Archives
- By thread 5225
-
By date
- June 2021 10
- July 2021 6
- August 2021 20
- September 2021 21
- October 2021 48
- November 2021 40
- December 2021 23
- January 2022 46
- February 2022 80
- March 2022 109
- April 2022 100
- May 2022 97
- June 2022 105
- July 2022 82
- August 2022 95
- September 2022 103
- October 2022 117
- November 2022 115
- December 2022 102
- January 2023 88
- February 2023 90
- March 2023 116
- April 2023 97
- May 2023 159
- June 2023 145
- July 2023 120
- August 2023 90
- September 2023 102
- October 2023 106
- November 2023 100
- December 2023 74
- January 2024 75
- February 2024 75
- March 2024 78
- April 2024 74
- May 2024 108
- June 2024 98
- July 2024 116
- August 2024 134
- September 2024 130
- October 2024 141
- November 2024 171
- December 2024 115
- January 2025 216
- February 2025 140
- March 2025 220
- April 2025 233
- May 2025 239
- June 2025 303
- July 2025 37
-
Employees are already using AI. How can leaders catch up?
Five Fifty
Get your briefing Many workers are already using AI, and business leaders who act on this momentum face a significant opportunity. Identifying four archetypes of employee sentiment can help companies understand where encouragement might be needed, say McKinsey’s Hannah Mayer, Lareina Yee, Michael Chui, and Roger Roberts. To learn more, check out the latest edition of the Five Fifty.
Share these insights
Did you enjoy this newsletter? Forward it to colleagues and friends so they can subscribe too. Was this issue forwarded to you? Sign up for it and sample our 40+ other free email subscriptions here.
This email contains information about McKinsey’s research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this email because you subscribed to our McKinsey Quarterly Five Fifty alert list.
Copyright © 2025 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "McKinsey Quarterly Five Fifty" <publishing@email.mckinsey.com> - 05:03 - 19 Mar 2025 -
Your next coworker might be a gen AI agent
On McKinsey Perspectives
Big Tech’s AI investments Brought to you by Alex Panas, global leader of industries, & Axel Karlsson, global leader of functional practices and growth platforms
Welcome to the latest edition of Only McKinsey Perspectives. We hope you find our insights useful. Let us know what you think at Alex_Panas@McKinsey.com and Axel_Karlsson@McKinsey.com.
—Alex and Axel
—Edited by Seth Stevenson, senior editor, New York
This email contains information about McKinsey's research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this email because you subscribed to the Only McKinsey Perspectives newsletter, formerly known as Only McKinsey.
Copyright © 2025 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "Only McKinsey Perspectives" <publishing@email.mckinsey.com> - 01:43 - 19 Mar 2025 -
(Video #2 Funnel Install) Dan Henry’s Webinar Funnel!
His secret to $30M in high-ticket sales...

Hey!
Was yesterday’s presentation from Trey incredible, or what!??
For my Ecom people… This is an absolute must see presentation…
If you missed Trey Lewellen’s e-commerce funnel breakdown, go watch it here >>
Are you on pins and needles wondering who we’ll hear from today?? Drum roll please….
Dan Henry!!
GO HERE TO WATCH THE VIDEO FROM DAN HENRY AND STEAL HIS WEBINAR FUNNEL FOR FREE! >>

OK, so most of you know, Dan Henry, right?
If not… Dan… he was dead broke when he stumbled across my book, DotComSecrets.
Fast forward, he’s now done over $30 million in sales (all thanks to one simple strategy).
His secret? High-ticket webinars.
And today, he’s revealing exactly how he sells high-ticket offers on autopilot… and giving YOU the same webinar funnel template that’s made him millions.
GO HERE TO WATCH THE VIDEO FROM DAN HENRY AND STEAL HIS WEBINAR FUNNEL FOR FREE! >>
This is just Day 2! We have 5 more to go! 🤯
Tomorrow, another top expert will break down their most successful funnel… so don’t miss it!
See you then!
Russell Brunson
P.S. - Don’t forget, you’re just one funnel away….
P.P.S - To dive in and start implementing what these experts are teaching, you’ll need to get a ClickFunnels account. If you don’t have one yet, I have a special 2-week FREE TRIAL link HERE >>
© Etison LLC
By reading this, you agree to all of the following: You understand this to be an expression of opinions and not professional advice. You are solely responsible for the use of any content and hold Etison LLC and all members and affiliates harmless in any event or claim.
If you purchase anything through a link in this email, you should assume that we have an affiliate relationship with the company providing the product or service that you purchase, and that we will be paid in some way. We recommend that you do your own independent research before purchasing anything.
Copyright © 2018+ Etison LLC. All Rights Reserved.
To make sure you keep getting these emails, please add us to your address book or whitelist us. If you don't want to receive any other emails, click on the unsubscribe link below.
Etison LLC
3443 W Bavaria St
Eagle, ID 83616
United States
by "Russell @ ClickFunnels" <noreply@clickfunnelsnotifications.com> - 10:46 - 18 Mar 2025 -
(Video #2 Funnel Install) Dan Henry’s Webinar Funnel!
His secret to $30M in high-ticket sales...
Hey!
Was yesterday’s presentation from Trey incredible, or what!??
For my Ecom people… This is an absolute must see presentation…
If you missed Trey Lewellen’s e-commerce funnel breakdown, go watch it here >>
Are you on pins and needles wondering who we’ll hear from today?? Drum roll please….
Dan Henry!!
GO HERE TO WATCH THE VIDEO FROM DAN HENRY AND STEAL HIS WEBINAR FUNNEL FOR FREE! >>
OK, so most of you know, Dan Henry, right?
If not… Dan… he was dead broke when he stumbled across my book, DotComSecrets.
Fast forward, he’s now done over $30 million in sales (all thanks to one simple strategy).
His secret? High-ticket webinars.
And today, he’s revealing exactly how he sells high-ticket offers on autopilot… and giving YOU the same webinar funnel template that’s made him millions.
GO HERE TO WATCH THE VIDEO FROM DAN HENRY AND STEAL HIS WEBINAR FUNNEL FOR FREE! >>
This is just Day 2! We have 5 more to go! 🤯
Tomorrow, another top expert will break down their most successful funnel… so don’t miss it!
See you then!
Russell Brunson
P.S. - Don’t forget, you’re just one funnel away….
P.P.S - To dive in and start implementing what these experts are teaching, you’ll need to get a ClickFunnels account. If you don’t have one yet, I have a special 2-week FREE TRIAL link HERE >>
© Etison LLC
By reading this, you agree to all of the following: You understand this to be an expression of opinions and not professional advice. You are solely responsible for the use of any content and hold Etison LLC and all members and affiliates harmless in any event or claim.
If you purchase anything through a link in this email, you should assume that we have an affiliate relationship with the company providing the product or service that you purchase, and that we will be paid in some way. We recommend that you do your own independent research before purchasing anything.
Copyright © 2018+ Etison LLC. All Rights Reserved.
To make sure you keep getting these emails, please add us to your address book or whitelist us. If you don't want to receive any other emails, click on the unsubscribe link below.
Etison LLC
3443 W Bavaria St
Eagle, ID 83616
United States
by "Russell @ ClickFunnels" <noreply@clickfunnelsnotifications.com> - 10:46 - 18 Mar 2025 -
Exploring Collaboration Opportunities in Semiconductor Testing
Dear info,
Good day to you. I am reaching out on behalf of SEMISHARE, a semiconductor testing company established in 2010. With a strong focus on advanced probe stations and wafer test solutions, we have successfully completed over 1,000 projects, showcasing our expertise in various testing fields, including WAT/CP, I-V/C-V, RF/mmW, MEMS and optoelectronic testing etc.
Our commitment to quality and reliability has made us a trusted partner for chip designers and semiconductor manufacturers. We offer a range of products, from fully-automatic probers to semi-automatic and manual probers, tailored to meet diverse testing needs.
We pride ourselves on our 24/7 support, ensuring minimal delays in the fast-paced semiconductor industry. I would welcome the opportunity to discuss how we can support your testing requirements.
Thank you for considering SEMISHARE. I look forward to your response.
Best regards,
Tyeshia Winokur
by "Tyeshia Winokur" <winokurtyeshia@gmail.com> - 08:39 - 18 Mar 2025 -
Architecture project
Dear info,
Greeting from TEAM-E, wish all is going well with you.Established in 2004, we are still passionate, energetic & creative, and striving to be forefront of the CG industry. TEAM-E built up the most comprehensive service for digital visualization,specializing in:
- 3D Rendering
- 3D Animation
- Scale Model
- Mutimedia InteractionWith 21 years'deveopment, TEAM-E works successfully with every major Architectural Firm, Real estate developer, as well as the Engineering Consultancy globally.
Welcome to view our Project Portfolio & contact for inquiryl. Wish partnering with you in the near future!

