- Mailing Lists
- in
- The Foundation of REST API: HTTP
Archives
- By thread 5286
-
By date
- June 2021 10
- July 2021 6
- August 2021 20
- September 2021 21
- October 2021 48
- November 2021 40
- December 2021 23
- January 2022 46
- February 2022 80
- March 2022 109
- April 2022 100
- May 2022 97
- June 2022 105
- July 2022 82
- August 2022 95
- September 2022 103
- October 2022 117
- November 2022 115
- December 2022 102
- January 2023 88
- February 2023 90
- March 2023 116
- April 2023 97
- May 2023 159
- June 2023 145
- July 2023 120
- August 2023 90
- September 2023 102
- October 2023 106
- November 2023 100
- December 2023 74
- January 2024 75
- February 2024 75
- March 2024 78
- April 2024 74
- May 2024 108
- June 2024 98
- July 2024 116
- August 2024 134
- September 2024 130
- October 2024 141
- November 2024 171
- December 2024 115
- January 2025 216
- February 2025 140
- March 2025 220
- April 2025 233
- May 2025 239
- June 2025 303
- July 2025 98
New Relic named a Leader in the 2023 Gartner® Magic Quadrant™
Forward Thinking on avoiding another false dawn for Africa and finally seizing the continent’s potential with Carlos Lopes
The Foundation of REST API: HTTP
The Foundation of REST API: HTTP
This is a sneak peek of today’s paid newsletter for our premium subscribers. Get access to this issue and all future issues - by subscribing today. Latest articlesIf you’re not a subscriber, here’s what you missed this month
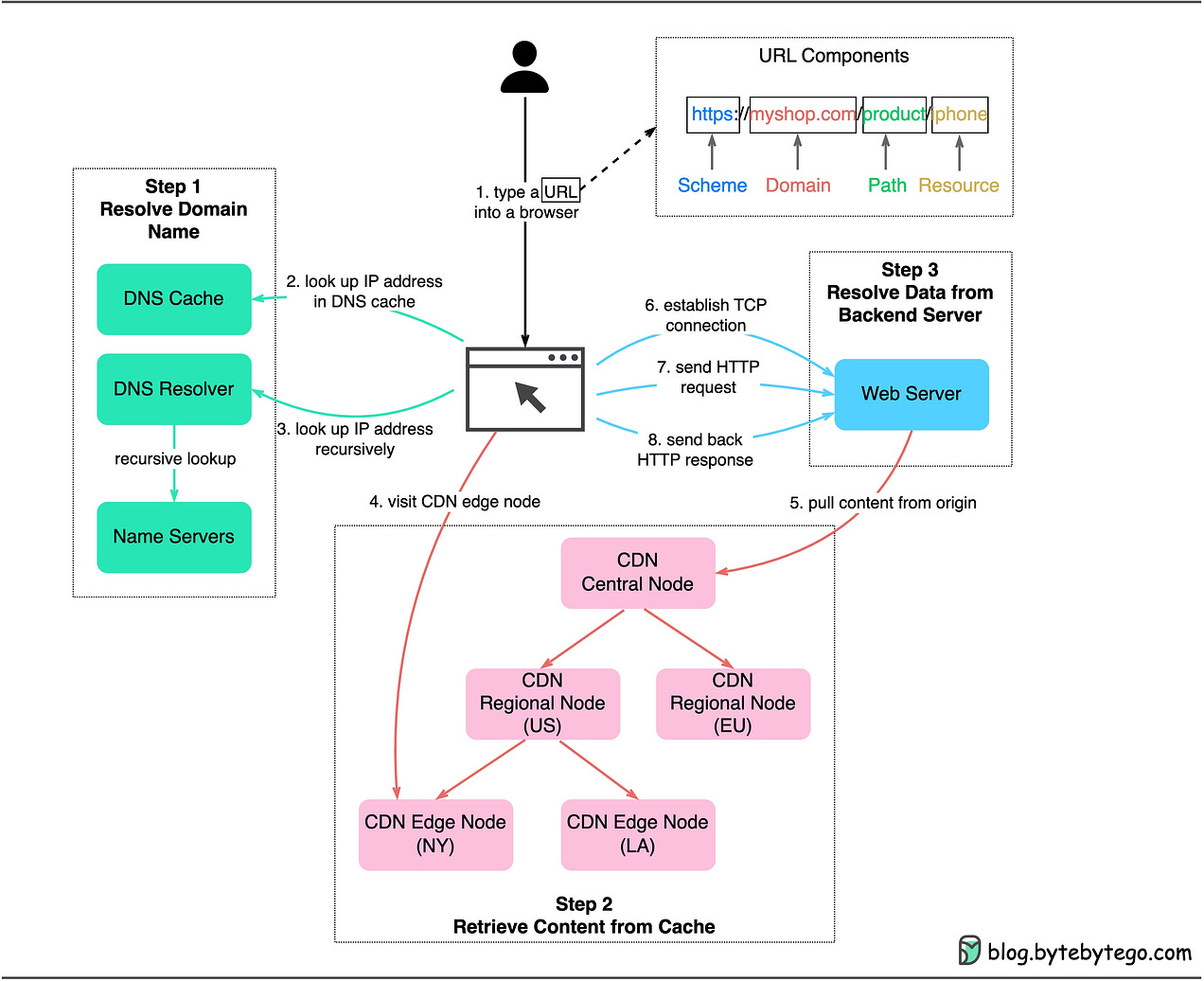
