- Mailing Lists
- in
- Good Code vs. Bad Code
Archives
- By thread 5201
-
By date
- June 2021 10
- July 2021 6
- August 2021 20
- September 2021 21
- October 2021 48
- November 2021 40
- December 2021 23
- January 2022 46
- February 2022 80
- March 2022 109
- April 2022 100
- May 2022 97
- June 2022 105
- July 2022 82
- August 2022 95
- September 2022 103
- October 2022 117
- November 2022 115
- December 2022 102
- January 2023 88
- February 2023 90
- March 2023 116
- April 2023 97
- May 2023 159
- June 2023 145
- July 2023 120
- August 2023 90
- September 2023 102
- October 2023 106
- November 2023 100
- December 2023 74
- January 2024 75
- February 2024 75
- March 2024 78
- April 2024 74
- May 2024 108
- June 2024 98
- July 2024 116
- August 2024 134
- September 2024 130
- October 2024 141
- November 2024 171
- December 2024 115
- January 2025 216
- February 2025 140
- March 2025 220
- April 2025 233
- May 2025 239
- June 2025 303
- July 2025 12
[Report] Unlocking retail success: Observability trends and strategies
Discover the path to the autonomous enterprise [MEGACAST]
Good Code vs. Bad Code
Good Code vs. Bad Code
Latest articlesIf you’re not a subscriber, here’s what you missed this month.
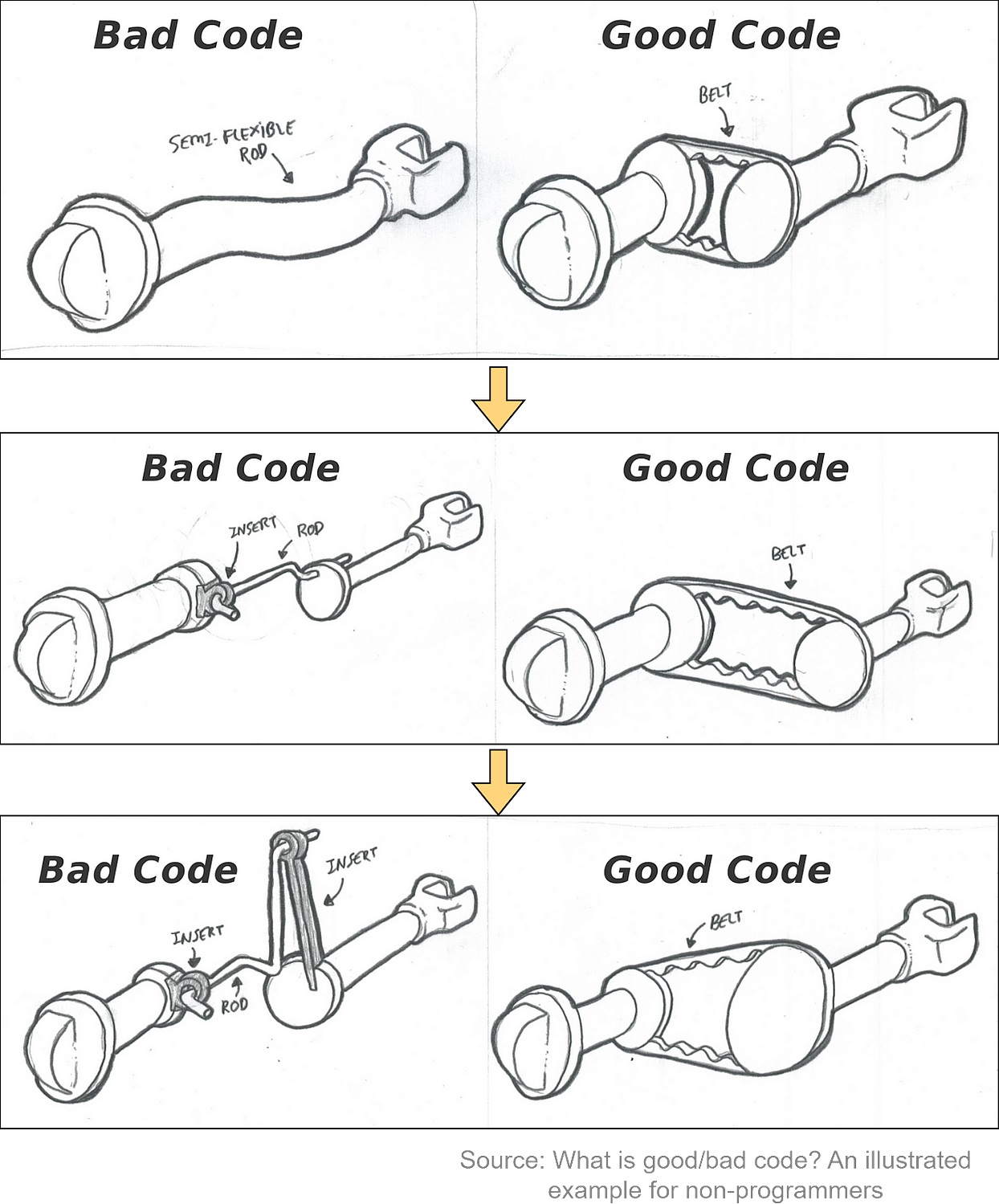
To receive all the full articles and support ByteByteGo, consider subscribing: In our newsletter, we’ve mainly focused on system designs. This time, we’re switching gears to a topic just as crucial: the code itself. Ever encountered a system that looks great in design but turns out to be a headache in code? That’s our focus in this issue. We’re breaking down what makes code good versus bad. It’s all about turning those great designs into equally great code. Let’s dive into the details that truly make a difference in coding. Why Good Code Matters?So, why should we care about good code? Think of it as the foundation of your software. Good code isn’t just about making things work; it’s about making them work efficiently and sustainably. It’s the difference between a smooth, efficient development experience and a frustrating, time-consuming one. Good code maintains stability and predictability, even as your project grows in complexity. It’s like having a reliable tool that keeps performing, no matter how tough the job gets. When it comes to scaling up, good code is