Archives
- By thread 5363
-
By date
- June 2021 10
- July 2021 6
- August 2021 20
- September 2021 21
- October 2021 48
- November 2021 40
- December 2021 23
- January 2022 46
- February 2022 80
- March 2022 109
- April 2022 100
- May 2022 97
- June 2022 105
- July 2022 82
- August 2022 95
- September 2022 103
- October 2022 117
- November 2022 115
- December 2022 102
- January 2023 88
- February 2023 90
- March 2023 116
- April 2023 97
- May 2023 159
- June 2023 145
- July 2023 120
- August 2023 90
- September 2023 102
- October 2023 106
- November 2023 100
- December 2023 74
- January 2024 75
- February 2024 75
- March 2024 78
- April 2024 74
- May 2024 108
- June 2024 98
- July 2024 116
- August 2024 134
- September 2024 130
- October 2024 141
- November 2024 171
- December 2024 115
- January 2025 216
- February 2025 140
- March 2025 220
- April 2025 233
- May 2025 239
- June 2025 303
- July 2025 176
-
Collagen and Gelatin Powder Producer
Dear Info
How are you doing ?
Beyond Biopharma is an ISO22000 and US FDA Registered manufacturer of collagen powder and Gelatin for foods supplements and pharmaceutical products.
Our collagen ingredients inlcudeds :
bovine collagen
fish collagen
chicken collagen type ii hydrolyzed
chicken collagen type ii undenatured.
Our gelatin products included:
bovine gelatin from both skin and bone
porcine skin gelatin
fish skin gelatin
For Gelatin, We have different jelly strength and viscosites available for different applications such as production of
Empty hard capsuples
Soft Gel
Candies
Gummies
Confectionary products
Meats products
Are you interested in get quotations of Collagen and Gelatin as an alternative sources?
Best regards,
Michael Qiao
Sales Manager
Beyond Biopharma Co., Ltd.
US FDA Registered, ISO22000 VerifiedVisit us at tradeshows of 2025 Worldwide below:
1. Vitafoods Asia, Sep.17-19, 2025, Bangkok Thailand, Booth No.:S31
2. Pharmaconex, Sep.1-3, 2025, Cairo Egypt, Booth No.: H3C14
Tel/Fax: +86 21 65010906
Cell/Whatsapp/WeChat:+ 86 18657345785
Skpye: live:sales_87476
Email: michael@beyondbiopharma.com
www.beyond-collagen.com
Address : NO.137 Haining Road,
Hongkou District, Shanghai, 200080 China
by "Lily" <Lily@beyondbiopharm.com> - 05:16 - 16 May 2025 -
Innovation Marking Revolution - Brand New Industrial Laser marking
Dear Info,
Thanks for your attention here.
We are professional manufacturer which focus on R&D, production and sales of laser marking machines. Here we have nearly 20 years experience in marking and coding industry, we clearly knows how to produce a reliable and stable industrial marking machine.
Here we provide two types of laser marking systems: integrable and dedicated systems.
The Integrate laser marking systems are integrated as part of a production line.
The dedicated laser marking systems are based on specific needs of the packaging machines .
Compared with traditional inkjet printer, the laser printer requires no consumables and nearly free of maintenance, no solvent pollution and user-friendly for operation.
As an essential part in the packaging process to meet market circulation requirements and policy regulations, laser marking has huge potential and good market prospect.
Please share above info with your team, any unclear let we know.
Warm regards,
Diane Gu
Product Manager / Hangzhou Kechuang Mark Technology Co .,Ltd
Tel & Wechat & Whatsapp 0086 15571418860
Ins @kec_marking (videos sharing here)
E-mail sales@kec-mark.com
by "Sheval Leer" <leersheval@gmail.com> - 01:56 - 16 May 2025 -
[SLC EVENT TODAY!] ClickFunnels Connect
Join Russell virtually for a big announcement!This is it!
It’s your last chance to grab a “virtual ticket” so you can be there for the Utah event that’s going live in a few hours.
JOIN US VIRTUALLY FOR THE SALT LAKE CITY HANGOUT EVENT HERE >>
Russell will be presenting… Other 2-comma club award winners will be sharing some awesome insights… It’s like a mini Funnel Hacking Live!
AND… Russell is making a big announcement you won’t want to miss!
JOIN US VIRTUALLY FOR THE SALT LAKE CITY HANGOUT EVENT HERE >>
See you in a few hours!!
