- Mailing Lists
- in
- Storing 200 Billion Entities: Notion’s Data Lake Project
Archives
- By thread 5372
-
By date
- June 2021 10
- July 2021 6
- August 2021 20
- September 2021 21
- October 2021 48
- November 2021 40
- December 2021 23
- January 2022 46
- February 2022 80
- March 2022 109
- April 2022 100
- May 2022 97
- June 2022 105
- July 2022 82
- August 2022 95
- September 2022 103
- October 2022 117
- November 2022 115
- December 2022 102
- January 2023 88
- February 2023 90
- March 2023 116
- April 2023 97
- May 2023 159
- June 2023 145
- July 2023 120
- August 2023 90
- September 2023 102
- October 2023 106
- November 2023 100
- December 2023 74
- January 2024 75
- February 2024 75
- March 2024 78
- April 2024 74
- May 2024 108
- June 2024 98
- July 2024 116
- August 2024 134
- September 2024 130
- October 2024 141
- November 2024 171
- December 2024 115
- January 2025 216
- February 2025 140
- March 2025 220
- April 2025 233
- May 2025 239
- June 2025 303
- July 2025 185
Storing 200 Billion Entities: Notion’s Data Lake Project
Storing 200 Billion Entities: Notion’s Data Lake Project
Data Modeling for Performance: Virtual Masterclass (Sponsored)
Get battle-tested tips from Bo Ingram, Discord Engineer and Author of ScyllaDB in Action This masterclass shares pragmatic data modeling strategies for real-time, always-on use cases. To make the discussion concrete, we’ll teach by example with a sample restaurant review application and live monitoring dashboards. After this free 2-hour masterclass, you will know how to:
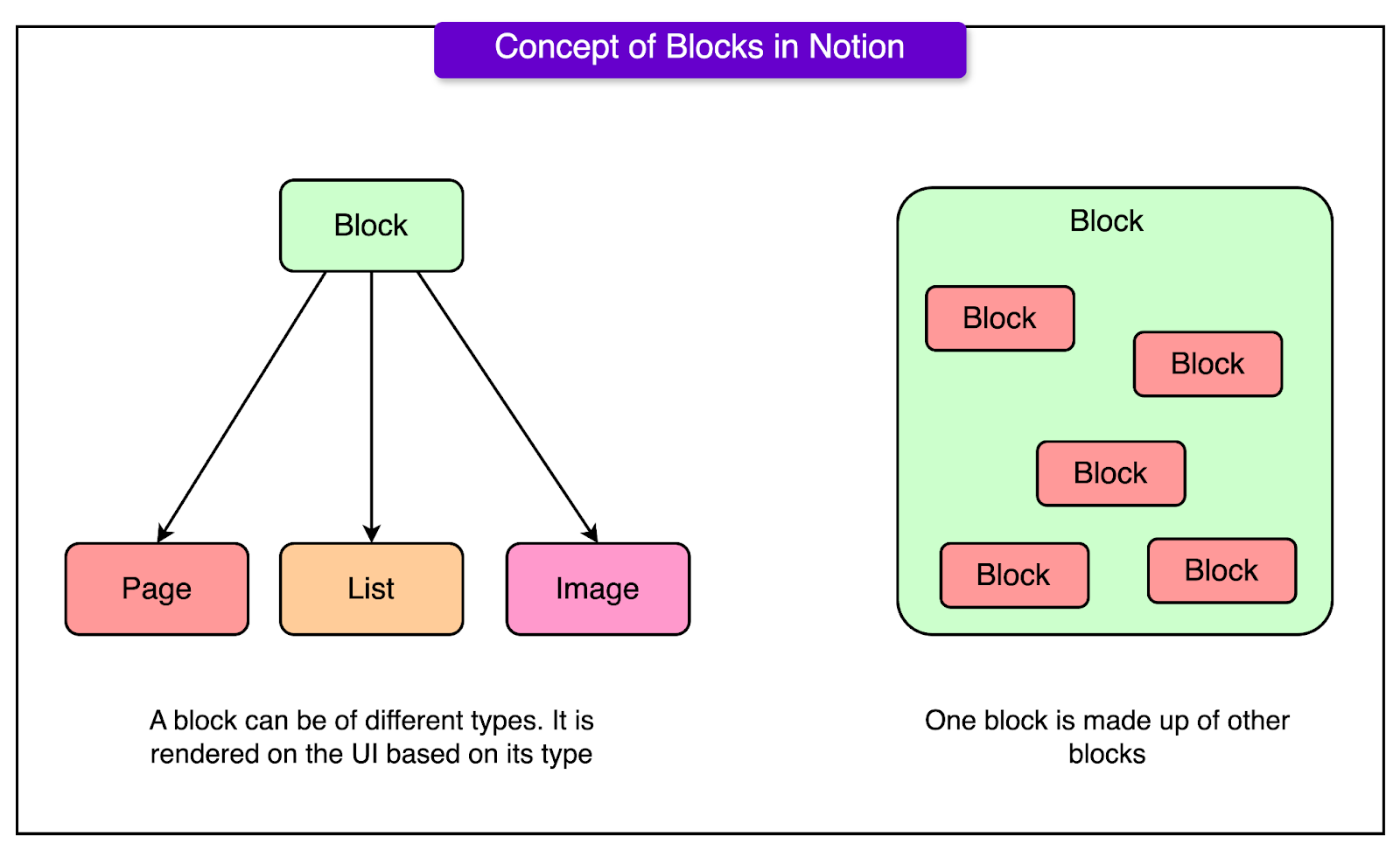
This is a great way to discover the strategies used by gamechangers like Discord, Disney+, Expedia, and more. Disclaimer: The details in this post have been derived from the Notion Engineering Blog. All credit for the technical details goes to the Notion engineering team. The links to the original articles are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them. The famous productivity app Notion has witnessed a staggering 10X data growth since 2021. At the start of 2021, they had around 20 billion block rows in Postgres. In 2024, this figure has grown to more than 200 billion blocks. The data volume, even when compressed, is