essential. It allows for expansion without the bottlenecks and headaches that come with a more shortsighted approach. Sure, crafting good code requires more thought and effort at the outset. But this investment pays off by saving costs in the long run. Bad code, on the other hand, is a ticking time bomb - difficult to update and can lead to costly rewrites. There’s also the aspect of teamwork and continuity. High-quality code, which is usually well-documented and adheres to standards, makes it easier for teams to collaborate. It streamlines the onboarding process, accelerates delivery, and facilitates team expansion. Let’s illustrate our points in the diagram below by comparing the two designs of a hypothetical knob-turning mechanism. The ‘good code’ uses a belt mechanism – flexible and easy to adjust. The ‘bad code’ version, however, relies on a rigid rod – more limited and prone to complications when changes are needed.
As requirements change and the knob needs to be relocated, the ‘good code’ with its belt mechanism easily accommodates this with a simple extension. The ‘bad code’, with its rigid rod, would require a whole new configuration, which is neither time nor cost-effective. In another inevitable revision, we need to alter the speed at which the know turns. The ‘good code’ can simply switch to a different-sized gear. The ‘bad code’ setup, however, becomes increasingly complex as it requires additional parts and makes the system more convoluted and susceptible to breakage. We're not advocating for overengineering from the get-go, especially in a startup context where resources are limited and the future is uncertain. The key is understanding the long-term implications of our coding choices. Building overly complex systems prematurely can be as counterproductive as repeatedly choosing quick fixes. The art lies in striking the right balance, a taste and skill that comes with experience and thoughtful consideration. To kick things off, we’ve selected five broad areas for discussion. They're not exhaustive by any means, but they are good for a good starting point for a broader conversation on what takes code from bad to good. Are you ready to dive in? The Importance of Good NamesCoding standards often start with naming conventions for classes, functions, variables, and more. This might seem