- Mailing Lists
- in
- Where to get started with GenAI
Archives
- By thread 5201
-
By date
- June 2021 10
- July 2021 6
- August 2021 20
- September 2021 21
- October 2021 48
- November 2021 40
- December 2021 23
- January 2022 46
- February 2022 80
- March 2022 109
- April 2022 100
- May 2022 97
- June 2022 105
- July 2022 82
- August 2022 95
- September 2022 103
- October 2022 117
- November 2022 115
- December 2022 102
- January 2023 88
- February 2023 90
- March 2023 116
- April 2023 97
- May 2023 159
- June 2023 145
- July 2023 120
- August 2023 90
- September 2023 102
- October 2023 106
- November 2023 100
- December 2023 74
- January 2024 75
- February 2024 75
- March 2024 78
- April 2024 74
- May 2024 108
- June 2024 98
- July 2024 116
- August 2024 134
- September 2024 130
- October 2024 141
- November 2024 171
- December 2024 115
- January 2025 216
- February 2025 140
- March 2025 220
- April 2025 233
- May 2025 239
- June 2025 303
- July 2025 12
Where to get started with GenAI
Where to get started with GenAI
How to monitor AWS container environments at scale (Sponsored)In this eBook, Datadog and AWS share insights into the changing state of containers in the cloud and explore why orchestration technologies are an essential part of managing ever-changing containerized workloads.
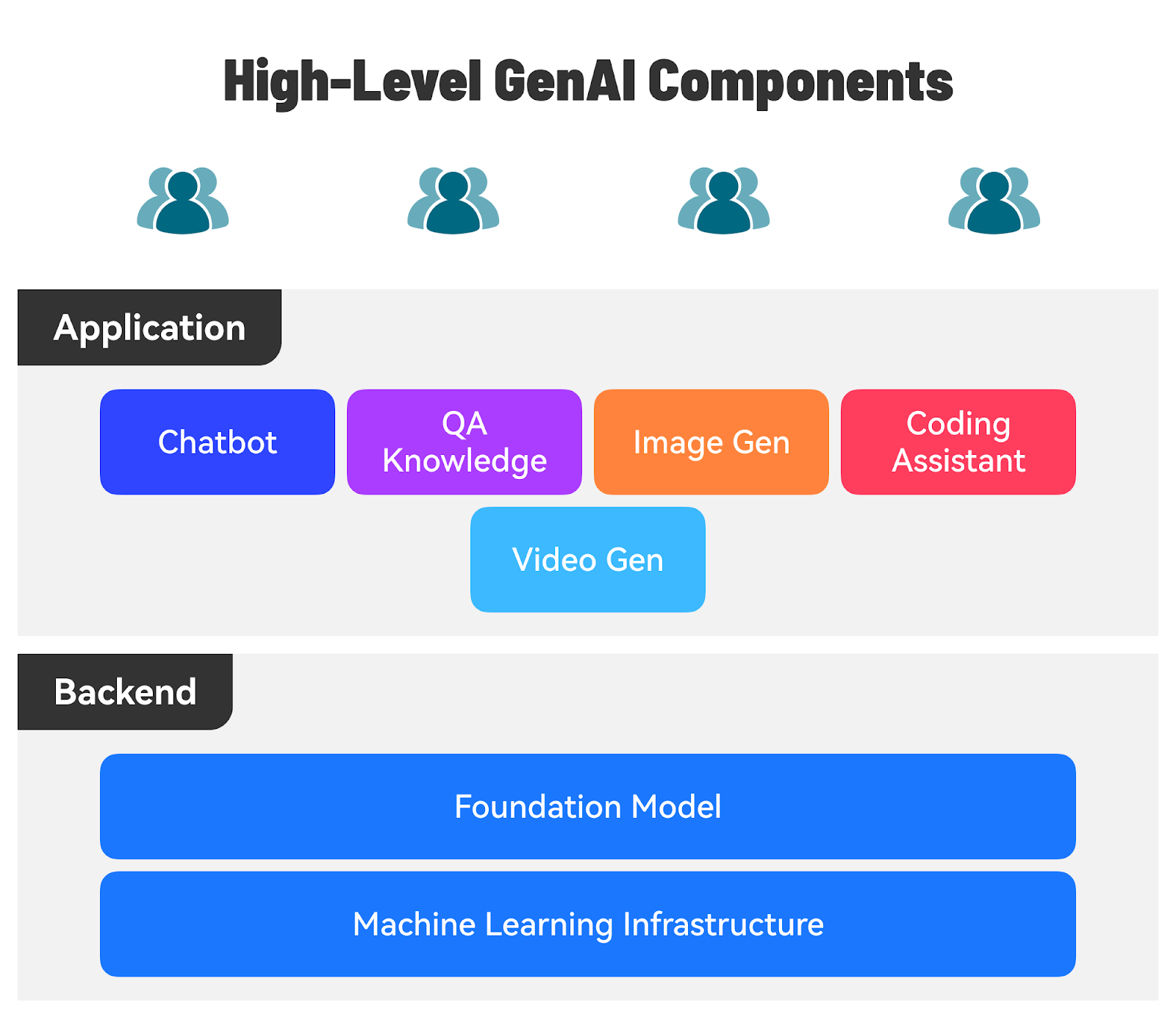
Introduction to Generative AIThe world of Generative AI (GenAI) is moving at a breakneck pace. New models, techniques, and applications emerge every day, pushing the boundaries of what's possible with artificial intelligence. Considering this fast-evolving landscape, developers and technology professionals need to keep their skills sharp and stay ahead of the curve. To help you get started with GenAI, Priyanka Vergadia and I have put together a concise guide covering essential steps, including:
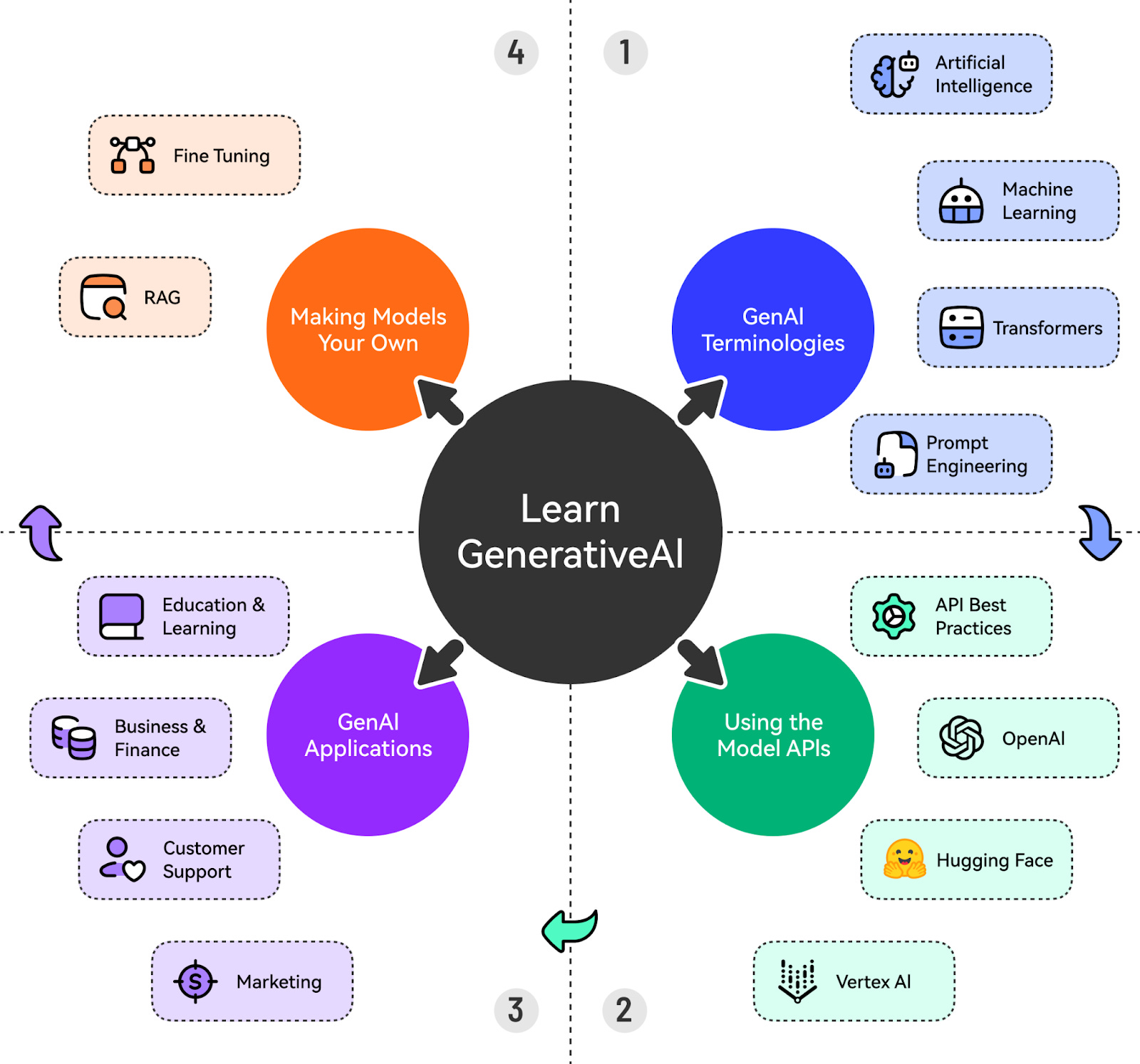
Here’s a sneak peek at all the cool topics we will cover.
