- Mailing Lists
- in
- Unlock Highly Relevant Search with AI
Archives
- By thread 5369
-
By date
- June 2021 10
- July 2021 6
- August 2021 20
- September 2021 21
- October 2021 48
- November 2021 40
- December 2021 23
- January 2022 46
- February 2022 80
- March 2022 109
- April 2022 100
- May 2022 97
- June 2022 105
- July 2022 82
- August 2022 95
- September 2022 103
- October 2022 117
- November 2022 115
- December 2022 102
- January 2023 88
- February 2023 90
- March 2023 116
- April 2023 97
- May 2023 159
- June 2023 145
- July 2023 120
- August 2023 90
- September 2023 102
- October 2023 106
- November 2023 100
- December 2023 74
- January 2024 75
- February 2024 75
- March 2024 78
- April 2024 74
- May 2024 108
- June 2024 98
- July 2024 116
- August 2024 134
- September 2024 130
- October 2024 141
- November 2024 171
- December 2024 115
- January 2025 216
- February 2025 140
- March 2025 220
- April 2025 233
- May 2025 239
- June 2025 303
- July 2025 182
This month’s Remote Global update features two major announcements, insights on remote work, and an on-demand webinar to boost your contractor skills.
COP28: Driving climate action and growth
Unlock Highly Relevant Search with AI
Unlock Highly Relevant Search with AI
Latest articlesIf you’re not a subscriber, here’s what you missed this month.
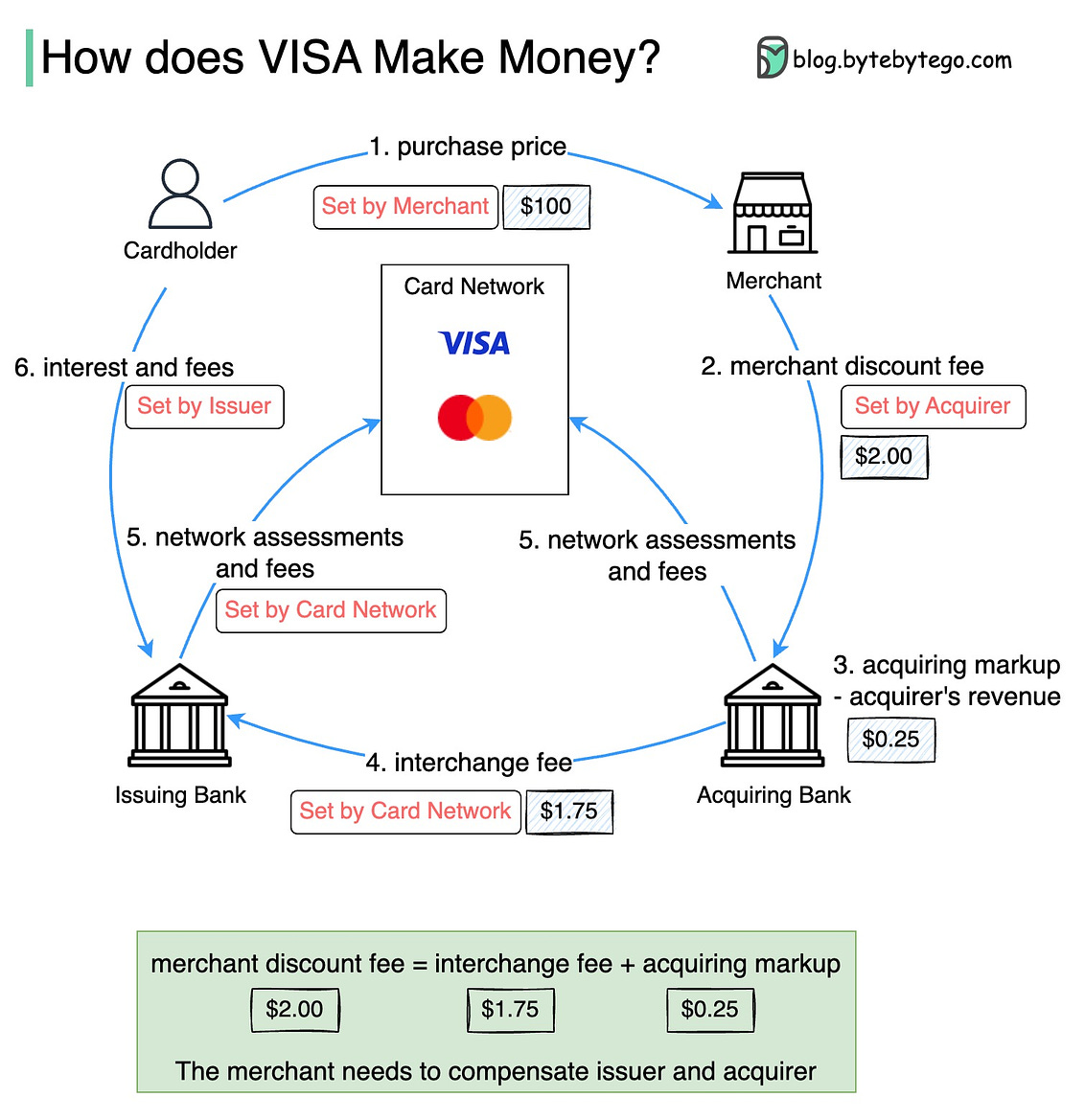
To receive all the full articles and support ByteByteGo, consider subscribing: We are considering launching a new ‘How We Built This’ series where we take a behind-the-scenes look at how innovative companies have created scalable, high-performing systems and architectures. Let us know if this is something you’d be interested in reading! In today’s issue, we are fortunate to host guest contributor Marcelo Wiermann, Head of Engineering at Y Combinator startup Cococart. He’ll be sharing insights into Cococart’s use of semantic search to power new in-store experiences. How agile teams can leverage LLMs, Vector Databases, and friends to quickly launch cutting-edge semantic search experiences for fame & profit
