Archives
- By thread 5224
-
By date
- June 2021 10
- July 2021 6
- August 2021 20
- September 2021 21
- October 2021 48
- November 2021 40
- December 2021 23
- January 2022 46
- February 2022 80
- March 2022 109
- April 2022 100
- May 2022 97
- June 2022 105
- July 2022 82
- August 2022 95
- September 2022 103
- October 2022 117
- November 2022 115
- December 2022 102
- January 2023 88
- February 2023 90
- March 2023 116
- April 2023 97
- May 2023 159
- June 2023 145
- July 2023 120
- August 2023 90
- September 2023 102
- October 2023 106
- November 2023 100
- December 2023 74
- January 2024 75
- February 2024 75
- March 2024 78
- April 2024 74
- May 2024 108
- June 2024 98
- July 2024 116
- August 2024 134
- September 2024 130
- October 2024 141
- November 2024 171
- December 2024 115
- January 2025 216
- February 2025 140
- March 2025 220
- April 2025 233
- May 2025 239
- June 2025 303
- July 2025 36
-
GRAB 3 FREE 1 SEAT !!! MICROSOFT EXCEL (ADVANCED LEVEL) (4 & 5 Jun 2025)
HRDC CLAIMABLE COURSE !!!
Please call 012-588 2728
email to pearl-otc@outlook.com
HYBRID PUBLIC PROGRAM
MICROSOFT EXCEL (ADVANCED LEVEL)
(** Choose either Zoom OR Physical Session)
Remote Online Training (Via Zoom) &
OTC TRAINING CENTRE SDN BHD SUBANG, SELANGOR (Physical)
(SBL Khas / HRD Corp Claimable Course)
Date : 4 Jun 2025 (Wed) | 9am - 5pm By Siti
5 Jun 2025 (Thu) | 9am - 5pm .
.
DESCRIPTION
This course will give you a deep understanding of the useful Excel functions that transform Excel from a basic spreadsheet program into a dynamic and powerful analytics tool. Focus on what each Functions does, hands-on, contextual examples designed to showcase why these Functions are awesome and how they can be applied in several ways and how to troubleshoot formulas. Manipulating data using analysis tools, password settings and record actions using macros.
OBJECTIVES
- Mastering the use of some of Excel's most popular and highly sought-after functions (VLOOKUP, IF, AVERAGE, INDEX/MATCH and many more...)
- Audit Excel Worksheet formulas to ensure clean formulas
- Worksheets and Workbooks protection
- Usefulness of the What-If Analysis
- Automate your day-to-day Excel tasks by mastering the power of Macros
REQUIREMENT
- A working knowledge of creating/formatting simple spreadsheets, basic formulas and functions
- Excel Introduction course or equivalent knowledge or experience.
FOR WHOM
Those wishing to increase their knowledge of Excel to create more in-depth worksheets and improve the presentation of data.
OUTLINE OF WORKSHOP
1. Excel List Functions
1.1 Introduction to Excels Function: DSUM()
1.2 Excel DSUM Function Single Criteria Continued
1.3 Excel DSUM Function with OR Criteria
1.4 Excel DSUM Function with AND Criteria
1.5 Excel Function: DAVERAGE()
1.6 Excel Function: DCOUNT()
1.7 Excel Function: SUBTOTAL()
2. Working with Excel’s Conditional Functions
2.1 Using Excel's IF() Function
2.2 Excel's IF() Function with a Name Range
2.3 Nesting Functions with Excel
2.4 Nesting Excels AND() Function within the IF() Function
2.5 Using Excel's COUNTIF() Function
2.6 Using Excel's SUMIF() Function
2.7 Using Excel's IFERROR() Function
3. Working with Excel’s Lookup Functions
3.1 Microsoft Excel VLOOKUP() Function
3.2 Microsoft Excel HLOOKUP() Function
3.3 Microsoft Excel INDEX() Function
3.4 Microsoft Excel MATCH() Function
3.5 Microsoft Excel INDEX() and MATCH() Function Combined
3.6 Microsoft Excel INDEX() and MATCH() Function Combined Continued
3.7 Creating a Dynamic HLOOKUP() with the MATCH() Function
4. Auditing an Excel Worksheet
4.1 Tracing Precedents in Excel Formulas
4.2 Tracing Dependents in Excel Formulas
4.3 Working with the Watch Window
4.4 Showing Formulas
5. Protecting Excel Worksheets and Workbooks
5.1 Protecting Specific Cells in a Worksheet
5.2 Protecting the Structure of a Workbook
5.3 Adding a Workbook Password
6. Mastering Excel’s “What If?” Tools
6.1 Working with Excel's Goal Seek Tool
6.2 Working with Excel's Solver Tool
6.3 Building Effective Data Tables in Excel
6.4 Creating Scenarios in Excel
7. Automating Repetitive Tasks in Excel with Macros
7.1 Understanding Excel Macros
7.2 Activating the Developer Tab in Excel
7.3 Creating a Macro with the Macro Recorder
7.4 Creating Buttons to Run Macros
**Certificate of attendance will be awarded for those who completed the course
ABOUT THE FACILITATOR
Siti
Microsoft Office Specialist (MOS)
Siti started her career as an Information Technology Lecturer in few local colleges and universities back in year 1999. In her 8 years’ experience as a lecturer, she picks up various discipline in IT related subjects. She also involved in giving Microsoft Office Applications training to various companies.
