- Mailing Lists
- in
- Redis Can Do More Than Caching
Archives
- By thread 4924
-
By date
- June 2021 10
- July 2021 6
- August 2021 20
- September 2021 21
- October 2021 48
- November 2021 40
- December 2021 23
- January 2022 46
- February 2022 80
- March 2022 109
- April 2022 100
- May 2022 97
- June 2022 105
- July 2022 82
- August 2022 95
- September 2022 103
- October 2022 117
- November 2022 115
- December 2022 102
- January 2023 88
- February 2023 90
- March 2023 116
- April 2023 97
- May 2023 159
- June 2023 145
- July 2023 120
- August 2023 90
- September 2023 102
- October 2023 106
- November 2023 100
- December 2023 74
- January 2024 75
- February 2024 75
- March 2024 78
- April 2024 74
- May 2024 108
- June 2024 98
- July 2024 116
- August 2024 134
- September 2024 130
- October 2024 141
- November 2024 171
- December 2024 115
- January 2025 216
- February 2025 140
- March 2025 220
- April 2025 233
- May 2025 239
- June 2025 35
Redis Can Do More Than Caching
Redis Can Do More Than Caching
This is a sneak peek of today’s paid newsletter for our premium subscribers. Get access to this issue and all future issues - by subscribing today. Latest articlesIf you’re not a subscriber, here’s what you missed this month.
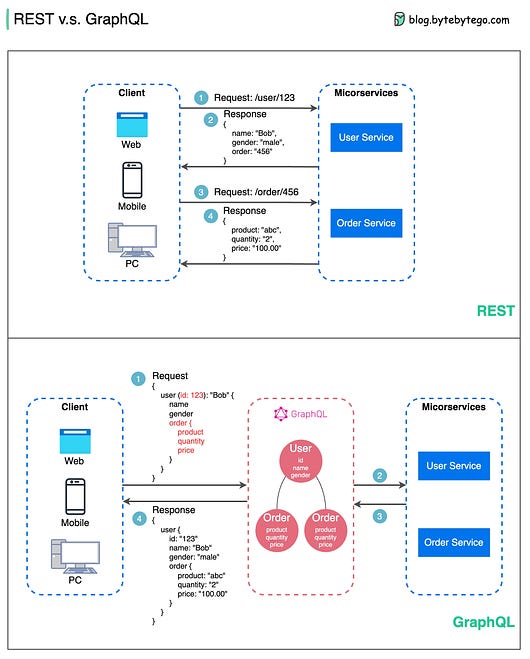
To receive all the full articles and support ByteByteGo, consider subscribing: In the last issue, we explored common use cases with Redis. In this issue, we will go deeper and demonstrate how Redis’ versatile data structures can power more complex applications like social networks, location-based services, and more. We will walk through practical examples of building key features like user profiles, relationship graphs, home timelines, and nearby searches using Redis’ native data types - Hashes, Sets, Sorted Sets, Streams, and Bitmaps. Understanding these advanced use cases will provide you with a solid foundation to leverage Redis for your own systems and products. You will gain insight into how Redis enables real-time experiences beyond simple caching. Social MediaRedis’ flexible data structures are well-suited for building social graph databases, which power the core functions of Twitter-like social media applications. Relational databases can struggle with the complex relationships and unstructured data of user-generated content. Redis provides high performance reads and writes to support features expected of social apps, allowing a small team to launch and iterate quickly. While Redis may not scale to the volumes of major social networks, it can power the first versions of an app through significant user growth. Redis enables implementing common social media features like:
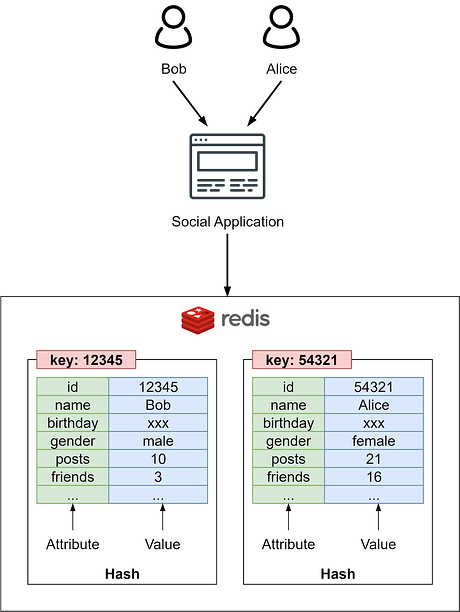
Let's explore how Redis supports these capabilities. User ProfilesIn social applications, a user profile stores identity attributes like name, location, interests, as well as preferences. We can represent each user profile as a Redis Hash, where the key is the user ID and the hash fields contain the profile properties. For example, we can store user Bob’s profile in a hash like: Compared to a relational model, Redis Hash provides flexibility to easily add new profile properties later without modifying the database schema. We just need to define how to retrieve and when adding more attributes to the user profile, because we don’t need to go through database schema change. In our application code, we would define how to retrieve and display the profile objects from these hashes. For example, we may only show name and location, or optionally include interests if present.