© Etison LLC
By reading this, you agree to all of the following: You understand this to be an expression of opinions and not professional advice. You are solely responsible for the use of any content and hold Etison LLC and all members and affiliates harmless in any event or claim.
If you purchase anything through a link in this email, you should assume that we have an affiliate relationship with the company providing the product or service that you purchase, and that we will be paid in some way. We recommend that you do your own independent research before purchasing anything.
Copyright © 2018+ Etison LLC. All Rights Reserved.
To make sure you keep getting these emails, please add us to your address book or whitelist us. If you don't want to receive any other emails, click on the unsubscribe link below.
Etison LLC
3443 W Bavaria St
Eagle, ID 83616
United States
by "Todd Dickerson" <noreply@clickfunnelsnotifications.com> - 11:01 - 16 May 2025 -
weekly update rate fm china
SHUNSHUNFA SHIP CO.LTD POL POD 20'GP 40'HQ Shanghai Jebel ali 1100 1200 Ningbo Jebel ali 1000 1100 Qingdao Jebel ali 1200 1300 Shenzhen Jebel ali 1100 1200 For more information about our services, visit our
website: https://www.ssf-logistics.comBest wishMOB:+86 13751768263
by "owen3" <owen3@shipshun.com> - 10:02 - 16 May 2025 -
Investigate Superior Thermoforming Systems for Efficient Production
Dear Info,
This is Aimee from Shantou Rayburn Machinery Co,Ltd.
Our Factory's leading products are RM series high-speed multi-station positive and negative pressure thermoforming machines and RM series large format four-station thermoforming machine, which are applying to disposable plastic cups,lids,containers,trays,bowls and so on. We also can supply all kinds of plastic products mold design and automatic auxiliary equipment .
I have browsed your company's website, I saw that you mainly make disposable plastic packaging.We are committed to providing customers with efficient and high-quality production equipment.Our machines are deeply trusted and praised by customers.
We hope to establish a long-term cooperative relationship with your company and jointly develop the market. If you are interested in our products or have any questions, please feel free to contact us. We will wholeheartedly provide you with professional services and support.
Email:rm-a@rm-machine.cn
Tel/Whatsapp:008617875405452
Best Regards,
Aimee
by "rm10" <rm10@strmmachine.com> - 09:37 - 16 May 2025 -
High-Quality Circuit Breakers for Your Switchgear Panels – Custom Solutions Available!
Dear Info,
Are you looking for reliable and cost-effective circuit breakers for your power switchgear panels? As a leading China OEM Circuit Breaker Factory, DeLing Tech specializes in manufacturing Molded Case Circuit Breakers (MCCB), Low Voltage Circuit Breakers, and Intelligent Molded Case Circuit Breakers that meet IEC 60947-2 standards. Our products are widely used in industrial and commercial applications, offering:
• High breaking capacity (up to 1600A)
• Customizable designs for OEM/ODM projects
• Competitive pricing with fast delivery
Let’s discuss how we can support your next project. Reply to this email or contact us at [Your Email/Phone] for a free quote!
Best regards,
Sales4
Sales Manager
DeLing Tech Co., Ltd.
by "sales4" <sales4@cndtmccb.com> - 07:35 - 16 May 2025 -
America at 250: A vision for the future
The Shortlist
Emerging ideas for leaders Curated by Alex Panas, global leader of industries, & Axel Karlsson, global leader of functional practices and growth platforms
Welcome to the latest edition of the CEO Shortlist, a biweekly newsletter of our best ideas for the C-suite. This week, we delve into the agenda for America’s CEOs, public sector leaders, and changemakers as the country nears its semiquincentennial—a plan of action that leaders around the world may also want to follow. You can reach us at Alex_Panas@McKinsey.com and Axel_Karlsson@McKinsey.com. Thank you, as ever.
—Alex and Axel
•
ten dimensions of change for trade, economics, and security—and strategies American businesses can use to help ensure long-term success
•
insights on how the United States can achieve energy abundance, emphasizing rapid and sustained growth in baseload, dispatchable energy, and grid capacity
•
strategies for developing human capital to meet the demands of automation and AI
•
and much more
We hope you find these ideas inspiring and helpful. See you in a couple of weeks with more McKinsey ideas for the CEO and others in the C-suite.
Share these insights
This email contains information about McKinsey’s research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this email because you subscribed to The CEO Shortlist newsletter.
