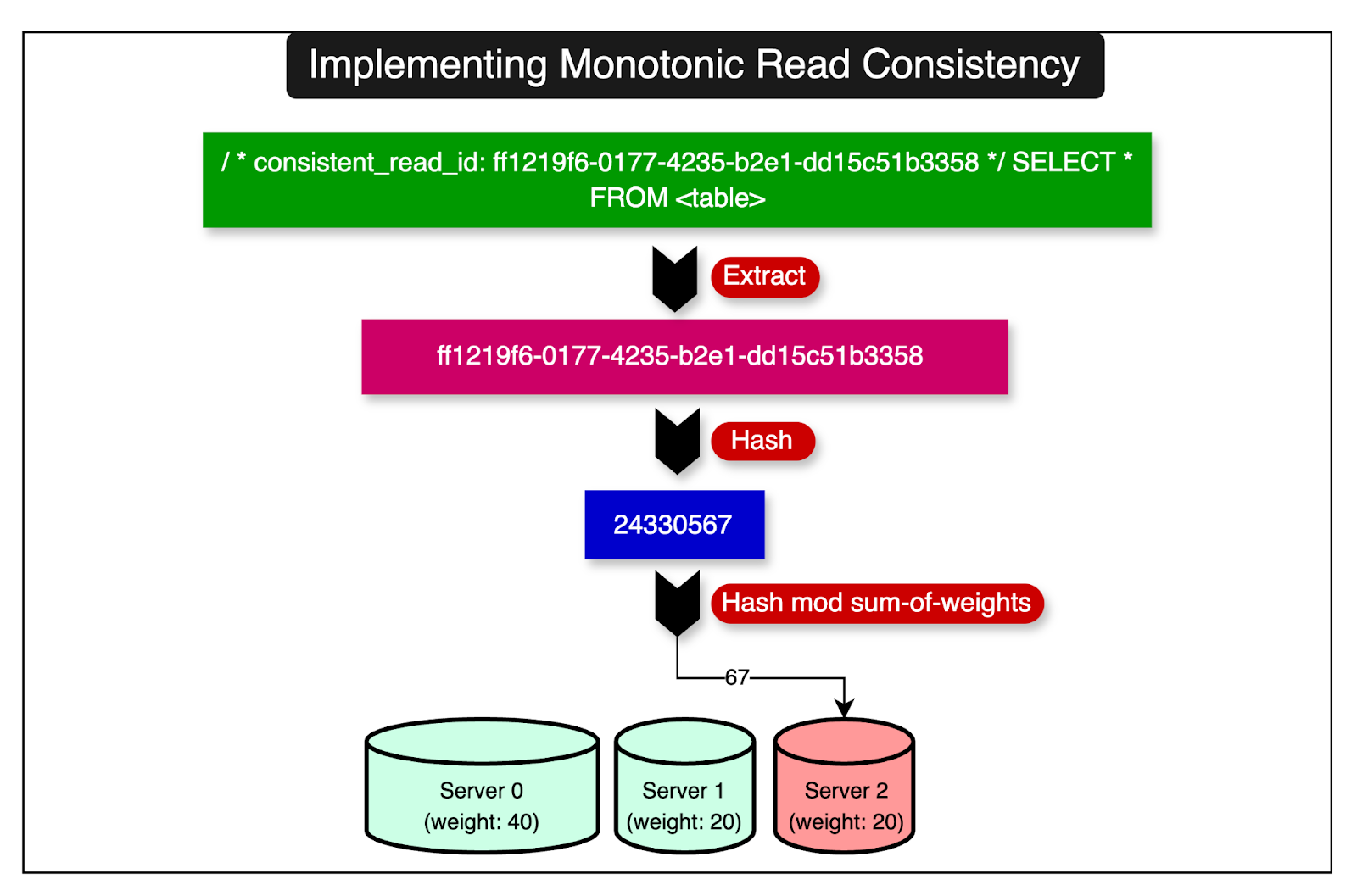
The identifier is a UUID that represents a series of related requests.
The UUID is labeled as consistent_read_id within the comments and goes through an extraction followed by a hashing process to determine the server that should receive all the requests that contain this identifier.
Shopify’s approach to consistent reads was simple to implement and had a low overhead in terms of processing. Its main drawback was that intermittent server outages can introduce read consistencies but this tradeoff was acceptable to them.