hundreds of terabytes. Moreover, all of this block data has been doubling every 6 to 12 months, driven by user activity and content creation. Notion’s engineering team had to manage this rapid growth while meeting the ever-increasing data demands of the core product and the analytics use cases. This required them to build and scale Notion’s data lake. In this post, we’ll take a look at the challenges Notion faced while doing so and how they overcame those challenges. What is a Block?Before going further, it’s important to understand the concept of “Block” in Notion. Everything you see in the Notion editor (texts, images, headings, lists, pages, etc) is modeled as a “block” entity in the backend. The block types may have different front-end representations and behaviors. However, they are all stored in a Postgres database with a consistent structure, schema, and associated metadata. See the diagram below for reference:
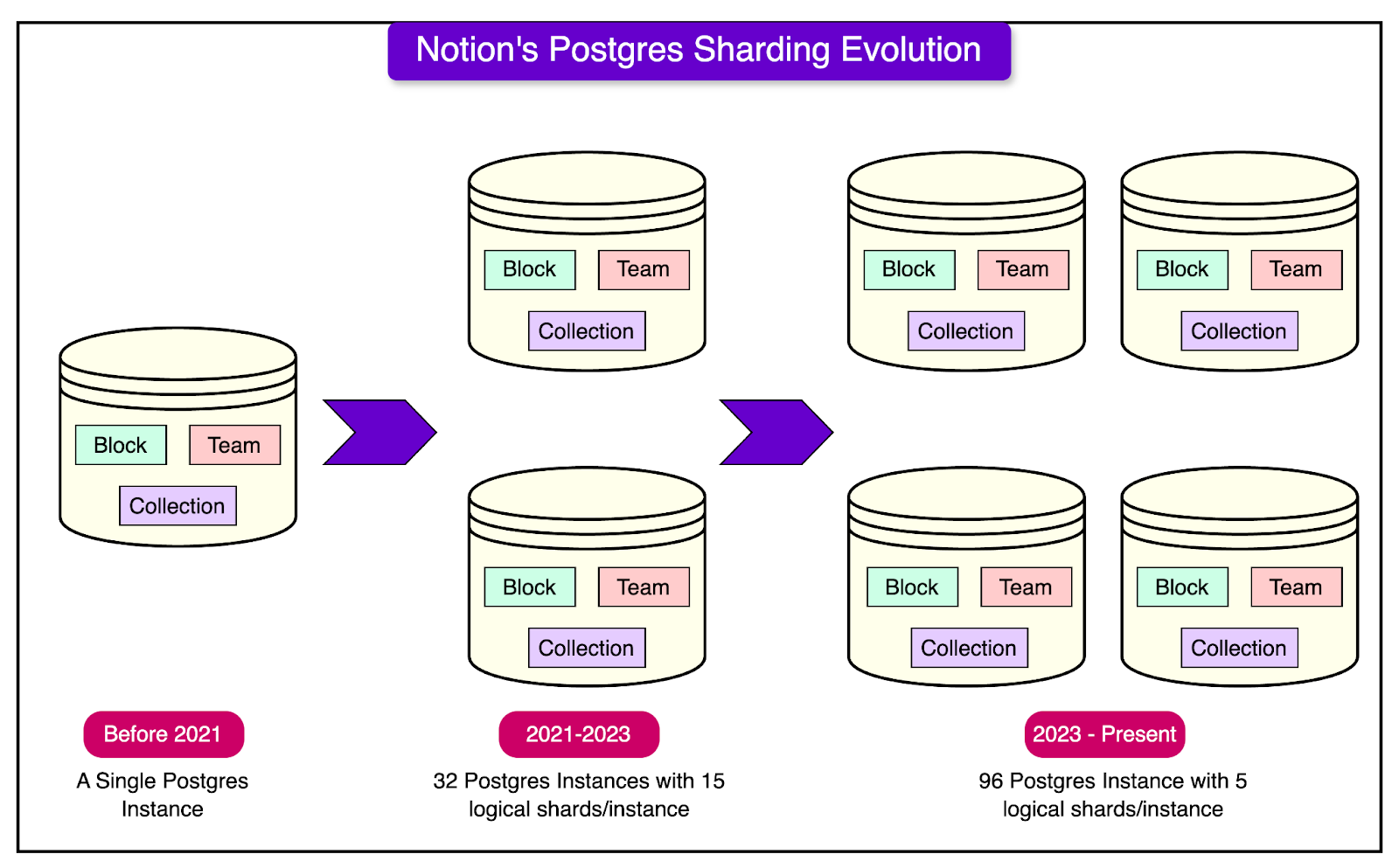
As Notion started to see data growth, its engineering team opted for sharding to scale the monolithic Postgres instance.