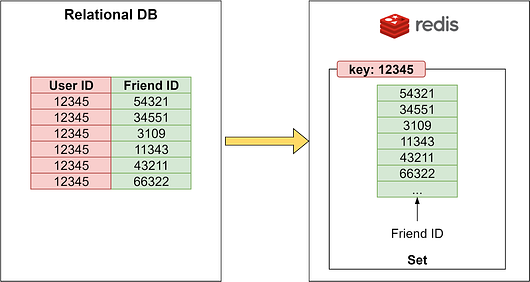
User RelationshipsOne of the major functions of a social application is establishing connections between users, like friend relationships or following others to receive their updates. Modeling these connections efficiently in a relational database can be challenging due to the complex graph-like structure of social networks. Redis provides a more natural way to represent user relationships using its built-in Set data structure. The diagram below shows a comparison of modeling user relationships in a relational database versus using Redis Sets. In the relational model, we use join tables to represent connections between users. Answering questions about relationships can involve complex SQL queries:
For example, to retrieve all of Bob's friends, we would need to query the join table like: In Redis, we can store Bob's friend ids directly in a Set with his user id as the key. Retrieving Bob's friends is as simple as returning the members of the ZSet. Checking if Alice is in Bob's extended network of friends is also easier with Redis Sets. We can take the intersection of their Sets:
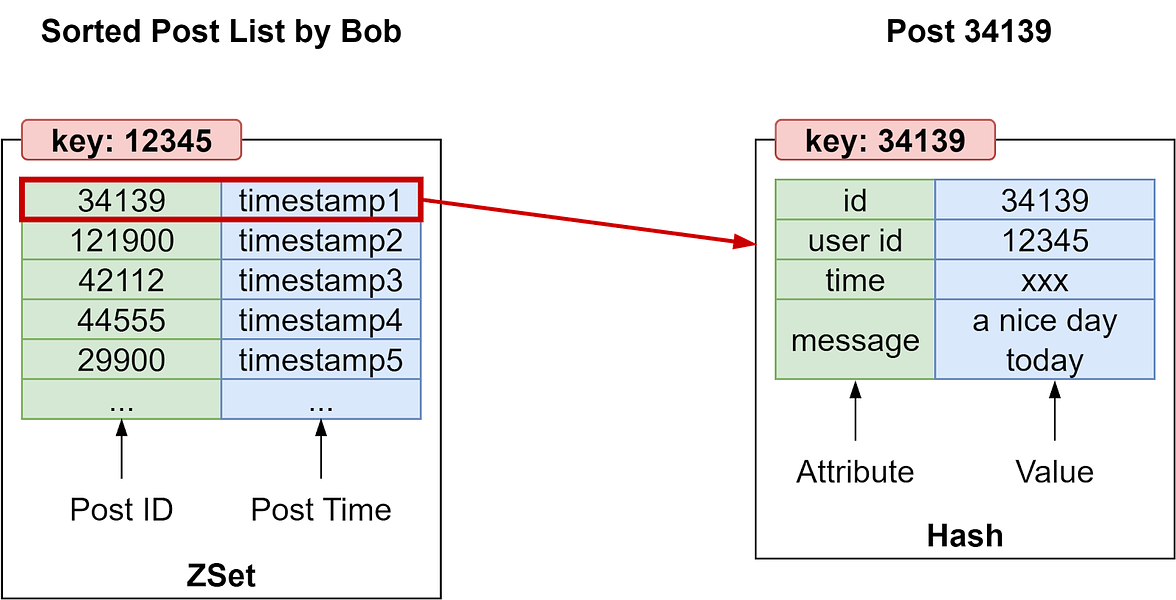
By avoiding complex join queries, Redis Sets provide faster reads and writes for managing unordered social connections. The Set data structure maps naturally to representing simple relationships in a social graph. PostsIn social apps, users create posts to share ideas, feelings, and status updates. Modeling this user-generated content can also be challenging in relational databases. We can leverage Redis more efficiently here as well. For each user, we can store post_ids in a Sorted Set ordered by timestamp. The key can be the user id, and each new post_id is added as a member to the Set. The post content itself is stored separately in Hashes, with the post_id as the hash key. Each Hash contains attributes like:
The diagram below shows how they work together. When a user creates a new post, we generate a new post_id, create a Hash to represent the post content, and add the post_id to the user's Sorted Set of posts. This provides a natural way to model posting timelines - new post_ids are added to the tail of the Set, and we can page through posts ordered chronologically using ZRANGE on post_ids.
Keep reading with a 7-day free trialSubscribe to ByteByteGo Newsletter to keep reading this post and get 7 days of free access to the full post archives.A subscription gets you:
© 2023 ByteByteGo
|
by "ByteByteGo" <bytebytego@substack.com> - 11:39 - 19 Oct 2023