- Mailing Lists
- in
- Uber’s Billion Trips Migration Setup with Zero Downtime
Archives
- By thread 5262
-
By date
- June 2021 10
- July 2021 6
- August 2021 20
- September 2021 21
- October 2021 48
- November 2021 40
- December 2021 23
- January 2022 46
- February 2022 80
- March 2022 109
- April 2022 100
- May 2022 97
- June 2022 105
- July 2022 82
- August 2022 95
- September 2022 103
- October 2022 117
- November 2022 115
- December 2022 102
- January 2023 88
- February 2023 90
- March 2023 116
- April 2023 97
- May 2023 159
- June 2023 145
- July 2023 120
- August 2023 90
- September 2023 102
- October 2023 106
- November 2023 100
- December 2023 74
- January 2024 75
- February 2024 75
- March 2024 78
- April 2024 74
- May 2024 108
- June 2024 98
- July 2024 116
- August 2024 134
- September 2024 130
- October 2024 141
- November 2024 171
- December 2024 115
- January 2025 216
- February 2025 140
- March 2025 220
- April 2025 233
- May 2025 239
- June 2025 303
- July 2025 74
Hi there, is Your Telecoms Consultant looking for a new CRM system?
How to deliver effective performance reviews
Uber’s Billion Trips Migration Setup with Zero Downtime
Uber’s Billion Trips Migration Setup with Zero Downtime
📅Meet your EOY deadlines – faster releases, zero quality compromises (Sponsored)
If slow QA processes and flaky tests are a bottleneck for your engineering team, you need QA Wolf. Their AI-native platform, backed by full-time QA engineers, enables their team to create tests 5x faster than anyone else. New tests are created in minutes and existing tests are updated almost instantaneously. ✔️Unlimited parallel test runs 🛒Also available through AWS, GCP, and Azure marketplaces. Disclaimer: The details in this post have been derived from the Uber Technical Blog. All credit for the technical details goes to the Uber engineering team. The links to the original articles and other references are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them. Maintaining uptime during system upgrades or migrations is essential, especially for high-stakes, real-time