Since 20 March 2006 till present, Siti decided for a career change. She moved to IT related training. As a Training Consultant, she focused more on Microsoft Office Applications training. She has facilitated training programs in link with broad-ranging groups of training institutes and clients. She is familiar and proficient with Microsoft Office Applications and during her training she will address the day to day issues faced by employees in today’s corporate environment.
In year 2007 till 2008 Siti had been appointed as one of the Master Trainer for The Teaching and Learning of Science and Mathematics in English (Pengajaran dan Pembelajaran Sains dan Matematik Dalam Bahasa Inggeris - PPSMI). Her role as a Master Trainer was to give training to all the trainers representing different states around Malaysia on how to deliver the training to all the teachers in various schools in Malaysia.
Aside to giving training, Microsoft Malaysia has engaged her to share her expertise on how to fully maximize the usage of Microsoft Office Applications since year 2008 till current. She had done many workshops around Malaysia for major Microsoft Malaysia customers mostly focusing on the Tips and Tricks and also best practices.
Siti was involved as a Handyman in Handyman Project under Shell Global Solutions, Malaysia since 2008 till 2011. To be given the opportunity to give One-to-one consultation with the client by looking, asking and solve problem related to the data provided by the clients. Examples of topics covered for Handyman sessions are E-mail and Calendar, Standard & Mobile Office, Archiving & Back-ups, NetMeeting, Livelink, Live Meeting? and Microsoft Office Applications.
Nov 2010 to Feb 2011 she was being given another golden opportunity by ExxonMobil Malaysiato be the lead trainer in the Migration from XME to GME project to train almost 3000 staffs. This training also includes Microsoft Office 2010 and Windows 7.
Academic Qualification
1999 – Bachelor of Computer Science (Honours) · Computing (Single Major) - USM
2001 – Master of Science · Distributed Computing - UPM
Working Experience
- Cybernetics International College of Technology · Lecturer · (June 1999 to May 2002)
- MARA University of Technology (UiTM Seri Iskandar) · Lecturer · (June 2002 to July 2003)
- Cosmopoint College of Technology · Lecturer · (September 2005 to March 2006)
- Iverson Associates Sdn Bhd · Senior Training Consultant · (March 2006 to February 2011)
- Info Trek Sdn Bhd · Senior Training Consultant· (February 2011 to April 2017)
- Fulltime Senior Training Consultant · (May 2017 to present)
(SBL Khas / HRD Corp Claimable Course)
training Fee
14 hours Remote Online Training (Via Zoom)
RM 1,296.00/pax (excluded 8% SST)
2 days Face-to-Face Training (Physical Training)
RM 1,850.00/pax (excluded 8% SST)
Group Registration: Register 3 participants from the same organization, the 4th participant is FREE.
(Buy 3 Get 1 Free) if Register before 26 May 2025. Please act fast to grab your favorite training program!We hope you find it informative and interesting and we look forward to seeing you soon.
Please act fast to grab your favorite training program! Please call 012-588 2728
or email to pearl-otc@outlook.com
Do forward this email to all your friends and colleagues who might be interested to attend these programs
If you would like to unsubscribe from our email list at any time, please simply reply to the e-mail and type Unsubscribe in the subject area.
We will remove your name from the list and you will not receive any additional e-mail
Thanks
Regards
Pearl
by "pearl@otcmsb.com.my" <pearl@otcmsb.com.my> - 07:09 - 31 Mar 2025 -
POWER BANK QUOTATION
Hi info,
This is Ray from PINENG power bank.
We have been in the power bank production industry for 14 years. We have our own brand-- PINENG, but OEM and ODM is always welcome.
We ready to provide drop shipping for your orders.
For more information. Just let me know. Looking for your earlier reply.

