Archives
- By thread 5384
-
By date
- June 2021 10
- July 2021 6
- August 2021 20
- September 2021 21
- October 2021 48
- November 2021 40
- December 2021 23
- January 2022 46
- February 2022 80
- March 2022 109
- April 2022 100
- May 2022 97
- June 2022 105
- July 2022 82
- August 2022 95
- September 2022 103
- October 2022 117
- November 2022 115
- December 2022 102
- January 2023 88
- February 2023 90
- March 2023 116
- April 2023 97
- May 2023 159
- June 2023 145
- July 2023 120
- August 2023 90
- September 2023 102
- October 2023 106
- November 2023 100
- December 2023 74
- January 2024 75
- February 2024 75
- March 2024 78
- April 2024 74
- May 2024 108
- June 2024 98
- July 2024 116
- August 2024 134
- September 2024 130
- October 2024 141
- November 2024 171
- December 2024 115
- January 2025 216
- February 2025 140
- March 2025 220
- April 2025 233
- May 2025 239
- June 2025 303
- July 2025 198
-
RE: Consumer Electronics Show - CES 2024 (Post Show)
Hi,
I was wondering if you had a chance to review my below email that I sent to you.
If you are interested, I can get back to you with Counts and Cost for the same.
Thanks,
Terry
From: terry.baker@datasmining.com <terry.baker@datasmining.com>
Sent: Friday, May 17, 2024 1:18 PM
To: 'info@learn.odoo.com' <info@learn.odoo.com>
Subject: Consumer Electronics Show - CES 2024 (Post Show)Hi,
The verified & updated contacts attendees list of Consumer Electronics Show - CES 2024 is available with us.
Attendees are: - Analyst, Content Developer, Distributor, Buyer, Engineer, Manager/Store Manager/Product Manager, Manufacturer’s Representative, Service Technician, Systems Installer/Integrator & More.
List includes: - Contact Name, Email address, Phone Number, Mailing Address, Job Title etc.
If you are interested in the list, I shall share the counts & cost details.
Best Regards,
Terry Baker - Marketing and Event Coordinator
If you don’t want to receive further emails please revert with “Take Out” in the subject
by terry.baker@datasmining.com - 02:18 - 21 May 2024 -
How Slack Built a Distributed Cron Execution System for Scale
How Slack Built a Distributed Cron Execution System for Scale
👋Goodbye low test coverage and slow QA cycles (Sponsored) Bugs sneak out when less than 80% of user flows are tested before shipping. But getting that kind of coverage — and staying there — is hard and pricey for any sized team. QA Wolf takes testing off your plate:͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ Forwarded this email? Subscribe here for more👋Goodbye low test coverage and slow QA cycles (Sponsored)

Bugs sneak out when less than 80% of user flows are tested before shipping. But getting that kind of coverage — and staying there — is hard and pricey for any sized team.
QA Wolf takes testing off your plate:
→ Get to 80% test coverage in just 4 months.
→ Stay bug-free with 24-hour maintenance and on-demand test creation.
→ Get unlimited parallel test runs
→ Zero Flakes guaranteed
QA Wolf has generated amazing results for companies like Salesloft, AutoTrader, Mailchimp, and Bubble.
🌟 Rated 4.5/5 on G2
Learn more about their 90-day pilot
Have you ever stretched a simple tool to its absolute limits before you upgraded?
We do it all the time. And so do the big companies that operate on a massive scale. This is because simple things can sometimes take you much further than you initially think. Of course, you may have to pay with some toil and tears.
This is exactly what Slack, a $28 billion company with 35+ million users, did for its cron execution workflow that handles critical functionalities. Instead of moving to some other new-age solutions, they rebuilt their cron execution system from the ground up to run jobs reliably at their scale.
In today’s post, we’ll look at how Slack architected a distributed cron execution system and the choices made in the overall design.
The Role of Cron Jobs at Slack
As you already know, Slack is one of the most popular platforms for team collaboration.
Due to its primary utility as a communication tool, Slack is super dependent on the right notification reaching the right person at the right time.
However, as the platform witnessed user and feature growth, Slack faced challenges in maintaining the reliability of its notification system, which largely depended on cron jobs.
For reference, cron jobs are used to automate repetitive tasks. You can configure a cron job to ensure that specific scripts or commands run at predefined intervals without manual intervention.
Cron jobs play a crucial role in Slack's notification system by making sure that messages and reminders reach users on time. A lot of the critical functionality at Slack relies on these cron scripts. For example,
Sending timely reminders to users.
Delivering email notifications to keep the users informed about important updates in the team.
Pushing message notifications to users so that they don’t miss critical conversations.
Performing regular database clean-ups to maintain system performance.
As Slack grew, there has been a massive growth in the number of cron scripts and the amount of data processed by these scripts. Ultimately, this caused a dip in the overall reliability of the execution environment.
The Issues with Cron Jobs
Some of the challenges and issues Slack faced with their original cron execution approach were as follows:
Maintainability Issues: Managing many cron scripts on a single node became cumbersome and error-prone as Slack’s functionalities expanded. Tasks like updating, troubleshooting, and monitoring the scripts required a lot of effort from the engineering team.
Cost-ineffective Vertical Scaling: As the number of cron scripts increased, Slack tried to vertically scale the node by adding more CPU and RAM. However, this approach quickly became cost-ineffective, as the hardware requirements grew disproportionately to the number of scripts.
Single Point of Failure: Relying on a single node to execute all cron jobs introduced a significant risk to Slack’s critical functionality. Any misconfigurations, hardware failures, or software issues on the node could bring down the entire notification system.
To solve these issues, Slack decided to build a brand new cron execution service that was more reliable and scalable than the original approach.
The High-Level Cron Execution Architecture
The below diagram shows the high-level cron execution architecture.
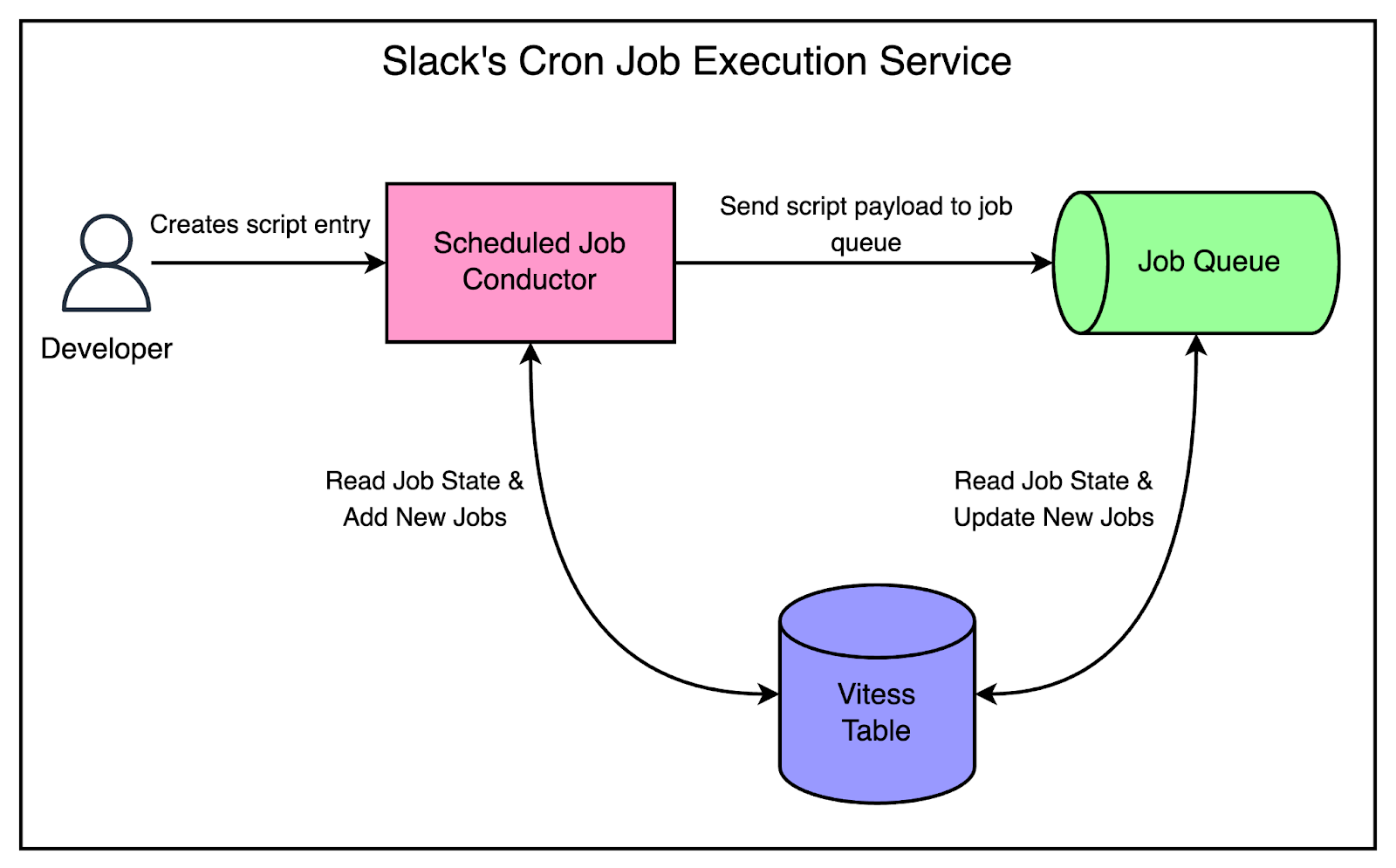
There are 3 main components in this design. Let’s look at each of them in more detail.
Scheduled Job Conductor
Slack developed a new execution service. It was written in Go and deployed on Bedrock.
Bedrock is Slack’s in-house platform that wraps around Kubernetes, providing an additional abstraction layer and functionality for Slack’s specific needs. It builds upon Kubernetes and adds some key features such as:
Simplified deployment
Custom resource definitions specific to Slack’s infrastructure
Enhanced monitoring and logging
Integration with Slack’s infrastructure
The new service mimics the behavior of cron by utilizing a Go-based cron library while benefiting from the scalability and reliability provided by Kubernetes.
The below diagram shows how the Scheduled Job Conductor works in practice.
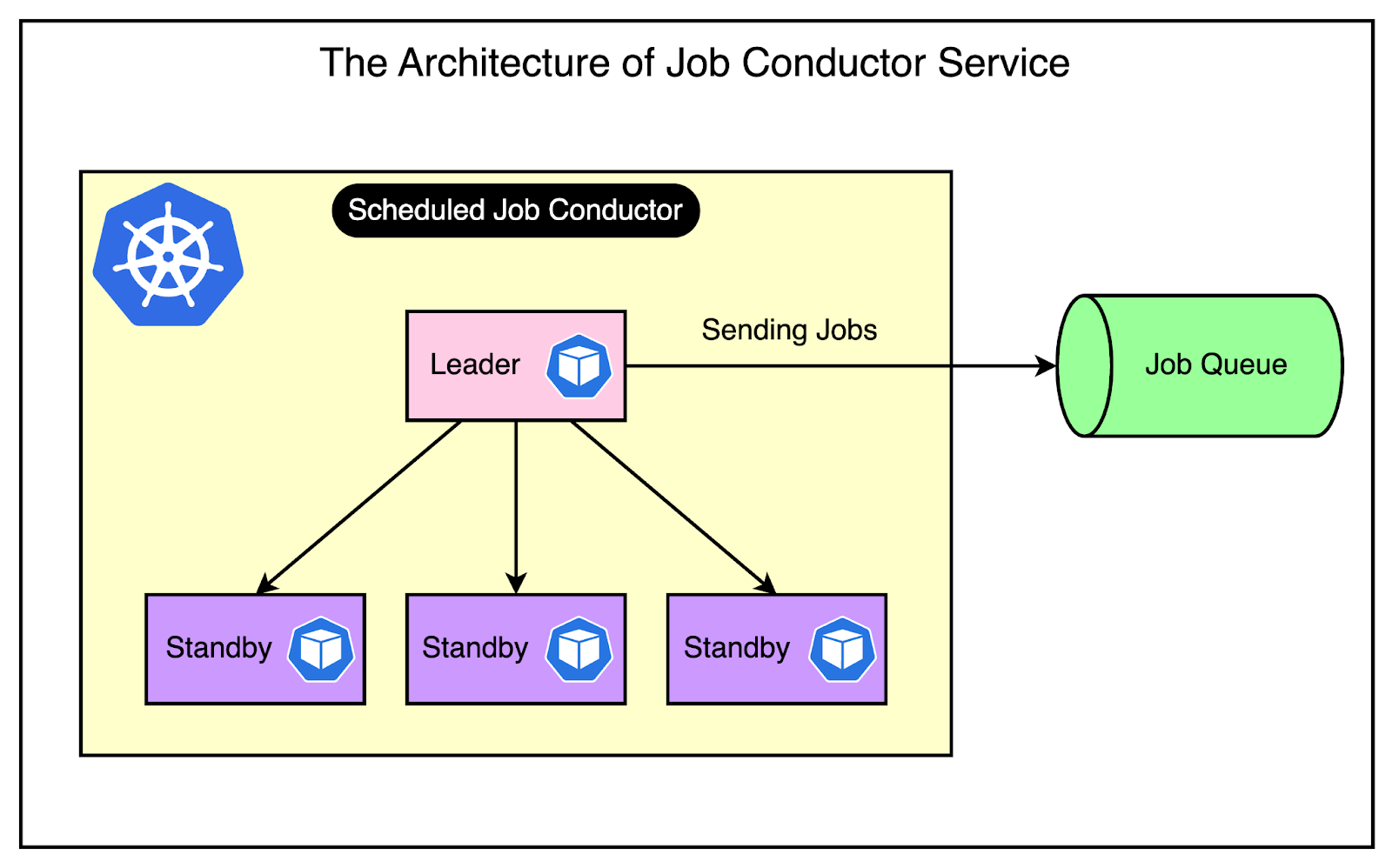
It had some key properties that we should consider.
1 - Scalability through Kubernetes Deployment
By deploying the cron execution service on Bedrock, Slack gains the ability to easily scale up multiple pods as needed.
As you might be aware, Kubernetes provides a flexible infrastructure for containerized applications. You can dynamically adjust the number of pods based on the workload.
2 - Leader Follower Architecture
Interestingly, Slack's cron execution service does not process requests on multiple pods simultaneously.
Instead, they adopt a leader-follower architecture, where only one pod (the leader) is responsible for scheduling jobs, while the other pods remain in standby mode.
This design decision may seem counterintuitive, as it appears to introduce a single point of failure. However, the Slack team determined that synchronizing the nodes would be a more significant challenge than the potential risk of having a single leader.
A couple of advantages of the leader-follower architecture are as follows:
Rapid Failover: If the leader pod goes down, Kubernetes can quickly promote one of the standby pods to take over the work. This minimizes downtime and makes the cron execution service highly available.
Simplified Synchronization: By having a single leader, Slacks avoids the complexity of dealing with conflicts.
3 - Offloading Resource-Intensive Tasks
The job conductor service is only responsible for job scheduling. The actual execution is handled by worker nodes.
This separation of concerns allows the cron execution service to focus on job scheduling while the job queue handles resource-intensive tasks.
Latest articles
If you’re not a paid subscriber, here’s what you missed.
To receive all the full articles and support ByteByteGo, consider subscribing:
The Job Queue
Slack's cron execution service relies on a powerful asynchronous compute platform called the Job Queue to handle the resource-intensive task of running scripts.
The Job Queue is a critical component of Slack's infrastructure, processing a whopping 9 billion jobs per day.
The Job Queue consists of a series of so-called theoretical “queues” through which various types of jobs flow. Each script triggered by a cron job is treated as a single job within the Job Queue.
See the below diagram for reference:
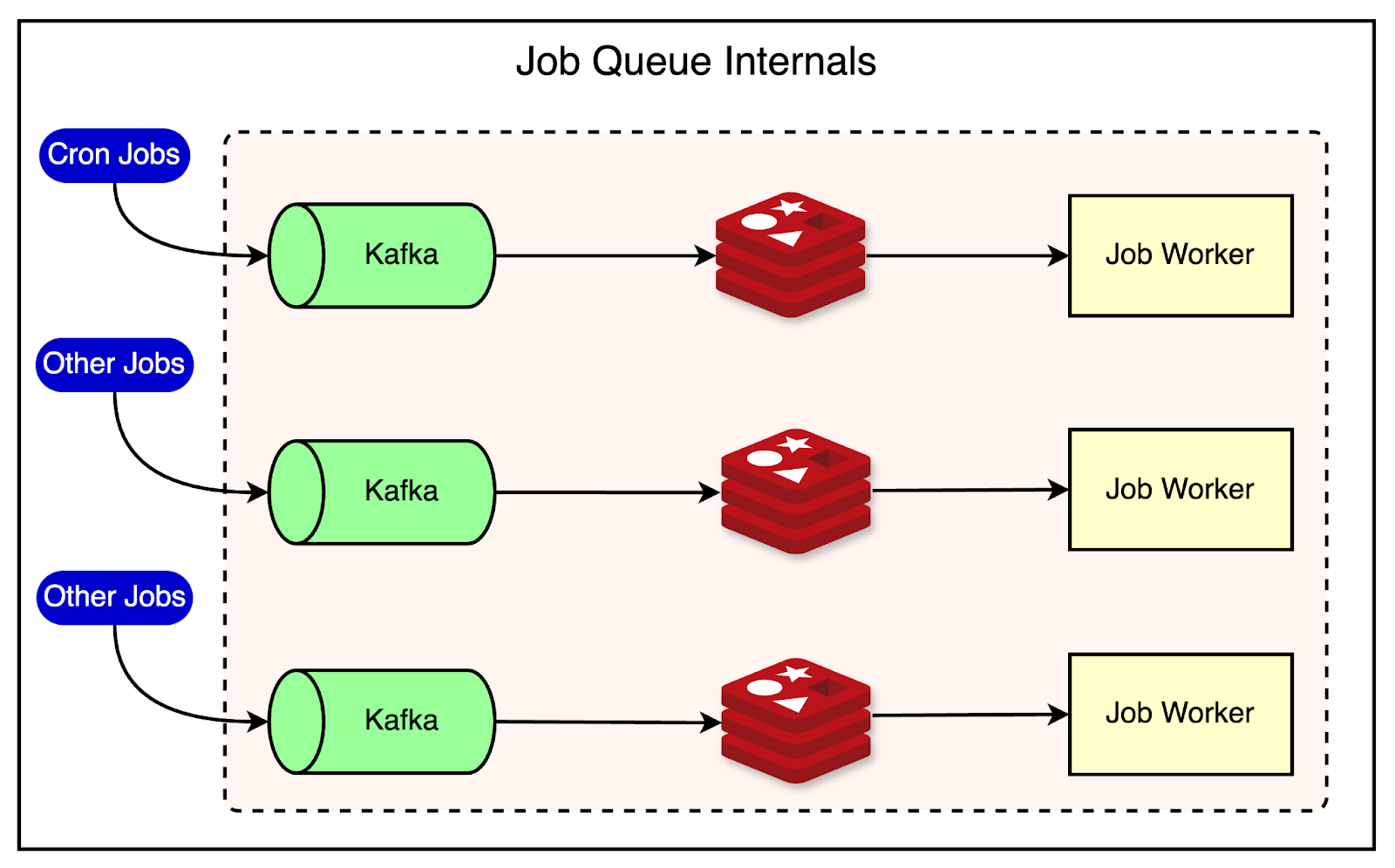
The key components of the job queue architecture are as follows:
Kafka: Jobs are initially stored in Kafka since it provides durable storage. Kafka ensures that jobs are persisted and can be recovered in case of system failures or backups.
Redis: From Kafka, jobs are moved into Redis (an in-memory data store) for short-term storage. Redis allows additional metadata, such as the identity of the worker executing the job, to be stored alongside the job itself. This metadata is important for tracking and managing job execution.
Job Workers: Jobs are dispatched from Redis to job workers, which are nodes that execute the script. Each job worker is capable of running the scripts associated with the jobs it receives.
Slack achieves several important benefits by using the Job Queue:
Offloading compute and memory concerns: The Job Queue is designed to handle a massive amount of work, with a capacity far exceeding the requirements of the cron execution service. Offloading the compute and memory demands of the running scripts helps keep the cron execution service lightweight.
Isolation and performance: The Job Queue lets them keep the jobs isolated on their specific “queues” so that the jobs triggered by the cron execution service are processed smoothly. There is no impact on them due to other jobs in the system.
Reliability and fault tolerance: The Job Queue’s architecture ensures that jobs are stored durably and recoverable in case of failures.
Reduce development and maintenance efforts: This was probably the most important factor since leveraging an existing, battle-tested system like the Job Queue helped Slack reduce the development time required to build the cron execution service.
Vitess Database Table for Job Tracking
To boost the reliability of their cron execution service, Slack also employed a Vitess table for deduplication and job tracking.
Vitess is a database clustering system for horizontal scaling of MySQL. It provides a scalable and highly available solution for managing large-scale data.
A couple of important requirements handled by Vitess are as described as follows:
1 - Deduplication
Within Slack’s original cron system, they used flocks, a Linux utility for managing locking in scripts so that only one copy of a script runs at a time.
While this approach worked fine, there were cases where a script’s execution time exceeded its recurrence intervals, leading to the possibility of two copies running concurrently.
To handle this issue, Slack introduced a Vitess table to handle deduplication.
Here’s how it works:
When a new job is triggered, Slack records its execution as a new row in the Vitess table.
The job’s status is updated as it progresses through the system, with possible states including “enqueued”, “in progress”, and “done”.
Before kicking off a new run of a job, Slack queries the table to check if there are any active instances of the same job already running. This query is made efficient by using an index on the script names.
The below diagram shows some sample data stored in Vitess.