platforms like Uber's trip fulfillment system. Uber relies on consistent, immediate responsiveness to manage millions of trip requests and transactions daily. The implications of downtime for a platform like Uber are scary: even a brief service interruption could lead to lost revenue, user dissatisfaction, and huge reputational damage. However, Uber faced the daunting challenge of migrating its complex fulfillment infrastructure from an on-premises setup to a hybrid cloud environment. This task not only required a deep understanding of system architecture but also an approach that could guarantee zero downtime, ensuring that millions of riders, drivers, and partners worldwide would experience uninterrupted service during the transition. In this article, we’ll look at Uber's zero-downtime migration strategy. We’ll also learn more about the technical solutions they implemented and the challenges they faced in the process. The Complexity of Uber’s Trip Fulfillment PlatformUber’s fulfillment system, before it migrated to a hybrid cloud setup, was designed to handle vast amounts of real-time data and high transaction volumes. At its core, the fulfillment system managed the interactions between millions of riders, drivers, couriers, and other service elements, processing over two million transactions per second. Some stats to describe the system’s importance are as follows:
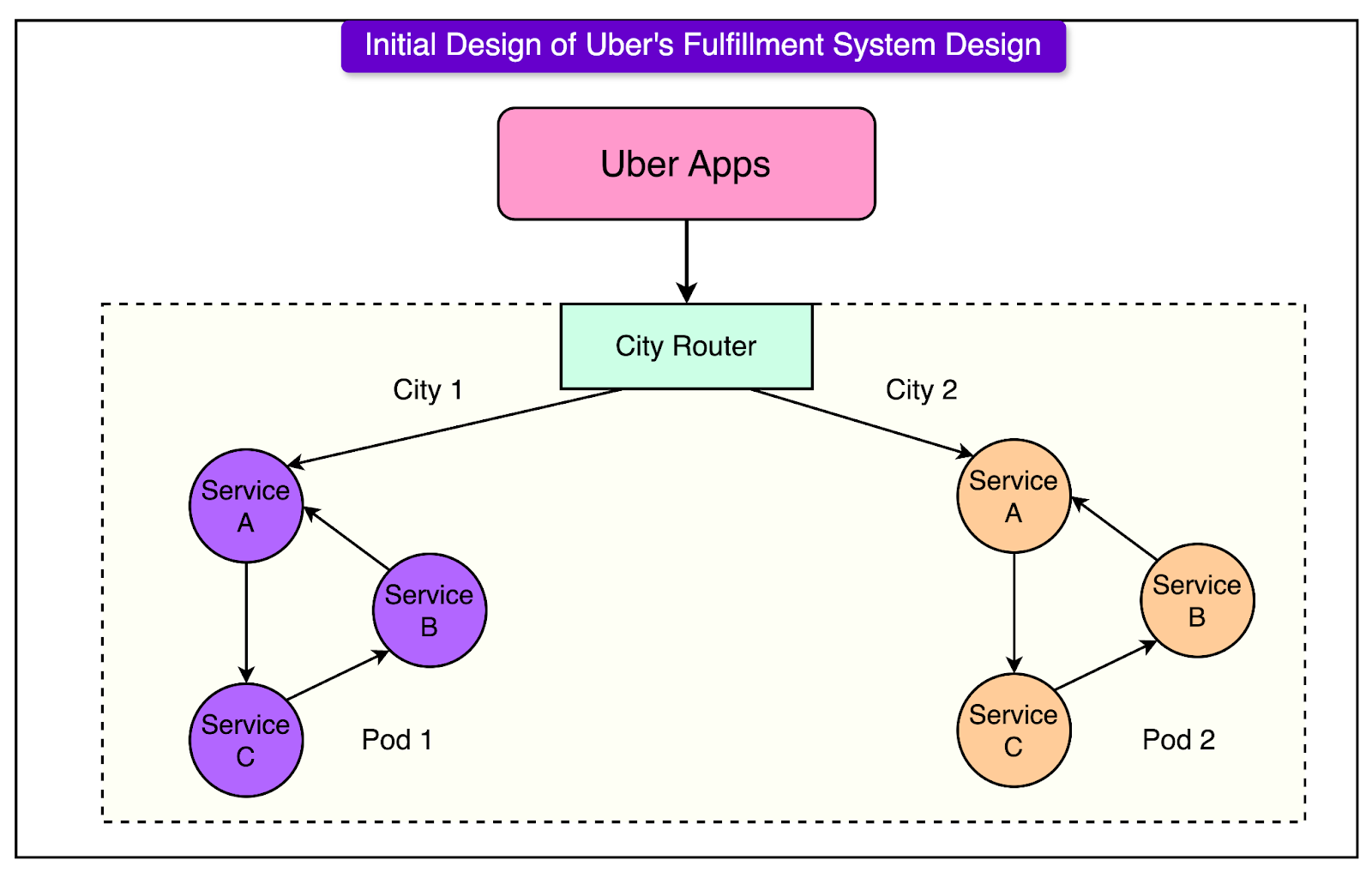
The architecture was organized into “pods”, where each pod was a self-contained unit of services dedicated to a particular city or geographic region. See the diagram below:
For reference, a pod is a self-sufficient unit with many services interacting with each other to handle fulfillment for a single city. Once a request enters a pod, it remains within the services in the pod unless it requires access to data from services outside the pod. Within each pod, services were divided into “demand” and “supply” systems. The demand and supply services were shared-nothing microservices with the entities stored in Apache Cassandra and Redis key-value tables.