Let’s start with the first step. Also, don't forget to follow Priyanka Vergadia’s LinkedIn, which is a must-read for anyone working on cloud and GenAI. Understanding the GenAI TerminologiesOne of the biggest obstacles to getting started with GenAI is not understanding the basic terminologies. Let’s cover the most important things to know about.
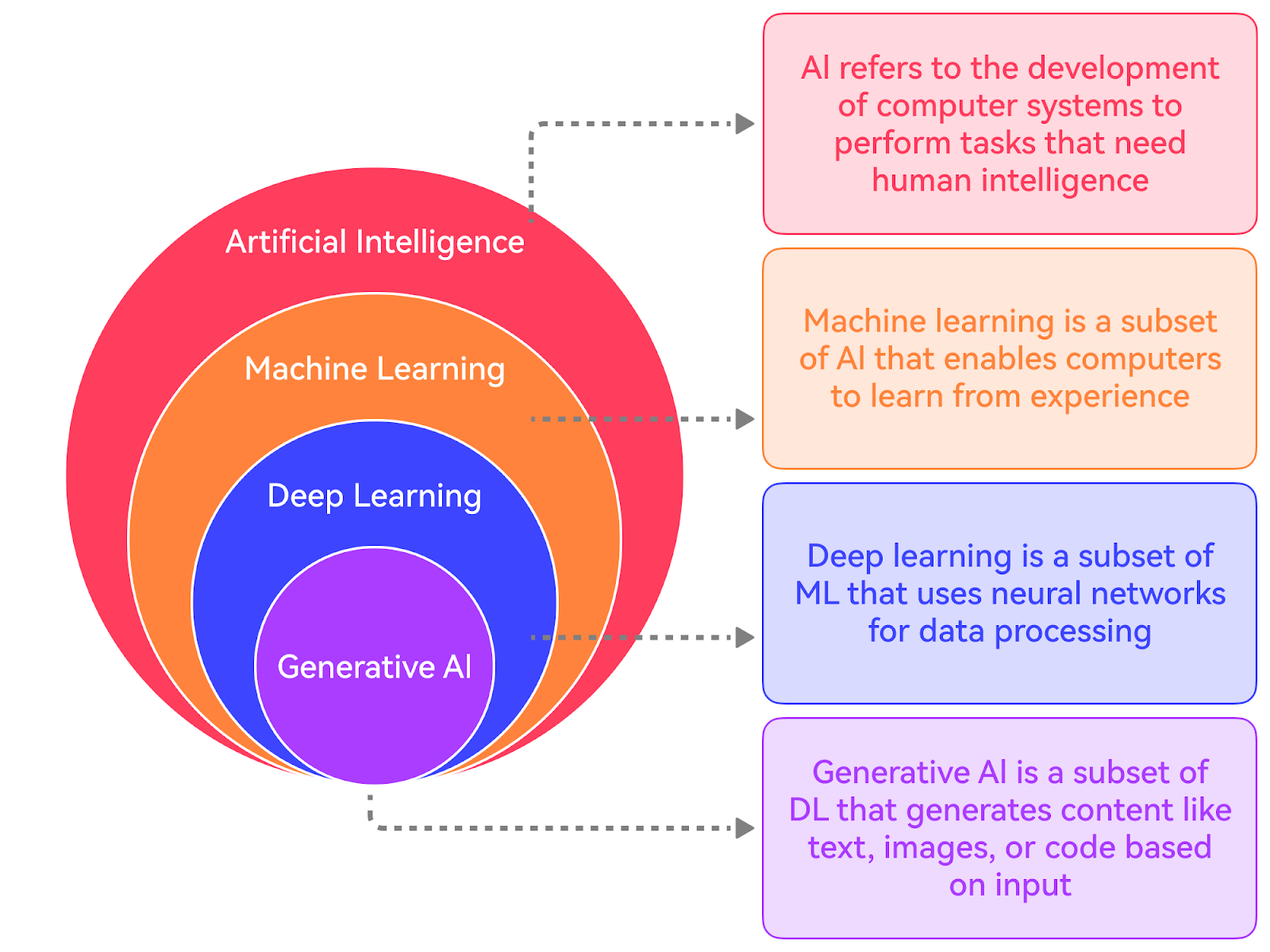
Artificial IntelligenceAI refers to the development of computer systems that can perform tasks that typically require human intelligence. It is a discipline like Physics. It encompasses various subfields, such as Machine Learning, Natural Language Processing, Computer