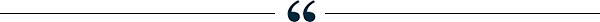Archives
- By thread 5365
-
By date
- June 2021 10
- July 2021 6
- August 2021 20
- September 2021 21
- October 2021 48
- November 2021 40
- December 2021 23
- January 2022 46
- February 2022 80
- March 2022 109
- April 2022 100
- May 2022 97
- June 2022 105
- July 2022 82
- August 2022 95
- September 2022 103
- October 2022 117
- November 2022 115
- December 2022 102
- January 2023 88
- February 2023 90
- March 2023 116
- April 2023 97
- May 2023 159
- June 2023 145
- July 2023 120
- August 2023 90
- September 2023 102
- October 2023 106
- November 2023 100
- December 2023 74
- January 2024 75
- February 2024 75
- March 2024 78
- April 2024 74
- May 2024 108
- June 2024 98
- July 2024 116
- August 2024 134
- September 2024 130
- October 2024 141
- November 2024 171
- December 2024 115
- January 2025 216
- February 2025 140
- March 2025 220
- April 2025 233
- May 2025 239
- June 2025 303
- July 2025 178
-
Demographic shifts in the workforce: A leader’s guide
Leading Off
Adapt and adjust
by "McKinsey Leading Off" <publishing@email.mckinsey.com> - 04:14 - 3 Feb 2025 -
The value of investing in employee health
On McKinsey Perspectives
New research Brought to you by Alex Panas, global leader of industries, & Axel Karlsson, global leader of functional practices and growth platforms
Welcome to the latest edition of Only McKinsey Perspectives. We hope you find our insights useful. Let us know what you think at Alex_Panas@McKinsey.com and Axel_Karlsson@McKinsey.com.
—Alex and Axel
•
Less than healthy. A workforce that’s healthy, resilient, and adaptable is better able to navigate the uncertainties and challenges of a rapidly changing world. Yet in a McKinsey Health Institute (MHI) survey of more than 30,000 global employees, only 57% reported good holistic health (that is, being physically, socially, spiritually, and mentally well). McKinsey Senior Partners Brooke Weddle and Shail Thaker and coauthors explain that with the wide variation in health outcomes across levels of education, income, and other demographic variables, improving workforce health often requires both systemic and tailored interventions.
—Edited by Belinda Yu, editor, Atlanta
This email contains information about McKinsey's research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this email because you subscribed to the Only McKinsey Perspectives newsletter, formerly known as Only McKinsey.
Copyright © 2025 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "Only McKinsey Perspectives" <publishing@email.mckinsey.com> - 01:35 - 3 Feb 2025 -
4 hours left!! (Selling out now or pay DOUBLE)
Warning, there are only 38 tickets remaining…I can’t believe it – it’s finally here…
This is officially THE FINAL email pushing you to grab one of the FINAL tickets to the FINAL Funnel Hacking LIVE!!!
So many finales it’s like the end of The Lord of The Rings!!
(I’m gonna take a moment to shed a tear ;)
Now, it wouldn’t be an official FINAL email if I didn’t tell you the bad news…
We only have 37 in-person tickets available.
We have sold out every year…
…and this was the fastest and craziest “sell out” I’ve seen (and it makes sense, seeing this is the LAST FHL).
If you’re planning on coming to Funnel Hacking LIVE… and for some reason haven’t gotten your tickets yet, then I’d recommend grabbing yours right now (literally, RIGHT NOW)…
>> Get Your FHL LAST DANCE Ticket Now <<
In 4 hours (if we don’t sell out before then) the price will be 2X what they are now…
And FHL is just days away…
So chances are, these last 37 tickets will be snapped up in no time.
So, what are you waiting for? LET'S GOOOOO!!!