These services stayed synchronized using distributed transactional techniques to ensure that trip-related data remained consistent within each pod. Uber employed the saga pattern for this. Entity consistency within each service was managed through in-memory data management and serialization. Architectural Limitations and Scalability IssuesThe initial architecture was designed to prioritize availability, sacrificing some aspects of strict data consistency to maintain a robust user experience. However, as Uber’s operations expanded, these architectural choices created bottlenecks:
Learn the Roadmap to making $100k using LinkedIn & AI 🚀(Sponsored)
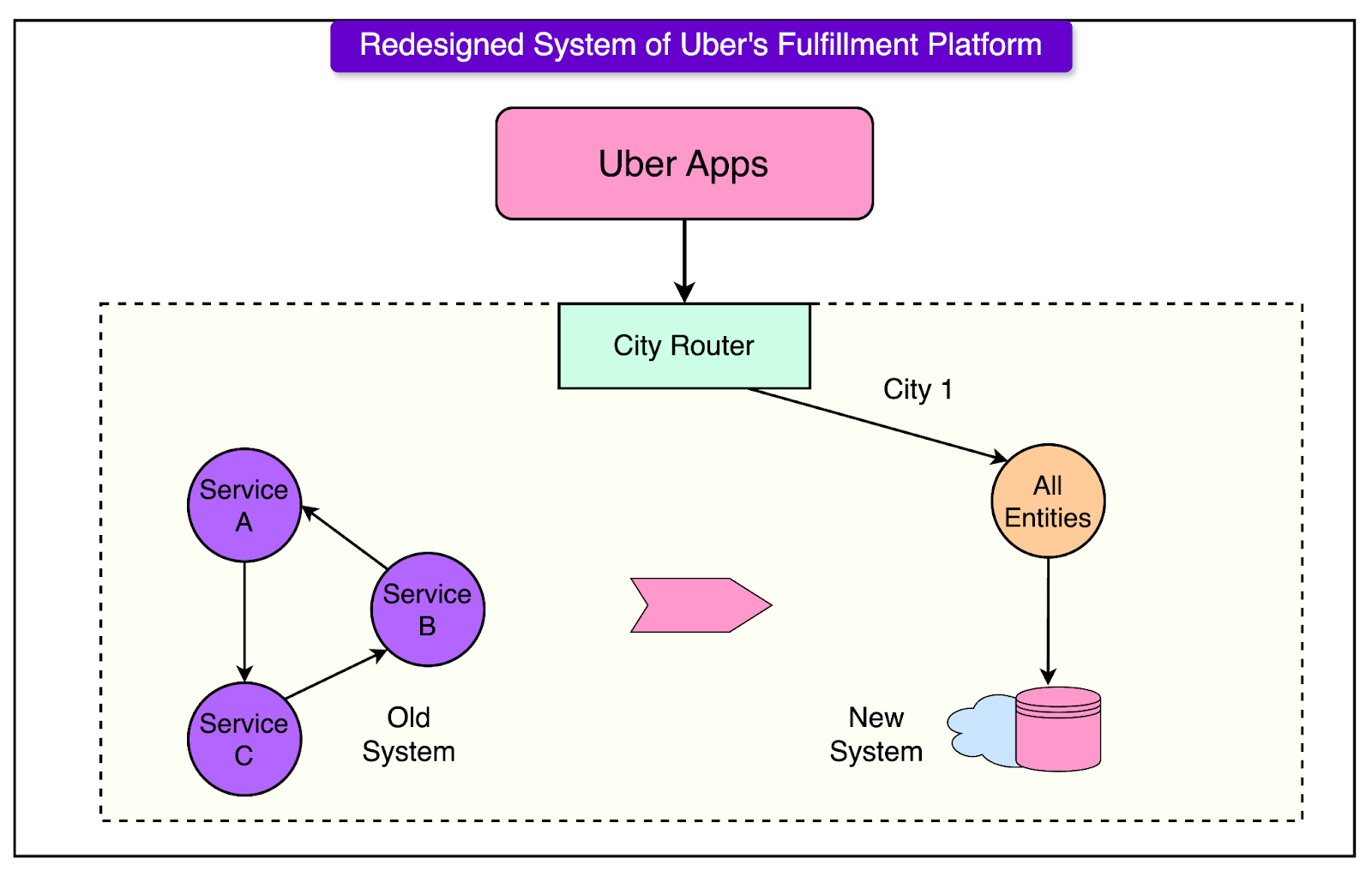
LinkedIn isn’t just a social platform—it’s a goldmine when you combine it with AI. In his AI Powered LinkedIn Workshop, you will learn how to harness the power of LinkedIn as a founder, marketer, business owner, or salaried professional. In this workshop, you will learn about how to: 👉 Automate lead generation to grow your business while you sleep 👉 Leverage AI to land high-paying jobs without wasting hours on application 👉 Master his $100K LinkedIn Outbound Strategy to boost revenue effortlessly 👉 Use AI to create and distribute content, saving you hours every week This workshop is the real deal for anyone who wants to dominate LinkedIn in 2024 and beyond.But it’s only FREE for the first 100 people. After that, the price jumps back to $399. The Redesigned ArchitectureIn the redesigned system architecture, the Uber engineering team shifted from a distributed, in-memory setup to a more centralized, cloud-backed infrastructure. The new system consolidated the previously separate “demand” and “supply” services into a single application layer supported by a cloud database. By moving data management to a datastore layer, the new system streamlined operations and improved scalability and consistency. See the diagram below to understand the new architecture:
