Archives
- By thread 5378
-
By date
- June 2021 10
- July 2021 6
- August 2021 20
- September 2021 21
- October 2021 48
- November 2021 40
- December 2021 23
- January 2022 46
- February 2022 80
- March 2022 109
- April 2022 100
- May 2022 97
- June 2022 105
- July 2022 82
- August 2022 95
- September 2022 103
- October 2022 117
- November 2022 115
- December 2022 102
- January 2023 88
- February 2023 90
- March 2023 116
- April 2023 97
- May 2023 159
- June 2023 145
- July 2023 120
- August 2023 90
- September 2023 102
- October 2023 106
- November 2023 100
- December 2023 74
- January 2024 75
- February 2024 75
- March 2024 78
- April 2024 74
- May 2024 108
- June 2024 98
- July 2024 116
- August 2024 134
- September 2024 130
- October 2024 141
- November 2024 171
- December 2024 115
- January 2025 216
- February 2025 140
- March 2025 220
- April 2025 233
- May 2025 239
- June 2025 303
- July 2025 192
-
Enhance Operational Efficiency with Shen Gong’s Certified Industrial Knives
Dear info,
I am Lmar Kiitty from Sichuan Shen Gong Carbide Knives Co., Ltd., the world’s largest manufacturer of carbide knives and blades since 1998. With ISO9001 certification and a track record as a trusted OEM partner, we provide a diverse range of high-performance industrial knives designed to improve operational efficiency.
Our product offerings include:
· Corrugated Slitter Scorer Knives
· Coil Slitting Knives, Razor Blades, Guillotine Knives
· Pelletizing and Granulator Knives
· Custom Solutions for Precision Cutting Needs
Shen Gong combines carbide material technology with manufacturing expertise to deliver durable, high-quality products that reduce maintenance and enhance productivity. Please let us know if you’d like more information or a customized solution tailored to your needs.

Warm Regards,
Lmar Kiitty
Overseas Sales Manager
Sichuan Shen Gong Carbide Knives Co., Ltd.
by "Lmar Kiitty" <kiittylmar709@gmail.com> - 05:38 - 4 Apr 2025 -
Collaborate with a Leading Industrial PC Manufacturer in China
Dear info,
My name is Robin Chen, and I am reaching out from APQ, a leading industrial PC manufacturer in China.
Ranked among the top three in our industry, we pride ourselves on our strong R&D capabilities, robust production systems, and effective sales channels.
We are currently looking to build partnerships with valued companies aboard. On our website: www.apuqi.net, you will find our company introduction and product catalog for your consideration.
Please feel free to reach out if you would like to explore opportunities to work together.
Best Regards!
Robin Chen
Overseas Operations
MobileCN/WhatsApp:+86 183-5162-8738
Website: www.apuqi.net
by "marketing" <marketing@apqtech.cn> - 03:16 - 4 Apr 2025 -
🚨LAST CHANCE! Will I see you in the masterclass?? 🚨
You should hop on the ‘52 Funnels’ I’m hosting with my good friends Paul Counts, Shreya Banerjee.

I know you “say” you’re busy…
But do you have 60 minutes… to change your life forever and finally have an online business that could set you financially free???
If so, you should hop on the live FREE Masterclass I’m hosting with my good friends Paul Counts, Shreya Banerjee.

If you’ve missed my emails up til now…
We’re gonna reveal a BUNCH of ready-to-launch funnels we pre-built for you.
As well as the sales page, upsell flow, email follow ups, everything…
Even the products!
So go save your spot because they are filling up fast, and I’m not sure when we’re going to offer this masterclass again…
We’re gonna walk you step-by-step through taking these funnels, and launching them in less than 15 minutes.
Don’t wait.
Save your spot here:
Russell Brunson
P.S. - Don’t forget, you’re just one funnel away….
© Etison LLC
By reading this, you agree to all of the following: You understand this to be an expression of opinions and not professional advice. You are solely responsible for the use of any content and hold Etison LLC and all members and affiliates harmless in any event or claim.
If you purchase anything through a link in this email, you should assume that we have an affiliate relationship with the company providing the product or service that you purchase, and that we will be paid in some way. We recommend that you do your own independent research before purchasing anything.
Copyright © 2018+ Etison LLC. All Rights Reserved.
To make sure you keep getting these emails, please add us to your address book or whitelist us. If you don't want to receive any other emails, click on the unsubscribe link below.
Etison LLC
3443 W Bavaria St
Eagle, ID 83616
United States
by "Russell | ClickFunnels" <noreply@clickfunnelsnotifications.com> - 02:33 - 4 Apr 2025 -
Make every step more dynamic: our shoe recommendations!
Dear info,
Have a nice day.
This is Andy from China. We got your info from google. We are a trader and manufacturer over 10 years specialized in custom sneaker, slippers, sandals,sport shoes .
As a professional trader, Our team has more than 10 years experience with the market. we have a highly efficient and experienced team to develop up-to-date designs and customized products. As a manufacturer, we can promise our quality and leading time. And we also can give you a competitive price with the quality in your market.
All kind of Our products always have stock, OEM&ODM welcome.
Samples time canbe in 15 days.
We will be happy to give you a quotation upon your requirement. Looking forward to hear from you soon .