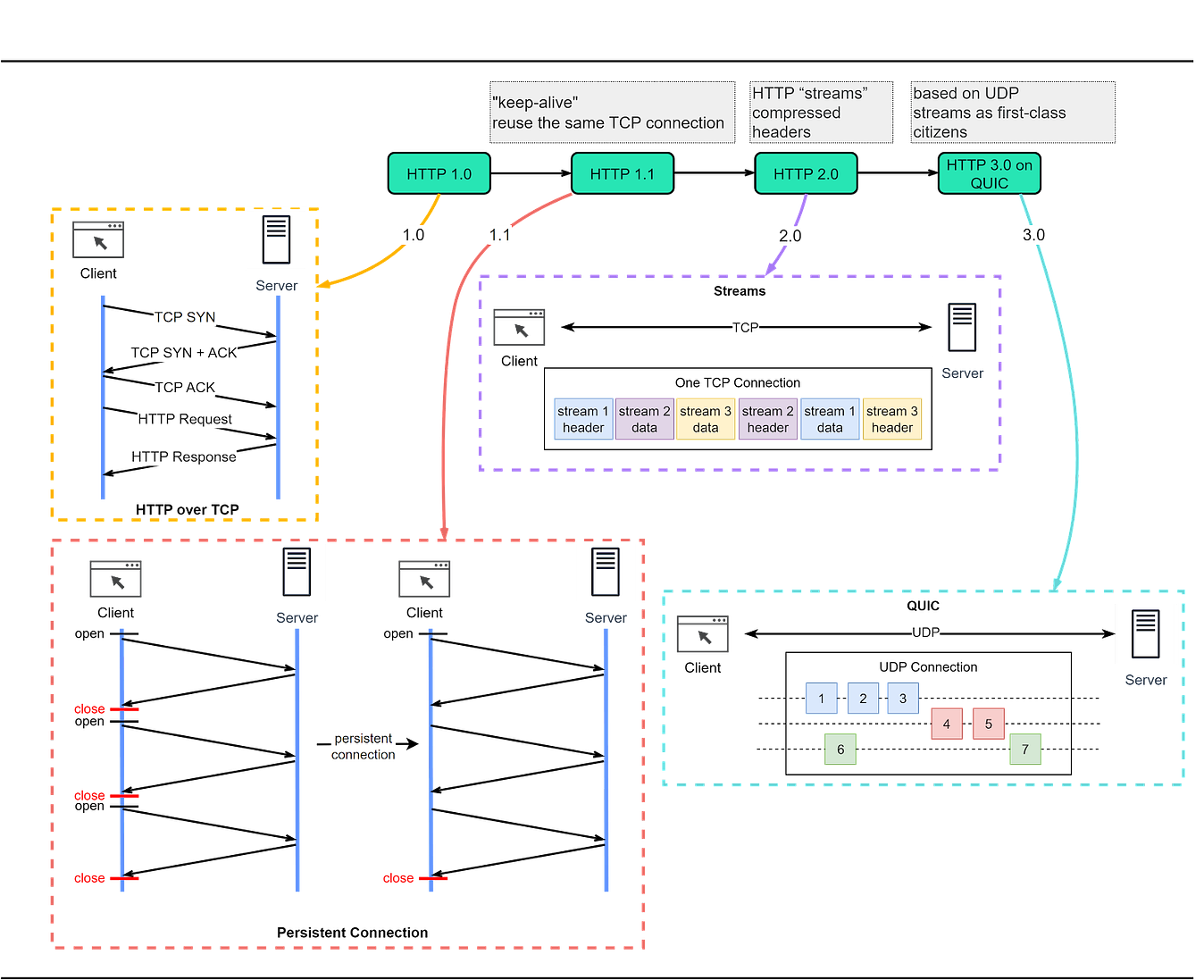
To receive all the full articles and support ByteByteGo, consider subscribing: In this issue, we’re diving into the foundation of data communication for the World Wide Web - HTTP. What is Hypertext?HTTP, or HyperText Transfer Protocol, owes its name to ‘hypertext’. So, what exactly is hypertext? Imagine a blend of text, images, and videos that are stitched together by the magic of hyperlinks. These links serve as portals that allow us to jump from one set of hypertext to another. HTML, or HyperText Markup Language, is a prime example of hypertext. HTML is a plain text file. It’s packed with many tags that define links to images, videos, and more. After the browser interprets these tags, it transforms the seemingly ordinary text file into a webpage filled with text and images. HTTP/1.1, HTTP/2, and HTTP/3HTTP has undergone significant transformations since its inception in 1989 with version 0.9. Let’s take a walk down memory lane and see the problems each version of HTTP addresses. The diagram below shows the key improvements.
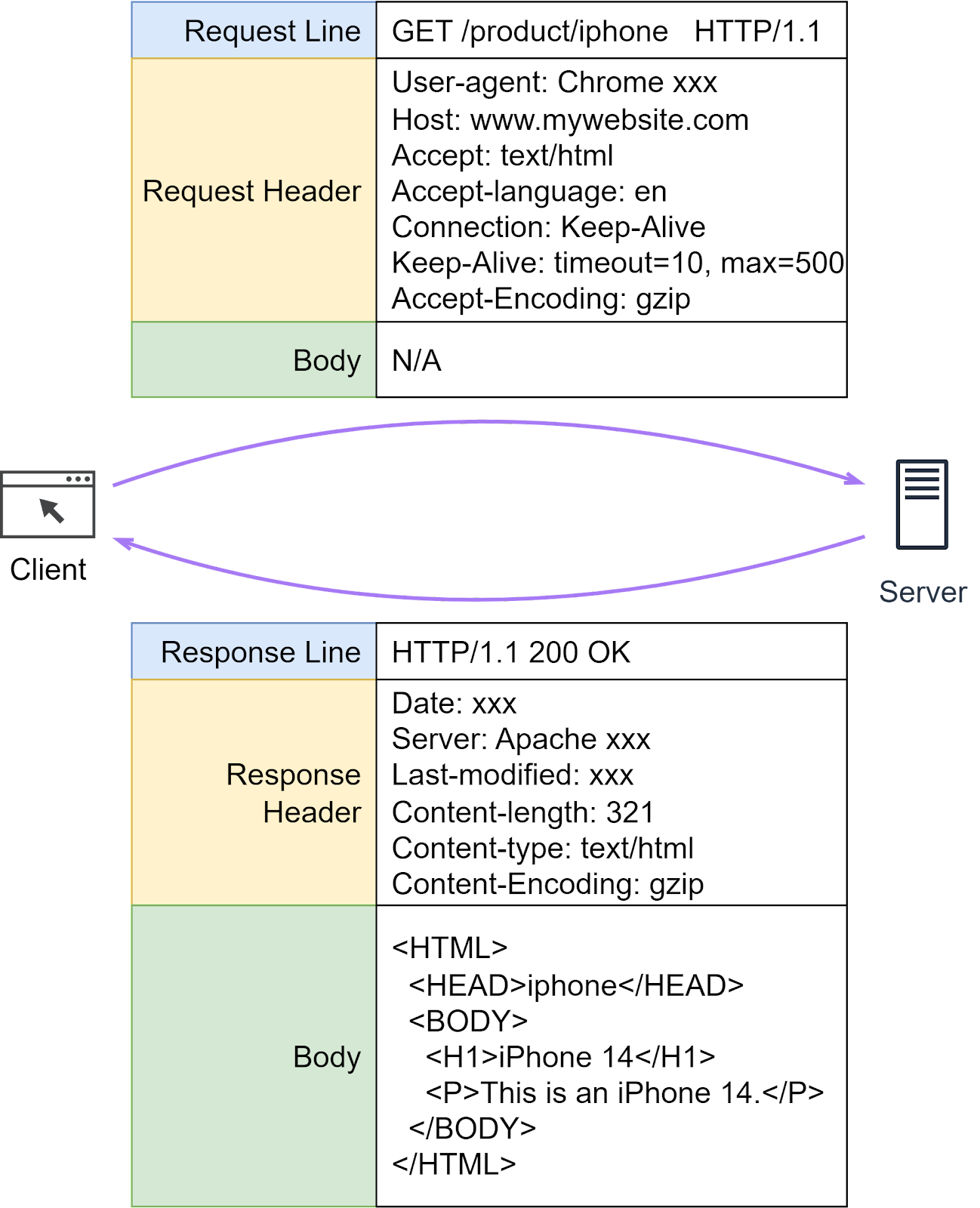
HTTP HeadersHTTP headers play a crucial role in how clients and servers send and receive data. They provide a structured way for these entities to communicate important metadata about the request or response. This metadata can contain various information like the type of data being sent, its length, how it's compressed, and more. An HTTP header consists of several