Best Regards,
Sarah Chow | Vice Manager
sarah@teame3d.com
by "cong" <cong@teame3d.com> - 07:54 - 18 Mar 2025 -
Navigating the Impact of Recent U.S. Tariffs on Digital Transformation Initiatives
Navigating the Impact of Recent U.S. Tariffs on Digital Transformation Initiatives

Hi MD Abul,
I wanted to address the recent developments in U.S. trade policy and their potential implications for our digital transformation efforts.
Recent U.S. Tariff Developments
On March 12, 2025, the U.S. government imposed 25% tariffs on all steel and aluminum imports, aiming to bolster domestic production. This move has prompted immediate retaliatory measures from key trading partners, including the European Union and Canada, escalating global trade tensions.
The Organization for Economic Cooperation and Development (OECD) has expressed concerns that these tariffs could slow global economic growth and increase inflation. Their projections indicate a downward revision of growth forecasts for major economies, particularly those heavily engaged in trade with the U.S.
Implications for Digital Transformation
These trade policy shifts can have significant ramifications for organizations embarking on digital transformation:
-
Supply Chain Disruptions: Increased tariffs may lead to higher costs for hardware and infrastructure components essential for digital initiatives.
-
Budget Reallocations: Organizations might need to adjust budgets to accommodate rising costs, potentially affecting funding for technology projects.
-
Strategic Reassessment: Companies may need to revisit their digital strategies to mitigate risks associated with an unpredictable trade environment.
Third Stage Consulting's Insights
In our 2025 Digital Transformation Report, we emphasize the importance of adaptability in the face of external economic pressures. Key recommendations include:
-
Diversifying Suppliers: Reducing reliance on a single region or supplier can mitigate risks associated with trade disputes.
-
Investing in Resilient Technologies: Adopting scalable and flexible technologies can help organizations adjust to changing economic conditions.
-
Continuous Monitoring: Staying informed about policy changes enables proactive adjustments to digital strategies.
For a more in-depth analysis, I encourage you to explore our full report here.
Please feel free to reach out if you have any questions or need assistance in navigating these developments.
Best regards,
Eric Kimberling
Third Stage Consulting 384 Inverness Pkwy Suite Englewood Colorado
You received this email because you are subscribed to Marketing Information from Third Stage Consulting.
Update your email preferences to choose the types of emails you receive.
Unsubscribe from all future emails
by "Eric Kimberling" <eric.kimberling@thirdstage-consulting.com> - 05:58 - 18 Mar 2025 -
-
Enhance Efficiency with Our Induction Cookers
Dear info,
Hope this email finds you in good health. I am Cindy from Guangdong Yipai Catering Equipment Co., Ltd., a leading provider of commercial induction cookers and electric ceramic stoves.
Our induction cookers offer:
1. Efficient and Energy-Saving: Up to 30% energy savings over traditional methods.
2. Intelligent Temperature Control: Automatically adjusts temperature for optimal cooking.I would be thrilled to discuss how our products can improve your kitchen operations. Looking forward to your feedback.
Best regards,
Cindy
Guangdong Yipai Catering Equipment Co., Ltd.
by "Marjorie Esther" <diann356478@gmail.com> - 05:44 - 18 Mar 2025 -
(SSW - Video #2) The Epiphany Bridge
This ONE shift makes selling feel effortless…

What’s up!!?
Hope you LOVED Day 1 of the Story Selling Workshop!
Yesterday, we laid the foundation for how stories break down resistance, build trust, and make selling feel completely natural.
Today I’m sharing a little “secret” that literally makes people sell themselves!
It’s called the Epiphany Bridge.

Hear me out… People don’t like being “sold to.” They resist logic, facts, and data when making a buying decision. But they DO love hearing stories that spark an epiphany!!!
In today’s training, I’ll break down exactly how to craft your own Epiphany Bridge story and use it inside your sales funnels, emails, videos, and more.
So cool, right!?!
GO WATCH VIDEO 2 IN THE FREE STORY SELLING WORKSHOP HERE >>
We’re only half way done! I still have two more FREE training videos for you in this workshop. Watch for video #3 tomorrow!
See you then!
Russell Brunson
P.S. Don’t forget, you’re just one funnel away…
P.P.S. If you missed video #1 of Story selling, go here >>
Then… watch video #2 (“Epiphany Bridge”) here >>Marketing Secrets
3443 W Bavaria St
Eagle, ID 83616
United States
by "Russell Brunson" <newsletter@marketingsecrets.com> - 03:22 - 18 Mar 2025 -
How Netflix Stores 140 Million Hours of Viewing Data Per Day
How Netflix Stores 140 Million Hours of Viewing Data Per Day
In this article, we’ll learn how Netflix tackled these problems and improved their storage system to handle millions of hours of viewing data every day.͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ Forwarded this email? Subscribe here for more🚀Faster mobile releases with automated QA (Sponsored)