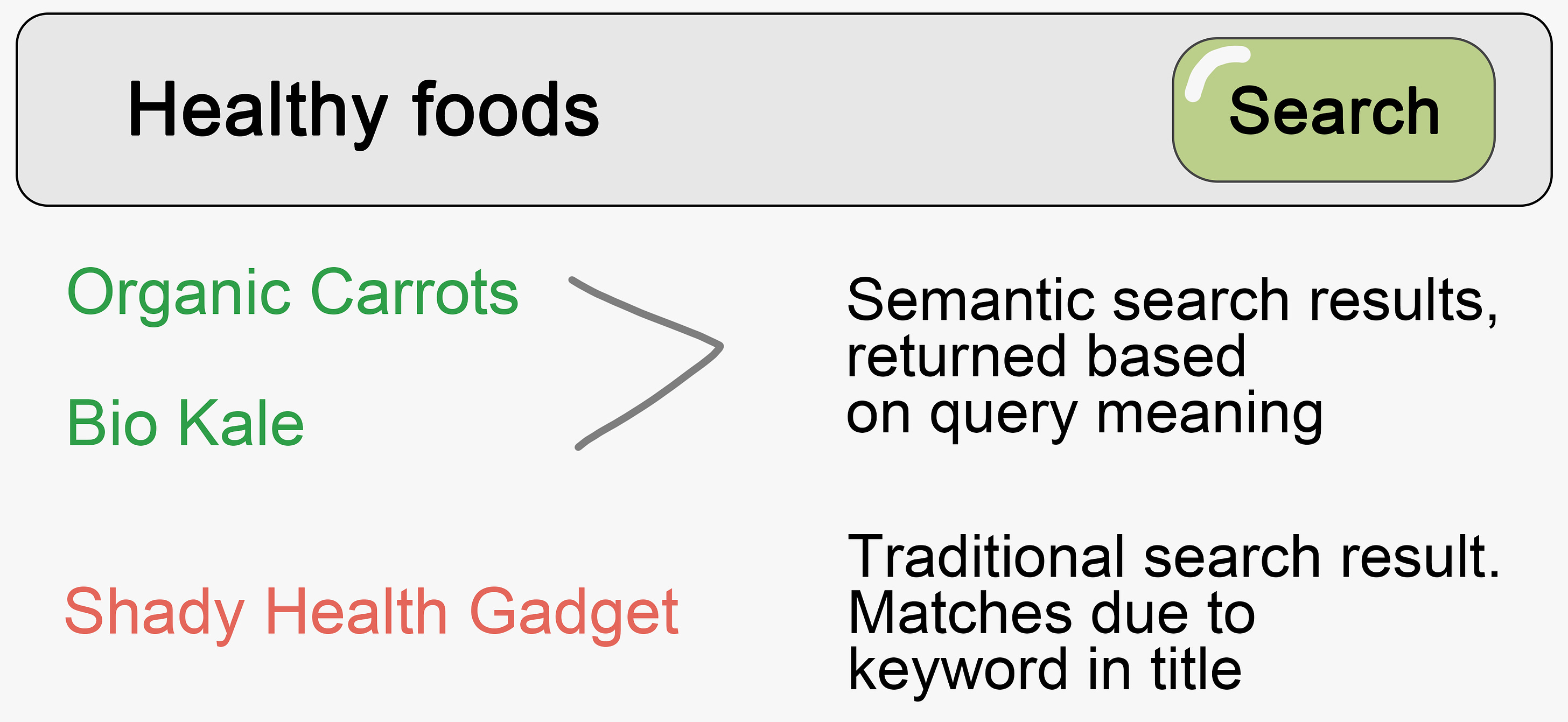
It’s remarkable how so many things are made better with great search. Google made it easy for normal folks to find whatever they needed online, no matter how obscure. IntelliJ IDEA’s fuzzy matching and symbol search helped programmers forget the directory structure of their code bases. AirTag added advanced spatial location capabilities to my cat. A well-crafted discovery feature can add that “wow” factor that iconic, habit-forming products have. In this post, I’ll cover how a fast-moving team can leverage Large Language Models (LLMs), Vector Databases, Machine Learning, and other technologies to create a wow-inspiring search and discovery experience with startup budget and time constraints. Semantic SearchSemantic Search is a search method for surfacing highly relevant results based on the meaning of the query, context, and content. It goes beyond simple keyword indexing or filtering. It allows users to find things more naturally and with better support for