Best regards,
Ray zhang
Guangdong Pineng Industrial Co., Ltd (China)
by "sales14" <sales14@pineng.ltd> - 07:00 - 31 Mar 2025 -
Reliable Distribution Transformers and Switchgear Solutions: Your Needs
Dear info ,
When you next consider your arrangements for transformers, I would welcome the opportunity to understand your requirements and situation.

We are specialized at producing distribution transformer, substation and switch gear from 3kV to 35kV for more than 15 years.
We are qualified supplier for many countries’ electricity department, such as China State Grid, Ethiopia, Nepal, Bangladesh, Nepal, Egypt, Zambia, Zimbabwe, Peru, Brazil etc.
I will send you more detailed information regarding this product in another email. When you receive it, can you please email me your requirement for this product?
Best regards.
...........................................................
Nana
Email: jsj06@jinsant.com
Tel/Wechat/Whatsapp:+8613806867185
Position.:Foreign Trade Salesperson
Company Name:Golden Triangle Electric Power Technology Co.,Ltd
Address:No.66, Binhai Nansan Road, Yueqing Economic Development Zone, Zhejiang Province, China
by "Bsksb Lsbskns" <bsksblsbskns@gmail.com> - 04:50 - 31 Mar 2025 -
Professional Solutions to Cutting Challenges in the Building Decoration Industry
Dear info,I'm Xavier from Koocut Cutting Technology (Sichuan) Co., Ltd. Our company has extensive experience in the cutting - tool industry, thanks to the technical accumulation of our parent company over the past two decades.In the building decoration industry, precision and efficiency are of utmost importance. Our PCD cement - fiber - board - processing circular saw blades and TCT color - steel - plate - processing circular saw blades are specifically designed to address the cutting challenges in this field. These blades can cut various building materials with high precision, resulting in smooth edges and minimal waste.Our factory, operating in line with Industry 4.0 standards, features intelligent and flexible production capabilities. This means we can quickly adjust production according to your specific order requirements, whether it's a small - batch customized order or a large - scale standard order. We also have a strict quality control system to ensure that every product leaving our factory meets the highest quality standards.We've already worked with many building decoration service providers globally, helping them improve project efficiency and customer satisfaction. We believe we can do the same for your company. If you have any questions or are interested in our products, please contact me.Best regards,
Contact Information:
WhatsApp:+86 17388372772
Email: xavier@koocut.comKoocut Cutting Technology (Sichuan) Co., Ltd.
by "Gonzaliz Levinsky" <levinskygonzaliz@gmail.com> - 02:11 - 31 Mar 2025 -
Provide power solutions and tender for various power projects
Hi info,
This is Mulang Electric,a company focus on Low voltage-ATS,MCCB,MCB,ACB,SPD. We work with organizations like Schneider,Siemens,ABB to Joint development of low-voltage electrical products.
Provide power solutions and tender for various power projects.
Our products are of top quality and help my clients increase sales by offering new and unique designs to capture the market and win projects. The benefit for our clients is that they can get more and more clients and projects.
Could you direct me to the right person to talk to about this so we can explore if this would be something valuable to incorporate into your projects?
Kind regards,
Mulang Electric
by "Josesgrimshaws" <josesgrimshaws@gmail.com> - 01:52 - 31 Mar 2025 -
Request for Employment Verification Contact. REF# E-032825-482487
Contact Details of Authorized Personnel
for Employment VerificationDear sir/madam,
We need to send a request for employment verification for one of your employees.
Click here to provide the contact details.
If you are unable to provide the contact details, please forward this email to the appropriate contact within your organization (Office manager or HR / Payroll personnel)
If you have any additional questions, please contact us:
This is an automatically generated email. Please do not reply to this email, it is not monitored.
Do you need more assistance? EmpInfo is happy to help. Please contact: - Verifications@EmpInfo.com - (800) 674-2974 toll free in the U.S. Monday to Friday 8 a.m. until 6 p.m. CST.
Sincerely,
EmpInfo Customer Support
by donotreply@empinfo.com - 12:36 - 31 Mar 2025 -
A leader’s guide to gen AI–powered workforce planning
Leading Off
Prepare for disruption
by "McKinsey Leading Off" <publishing@email.mckinsey.com> - 04:15 - 31 Mar 2025 -
What common biases can distort decision-making?
On McKinsey Perspectives
Corrective actions to take Brought to you by Alex Panas, global leader of industries, & Axel Karlsson, global leader of functional practices and growth platforms
Welcome to the latest edition of Only McKinsey Perspectives. We hope you find our insights useful. Let us know what you think at Alex_Panas@McKinsey.com and Axel_Karlsson@McKinsey.com.