Database Backup and Restore
The last major learning point from Shopify’s data management is related to how they manage database backup and restore.
As mentioned earlier, Shopify runs a large fleet of MySQL servers. These servers are spread across three Google Cloud Platform (GCP) regions.
Initially, Shopify’s data backup process was as follows:
Use Percona’s Xtrabackup utility
Store output in files
Archive them on Google Cloud Storage
While the process was robust, it was time-consuming. Backing up a petabyte of data spread across multiple regions was too long. Also, the restore time for each shard was more than six hours. This meant Shopify had to accept a very high Recovery Time Objective (RTO).
To bring the RTO down to just 30 minutes, Shopify redesigned the backup and restore process. Since their MySQL servers ran on GCP’s VM using Persistent Disk (PD), they decided to leverage PD’s snapshot feature.
Let’s look at each step of the process in detail.
Taking a Backup
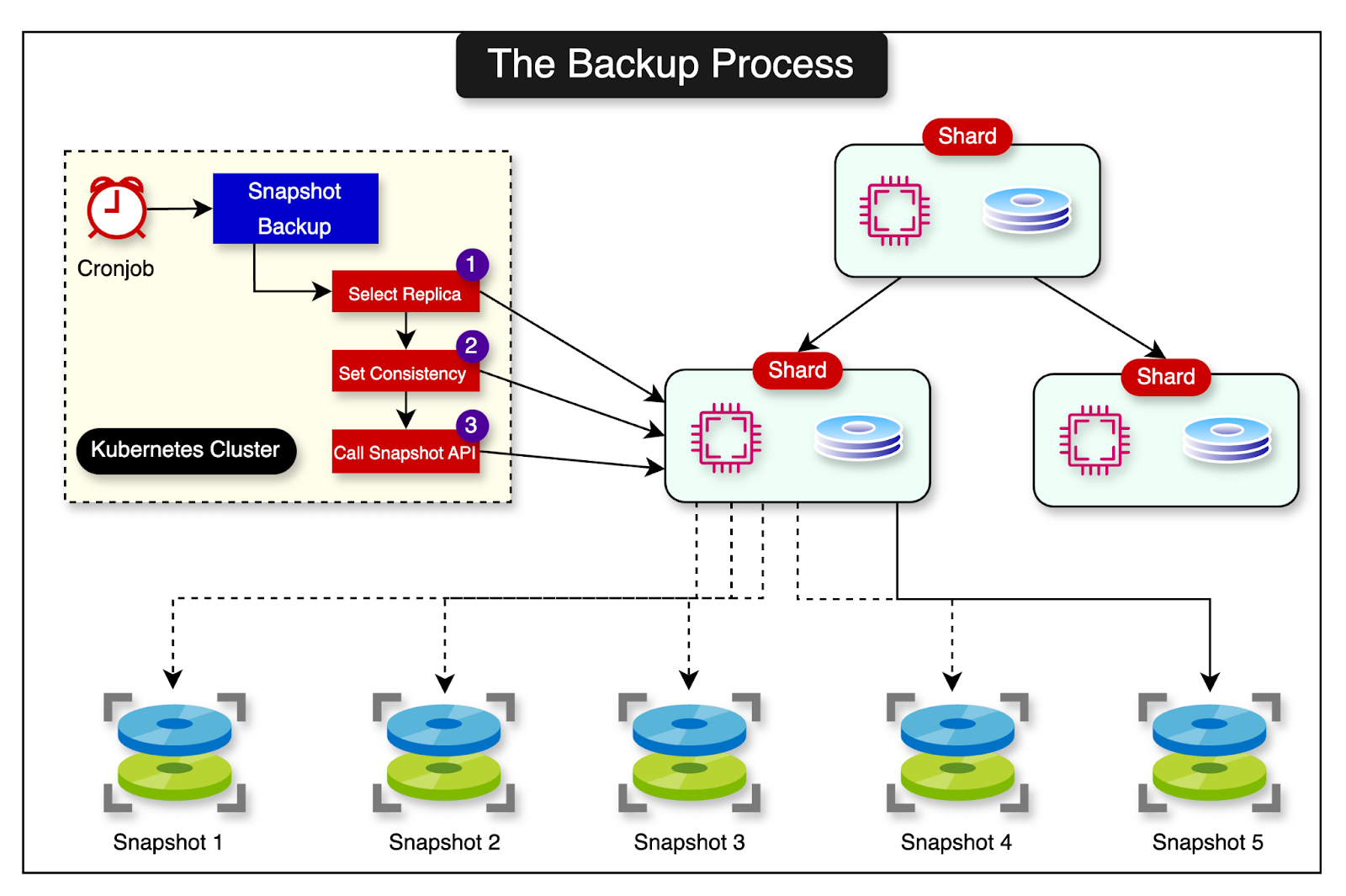
Shopify developed a new backup solution that uses GCP API to create persistent disk snapshots of their MySQL instances.