simple, but it requires thoughtful design. Consider the following service class names: By suffixing “ManagementService” to everything, the names become unnecessarily long and repetitive. Next look at this function: Despite following naming conventions, “processPayment” does not communicate what exactly happens. The word “process” is too generic. It doesn’t tell us the current state of the payment and what we are going to do with it. We understand from reading the code that it sends the payment instruction to an external channel for processing. We could name it “sendPaymentToExternalChannel()” but that exposes too many details. “startPayment()” can be a good choice, as it indicates initiating the payment flow without exposing internal details. Good names like this reduce the need for excessive comments when collaborating! Let’s look at another example. It would be good if “userId” were renamed to a more domain-relevant name, such as “payerId”. So in conclusion, effective names should:
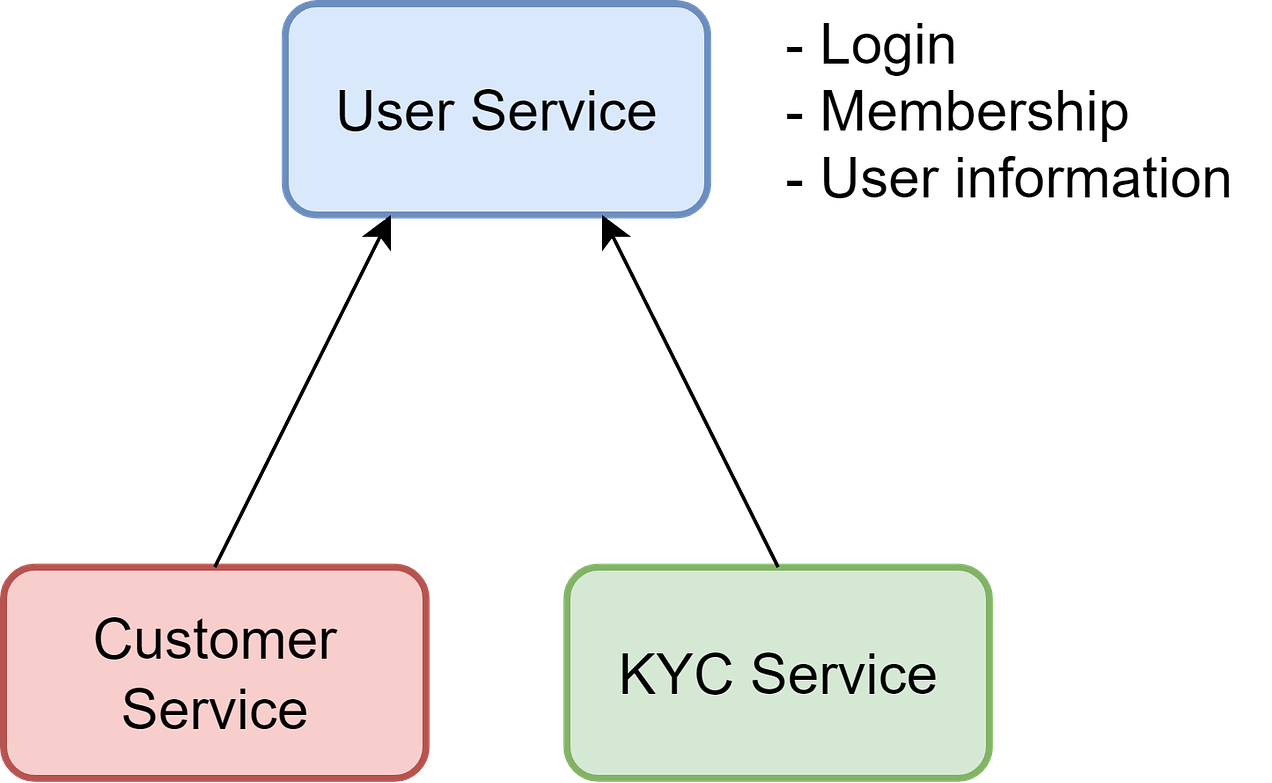
The Perils of Copying CodeSometimes urgent business requirements arise, but modifying existing code is too risky because it is badly-encapsulated with very few tests. In these situations, it is tempting to simply copy portions of code into new components as a shortcut, then start modifying to suit new needs. We faced this circumstance when building a compliance-centric Know Your Client (KYC) service. It required user management functionality already present in a tightly coupled UserService module used elsewhere. Lacking time to modularize UserService, we copied relevant parts into the new KYC service and customized it. So two duplicated versions of the user service logic stayed there long-term. Whenever we needed to update the user-related functionalities, we had to remember to modify two places - both the original UserService and the copied code now in the KYC service. This was often forgotten by developers, resulting in inconsistent behavior and outages. Keeping duplicate copies of the same logic in sync proved error-prone
Keep reading with a 7-day free trialSubscribe to ByteByteGo Newsletter to keep reading this post and get 7 days of free access to the full post archives. A subscription gets you:
© 2024 ByteByteGo
|

by "ByteByteGo" <bytebytego@substack.com> - 11:38 - 1 Feb 2024