Copyright © 2025 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "McKinsey CEO Shortlist" <publishing@email.mckinsey.com> - 04:08 - 16 May 2025 -
Introducing an Exclusive Opportunity at Poulton Park Golf Club
We’re excited to introduce a new business partnership... 

Hi Sir/Madam,
We’re excited to introduce a new business partnership opportunity at Poulton Park Golf Club, one of the most prestigious golf clubs in the area.
This exclusive package combines advertising, marketing, networking, and complimentary golf - designed to help a business like yours:
- Build your brand presence with high-value members and visitors.
- Gain access to networking events tailored for relationship building.
- Leverage innovative digital advertising on large screens and mobile apps.
As part of the package, you’ll receive free golf at Poulton Park Golf Club and over 600 other venues across the UK, including iconic courses such as The Belfry, The Shire, Close House, Macdonald Hotels, and Celtic Manor.
Would you like to discuss how this opportunity could benefit Your Telecoms Consultant?
Looking forward to hearing from you!
Best regards,
James Thomson
Account Manager
+44 (0)7453 145 120

by "James Thomson - Golf Marketing Agency" <info@golfmarketingagency.co.uk> - 03:02 - 16 May 2025 -
Meet the Gen Z health consumer
On McKinsey Perspectives
Social media’s growing influence Brought to you by Alex Panas, global leader of industries, & Axel Karlsson, global leader of functional practices and growth platforms
Welcome to the latest edition of Only McKinsey Perspectives. We hope you find our insights useful. Let us know what you think at Alex_Panas@McKinsey.com and Axel_Karlsson@McKinsey.com.
—Alex and Axel
—Edited by Belinda Yu, editor, Atlanta
This email contains information about McKinsey's research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this email because you subscribed to the Only McKinsey Perspectives newsletter, formerly known as Only McKinsey.
Copyright © 2025 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "Only McKinsey Perspectives" <publishing@email.mckinsey.com> - 01:18 - 16 May 2025 -
Custom Lighting & Furniture for Your Unique Projects
Dear Info,
At Dezignlover, we bring your creative visions to life with custom lighting and designer furniture. Designed for professionals like architects, interior designers, and real estate developers, our products combine artistry with functionality.
From luxurious chandeliers to bespoke furniture, we deliver solutions tailored to your projects—whether it’s a boutique hotel, residential masterpiece, or retail space. Our goal is to help you create timeless interiors that leave a lasting impression.
Let’s collaborate to turn your ideas into reality. Explore our offerings at www.dezignlover.com or reply to email contact@dezignlover.com to discuss your next project.

Best regards,
Sophie
Sales Representativewww.dezignlover.com
WhatsApp: +1 (832) 844 1221
by "sale18" <sale18@dezignpromail.com> - 10:23 - 15 May 2025 -
Unleashing the Power of Herbal Medicine for Your Supplements-Life Energy
Dear Info,
Do you want to use natural and effective ingredients to improve the quality of your health care products? Don't hesitate any longer! At Life Energy, we focus on providing high-quality raw materials that can revolutionize your products.
One of our most outstanding ingredients is traditional Chinese herbal medicine. Known for their healing properties and used in holistic medicine for centuries, these herbs can add significant value to your health products.
Join the growing list of wellness brands harnessing the power of Chinese herbal medicine through our premium raw materials. Enhance your products, delight your customers, and unleash the ancient wisdom of Chinese herbal medicine.Contact us today at the mail to learn more about our products and take the first step toward a healthier, more natural product line.
Kind regards,
Cherry
Life Energy Co., Ltd
Cherry (Sales Manager)
Phone: +86 18192562267
Mail/Skype: cherry@flifenergy.cn
Website: www.flifenergy.com
Address: A-911 Tiandi Times Square, FengCheng 2th Road, Xi'an, Shaanxi, 710016 China.
by "kiki" <kiki@lifenergyt.com> - 09:18 - 15 May 2025 -
Premium PC Components for Seamless Performance
Dear Info,
At Shenzhen Tianfeng International Technology Co., Ltd., we specialize in high-efficiency PC power supplies, durable motherboards, and cutting-edge GPUs designed to meet global OEM/ODM demands. Our products are engineered with advanced thermal management and energy-saving technologies, ensuring reliability under heavy workloads.
Key highlights:
Certified Quality: CE, FCC, and RoHS compliance.