—Alex and Axel
•
Conquering cognitive distortions. Humans have inherent biases that can stall, skew, or deny the clear and objective decision-making that’s essential to strategic management. Yet as the late Nobel Prize–winning psychologist and economist Daniel Kahneman noted, “Organizations can put systems in place to help them.” Indeed, by creating rules and processes that enable organizations to overcome people’s biases, leaders can more effectively link strategy to value creation, McKinsey Partner Tim Koller explains.
—Edited by Belinda Yu, editor, Atlanta
This email contains information about McKinsey's research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this email because you subscribed to the Only McKinsey Perspectives newsletter, formerly known as Only McKinsey.
Copyright © 2025 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "Only McKinsey Perspectives" <publishing@email.mckinsey.com> - 01:42 - 31 Mar 2025 -
Re: Artificial grass you need/17 years factory
Dear info,
Very glad to know you from your web site, that you are on the market of artificial grass with most prestigious quality.
To be even more successful, you might look for a very capable & reliable producing supplier. QIYUE GRASS is a good one for you to rely on. We have 17 years of production experience.
Can you do me a favor? What we should do to apply for & become your
new vendor?
Thanks & Best regards,
Eddy Zhang Factory Owner
SUQIAN QIYUE ARTIFICIAL GRASS CARPET CO.,LTD
Add: North side of Sanchuang Industrial Park,Suqian city,Jiangsu,China.
Mobile/Whatsapp: +86-18705246071
Website: www.qiyueflooring.com
by "Rue Lusia" <lusiarue725@gmail.com> - 01:07 - 31 Mar 2025 -
20 years old fiber optic cable and patch factory
Dear info
Good days
This is YUXIN FIBER CABLE Company,we specialize in manufacturing all kinds of fiber optic cable and patch cord.Our company have 20 years expeerience in producing fiber optic cable and patch cord. Aerial fiber cable,duct fiber cable,diret-buried fiber cable,mining fiber cable,ftth drop cable,etc are our main and best selling types.For patch cord, sc,st,lc,fc,mpo,etc.
Would you like to know more about us?
pls check the following website:
our company website:www.nbyuxin.com
our Alibaba website: https://nbyuxinfiber.en.alibaba.com

Best reagrds
Shenhui
Ningbo Yuxin Optical Fiber Cable Co., Ltd.
by "sales08" <sales08@yuxinfibercable.com> - 10:52 - 30 Mar 2025 -
office chairs/Quality Manufacturers
Dear info
Thank you for opening my email.
My name is Allen from China.
We are a professional office chair manufacturer in China and would like to establish business relationship with your company. We have 15 years experience in manufacturing and exporting, we have good price and quality which can bring more profit for your company.
Attached is one of our office chairs that has been a best seller for many years, please check.
We accept OEM and ODM orders, if you are interested feel free to contact me.
Looking forward to your reply.
Best Regards.Allen
Sales Manager
WeChat:A19157900359
WhatsAPP:+86 19157900359
HANGZHOU MINGCHEN FURNITURE CO.,LTD.
www.dhksy.com

by "Azemi Cruise" <cruiseazemi@gmail.com> - 09:26 - 30 Mar 2025 -
Exploring cooperation: Supply high-quality motorcycle spokes& rims from China
Dear info,
I'm Cindy from Hangzhou Zhenrong Import and Export Co., Ltd. Please allow me to introduce our company and our range of high-quality motorcycle spokes and accessories. With more than 40 years of industry experience, we have become a leading manufacturer focusing on technology development, design and OEM processing capabilities.
Our product range includes a variety of spokes such as 8G, 9G, 10G straight and forged spokes and 11G spokes, as well as a variety of spoke nipples to choose from. We also offer a variety of surface treatments for our products, including blue zinc plating, white zinc plating, nickel chromium plating and colored zinc plating. In addition, we also provide rims (WM1.2,1.4,1.6,1.85,2.15 ) and other related accessories to meet the diverse needs of motorcycle enthusiasts.
We pride ourselves on producing high-quality products that meet the industry's strict standards. Every year we export more than 50-60 containers of products to Southeast Asia, North America, South America and Europe to meet the needs of motorcycle parts companies in these regions.
We supply zinc and stainless steel spokes and nipples to a 125 year old British spoke factory.
We understand the importance of reliable and durable motorcycle components, and our products are designed to meet and exceed rider and manufacturer expectations. Whether it's a custom, aftermarket upgrade or OEM application, our range of spokes, nipples and rims are engineered to deliver exceptional performance and longevity.
We are keen to explore potential collaboration opportunities with motorcycle parts companies worldwidely and we believe our products can complement your existing product range and meet the needs of your discerning customers.
Thank you for considering our products and I look forward to the possibility of collaboration.