ANDY LUO
QUANZHOU HANTUO SHOES CO.,LTD.
EMAIL:andy1@hentoll.com
PHONE/WHATSAPP:+8615106092217
Website: www.hentoll.com
by "sales14" <sales14@hentol1314.com> - 01:42 - 4 Apr 2025 -
Wealth requires health
The Shortlist
Emerging ideas for leaders Curated by Alex Panas, global leader of industries, & Axel Karlsson, global leader of functional practices and growth platforms
Welcome to the CEO Shortlist, a biweekly newsletter of our best ideas for the C-suite. This week, we examine what health means for CEOs and their employees. You can reach us with thoughts, ideas, and health tips at Alex_Panas@McKinsey.com and Axel_Karlsson@McKinsey.com. Thank you, as ever.
—Alex and Axel
Healthy leaders. Most CEOs got to where they are through a focused approach to hard work. But our latest research shows that personal health is more important than long hours. We asked more than 100 leaders of companies around the world about the daily routines that keep them effective in their roles. Six categories of mindsets and practices emerged. Staying healthy on these six dimensions is a prerequisite for high performance.
Healthy employees. Employee health means much more than physical safety in the workplace, says Lucy Pérez, McKinsey senior partner and global leader of the McKinsey Health Institute. Holistic health means mental, social, and emotional well-being. And, as with all kinds of health, prevention is key. Learn how to advocate for your employees—and yourself—in our latest article.
We hope you find these ideas novel and insightful. See you in a couple weeks with more McKinsey ideas for the CEO and others in the C-suite.Share these insights
This email contains information about McKinsey’s research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this email because you subscribed to The CEO Shortlist newsletter.
Copyright © 2025 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "McKinsey CEO Shortlist" <publishing@email.mckinsey.com> - 04:44 - 4 Apr 2025 -
PLASTIC INJECTION MOLDING: ROBUST PROCESS DEVELOPMENT & SCIENTIFIC MOLDING (23 & 24 April 2025)
CLICK HERE TO DOWNLOAD BROCHURE
Please call 012-588 2728
email to pearl-otc@outlook.com
HYBRID PUBLIC PROGRAM
PLASTIC INJECTION MOLDING:
ROBUST PROCESS DEVELOPMENT & SCIENTIFIC MOLDING
(** Choose either Zoom OR Physical Session)
Remote Online Training (Via Zoom) &
Wyndham Grand Bangsar Kuala Lumpur Hotel (Physical)
(SBL Khas / HRD Corp Claimable Course)
Date : 23 Apr 2025 (Wed) | 9am – 5pm By Selvaraj
24 Apr 2025 (Thu) | 9am – 5pm . .
INTRODUCTION:
Scientific Injection Molding is typically used in the production of complex parts and components where small variations in molding variables can severely impact the process or finished product. Therefore, the goal of Scientific Injection Molding is twofold:
1. Develop a process that produces repeatable results with minimal variation.
2. Optimize dimensional or mechanical characteristics of a molded part.
When developing a molding process using Scientific Injection Molding, key inputs such as time (fill, pack/hold, etc.), temperature (melt, barrel, etc.), and pressure (hydraulic, injection melt, cavity, etc.) are meticulously monitored, adjusted, and controlled, to ensure that process robustness is achieved, and a good part is consistently produced. A process can be robust or on the other hand must be changed frequently. A robust process ensures repeatability and a wide processing window for better quality & cost.
COURSE OBJECTIVES:
1. Material properties that affect processing
2. The importance of drying
3. Explains specific rules for controlling the plastic during processing
4. Injection molding machine selection
5. Provides thorough overview of injection molding and troubleshooting techniques.
6. Exercise greater control over the molding process
7. Reduce rejects and scrap
8. Improve part quality
9. Increase productivity
10. Robust parameter optimization
INTENDED AUDIENCE:
This workshop has been designed for all Managers, Section Heads, Engineers and Senior Technicians who are involved in the process of Plastic Injection Molding and want to make their workplace more productive & optimized. Following groups of people will benefit from this training:
1. Tool makers
2. Manufacturing engineers
3. Production engineers
4. Any technical personnel involved with plastic injection moulded parts
METHODOLOGY:
1. Participants will inform the organizer their top 6 issues to be discussed during the Troubleshooting section.
2. Interactive and action based with personal examples.
3. Participants are strongly encouraged to prepare their statistical software of choice for DOE simulation.
PREREQUISITE:
Participants are expected to have a basic understanding in Plastic Injection Moulding with a minimum of 2 years’ experience.
OUTLINE OF WORKSHOP
DAY 1 (9.00am—5.00pm)
1. Handling Semi Crystalline & Amorphous Polymers
i. Shrinkage
ii. Mel temperature
iii. Mold filling speed
iv. Mold temperatures
v. Barrel Heat Profile
vi. Screw recovery speeds
vii. Nozzle temperature
viii. Cooling times
ix. Mechanical properties
x. Optical clarity
2. Plastic drying
i. Degradation
ii. Drying time
iii. Drying temperature
iv. Types of dryers
v. Moisture measurement
vi. Overdrying effect
3. Injection moulding machine selection
i. Clamp force
ii. Machine platen size
iii. Shot size
iv. Screw diameter
v. Compression ratio
vi. Types of screws
vii. Check ring importance
DAY 2 (9.00am—5.00pm)
4. Process optimization
i. Optimization of injection phase
ii. Cavity balance
iii. Pressure drop
iv. Process window
v. Gate seal time
vi. Cooling time
vii. Screw speed & back pressure
5. Mold qualification flowchart
i. Mold qualification checklist
ii. Waterline diagrams
iii. Mold temperature maps
iv. Setup instructions
6. Mould cooling, venting & regrind management
i. Mould cooling
ii. Mould venting
iii. Regrind
7. DOE to develop robust injection molding parameters
8. Troubleshooting common issues at customer location
i. Short molding – consistent and inconsistent
ii. Flash
** Certificate of attendance will be awarded for those who completed the course
ABOUT THE FACILITATOR
Selvaraj is a highly qualified technical trainer in the areas of Continuous Improvement and Quality Excellence. He believes in interactive and fun filled training. His method of training is sharing rather than lecturing. With 23 years of experience in the field of Manufacturing Improvement & Quality Excellence covering areas of Design, Material Selection, Tooling, Machine & Process Engineering, Production and Supply Chain Management, Selvaraj B uses lots of real life examples. Selvaraj B started his career in 1989 as a Mechanical Engineer and in 23 years, has worked in 3 MNC companies that are World Class, i.e. Matsushita (Japanese), Robert Bosch (German) and Entegris (American) up to the level of an Operations Manager. Selvaraj B is a certified HRDF trainer. His strength is combining the intricacies and details of technical training with highly humorous anecdotes for maximum training effectiveness.
AMONG HIS NOTABLE ACHIEVEMENTS ARE:
1. Leading Gold Medal winning teams to NPC conventions – 1995 - 2002
2. Certified MTM and Ergonomics practitioner - 1997
3. Tooling & plastic parts design standardization - 2000
4. Awarded best Six Sigma Champion award in 2006 for promoting successful Sigma projects – 2006
5. Certified Trainer with Napoleon Hill International - 2007
6. Certified Lean Sigma Champion - 2010
7. Competent Communicator & Humorous Speech Division N Champion in Toastmasters International – 2012
8. Certified Six Sigma Master Black Belt - 2016
9. Member of the Society of Plastics Engineers
10. Member of the Institute of Engineers Malaysia
11. Certified NLP Practitioner - 2016
12. Certified VDI Quality Systems auditor - 1997
13. Certified Industry 4.0 Professional accredited by the US-based
International Institute of Executive Careers™ (IIEC)
AMONG HIS NOTABLE IMPROVEMENTS PROJECTS ARE:
1. Consolidating the Plastic Injection Moulding sections into 1 department & leading it – Bosch Bayan Lepas
2. Motivating and guiding numerous scrap reduction & quality improvement teams – Bosch Bayan Lepas, Automotive Lighting Bayan Lepas
3. Reduction of manufacturing lead time from 28 days to 3 days – Entegris
4. Cycle time reduction projects – Bosch, Entegris
5. Lean improvement projects – Signature Kitchen Sdn. Bhd. KL, Anshin Precision Sdn. Bhd. Shah Alam, Silverstone Berhad Taiping.
6. Starting a new factory of 200 headcount for Silicone Wafer Process Carrier comprising of Manufacturing, Maintenance, Engineering, Tooling, Production Planning & Continuous Improvement Department – Entegris Kulim Hi-Tech.
7. Guiding and inspiring numerous quality improvement and cost reduction teams to State level and National level competition and recognition.
8. Setting up & developing a World Class Manufacturing team for clean room fittings manufacturing – Entegris Kulim Hi-Tech
(HRD Corp/SBL Khas Claimable)
training Fee
14 hours Remote Online Training (Via Zoom)
RM 1,296.00/pax (excluded 8% SST)
2 days Face-to-Face Training (Physical Training at Hotel)
RM 2,250.00/pax (excluded 8% SST)
Group Registration: Register 3 participants from the same organization, the 4th participant is FREE.
(Buy 3 Get 1 Free) if Register before 11 April 2025. Please act fast to grab your favorite training program!We hope you find it informative and interesting and we look forward to seeing you soon.
Please act fast to grab your favorite training program! Please call 012-588 2728
or email to pearl-otc@outlook.com
Do forward this email to all your friends and colleagues who might be interested to attend these programs
If you would like to unsubscribe from our email list at any time, please simply reply to the e-mail and type Unsubscribe in the subject area.
We will remove your name from the list and you will not receive any additional e-mail
Thanks
Regards
Pearl
by "sump@otcmsb.com.my" <sump@otcmsb.com.my> - 02:21 - 4 Apr 2025 -
Economic mobility in rural America: A first look at new research
On McKinsey Perspectives
Characteristics of rural communities Brought to you by Alex Panas, global leader of industries, & Axel Karlsson, global leader of functional practices and growth platforms
Welcome to the latest edition of Only McKinsey Perspectives. We hope you find our insights useful. Let us know what you think at Alex_Panas@McKinsey.com and Axel_Karlsson@McKinsey.com.
—Alex and Axel
—Edited by Belinda Yu, editor, Atlanta
This email contains information about McKinsey's research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this email because you subscribed to the Only McKinsey Perspectives newsletter, formerly known as Only McKinsey.
Copyright © 2025 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "Only McKinsey Perspectives" <publishing@email.mckinsey.com> - 11:05 - 3 Apr 2025 -
Reliable Cable Ties and Seals for Your Projects
Dear info,
I am reaching out to introduce our company, a trusted supplier of consumer electronics. We specialize in Type-C, HDMI, and USB cables, providing top-tier connectivity solutions for various devices.
In addition to cables, we offer mobile phone cases, headphones, and DP and AV cables. Each product is crafted for superior quality, ensuring long-lasting use and user satisfaction.
We would love the opportunity to work with you and discuss how our products can fit your needs. Please feel free to reach out for further details.
Best regards,
Wenzhou Accory Security Seals CO., Ltd
Whatsapp: +8613588958250
by "Asab Xyd" <xydasab@gmail.com> - 05:02 - 3 Apr 2025 -
Wholesale eyewear catalog"save you 30%-50% procurement cost“