Custom Solutions: Tailored configurations for bulk orders.
Fast Lead Times: Streamlined logistics for timely delivery.
Let’s power innovation together.
Best regards,
Whisper
Mobile:+86 0 18816471391
Whatsapp:+86 18816471391Shenzhen Tianfeng International Technology Co., Ltd.
Website:https://www.skywindintl.com/
802, Fucheng Digital Innovation Park, No. 15, Shijing Road, Fumin Community, Fucheng Street, Shenzhen, Guangdong, China

by "andy" <andy@pcgearshub.com> - 05:40 - 15 May 2025 -
EU Carbon Tax Alert! Optimize [Industry] Waste Treatment Before 2025 Deadline
Dear Info ,
Hello! I am [Marketing center director] from [JIANGSU WORLD TOP THERMAL SCIENCE TECHNOLOGY CO.,LTD]. We specialize in providing advanced environmental technologies and engineering services to global manufacturing industries, helping companies meet environmental requirements while improving production efficiency.
We understand that your company is facing increasing environmental pressures in [Lithium battery manufacturing, pulp manufacturing, seawater desalination for salt production, landfill sites, utilization and disposal of waste incineration fly ash, coal chemical industry, raw material drug production/large-scale pharmaceutical industry, industrial wastewater water treatment, metallurgical industry, utilization of hazardous waste production enterprises]. Our [MVR evaporator, multi effect evaporator, mother liquor dryer, disc dryer, tire rubber cracking device, vibrating fluidized bed, forced circulation heater, condensate preheater, OSLO crystallizer, FC crystallizer, condenser, condensate water tank, thickener, mother liquor tank, fresh steam condensate water tank, scraper film evaporator, plate heat exchanger] can effectively reduce emissions, enhance resource utilization, and help your company achieve lower production costs and higher efficiency.
If you are interested in our environmental technologies, we would be happy to provide you with a detailed solution and discuss the best implementation plan for your company.
Looking forward to hearing from you!
Best regards,
SubscribeUnsubscribe
by "Annual Kiba" <kibaannual@gmail.com> - 02:22 - 15 May 2025 -
[LAST CHANCE] Virtual ticket for SLC Live Event
You might still have a shot to hang out with Russell…I hope you’ve been getting my emails about the SLC event…
When: Friday, May 16th 3pm ET
Where: Anywhere with Wi-Fi
You’ll want to be there because even though this is a smaller “Underground Utah Funnel Hacker Event”, Russell is using it to make a MASSIVE announcement!
If I were you, I’d move any meetings you have on your calendar, and set aside a few hours to attend this. It will be solid gold! AND… Russell’s announcing something big.
JOIN US VIRTUALLY FOR MY SALT LAKE CITY HANGOUT EVENT HERE >>
Hope to see you on the Zoom!
(And BTW… If you’re anywhere close to Utah, you should totally make the trip and hang out!)
© Etison LLC
By reading this, you agree to all of the following: You understand this to be an expression of opinions and not professional advice. You are solely responsible for the use of any content and hold Etison LLC and all members and affiliates harmless in any event or claim.
If you purchase anything through a link in this email, you should assume that we have an affiliate relationship with the company providing the product or service that you purchase, and that we will be paid in some way. We recommend that you do your own independent research before purchasing anything.
Copyright © 2018+ Etison LLC. All Rights Reserved.
To make sure you keep getting these emails, please add us to your address book or whitelist us. If you don't want to receive any other emails, click on the unsubscribe link below.
Etison LLC
3443 W Bavaria St
Eagle, ID 83616
United States
by "Todd Dickerson" <noreply@clickfunnelsnotifications.com> - 12:50 - 15 May 2025 -
Engineering Trade-offs: Eventual Consistency in Practice
Engineering Trade-offs: Eventual Consistency in Practice
Modern applications don’t run on a single database or monolithic backend anymore. They run on event-driven, distributed systems.͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ Forwarded this email? Subscribe here for moreLatest articles
If you’re not a subscriber, here’s what you missed this month.
Coupling and Cohesion: The Two Principles for Effective Architecture
OOP Design Patterns and Anti-Patterns: What Works and What Fails
The Art of REST API Design: Idempotency, Pagination, and Security
To receive all the full articles and support ByteByteGo, consider subscribing:
Imagine a ride-sharing app that shows a driver’s location with a few seconds of delay. Now, imagine if the entire app refused to show anything until every backend service agreed on the perfect current location. No movement, no updates, just a spinning wheel.