They deployed this backup tooling as a CronJob within their Kubernetes infrastructure. The CronJob is configured to run every 15 minutes across all clusters in all available regions. The tool creates snapshots of MySQL instances nearly 100 times a day across all shards, resulting in thousands of daily snapshots.
The diagram below shows the process:
Retaining Snapshots
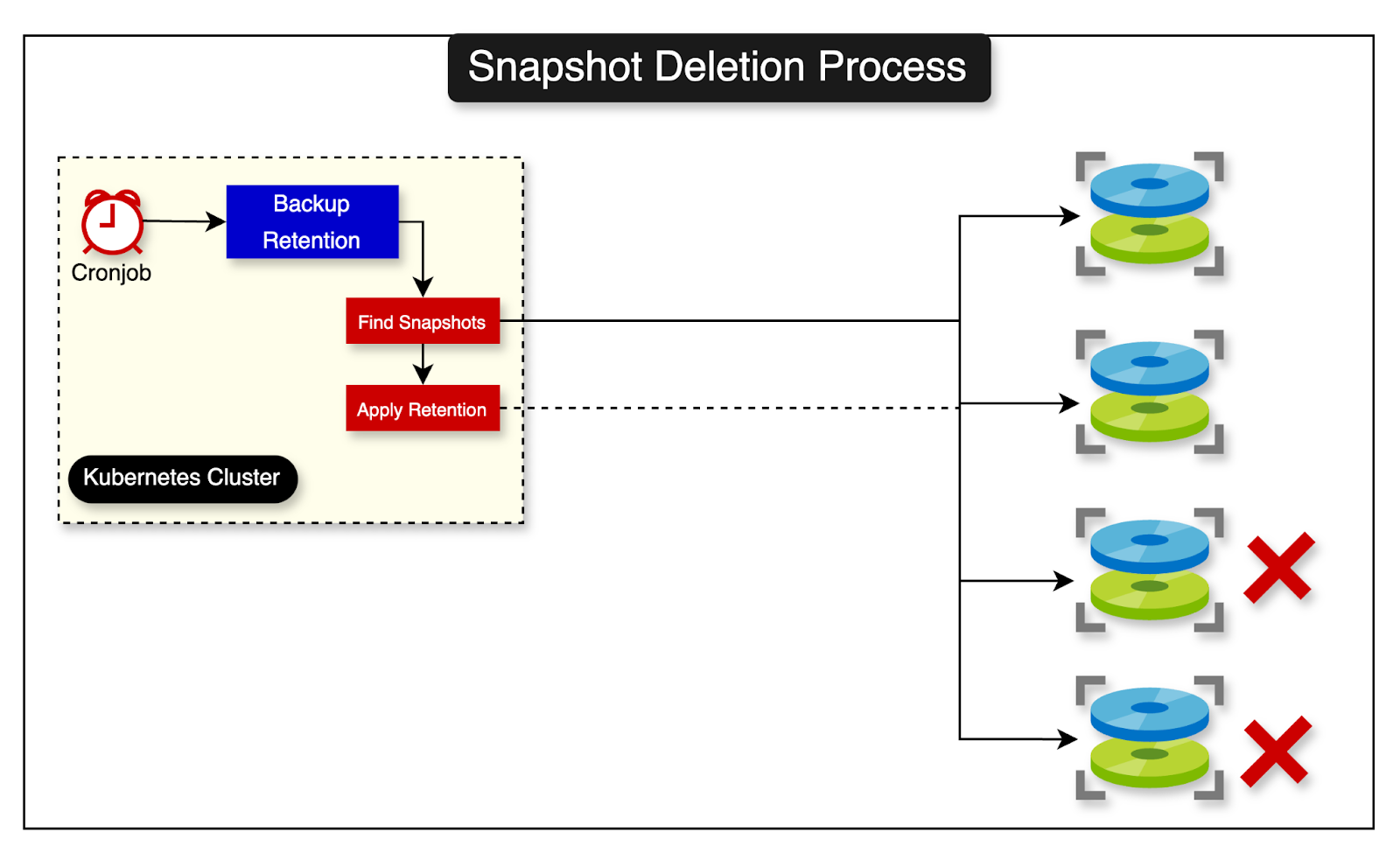
Since the backup process generated so many snapshots, Shopify also wanted to have a retention process to keep the important snapshots only. This was to keep the costs down.