China MIDOEYEWAER Glasses Factory Direct Sales - Frames wholesale price is cheaper than purchasing in your country
"Save you 30%-50% of purchasing costs"
1. Support small batch orders mixed wholesale and sample delivery
2. 5-7 days international express UPS DHL to your country, relieve your inventory pressure
2025 new glasses frame wholesale catalog for quotation referenceEyeglass Frames Wholesale Catalog Starting from $5 





Sunglasses Wholesale Catalog from $5 






Why Choose Us?
1. Save 30-50% on Procurement Costs: As a direct factory seller, we eliminate the middleman, offering you highly competitive prices.
2. Support Small Batch Orders: Whether you are making a large-scale purchase or a small trial order, we can flexibly meet your needs.
3. Wholesale of Over 10,000 In-stock Models: We have a rich inventory covering a variety of styles and materials and can arrange for quick delivery.
3. Wholesale of Over 10,000 In-stock Models: We have a rich inventory covering a variety of styles and materials and can arrange for quick delivery.
4. Support Custom Brand LOGO: We provide OEM/ODM services and can customize brand logos and designs according to your requirements.
5. International Express Delivery within 7-10 Days: We cooperate with several international logistics companies to ensure that the goods are delivered to your country quickly and safely.


• One-stop Solution: From design, production to logistics, we provide full-process services, making your procurement more worry-free.
• Quick Response: Our professional team provides 24/7 service to ensure that your needs are addressed promptly.
Our Services and Advantages:
• Direct Factory Sales: Without middlemen, our prices are more competitive.
• Flexible Payment Methods: We support various payment methods such as T/T, letter of credit, and PayPal, which are convenient and fast.
• High Quality Assurance: All products are made of high-quality materials (such as titanium and acetate fiber) and comply with international quality standards (such as CE and FDA certifications).


Simple and Efficient Import Process:
1. Select Products: Choose from our more than 10,000 styles or provide us with your design requirements.
2. Confirm the Order: We provide a detailed quotation and sample confirmation.
3. Production and Quality Inspection: Efficient production and strict quality inspection to ensure product quality.
4. Logistics and Delivery: Through international express delivery or sea freight.
CUSTOM LOGO


4043 Jinhao Business Building, No. 146 tang'an Road, Tianhe District, Guangzhou, China
- Whats App: +8619570007585
- Write us:huangmichelle7333@gmail.com
QUOTE 