That’s what would happen if strong consistency were always preferred in a distributed system.
Modern applications (social feeds, marketplaces, logistics platforms) don’t run on a single database or monolithic backend anymore. They run on event-driven, distributed systems. Services publish and react to events. Data flows asynchronously, and components update independently. This decoupling unlocks flexibility, scalability, and resilience. However, it also means consistency is no longer immediate or guaranteed.
This is where eventual consistency becomes important.
Some examples are as follows:
A payment system might mark a transaction as pending until multiple downstream services confirm it.
A feed service might render posts while a background job deduplicates or reorders them later.
A warehouse system might temporarily oversell a product, then issue a correction as inventory updates sync across regions.
These aren’t bugs but trade-offs.
Eventual consistency lets each component do its job independently, then reconcile later. It prioritizes availability and responsiveness over immediate agreement.
This article explores what it means to build with eventual consistency in an event-driven world. It breaks down how to deal with out-of-order events and how to design systems that can handle delays.
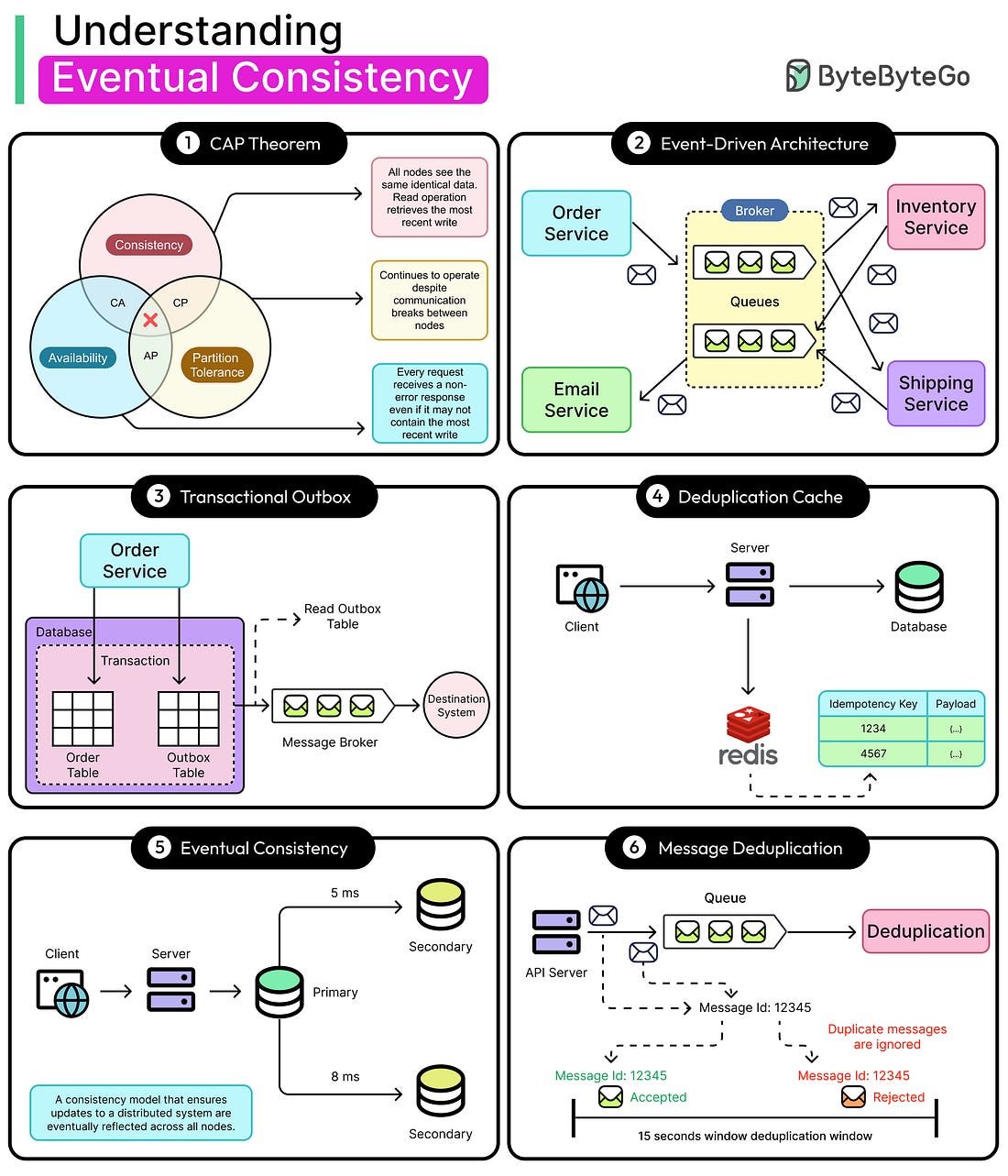
What is Eventual Consistency?...