Thank you and best regards,
Cindy
WhatsApp:+86 13666697939
Hangzhou Zhenrong Import and Export Co., Ltd.
by "Cindy15" <Cindy15@hzzrspoke.com> - 09:11 - 30 Mar 2025 -
Microwave/Millimeter Wave Components DC-330GHz from Qualwave Inc.
Dear Sir/Madam,
Qualwave Inc. supplies broadband microwave/millimeter wave components with frequency range DC-330GHz. Our products have advantages in specifications and quality.
We can support you a competitive price and very fast lead time of 0~2 weeks & 2~4 weeks for most of our products.
Our main products (Coaxial & Waveguide):
1. Adapters: DC-110GHz, Coaxial Adapters & Waveguide to Coax Adapters
2. Amplifiers: 9KHz-260GHz, Power Amplifiers, Low Noise Amplifiers (modules & systems), BUCs, LNBs, DLVAs
3. Antennas: 0.64-330GHz, Standard Gain Horn Antennas, Conical Horn Antenna
4. Attenuators: DC-110GHz, 0.1W-5KW, Fixed Attenuators, Variable Attenuators, Digital Controlled Attenuators & Voltage Controlled Attenuators
5. Baluns: 500KHz-110GHz
6. Bias Tees: 50KHz-40GHz
7. Cable Assemblies: DC-110GHz, Ultra Low Loss & Phase Stable & High Power
8. Calibration Kits: DC-67GHz, Precision, 3-in-1, Ecomonic version available
9. Circulators/Isolators: 10MHz-110GHz, Coaxial, Drop-In, SMD, Waveguide types avaible
10. Connectors: DC-110GHz, PCB Connectors, Cable Coneectors & End Launch Connectors, Vertical Launch Connectors, Multi-Channel Connectors
11. Couplers: 4KHz-110GHz, Directinal Couplers, Dual Directional Couplers, 90°/180°Hybrid Couplers
12. DC Blocks: 9KHz-110GHz
13. Detectors: 0.01-110GHz
14. Equalizers: DC-40GHz
15. Filters/Diplexers: DC-67GHz, Low Pass Filters, High Pass Filters, Band Pass Filters, Band Reject Filters
16. Frequency Multipliers/Dividers: 0.01-110GHz
17. Frequency Sources: 0.01-40GHz, Synthesizers, PLDRO, DRO, PLVCO, VCO, PLXO, DRVCO, etc.
18. Impedance Matching Pads: 50-75 Ohms
19. Limiters: 0.03-40GHz
20. Mixers: 1MHz-110GHz
21. Phase Shifters: DC-40GHz, Manual Phase Shifters, Digital Controlled Phase Shifters & Voltage Controlled Phase Shifters
22. Probes: DC-110GHz
23. Power Dividers/Combiners: DC-110GHz, 2, 3, 4, 6, 8, 16, 32 Ways
24. Rotary Joints: DC-50GHz
25. Surge Protectors: DC-6GHz
26. Switches: DC-110GHz, Coaxial Switches, PIN Diode Switches, Waveguide Switches, Surface Mount Switches, Manual Switches & Switch Matrix Systems
27. Terminations: DC-110GHz, 0.5W-2500W, Coaxial & Waveguide type
28. Other Waveguide Products: Flexible Waveguide, Pressure Windows, Waveguide Bends /Straight Sections /Transitions /TwistsPlease refer to our official website to check information of our standard products. You can download our catalog from the URL bellow.
www.qualwave.com/products/files/Qualwave-Catalog.pdf
If you have any question, please feel free to contact us. I look forward to hear from you for future cooperation. Thank you!
Best Regards,
--
Devin He
Qualwave Inc.
5F, Bld.1, Tianke Plaza, No.999 Tiangong Ave.,
Tianfu New Area, Chengdu, 610213, China
Tel: +86-28-6115-4929
E-mail: sales@qualwave.com
Website: www.qualwave.com
by "Morciano Vitolano" <vitolanomorciano412@gmail.com> - 05:00 - 30 Mar 2025 -
An excellent natural fiber products factory from China
Dear info
I am coming from Jiangsu Himalaya Natural Fiber,we specialized in the production of sisal,jute,seagrass,polypropylene,wool and other natural fiber carpets.We also produce sisal cat scratching pads and cat scratching post for the pet products factory.
1.Our factory has been established for 20 years.Cooperated with the following customers:SAFAVIEH(USA),ALDI Supermarket,Nourison(USA)
2.Our own factory, we offer first-hand competitive prices.
3.Our factory is certified by authoritative organizations such as BSCI.
4.With extensive industry-related experience, we can develop and customize any product according to requirements.
Reply to get catalog and FOC samples.