Manual testing on mobile devices is too low and too limited. It forces teams to cut releases a week early just to test before submitting them to app stores. And without broad device coverage, issues slip through.
QA Wolf’s AI-native service delivers 80% automated test coverage in weeks, with test running on real iOS devices and Android emulators—all in 100% parallel with zero flakes.
QA cycles reduced to just 15 minutes
Multi-device + gesture interactions fully supported
Reliable test execution with zero flakes
Human-verified bug reports
Engineering teams move faster, releases stay on track, and testing happens automatically—so developers can focus on building, not debugging.
Rated 4.8/5 ⭐ on G2
Disclaimer: The details in this post have been derived from the Netflix Tech Blog. All credit for the technical details goes to the Netflix engineering team. Some details related to Apache Cassandra® have been taken from Apache Cassandra® official documentation. Apache Cassandra® is a registered trademark of The Apache Software Foundation. The links to the original articles are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
Every single day millions of people stream their favorite movies and TV shows on Netflix.
With each stream, a massive amount of data is generated: what a user watches, when they pause, rewind, or stop, and what they return to later. This information is essential for providing users with features like resume watching, personalized recommendations, and content suggestions.
However, Netflix's growth has led to an explosion of time series data (data recorded over time, like a user’s viewing history). The company relies heavily on this data to enhance the user experience, but handling such a vast and ever-increasing amount of information also presents a technical challenge in the following ways:
Every time a user watches a show or movie, new records are added to their viewing history. This history keeps growing, making it harder to store and retrieve efficiently.
As millions of people use Netflix, the number of viewing records increases not just for individual users but across the entire platform. This rapid expansion means Netflix must continuously scale its data storage systems.
When Netflix introduces new content and features, people spend more time watching. With the rise of binge-watching and higher-quality streaming (like 4K videos), the amount of viewing data per user is also increasing.
A failure to manage this data properly could lead to catastrophic user experience delays when loading watch history. It could also result in useless recommendations, or even lost progress in shows.
In this article, we’ll learn how Netflix tackled these problems and improved their storage system to handle millions of hours of viewing data every day.
The Initial Approach
When Netflix first started handling large amounts of viewing data, they chose Apache Cassandra® for the following reasons:
Apache Cassandra® allows for a flexible structure, where each row can store a growing number of viewing records without performance issues.
Netflix’s system processes significantly more writes (data being stored) than reads (data being retrieved). The ratio is approximately 9:1, meaning for every 9 new records added, only 1 is read. Apache Cassandra® excels in handling such workloads.
Instead of enforcing strict consistency, Netflix prioritizes availability and speed, ensuring users always have access to their watch history, even if data updates take a little longer to sync. Apache Cassandra® supports this tradeoff with eventual consistency, meaning that all copies of data will eventually match up across the system.
See the diagram below, which shows the data model of Apache Cassandra® using column families.
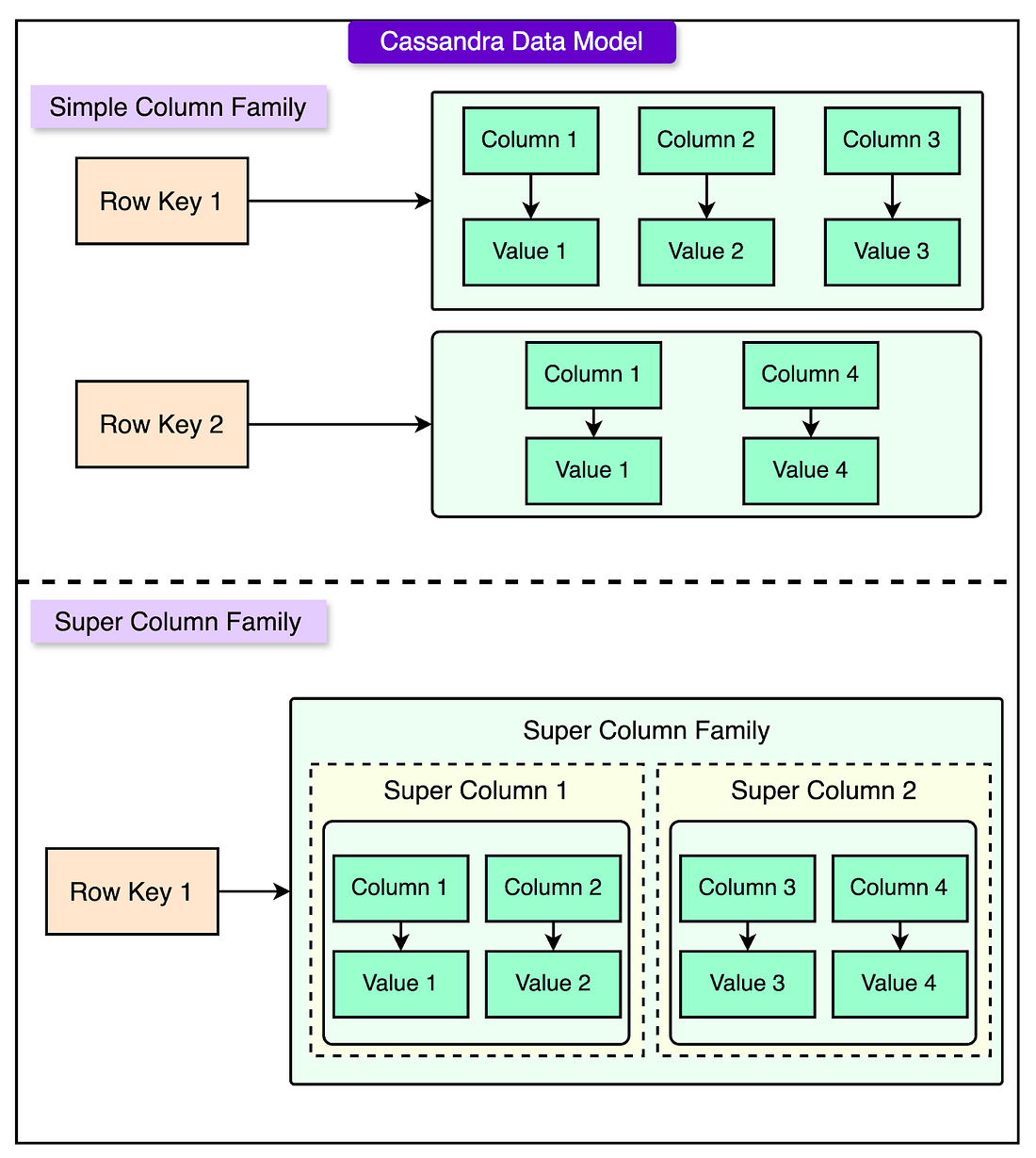
To structure the data efficiently, Netflix designed a simple yet scalable storage model in Cassandra®.
Each user’s viewing history was stored under their unique ID (CustomerId). Every viewing record (such as a movie or TV show watched) was stored in a separate column under that user’s ID. To handle millions of users, Netflix used "horizontal partitioning," meaning data was spread across multiple servers based on CustomerId. This ensured that no single server was overloaded.
Reads and Writes in the Initial System
The diagram below shows how the initial system handled reads and writes to the viewing history data.
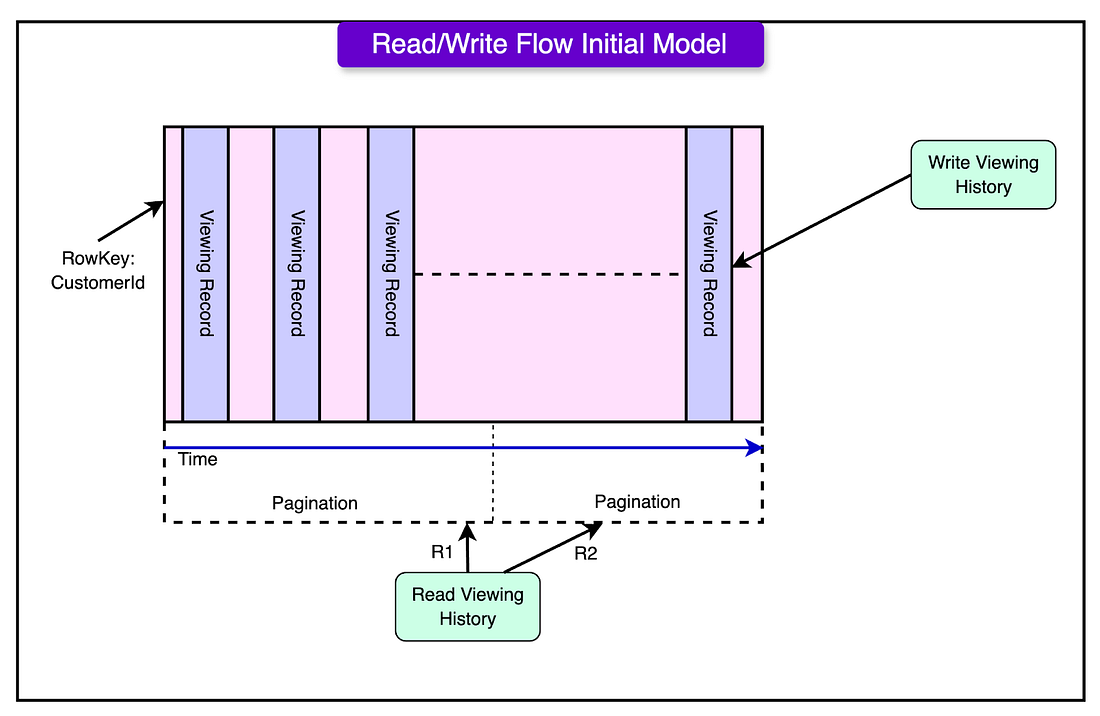
Every time a user started watching a show or movie, Netflix added a new column to their viewing history record in the database. If the user paused or stopped watching, that same column was updated to reflect their latest progress.
While storing data was easy, retrieving it efficiently became more challenging as users' viewing histories grew. Netflix used three different methods to fetch data, each with its advantages and drawbacks:
Retrieving the Entire Viewing History: If a user had only watched a few shows, Netflix could quickly fetch their entire history in one request. However, for long-time users with large viewing histories, this approach became slow and inefficient as more data accumulated.
Searching by Time Range: Sometimes, Netflix only needed to fetch records from a specific time period, like a user’s viewing history from the last month. While this method worked well in some cases, performance varied depending on how many records were stored within the selected time range.
Using Pagination for Large Histories: To avoid loading huge amounts of data at once, Netflix used pagination. This approach prevented timeouts (when a request takes too long and fails), but it also increased the overall time needed to retrieve all records.
At first, this system worked well because it provided a fast and scalable way to store viewing history. However, as more users watched more content, this system started to hit performance limits. Some of the issues were as follows:
Too Many SSTables: Apache Cassandra® stores data in files called SSTables (Sorted String Tables). Over time, the number of these SSTables increased significantly. For every read, the system had to scan multiple SSTables across the disk, making the process slower.
Compaction Overhead: Apache Cassandra® performs compactions to merge multiple SSTables into fewer, more efficient ones. With more data, these compactions took longer and required more processing power. Other operations like read repair and full column repair also became expensive.
To speed up data retrieval, Netflix introduced a caching solution called EVCache.
Instead of reading everything from the Apache Cassandra® database every time, each user’s viewing history is stored in a cache in a compressed format. When a user watches a new show, their viewing data is added to Apache Cassandra® and merged with the cached value in EVCache. If a user’s viewing history is not found in the cache, Netflix fetches it from Cassandra®, compresses it, and then stores it in EVCache for future use.
By adding EVCache, Netflix significantly reduced the load on their Apache Cassandra® database. However, this solution also had its limits.
The New Approach: Live & Compressed Storage Model
One important fact about the viewing history data was this: most users frequently accessed only their recent viewing history, while older data was rarely needed. However, storing everything the same way led to unnecessary performance and storage costs.
To solve this, Netflix redesigned its storage model by splitting viewing history into two categories:
Live Viewing History (LiveVH): It stores recently watched content that users access frequently. It is also uncompressed for fast reads and writes. This is designed for quick updates, like when a user pauses or resumes a show.
Compressed Viewing History (CompressedVH): Stores older viewing records that are accessed less frequently. It is compressed to save storage space and improve performance.
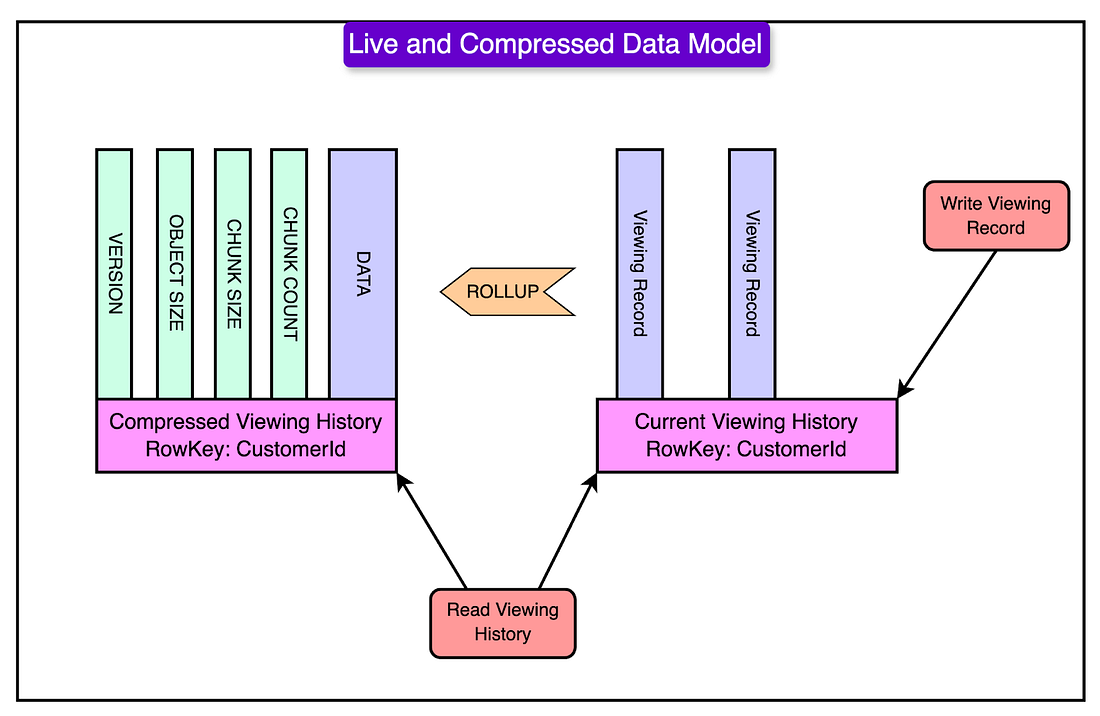
Since LiveVH and CompressedVH serve different purposes, they were tuned differently to maximize performance.
For LiveVH, which stores recent viewing records, Netflix prioritized speed and real-time updates. Frequent compactions were performed to clean up old data and keep the system running efficiently. Additionally, a low GC (Garbage Collection) grace period was set, meaning outdated records were removed quickly to free up space. Since this data was accessed often, frequent read repairs were implemented to maintain consistency, ensuring that users always saw accurate and up-to-date viewing progress.
On the other hand, CompressedVH, which stores older viewing records, was optimized for storage efficiency rather than speed. Since this data was rarely updated, fewer compactions were needed, reducing unnecessary processing overhead. Read repairs were also performed less frequently, as data consistency was less critical for archival records. The most significant optimization was compressing the stored data, which drastically reduced the storage footprint while still making older viewing history accessible when needed.
The Large View History Performance Issue
Even with compression, some users had extremely large viewing histories. For these users, reading and writing a single massive compressed file became inefficient.
If CompressedVH grows too large, retrieving data becomes slow. Also, single large files create performance bottlenecks when read or written. To avoid these issues, Netflix introduced chunking, where large compressed data is split into smaller parts and stored across multiple Apache Cassandra® database nodes.
Here’s how it works:
Instead of storing everything in one large file, Netflix stores metadata that tracks data version and chunk count.
Instead of writing one large file, each chunk is written separately. A metadata entry keeps track of all the chunks, ensuring efficient storage.
Metadata is read first, so Netflix knows how many chunks to retrieve. Chunks are fetched in parallel, significantly improving read speeds.
This system gave Netflix the headroom needed to handle future growth.
The New Challenges
With the global expansion of Netflix, the company launched its service in 130+ new countries and introduced support for 20 languages. This led to a massive surge in data storage and retrieval needs.
At the same time, Netflix introduced video previews in the user interface (UI), a feature that allowed users to watch short clips before selecting a title. While this improved the browsing experience, it also dramatically increased the volume of time-series data being stored.
When Netflix analyzed the performance of its system, it found several inefficiencies:
The storage system did not differentiate between different types of viewing data. Video previews and full-length plays were stored identically, despite having very different usage patterns.
Language preferences were stored repeatedly across multiple viewing records, leading to unnecessary duplication and wasted storage.
Since video previews generated many short playback records, they accounted for 30% of the data growth every quarter.
Netflix’s clients (such as apps and web interfaces) retrieved more data than they needed. Most queries only required recent viewing data, but the system fetched entire viewing histories regardless. Because filtering happened after data was fetched, huge amounts of unnecessary data were transferred across the network, leading to high bandwidth costs and slow performance.
Read latencies at the 99th percentile (worst-case scenarios) became highly unpredictable. Some queries were fast, but others took too long to complete, causing an inconsistent user experience.
At this stage, Netflix’s existing architecture could no longer scale efficiently.
Apache Cassandra® had been a solid choice for scalability, but by this stage, Netflix was already operating one of the largest Apache Cassandra® clusters in existence. The company had already pushed Apache Cassandra® to its limits, and without a new approach, performance issues would continue to worsen as the platform grew.
A more fundamental redesign was needed.
Netflix’s New Storage Architecture
To overcome the growing challenges of data overload, inefficient retrieval, and high latency, Netflix introduced a new storage architecture that categorized and stored data more intelligently.
Step 1: Categorizing Data by Type
One of the biggest inefficiencies in the previous system was that all viewing data (whether it was a full movie playback, a short video preview, or a language preference setting) was stored together.
Netflix solved this by splitting viewing history into three separate categories, each with its dedicated storage cluster:
Full Title Plays: Data related to complete or partial streaming of movies and TV shows. This is the most critical data because it affects resume points, recommendations, and user engagement metrics.
Video Previews: Short clips that users watch while browsing content. Since this data grows quickly but isn’t as important as full plays, it required a different storage strategy.
Language Preferences: Information on which subtitles or audio tracks a user selects. This was previously stored redundantly across multiple viewing records, wasting storage. Now, it is stored separately and referenced when needed.
Step 2: Sharding Data for Better Performance
Netflix sharded (split) its data across multiple clusters based on data type and data age, improving both storage efficiency and query performance.
See the diagram below for reference:
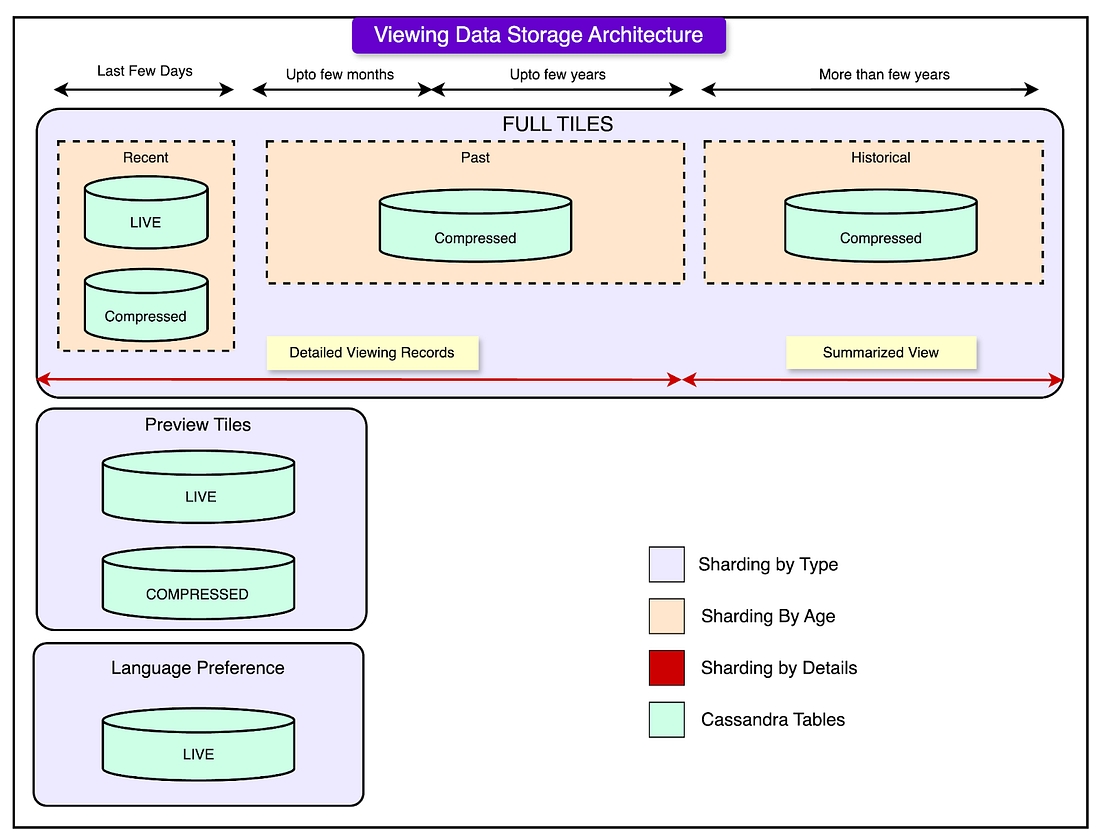
1 - Sharding by Data Type
Each of the three data categories (Full Plays, Previews, and Language Preferences) was assigned its separate cluster.
This allowed Netflix to tune each cluster differently based on how frequently the data was accessed and how long it needed to be stored. It also prevented one type of data from overloading the entire system.
2 - Sharding by Data Age
Not all data is accessed equally. Users frequently check their recent viewing history, but older data is rarely needed. To optimize for this, Netflix divided its data storage into three time-based clusters:
Recent Cluster (Short-Term Data): Stores viewing data from the past few days or weeks. Optimized for fast reads and writes since recent data is accessed most frequently.
Past Cluster (Archived Data): Holds viewing records from the past few months to a few years. Contains detailed records, but is tuned for slower access since older data is less frequently requested.
Historical Cluster (Summarized Data for Long-Term Storage): Stores compressed summaries of viewing history from many years ago. Instead of keeping every detail, this cluster only retains key information, reducing storage size.
Optimizations in the New Architecture
To keep the system efficient, scalable, and cost-effective, the Netflix engineering team introduced several key optimizations.
1 - Improving Storage Efficiency
With the introduction of video previews and multi-language support, Netflix had to find ways to reduce the amount of unnecessary data stored. The following strategies were adopted:
Many previews were only watched for a few seconds, which wasn’t a strong enough signal of user interest. Instead of storing every short preview play, Netflix filtered out these records before they were written to the database, significantly reducing storage overhead.
Previously, language preference data (subtitles/audio track choices) was duplicated across multiple viewing records. This was inefficient, so Netflix changed its approach. Now, each user's language preference is stored only once, and only changes (deltas) are recorded when the user selects a different language.
To keep the database from being overloaded, Netflix implemented Time-To-Live (TTL)-based expiration, meaning that unneeded records were deleted automatically after a set period.
Netflix continued using two separate storage methods to store recent data in an uncompressed format and older data in compressed format.
2 - Making Data Retrieval More Efficient
Instead of fetching all data at once, the system was redesigned to retrieve only what was needed:
Recent data requests were directed to the Recent Cluster to support low-latency access for users checking their recently watched titles.
Historical data retrieval was improved with parallel reads. Instead of pulling old records from a single location, Netflix queried multiple clusters in parallel, making data access much faster.
Records from different clusters were intelligently stitched together. Even when a user requested their entire viewing history, the system combined data from various sources quickly and efficiently.
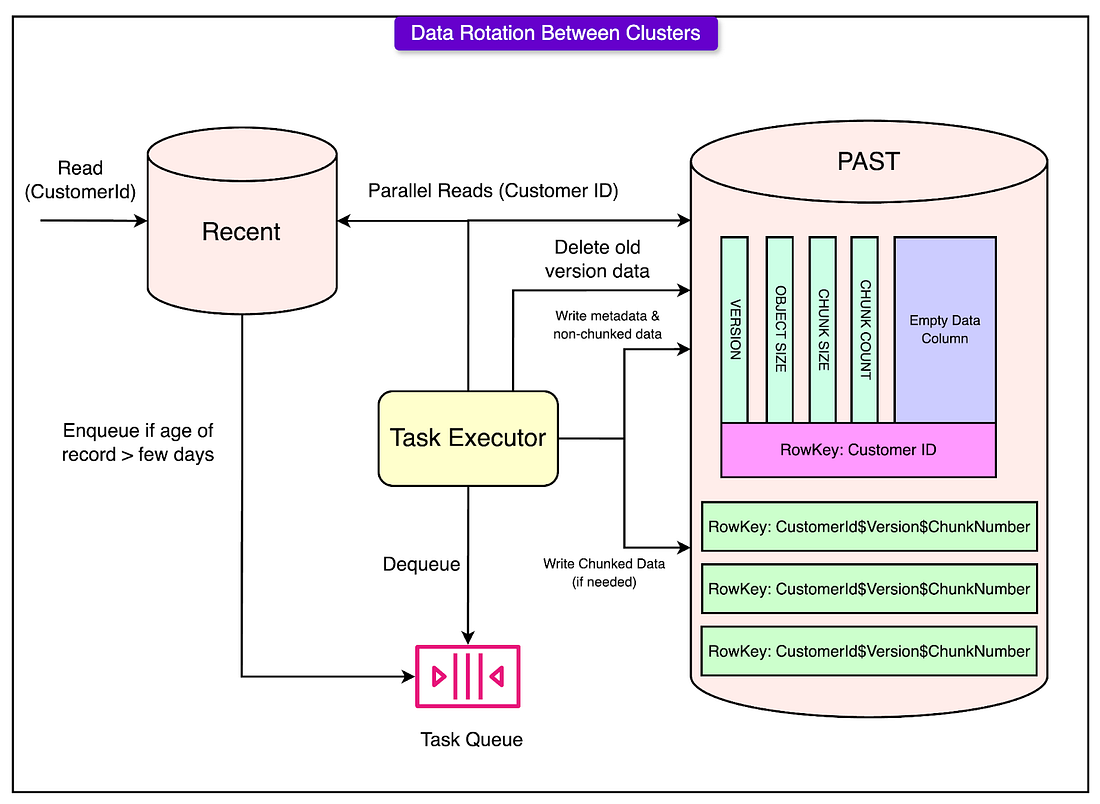
3 - Automating Data Movement with Data Rotation
To keep the system optimized, Netflix introduced a background process that automatically moved older data to the appropriate storage location:
Recent to Past Cluster: If a viewing record was older than a certain threshold, it was moved from the Recent Cluster to the Past Cluster. This ensured that frequently accessed data stayed in a fast-access storage area, while older data was archived more efficiently.
Past to Historical Cluster: When data became older, it was summarized and compressed, then moved to the Historical Cluster for long-term storage with minimal resource usage.
Parallel writes & chunking were used to ensure that moving large amounts of data didn’t slow down the system.
See the diagram below:
4 - Caching for Faster Data Access
Netflix restructured its EVCache (in-memory caching layer) to mirror the backend storage architecture.
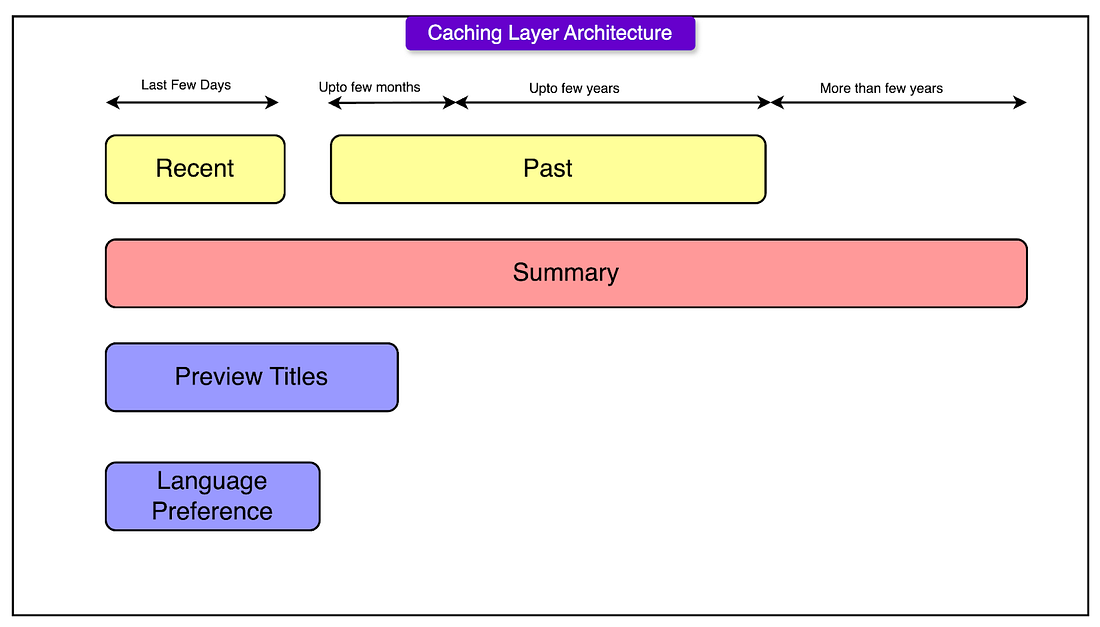
A new summary cache cluster was introduced, storing precomputed summaries of viewing data for most users. This meant that instead of computing summaries every time a user made a request, Netflix could fetch them instantly from the cache. They managed to achieve a 99% cache hit rate, meaning that nearly all requests were served from memory rather than querying Apache Cassandra®, reducing overall database load.
Conclusion
With the growth that Netflix went through, their engineering team had to evolve the time-series data storage system to meet the increasing demands.
Initially, Netflix relied on a simple Apache Cassandra®-based architecture, which worked well for early growth but struggled as data volume soared. The introduction of video previews, global expansion, and multilingual support pushed the system to its breaking point, leading to high latency, storage inefficiencies, and unnecessary data retrieval.
To address these challenges, Netflix redesigned its architecture by categorizing data into Full Title Plays, Video Previews, and Language Preferences and sharding data by type and age. This allowed for faster access to recent data and efficient storage for older records.
These innovations allowed Netflix to scale efficiently, reducing storage costs, improving data retrieval speeds, and ensuring a great streaming experience for millions of users worldwide.
Note: Apache Cassandra® is a registered trademark of the Apache Software Foundation.
References:
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.
Like
Comment
Restack
© 2025 ByteByteGo
548 Market Street PMB 72296, San Francisco, CA 94104
Unsubscribe