nuance than highly sophisticated but rigid traditional relevancy methods. In practice, it feels like the difference between asking a real person or talking to a machine. Tech companies across the world are racing to incorporate these capabilities into their existing products. Instacart published an extensive article on how they added semantic deduplication to their search experience. Other companies implementing some form of semantic search include eBay, Shopee, Ikea, Walmart, and many more.
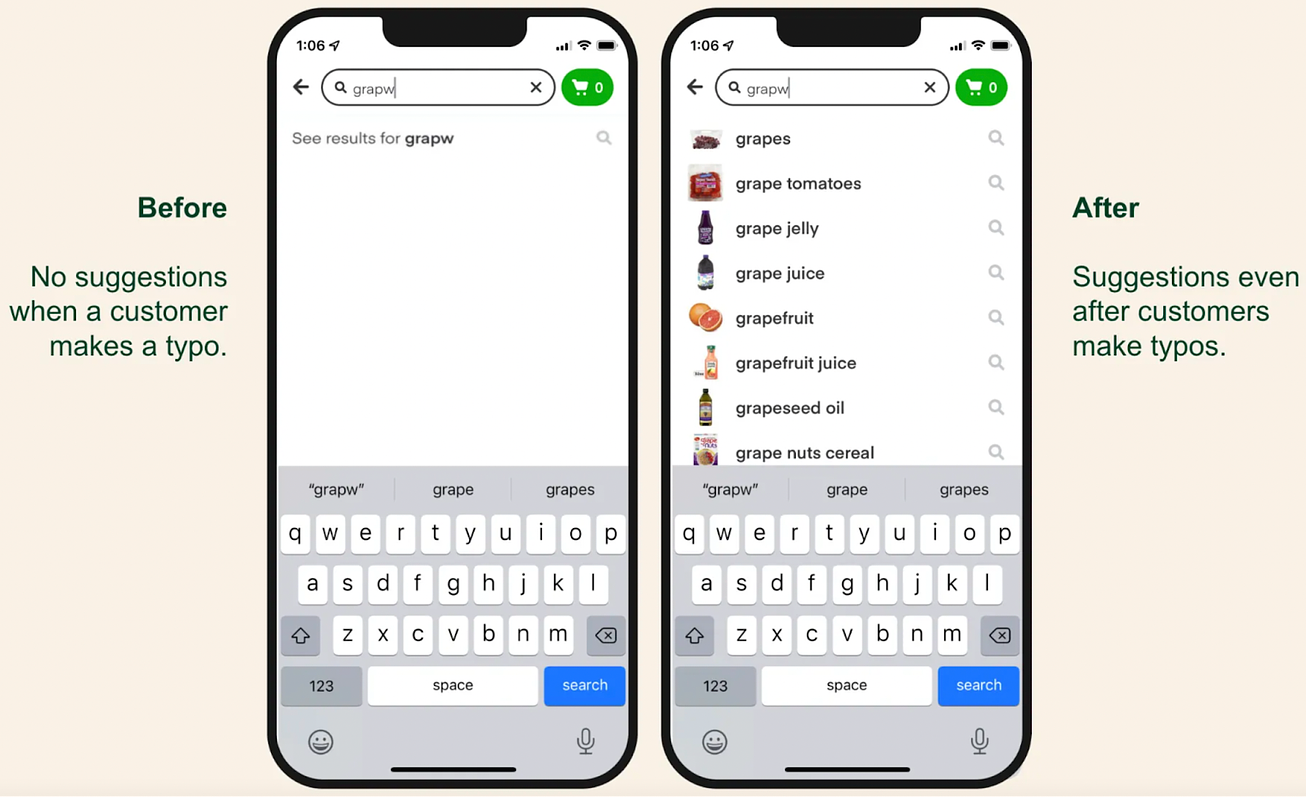
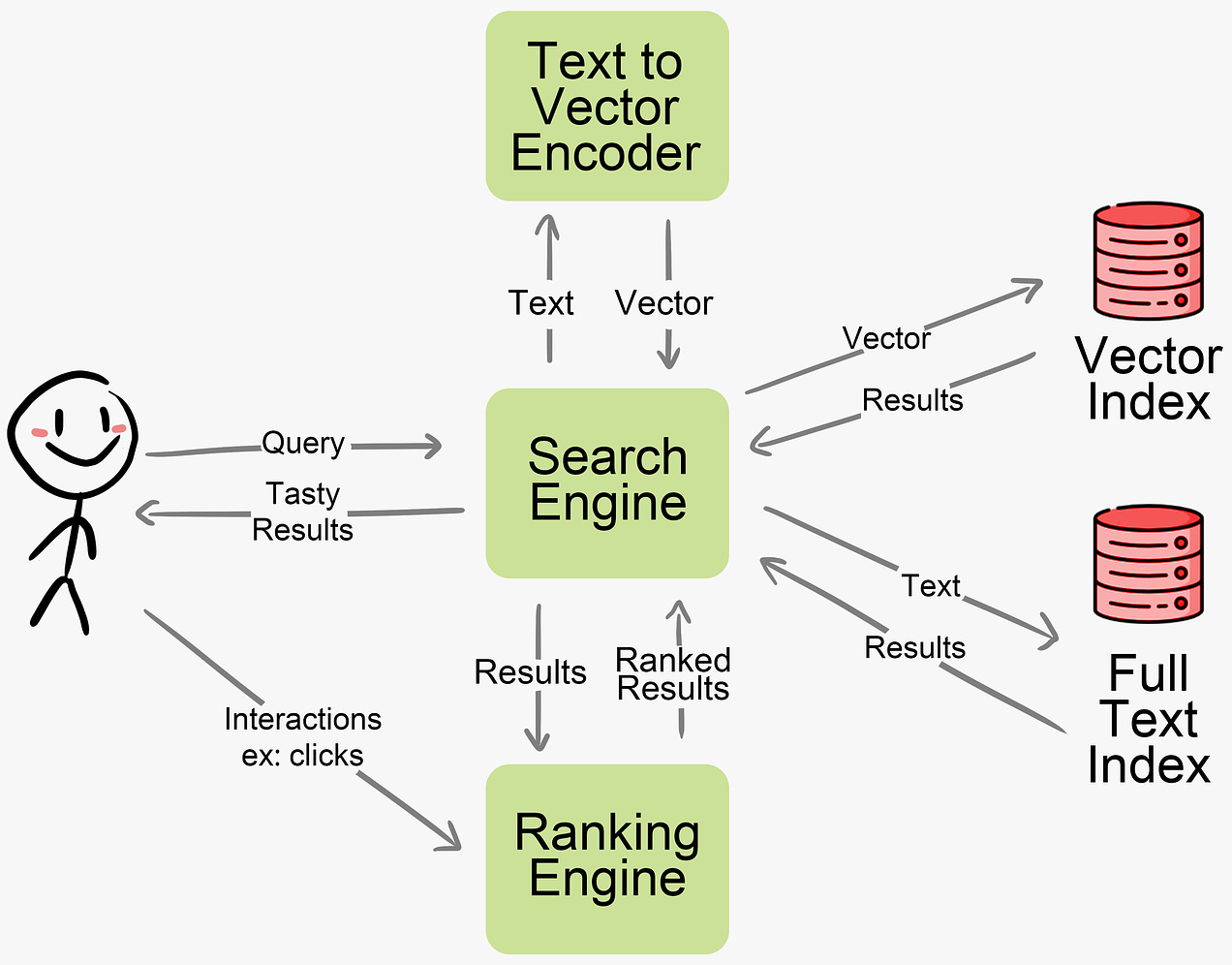
The motivation for embracing semantic search is simple: more relevant results lead to happier customers and more revenue. Discovery, relevancy, and trustworthiness are some of the hardest problems to solve in e-commerce. An entire ecosystem of solutions exists to help companies address these challenges. Many solutions today rely on document embeddings - representing meaning as vectors. Since semantic search alone may not provide sufficient relevant