Vision, etc. AI systems can be narrow (focused on specific tasks) or general (able to perform a wide range of tasks). Machine LearningMachine Learning is a subset of AI that focuses on enabling computers to learn and improve from experience without being explicitly programmed. It involves training models on data to recognize patterns, make predictions, or take actions. There are three main types of ML:
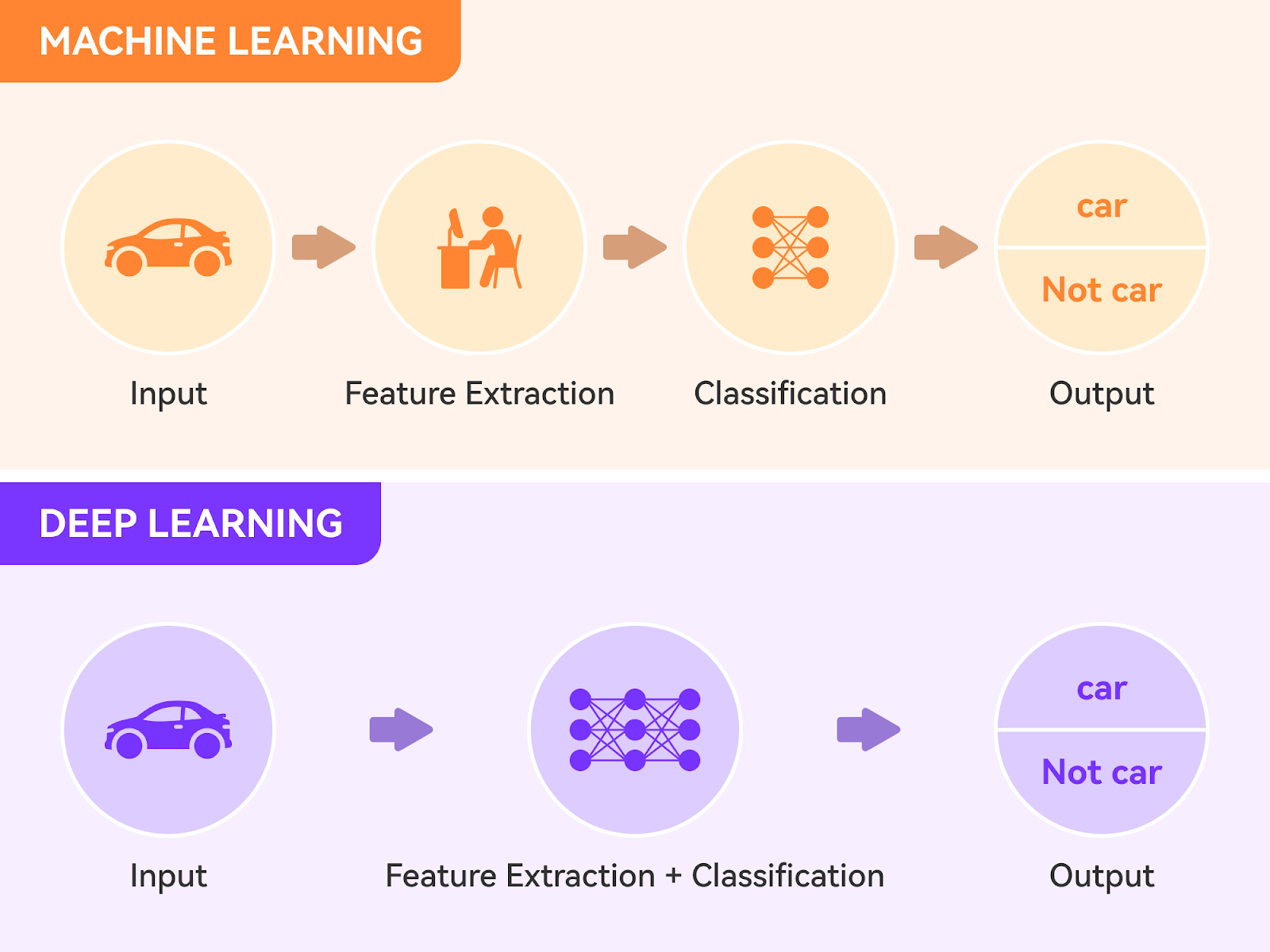
Lastly, there is Deep Learning, which uses artificial neural networks and is a subfield of Machine Learning. The diagram below shows the key difference between a typical machine learning workflow and Deep Learning.