by "ByteByteGo" <bytebytego@substack.com> - 11:36 - 18 Mar 2025 -
Birchwood Golf Club is one of the finest venues in the Warrington area
Birchwood Golf Club is one of the finest venues in the Warrington area
Hi there,
Birchwood Golf Club is one of the finest venues in the Warrington area and the opportunity to promote Your Telecoms Consultant on the My Caddie Golf Platform featuring this club does not come around often.
Golf enthusiasts often include local business owners professionals and high net worth individuals. This partnership allows you to showcase your produts and services and gain access to a wealth of potential new clients.
The partnership package we have put together for Telecommunication Companies includes the following unique benefits:
1) Complimentary golf for you to entertain clients, colleagues and guests.
2) Exposure on the members and visitors Android app.
3) Your branding on the flyovers on one of the holes on our Birchwood Golf Club web flyovers which is trackable and targeted to your demographic within the local area.
4) Providing you with exposure on the members and visitors iPhone app.
5) Exclusivity for your sector.
6) Access to our networking groups between all partners and plus ones.
All of this costs equivalent of just £26 per week for a 2-year partnership + £399 Artwork (one-off, optional) + VAT.
I am excited about discussing how this partnership can seamlessly integrate with your company's objectives and create new avenues for customer engagement. I'd be delighted to arrange a meeting to delve deeper into the details.
Best wishes,
Jack StevensAccount Manager0113 5197 994
We have sent this email to info@learn.odoo.com having found your company contact details online. If you don't want to get any more emails from us you can stop them here.
West 1 Group UK Limited, registered in England and Wales under company number 07574948. Our registered office is Unit 1 Airport West, Lancaster Way, Yeadon, Leeds, West Yorkshire, LS19 7ZA.
Disclaimer: Our app operates independently. While we provide authentic and accurate hole-by-hole guides, we do not have a direct association with Birchwood Golf Club or claim any endorsement from them. We aim to offer golfers a reliable guide as they navigate their favourite courses. As a value-add for our advertisers, we offer free tee times at Birchwood Golf Club which we procure as any customer would, directly from the venue. We also host networking events, which may be held a various local venues as well as online sessions.Furthermore, advertisers have the unique opportunity to be featured in our flyovers of each golf hole. All offerings are subject to availability and terms.
by "Jack Stevens" <jack@w1g.biz> - 08:27 - 18 Mar 2025 -
You're Invited! Product Expert Series: Intelligent Observability for Digital Experience
New Relic