Let me know if you need more help.
by "Gru Oneill" <oneillgru@gmail.com> - 08:52 - 29 Mar 2025 -
The week in charts
The Week in Charts
Global lighthouses, IT excellence, and more Share these insights
Did you enjoy this newsletter? Forward it to colleagues and friends so they can subscribe too. Was this issue forwarded to you? Sign up for it and sample our 40+ other free email subscriptions here.
This email contains information about McKinsey's research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this email because you subscribed to The Week in Charts newsletter.
Copyright © 2025 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "McKinsey Week in Charts" <publishing@email.mckinsey.com> - 03:32 - 29 Mar 2025 -
Push Button Switch & touch switch/China
Dear info,
Good day!
We are switches manufacturer for thousand kinds household appliances since 2006.
We are able to produce your target swithes with high quality. Our switches have passed many approvals such as CE,CB,UL,CQC, ENEC,ROSH and so on.
Attached kindly pls find pictures some of our products FYI.
Any question pls feel free to contact me. Thank you.
Regards!
Suanhttps://ymd-zy.en.alibaba.com

by "Tiffany Reece" <tiffanyreece640@gmail.com> - 03:20 - 29 Mar 2025 -
Enhanced value switch solutions
Dear info,
Hello!
We specialize in the production of micro switches, rocker switches, push button switches and keyboard switches, and are committed to providing customers with high-performance, customized switch solutions.
Our products are widely used in home appliances, automobiles, electronic equipment and other fields, with the following advantages:
High quality: using high-quality materials to ensure product durability and stability;
Flexible customization: support OEM/ODM services, design according to needs;
Competitive price: ensure high cost performance and help customers reduce procurement costs.
At present, our products have been exported to many countries and are deeply trusted by customers. I hope to take this opportunity to support your company and work with you to create a win-win situation!
If you are interested in learning more, please feel free to contact me, we can provide sample testing or product information for your reference.
Best regards&Thanks
David Wu
Yueqing Tongda Wire Electric Factory
ADD:No.8 Chuanger Road,Yuqing Bay Port Area, Wenzhou,Zhejiang,325609
Tel: 0086-577 57158583
Mobil: 0086-13780102300
Web: www.chinaweipeng.com
Mail: wdm@tdweipeng.com(If email Failed, pls send to weipeng@tdweipeng.com)
Made-In-China: tongdaswitch.en.made-in-china.com
by "Almaistro Shamia" <shamiaalmaistro@gmail.com> - 02:50 - 29 Mar 2025 -
Accelerate Your Production with MINGDA’s High-Speed, Large Dual-Extruder 3D Printers
Hi info,
I hope you’re doing well.
I’m Chris, Channel Sales Manager at MINGDA 3D, a trusted 3D printer manufacturer with over 12 years of experience.
I’d like to introduce our high-speed, dual-extruder 3D printers: MD-600D (600x600x600mm) and MD-1000D (1000x1000x1000mm).
Key Features:5X Faster Printing: Up to 300mm/s.
Dual Extruders: Multi-color and multi-material printing (PLA, ABS, TPU, PETG, Carbon Fiber, and more).
High-Temperature 350°C Extruders: For advanced composites.
Full-Size Printing: 100% build area.
Remote Monitoring: Camera & Wi-Fi control.
Easy Setup: Quick auto bed leveling & camera calibration.
Silent Printing: Closed-loop motors for smooth operation.
The MD-600D and MD-1000D are perfect for rapid prototyping and end-use parts, offering larger builds, faster speeds, and material flexibility.
Let me know if you’d like more details or have any questions.