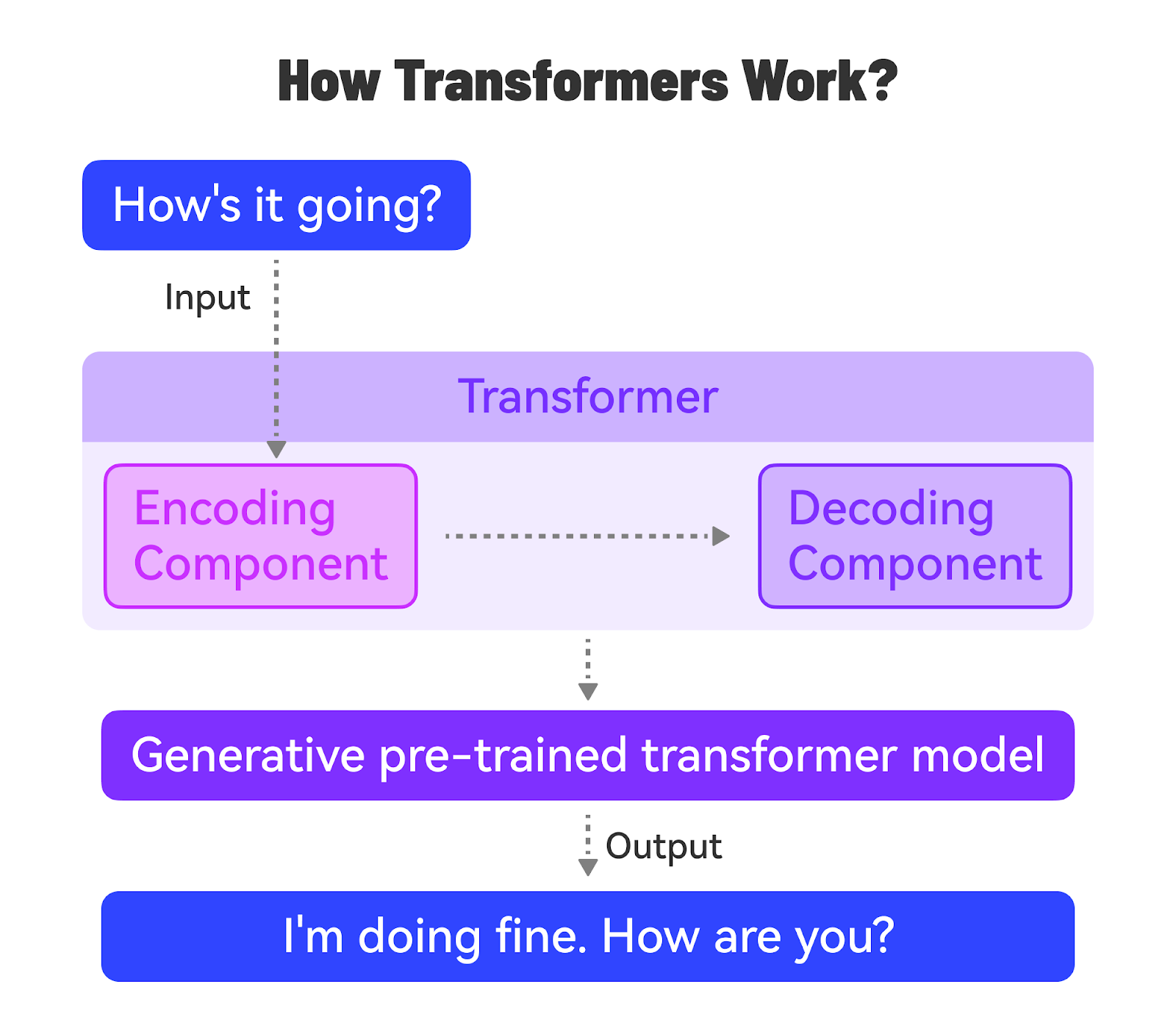
Natural Language Processing (NLP)NLP is a subfield of AI that focuses on enabling computers to understand, interpret, and generate human language. It involves tasks such as text classification, sentiment analysis, entity recognition, machine translation, and text generation. Deep learning models, particularly Transformer models, have revolutionized NLP in recent years. Transformer ModelsTransformer models are a type of deep learning model architecture introduced in the famous paper “Attention is All You Need” in 2017. They rely on self-attention mechanisms to process and generate sequential data, such as text.