I can’t emphasize enough…
This is it.
People will be talking about this event for YEARS AND YEARS to come.
People will be walking away from Vegas with a COMPLETELY new perspective on life, business, relationships…
FHL 10 – The Last Dance – could be the beginning of your NEW trajectory in life.
It’s up to you.
While I would want to savor this moment, seeing as this is the last email about the last FHL…
I have to go prepare the final touches on my presentations I know will be the next game-changer in the marketing world.
So with that said… if you want to have a thriving 2025, unleash your full potential, and have the business you’ve always wanted…
…then I’ll see you in Vegas.
Don’t forget: you have until midnight tonight before the price doubles.
See you next week!
Russell Brunson
P.S. - Don’t forget, you’re just one funnel away…
P.P.S. FHL ticket PRICE DOUBLES in 4 hours – get your ticket NOW before we sell out (or you pay double) →
© Etison LLC
By reading this, you agree to all of the following: You understand this to be an expression of opinions and not professional advice. You are solely responsible for the use of any content and hold Etison LLC and all members and affiliates harmless in any event or claim.
If you purchase anything through a link in this email, you should assume that we have an affiliate relationship with the company providing the product or service that you purchase, and that we will be paid in some way. We recommend that you do your own independent research before purchasing anything.
Copyright © 2018+ Etison LLC. All Rights Reserved.
To make sure you keep getting these emails, please add us to your address book or whitelist us. If you don't want to receive any other emails, click on the unsubscribe link below.
Etison LLC
3443 W Bavaria St
Eagle, ID 83616
United States
by "Russell Brunson" <noreply@clickfunnelsnotifications.com> - 12:35 - 3 Feb 2025 -
EDB_Quote-project Iapple international
Dear Sir Md Abul Khayer
From Varoon (Ingram Thailand)
Here is the quotation for project Iapple international in THB
Date:
3-Feb-25
Customer Name:
Iapple international
Rev:
Valid until:
4-Apr-25
Item
Part Number
Description
Service Terms
QTY
Unit Price
Total Price
(Months)
(THB)
(THB)
1
OP-STPD-UC-001
On Prem - Standard Plan with Production Support (uniCore)
12
8
68,000
544,000
Total
544,000
Note:
Price to Partner, Excluded VAT, Excluded Services and Training
Best Regards
Varoon Nomjitjiam (YiM)
Product Manager – Red Hat | EDB
M.+668-1245-1487
Varoon.nomjitjiam@ingrammicro.com
Ingram Micro (Thailand) Ltd.
If you do not wish to receive promotional materials from Ingram Micro via e-mail, please go to Our unsubscribe link and select your Country and Language Preference to unsubscribe.
Ingram Micro Inc.
Corporate Headquarters, 3351 Michelson Drive, Suite 100, Irvine, CA 92612
This email may contain material that is confidential, and proprietary to Ingram Micro, for the sole use of the intended recipient. Any review, reliance or distribution by others or forwarding without express permission is strictly prohibited. If you are not the intended recipient, please contact the sender and delete all copies.
[Ingram_2818e5de]
by "Nomjitjiam, Varoon" <Varoon.Nomjitjiam@ingrammicro.com> - 11:31 - 2 Feb 2025 -
Iapple international | EDB | Discovery call
Iapple international | EDB | Discovery callHi Everyone,
I hope you all are doing well. This is just a gentle reminder for today's call. Please use the following link to join the discussion:
https://enterprisedb.zoom.us/j/5416180431
Looking forward to our discussion
Best,
Ganesh KaleIapple international | EDB | Discovery callMonday Feb 3, 2025 ⋅ 9:30am – 10:15am (India Standard Time - Kolkata)Dear Sir Md Abul Khayer,
Thank you for your time on the call earlier. I have scheduled this call for 3rd Feb at 11.00 AM Thailand time. Please confirm your acceptance and feel free to share this invite with the team members you’d like to include in the discussion.
To recap our previous discussion:- You are looking to set up replication between two databases.
- You are interested in understanding the High Availability (HA) options available in EDB PostgreSQL.
This upcoming call is scheduled to address your questions in detail and to provide you with pricing information.
Join Zoom Meeting:https://enterprisedb.zoom.us/j/5416180431
Meeting ID: 541 618 0431
Find your local number: https://enterprisedb.zoom.us/u/abxJm2UFM4I look forward to our discussion.
Best regards,
https://enterprisedb.zoom.us/j/5416180431Location
View map
by "Ganesh Kale" <ganesh.kale@enterprisedb.com> - 10:41 - 2 Feb 2025 -
Iapple international | EDB | Discovery call
Iapple international | EDB | Discovery callHi Everyone,
I hope you all are doing well. This is just a gentle reminder for today's call. Please use the following link to join the discussion:
https://enterprisedb.zoom.us/j/5416180431
Looking forward to our discussion
Best,
Ganesh KaleIapple international | EDB | Discovery callMonday Feb 3, 2025 ⋅ 9:30am – 10:15am (India Standard Time - Kolkata)Dear Sir Md Abul Khayer,
Thank you for your time on the call earlier. I have scheduled this call for 3rd Feb at 11.00 AM Thailand time. Please confirm your acceptance and feel free to share this invite with the team members you’d like to include in the discussion.
To recap our previous discussion:- You are looking to set up replication between two databases.
- You are interested in understanding the High Availability (HA) options available in EDB PostgreSQL.
This upcoming call is scheduled to address your questions in detail and to provide you with pricing information.
Join Zoom Meeting:https://enterprisedb.zoom.us/j/5416180431
Meeting ID: 541 618 0431
Find your local number: https://enterprisedb.zoom.us/u/abxJm2UFM4I look forward to our discussion.
Best regards,
https://enterprisedb.zoom.us/j/5416180431Location
View map
by "Ganesh Kale" <ganesh.kale@enterprisedb.com> - 10:40 - 2 Feb 2025 -
Only 74 FHL tickets left…
Might not have to double the price after all…There’s 8 hours left to get your FHL 10 THE LAST DANCE ticket before the price DOUBLES (or we sell out… whichever happens first.)
As of right now, there’s 74 in-person tickets left.
There was a massive spike in ticket sales… and it makes sense.
See, once I spilled the news about Tony Robbins…
…about how we sent a survey to all attendees of FHL 10, and how Tony is going to read each response and then tailor his message specifically for our Funnel Hackers…
…people jumped at this very real, once in a lifetime opportunity!!!
I mean…
…to have the greatest business and life coach in the world deliver a message that could become THE single ‘a-ha’ breakthrough you’ve been looking for…
You can’t even put a price on that…
Anyway, all that to say – I probably won’t be doubling the price because we now are DANGEROUSLY HIGH from selling out!!!
So this very well could be YOUR LAST CHANCE on securing a ticket for FHL (which is happening next week)!!