They built another tool that implements the retention policy and deployed it using another CronJob on Kubernetes.
The diagram below shows the snapshot deletion process based on the retention policy.
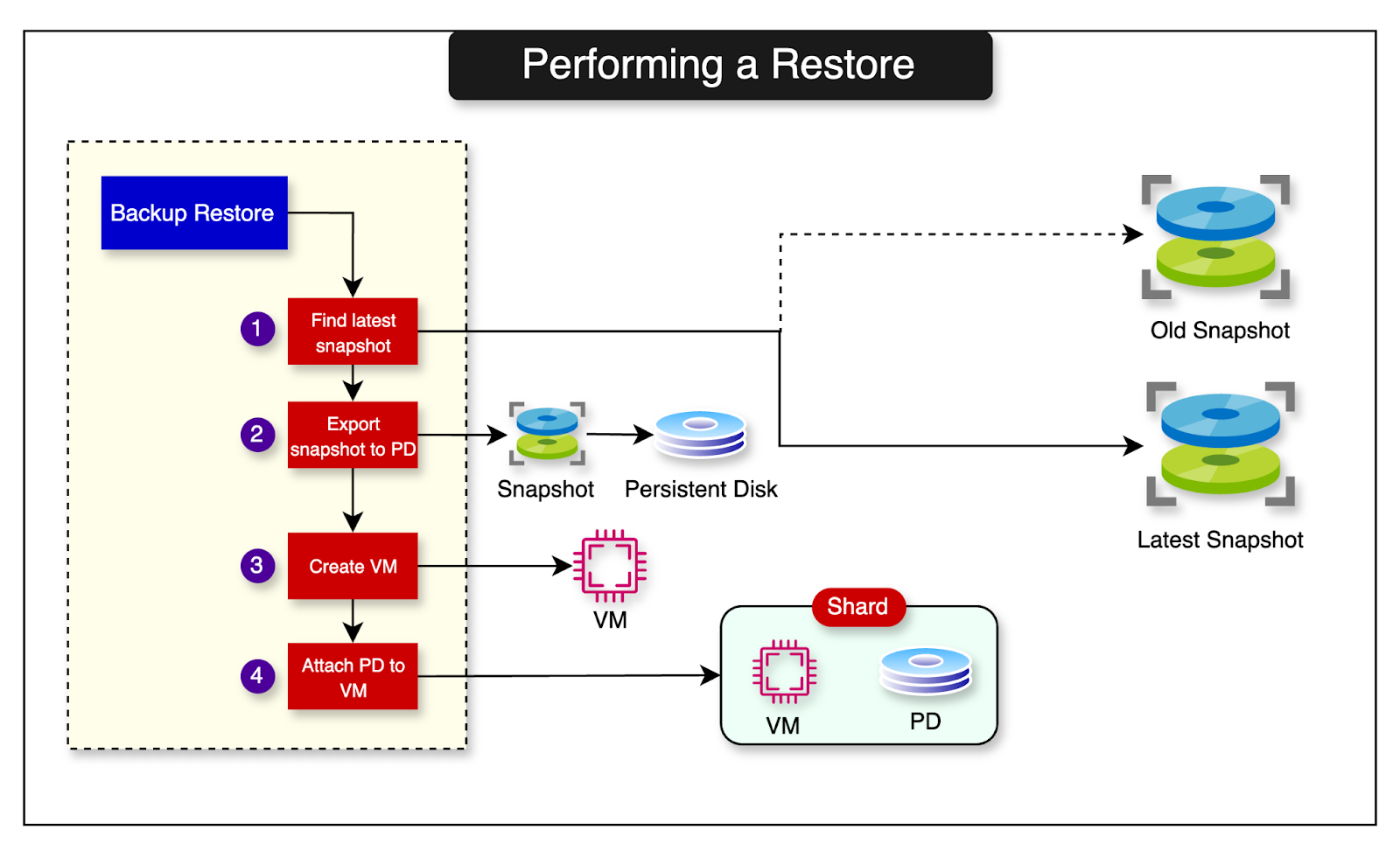
Performing a Restore
Having a very recent snapshot readily available enables Shopify to clone replicas with the most up-to-date data possible.