Continue reading this post for free in the Substack app
Like
Comment
Restack
© 2025 ByteByteGo
548 Market Street PMB 72296, San Francisco, CA 94104
Unsubscribe

by "ByteByteGo" <bytebytego@substack.com> - 11:37 - 15 May 2025 -
Your invited! New Relic University - Observability Workshop Series
Hi MD,
Phil Weber, Lead Customer Training Specialist from New Relic, here.
New Relic Certification is now available to help you continue to grow your observability knowledge throughout your career. I am running a series of workshops designed to upskill your observability skills with New Relic, and help you get the skills and knowledge to take your chosen exams. We’ll also dive into some hands-on labs where you’ll work within a sandbox in a live working environment to put your skills to the test.
Dates and topics:
- 20 May: Maximise performance engineering with APM and infrastructure monitoring - Learn powerful APM and infrastructure monitoring techniques to track, spot and visualise overall system health, and explore how to leverage these insights to make informed, data-driven decisions.
- 21 May: Enhance reliability engineering by resolving incidents faster with New Relic alerts and AI - Explore the fundamentals of New Relic alerts and artificial intelligence, focusing on equipping you with the skills to proactively implement, configure, and optimise for system reliability.
- 22 May: Boost performance & reliability engineering with dashboard visualisation techniques - Learn dashboard design strategies, access best in class templates, discover how to create powerful charts and how to correlate different data sets.
Unable to make it? No sweat. Register here and an on-demand recording of the session will be sent to you after the webinar.
I hope to see you then,
Phil Weber,Lead Customer Training SpecialistNew Relic
This email was sent to info@learn.odoo.com · · View this online
This email was sent to info@learn.odoo.com. If you no longer wish to receive these emails, click on the following link: Unsubscribe
by "Phil Weber, New Relic" <emeamarketing@newrelic.com> - 05:02 - 15 May 2025 -
Can better reading make you a better leader?
On McKinsey Perspectives
McKinsey experts’ top tips Brought to you by Alex Panas, global leader of industries, & Axel Karlsson, global leader of functional practices and growth platforms
Welcome to the latest edition of Only McKinsey Perspectives. We hope you find our insights useful. Let us know what you think at Alex_Panas@McKinsey.com and Axel_Karlsson@McKinsey.com.
—Alex and Axel
•
The first step is the hardest. The corporate world often talks about the “glass ceiling,” but the real barrier for women may come earlier in their careers, reveal McKinsey Senior Partners Kweilin Ellingrud, Lareina Yee, and María del Mar Martínez in their new book, The Broken Rung. As Fortune reports, joint research by McKinsey and LeanIn.Org finds that for every 100 men who win their first promotion to a management position, 81 women receive that same opportunity. The authors explore how women can build “experience capital” to close this gap, unlock career mobility, and boost long-term earning power. [Fortune]
•
Tell the truth. In today’s uncertain environment, leaders can’t afford to operate in an echo chamber. McKinsey Senior Partners Dana Maor, Kurt Strovink, and Ramesh Srinivasan and Senior Partner emeritus Hans-Werner Kaas, authors of The Journey of Leadership, share that great leaders actively seek out truth tellers—and create a culture where it’s safe to challenge assumptions. The higher up someone is in an organization, the harder it becomes to get unfiltered feedback. But leaders who welcome candor will have an unvarnished set of facts to guide decision-making.
•
Be bold or fall behind. What separates the best CEOs from the rest? According to CEO Excellence authors Carolyn Dewar, Scott Keller, and Vik Malhotra, it’s not caution—it’s courage. The most successful leaders don’t just manage complexity; they reframe it, making bold moves that redefine their companies’ trajectories. “You can be bold regardless of context, or you can be bold within that context,” says Malhotra. The authors, joined by McKinsey Senior Partner Kurt Strovink, build on these insights in their upcoming book, A CEO for All Seasons, which offers a practical guide to mastering the four critical phases of leadership. For more leadership lessons and must-reads, visit McKinsey on Books.