I want you to come join me at FHL in Vegas next week.
I want you to get out of your everyday environment, and immerse yourself in this exciting, high-energy community for 4 full days...
I want you to meet and connect with the other thousands of Funnel Hackers who will be attending with you…
I want you to sit in the same room with all the Two Comma award winners who are on this journey with you…
So you can see first-hand it’s possible for YOU too!
All of this is waiting for you at Funnel Hacking LIVE 10 – THE LAST DANCE!
But it looks like tickets will sell out within hours.
So, are you IN?
Grab your ticket now (only 74 left) →
Talk soon,
Russell Brunson
P.S. Don’t forget, you’re just one funnel away…
P.P.S. This is important because rooms are getting booked up everywhere… Once you purchase your ticket, you’ll want to go here and secure your room with our room block (aka where all of the funnel hackers will be hanging out and masterminding) →© Etison LLC
By reading this, you agree to all of the following: You understand this to be an expression of opinions and not professional advice. You are solely responsible for the use of any content and hold Etison LLC and all members and affiliates harmless in any event or claim.
If you purchase anything through a link in this email, you should assume that we have an affiliate relationship with the company providing the product or service that you purchase, and that we will be paid in some way. We recommend that you do your own independent research before purchasing anything.
Copyright © 2018+ Etison LLC. All Rights Reserved.
To make sure you keep getting these emails, please add us to your address book or whitelist us. If you don't want to receive any other emails, click on the unsubscribe link below.
Etison LLC
3443 W Bavaria St
Eagle, ID 83616
United States
by "Russell Brunson" <noreply@clickfunnelsnotifications.com> - 08:30 - 2 Feb 2025 -
Invitation: Muhammad Abul Khayer and Chandu @ Sat 8 Feb 2025 6:30pm - 6:45pm (IST) (info@learn.odoo.com)
Muhammad Abul Khayer and ChanduEvent Name: Connect with Freebird Founder Book a meeting for customer support, share feedback, discuss ideas. Location: WhatsApp Audio Call WhatsApp Number: +66 93 009 0021 Agenda of the meeting:Event Name: Connect with Freebird FounderBook a meeting for customer support, share feedback, discuss ideas.
Location: WhatsApp Audio Call
WhatsApp Number: +66 93 009 0021
Agenda of the meeting: Demo
Need to make changes to this event?
Cancel: https://calendly.com/cancellations/b41b72ac-6226-4f3a-8d58-7b3619108adb
Reschedule: https://calendly.com/reschedulings/b41b72ac-6226-4f3a-8d58-7b3619108adbPowered by Calendly.com
Saturday 8 Feb 2025 ⋅ 6:30pm – 6:45pm (India Standard Time - Kolkata)When
WhatsApp Audio CallLocation
View mapReply for info@learn.odoo.comInvitation from Google Calendar
You are receiving this email because you are an attendee of the event.
Forwarding this invitation could allow any recipient to send a response to the organiser, be added to the guest list, invite others regardless of their own invitation status or modify your RSVP. Learn more
by "Chandrahasan Vantaku" <chandu@usefreebird.com> - 04:31 - 2 Feb 2025 -
You heard what Tony Robbins did…?!
I can’t believe it… (this goes away at midnight tonight)Super important, so please read the whole thing…
So by now you may have heard –
Tony Robbins’ team reached out and asked if they could send a survey to all FHL attendees – that way Tony can tailor his message SPECIFICALLY for Funnel Hackers!!
Tony is so pumped about speaking at the LAST Funnel Hacking LIVE, he’s going to personally read every response.
Just imagine what it will feel like to have Tony Robbins deliver the EXACT message you’ve been needing to hear… and it’s the single “a-ha” moment that becomes the catalyst to the un-ending success thereafter…
Imagine…
Tony unearthing years and years of hurtful, judgmental talk you and I have done to ourselves… with a presentation that shakes you to your core and helps you unleash your full potential, becoming the greatest version of yourself, which spreads across all areas of your life.
Listen, I’ve said it before and I’ll say it again: LIVES WILL CHANGE.
And if you want to set yourself up for MASSIVE success, and create the change you want so you can have a THRIVING business in 2025…
…then you’ll want to hurry and grab one of the LAST remaining FHL tickets here →
That’s the next part I need to talk to you about…
I just got today’s update…
We have 136 FHL tickets left. 🤯
Which means at this rate, I’m guessing we’ll hit MAX occupancy before I have to double ticket prices tonight at midnight!
If you haven’t grabbed your ticket yet, make sure you…
Secure your ticket now (before the price doubles tonight!) →
I don’t want you left behind… or having to pay DOUBLE the cost.
Look…
We’ve already poured over $5+ MILLION into this year’s Funnel Hacking LIVE event (and the number continues to climb...) with all of the events, amazing food, world-class speakers we’re bringing to the stage, etc.
Which might seem totally insane...
I’ve had people ask me “WHY?”...
“Why would you dump that much cash on ONE event?”
Because... I believe in YOU!
Because… I believe in bringing you world-class speakers to reveal to you what’s currently working in the marketplace.
Because… I want you to see & feel for yourself what happens when you put thousands of #funnelhackers in a room together, connecting, learning from each other, and scheming together for 4 straight days.
Because… I want you (and your business) to come away forever changed.
Because… I want you to see what’s possible as you watch hundreds of other #funnelhackers walk across the stage to accept their ‘Two Comma Club’ award...
...and truly realize that YOU can do it, too.
I believe in you that much.
So join me in Vegas next week — I can’t wait for you to see all the cool stuff I have planned for you!
Reserve Your Funnel Hacking LIVE 10 Ticket NOW (PRICE DOUBLES @ MIDNIGHT) →
Talk soon,
Russell Brunson
P.S. Don’t forget, you’re just one funnel away…
© Etison LLC
By reading this, you agree to all of the following: You understand this to be an expression of opinions and not professional advice. You are solely responsible for the use of any content and hold Etison LLC and all members and affiliates harmless in any event or claim.
If you purchase anything through a link in this email, you should assume that we have an affiliate relationship with the company providing the product or service that you purchase, and that we will be paid in some way. We recommend that you do your own independent research before purchasing anything.
Copyright © 2018+ Etison LLC. All Rights Reserved.
To make sure you keep getting these emails, please add us to your address book or whitelist us. If you don't want to receive any other emails, click on the unsubscribe link below.
Etison LLC
3443 W Bavaria St
Eagle, ID 83616
United States
by "Russell Brunson" <noreply@clickfunnelsnotifications.com> - 03:32 - 2 Feb 2025 -
High Quality Safety Gloves – Enhance Your Workforce Protection
Dear info,
Nice day. This is Tony from Perfect safety.
Our company founded in 2010, now has two factories. One factory is focus on twisting, making all kinds of glove liner; Another factory mainly for the dipping of glove. Now our annual output nearly 10 million dozens. We mainly produce latex, nitrile, PU coated gloves and impact resistant gloves,cut resistant glove etc.Looking forward to your reply, if you have any question and requirement, freely let me know.
Regards!
Perfect safety
by "david" <david@pufeitesafety.com> - 01:52 - 2 Feb 2025 -
The week in charts
The Week in Charts
AI-enhanced cyberattacks, US transit, and more Share these insights
Did you enjoy this newsletter? Forward it to colleagues and friends so they can subscribe too. Was this issue forwarded to you? Sign up for it and sample our 40+ other free email subscriptions here.
This email contains information about McKinsey's research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this email because you subscribed to The Week in Charts newsletter.
Copyright © 2025 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "McKinsey Week in Charts" <publishing@email.mckinsey.com> - 03:36 - 1 Feb 2025 -
A WARNING if you’re on the fence…
2 days before tickets either sell out or I DOUBLE pricesThis is it…
48 hours before we either sell out tickets to Funnel Hacking LIVE 10 (The LAST DANCE)…
Or I DOUBLE the ticket cost! Muahaha!! ;)
You have until THIS SUNDAY AT MIDNIGHT to grab one of the remaining tickets to FHL, before the ticket price to attend FHL doubles!!
GRAB YOUR FHL TICKET NOW BEFORE THE PRICE DOUBLES →
As of this past week, we’ve sold nearly 5 BAJILLION tickets (Scratch that - nearly all of our 5,000 tickets!!)
I found out a TON of people who will be attending ASW (Affiliate Summit West) are gonna stay the following week so they can join us at Funnel Hacking LIVE 10!!
So if you’re going to be at Affiliate Summit West… then do what a ton of people are already doing and extend your time and join us with the Funnel Hacking family!
It’s kind of the perfect combo when you think about it… you’re going to learn how to become THE RADICAL at Funnel Hacking Live… which is EXACTLY what you’ll need to do in order to SCALE your offers, including affiliate offers, to a whole new level!!
…and this is coming from a well-known super-affiliate who’s been doing affiliate marketing for YEARS! ;)
But there’s a problem…
We have less than a couple hundred seats left before we hit MAX occupancy.
And ticket sales are still flooding in!