CONTACT
US

by "Eugene Pauline" <paulineeugene97@gmail.com> - 01:23 - 3 Apr 2025 -
Your “pre-built” path to income and lifestyle
It’s already been bolted and screwed together by professionals.
When you get your driver’s license, you go buy a car, right?
…One you like, and can afford.
Is it the best, fastest, most high-end, luxurious car you can get? Probably not.
But it gets you to where you need to go. Consistently and reliably.
And the best part is, it’s already bolted together by professionals.
No need to build it yourself!
So here’s a question…
Why not do the same thing when you’re starting your online business?
I explain everything in my FREE “52 Funnels” masterclass… AND I give you the funnels!
Why make it harder on yourself by building everything from scratch?
Like I said – these funnels are truly DONE for you.
The sales page, upsell flow, email follow ups, everything…
Heck, even the products are done for you!
All you need to do is change out your payment link, and you can launch the funnel.
Plus, you can keep ALL the profit – you don’t owe us a dime. 🙂
So don’t make all of this harder on yourself.
Save your spot for our FREE “52 Funnels” Masterclass…
Where we’ll show you exactly how to take these pre-built funnels, launch them in less than 15 minutes each…
And start bringing in sales within MINUTES!
Go save your spot here, right now:
Russell Brunson
P.S. - Don’t forget, you’re just one funnel away….
© Etison LLC
By reading this, you agree to all of the following: You understand this to be an expression of opinions and not professional advice. You are solely responsible for the use of any content and hold Etison LLC and all members and affiliates harmless in any event or claim.
If you purchase anything through a link in this email, you should assume that we have an affiliate relationship with the company providing the product or service that you purchase, and that we will be paid in some way. We recommend that you do your own independent research before purchasing anything.
Copyright © 2018+ Etison LLC. All Rights Reserved.
To make sure you keep getting these emails, please add us to your address book or whitelist us. If you don't want to receive any other emails, click on the unsubscribe link below.
Etison LLC
3443 W Bavaria St
Eagle, ID 83616
United States
by "Russell | ClickFunnels" <noreply@clickfunnelsnotifications.com> - 01:13 - 3 Apr 2025 -