Transformers have become the foundation for state-of-the-art models in NLP, such as BERT, GPT, and T5. They have also been adapted for other domains, like computer vision and audio processing. GenAIGenAI, short for Generative Artificial Intelligence, refers to AI systems that can generate new content, such as text, images, or music. It can be considered a subset of Deep Learning. GenAI models can generate novel and coherent outputs that resemble the training data. They use machine learning models, particularly deep learning models, to learn patterns and representations from existing data. NLP is a key area of focus within GenAI, as it deals with generating and understanding human language. Transformer models have become the backbone of many GenAI systems, particularly language models. The ability of Transformers to learn rich representations and generate coherent text has made them well-suited for GenAI applications. For reference, a transformer model is a type of neural network that excels at understanding the context of sequential data, such as text or speech, and generating new data. It uses a mechanism called “attention” to weigh the importance of different parts of the input sequence and better understand the overall context. There are various types of GenAI Models:
Prompt EngineeringPrompt engineering is the practice of designing effective prompts to get desired outputs from GenAI models. It involves understanding the model’s capabilities, limitations, and biases. Effective prompts provide clear instructions, relevant examples, and context to guide the model’s output. Prompt engineering is a crucial skill for getting the most out of GenAI models. Using the Model APIsMost Generative AI (GenAI) models are accessible through REST APIs, which allow developers to integrate these powerful models seamlessly into their applications. To get started, you'll need to obtain API access from the desired platform, such as Google’s Vertex AI, OpenAI, Anthropic, or Hugging Face. Each platform has its process for granting API access, typically involving
Once you have your API key, you can authenticate your requests to the GenAI model endpoints. Authentication usually involves providing the API key in the request headers or as a parameter. It's crucial to keep your API key secure and avoid sharing it publicly. It’s also important to follow best practices to ensure reliability and efficiency. Here are a couple of important best practices:
Building Application using the AI ModelThere are several use cases for GenAI-powered applications across various domains:
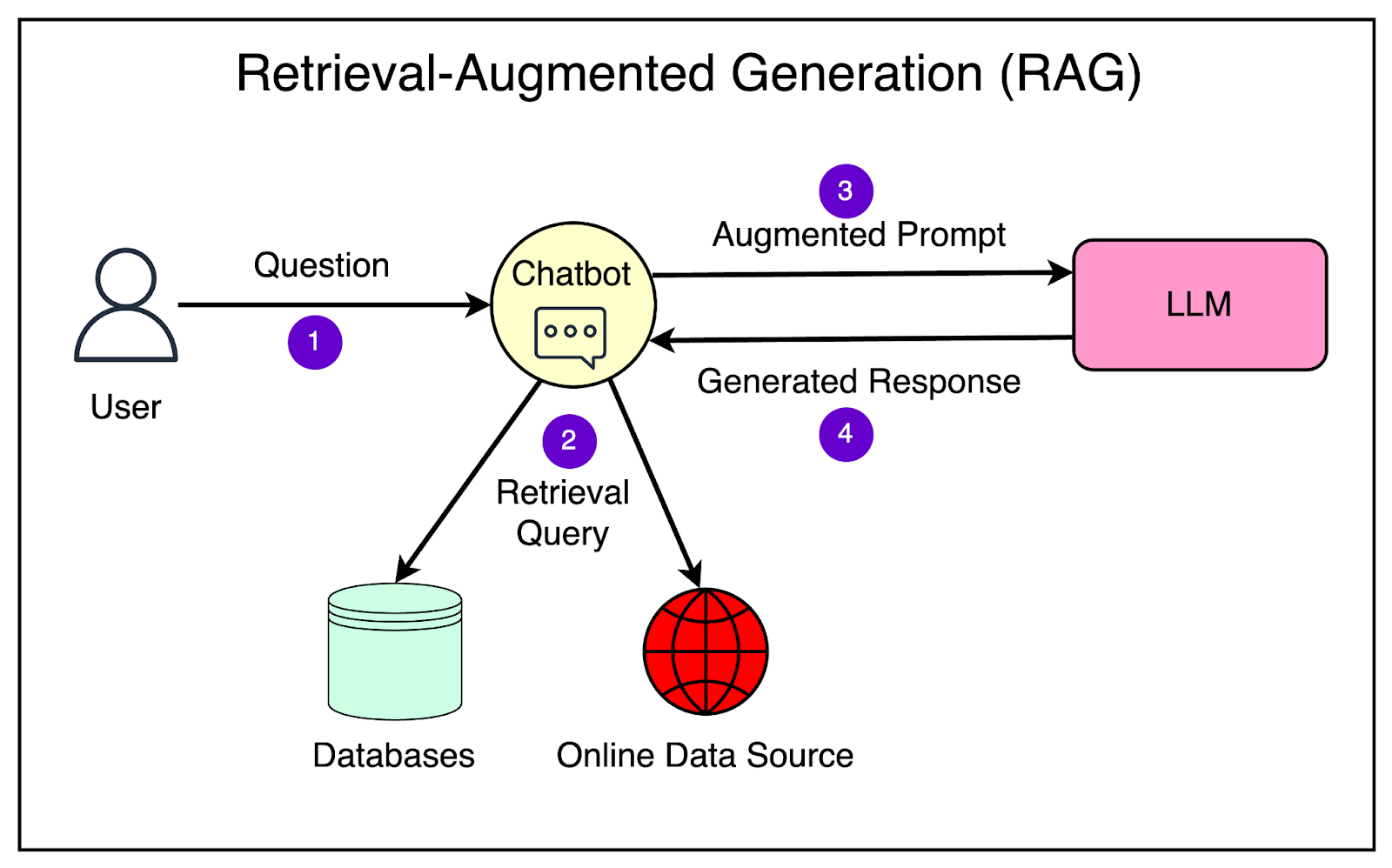