fields, each with a specific role and meaning. Now that we have an understanding of what HTTP headers are, let's dive deeper into some specific HTTP fields. HTTP FieldsWhen we send HTTP requests to a server, several common fields play a critical role. Let’s dissect some of them.
HTTP GET vs HTTP POSTHTTP protocols define various methods or ‘verbs’ to perform different actions on web resources. The commonly used ones are GET, POST, PUT, and DELETE, which are often used to read, create, update, and delete resources. Less common methods include HEAD, CONNECT, OPTIONS, TRACE, and PATCH, which we covered in our previous “API Design” issues. One common interview question is: “What is the difference between GET and POST?” Let’s dive into their definitions. HTTP GET: This method retrieves resources from the server via URLs without producing any other effect. As GET requests usually lack a payload body, they enable bookmarking, sharing, and caching of web pages. HTTP POST: This method interacts with resources based on the payload body. The interaction varies depending on the resource type. For example, if we’re leaving a comment after purchasing an iPhone 14, clicking “submit” sends a POST request to the server with the comment in the message body. While there's no defined limit to the size of the message body in a POST request by the HTTP protocol itself, in practice, browsers and servers often impose their own limits. Understanding the Characteristics of GET and POSTHTTP methods have certain properties that define how they interact with server resources. Two such properties are whether they're 'non-mutating' and 'idempotent.' A non-mutating method doesn't alter any server resources. On the other hand, an idempotent method produces the same result, regardless of how many times it's repeated. HTTP GET: The GET method retrieves data without causing changes, making it non-mutating. Additionally, repeating a GET request won't change the outcome, making it idempotent. HTTP POST: Unlike GET, the POST method sends data that can modify server resources, making it potentially mutating. Furthermore, if we repeat a POST request, it can create additional resources, making it non-idempotent. However, it's important to note that actual behavior can depend on how the server implements these methods. While the standards suggest certain behaviors, developers sometimes use these methods in non-standard ways. For instance, a GET method might be used to delete data (making it both mutating and non-idempotent), or a POST method may be used to retrieve data (making it non-mutating and potentially idempotent). One infamous example of non-standard usage involved a blogger who implemented post deletion operations with HTTP GET, assuming no one would visit the blog. But when Google crawled the blog, all posts were deleted! It's also essential to remember that when it comes to security and preventing information leaks, neither GET nor POST is inherently secure. GET