by "Chris" <Chris@3dprintermingda.com> - 02:21 - 29 Mar 2025 -
EP156: Software Architect Knowledge Map
EP156: Software Architect Knowledge Map
Becoming a Software Architect is a journey where you are always learning. But there are some things you must definitely strive to know.͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ Forwarded this email? Subscribe here for moreThe Ultimate Weapon for Software Architect 🗺️ (Sponsored)
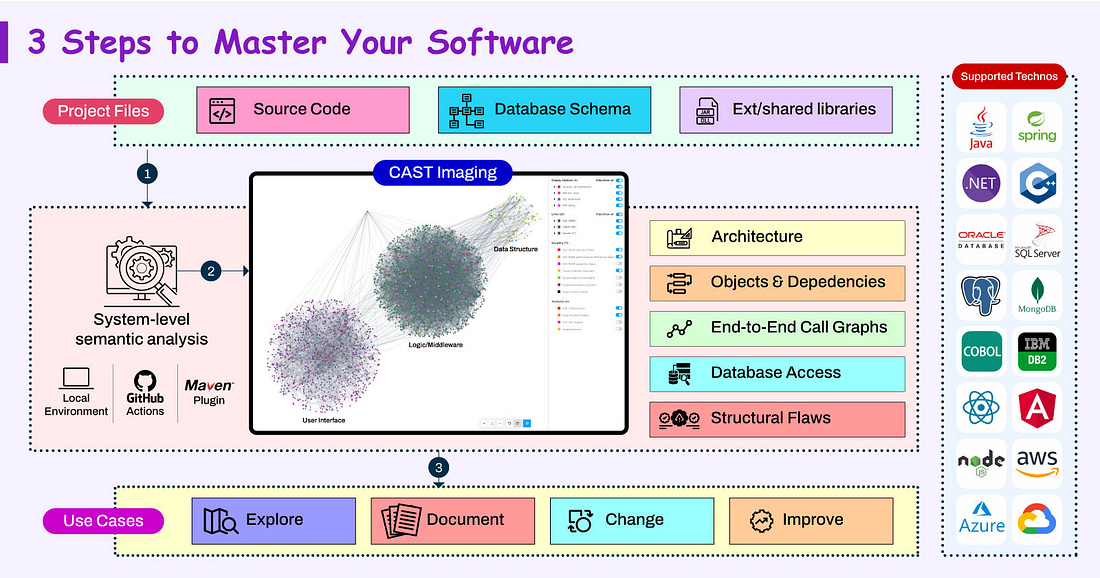
What if you could instantly identify the only 3 functionalities to test for non-regression after modifying a complex Java class?
What if you could visualize the ripple effect, from database to front-end, of changing a column data type?
Master your application with the architects’ ultimate weapon🗺️
CAST Imaging automatically maps any application’s inner workings:
Visualize all dependencies, explore database access
Trace end-to-end data & call flows, assess change impact
Identify structural flaws typically missed by code quality tools
Stop wasting countless hours reverse-engineering your code manually.
Move faster with CAST Imaging, the automated software mapping tech.MAP YOUR APPLICATION - FREE TRIAL
CAST Imaging supports any mix of Java/JEE, .NET, C#, COBOL, SQL, and 100+ other languages, frameworks, and database engines.
This week’s system design refresher:
Software Architect Knowledge Map
What is Retrieval-Augmented Generation (RAG)?
How Amazon S3 Works?
How Two-factor Authentication (2FA) Works?
SPONSOR US
Software Architect Knowledge Map
Becoming a Software Architect is a journey where you are always learning. But there are some things you must definitely strive to know.

Master a Programming Language
Look to master 1-2 programming languages such as Java, Python, Golang, JavaScript, etc.Tools
Build proficiency with key tools such as GitHub, Jenkins, Jira, ELK, Sonar, etc.Design Principles
Learn about important design principles such as OOPS, Clean Code, TDD, DDD, CAP Theorem, MVC Pattern, ACID, and GOF.Architectural Principles
Become proficient in multiple architectural patterns such as Microservices, Publish-Subscribe, Layered, Event-Driven, Client-Server, Hexagonal, etc.Platform Knowledge
Get to know about several platforms such as containers, orchestration, cloud, serverless, CDN, API Gateways, Distributed Systems, and CI/CDData Analytics
Build a solid knowledge of data and analytics components like SQL and NoSQL databases, data streaming solutions with Kafka, object storage, data migration, OLAP, and so on.Networking and Security
Learn about networking and security concepts such as DNS, TCP, TLS, HTTPS, Encryption, JWT, OAuth, and Credential Management.Supporting Skills
Apart from technical, software architects also need several supporting skills such as decision-making, technology knowledge, stakeholder management, communication, estimation, leadership, etc.
Over to you - What else would you add to the roadmap?
Free Roadmap: Future-proof your Dev Skills (Sponsored)

Feeling the pressure to master DevOps while juggling your development responsibilities?
You're not alone.
That’s why we've created an actionable DevOps Roadmap specifically for software engineers looking to level up their operational skills without getting overwhelmed.
This clear, step-by-step guide maps out the essential DevOps tools, practices, and concepts that directly enhance a developer's career trajectory.
From containerization to CI/CD pipelines, from cloud to monitoring solutions – we've distilled years of DevOps expertise into an actionable learning path.
Join thousands of developers who've transformed their technical capabilities with our structured approach:
This guide was created exclusively for ByteByteGo readers by TechWorld with Nana | 1M+ ENGINEERS TRAINED
What is Retrieval-Augmented Generation (RAG)?

RAG is the process of optimizing an LLM's output to reference a specific knowledge base that may not have been part of its training data before generating a response.
In other words, RAG helps extend the powerful capabilities of LLMs to specific domains or knowledge bases without the need for additional training.