The Art of REST API Design: Idempotency, Pagination, and Security
The Art of REST API Design: Idempotency, Pagination, and Security
APIs are the front doors to most systems.͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ Forwarded this email? Subscribe here for moreLatest articles
If you’re not a subscriber, here’s what you missed this month.
Monolith vs Microservices vs Modular Monoliths: What's the Right Choice
Dark Side of Distributed Systems: Latency and Partition Tolerance
To receive all the full articles and support ByteByteGo, consider subscribing:
APIs are the front doors to most systems.
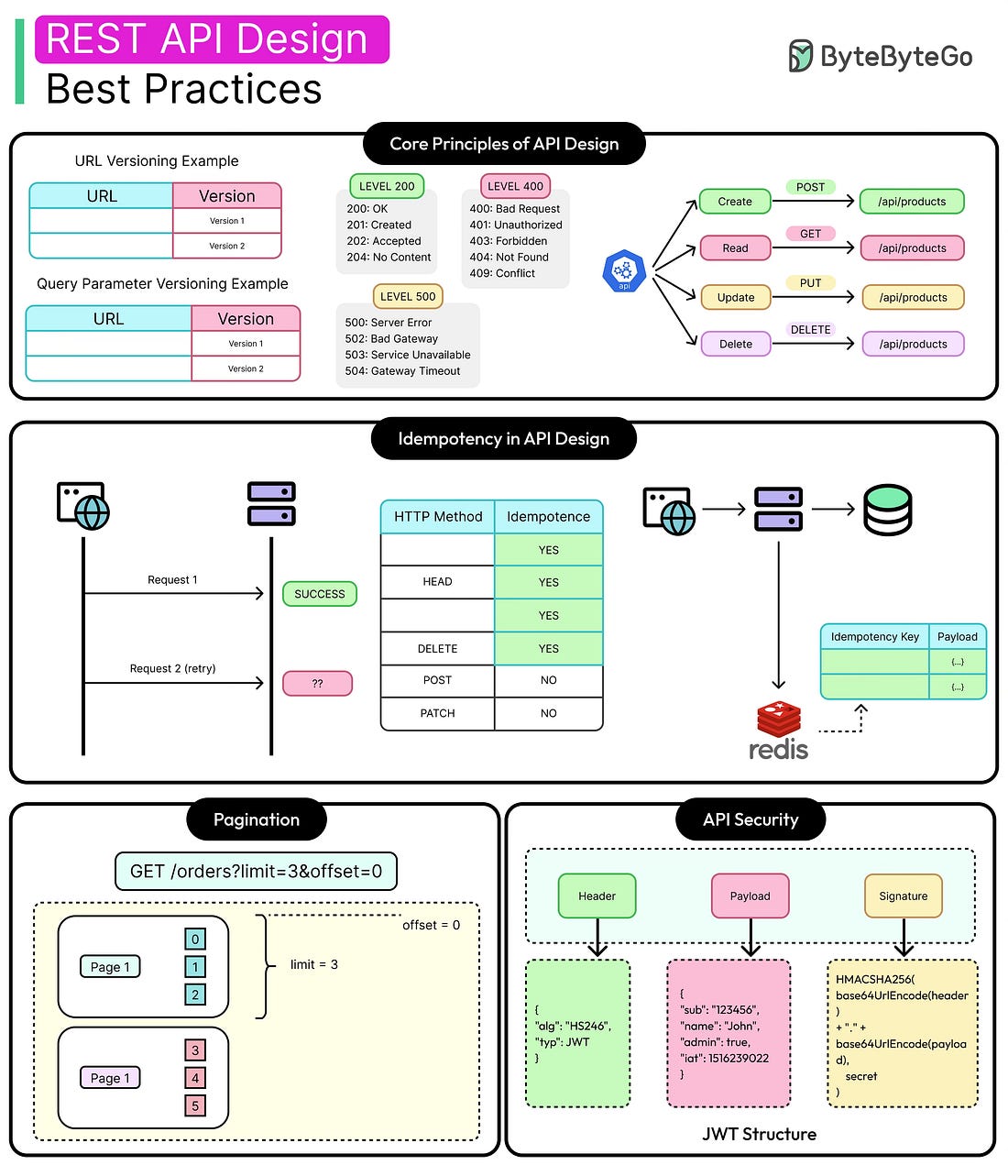
They expose functionality, enable integrations, and define how teams, services, and users interact. But while it’s easy to get an API working, it’s much harder to design one that survives change, handles failure gracefully, and remains a joy to work with six months later.
Poorly designed APIs don’t just annoy consumers. They slow teams down, leak data, cause outages, and break integrations. One inconsistent response structure can turn into dozens of custom client parsers. One missing idempotency check can result in duplicate charges. One weak authorization path can cause a security breach.
Well-designed APIs, on the other hand, create leverage and help the team do more. Some defining features are as follows:
They act as contracts, not just access points.
They scale with usage.
They reduce surprises for the developers and other stakeholders.
And they are reliable, internally and externally.
Most of the pain in API systems doesn’t come from the initial development. It comes from evolving them: adding new fields without breaking old clients, handling retries without state duplication, and syncing data between systems without losing events.
A good API design is defensive and anticipates growth, chances of misuse, and failures. It understands that integration points are long-lived and every decision has an impact down the line.
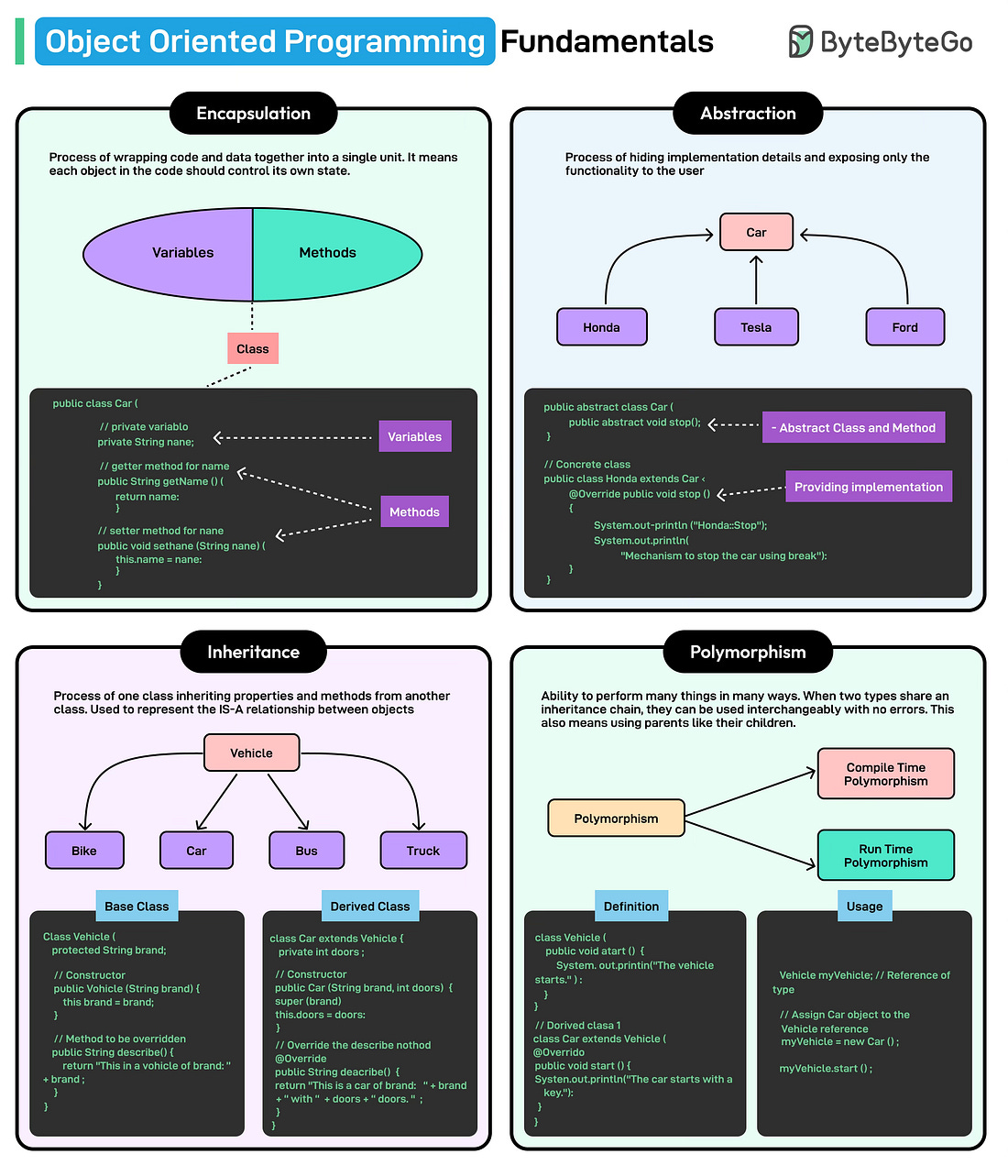
In this article, we explore the core principles and techniques of good API Design that make APIs dependable, usable, and secure. While our focus will primarily be on REST APIs, we will also explore some concepts related to gRPC APIs to have a slightly more holistic view.
Principles of Good API Design...