parameters are visible in the URL, while POST bodies, though not visible in the URL, can still be intercepted if not encrypted. To ensure secure data transmission, the use of HTTPS is advised, a topic we will discuss in more detail later. HTTP Keep-Alive vs TCP keepaliveWe’ve discussed how HTTP can initiate a persistent connection using “Connection: Keep-Alive”. Recall that in the issue about TCP, we’ve also mentioned TCP’s keepalive mechanism. Are they the same? No, they’re quite different:
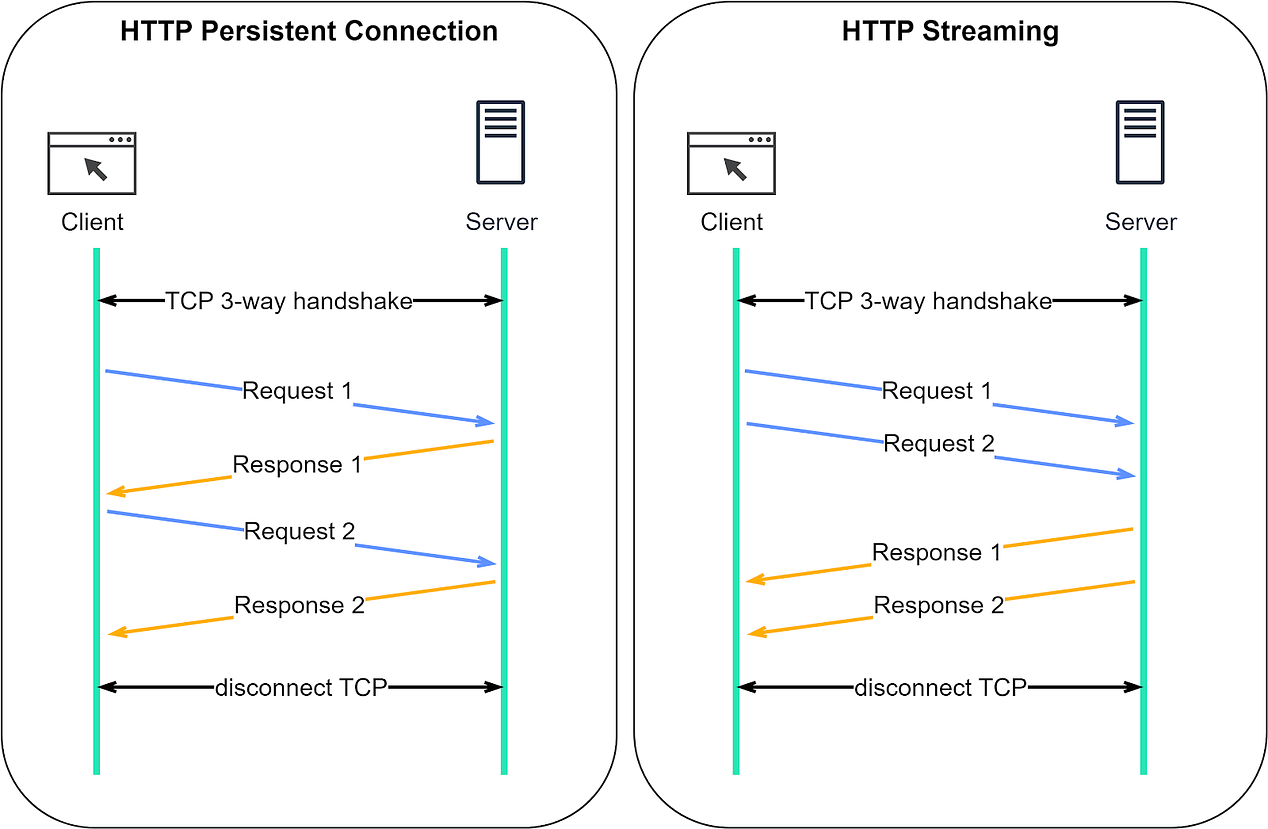
Let’s dive deeper. HTTP Keep-AliveHTTP, except for HTTP/3, is built on TCP. Establishing an HTTP connection requires a 3-way TCP handshake. After sending an HTTP request and receiving a response, the TCP connection disconnects. Sending multiple requests to the same server this way is quite inefficient. Wouldn’t it be better to reuse the same TCP connection? That’s the purpose of HTTP Keep-Alive. It maintains the TCP connection until either party requests disconnection. HTTP/1.1 enables HTTP Keep-Alive by default. HTTP Keep-Alive reduces the overhead of opening and closing TCP connections. It's even more powerful when combined with HTTP/2, which introduces the concept of “streams”. Streams allow us to send multiple requests simultaneously without waiting for server responses. More importantly, these requests and responses can be handled out of order, which is not possible with only HTTP Keep-Alive. The comparison diagram below shows the