Let’s say we want to build a chatbot application that uses an LLM to provide personalized book recommendations based on user preferences. Here are the high-level steps involved. 1 - Choose an LLM ProviderResearch and compare different LLM providers, such as Google AI, Open AI, or a Hugging Face. Before choosing, you can consider multiple factors such as pricing, availability, API documentation, and community support. 2 - Set up the Development EnvironmentTypically, the LLM providers give access to their LLM via APIs. You must sign up for an API key from the chosen provider and install the necessary libraries and frameworks. For example, if you build your application using Python, you should set up a Python project and configure the API credentials according to the best practices. 3 - Design the Chatbot Conversation FlowPlan out the conversation flow for the book recommendation chatbot. Define the key questions the chatbot will ask users to gather preferences, such as favorite genres, authors, or book themes. Determine the structure and format of the chatbot’s responses, including the recommended books and any additional information to provide. 4 - Implement the Chatbot ApplicationUse a web framework like Flask or Django to build the chatbot application. Create a user interface for the chatbot, either as a web page or a messaging interface. Implement the necessary routes and views to handle user interactions and generate chatbot responses. 5 - Integrate the LLMMost LLM providers have released libraries to talk to their model APIs. Initialize the model with the appropriate parameters, such as the model name, version, and temperature. Define the prompts and instructions for the LLM to generate personalized book recommendations based on user preferences. For example, you can create prompts like: “Recommend a science fiction book for a user who enjoys fast-paced plots and space exploration.” Pass the user’s preferences and the prompts to the LLM using the API and retrieve the generated book recommendations. 6 - Process and Display the RecommendationsProcess the LLM-generated book recommendations to extract the relevant information, such as book titles, authors, and descriptions. Display the recommended books in a clear and visually appealing format. Provide options for users to interact with the recommendations, such as saving them for later or requesting more details about a specific book. 7 - Refine and ExpandTest the chatbot application with various user preferences and prompts to ensure it generates relevant and diverse book recommendations. Gather user feedback and iterate on the chatbot’s conversation flow, prompts, and recommendation formatting based on suggestions. Integrate additional features, such as providing book reviews, suggesting similar authors, and so on, to expand the chatbot's capabilities. 