2 - Job Tracking and Monitoring
The Vitess table also helps with job tracking and monitoring since it contains information about the state of each job.
The job tracking functionality is exposed through a simple web page that displays the execution details. Developers can easily look up the state of their script runs and any errors encountered during execution.
Conclusion
One can debate whether using cron was the right decision for Slack when it came to job scheduling.
But it can also be said that organizations that choose the simplest solution for critical functionalities are more likely to grow into organizations of Slack’s size. On the other hand, companies that deploy solutions that try to solve all the problems when they have 0 customers never become that big. The difference is an unrelenting focus on solving the business problem rather than building fancy solutions from the beginning.
Slack’s journey from a single cron box to a sophisticated, distributed cron execution service shows how simple solutions can be used to build large-scale systems.
References:
SPONSOR US
Get your product in front of more than 500,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing hi@bytebytego.com
Like
Comment
Restack
© 2024 ByteByteGo
548 Market Street PMB 72296, San Francisco, CA 94104
Unsubscribe

by "ByteByteGo" <bytebytego@substack.com> - 11:36 - 21 May 2024 -
How things change when employees are seen as artists and athletes
Only McKinsey
Actions to build healthy workplaces Brought to you by Liz Hilton Segel, chief client officer and managing partner, global industry practices, & Homayoun Hatami, managing partner, global client capabilities
—Edited by Belinda Yu, editor, Atlanta
This email contains information about McKinsey's research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this newsletter because you subscribed to the Only McKinsey newsletter, formerly called On Point.
Copyright © 2024 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "Only McKinsey" <publishing@email.mckinsey.com> - 01:20 - 21 May 2024 -
Inventures 2024
Hope you are doing well!
We are following up to confirm if you are interested in acquiring the Visitors/ Attendees List.
Date: 29 - 31 May 2024
Location: Calgary Telus Convention Centre, Calgary, Canada
Counts: 4000
If you are interested in acquiring the list, we can Send you the Discounted cost and additional details.
Each record of the list contains: Contact Name, Email Address, Company Name, URL/Website, Phone No, Title/Designation.
We are looking forward to hearing from you.
Thanks & Regards,
Christy
by "Christy Justin" <christy.justininfotech@gmail.com> - 12:53 - 20 May 2024 -
Challenger in the 2024 Gartner Magic Quadrant for SIEM
Sumo Logic
Gartner Magic Quadrant for SIEM 2024
 Sumo Logic was recognized as 'a Challenger' in the 2024 Gartner® Magic Quadrant™ for Security Information and Event Management. In case you missed it, highlights to the report include:
Sumo Logic was recognized as 'a Challenger' in the 2024 Gartner® Magic Quadrant™ for Security Information and Event Management. In case you missed it, highlights to the report include:
- How SIEM solutions are evaluated for the report
- How Sumo Logic is positioned as 'a Challenger'
Sumo Logic, Aviation House, 125 Kingsway, London WC2B 6NH, UK
© 2024 Sumo Logic, All rights reserved.Unsubscribe 


by "Sumo Logic" <marketing-info@sumologic.com> - 12:31 - 20 May 2024 -
Update: Changes to OF
Dear Friend,
I am Jeffery from Hong-ocean, a freight forwarding company based in China.
You may be interested in the following content:
Limited-Time Shipping Space
Departure port
Destination Port
SZ
LA :O/F: $4600/40HQ
SH
NY :O/F: $5700/40HQ
Validity time is 31th May 2024
If you have any further questions, please feel free to contact me
by "Jeffery" <azemin13@hongoceanforwarding.com> - 12:27 - 20 May 2024 -
Cloudflare’s Trillion-Message Kafka Infrastructure: A Deep Dive
Cloudflare’s Trillion-Message Kafka Infrastructure: A Deep Dive
2024 State of the Java Ecosystem Report by New Relic (Sponsored) Get an in-depth look at one of the most popular programming languages in New Relic's 2024 State of the Java Ecosystem report. You'll get insight to: The most used Java versions in production͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ Forwarded this email? Subscribe here for more2024 State of the Java Ecosystem Report by New Relic (Sponsored)