So if you haven’t gotten your FHL ticket yet, and you’re planning to go to FHL or Affiliate Summit West...
Consider this just about your “final warning”.
I can’t stress this enough:
Grab one of the remaining tickets now, and come join us at Funnel Hacking LIVE! (THE LAST DANCE) →
Tickets will be GONE or DOUBLED in price on Sunday at 11:59pm.
Talk soon,
Russell Brunson
P.S. - Don’t forget, you’re just one funnel away…
P.P.S. - Grab one of the REMAINING tickets to FHL BEFORE the price doubles this Sunday @ midnight!! →© Etison LLC
By reading this, you agree to all of the following: You understand this to be an expression of opinions and not professional advice. You are solely responsible for the use of any content and hold Etison LLC and all members and affiliates harmless in any event or claim.
If you purchase anything through a link in this email, you should assume that we have an affiliate relationship with the company providing the product or service that you purchase, and that we will be paid in some way. We recommend that you do your own independent research before purchasing anything.
Copyright © 2018+ Etison LLC. All Rights Reserved.
To make sure you keep getting these emails, please add us to your address book or whitelist us. If you don't want to receive any other emails, click on the unsubscribe link below.
Etison LLC
3443 W Bavaria St
Eagle, ID 83616
United States
by "Russell Brunson" <noreply@clickfunnelsnotifications.com> - 01:32 - 1 Feb 2025 -
EP148: DeepSeek 1-Pager
EP148: DeepSeek 1-Pager
An AI agent is a software program that can interact with its environment, gather data, and use that data to achieve predetermined goals.͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ Forwarded this email? Subscribe here for moreBuild the API your users deserve (Sponsored)

Creating a best in class API experience for your partners and customers shouldn't require an army of engineers. Speakeasy’s platform automates the generation of idiomatic SDKs, custom-branded docs, and robust test suites that are as good as what you'd build yourself. That means you can unlock API revenue while keeping your team focused on what matters most: shipping new products. All you need to get started is your OpenAPI document.
This week’s system design refresher:
DeepSeek 1-Pager
My Favorite 10 Books for Software Developers
What is an AI Agent?
Git vs GitHub
A Cheatsheet on Database Performance
18 Common Ports Worth Knowing
SPONSOR US
DeepSeek 1-Pager

It is said to have developed a powerful AI model at a remarkably low cost, approximately $6 million for the final training run. In January 2025, it is said to have released its latest reasoning-focused model known as DeepSeek R1.
The release made it the No. 1 downloaded free app on the Apple Play Store.
Most AI models are trained using supervised fine-tuning, meaning they learn by mimicking large datasets of human-annotated examples. This method has limitations.
DeepSeek R1 overcomes these limitations by using Group Relative Policy Optimization (GRPO), a reinforcement learning technique that improves reasoning efficiency by comparing multiple possible answers within the same context.
Some facts about DeepSeek’s R1 model are as follows:DeepSeek-R1 uses a Mixture-of-Experts (MoE) architecture with 671 billion total parameters, activating only 37 billion parameters per task.
It employs selective parameter activation through MoE for resource optimization.
The model is pre-trained on 14.8 trillion tokens across 52 languages.
DeepSeek-R1 was trained using just 2000 Nvidia GPUs. By comparison, ChatGPT-4 needed approximately 25K Nvidia GPUs over 90-100 days.
The model is 85-90% more cost-effective than competitors.
It excels in mathematics, coding, and reasoning tasks.
Also, the model has been released as open-source under the MIT license.
Over to you: Have you tried DeepSeek?
Download the high-resolution image here.
My Favorite 10 Books for Software Developers

General Advice
The Pragmatic Programmer by Andrew Hunt and David Thomas
Code Complete by Steve McConnell: Often considered a bible for software developers, this comprehensive book covers all aspects of software development, from design and coding to testing and maintenance.
Coding
Clean Code by Robert C. Martin
Refactoring by Martin Fowler
Software Architecture
Designing Data-Intensive Applications by Martin Kleppmann
System Design Interview (our own book :))
Design Patterns
Design Patterns by Eric Gamma and Others
Domain-Driven Design by Eric Evans
Data Structures and Algorithms
Introduction to Algorithms by Cormen, Leiserson, Rivest, and Stein
Cracking the Coding Interview by Gayle Laakmann McDowell
Over to you: What is your favorite book?
How I use 20+ AI models in one app
(PRESENTED BY YOU.COM)

I routinely have ChatGPT, Claude, and DeepSeek open side-by-side because each model excels at tasks that the others don't.
That’s why I like using You.com, the tool that combines the most popular AI models in one app:
Toggle 20+ AI models in the same chat thread
Compare answers to find the best one
Eliminates tab switching/prompt pasting
Ends soon: Access 12 months of Pro at no cost ($180 value). Just visit the offer page to redeem your special offer as a ByteByteGo newsletter subscriber.
What is an AI Agent?