Join us for our Product Expert Series: Intelligent Observability for Digital Experience.
This is your chance for a deep dive tour from the New Relic product experts behind Engagement Intelligence and Streaming Video & Ads Intelligence. Learn how you can:- Tap user behaviour to untangle impactful issues
- Connect frontend signals to backend performance
- Detect user friction and performance bottlenecks instantly
- Optimise video and ad streaming without buying a new tool
- Gain full-stack visibility across app, infra, and client
This live session is ideal for asking questions in real-time, discussing your top use cases, and seeing how Intelligent Observability improves digital experiences in real-world scenarios.
Register Now 


View in browser
This email was sent to info@learn.odoo.com. Update your email preferences.For information about our privacy practices, see our Privacy Policy.
Need to contact New Relic? You can chat or call us at +44 20 3859 9190
Strand Bridge House, 138-142 Strand, London WC2R 1HH
© 2025 New Relic, Inc. All rights reserved. New Relic logo are trademarks of New Relic, Inc.
by "New Relic" <emeamarketing@newrelic.com> - 06:07 - 18 Mar 2025 -
The best choice for improving feed production efficiency: our pellet mills
Dear Sir/Madam,
I hope this message finds you well. My name is Sandy, and I am reaching out on behalf of Sinova Technologies, a leading provider of customized machinery and comprehensive engineering solutions.
At Sinova Technologies, we specialize in designing and manufacturing high-performance equipment tailored to meet the unique demands of your industry. Our core products include:Pellet Mill : Efficient and durable crushing solutions for a wide range of materials.
Mixers: Precision mixing technology to ensure consistent and high-quality results.
Hammer Mill: Advanced granulation systems designed for optimal particle size and output.
What sets us apart is our commitment to delivering custom-engineered solutions that align with your specific operational requirements. Whether you need a standalone machine or a complete turnkey system, our team of experts is dedicated to providing innovative, reliable, and cost-effective solutions.
We would love to explore how Sinova Technologies can support your business goals. If you’re interested, I’d be happy to schedule a call or provide additional information about our products and services.
Looking forward to hearing from you!