—Edited by Belinda Yu, editor, Atlanta
This email contains information about McKinsey's research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this email because you subscribed to the Only McKinsey Perspectives newsletter, formerly known as Only McKinsey.
Copyright © 2025 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "Only McKinsey Perspectives" <publishing@email.mckinsey.com> - 01:12 - 15 May 2025 -
Emerging Markets Custom Solutions | Inventory Risk Control
Dear Info,
In the face of rapidly shifting demands and inventory overstock risks in emerging markets, we, as an OEM/ODM manufacturer, provide end-to-end solutions to empower your growth:
✓ Flexible Small-Batch Production
- MOQ 1,000 units | 5-day rapid turnaround (mixed SKUs supported)
- Custom packaging/flavors/hardware specs (e.g., humidity-proof versions)
✓ Dynamic Inventory Management
- Pre-sale model + safety stock alerts
- 20% order value for overstock compensation
- Free return with new products on extra discount in terms of the overstock problem
✓ Localized logistic and marketing Support
- Global warehouses to support you with faster delivery
- Customized bundles (e.g. 1/2/3 pod + 3/6/9 cartridges)
Success Story:
In 2024, our Russian partner boosted top-selling SKU ratio from 45% to 82% with data-driven product selection guidance, cutting inventory turnover time by 15 days.
Act Now:
? Claim Your Free Sample (First-order exclusive)
? Download attached our E-catalog and tell us the products of your interests
Looking forward to hearing from you.Best regards,
Yeser
Sales manager
Tel:+86 135 0280 4383
by "Sava Wheatley" <savawheatley@gmail.com> - 05:33 - 14 May 2025 -
Consolidation&Warehouse Services covering all the China port
Dear Info,
Smartrans International Ltd is a freight-forwarding agency based in Shenzhen China, Services as belows.
1)Professional Ocean&AIR freight transportation handing
2)Professional Ocean&AIR freight ground handling agent, Ocean & Airr freight consolidator
3)Worldwide door to door service by SEA or by AIR
4)Common Sea & air freight warehousing and Sea & air freight handling for forwarders
5)Customs clearance Import&Export
6)Cheaking the package at our warehouse
7)Air freight charter from China main cities to worldwide handling
8)FBA shipping
9)Import&Export License documents purchasing
by "Marsha Bendetti" <marshabendetti54@gmail.com> - 03:54 - 14 May 2025 -
RE: Are you still losing bids? No worries!
I've reached out a couple of times, but haven't heard back. If you could respond to my original email below, I can cross this off my list.
Thanks
From: Mike Calvin
Sent: Monday, May 12, 2025 11:49 AM
Subject: RE: Are you still losing bids? No worries!I have not heard from you. Please Let me know if we can be of any assistance in regards to providing Takeoff/Estimating services.
ThanksFrom: Mike Calvin
Sent: Thursday, May 8, 2025 8:21 AM
Subject: RE: Are you still losing bids? No worries!I'm sure you're busy because I didn't hear anything back from you. I’d appreciate a response to my original email below.
Thanks
From: Mike Calvin
Sent: Tuesday, May 6, 2025 7:59 AM
Subject: RE: Are you still losing bids? No worries!Just making sure you saw this.
Thanks
From: Mike Calvin
Sent: Thursday, May 1, 2025 1:28 PM
Subject: Are you still losing bids? No worries!At JU Estimating, we deal in all kinds of residential, commercial, and industrial projects estimating and material takeoff services. Our services cover up all construction trades and CSI divisions. Here you can get quality construction estimates and affordability under one roof.
Our qualified and professional estimators can provide you accurately detailed material takeoffs and cost estimates for your upcoming building projects with no compromise over the quality of work. If you're holding any job then send us the project plans and get a quick service proposal.
If there're any questions or concerns feel free to reach out.
Thanks & Regards,
Mike Calvin | (703) 721-8864
JU Estimating LLC
8855 Peregrine Heights Rd Apt 201 Manassas, VA 20111
If you no longer wish to receive emails from us, please respond with unsubscribe. We apologize if this email was not relevant to your needs.
by "Mike Calvin" <mike@juestimating.net> - 02:17 - 14 May 2025










