Archives
- By thread 5226
-
By date
- June 2021 10
- July 2021 6
- August 2021 20
- September 2021 21
- October 2021 48
- November 2021 40
- December 2021 23
- January 2022 46
- February 2022 80
- March 2022 109
- April 2022 100
- May 2022 97
- June 2022 105
- July 2022 82
- August 2022 95
- September 2022 103
- October 2022 117
- November 2022 115
- December 2022 102
- January 2023 88
- February 2023 90
- March 2023 116
- April 2023 97
- May 2023 159
- June 2023 145
- July 2023 120
- August 2023 90
- September 2023 102
- October 2023 106
- November 2023 100
- December 2023 74
- January 2024 75
- February 2024 75
- March 2024 78
- April 2024 74
- May 2024 108
- June 2024 98
- July 2024 116
- August 2024 134
- September 2024 130
- October 2024 141
- November 2024 171
- December 2024 115
- January 2025 216
- February 2025 140
- March 2025 220
- April 2025 233
- May 2025 239
- June 2025 303
- July 2025 38
-
Your potential partner for iron oxide business
Dear info,
Hope this email finds you well.
This is Joanna on behalf of XT pigment technology Co.ltd. We are top 1 iron oxide manufacturer in northwest of China.
Our core business is producing iron oxide pigments, there are 7 colors available, widely used in tiles, interlocks, paintings & plastic.
We have factory, supporting customized products.
Small qty is available for testing the quality.
Are you interested in our products?
Best Regards,
Joanna

by "andy" <andy@colorxtpigment.com> - 11:12 - 8 Apr 2025 -
From the largest supermarket shelf manufacturing factory in Jiangsu, China
Dear info,
Glad to learn you're on the market of shelf products.I work in foreign trade in a shelf company. We Jiangsu Jinyihao Metal Technology Co., LTD Company specialized in shelf for 20 years.Our main products cover supermarket shelf,drugstore shelves, warehouse shelves ,home shelves and other various items of storage shelves.
If any product meed your demand, please feel free to contact us. We're sure your any inquiry or requirement will get prompt attention.
Best regards,
Nico
Sales Manager
P: +86 18852930810
E: nico@jyhshelf.com
by "Cristiano Rool" <roolcristiano827@gmail.com> - 08:03 - 8 Apr 2025 -
Navigating Vendor Layoffs: Insights for Your ERP Implementation
Navigating Vendor Layoffs: Insights for Your ERP Implementation

Hi MD Abul,
I hope this message finds you well. In light of recent developments within the tech industry, I wanted to share some insights on how vendor layoffs might affect your ERP implementation and how to navigate these challenges effectively.
Recent Vendor Layoffs
Several prominent technology companies have announced significant workforce reductions recently:
-
Hewlett Packard Enterprise (HPE): Announced plans to cut approximately 2,500 jobs, representing about 5% of its workforce, as part of cost-cutting measures.
-
Autodesk: Initiated a restructuring plan that includes reducing approximately 9% of its workforce, affecting around 1,350 employees.
-
Workday: Announced a reduction of about 1,750 jobs, equating to 8.5% of its workforce, to invest more heavily in artificial intelligence amid a challenging macroeconomic environment.
Implications for ERP Implementations
These workforce reductions can have several potential impacts on organizations undergoing ERP implementations:
-
Resource Availability: Layoffs may lead to reduced support and development resources from your ERP vendors, potentially affecting project timelines and the availability of expertise.
-
Product Development: Restructuring efforts might shift vendor focus towards specific areas, such as artificial intelligence, possibly deprioritizing other functionalities critical to your implementation.
-
Vendor Stability: Significant layoffs can signal financial or strategic shifts within a vendor organization, which may impact their long-term viability and commitment to product support.
Strategies to Mitigate Risks
To navigate these challenges effectively, consider the following strategies:
-
Maintain Open Communication: Regularly engage with your ERP vendors to stay informed about organizational changes and understand how they might affect your project.
-
Assess Vendor Roadmaps: Review and reassess your vendors' product development roadmaps to ensure alignment with your organization's needs and timelines.
-
Diversify Support Channels: Consider augmenting vendor support with third-party consulting services to mitigate potential gaps in expertise or resources.
-
Monitor Vendor Health: Keep abreast of your vendors' financial and organizational health to anticipate and prepare for potential disruptions.
Best regards,
Eric Kimberling
Third Stage Consulting 384 Inverness Pkwy Suite Englewood Colorado
You received this email because you are subscribed to Marketing Information from Third Stage Consulting.
Update your email preferences to choose the types of emails you receive.
Unsubscribe from all future emails
by "Eric Kimberling" <eric.kimberling@thirdstage-consulting.com> - 06:04 - 8 Apr 2025 -
-
French Pattern Porcelain Tiles – Elegant, Durable & Low Water Absorption
Dear info,
I hope this email finds you well.
We are excited to introduce our exquisite **French Pattern Porcelain Tiles**, designed to bring timeless elegance and superior performance to any space. These tiles combine aesthetic appeal with exceptional durability, making them ideal for both residential and commercial applications.
**Key Features:**
- **Available Sizes:** 400×600 mm, 400×400 mm, 200×400 mm, 200×200 mm
- **Thickness:** 9 mm – Perfect for high-traffic areas
- **Ultra-Low Water Absorption:** **< 0.5%** – Ensures excellent resistance to stains, frost, and moisture
- **Premium French Pattern Design** – A sophisticated and versatile choice for modern interiors
Whether you’re looking for flooring, wall cladding, or decorative accents, these tiles offer unmatched quality and style.
Would you be interested in these kinds of porcelain tiles? We’d be happy to provide more information or discuss bulk pricing options.
Looking forward to your kind reply!
P.S:some of our Pocerlain tiles French pattern
Sizes :400*600,400*400,200*400,200*200,Thickenss :9mm
Waterabsorption:<0.5%