hits, traditional full-text search is often used to supplement resuts. A feedback loop based on user interactions (clickes, likes, etc.) provides input to continuously improve relevancy. The key processes are: indexing, querying, and tracking
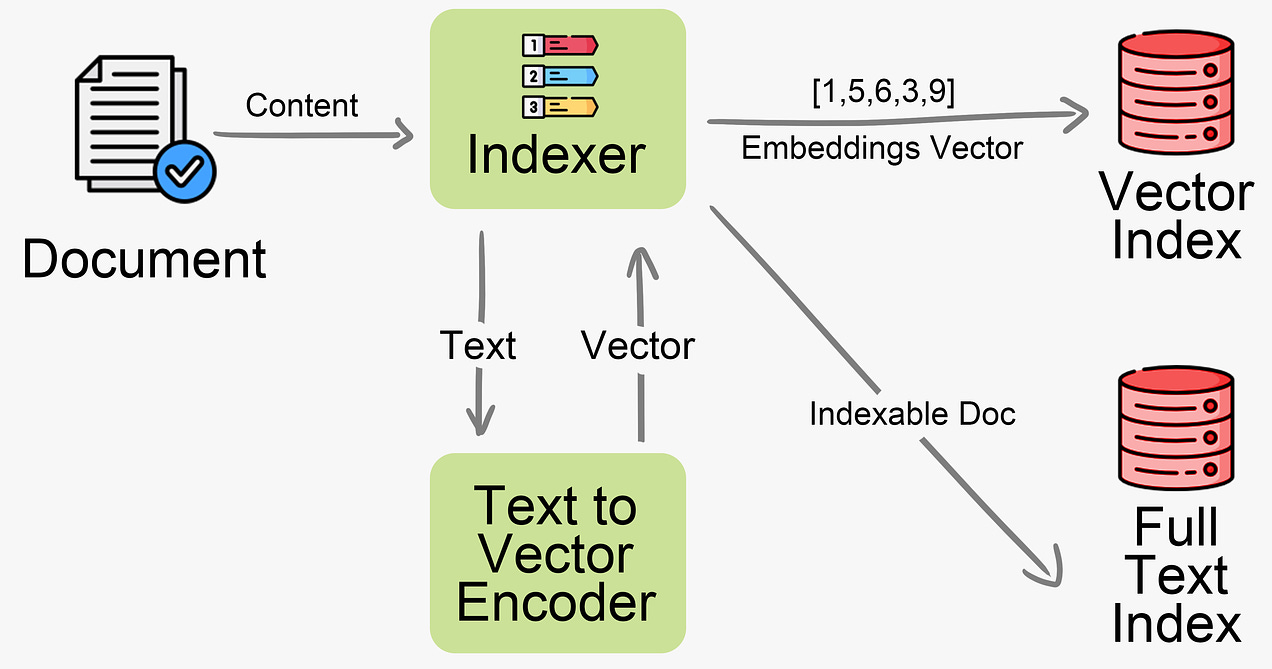
Indexing is done by converting a document’s content to an embeddings vector through a text-to-vector encoder (e.g. OpenAI’s Embeddings API). The vectors are inserted into a vector database (e.g. Qdrant, Milvus, Pinecone). Text-to-vector encoding models like sentence-transformers convert text snippets into numeric vector representations that capture semantic meaning and similarities between text. Documents are also indexed in a traditional full-text search engine (e.g. Elasticsearch)
Keep reading with a 7-day free trialSubscribe to ByteByteGo Newsletter to keep reading this post and get 7 days of free access to the full post archives. A subscription gets you:
© 2023 ByteByteGo
|
by "ByteByteGo" <bytebytego@substack.com> - 11:40 - 30 Nov 2023