Get an in-depth look at one of the most popular programming languages in New Relic's 2024 State of the Java Ecosystem report.
You'll get insight to:
The most used Java versions in production
The most popular JDK vendors
The use of compute & memory in Java applications
The most popular java frameworks & libraries for logging, encryption, & databases
The most common types of Java-related questions & requests asked by developers
How much is 1 trillion?
If you were to start counting one number per second, it would take you over 31000 years to reach 1 trillion.
Now, imagine processing 1 trillion messages. This is the incredible milestone Cloudflare’s Kafka infrastructure achieved recently.
Cloudflare’s vision is to build a better Internet by providing a global network. They enable customers to secure and accelerate their websites, APIs, and applications.
However, as Cloudflare’s customer base grew rapidly, they needed to handle massive volumes of data and traffic while maintaining high availability and performance. Both scale and resilience were significant for their Kafka infrastructure.
Cloudflare has been using Kafka in production since 2014. They currently run 14 distinct Kafka clusters with roughly 330 nodes spread over multiple data centers.
In this article, we will explore the challenges solved and lessons learned by Cloudflare’s engineering team in their journey of scaling Kafka.
The Early Days
In the early days of Cloudflare, their architecture was built around a monolithic PHP application.
While this approach worked well initially, it created challenges as their product offerings grew. With numerous teams contributing to the same codebase, the monolithic architecture started to impact Cloudflare's ability to deliver features and updates safely and efficiently.
A couple of major issues were as follows:
There was a tight coupling between services. Any change had a significant impact radius and required a lot of coordination between teams.
It was difficult to implement retry mechanisms to handle scenarios when something went wrong.
To address these challenges, Cloudflare turned to Apache Kafka as a solution for decoupling services and enabling retry mechanisms.
See the diagram below that demonstrates this scenario.
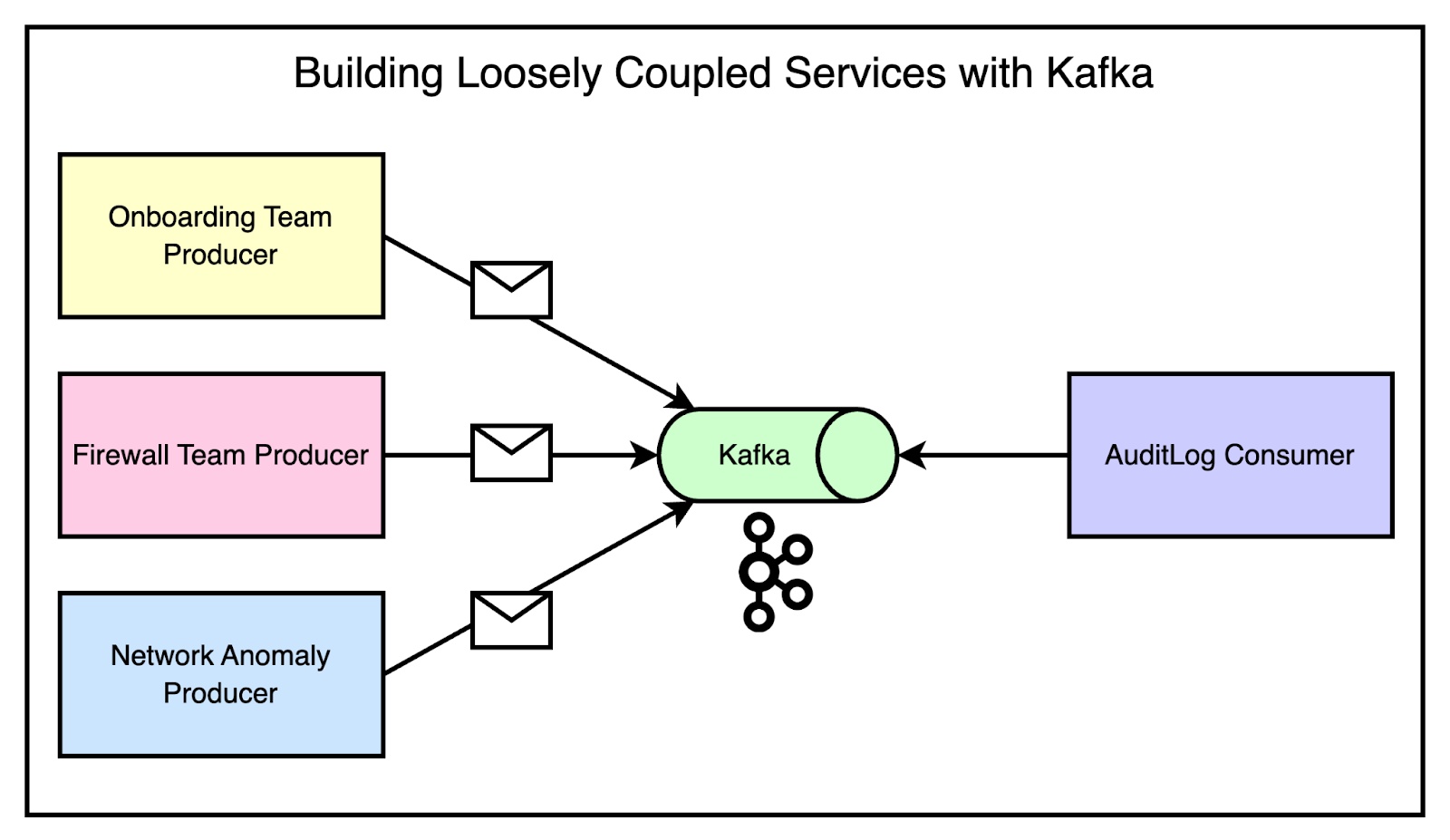
As you can notice, if multiple teams needed to emit messages that the audit log system was interested in, they could simply produce messages for the appropriate topics.
The audit log system could then consume from those topics without any direct coupling to the producing services. Adding a new service that needed to emit audit logs was as simple as producing for the right topics, without requiring any changes to the consuming side.
Kafka, a distributed streaming platform, had already proven its ability to handle massive volumes of data within Cloudflare's infrastructure.
As a first step, they created a message bus cluster on top of Kafka. It became the most general-purpose cluster available to all application teams at Cloudflare.
Onboarding to the cluster was made simple through a pull request process, which automatically set up topics with the desired replication strategy, retention period, and access control lists (ACLs).
The impact of the message bus cluster on loose coupling was evident.
Teams could now emit messages to topics without being aware of the specific services consuming those messages.
Consuming services could listen to relevant topics without needing to know the details of the producing services.
There was greater flexibility and independence among teams.
Standardizing Communication
As Cloudflare’s architecture evolved towards a decoupled and event-driven system, a new challenge emerged: unstructured communication between services.
There was no well-defined contract for message formats, leading to issues.
A common pitfall was the lack of agreement on message structure. For example, a producer might send a JSON blob with certain expected keys, but if the consumer wasn’t aware of this expectation, it could lead to unprocessable messages and tight coupling between services.
To address this challenge, Cloudflare turned to Protocol Buffers (Protobuf) as a solution for enforcing message contracts.
Protobuf, developed by Google, is a language-agnostic data serialization format that allows for defining strict message types and schemas.
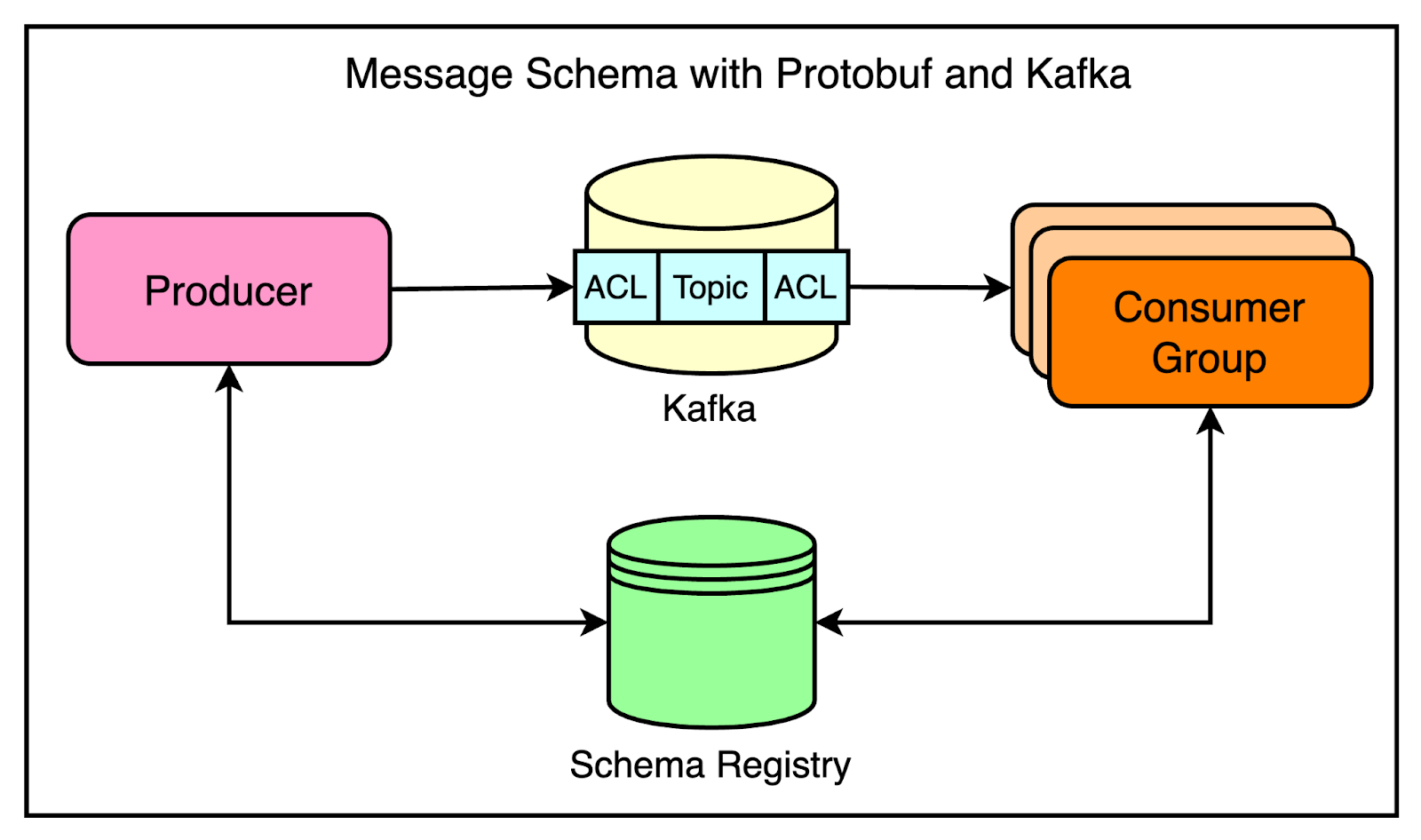
It provided several benefits such as:
Producers and consumers could have a shared understanding of message structures using a schema registry.
Since Protobuf supports versioning and schema evolution, it was possible to make changes to message formats without breaking existing consumers. This enabled both forward and backward compatibility.
Protobuf’s compact binary format results in smaller message sizes compared to JSON, improving efficiency.
To streamline Kafka usage and enforce best practices, Cloudflare developed an internal message bus client library in Go. This library handled the complexities of configuring Kafka producers and consumers. All the best practices and opinionated defaults were baked into this library.
There was one controversial decision at this point.
The message bus client library enforced a one-to-one mapping between Protobuf message types and Kafka topics. This meant that each topic could only contain messages of a single Protobuf type. The idea was to avoid the confusion and complexity of handling multiple message formats within a single topic.
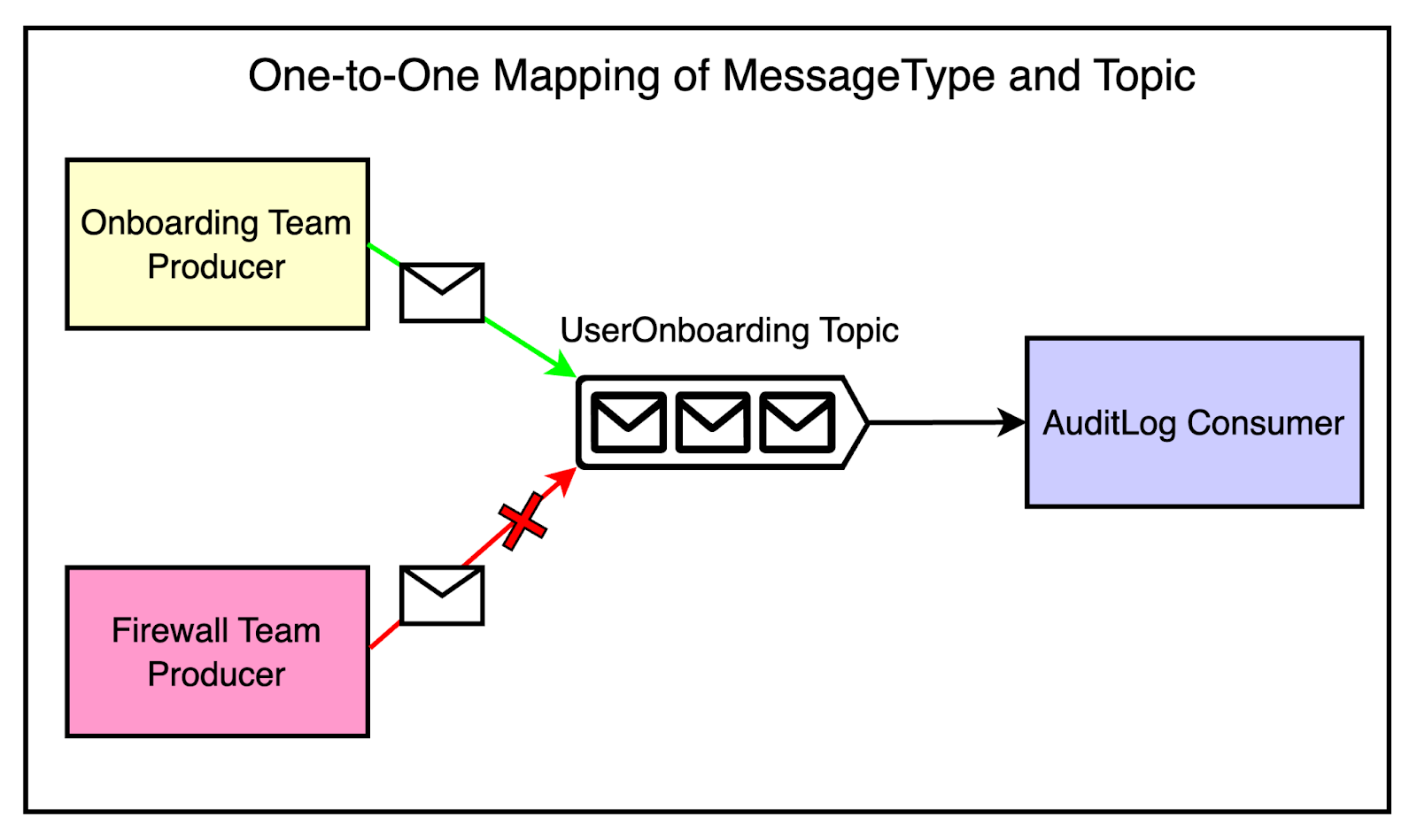
There was a major trade-off to consider.
The strict one-to-one mapping between message types and topics resulted in a larger number of topics, partitions, and replicas while impacting resource utilization. On the other side, it also improved the developer experience, reduced coupling, and increased reliability.
Latest articles
If you’re not a paid subscriber, here’s what you missed.
To receive all the full articles and support ByteByteGo, consider subscribing:
Abstracting Common Patterns
As Cloudflare’s adoption of Kafka grew and more teams started leveraging the message bus client library, a new pattern emerged.
Teams were using Kafka for similar styles of jobs. For example, many teams were building services that read data from one system of record and pushed it to another system, such as Kafka or Cloudflare edge database called Quicksilver. These services often involved similar configurations and boilerplate code.
There were a couple of problems such as:
Duplicated efforts across teams.
Following best practices was harder.
To address this, the application services team developed the connector framework.
Inspired by Kafka connectors, the framework allows engineers to quickly spin up services that can read from one system and push data to another with minimal configuration. The framework abstracts away the common patterns and makes it easy to build data synchronization pipelines.
The diagram below shows a high-level view of the connector approach.
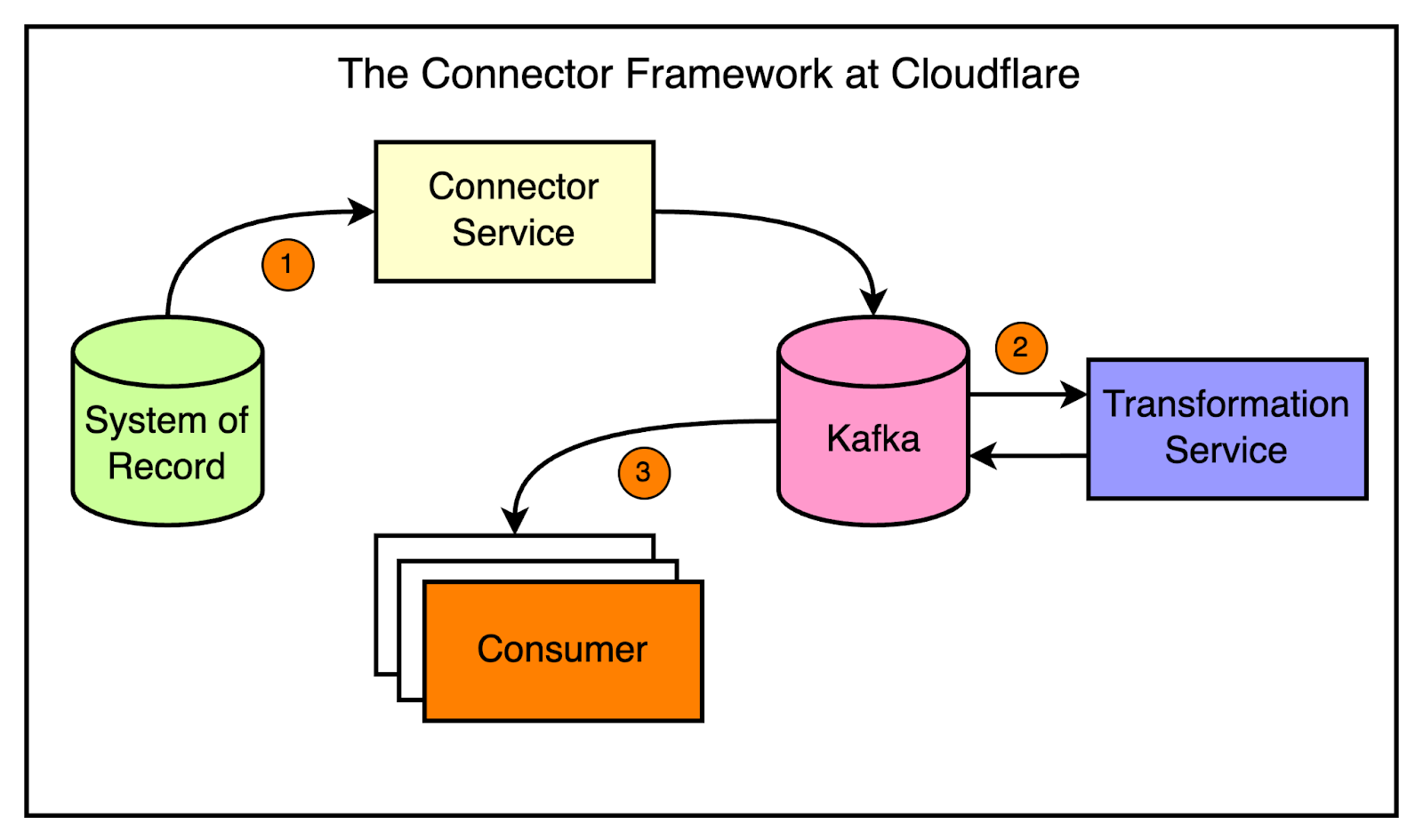
Using the connector framework is straightforward.
The developers use a CLI tool to generate a ready-to-go service by providing just a few parameters.
The generated service includes all the necessary components, such as a reader, a writer, and optional transformations.
To configure the connector, you just need to tweak the environment variables, eliminating the need for code changes in most cases. For example, developers can specify the reader (let’s say, Kafka), the writer (let’s say Quicksilver), and any transformations using environment variables. The framework takes care of the rest.
Here’s a more concrete example of how the connector framework is used in Cloudflare’s communication preferences service.
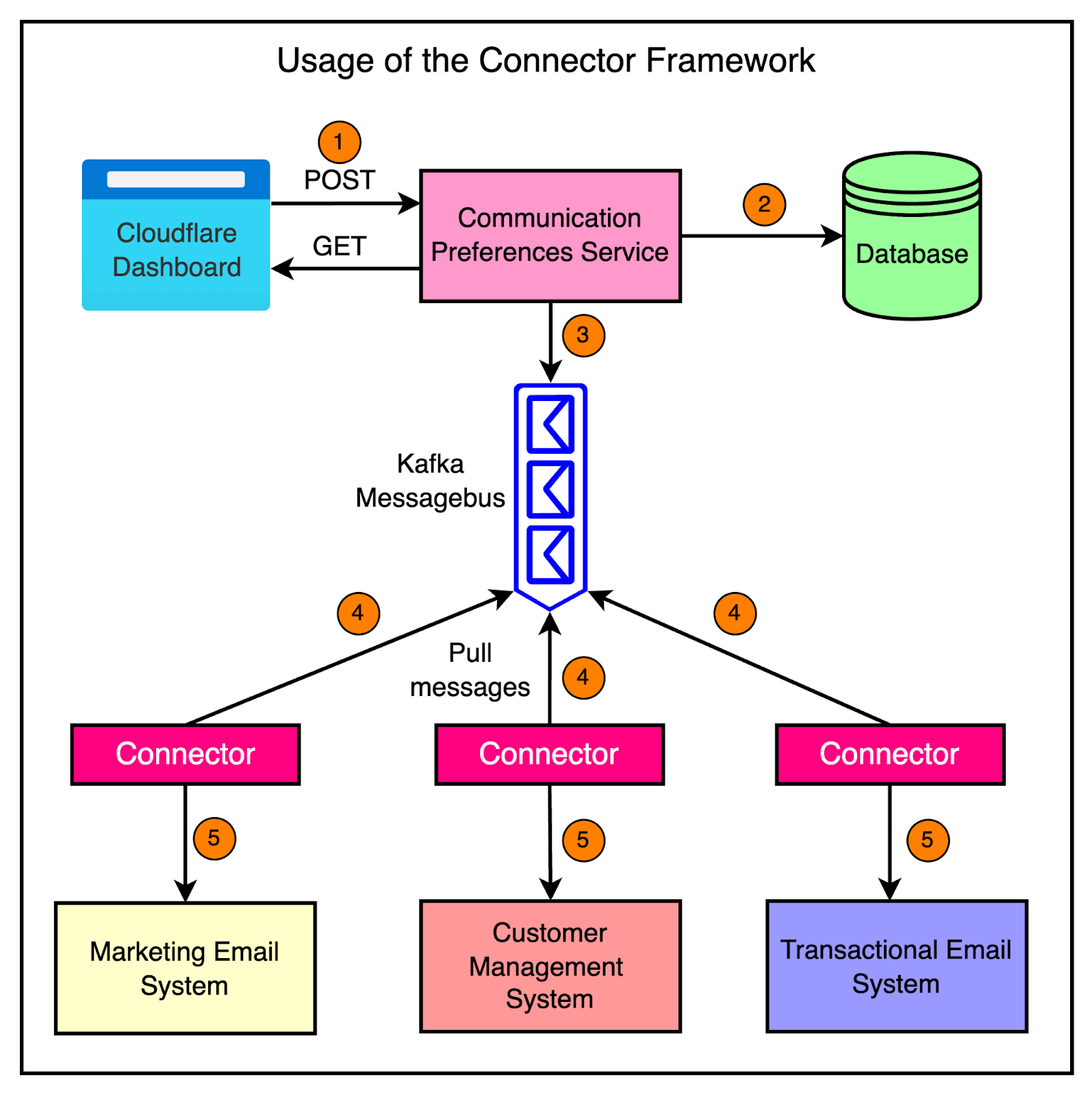
The communication preferences service allows customers to opt out of marketing information through the Cloudflare dashboard. When a customer updates their communication preferences, the service stores the change in its database and emits a message to Kafka.
To keep other systems in sync with the communication preferences, the team leverages the connector framework. They have set up three different connectors that read the communication preference changes from Kafka and synchronize them to three separate systems such as:
Transactional email service
Customer management system
Marketing email system
Scaling Challenges and Solutions