An AI agent is a software program that can interact with its environment, gather data, and use that data to achieve predetermined goals. AI agents can choose the best actions to perform to meet those goals.
Key characteristics of AI agents are as follows:
An agent can perform autonomous actions without constant human intervention. Also, they can have a human in the loop to maintain control.
Agents have a memory to store individual preferences and allow for personalization. It can also store knowledge. An LLM can undertake information processing and decision-making functions.
Agents must be able to perceive and process the information available from their environment.
Agents can also use tools such as accessing the internet, using code interpreters and making API calls.
Agents can also collaborate with other agents or humans.
Multiple types of AI agents are available such as learning agents, simple reflex agents, model-based reflex agents, goal-based agents, and utility-based agents.
A system with AI agents can be built with different architectural approaches.
Single Agent: Agents can serve as personal assistants.
Multi-Agent: Agents can interact with each other in collaborative or competitive ways.
Human Machine: Agents can interact with humans to execute tasks more efficiently.
Over to you: Have you used AI Agents?
Git vs GitHub

Git and GitHub are popular tools for version control. They work together and complement each other to provide effective source control management.
On a high level, Git is focused on version control and code sharing, whereas GitHub is focused on centralized source code hosting for sharing with other developers.
However, they have some key differences
Git is a free, open-source version control tool. GitHub is a cloud-based, pay-for-use service that runs Git in the cloud.
Git is installed locally on a developer’s machine. GitHub is hosted in the cloud.
The Linux Foundation maintains Git. Microsoft owns GitHub.
Git can manage different versions of edits, made to files in a git repository. GitHub is a space to upload a copy of the Git repository.
Git supports version control and source code management. GitHub can be used for hosting code, collaboration, and project management.
Git has minimal external tool configuration. GitHub provides an active marketplace for tool integration.
Lastly, you can use Git without GitHub but you cannot use GitHub without Git.
Over to you: What else will you add to distinguish between Git and GitHub?A Cheatsheet on Database Performance

Good database performance is critical since it directly impacts user experience, operational costs, and scalability.
But what impacts database performance?
Evaluating database performance depends on key metrics such as query execution time, throughput, latency, and resource utilization.
Workload Types such as write-heavy, read-heavy, delete-heavy, and competing workloads pose unique challenges.Other factors that impact performance are item size, item type, dataset size, concurrency expectations, consistency requirements, HA expectations, and geographic distribution.
Multiple strategies exist to improve database performance. Some of the most important ones are as follows:Database Indexing
Indexes are important for speeding up database queries by reducing the amount of data scanned. Also, choosing the right index type is crucial.Sharding and Partitioning
Divide the data into smaller, more manageable chunks known as shards. Each shard is also stored on a different server.Denormalization
Denormalization combines data into fewer tables to reduce the overhead of joins, improving read performance.Database Replication
Replication involves maintaining multiple copies of the same database, typically with a primary node for writes (and critical reads) and secondary nodes for most read operations.Database Locking Techniques
Use locking techniques like pessimistic and optimistic locking to manage concurrency levels and resource contention.
Over to you: Which other database performance strategy will you add to the list?
18 Common Ports Worth Knowing

FTP (File Transfer Protocol): Uses TCP Port 21
SSH (Secure Sheel for Login): Uses TCP Port 22
Telnet: Uses TCP Port 23 for remote login
SMTP (Simple Mail Transfer Protocol): Uses TCP Port 25
DNS: Uses UDP or TCP on Port 53 for DNS queries
DHCP Server: Uses UDP Port 67
DHCTP Client: Uses UDP Port 68
HTTP (Hypertext Transfer Protocol): Uses TCP Port 80
POP3 (Post Office Protocol V3): Uses TCP Port 110
NTP (Network Time Protocol): Uses UDP Port 123
NetBIOS: Uses TCP Port 139 for NetBIOS service
IMAP (Internet Message Access Protocol): Uses TCP Port 139
HTTPS (Secure HTTP): Uses TCP Port 443
SMB (Server Message Block): Uses TCP Port 445
Oracle DB: Uses TCP Port 1521 for Oracle database communication port
MySQL: Uses TCP Port 3360 for MySQL database communication port
RDP: Uses TCP Port 3389 for Remote Desktop Protocol
PostgreSQL: Uses TCP Port 5432 for PostgreSQL database communication
Over to you: Which other port will you add to the list?
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.
Like
Comment
Restack
© 2025 ByteByteGo
548 Market Street PMB 72296, San Francisco, CA 94104
Unsubscribe

by "ByteByteGo" <bytebytego@substack.com> - 11:36 - 1 Feb 2025 -
Stretched Canvas from Jiade in china
Dear info,
I hope this email find that you are well.
I am Shuyang Jiade painting material of Jiangsu Province. We specialize in producing DIY handmade products such as painting, drawing canvas, pole frame, wooden easel, canvas canvas board and art supplies.
1. Cooperate with Michaels to provide superior product quality.
2. Our own factory, we offer competitive first hand prices.
3. The products have passed the certification of CE and ANSI,ISO 9001,ISO 14001 and other authoritative organizations.
4. With extensive industry related experience, we can develop and customize any product according to requirements
Reply catalogues and FOC samples.
If you need more help, please let me know
Best Regards
Allen Wang
Suqian Jiade Painting Materials Co., Ltd.
Wechat/Tel:+86 15151113243
Email:jiadehuacai@gmail.com
Floor 3, No.9 Chaoyang Industrial Park, Shuyang City, Jiangsu Province, China
Website: https://jdartmaterials.cn/
by "Luna" <Luna@jdartmaterials.com> - 03:01 - 31 Jan 2025 -
GC & Sub Contractors Estimate
HelloWe are an estimation company providing takeoff and estimation services to GCs and subcontractors across the USA, UK, and Canada.
We handle both commercial and residential projects, covering all trades, including electrical, mechanical, plumbing, painting, framing, and more.
Send us your plans for a quote. If you agree, we’ll proceed further. You can also request a sample estimate.
Best regards.