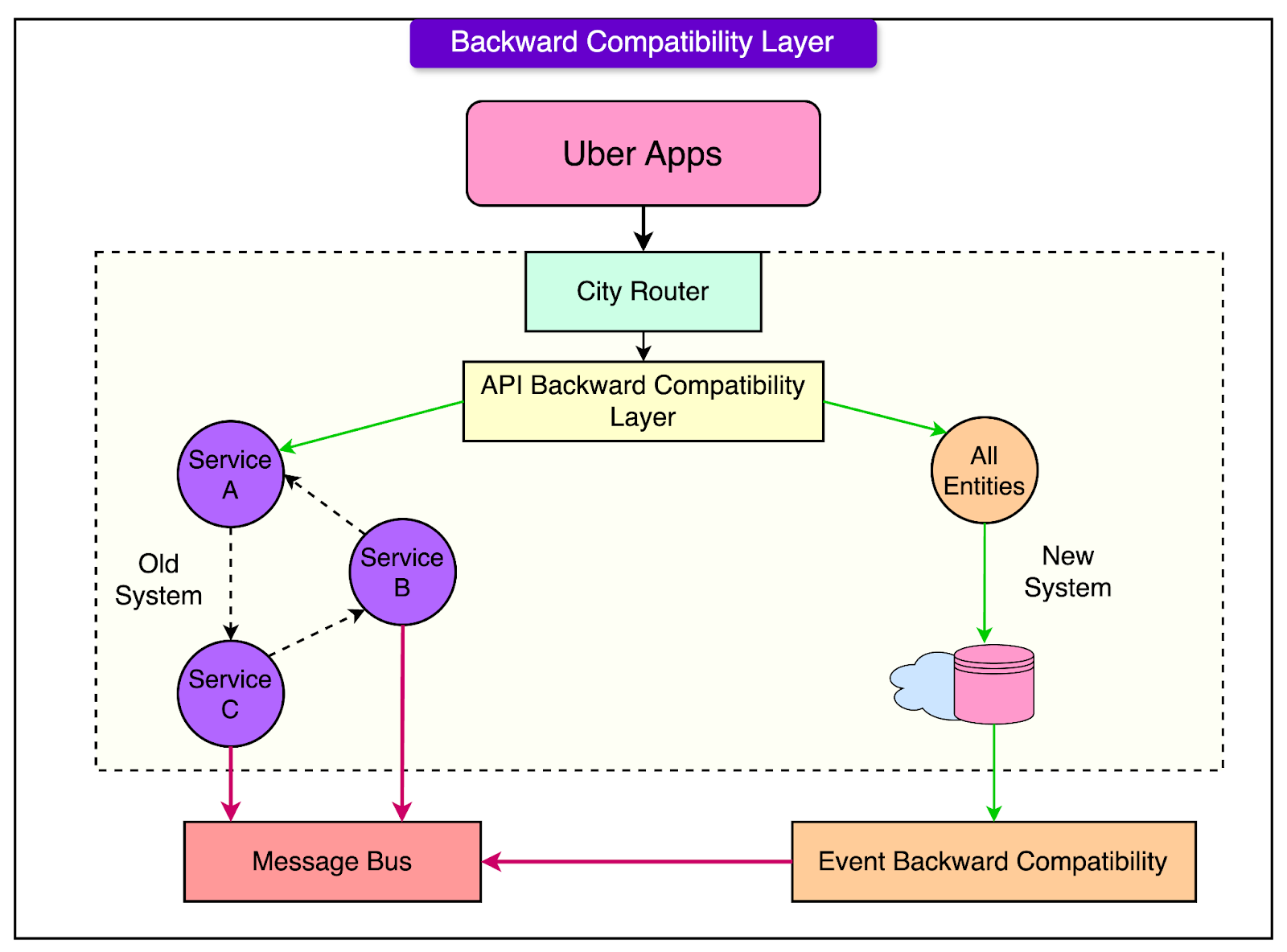
Key Solutions Implemented By UberWhile designing the new solution had its share of the complexity, the real challenge was migrating the workload to the new design. Some of the key solutions implemented by Uber’s engineering team to achieve zero downtime migration to the new system are as follows: 1 - Backward Compatibility LayerUber implemented a backward compatibility layer as a core component of its zero-downtime migration strategy. This layer served as a bridge, allowing existing APIs and event contracts to function normally while Uber transitioned to a new system architecture. By supporting the old API contracts and event schemas, the backward compatibility layer ensured that many internal and external consumers of Uber’s APIs could continue to operate without modification. See the diagram below to understand the role of the backward compatibility layer.
Some of the benefits of the backward compatibility layer are as follows:
However, there were also some downsides to this:
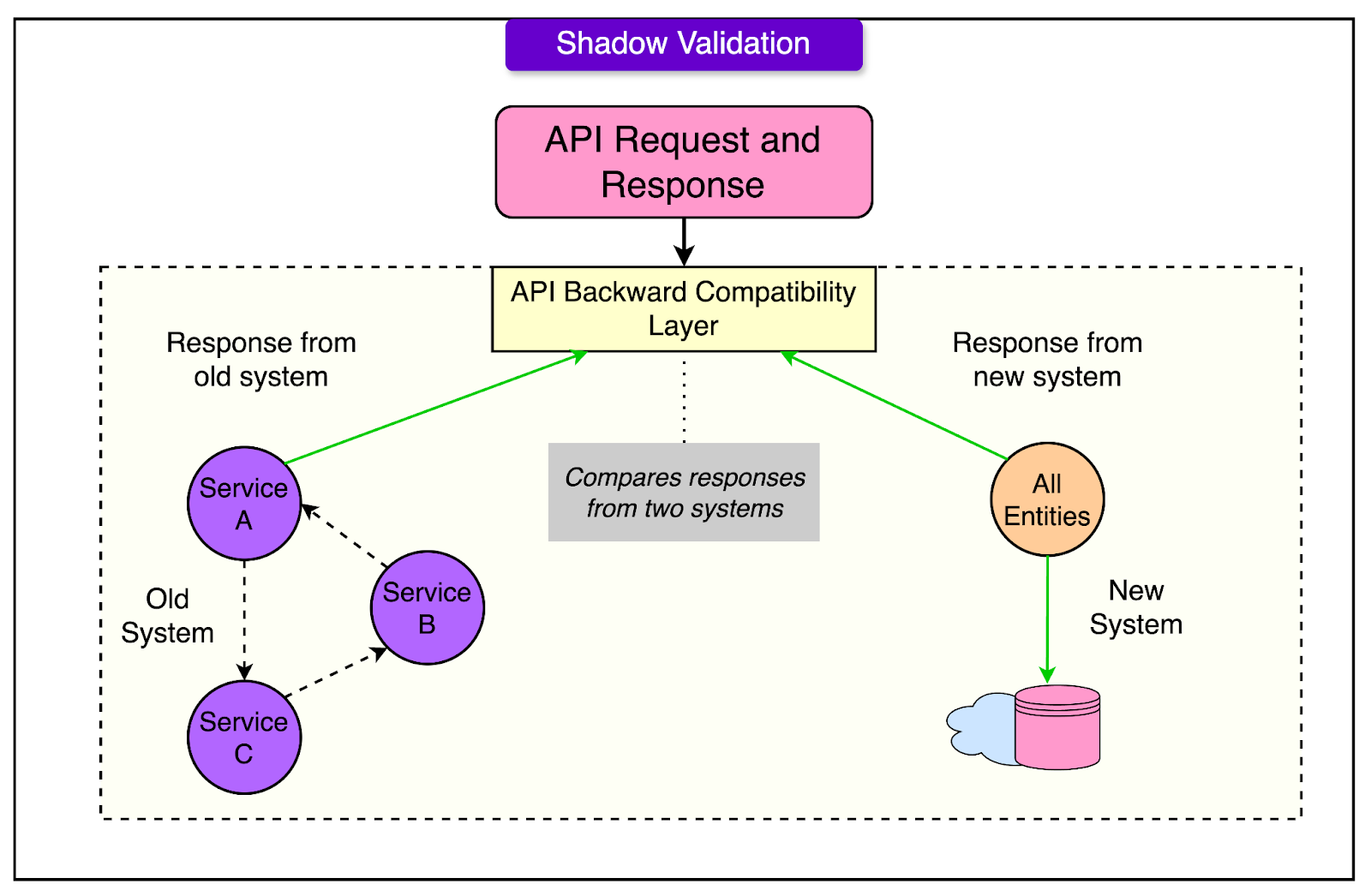
2 - Shadow ValidationShadow validation was integrated into Uber’s high-transaction, real-time platform. Each request sent to the old system was mirrored in the new one, and responses from both were compared on a key-value basis. Discrepancies were logged and analyzed within Uber’s observability framework, with differences captured in a dedicated observability system for further examination.
This comparison was not simply binary; Uber allowed for certain predefined tolerances and exceptions to accommodate unavoidable variances, such as transient data changes or slight delays due to processing orders. When differences between systems arose, Uber took a two-fold approach:
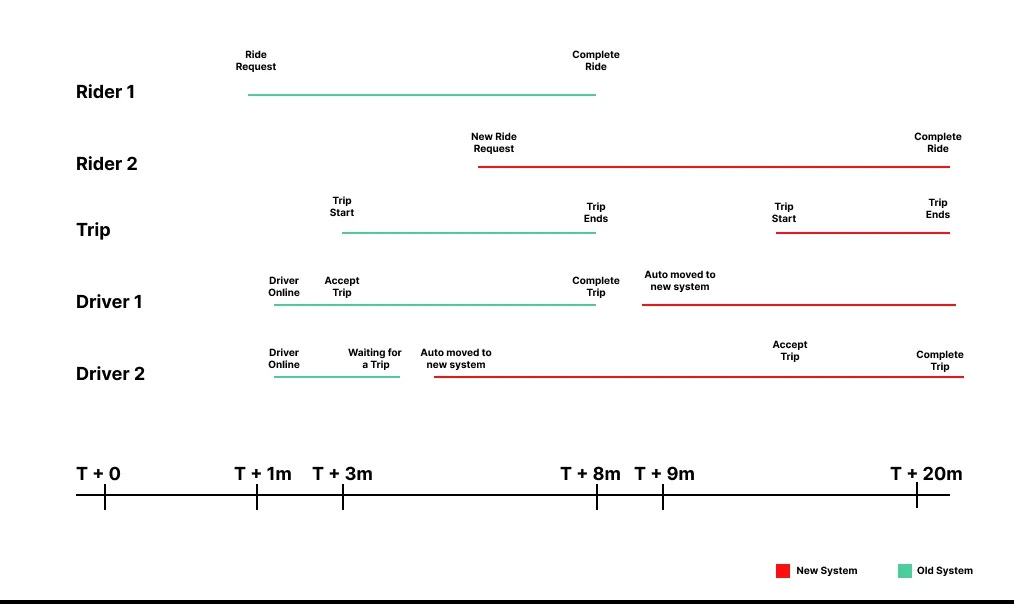
Migration PhaseLet’s now understand how Uber carried out the migration. 1 - Pre-Rollout PreparationsUber’s pre-rollout preparation steps were foundational to achieving a smooth, zero-downtime migration for their trip fulfillment platform. Each step, such as shadow validation, end-to-end (E2E) testing, load testing, and database warm-up, played a critical role in minimizing potential risks and ensuring the new system would perform reliably under real-world conditions. Some of the key activities that were performed are as follows: End-to-End (E2E) TestingE2E testing enabled Uber to verify the complete functionality of the new system from start to finish. It was essential to identify potential integration issues or bottlenecks. By simulating realistic user journeys, these tests checked that all workflows, integrations, and dependencies performed as expected under different scenarios. Load TestingLoad testing subjected the new system to simulated traffic levels that matched or exceeded actual usage, evaluating its capacity to handle high transaction volumes without degradation. Load testing confirmed that the new system could withstand Uber’s high operational demands, from peak traffic to unexpected surges. It allowed Uber to preemptively address any performance issues, such as latency or system overload, under stress conditions. Database Warm-UpDatabase warm-up involved generating synthetic data loads to pre-fill caches and split partitions, ensuring the database was primed for full production traffic from the start. For Uber, whose cloud database had to handle rapid scaling, database warm-up prevented “cold-start” issues by ensuring that common queries and data partitions were already optimized for performance. This step reduced the chance of initial slowdowns or resource bottlenecks during migration. 