Cloudflare faced multiple scaling challenges with its Kafka adoption. Let’s look at a few of the major ones and how the team solved those challenges.
1 - Visibility
When Cloudflare experienced a surge in internet usage and customer growth during the pandemic, the audit logs system faced a lot of challenges in keeping up with the increased traffic.
Audit logs are a crucial feature for customers to track changes to their resources, such as the deletion of a website or modifications to security settings. As more customers relied on Cloudflare’s services, the audit logs systems struggled to process the growing volume of events on time.
As a first fix, the team invested in a pipeline that pushes audit log events directly into customer data buckets, such as R2 or S3.
See the diagram below:
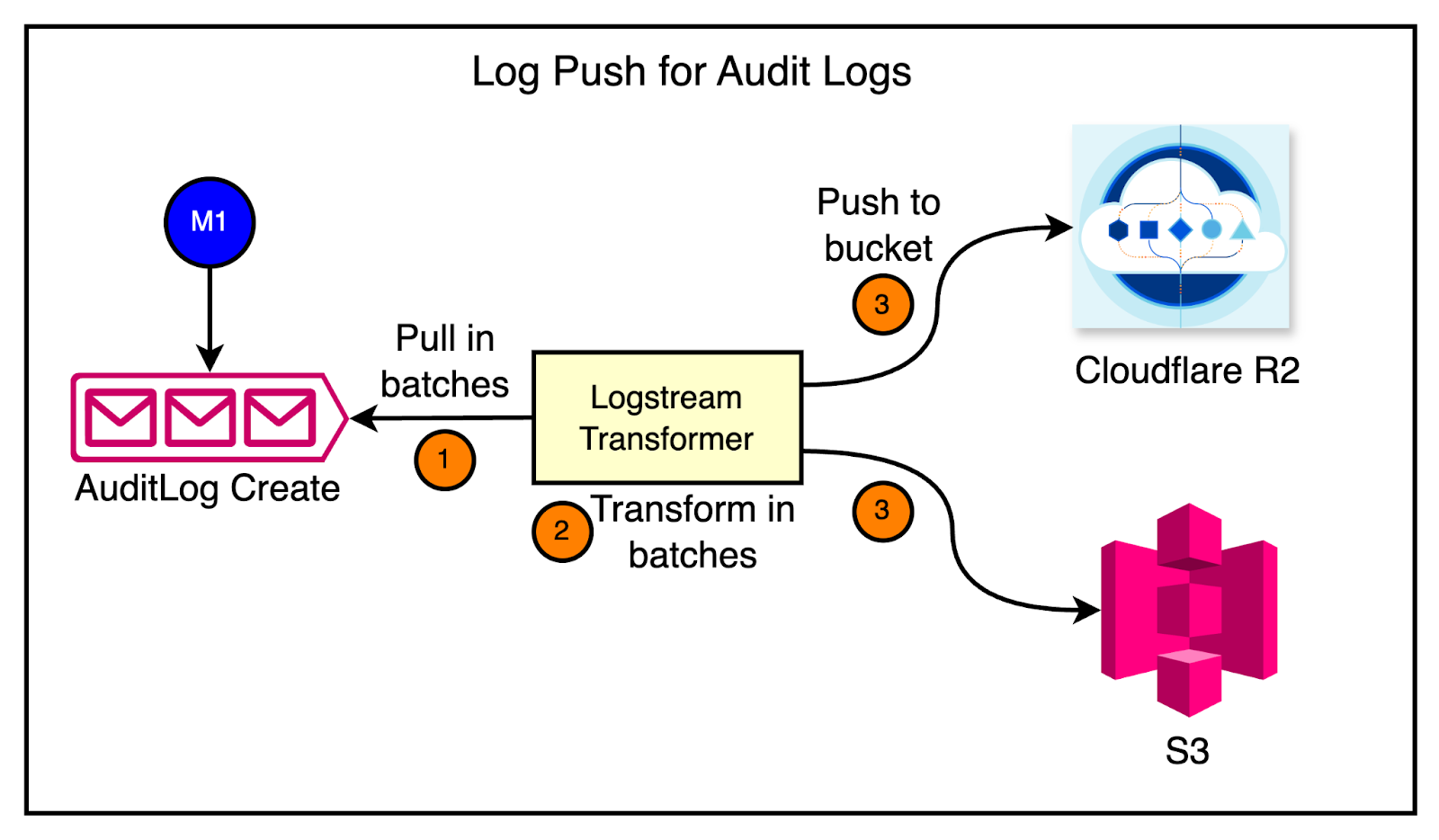
However, when the pipeline was deployed to production, they encountered multiple issues.
The system was accruing logs and failing to clear them fast enough.
Breaches in service level objectives (SLOs).
Unacceptable delays in delivering audit log data to customers.
Initially, the team lacked the necessary tooling in their SDK to understand the root cause of the performance issues. They couldn’t determine whether the bottleneck was in reading from Kafka, performing transformations, or saving data to the database.
To gain visibility, they enhanced their SDK with Prometheus metrics, specifically using histograms to measure the duration of each step in the message processing flow. They also explored OpenTelemetry, a collection of SDKs and APIs that made it easy to collect metrics across services written in different programming languages.
With better visibility provided by Prometheus and OpenTelemetry, the team could identify the longest-running parts of the pipeline. Both reading from Kafka and pushing data to the bucket were slow.
By making targeted improvements, they were able to reduce the lag and ensure that audit logs were delivered to customers on time, even at high throughput rates of 250 to 500 messages per second.
2 - Noisy On-call
One thing leads to another.
Adding metrics to the Kafka SDK provided valuable insights into the health of the cluster and the services using it. However, it also led to a new challenge: a noisy on-call experience.
The teams started receiving frequent alerts related to unhealthy applications unable to reach the Kafka brokers. There were also alerts about lag issues and general Kafka cluster health problems.
The existing alerting pipeline was fairly basic. Prometheus collected the metrics and AlertManager continuously monitored them to page the team via PagerDuty.
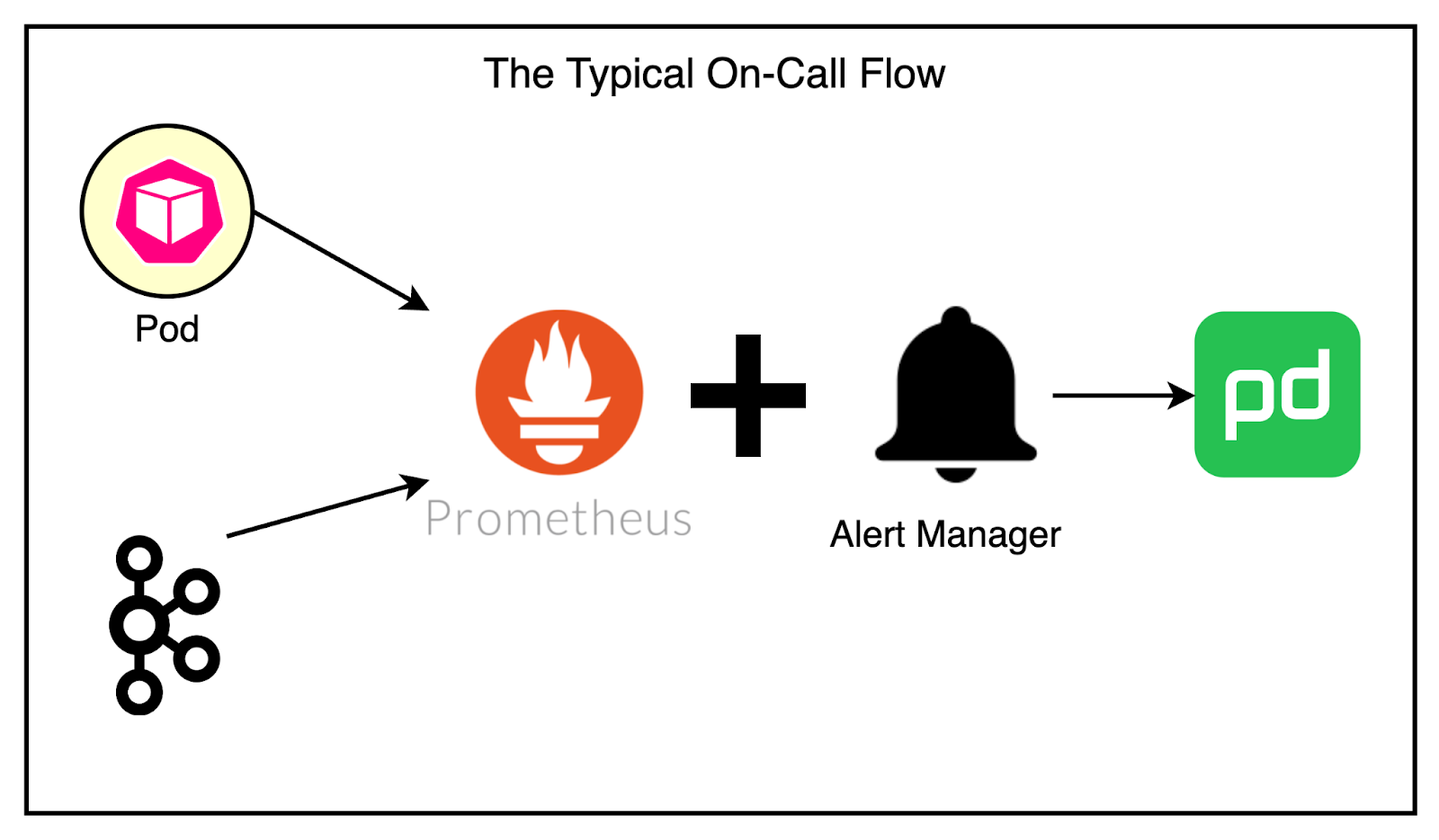
Most problems faced by services concerning Kafka were due to deteriorating network conditions. The common solution was to restart the service manually. However, this often required on-call engineers to wake up during the night to perform manual restarts or scale services up and down, which was far from ideal.
To address this challenge, the team decided to leverage Kubernetes and their existing knowledge to improve the situation. They introduced health checks.
Health checks allow applications to report their readiness to operate, enabling the orchestrator to take appropriate actions when issues arise.
In Kubernetes, there are three types of health checks:
Liveness Probe: They indicate whether a service is ready to run.
Readiness Probe: They determine if a service is prepared to receive HTTP traffic.
Startup Probes: They act as an extended liveness check for slow-starting services.
Kubernetes periodically pings the service at a specific endpoint (example: /health), and the service must respond with a successful status code to be considered healthy.
For Kafka consumers, implementing a readiness probe doesn’t make much sense, as they typically don’t expose an HTTP server. Therefore, the team focused on implementing simple liveness checks that worked as follows:
Perform a basic operation with the Kafka broker, such as listing topics.
If the operation fails, the health check fails, indicating an issue with the service’s ability to communicate with the broker.
The diagram below shows the approach:
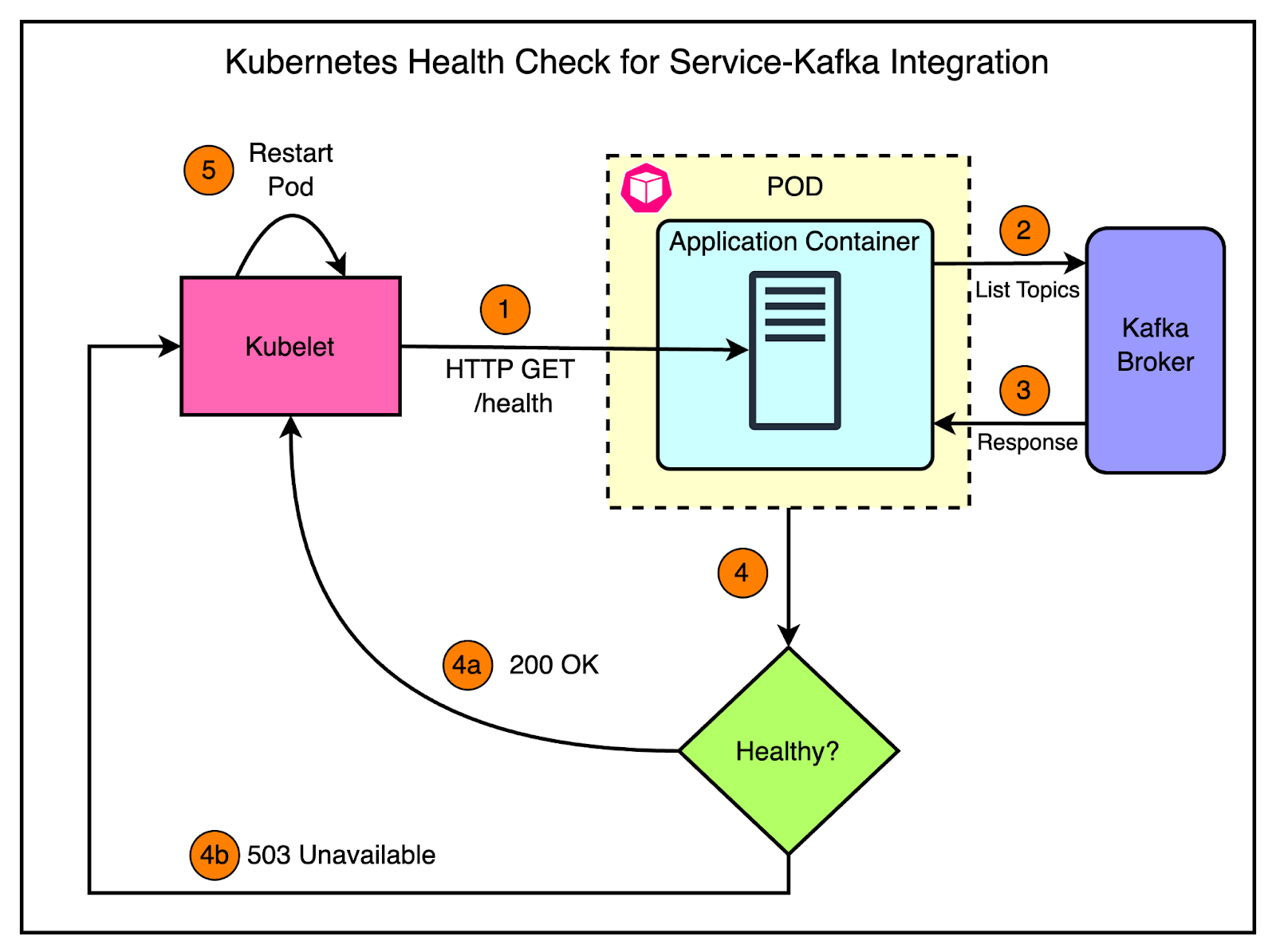
There were still cases where the application appeared healthy but was stuck and unable to produce or consume messages. To handle this, the team implemented smarter health checks for Kafka consumers.
The smart health checks rely on two key concepts:
The current offset represents the last available offset on a partition.
The committed offset is the last offset committed by a specific consumer for that partition.
Here’s what happens during the health check:
The consumer retrieves both offsets.
If it fails to retrieve them, the consumer is considered unhealthy.
If the offsets are successfully retrieved, the consumer compares the last committed offset with the current offset.
If they are the same, no new messages have been appended to the partition, and the consumer is considered healthy.
If the last committed offset hasn’t changed since the previous check, the consumer is likely stuck and needs to be restarted.
Implementing these smart health checks led to improvements in the on-call experience as well as overall customer satisfaction.
3 - Inability to Keep Up
Another challenge that sprang up as Cloudflare’s customer base grew was with the email system.
The email system is responsible for sending transactional emails to customers, such as account verification emails, password reset emails, and billing notifications. These emails were critical for customer engagement and satisfaction, and any delays or failures in delivering them can hurt the user experience.
During traffic spikes, the email system struggled to process the high volume of messages being produced to Kafka.
The system was designed to consume messages one at a time, process them, and send the corresponding emails. However, as the production rate increased, the email system fell behind, creating a growing backlog of messages and increased lag.
One thing was clear to the engineering team at Cloudflare. The existing architecture wasn’t scalable enough to handle the increasing production rates.
Therefore, they introduced batch consumption to optimize the email system’s throughput.
Batch consumption is a technique where instead of processing messages one at a time, the consumer retrieves a batch of messages from Kafka and processes them together. This approach has several advantages, particularly in scenarios with high production rates.
The diagram below shows the batching approach.
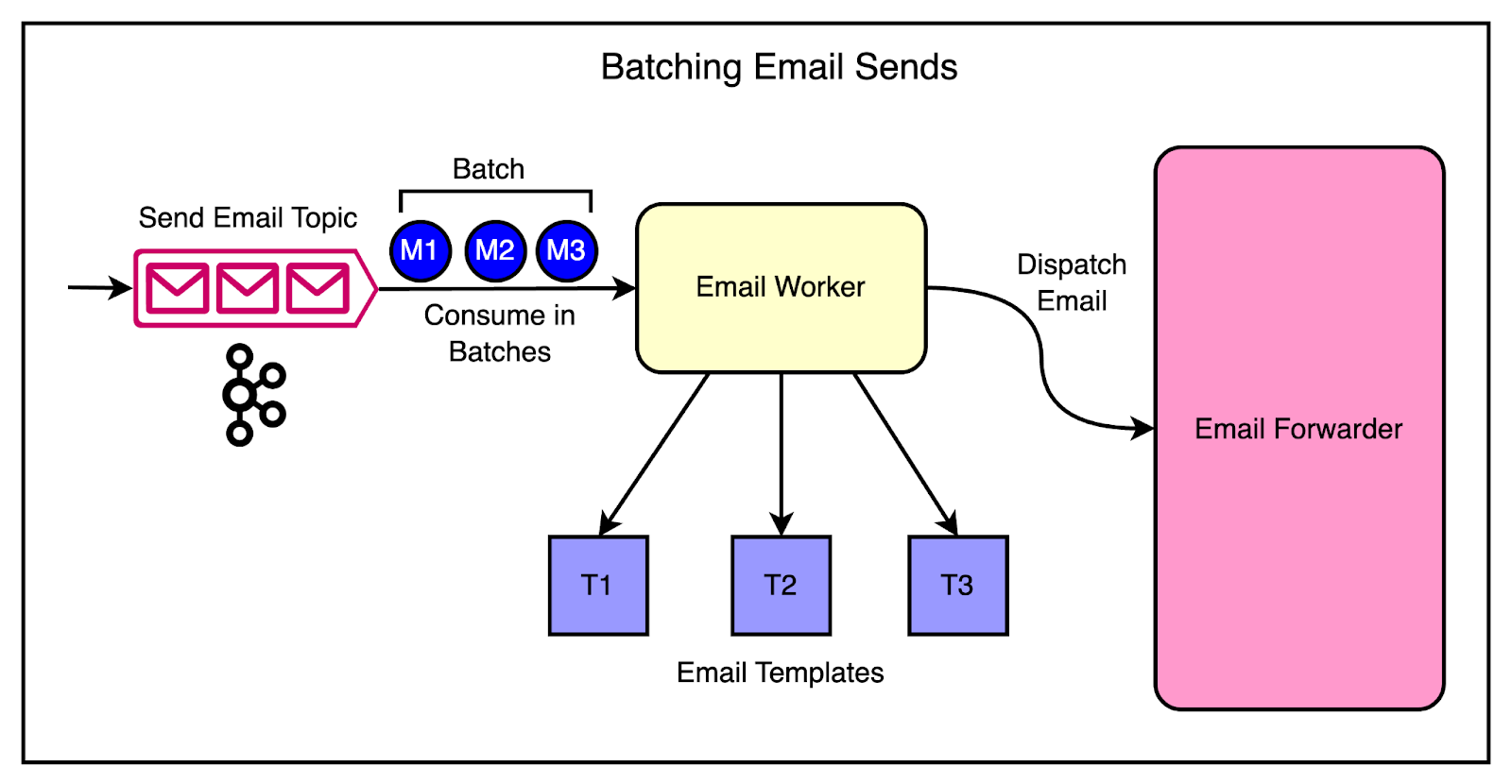
The changes made were as follows:
The Kafka consumer was modified to retrieve a configurable number of messages in each poll.
They updated the email-sending logic to process the batch of messages. Techniques like bulk database inserts and parallel email dispatching were used.
Batch consuming with emails was soon put to the test during a major product launch that generated a surge in sign-ups and account activations.
This resulted in a massive increase in the number of account verification emails that had to be sent. However, the email system was able to handle the increased load efficiently.
Conclusion
Cloudflare’s journey of scaling Kafka to handle 1 trillion messages is remarkable.
From the early days of their monolithic architecture to the development of sophisticated abstractions and tools, we’ve seen how Cloudflare tackled multiple challenges across coupling, unstructured communication, and common usage patterns.
Along the way, we’ve also learned valuable lessons that can be applied to any organization. Here are a few of them:
It’s important to strike a balance between configuration and simplicity. While flexibility is necessary for diverse use cases, it’s equally important to standardize and enforce best practices.
Visibility is the key in distributed systems. If you can’t see what’s happening in a certain part of your application, it becomes hard to remove bottlenecks.
Clear and well-defined contracts between producers and consumers are essential for building loosely coupled systems that can evolve independently.
Sharing knowledge and best practices across the organization helps streamline the adoption process and creates opportunities for improvement.
References:
SPONSOR US