difference between HTTP Keep-Alive and HTTP/2 streams. Normally, we wait for the first response before sending a second request. With HTTP/2 streams, we can send multiple requests simultaneously without waiting for the first response, and the server can respond out of order. Why is this important? This feature is crucial to avoid head-of-line (HOL) blocking. In earlier versions of HTTP, if the server takes a long time to process one request, subsequent requests have to wait, leading to delays. But with HTTP/2 streams, each request is independent. Even if a server takes longer to process one request, it can still respond to other requests. Responses can come back as soon as they're ready, even if that means they're not in the original request order.
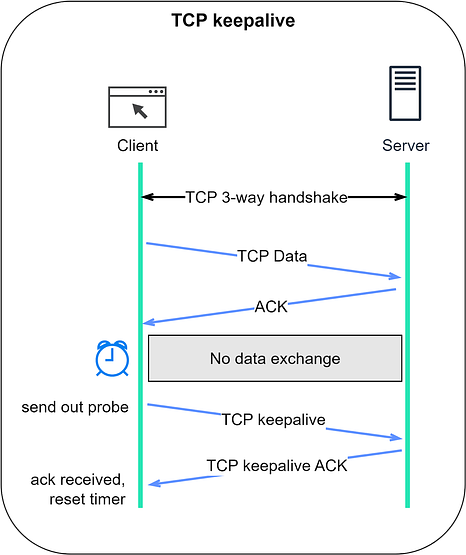
TCP keepaliveTCP keepalive is unrelated to HTTP Keep-Alive. In a TCP connection, both parties remain in the ESTABLISHED state until one ends it. If one party disconnects without notifying the other, the remaining party wouldn’t know about it. TCP keepalive addresses this by periodically sending probes when there’s no data exchange. We discussed this in our previous TCP issue. The following diagram should serve as a refresher.
Keep reading with a 7-day free trialSubscribe to ByteByteGo Newsletter to keep reading this post and get 7 days of free access to the full post archives. A subscription gets you:
© 2023 ByteByteGo
|
by "ByteByteGo" <bytebytego@substack.com> - 11:38 - 13 Jul 2023