The process of restoring the backup is quite simple. It involves the following steps:
Create new PDs using the latest snapshot as the source.
Start MySQL on top of the newly created disks.
By exporting a snapshot to a new PD volume, Shopify can restore the database in a matter of minutes. This approach has reduced their RTO to less than 30 minutes, including the time needed to recover from any replication lag.
The diagram below shows the database restore process:
Conclusion
Shopify’s database management techniques are a great example of how simple solutions can help organizations achieve the needed scale. Also, it shows that companies like Shopify have a strong focus on the user experience and cost while making any technical decision.
In this post, we’ve seen a glimpse of how Shopify manages its petabyte-scale MySQL database. Some of the key things we’ve covered are as follows:
Shard balancing with zero downtime is important for efficient resource utilization and a good customer experience.
Database replication improves the availability and performance but also creates issues related to lag. A clear consistency model is needed to counter the effects of replication lag.
A quick and efficient database backup and restore process is important to minimize the recovery time.
References:
© 2024 ByteByteGo
548 Market Street PMB 72296, San Francisco, CA 94104
Unsubscribe
by "ByteByteGo" <bytebytego@substack.com> - 11:35 - 10 Sep 2024 -
post your all catogary articles or link insertion
I have some very good sites related to all categories for posting your article. my sites have pure organic traffic or good da
Please check site
site traffic
https://hustlersgrip.com/ 21.6k
Let me know if you need post on above sites
Add reaction
by "Alison Whyte" <alisonwhyte502@gmail.com> - 10:27 - 10 Sep 2024 -
Did you just hire a hacker?
Only McKinsey Perspectives
Trends in cybersecurity Brought to you by Alex Panas, global leader of industries, & Axel Karlsson, global leader of functional practices and growth platforms
Welcome to the latest edition of Only McKinsey Perspectives. We hope you find our insights useful. Let us know what you think at Alex_Panas@McKinsey.com and Axel_Karlsson@McKinsey.com.
—Alex and Axel
•
Protect data. Damage from cyberattacks could amount to about $10.5 trillion annually by 2025. That makes cybersecurity, or the practice of protecting computer systems, networks, and data from malicious attacks, essential for organizations. With only 10% of the security solutions market penetrated, the gap between the current market and the total addressable market is huge. The overall opportunity is a staggering $1.5 trillion to $2 trillion, McKinsey partner Marc Sorel and colleagues share.
—Edited by Aarushi Jain, editor, Atlanta
This email contains information about McKinsey's research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this email because you subscribed to the Only McKinsey Perspectives newsletter, formerly known as Only McKinsey.
Copyright © 2024 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "Only McKinsey Perspectives" <publishing@email.mckinsey.com> - 01:15 - 10 Sep 2024 -
Meet in Bangkok, Join for Success
Dear Logistics Partner,
This is Joy from GLA network, hope this email finds you well!
Join us on our mission to make a difference from November 22 to November 25 !
Location: Centara Grand & Bangkok Convention Centre at Central World, Bangkok, Thailand
Conference Highlights:Ø 2000+ Participants
Ø 130+ Countries Represented
Ø 200+ Exhibition Booths
Ø 100,000+ One-on-One Meetings
Ø Cocktail Party
Ø Grand Opening Ceremony
Ø Insightful Panel Discussions
Ø Gala Dinner
Ø Exciting Sports Tournaments, Thailand Tour, and much more!
Don't miss out! Register now at http://www.glafamily.com/meeting/registration/Joy
Please do not hesitate to reach out to me if you need more information.
Best regards,
Conference register: http://www.glafamily.com/meeting/registration/Joy
(Notice: If you would not like to receive email blush, please inform us timely. We will delete your data from the database)
Joy Jiang
Overseas Dept
M: +86 153 6164 8088;
( Whatsapp & Wechat)
A:GLA Co.,Limited
HongChang Plaza, 2001,Shennan Dong Road,Shenzhen
518000,China
by "GLA family" <member321@glafamily.com> - 07:44 - 9 Sep 2024