Get your product in front of more than 500,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing hi@bytebytego.com
© 2024 ByteByteGo
548 Market Street PMB 72296, San Francisco, CA 94104
Unsubscribe
by "ByteByteGo" <bytebytego@substack.com> - 11:37 - 20 May 2024 -
A leader’s guide to understanding quantum technologies
Prepare to reboot Brought to you by Liz Hilton Segel, chief client officer and managing partner, global industry practices, & Homayoun Hatami, managing partner, global client capabilities
Back in 2020, McKinsey senior partners Alexandre Ménard and Mark Patel and colleagues suggested that given quantum computing’s immense potential, “every business leader should have a basic understanding of how the technology works.” Today, quantum technologies are still far from being everyday fixtures in the workplace, but innovative companies in so-called first-wave industries, such as pharmaceuticals, finance, transportation, and energy, have already taken strategic steps into quantum computing. Here are some ways to ensure that your organization doesn’t get left behind.
While traditional computers are built on bits—a unit of information that can store either a zero or a one—quantum computers are constructed on quantum bits, or qubits, which can store zeros and ones at the same time. This feature, called superposition, makes quantum computers exponentially more powerful than classical computers, allowing them to work faster, make many different calculations simultaneously, and deliver a range of possible answers to previously intractable problems. Developing quantum computers is an uphill task: qubits are volatile and prone to error, and powering a quantum computer large enough to connect the millions of qubits needed to operate at scale may be cost prohibitive. “But leaders in every sector can—and should—prepare for the inevitable quantum advancements of the coming years,” note McKinsey experts. “Quantum computing alone could account for nearly $1.3 trillion in value by 2035.”
That approach could enable organizations to use quantum technologies more effectively and to solve a wider range of problems, according to McKinsey experts. “Different technologies can fulfill different functions in the computer and play to each other’s strengths while mitigating downsides,” they suggest. For example, hardware that combines photonic networks with neutral atoms can be much faster at computation than either technology alone. Technologies related to quantum computing, such as quantum sensing and quantum communication, could be available much earlier and transform industries such as finance, pharmaceuticals, medical imaging, and environmental monitoring.
“Quantum is not the end goal,” says physicist Théau Peronnin in a conversation with McKinsey partner Henning Soller. “The end goal is to change the scale at which we can compute, which can drive better engineering and thereby increase value creation.” Peronnin, CEO and cofounder of Alice & Bob, a company of physicists and engineers working to build a universal fault-tolerant quantum computer, believes that it’s not too early for businesses to prepare for quantum computing. “Quantum is all about first-mover advantage,” he says. For example, in the automotive industry, the first company to leverage new hardware may be the first to gain intellectual property rights to novel battery design. But it can take several years to ramp up the resources and talent necessary to seize the opportunity when it arrives. “It’s important not to get lost in proofs of concept,” cautions Peronnin. “Companies should start by doing value calculations and prioritizing use cases.”
Can a cat be both alive and dead at the same time? Yes, until it is observed, according to the physicist Erwin Schrödinger’s famous thought experiment in 1935. Cat qubits, named after this paradox, allow for error correction by suppressing one type of error out of two that could affect quantum computing. For organizations that are thinking about implementing the technology, that means getting at least one step closer to making it commercially viable. “The challenge of bringing quantum computing to market is massive—comparable to the human genome project or landing on the moon,” note McKinsey senior partner Rodney Zemmel and colleagues. “But with enough money, scientists and engineers will eventually be able to overcome the challenges of building a quantum computer—and unlock significant market opportunities.”
Lead with quantum technology.
— Edited by Rama Ramaswami, senior editor, New York
Share these insights
Did you enjoy this newsletter? Forward it to colleagues and friends so they can subscribe too. Was this issue forwarded to you? Sign up for it and sample our 40+ other free email subscriptions here.
This email contains information about McKinsey’s research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this email because you subscribed to the Leading Off newsletter.
Copyright © 2024 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "McKinsey Leading Off" <publishing@email.mckinsey.com> - 04:42 - 20 May 2024 -
CEOs, could your relationship with the board use a tune-up?
Only McKinsey
3 tips for better communication Brought to you by Liz Hilton Segel, chief client officer and managing partner, global industry practices, & Homayoun Hatami, managing partner, global client capabilities
•
Better communication. CEOs need to use every resource to propel their growth agenda in the face of unprecedented change. The board of directors is an important partner. Yet many CEOs fail to communicate with their board in a way that makes the most of the relationship, McKinsey senior partner Celia Huber and coauthors say. Only 30% of board members report that their processes―including sharing information and aligning on tasks―are effective, our 2019 survey of more than 1,000 board directors and 250 C-suite leaders found.
—Edited by Belinda Yu, editor, Atlanta
This email contains information about McKinsey's research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this newsletter because you subscribed to the Only McKinsey newsletter, formerly called On Point.
Copyright © 2024 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "Only McKinsey" <publishing@email.mckinsey.com> - 11:06 - 19 May 2024 -
The week in charts
The Week in Charts
CO2 removal, productivity in emerging economies, and more Share these insights
Did you enjoy this newsletter? Forward it to colleagues and friends so they can subscribe too. Was this issue forwarded to you? Sign up for it and sample our 40+ other free email subscriptions here.
This email contains information about McKinsey's research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this email because you subscribed to The Week in Charts newsletter.
Copyright © 2024 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "McKinsey Week in Charts" <publishing@email.mckinsey.com> - 03:08 - 18 May 2024 -
Three tips on how to become more strategic
Flex your strategy muscle Brought to you by Liz Hilton Segel, chief client officer and managing partner, global industry practices, & Homayoun Hatami, managing partner, global client capabilities
Creating a strategy dream team
How many members of your top team are involved in shaping your company’s strategic direction? If you needed fewer fingers than you have on one hand to answer that question, your team may need to be reshuffled. These days, disruption wears many faces, so the more senior leaders an organization has flexing their collective strategic muscles the better.
The good news is any executive can become more strategic. To start, make sure you really know the strategy of your specific industry. Generic strategy frameworks are just that: generic. When forming an appropriately nuanced strategy, context is everything. Next, know your disrupter. Bolstering your top team with a diverse range of perspectives and expertise can help ensure you’re sufficiently covering—and outthinking—the competition. Finally, innovate on ways to communicate your strategy so that everyone has a firm grasp on its direction.
Strategy can no longer be the purview of one person. An endless array of competing forces demands a dynamic strategy team—one where each person is firing on all cylinders. To help craft your strategy dream team, read Michael Birshan and Jayanti Kar’s 2012 McKinsey Quarterly classic, “Becoming more strategic: Three tips for any executive.”Enhance your strategic capabilities 