Best regards,
Sandy Song
Sinova Technologies
www.sinova-group.com
by "Manager" <Manager@stcfeedmachines.com> - 04:30 - 18 Mar 2025 -
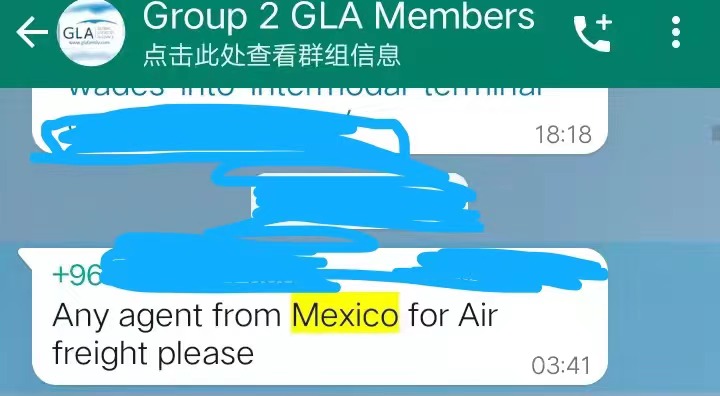
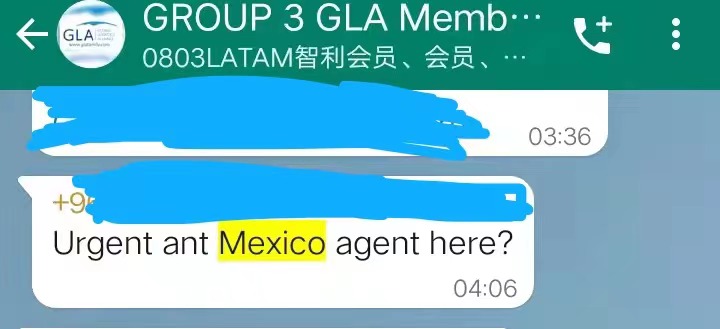
RE: Freight Enquiry for Agents in Mexico/GLA
Dear Sir/Madam,
This is Alina from GLA. Do you provide international logistics services?
We are looking for Mexico agents to provide a quote and local service. Our inquiries have not been settled, we‘re planning to invite another quality Mexico agent in the first quarter of this year. Do you plan to start a partnership with us?
Below are the inquiries from our agents:
For mutual support, we would like to offer the best deal on membership fees for you. I am looking forward to your early feedback.
Best Regards,
Alina