8 - Deploy and MonitorDeploy the chatbot application to a hosting platform or cloud service provider, making it accessible to users via a web URL. Set up monitoring and analytics to track user interactions, chatbot performance, and any errors or issues. Regularly update the LLM prompts and application logic based on user feedback and new book releases. Making Models Your OwnThere is significant interest in making models more adaptable and customizable to suit the specific needs of the domain. Let’s look at the main techniques to achieve this goal. Retrieval-Augmented Generation (RAG)RAG is a technique that helps improve the accuracy and relevance of the generated responses based on your use case. It allows your LLM to have external information sources like your databases, documents, and even the Internet in real time. This way the LLM can get the most up-to-date and relevant information to answer the queries specific to your business. Here’s a high-level overview of how a RAG system works:
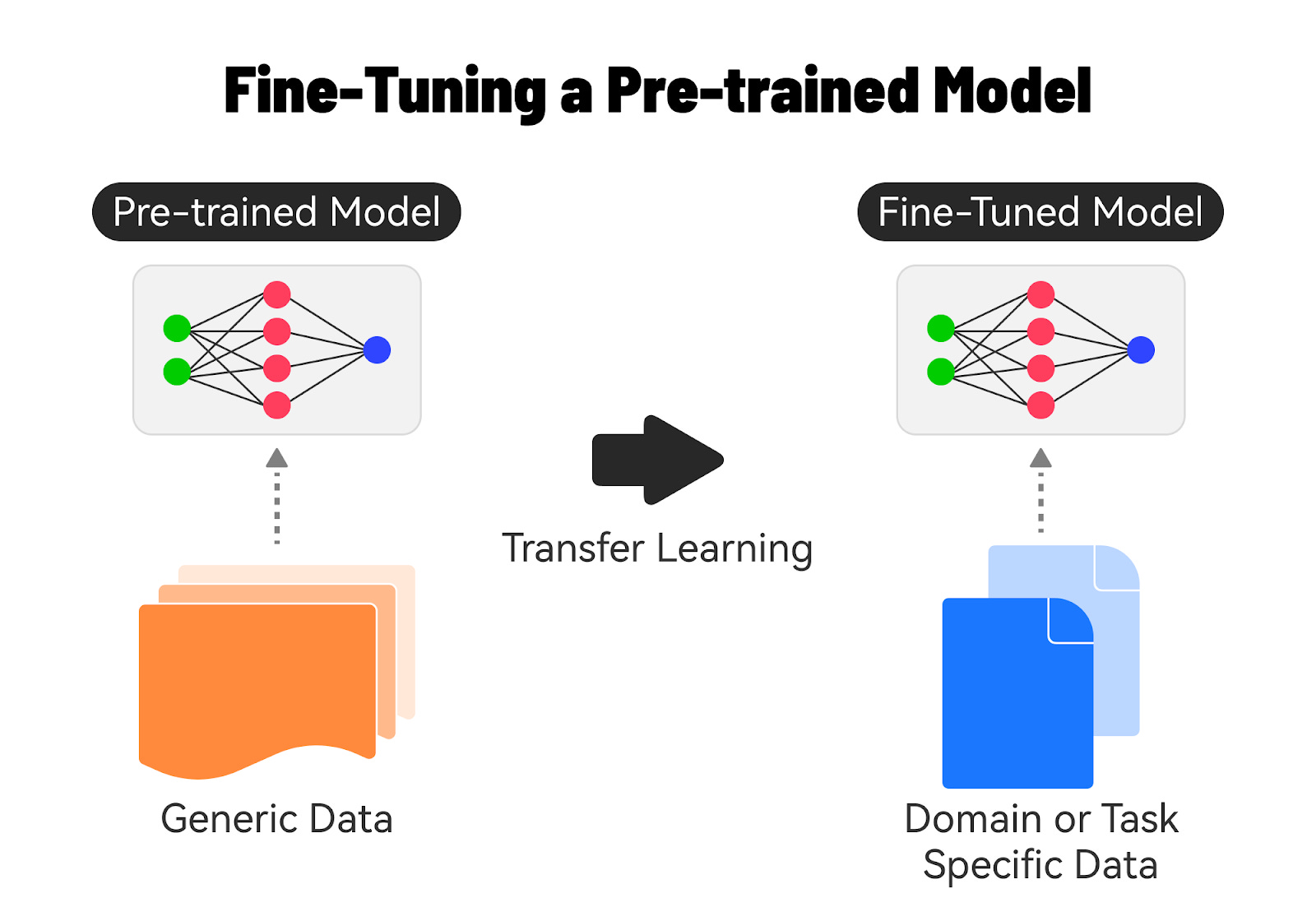
RAG has shown promising results in improving the accuracy and relevance of generated responses, especially in scenarios where the answer requires synthesizing information from multiple sources. It leverages the strengths of both information retrieval and language generation to provide better answers. Fine-Tuning AI ModelsFine-tuning a base model on domain-specific data is a powerful technique to improve the performance and accuracy of AI models for specific tasks or industries. Let’s understand how it’s done. 1 - Understanding Base ModelsBase models, also known as pre-trained models, are AI models that have been trained on large, general-purpose datasets. These models have learned general knowledge and patterns from the training data, making them versatile and applicable to a wide range of tasks. Examples of base models include Google’s BERT and GPT, which have been trained on massive amounts of text or image data. 2 - The Need for Fine-TuningWhile base models are powerful, they may not always perform optimally for specific domains or tasks. The reasons for fine-tuning a foundation model are as follows:
Fine-tuning allows us to adapt the base model to better understand and generate content specific to a particular domain. 3 - Fine-Tuning ProcessThe fine-tuning process consists of several steps such as:
4 - Benefits of Fine-TuningThere are significant benefits to fine-tuning:
ConclusionIn conclusion, getting started with Generative AI is an exciting journey that opens up a world of possibilities for developers and businesses alike. By understanding the key concepts, exploring the available models and APIs, and following best practices, you can harness GenAI's power to build innovative applications and solve complex problems. Whether you're interested in natural language processing, image generation, or audio synthesis, there are numerous GenAI models and platforms to choose from. You can create highly accurate and efficient AI solutions tailored to your specific needs by leveraging pre-trained models and fine-tuning them on domain-specific data. © 2024 ByteByteGo
|
by "ByteByteGo" <bytebytego@substack.com> - 11:35 - 16 Jul 2024