Share these insights
Did you enjoy this newsletter? Forward it to colleagues and friends so they can subscribe too. Was this issue forwarded to you? Sign up for it and sample our 40+ other free email subscriptions here.
This email contains information about McKinsey's research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this email because you subscribed to our McKinsey Classics newsletter.
Copyright © 2024 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "McKinsey Classics" <publishing@email.mckinsey.com> - 12:44 - 18 May 2024 -
EP112: What is a deadlock?
EP112: What is a deadlock?
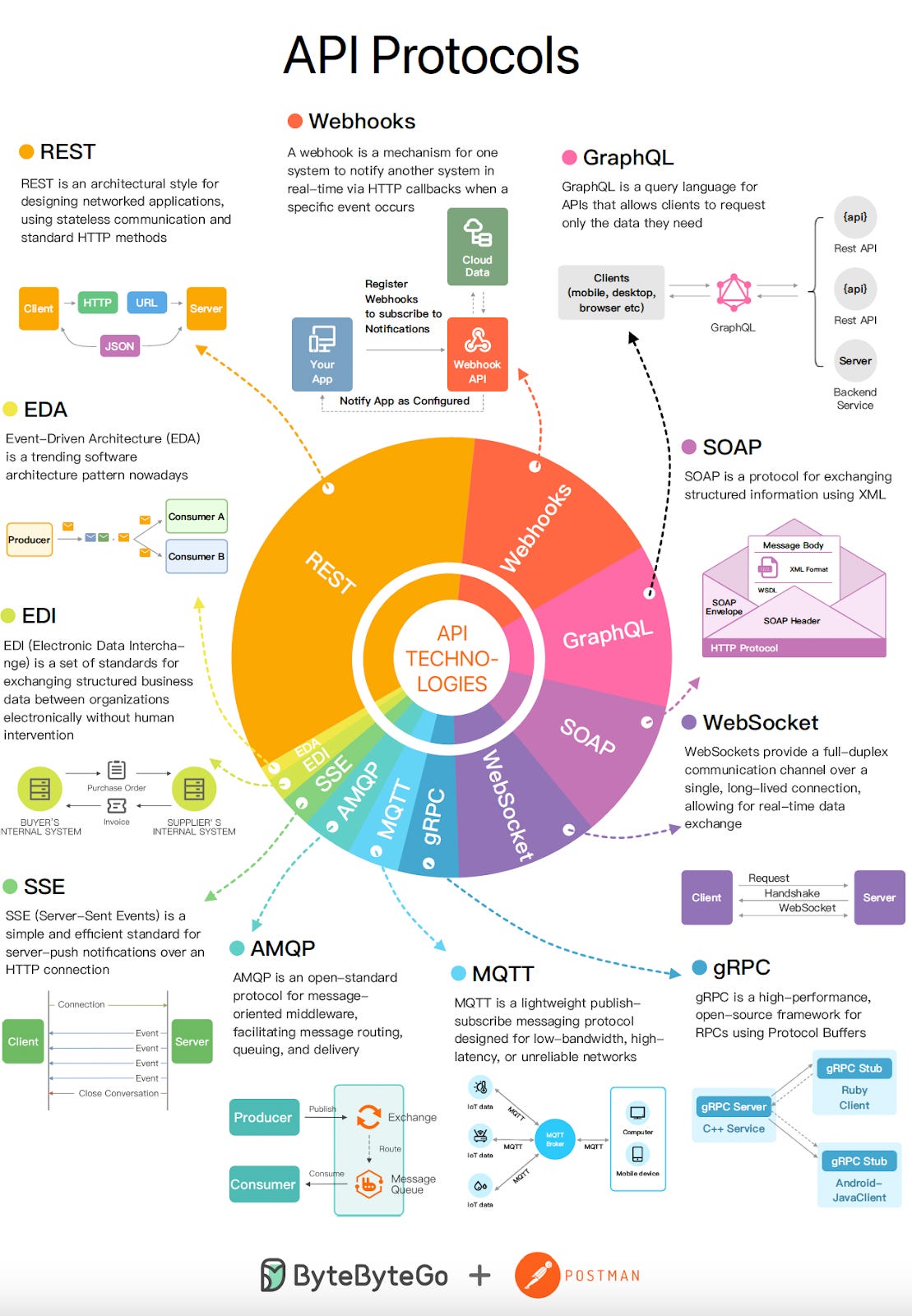
This week’s system design refresher: Top 9 Most Popular API Protocols (Youtube video) What is a deadlock? What’s the difference between Session-based authentication and JWTs? Top 6 ElasticSearch Use Cases Top 9 Cases Behind 100% CPU Usage SPONSOR US͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ Forwarded this email? Subscribe here for moreThis week’s system design refresher:
Top 9 Most Popular API Protocols (Youtube video)
What is a deadlock?
What’s the difference between Session-based authentication and JWTs?
Top 6 ElasticSearch Use Cases
Top 9 Cases Behind 100% CPU Usage
SPONSOR US
[Complimentary Download] Gartner Market Guide: Software Engineering Intelligence (SEI) Platforms (Sponsored)