Continue reading this post for free in the Substack app
Like
Comment
Restack
© 2025 ByteByteGo
548 Market Street PMB 72296, San Francisco, CA 94104
Unsubscribe

by "ByteByteGo" <bytebytego@substack.com> - 11:35 - 3 Apr 2025 -
▶ Register now for SAP Sapphire Virtual!
Catch the "best-of" SAP Sapphire at our online event May 20–21.

Get the “best‑of” SAP Sapphire!
Register now for our free online event.Experience the best in technology, innovation, and new ideas.
Join us for SAP Sapphire Virtual to learn about our latest breakthroughs in applications, data, AI, and more.
What you can expect:
•
Livestreamed keynotes and exclusive interviews
•
Breaking news and announcements
•
Top-rated demos, road maps, and strategy talks
•
Live chats, Q&As, polls
•
And so much more!
Are you ready to
bring out the best in your business?
Looking for more information
about our SAP Sapphire event program?



SAP (Legal Disclosure | SAP)
This e-mail may contain trade secrets or privileged, undisclosed, or otherwise confidential information. If you have received this e-mail in error, you are hereby notified that any review, copying, or distribution of it is strictly prohibited. Please inform us immediately and destroy the original transmittal. Thank you for your cooperation.You are receiving this e-mail for one or more of the following reasons: you are an SAP customer, you were an SAP customer, SAP was asked to contact you by one of your colleagues, you expressed interest in one or more of our products or services, or you participated in or expressed interest to participate in a webinar, seminar, or event. SAP Privacy Statement
This e-mail was sent to you on behalf of the SAP Group with which you have a business relationship. If you would like to have more information about your Data Controller(s) please click here to contact webmaster@sap.com.
This promotional e-mail was sent to you by SAP Global Marketing and provides information on SAP's products and services that may be of interest to you. If you would prefer not to receive such e-mails from SAP in the future, please click on the Unsubscribe link.
To ensure you continue to receive SAP related information properly please add sap@mailsap.com to your address book or safe senders list.

by "SAP Sapphire" <sap@mailsap.com> - 06:41 - 3 Apr 2025 -
Protect Your Wealth, Save on Tax, and Tee Off in Style
Here’s what you can expect when you work with... 

Hello Sir/Madam,
Wherever you are in your financial journey, it’s important to:
- Safeguard Your Assets: Ensure your savings and investments are well protected.
- Plan for the Future: Organise your estate planning and inheritance strategies.
- Optimise Tax Efficiencies: Make the most of available reliefs and allowances.
Our recommended IFAs excel in these areas. Plus, when you work with us, you’ll enjoy:
- 4 VIP golf invitations every year.
- Monthly four-ball rounds at over 600 UK golf clubs.
- Priceless networking with fellow professionals on the fairway.
Click here or simply reply to this email to arrange your free consultation. Let’s protect your wealth and help you make the most of every tee time.
Best regards,
Richard Ellis
Project Director
+44(0)7380 337 315
+44(0)1924 975 502