In essence, they maintained a total of 480 logical shards while increasing the number of physical instances. See the diagram below for reference:
In 2021, Postgres at Notion catered to online user traffic as well as the various offline data analytics and machine learning requirements. However, as the demands grew for both data needs, the Notion engineering team decided to build a dedicated data infrastructure to handle offline data without interfering with online traffic. Build client and partner portals in 30 minutes (Sponsored)
Are your engineering teams spending months building and maintaining customer-facing dashboards and portals? Join our 30-minute demo to see how you can:
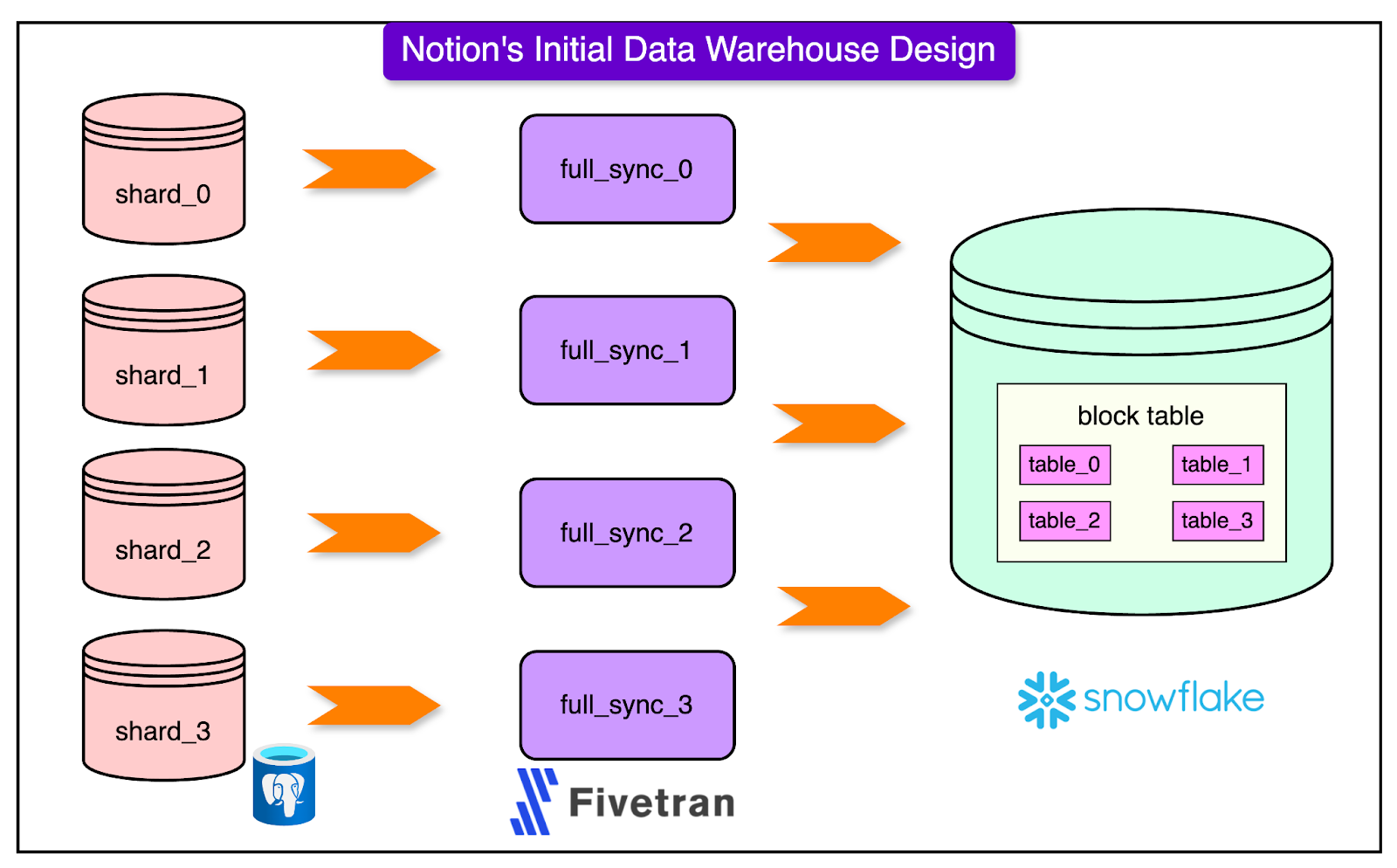
Hear why companies are building their products and client-facing tools with Retool: Teachable launched enterprise analytics to 1,000+ customers in just two months, while Ylopo scaled their customer portal from hundreds to tens of thousands of users in weeks by externalizing their Retool apps. The Initial Data Warehouse ArchitectureNotion built the first dedicated data infrastructure in 2021. It was a simple ELT (Extract, Load, and Transform) pipeline. See the diagram below:
The pipeline worked as follows:
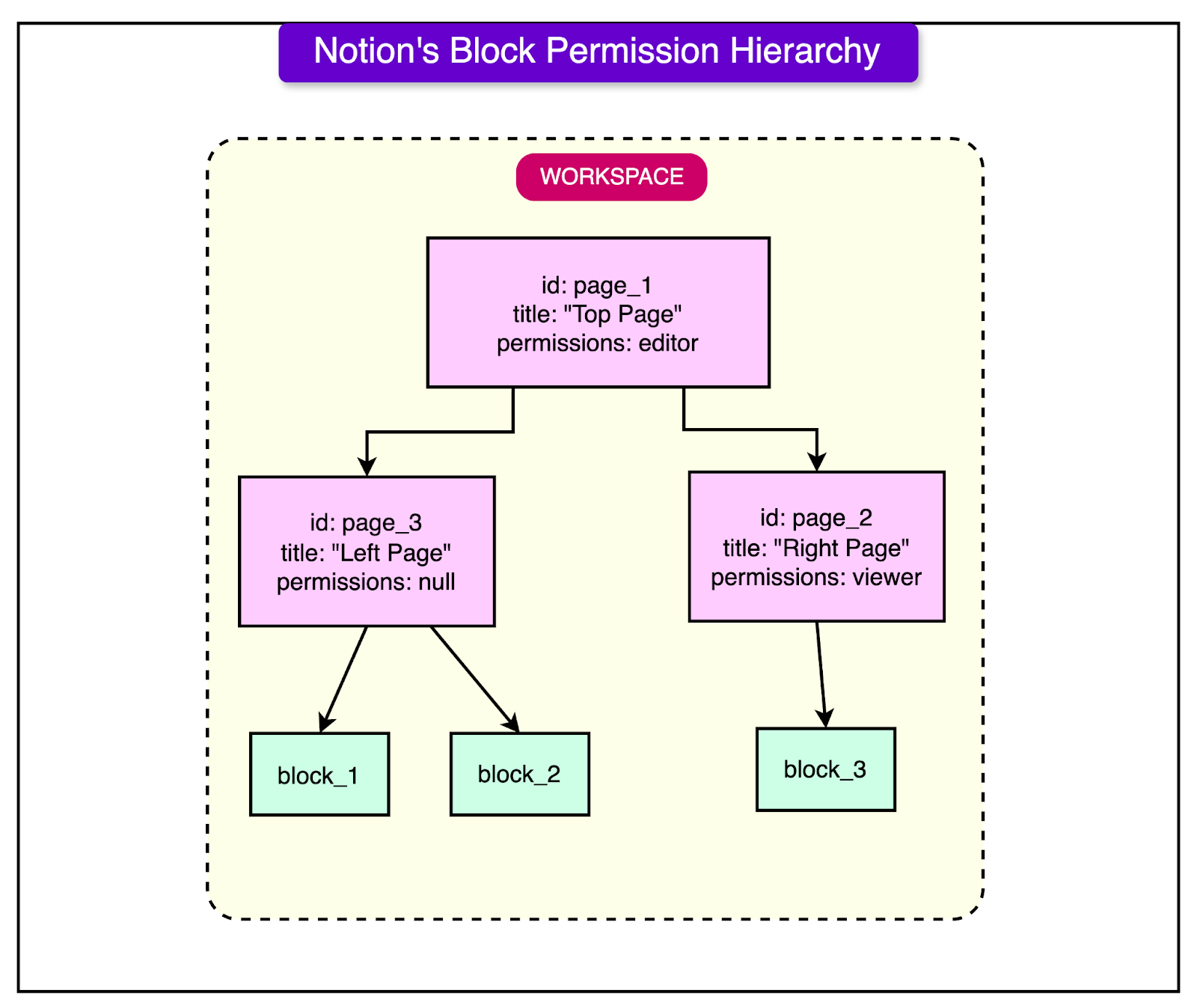
There were multiple scaling challenges with this approach. 1 - Operational DifficultyMonitoring and managing 480 Fivetran connectors (one for every shard) was a difficult job. Activities such as re-syncing these connectors during Postgres re-sharding, upgrade, and maintenance periods created a significant on-call burden for the support team. 2 - Speed and CostIngesting data to Snowflake became slower and costlier, particularly due to Notion’s update-heavy workload. Since Notion’s primary use is note-taking and managing those notes, users update existing blocks much more often than they add new ones. This results in an update-heavy workload. However, most data warehouses (including Snowflake) are optimized for insert-heavy workloads. 3 - Support for RequirementsEven more than the first two, the lack of support for certain requirements eventually became a more important challenge. As Notion grew, the data transformation logic became more