by "Ben Frank" <ben.aimestimating@gmail.com> - 12:23 - 31 Jan 2025 -
Professional sales of high-end building materials, including ceramic tiles, marble tiles, tombstones
Dear info,
I hope this email finds you well. I am writing to introduce our company and our range of high-quality building materials that are well suited for the Middle East market.
At our company, we specialize in the sales of top-grade building materials, including Tile, Tombstone Garden Building, grante and marble tile, countertop, Tombstone, and Kerb Stone. Our products are made from the finest materials and are designed to meet the high standards of quality and durability that are required in the Middle East.
We understand the unique needs of the construction industry in the Middle East and are committed to providing products that are not only aesthetically pleasing but also capable of withstanding the harsh climate conditions of the region.
We would welcome the opportunity to discuss how our products can meet your specific needs and contribute to the success of your projects. Please feel free to contact us to schedule a meeting or to request any additional information.
Thank you for considering our products. We look forward to the possibility of working with you.
Sincerely,
Anna
by "yoshiko" <y1895528@gmail.com> - 02:19 - 31 Jan 2025 -
Clean Architecture 101: Building Software That Lasts
Clean Architecture 101: Building Software That Lasts
Modern software development often involves complex systems that need to adapt quickly to changes, whether it's user requirements, technology updates, or market shifts.͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ Forwarded this email? Subscribe here for moreLatest articles
If you’re not a subscriber, here’s what you missed this month.
Kubernetes Made Easy: A Beginner’s Roadmap to Container Orchestration
The Sidecar Pattern Explained: Decoupling Operational Features
Database Performance Demystified: Essential Tips and Strategies
To receive all the full articles and support ByteByteGo, consider subscribing:
Modern software development often involves complex systems that need to adapt quickly to changes, whether it's user requirements, technology updates, or market shifts.
Clean Architecture can help with this.
It is a software design philosophy that emphasizes creating systems that are easy to understand, maintain, and extend.
At its core, Clean Architecture tries to ensure that the most important parts of your application, like business rules and logic, are independent of external concerns such as frameworks, databases, or user interfaces.
Clean Architecture was popularized by Robert C. Martin, also known as Uncle Bob. He introduced the concept in his book Clean Architecture where he built upon earlier design paradigms like Hexagonal Architecture and Onion Architecture.
The main purpose of Clean Architecture is to:
Make software maintainable
Improve scalability
Enhance the testability of components
Decouple business logic from external details
In simple terms, Clean Architecture organizes a software system into layers, each with a specific responsibility. Dependencies flow only in one direction: toward the core business logic. This structure helps keep the system modular, testable, and resilient to changes.
In this article, we’ll understand what Clean Architecture is in detail. We’ll explore the key principles of Clean Architecture and also look at the various parts of the layered structure.
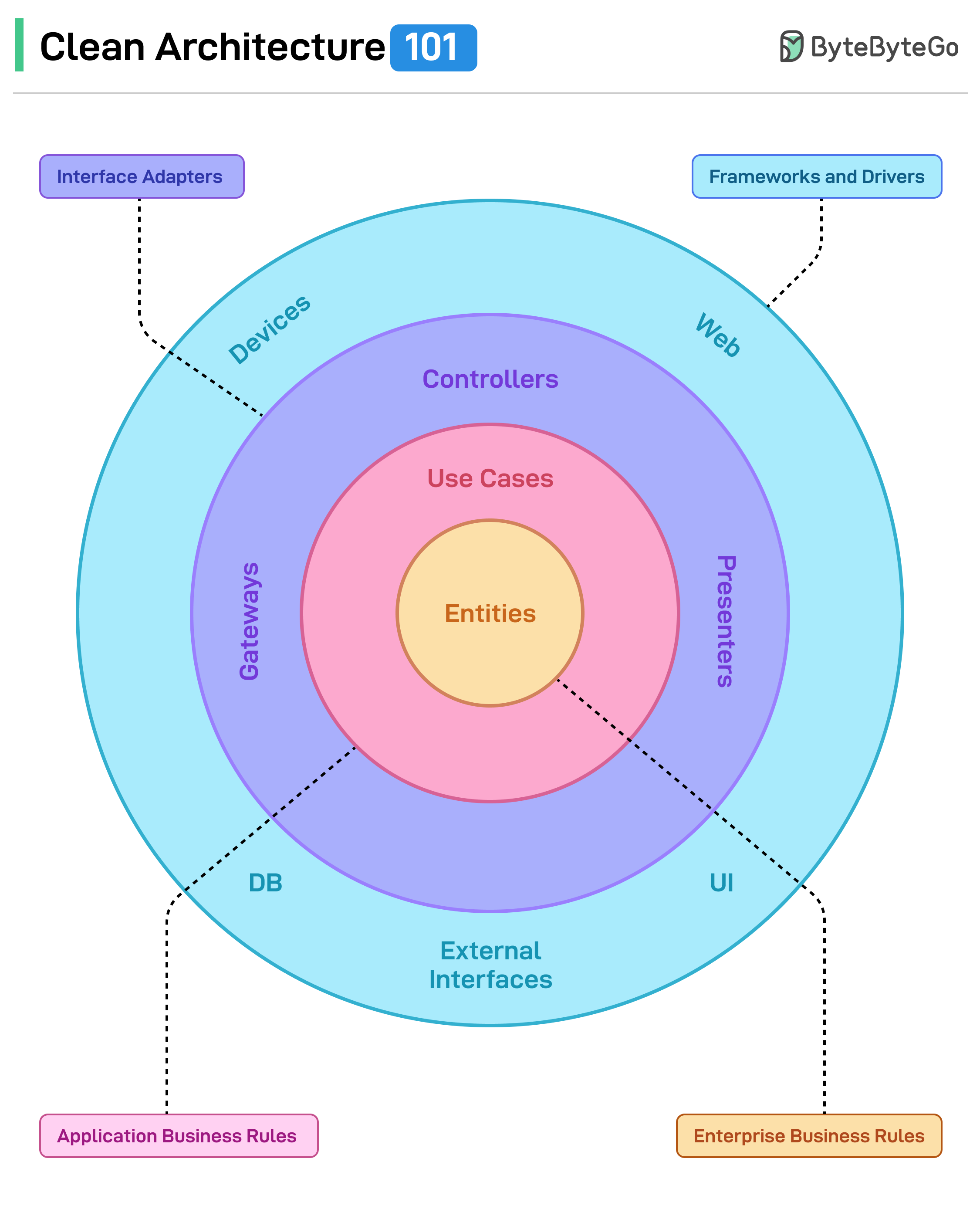
Key Principles of Clean Architecture...