by "Richard - Fairway Wealth Partners" <info@fairwaywealthpartners.com> - 03:49 - 3 Apr 2025 -
📣 Just released: Preview DASH 2025 Workshops
New sessions added everyday–time to explore Hi Abul,
Hi Abul,
Great news! The DASH workshops are now live in the session catalog. Join us for hands-on, immersive sessions on APM, OpenTelemetry, security, and more. Register by April 30 to be among the first to start building your conference agenda. Plus, gain access to additional workshops on June 9 during the pre-conference day (included with your ticket).Our DASH workshops feature purpose-built applications running on real cloud instances. You'll receive guided, step-by-step instructions to help you observe, secure, and optimize your applications and infrastructure using Datadog. Or, explore freely in our open environment at your own pace and collaborate with fellow attendees.
Stay tuned! Talks and product deep dives will be available soon in the catalog. Browse this year’s sessions to see what’s coming, with new content added every week:- Inspiring talks from your peers at companies like Riot Games, Coinbase, Redfin, Toyota, and more, showcasing how top teams tackle observability, performance, and security challenges.
- Datadog product deep dives that expand your knowledge of the latest tools for building and scaling the next generation of applications, infrastructure, and security. Move beyond theory by learning alongside Datadog experts who built and use the tools you rely on.
- Certifications validating your deep understanding of installing, configuring, and using the Datadog platform.
BE AN EARLY BIRD! SAVE $400Register today to secure your ticket at the best deal.REGISTER NOW See you in NYC!
Cheers,
The DASH Team


 Visit our email preference center to unsubscribe or update subscription options© 2025 Datadog Inc, 620 8th Ave, 45th Floor, New York, NY 10018
Visit our email preference center to unsubscribe or update subscription options© 2025 Datadog Inc, 620 8th Ave, 45th Floor, New York, NY 10018This email was sent to info@learn.odoo.com.
by "DASH by Datadog" <dash@datadoghq.com> - 03:00 - 3 Apr 2025 -
How did Rolls-Royce’s CEO lead an astonishing transformation?
On McKinsey Perspectives
The art of transformation Brought to you by Alex Panas, global leader of industries, & Axel Karlsson, global leader of functional practices and growth platforms
Welcome to the latest edition of Only McKinsey Perspectives. We hope you find our insights useful. Let us know what you think at Alex_Panas@McKinsey.com and Axel_Karlsson@McKinsey.com.
—Alex and Axel
•
Powerfully ambitious. “There’s a big difference between restructuring and transformation,” the Rolls-Royce CEO said to McKinsey Senior Partner Michael Birshan. Transformation takes more ambition, Erginbilgiç added, as “taking the company from point A to point B . . . opens more potential.” Rolls-Royce’s transformation began with creating a top-notch leadership team to communicate both the vision for the company and its path forward. “You have to talk about where you’re going to take the business and why you think it’s possible,” he explained.
•
Crafting effective strategies. Successfully transforming a company requires mobilizing people with “purpose, focus, and alignment,” Erginbilgiç noted. An essential step is translating performance goals into clear strategic initiatives so that the strategy’s goals are relevant to employees and “aren’t just a bunch of numbers.” For the CEO, strategy development comes from “free-flowing, blue-sky conversation” that can be chaotic at times but must eventually take implementation into account. Learn more of the leadership practices that Erginbilgiç follows as he reinvigorates an iconic brand.
—Edited by Belinda Yu, editor, Atlanta
This email contains information about McKinsey's research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this email because you subscribed to the Only McKinsey Perspectives newsletter, formerly known as Only McKinsey.
Copyright © 2025 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "Only McKinsey Perspectives" <publishing@email.mckinsey.com> - 01:49 - 3 Apr 2025 -
Explore Our High-Quality Polyester Staple Fiber Products
Dear info,
Hi.
This is Kelly from Shaoxing Meilun Chemical Fibre Co.,ltd. Since 1993 we started production of polyester staple fiber. We have large range of products for your choice. Our fiber is from 3D, 7D, 15D, micro fiber, both silicon and non silicon. The cut length can be 25mm, 32mm, 51mm and 64mm. Most of them can be used in stuffing toys, pillow, cushions, mattress, clothing and non woven fabrics. 15Dx64mm HCS is our hot product for its high elasticity.
We are certified by GRS and OEKO TEX 100 and TC certificate can be issued according to customers’ requirements.
We take flexible marketing way. For direct plant, we can send you samples for your making sample.
You can search our web and know further information.
Looking forward to receiving your reply.
Best wishes
Kelly
by "Racheal Ottesen" <rachealottesen@gmail.com> - 09:42 - 2 Apr 2025 -
Power Up Your Brand’s Visuals with YOUXI LED Projectors
Dear info,
In a world where visual impact matters, YOUXI LED projectors are the perfect solution to amplify your brand’s presence in both retail spaces and home environments. Trusted by major brands in the retail and consumer electronics sectors, our projectors provide unmatched quality and reliability.
Our products help you:
· Stand Out in Retail Spaces: Create stunning displays that attract and engage customers.
· Enhance Consumer Electronics: Offer your customers high-quality home entertainment experiences with our top-tier projectors.
· Boost Brand Value: Deliver exceptional visuals, backed by internationally recognized certifications.
I’d love the opportunity to show you how YOUXI projectors can support your brand’s goals. Let’s schedule a quick call to discuss how we can collaborate.
Best regards,
Vrea YOUXI
YOUXI (shenzhen)Technology Co., Ltd.Website:https://www.uxprojection.com
by "Sol Fleurissaint" <solfleurissaint@gmail.com> - 05:50 - 2 Apr 2025 -
We built 52 funnels for you (products INCLUDED!)
Doesn’t matter if you have your own product or not. You can use these 52 funnels right away!
Did you sign up for the FREE Masterclass yet? Remember… When you attend you’ll get 52 ready-to-launch funnels my friends, Paul Counts, Shreya Banerjee, and I built for you!
Don’t worry if you’re lost on where to start…
Aren’t good at “marketing” or “copywriting”...
And don’t have the first clue as to what product you could create…
We’ve taken care of ALL of that for you. ;)
Just change out the payment link in these pre-built funnels, and click to go LIVE!
And it’s not just the sales page and the product that’s done for you.
It’s the upsell flow… email follow ups… ads… everything.
You get it all!
HOWEVER…
In order to claim your ready-to-launch funnels…
You MUST attend the webinar demo!
That’s the only place to secure your funnels, and launch your online business in minutes. No other page on the internet has this deal.
So go save your spot, and get HYPED!
Thanks,
Russell Brunson
P.S. - Don’t forget, you’re just one funnel away….
© Etison LLC
By reading this, you agree to all of the following: You understand this to be an expression of opinions and not professional advice. You are solely responsible for the use of any content and hold Etison LLC and all members and affiliates harmless in any event or claim.
If you purchase anything through a link in this email, you should assume that we have an affiliate relationship with the company providing the product or service that you purchase, and that we will be paid in some way. We recommend that you do your own independent research before purchasing anything.
Copyright © 2018+ Etison LLC. All Rights Reserved.
To make sure you keep getting these emails, please add us to your address book or whitelist us. If you don't want to receive any other emails, click on the unsubscribe link below.
Etison LLC
3443 W Bavaria St
Eagle, ID 83616
United States
by "Russell | ClickFunnels" <noreply@clickfunnelsnotifications.com> - 02:29 - 2 Apr 2025 -
Live demo 20+ new product releases
New Relic
20+ innovations unveiled at New Relic Now
 March 2025
March 2025
20+ new product releases. Live demo each one First up is Intelligent Observability for Digital Experience. Hear from New Relic product experts behind Engagement Intelligence and Streaming Video & Ads Intelligence.Watch on-demand 