complex and heavy, making it difficult to handle using the standard SQL interface offered by off-the-shelf data warehouses. For example, an important use case was to construct denormalized views of Notion’s block data for key features related to AI and Search. However, constructing permission data for a block was difficult since it wasn’t statically stored in Postgres but constructed on the fly via tree traversal computation. See the example below:
In this example, the various blocks (block_1, block_2, and block_3) inherit permissions from their immediate parents (page_3 and page_2) and ancestors (page_1 and the workspace itself). Permission data for such blocks can be built only by traversing the tree up to the root (i.e. the workspace). With billions of blocks, Notion found this computation very costly in Snowflake. Notion’s New Data LakeDue to the challenges with scaling and operating the initial data warehouse, Notion decided to build a new in-house data lake with the below objectives:
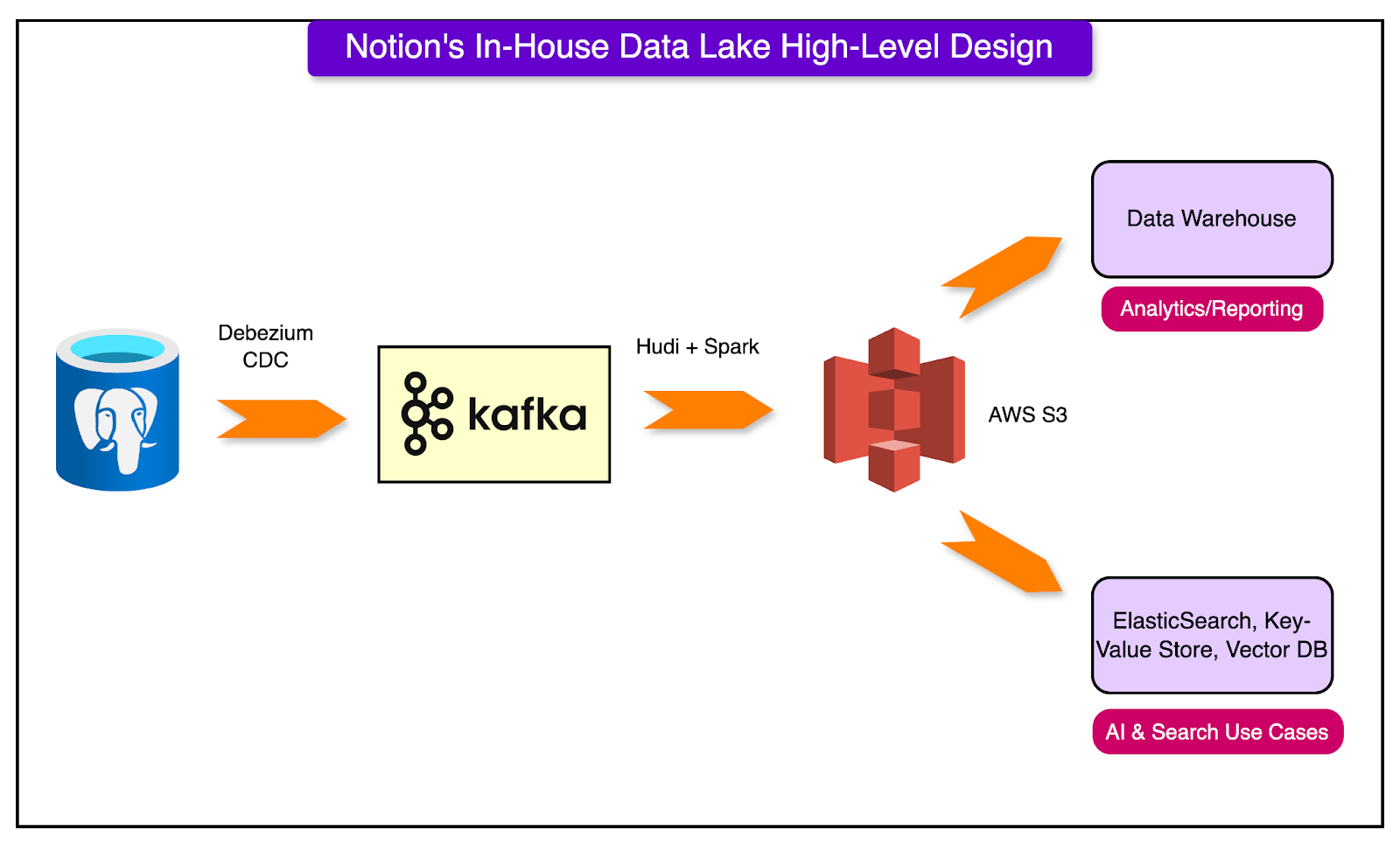
The diagram below shows the high-level design of the new data lake.