Continue reading this post for free in the Substack app
© 2025 ByteByteGo
548 Market Street PMB 72296, San Francisco, CA 94104
Unsubscribe
by "ByteByteGo" <bytebytego@substack.com> - 11:36 - 30 Jan 2025 -
🎂 Celebrate Remote's 6th birthday with us!
🎂 Celebrate Remote's 6th birthday with us!
Your monthly global update from Remote has landed, check it out!.png?width=204&upscale=true&name=Logo%20Horizontal%20(3).png)


Featured news

Must read: Level up 💪 your contractor compliance with Remote Contractor of Record
Remote Contractor of Record is a game changer for businesses who are looking to go global. Learn more about how Remote COR can help businesses avoid misclassification risks and ease the burden of admin and compliance while working with contractors.

Remote AI: Global HR insights at your fingertips
Simplify the complexities of managing an international workforce with Remote AI. Our cutting-edge AI-powered chat provides real-time, global insights to help your teams work smarter and faster.
- Get real-time, localized insights tailored to your needs.
- Reduce manual effort and streamline operations.
- Make confident decisions without hours searching for the right answers.
Remote news
Remote is celebrating its sixth birthday 🎂🎉

We are very grateful to all our customers and our employees for getting us this far. A heartfelt thank you, and here's to the next six years!
Product news
Introducing Remote Device Management: Simplify global IT operations

Managing technology for a distributed workforce doesn’t have to be a logistical headache. In partnership with Fleet, Remote’s Device Management simplifies device management for your global teams, ensuring employees and contractors worldwide are equipped with reliable technology from day one.
Upcoming events
🇧🇪 Brussels HR leadership workshop on hiring from abroad
When: February 11th, 6:30 - 9:00pm
Join Remote and the D2 Collective in Brussels this February 11th for a workshop dedicated to the best solutions for Belgium companies to hire knowledge workers from anywhere.
🇳🇱 Amsterdam HR leadership workshop on global hiring
When: February 12th, 6:30 - 9:00pm
A call for HR leaders and company founders to join Remote and the D2 Collective in Amsterdam. You will leave this workshop with actionable insights to start hiring from anywhere asap.
🇦🇹 Join our HR meet up in Wien
When: February 19th, 6:00 pm – 10:00 pm
Join us for a fun HR Meetup co-hosted by WeAreDevelopers filled with good pizza, drinks, and the opportunity to connect with fellow HR professionals! Don't miss the panel discussion: All About the Benefits: Hiring IT Talent in 2025, featuring Talent Acquisition and Recruiting experts.
🇩🇪 Join Leapsome and Remote in Berlin
When: February 20th, 5:00 pm
Join us for an enlightening session co-hosted by Leapsome and Remote, tailored specifically for HR leaders looking to cultivate high-performing teams in a demanding economic landscape.
Upcoming virtual events
Strategies to Attract and Hire Top Talent from All the World in a Competitive Landscape Webinar
When: February 27th, 6pm CET / 12pm EST
Join Remote’s Director of Talent Acquisition for this sourcing webinar with Matchr and find how to build your hiring strategy and techniques for sourcing the best talent from anywhere.
Talent Leaders Virtual Roundtable: Strategies for hiring faster and smarter in 2025
When: February 5th, 1:00pm EST
Join our exclusive TA & HR Leaders in SMB virtual roundtable around strategies for hiring faster and smarter in 2025. Don’t miss out on an insightful night of networking and collaboration with TALiNT Partners Talent Leaders.
Successful global onboarding: Mastering International expansion Webinar
When: February 4th, 12:30pm GMT
Mastering international expansion starts with onboarding - don't miss Remote's upcoming webinar in collaboration with HR magazine.
🇩🇪 Webinars in German
German Online conference: Breaking bad hiring habits
When: February 4th, 10:15 - 10:45am
Join Ina Brunner in an exclusive webinar to explore the top hiring strategies for 2025 and stay ahead in the ever-evolving talent landscape.
HR Collective Webinar Remote recruiting strategies for 2025
When: February 12th at 10:00 - 11:30am
Gain insights from Lisa Berglund, Account Executive at Remote, on hiring strategies for 2025 and hear real success stories from the HR Collective community. Walk away with actionable tips to overcome cultural challenges and attract the best talent.
Online conference for HR in Austria
When: February 19th, 9:45 -10:15am
Challenging times require special personnel management: What awaits Austria's HR managers and what skills do they need to master in this new economy? Brigitte Gneissl, Account Executive at Remote will be talking about successful hiring strategies for 2025.
The HR platform for global businesses
Remote makes running global teams simple. Hire, manage, and pay anyone, anywhere. Book a personal consultation with an expert to discuss your unique HR needs.