Engineering teams are rapidly adopting Software Engineering Intelligence (SEI) Platforms to improve productivity and value delivery. According to Gartner’s recent Market Guide, use of SEI platforms by engineering organizations will rise to 50% by 2027, compared to 5% in 2024. LinearB was recognized by Gartner as a representative vendor, so we’re offering ByteByteGo readers a complimentary copy.
Learn how you can unlock the transformative potential of SEI platforms by leveraging key features like:
Extensive data from DevOps tools for critical metrics and insights.
Customizable dashboards that highlight pivotal trends and inform strategic decisions.
Insights into KPIs that showcase your team's achievements.
Top 9 Most Popular API Protocols
What is a deadlock?
A deadlock occurs when two or more transactions are waiting for each other to release locks on resources they need to continue processing. This results in a situation where neither transaction can proceed, and they end up waiting indefinitely.

Coffman Conditions
The Coffman conditions, named after Edward G. Coffman, Jr., who first outlined them in 1971, describe four necessary conditions that must be present simultaneously for a deadlock to occur:
- Mutual Exclusion
- Hold and Wait
- No Preemption
- Circular WaitDeadlock Prevention
- Resource ordering: impose a total ordering of all resource types, and require that each process requests resources in a strictly increasing order.
- Timeouts: A process that holds resources for too long can be rolled back.
- Banker’s Algorithm: A deadlock avoidance algorithm that simulates the allocation of resources to processes and helps in deciding whether it is safe to grant a resource request based on the future availability of resources, thus avoiding unsafe states.Deadlock Recovery
- Selecting a victim: Most modern Database Management Systems (DBMS) and Operating Systems implement sophisticated algorithms for detecting deadlocks and selecting victims, often allowing customization of the victim selection criteria via configuration settings. The selection can be based on resource utilization, transaction priority, cost of rollback etc.
- Rollback: The database may roll back the entire transaction or just enough of it to break the deadlock. Rolled-back transactions can be restarted automatically by the database management system.
Over to you: have you solved any tricky deadlock issues?
Latest articles
If you’re not a paid subscriber, here’s what you missed.
To receive all the full articles and support ByteByteGo, consider subscribing:
What’s the difference between Session-based authentication and JWTs?