The process works as follows:
While the final look of the design seems quite straightforward, Notion arrived at it after making several important design decisions. Let’s look at a few of them in more detail. 1 - Choosing a Data Repository and LakeNotion used S3 as a data repository and lake to store both the raw and processed data. Other product-facing data stores such as ElasticSearch, Vector Database, and Key-Value store were downstream of this. Choosing S3 was a logical choice since Notion’s Postgres database is based on AWS RDS and its export-to-S3 feature made it easy to bootstrap tables in S3. Also, S3 is proven to store large amounts of data and support data processing engines like Spark at low cost. 2 - Choosing the Processing EngineNotion engineering team chose Spark as the main data processing engine. As an open-source framework, it was easy to set up and evaluate. There were some key benefits to using Spark:
3 - Incremental Ingestion or Snapshot DumpBased on performance and cost comparisons, Notion went with a hybrid design with more emphasis on incremental ingestion.
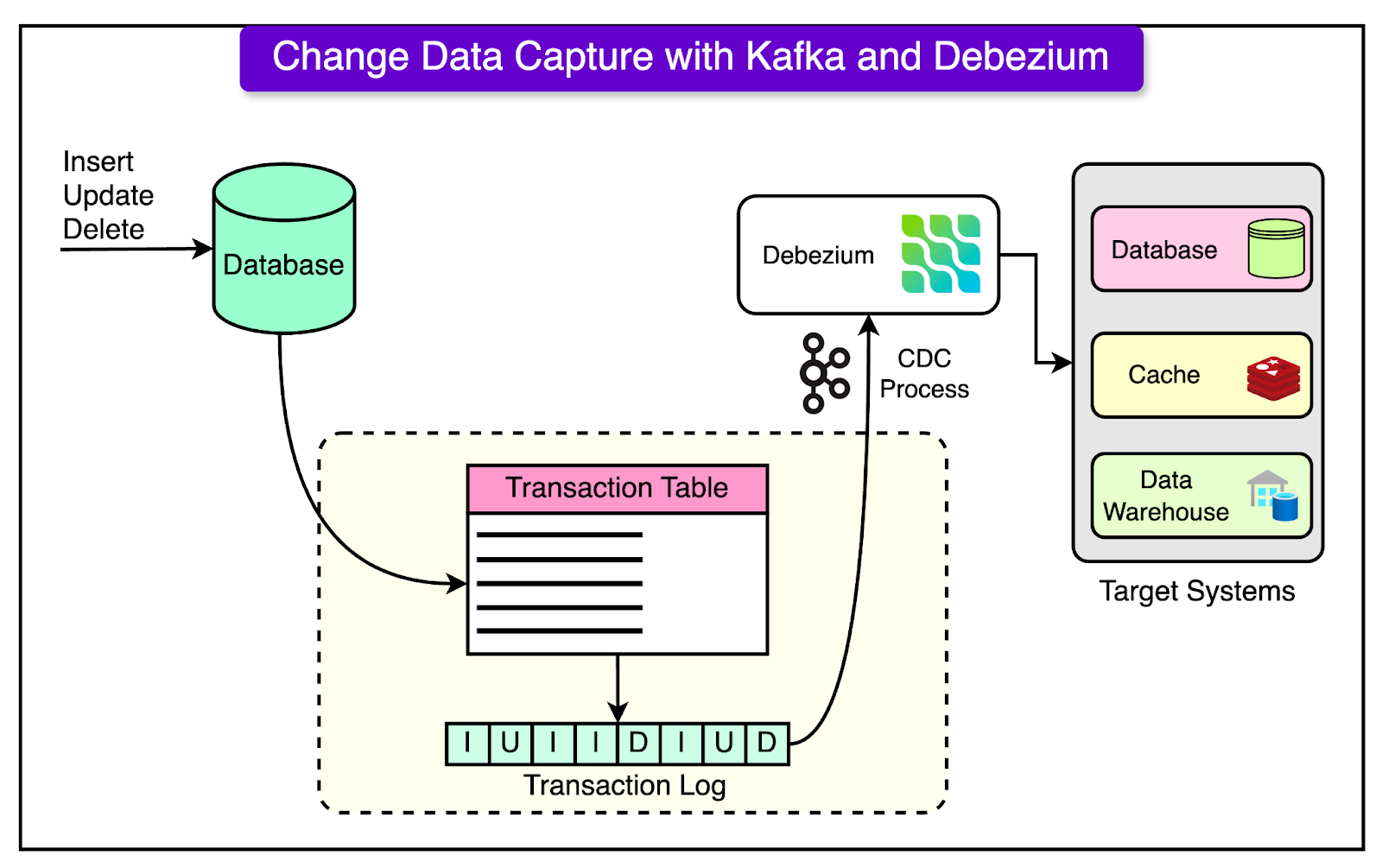
This was done because the incremental approach ensures fresher data at a lower cost and minimal delay. For example, the incremental approach takes a few minutes to a couple of hours as compared to the snapshot dump taking more than 10 hours and costs twice as much. 4 - Streamline Incremental IngestionThe Notion engineering team chose the Kafka Debezium CDC (Change Data Capture) connector to publish incrementally changed Postgres data to Kafka. This was done for the scalability, ease of setup, and close integration with the existing infrastructure. For ingesting incremental data from Kafka to S3, they chose Apache Hudi. Other options on the table were Apache Iceberg and DataBricks Delta Lake. However, Hudi gave a better performance with Notion’s update-heavy workload along with native integration with Debezium CDC messages. 5 - Ingest Raw Data Before ProcessingAnother interesting decision was to ingest raw Postgres data to S3 without on-the-fly processing. This was done to create a single source of truth and simplify debugging across the data pipeline. Once the data is in S3, they perform the transformation, denormalization, and enrichment. The intermediate data is once again stored in S3 and only highly clean, structured, and business-critical data is ingested to downstream analytics systems. Solving Scaling Challenges of the New Data LakeSince the data volume at Notion was ever-growing, the engineering team took many steps to tackle the scalability challenges. Here are a few important ones to understand. 