You received this email because you are subscribed to
News & Offers from Remote Europe Holding B.V
Update your email preferences to choose the types of emails you receive.
Unsubscribe from all future emailsRemote Europe Holding B.V
Copyright © 2025 Remote Europe Holding B.V All rights reserved.
Kraijenhoffstraat 137A 1018RG Amsterdam The Netherlands
by "Remote" <hello@remote-comms.com> - 10:17 - 30 Jan 2025 -
GONE in 4 hours (bye bye bonuses…)
Time’s tickin’...This is it…
We’re down to the wire.
T-minus 3 hours (and some minutes) and counting… until ALL of my FHL speakers bonuses (eeeeeeeasily worth $20K+ in value)... GOES AWAY FOR GOOD!!!
If you want them, come and claim them…
…when you click or tap the link below:
Hurry here and claim your FHL ticket (and unlock the $20K in free bonuses instantly) →
Again, here are all of the FREE bonuses you’ll receive when you secure your ticket to FHL 10 before MIDNIGHT!!!
-
Ashley Kirkwood’s Bonus! The “cheat sheet” that will not only help INCREASE your engagement and sales… but can change your entire business model into the one you’ve always wanted!! (Watch Ashley’s bonus reveal HERE→)
-
Eileen Wilder’s Bonus! Hours of coaching content teaching you her framework of persuasion and influence you can use absolutely ANYWHERE to maximize influence and quickly increase sales!! (Watch Eileen’s bonus reveal HERE→)
- Tim Shields’ Bonus! THE essential webinar-building companion that will help you create your expert level, game-changing webinar faster than you ever thought possible! (Watch Tim’s bonus reveal HERE→)
-
Trent Shelton’s Bonus! Become a more confident and successful speaker and overall expert communicator with Trent’s extremely beneficial training that will help you improve in ALL areas of selling! (Watch Trent’s bonus reveal HERE→)
- Armand Morin’s Bonus! Discover the exact formula Armand uses to compound the effectiveness of the “stack and close” system! (Watch Armand’s bonus reveal HERE→)
-
Garrett J. White’s Bonus! Unlock the six skills you need to become a true movement maker in business with Garrett’s 3-day FREE virtual training!! (Watch Garrett’s bonus reveal HERE→)
-
Josiah Grimes’ Bonus! Uncover Josiah’s incredible wealth of knowledge that will work in ANY NICHE! (Watch Josiah’s bonus reveal HERE→)
Andy Elliott’s Bonus! Become a better entrepreneur, become a better spouse, become a better human being!! (Watch Andy’s speaker reveal HERE→)
-
McCall Jones’ Bonus! (Watch McCall’s bonus reveal HERE→) Learn how to apply your unique voice to my (Russell’s) strategies for top-converting presentations and offers!
-
Myron Golden’s Bonus! Start learning how to unlock your top-tier mindset before you’ve even made your first million! (Watch Myron’s bonus reveal HERE→)
-
Hala Taha’s Bonuses! Get the tools and knowledge you need to get started on your own profitable podcast FAST!! (Watch Hala’s bonus reveal HERE→)
-
Stu McLaren’s Bonuses! Get the training that reveals the incredible process Stu has used to sell courses, memberships, events, software, masterminds and more!! (Watch Stu's bonus reveal HERE→)
- Dr. Sonja’s Bonuses! Get the “runway guide” that you can use as a blueprint for massive growth in your own business, regardless of what product or service you sell!! (Watch Dr. Sonja’s bonus reveal HERE→)
And that’s it!
This is the FINAL email you’ll receive from me regarding the speaker bonuses.
You’ll get them INSTANTLY as soon as you grab one of the last remaining tickets for FHL 10 in Vegas!!!
HURRY AND GRAB YOUR FHL TICKET & SECURE THE FREE BONUSES WORTH OVER $20K IN VALUE!! →

© Etison LLC
By reading this, you agree to all of the following: You understand this to be an expression of opinions and not professional advice. You are solely responsible for the use of any content and hold Etison LLC and all members and affiliates harmless in any event or claim.
If you purchase anything through a link in this email, you should assume that we have an affiliate relationship with the company providing the product or service that you purchase, and that we will be paid in some way. We recommend that you do your own independent research before purchasing anything.
Copyright © 2018+ Etison LLC. All Rights Reserved.
To make sure you keep getting these emails, please add us to your address book or whitelist us. If you don't want to receive any other emails, click on the unsubscribe link below.
Etison LLC
3443 W Bavaria St
Eagle, ID 83616
United States
by "Russell Brunson" <noreply@clickfunnelsnotifications.com> - 07:10 - 30 Jan 2025 -
Ashley Kirkwood’s Bonus! The “cheat sheet” that will not only help INCREASE your engagement and sales… but can change your entire business model into the one you’ve always wanted!! (Watch Ashley’s bonus reveal HERE→)
-
You’re Invited! Dive into Exclusive Content Now!
There’s so much more to discover in the new Skool group...Hey there!
Wanna check out a TOP SECRET copywriting training I shared with a group of top marketers...2 YEARS before launching ClickFunnels?
Or maybe get your hands on a FULL PDF copy of my book *108 Split Test Winners*?
How about a rare original copy of Napoleon Hill’s “1357 Plan For Personal Achievement” (trust me, you haven’t seen this before)...?
That’s just the tip of the iceberg when it comes to what I’ve been dropping in the new, FREE Selling Online Skool group!!
Honestly, if you’re not in there yet… WHAT ARE YOU WAITING FOR?!
Here’s just a taste of the value-packed posts I’ve been sharing:
→ PRIVATE ‘Inception Secrets’ 1 Hour Copywriting Training (Tap Here)
→ PDF of ‘108 Split Test Winners’ (Tap Here)
→ Napoleon Hill’s ‘1357 Plan For Personal Achievement (Tap Here)
→ The ‘Star, Story, Solution’ Script (Tap Here)
→ Robert Collier’s ‘Life Magnet’ (Tap Here)
Click any of the links above to dive in.
And that’s just the start—there’s EVEN MORE incredible content and resources waiting for you inside!!!
Thanks,
Russell Brunson
P.S. - Remember, you’re just ONE funnel away…
Join the COMPLETELY FREE Selling Online Skool group and discover everything you need to sell anything online.
Marketing Secrets
3443 W Bavaria St
Eagle, ID 83616
United States
by "Russell Brunson" <newsletter@marketingsecrets.com> - 03:45 - 30 Jan 2025