Observability Certification Program Gain the core skills you need to boost your career. Earn your New Relic credentials designed for the observability industry.
Get started 
Vulnerability Management is now Security RX—new name, more features. New Relic's Vulnerability Management is now Security Remediation Explorer—Security RX. Security RX prioritises vulnerabilities in your infrastructure hosts as well as application libraries so you know which risks need to be fixed first and what can wait.
Learn more 
New Relic Now Live: Berlin
Join us in person tomorrow to learn how top companies use Intelligent Observability to drive better business outcomes, improve digital customer experiences, optimise cloud costs and boost productivity—and then get hands-on in a GameDay workshop.
This is a free event, so sign up today to save your space. We’ll wrap up the day with food, drinks, and fun. Save your spot.
New Relic Now+ On-demand
Catch up on-demand for the launch of Intelligent Observability and 20+ AI-driven innovations that redefine how IT and engineering teams power digital business. Watch here.
New Relic University online workshops
Catch our recent New Relic workshops on-demand. These trainer-led workshops with hands-on labs will help you up-level your observability skills. Watch now.

New Relic Now+ 2025: Guide to New Relic’s innovation announcements.
Explore the 20+ exciting innovations unveiled at New Relic Now+ 2025. From AI-powered tools that redefine efficiency to advanced transaction monitoring and deeper database performance insights, discover how these updates elevate engineering excellence and business uptime. Read the blog
2024 State of Observability for Media and Entertainment
Read the State of Observability for Media and Entertainment report to uncover insights and strategies that enhance viewer satisfaction and reliability, ensuring your streaming platform meets the demands of today's digital landscape. Read the report

Capture and analyse changes in your systems with change tracking.
Change tracking allows you to capture changes on any part of your system and contextualise performance data. Our change analysis UIs provide details and insights about each of the changes you track, such as faceted errors, log attribute trends, and more. Start tracking your changes today.
Not an existing New Relic user? Sign up for a free account to get started!


Need help? Let's get in touch.



This email is sent from an account used for sending messages only. Please do not reply to this email to contact us—we will not get your response.
This email was sent to info@learn.odoo.com Update your email preferences.
For information about our privacy practices, see our Privacy Policy.
Need to contact New Relic? You can chat or call us at +44 20 3859 9190.
Strand Bridge House, 138-142 Strand, London WC2R 1HH
© 2025 New Relic, Inc. All rights reserved. New Relic logo are trademarks of New Relic, Inc
by "New Relic" <emeamarketing@newrelic.com> - 06:31 - 2 Apr 2025 -
AI agents: What can they do for you?
On McKinsey Perspectives
Call my agent Brought to you by Alex Panas, global leader of industries, & Axel Karlsson, global leader of functional practices and growth platforms
Welcome to the latest edition of Only McKinsey Perspectives. We hope you find our insights useful. Let us know what you think at Alex_Panas@McKinsey.com and Axel_Karlsson@McKinsey.com.
—Alex and Axel
•
More-capable agents. If you’ve ever chatted with a customer service bot, you’ve probably experienced a basic version of an AI agent: a software component that can perform tasks on behalf of users and systems. Recent gen AI models have enabled a range of new possibilities that allow agent systems to plan, collaborate, complete tasks, and even learn to improve their own performance. As McKinsey Senior Partner Lari Hämäläinen explains, “Today, the joint human-plus-machine outcome can generate great quality and great productivity.”
•
Hurdles to adoption. Building trust is a big hurdle in adopting AI agent technology. McKinsey finds that customers of all ages—even Gen Zers—still prefer to talk to someone live on the phone for customer help and support, reveals Partner Nicolai von Bismarck. As organizations scale AI agents, says Senior Partner Jorge Amar, there are additional challenges, including change management and data protection. Explore one of our latest McKinsey Explainers, “What is an AI agent?” to understand how enterprises can make the most of this technology.
—Edited by Belinda Yu, editor, Atlanta
This email contains information about McKinsey's research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this email because you subscribed to the Only McKinsey Perspectives newsletter, formerly known as Only McKinsey.
Copyright © 2025 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "Only McKinsey Perspectives" <publishing@email.mckinsey.com> - 01:06 - 2 Apr 2025