1 - CDC Connector and KafkaThey set up one Debezium CDC connector per Postgres host and deployed them in an AWS EKS cluster. For reference, the diagram below shows how CDC with Debezium and Kafka works on a high level.
Also, there is one Kafka topic per Postgres table, and all connectors consuming from 480 shards write to the same topic for that table. This approach simplified downstream Hudi ingestion to S3 by reducing the complexity of maintaining 480 separate topics for each table. 2 - Hudi SetupThe Notion engineering team used Apache Hudi Deltastreamer (Spark-based) to consume Kafka messages and replicate Postgres tables in S3. They utilized COPY_ON_WRITE Hudi table type with UPSERT operation to support the update-heavy workload. Some key optimizations were as follows:
3 - Spark Data Processing SetupThey used PySpark for the majority of data processing jobs because of its low learning curve and accessibility to team members. For tasks like tree traversal and denormalization, they utilized Scala Spark. A key optimization was to manage data by handling large and small shards differently. Small shards were loaded entirely into memory whereas large shards were managed through disk reshuffling. Also, to optimize runtime and efficiency, they implemented multi-threading and parallel processing for 480 shards. 4 - Bootstrap SetupThe bootstrap setup works as follows:
To maintain data completeness and integrity, all changes made during the snapshotting process are captured by setting up Deltastreamer to read Kafka messages from the specific timestamp. ConclusionNotion’s data lake infrastructure project development started in the spring of 2022 and was completed by the fall. It has been a huge success for them in terms of cost and reliability. Some key benefits have been as follows:
References: SPONSOR USGet your product in front of more than 1,000,000 tech professionals. Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases. Space Fills Up Fast - Reserve Today Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com © 2024 ByteByteGo
|


by "ByteByteGo" <bytebytego@substack.com> - 11:38 - 12 Nov 2024