2 - Traffic Pinning and Phased RolloutsUber employed a traffic pinning and phased rollout strategy to migrate specific trips incrementally to the new system to reduce the risk of inconsistencies This approach allowed Uber to gradually shift parts of its trip fulfillment platform to the new architecture. Technical Process of Traffic Pinning and Phased RolloutTraffic pinning ensured that each trip’s data was processed by a single system—either the old or the new—throughout its lifecycle. This was critical for preventing data fragmentation and ensuring consistent trip updates, as each trip involves multiple interactions, such as driver updates, route changes, and fare calculations. To achieve this, Uber developed a routing logic to “pin” ongoing trips to the system where they were initiated. Before migration, consumer identifiers for riders and drivers were recorded, enabling Uber to route each interaction related to a given trip back to its origin system, preventing mid-trip transitions that could lead to data mismatches. This tracking persisted until the trip was completed, after which riders and drivers were gradually transitioned to the new system for future trips. The diagram below demonstrates the concept of traffic pinning.
Initially, Uber migrated less critical or idle riders and drivers to the new system, followed by active trips in specific cities. Over time, this phased approach allowed Uber to monitor and control the migration, expanding it to cover larger segments and eventually all active users. The key benefits of traffic pinning are as follows:
Key Observability and Rollback MechanismsUber developed detailed dashboards and monitoring tools to track metrics like trip volume, trip completion rates, driver availability, and overall system load. These dashboards provided visibility into performance and data consistency across both systems, allowing engineers to observe how traffic gradually drained from the old system while increasing in the new one. The goal was that the overall aggregate metrics should remain flat. Key metrics, including transaction success rates, latency, and error rates, were monitored at city-level granularity to catch any localized disruptions. These observability tools also enabled Uber to spot irregularities in real-time. For example, if completion rates dropped in a specific city, engineers could quickly investigate and determine whether the issue originated from the new system. The tools flagged critical problems that could trigger a rollback for specific regions, allowing Uber to maintain stability while continuing the migration elsewhere. The rollback mechanism was equally important. Uber could reverse traffic flow for any region back to the old system if metrics indicated significant deviations from expected performance. ConclusionUber’s zero-downtime migration approach highlights key technical strategies for complex, large-scale migrations.
Despite its success, Uber’s approach faced challenges, such as the high infrastructure demand of maintaining dual systems and the complexity of managing large-scale observability. References:
SPONSOR USGet your product in front of more than 1,000,000 tech professionals. Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases. Space Fills Up Fast - Reserve Today Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com © 2024 ByteByteGo
|


by "ByteByteGo" <bytebytego@substack.com> - 11:36 - 19 Nov 2024