Ø The 11th GLA Conference in Bangkok Thailand, online album
Ø The 10th GLA Conference in Dubai UAE, online album
Ø The 9th GLA Conference in Hainan China, online album
AlinaOverseas DeptM: +86 18948304258
( Whatsapp & Wechat)
A:GLA Co.,Limited
HongChang Plaza, 2001,Shennan Dong Road,Shenzhen
518000,China
by "GLA Alina" <member039@glafamily.com> - 03:08 - 18 Mar 2025 -
How are mobility start-ups accelerating growth?
On McKinsey Perspectives
Six moves to make Brought to you by Alex Panas, global leader of industries, & Axel Karlsson, global leader of functional practices and growth platforms
Welcome to the latest edition of Only McKinsey Perspectives. We hope you find our insights useful. Let us know what you think at Alex_Panas@McKinsey.com and Axel_Karlsson@McKinsey.com.
—Alex and Axel
•
Competitive pressure. As start-ups and established OEMs alike invest in autonomous driving, connectivity, electrification, and other major trends, the mobility industry has entered a new age of innovation. Since 2010, thousands of entrepreneurial businesses have attracted billions in funding, explain McKinsey’s Kersten Heineke, Philipp Kampshoff, and Timo Möller. Yet despite substantial financial backing, some start-ups are still shutting down.
—Edited by Belinda Yu, editor, Atlanta
This email contains information about McKinsey's research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this email because you subscribed to the Only McKinsey Perspectives newsletter, formerly known as Only McKinsey.
Copyright © 2025 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "Only McKinsey Perspectives" <publishing@email.mckinsey.com> - 11:09 - 17 Mar 2025 -
SSWW--Luxury Sanitary Facrory in China
Dear info,
Glad to hear that you’re on the market for sanitary,we specialize in this field for 30 years,with 4 different factories to manufacture different kind of sanitary products inclduing bathtub, steam room, ceramic toilet, basin, bathroom cabinet, hardware mixer and shower enclosur since 1994.
We have been export to Pakistan for more than 10 years,Aqua Solution is one of our partner in India, Hoprfully we can work with you together.
Should you have any questions,call me,let’s talk details.
Best regards,
Sam
Sales Manager
by "Celia" <Celia@kingfitglobal.net> - 11:09 - 17 Mar 2025 -
Develop a integration strategy and unlock your data
Learn how to establish connectivity and reliability across your IT estate
CIO Guide to Integration.

Download whitepaper Organisations seek new technologies and industry trends to stay agile in the marketplace. To do so, their entire collection of digital building blocks, including data, LLMs, and processes, must be streamlined, connected, and accessible.
Teams look to IT leadership to help navigate these uncharted waters, and a comprehensive integration strategy is the first step.
Explore the CIO Guide to Integration and get started today.
© 2025, Salesforce, Inc.
Salesforce.com 2 Silom Edge, 14th Floor, Unit S14001-S14007, Silom Road, Suriyawong, Bangrak, Bangkok 10500
General Enquiries: +66 2 430 4323




This email was sent to info@learn.odoo.com
Manage Preferences or Unsubscribe | Privacy Statement
Powered by Salesforce Marketing Cloud
by "MuleSoft from Salesforce" <apacemarketing@mail.salesforce.com> - 11:08 - 17 Mar 2025 -
I’m giving you 7 FREE funnels (Starting NOW!)
Day 1 is Trey Lewellen’s secret to $100M in e-commerce!
OK… I’ve got something really cool lined up for you this week!
I’m so pumped to tell you about this!
Every day for the next 7 days, I’m giving you access to a presentation from a top marketing expert, showing you EXACTLY how they built their most successful funnel…
But that’s not all… You’ll also get their entire funnel template for FREE!
Kicking things off for DAY 1… Trey Lewellen!
If you don’t know Trey… he’s made over $100 million selling physical products online.
That’s more than anyone in ClickFunnels history!!!
GO HERE TO WATCH THE FIRST VIDEO FROM TREY LEWELLEN AND STEAL HIS ECOM FUNNEL FOR FREE! >>

In this video he’s breaking down the exact e-commerce funnel that allows him to…
Launch a brand-new product every week…
Make sales on Day 1 (without expensive ads)...
Scale to six or seven figures, without holding a ton of inventory…
And today, he’s revealing exactly how he sets up his PROVEN Ecom framework… and giving YOU the same webinar funnel template that’s made him millions.
GO HERE TO WATCH THE FIRST VIDEO FROM TREY LEWELLEN AND STEAL HIS ECOM FUNNEL FOR FREE! >>
And BTW…. Let me clarify how the next 7 days/emails from me could change your life…
This means no guessing, no starting from scratch… Just plug in your offer, hit launch, and start seeing results.
The best part??
This is just Day 1!!!
And trust me, the next 6 days are gonna be just as powerful.
See you tomorrow for Day 2…
Enjoy!
Russell Brunson
P.S. - Don’t forget, you’re just one funnel away….
© Etison LLC
By reading this, you agree to all of the following: You understand this to be an expression of opinions and not professional advice. You are solely responsible for the use of any content and hold Etison LLC and all members and affiliates harmless in any event or claim.
If you purchase anything through a link in this email, you should assume that we have an affiliate relationship with the company providing the product or service that you purchase, and that we will be paid in some way. We recommend that you do your own independent research before purchasing anything.
Copyright © 2018+ Etison LLC. All Rights Reserved.
To make sure you keep getting these emails, please add us to your address book or whitelist us. If you don't want to receive any other emails, click on the unsubscribe link below.
Etison LLC
3443 W Bavaria St
Eagle, ID 83616
United States
by "Russell @ ClickFunnels" <noreply@clickfunnelsnotifications.com> - 07:34 - 17 Mar 2025 -
[FREE WORKSHOP] How to use story selling
Learn how stories do all the heavy lifting
What’s up everyone!!
This week I’ve got something up my sleeve that I think will absolutely blow you away!
People ask me all the time, “What’s your secret sauce, Russell??”
Well… That’s EXACTLY what I’m going to reveal to you in this FREE STORY SELLING WORKSHOP!!
For the next few days, I’ll be sending you links to a free Story Selling Workshop, where you’ll discover how to sell more, convert better, and never feel “sales-y” again.
This is the secret weapon I use… And I’m guessing your competitors are using it too! So you need to know this!!
Here’s the BIG IDEA: The best marketers don’t “sell.” They tell stories that make people WANT to buy.
It’s not about pressure, tactics, or gimmicks, it’s about leading people to the “a-ha” moment where they convince themselves.
SIGN UP FOR THE FREE STORY SELLING WORKSHOP HERE >>
Here’s what you’ll see on Day 1 of the workshop…
✔ Why stories break down resistance (and how to craft yours)
✔ The #1 mistake that kills conversions - and how to avoid it
✔ How to replace “selling” with simple, powerful storytelling
It all starts with Lesson 1 of the Workshop! Are you in??
SIGN UP FOR THE FREE STORY SELLING WORKSHOP HERE >>
Stay tuned… tomorrow, we go even deeper into this game-changing strategy. (Spoiler… I’m going to be talking about the epiphany bridge!)
See you in the workshop!
Russell Brunson
P.S. Don’t forget, you’re just one funnel away…
P.P.S - I teach what’s covered in this masterclass AND MUCH MORE in the selling online event I have coming up at the end of the month. Have you seen that yet? CLICK HERE TO LEARN MORE ABOUT SELLING ONLINE!
Marketing Secrets
3443 W Bavaria St
Eagle, ID 83616
United States
by "Russell Brunson" <newsletter@marketingsecrets.com> - 07:18 - 17 Mar 2025 -
Introducing Trendy Multi-Sofa Fabrics – No MOQ, Certified, and Ready to Ship
Dear info,
I hope this email finds you well.
I am reaching out to introduce our company, a Poland-based brand specializing in high-quality multi-sofa fabrics. With our headquarters in Poland and additional warehouses in Germany, Italy, and Romania, we ensure seamless distribution across Europe.
We maintain a vast inventory of over 10 million fabric in China, allowing us to supply orders with no minimum order quantity (MOQ). All our products come with the necessary certifications, ensuring quality and compliance with industry standards.
Having established strong relationships with major partners, including Home Centre in Dubai, we are keen to explore new collaborations. We would love the opportunity to share some of our latest trending designs that are currently in high demand in the market.
Would you be open to discussing how our fabrics can add value to your business? I would be happy to provide samples or further details at your convenience.
Looking forward to your thoughts.
Best regards,
SIC textile(hangzhou)co.,ltd
by "Font Pacapac" <fontpacapac@gmail.com> - 01:45 - 17 Mar 2025