Here’s a simple breakdown for both approaches:
Session-Based Authentication
In this approach, you store the session information in a database or session store and hand over a session ID to the user.
Think of it like a passenger getting just the Ticket ID of their flight while all other details are stored in the airline’s database.
Here’s how it works:The user makes a login request and the frontend app sends the request to the backend server.
The backend creates a session using a secret key and stores the data in session storage.
The server sends a cookie back to the client with the unique session ID.
The user makes a new request and the browser sends the session ID along with the request.
The server authenticates the user using the session ID.
JWT-Based Authentication
In the JWT-based approach, you don’t store the session information in the session store.
The entire information is available within the token.
Think of it like getting the flight ticket along with all the details available on the ticket but encoded.
Here’s how it works:The user makes a login request and it goes to the backend server.
The server verifies the credentials and issues a JWT. The JWT is signed using a private key and no session storage is involved.
The JWT is passed to the client, either as a cookie or in the response body. Both approaches have their pros and cons but we’ve gone with the cookie approach.
For every subsequent request, the browser sends the cookie with the JWT.
The server verifies the JWT using the secret private key and extracts the user info.
Top 6 ElasticSearch Use Cases
Elasticsearch is widely used for its powerful and versatile search capabilities. The diagram below shows the top 6 use cases:

Full-Text Search
Elasticsearch excels in full-text search scenarios due to its robust, scalable, and fast search capabilities. It allows users to perform complex queries with near real-time responses.Real-Time Analytics
Elasticsearch's ability to perform analytics in real-time makes it suitable for dashboards that track live data, such as user activity, transactions, or sensor outputs.Machine Learning
With the addition of the machine learning feature in X-Pack, Elasticsearch can automatically detect anomalies, patterns, and trends in the data.Geo-Data Applications
Elasticsearch supports geo-data through geospatial indexing and searching capabilities. This is useful for applications that need to manage and visualize geographical information, such as mapping and location-based services.Log and Event Data Analysis
Organizations use Elasticsearch to aggregate, monitor, and analyze logs and event data from various sources. It's a key component of the ELK stack (Elasticsearch, Logstash, Kibana), which is popular for managing system and application logs to identify issues and monitor system health.Security Information and Event Management (SIEM)
Elasticsearch can be used as a tool for SIEM, helping organizations to analyze security events in real time.
Over to you: What did we miss?
Top 9 Cases Behind 100% CPU Usage
The diagram below shows common culprits that can lead to 100% CPU usage. Understanding these can help in diagnosing problems and improving system efficiency.

Infinite Loops
Background Processes
High Traffic Volume
Resource-Intensive Applications
Insufficient Memory
Concurrent Processes
Busy Waiting
Regular Expression Matching
Malware and Viruses
Over to you: Did we miss anything important?
SPONSOR US
Get your product in front of more than 500,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing hi@bytebytego.com
© 2024 ByteByteGo
548 Market Street PMB 72296, San Francisco, CA 94104
Unsubscribe
by "ByteByteGo" <bytebytego@substack.com> - 11:35 - 18 May 2024 -
Reminder: Join us for a McKinsey Live webinar on productivity through tech investment
Register now New from McKinsey & Company

Productivity is the foundation of prosperity. We need productivity growth now more than ever. Today, there is more at stake: new seemingly limitless opportunities from technologies like generative AI, but also the need to address rising inflation, fund the energy transition, and raise living standards as the population ages.
On Monday, May 20 at 10:30 a.m. EDT / 4:30 p.m. CET, join us for a McKinsey Live session where we explore the most important features of productivity growth across countries and sectors, why it slowed, and the critical role of investment in accelerating it.
Olivia White, a senior partner and director of the McKinsey Global Institute, will share insights from MGI’s latest research. She will be joined by Rodney Zemmel, a senior partner and global leader of McKinsey Digital, who will discuss how leaders can rewire their organizations to make the most of technology investments and contribute to a new wave of productivity growth.This email contains information about McKinsey's research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this email because you subscribed to our McKinsey Global Institute alert list.
Copyright © 2024 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "McKinsey & Company" <publishing@email.mckinsey.com> - 02:43 - 17 May 2024 -
Consumer Electronics Show - CES 2024 (Post Show)
Hi,
The verified & updated contacts attendees list of Consumer Electronics Show - CES 2024 is available with us.
Attendees are: - Analyst, Content Developer, Distributor, Buyer, Engineer, Manager/Store Manager/Product Manager, Manufacturer’s Representative, Service Technician, Systems Installer/Integrator & More.
List includes: - Contact Name, Email address, Phone Number, Mailing Address, Job Title etc.
If you are interested in the list, I shall share the counts & cost details.
Best Regards,
Terry Baker - Marketing and Event Coordinator
If you don’t want to receive further emails please revert with “Take Out” in the subject
by terry.baker@datasmining.com - 01:18 - 17 May 2024 -
Thrive or dive: How workers respond to gen AI
The Shortlist
Four new insights Curated by Liz Hilton Segel, chief client officer and managing partner, global industry practices, & Homayoun Hatami, managing partner, global client capabilities
You’ve bought your AI chips, or maybe you’ve upgraded your cloud contract. You’ve started to rethink your IT stack. But is that enough? In our experience, it’s never just about the tech. To extract full value from today’s technologies, companies need much more than hardware and software. They need new ways of thinking about talent, growth, leadership, and change management. This edition of the CEO Shortlist highlights several of the elements needed to get the most out of generative AI and quantum computing. We hope you enjoy the read.
—Liz and Homayoun
Gen AI wealth is built on workplace health. The savviest among us are already using gen AI to knock out busywork. So why are heavy gen AI users increasingly likely to leave their jobs due to burnout? It’s likely because the work gen AI can’t do takes more mental energy to complete—and the elite employees who do it need time to recharge to keep performing at their best. Healthy working cultures will matter even more in the future than they have in the past.
Keep busy with five actions to maximize employee well-being in “To defend against disruption, build a thriving workforce,” a new article by Aaron De Smet, Brooke Weddle, and colleagues.Put away your magic wand. Organizational growth doesn’t happen just like that. Executives at the helm of high-growth organizations actively choose growth every day—especially amid uncertainty. We’ve seen a much steeper growth curve in companies that made bold bets during downturns, including on new technologies, than in those that played it safe.
But don’t mistake bold for reckless. Learn to walk the line with “Six strategies for growth outperformance,” the latest episode of McKinsey’s Inside the Strategy Room podcast, featuring Jill Zucker and colleagues.The quantum advantage. No, it’s not the latest Bond movie. It’s what the world’s leading companies are pursuing through investment and research in quantum computing, sensing, and communication. Our third annual Quantum Technology Monitor reviews the burgeoning opportunities, the flow of new investments, and the startling technological advances.
Leap into the Monitor’s key takeaways with “Steady progress in approaching the quantum advantage,” by Rodney Zemmel and colleagues.Time is money. When it comes to new technologies such as gen AI, speed is a strategy. But whoever invented time isn’t making more of it, as business leaders know well. Our new research reveals six ways that CFOs and other top leaders find the time to not just do their core jobs but also serve as thought partners to CEOs on topics well beyond finance, including new technologies.
Set your watch to “Six ways CFOs find the time to unlock their full potential,” by Ankur Agrawal and colleagues.We hope you find these ideas inspiring and helpful. See you next time with four more McKinsey ideas for the CEO and others in the C-suite.
Share these insights
This email contains information about McKinsey’s research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this email because you subscribed to The CEO Shortlist newsletter.
Copyright © 2024 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "McKinsey CEO Shortlist" <publishing@email.mckinsey.com> - 04:07 - 17 May 2024 -
Google 1st page?
Hi,
I found your detail on Google.com and I have looked at your website but noticed that you aren't at the top of Google search.
I can fix that for you and make your company more profitable.
If you are interested, let me know, and I will send you the cost and details about our company. Sincerely,
Geeta Jaiswal,SEO Professional (India)
by "Geeta Jaiswal" <anjalisinghwebsolution@outlook.com> - 03:32 - 17 May 2024 -
How might featuring more Asians and Pacific Islanders advantage Hollywood?
Only McKinsey
API consumers’ untapped potential Brought to you by Liz Hilton Segel, chief client officer and managing partner, global industry practices, & Homayoun Hatami, managing partner, global client capabilities
•
Surge in API on-screen presence. As the entertainment industry undergoes a transformation, studios have the chance to adopt a more inclusive casting approach and broaden their content to appeal to the Asian and Pacific Islander (API) community. While there’s been a remarkable upswing in API on-screen representation in US-distributed films, there’s a long way to go for API on- and off-screen professionals to reach parity with their peers. Moreover, US API consumers still feel their stories are not authentically portrayed. They could be convinced to spend more on entertainment if this pain point is addressed, note McKinsey senior partner Kabir Ahuja and coauthors.
—Edited by Querida Anderson, senior editor, New York
This email contains information about McKinsey's research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this newsletter because you subscribed to the Only McKinsey newsletter, formerly called On Point.
Copyright © 2024 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "Only McKinsey" <publishing@email.mckinsey.com> - 01:47 - 17 May 2024 -
Wide Range of GPS tracking software products that are easy to white-label and customize for your business needs
Wide Range of GPS tracking software products that are easy to white-label and customize for your business needs
Telematics solutions that will supercharge your business
Telematics Solutions We Offer
.png?width=1200&upscale=true&name=Frame%201%20(2).png)


Uffizio Technologies Pvt. Ltd., 4th Floor, Metropolis, Opp. S.T Workshop, Valsad, Gujarat, 396001, India






by "Sunny Thakur" <sunny.thakur@uffizio.com> - 08:02 - 16 May 2024 -
A Crash Course in GraphQL
A Crash Course in GraphQL
The complexity of software applications has grown by leaps and bounds over the years. This has led to a rise in the number of interfaces between various systems, resulting in an ever-growing API footprint. While APIs have revolutionized the connectivity between systems, the explosion of integrations between clients and servers often leads to maintenance problems. Even minor backend changes take more implementation time since developers must analyze and test more. Despite all the effort, there are still high chances that issues creep into the application.͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ Forwarded this email? Subscribe here for moreLatest articles
If you’re not a subscriber, here’s what you missed this month.
To receive all the full articles and support ByteByteGo, consider subscribing:
The complexity of software applications has grown by leaps and bounds over the years.
This has led to a rise in the number of interfaces between various systems, resulting in an ever-growing API footprint.
While APIs have revolutionized the connectivity between systems, the explosion of integrations between clients and servers often leads to maintenance problems. Even minor backend changes take more implementation time since developers must analyze and test more. Despite all the effort, there are still high chances that issues creep into the application.
Refactoring the application interfaces is one way to address growing maintenance costs. However, this is costly, and there’s no guarantee that we won’t encounter similar issues as the system evolves.
What’s the solution to this problem?
GraphQL is a tool that brings a major change in how clients and servers interact. While it’s not a silver bullet, it can be a sweet spot between a complete application overhaul and doing absolutely nothing
In this issue, we’ll explore GraphQL's features and concepts, compare it to REST API and BFFs, and discuss its advantages and disadvantages.
The Evolving Landscape of API Protocols in 2023 What is GraphQL?...

Continue reading this post for free, courtesy of Alex Xu.
A subscription gets you:
An extra deep dive on Thursdays Full archive Many expense it with team's learning budget © 2024 ByteByteGo
548 Market Street PMB 72296, San Francisco, CA 94104
Unsubscribe
by "ByteByteGo" <bytebytego@substack.com> - 11:36 - 16 May 2024 -
RE: DIA Global 2024
Hi,
I’m curious to know if would you be interested in our mailing lists.?
Could you please just hit me back with a number 1-2-3 that best describes your response?
1.Interested to see Count & Cost.
2.Too busy, email me again in a month, please.
3.Please close my tab, I’m not interested…
Looking back to hear from you.
Marketing Analyst - Laurie Young
Please let me know if you have any particular goals in mind so that I can adjust the list.
From: laurie.young@planetmaillinglist.com <laurie.young@planetmaillinglist.com>
Sent: Tuesday, May 14, 2024 5:41 PM
To: 'info@learn.odoo.com' <info@learn.odoo.com>
Subject: DIA Global 2024Greetings,
An attendees list for the Drug Information Association Annual Meeting - DIA Show is available tailored to meet your marketing needs.
List Includes: Company Name, Contact Name, Verified E-mail id’s, Tel.no, URL/Website, Title/Designation.
Can I send you cost of full lists.? If you are interested.
Marketing Manager – Laurie Young
Let me know if you have any particular targets in mind so that I can customize the list.
by laurie.young@planetmaillinglist.com - 10:52 - 16 May 2024