Here’s how RAG works:
1 - The user writes a query prompt in the LLM’s user interface. This query is passed to the backend server where it is converted to a vector representation.
2 - The query is sent to a search system.
3 - This search system can refer to various knowledge sources such as PDFs, Web Search, Code-bases, Documents, Database, or APIs to fetch relevant information to answer the query.
4 - The fetched information is sent back to the RAG model.
5 - The model augments the original user input by adding the fetched information to the context and sending it to the LLM endpoint. Various LLM options are Open AI’s GPT, Claude Sonnet, Google Gemini, and so on.
6 - The LLM generates an answer based on the enhanced context and provides a response to the user.
Over to you: Have you used RAG with your favorite LLM?How Two-factor Authentication (2FA) Works?
Two-factor authentication (2FA) is a type of multi-factor authentication that makes accounts more secure.

The idea behind 2FA is that you need to provide two identifying factors to prove your identity and gain access to your account.
The first factor is the knowledge factor, where a user needs to know a secret, such as a password. The second factor depends on the possession factor (such as RSA, authenticator app) or inherence factor (biometrics).
Here’s how 2FA works:The user enters username and password. This is for the first level of authentication, also known as single-factor.
The authentication request goes to the authentication server.
The authentication credentials are verified.
In case of any incorrect credentials, a certain number of retries may be allowed.
If the credentials are correct, the two-factor authentication kicks in. There are multiple options available: biometric verification, OTP verification, or Authenticator App Verification. Organizations like Google and Microsoft also provide such apps.
The user verifies using the chosen option.
If the verification fails, access is denied. However, if verification succeeds, access is granted.
Note that the OTP verification using SMS is often considered less secure as a 2FA mechanism.
Over to you - Have you used two-factor authentication?
How Amazon S3 Works?
This post is based on:
Building and operating a pretty big storage system called S3 published on All Things Distributed.

Amazon S3 is one of the largest and most complex distributed storage systems in the world. It processes millions of requests per second and stores over 350 trillion objects while maintaining 99.999999999% durability.
AWS architected S3 using a microservices-based design
Here’s how it works:Front-end Request Handling Services
These services receive API requests from clients. The clients can be web, CLI, and SDKs for programming languages like Java, Python, JS, or Golang. After receiving the request, the services authenticate users, validate requests, and route them to the correct storage service. The services consist of DNS routing, authentication service, and load balancing.Indexing and Metadata Services
Every object stored in S3 is assigned a unique identifier and metadata. The indexing services track object locations. They consist of a global metadata store and partitioning engine.Storage and Data Placement Services
This part handles the physical storage of objects across multiple S3 nodes. To protect against data loss, it uses erasure coding and multi-AZ replication.Durability and Recovery Services
These services ensure data integrity and fault recovery. They consist of checksum verification, background auditing, and disaster recovery.Security and Compliance Services
These services protect S3 from unauthorized access and support features such as IAM and bucket Policy, DDoS Mitigation, and Object Lockiand versioning.
Over to you: Have you used Amazon S3?
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.
Like
Comment
Restack
© 2025 ByteByteGo
548 Market Street PMB 72296, San Francisco, CA 94104
Unsubscribe

by "ByteByteGo" <bytebytego@substack.com> - 11:36 - 29 Mar 2025 -
Top 10 articles this quarter
McKinsey&Company
At #1: Superagency in the workplace: Empowering people to unlock AI’s full potential Our top ten articles this quarter look at the future of the office, a new demographic reality, private equity and M&A trends, and more. At No. 1, McKinsey's Hannah Mayer, Lareina Yee, Michael Chui, and Roger Roberts explore AI adoption readiness in "Superagency in the workplace: Empowering people to unlock AI’s full potential." Prompted by Reid Hoffman’s book Superagency: What Could Possibly Go Right with Our AI Future, the report concludes that employees are ready for AI, but the biggest barrier to success is leadership.

1. Superagency in the workplace: Empowering people to unlock AI’s full potential
Almost all companies invest in AI, but just 1 percent believe they are at maturity. Our research finds the biggest barrier to scaling is not employees—who are ready—but leaders, who are not steering fast enough. Think big

3. The state of AI: How organizations are rewiring to capture value
Organizations are beginning to create the structures and processes that lead to meaningful value from gen AI. While still in early days, companies are redesigning workflows, elevating governance, and mitigating more risks. See survey results
Share these insights
This email contains information about McKinsey’s research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this email because you are a registered member of the Top Ten Most Popular newsletter.
Copyright © 2025 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "McKinsey Top Ten" <publishing@email.mckinsey.com> - 10:26 - 29 Mar 2025