Best Regards,
Maria Lin / General Manager
Pedesen Stone Co.,Ltd
ADD:FLOOR 5, QIANAN NO.326,NEICUO TOWN,XIANGAN DISTRICT,XIAMEN,FUJIAN,CHINA
TE:0086 592 7619558 | Mobile NO.: 0086 15306926985 (WhatsApp/Wechat)
Email: marialin@pedesenstone.com
by "Amanda" <Amanda@a-pdsstone.com> - 03:04 - 8 Apr 2025 -
EMB SPOT - Aufnäher zu einem aufregenden Preis


STICKEREI
AUFNÄHER
Präzision, Leidenschaft und perfekte Stiche
EMB Spot bietet Ihnen ein exklusives Angebot für hochwertige Aufnäher – stärken Sie Ihre Marke und hinterlassen Sie einen bleibenden Eindruck!
Sublimations Aufnäher
Mindestens 50 Aufnäher für €92
Wir bieten
• Wärmeadhäsive Rückseite
• Klettverschluss-Rückseite
• Abziehbare Rückseite
• Zum Nähen auf der Rückseite
Gewebte Aufnäher
Mindestens 50 Aufnäher für €92
Wir bieten
• Wärmeadhäsive Rückseite
• Klettverschluss-Rückseite
• Abziehbare Rückseite
• Zum Nähen auf der Rückseite
Stickerei Aufnäher
Mindestens 50 Aufnäher für €115
Wir bieten
• Wärmeadhäsive Rückseite
• Klettverschluss-Rückseite
• Abziehbare Rückseite
• Zum Nähen auf der Rückseite
PVC-Aufnäher
Mindestens 50 Aufnäher für €115
Wir bieten
• Wärmeadhäsive Rückseite
• Klettverschluss-Rückseite
• Abziehbare Rückseite
• Zum Nähen auf der RückseiteLass uns anfangen.
Wir nutzen eine Vielzahl von Formaten, die mit Stickmaschinen kompatibel sind, und stellen sicher, dass Ihr Design jedes Mal perfekt aussieht.
www.embspot.com
by mary@embspot.com - 02:05 - 8 Apr 2025 -
Exploring Durable and Affordable PVC Flooring Solutions
Dear info,
My name is Zhuge Chao, and I am the Chairman of Lianyungang Kingly Plastic Industry Co., Ltd., a leading manufacturer specializing in residential and commercial PVC flooring rolls.
We understand that your company is important role in the flooring industry in [Target Market/Country]. Our products are both affordable and durable, making them an excellent addition to your product portfolio.Why Choose Kingly PVC Flooring Rolls? Versatile Specifications: Available in 2m and 4m widths (1.8m, 2m, 2.5m, 3m, 3.3m, 3.5m, 3.7m, 4m) .Available to meet different market needs.
High Durability: Waterproof, anti-slip, and wear-resistant.
Customizable Designs: Offering a wide range of patterns and textures, with options for custom designs.
We are currently expanding our global partnerships and would be pleased to offer you exclusive pricing and support to help grow your business. Please find our product catalog attached for your reference.
Could we discuss how we can meet your market needs via email? I look forward to your reply.
Best regards,Zhuge Chao
Chairman
Lianyungang Kingly Plastic Industry Co., Ltd.
[+8615266638777]
by "wholesale" <wholesale@kinglyflooring.com> - 01:49 - 8 Apr 2025 -
Russell burnt this to the ground (confession)
I’m as shocked as you are…

Well… I wasn’t expecting this.
So, you remember One Funnel Away Challenge, right??
It’s arguably our MOST successful challenge we’ve ever done at ClickFunnels…
…and Russell went and burned it to the ground.
And built it back EVEN BETTER!!!
See, instead of choosing only “one path” for the One Funnel Away Challenge…
…you can now choose between TWO PATHS!!
You can choose the path with Russell and learn how to build a ‘one-to-many’ sales presentation that attracts your golden customers who are EAGER to buy your info product or service!
OR…
You can choose the Ecom path with THE #1 Ecom expert, Trey Lewellen, and learn how to sell physical Ecom products… (who by the way, still holds the record for the MOST Ecom products sold using ClickFunnels)!
GO HERE TO REGISTER FOR 30 DAY ONE FUNNEL AWAY CHALLENGE FOR FREE!! >>
This is the NEW and improved One Funnel Away… that works FOR YOU regardless of where you are in your life and business…. where you can CHOOSE which path you want to take… WHILE learning from the best-of-the-best!!
Doesn’t matter if this is your 1st or 100th funnel… The OFA challenge is like jet fuel for your online business.
It’s all the training, accountability, resources, motivation, and anything else you need to make things happen fast!!
GO HERE TO REGISTER FOR 30 DAY ONE FUNNEL AWAY CHALLENGE FOR FREE!! >>
This OFA is FREE for ClickFunnels Members and NON-MEMBERS!
If you’re a member of ClickFunnels, then you can join right away for FREE!
And if you’re not a NOT a member of ClickFunnels yet, then you can still join OFA for free when you sign up for a 14-day free trial of ClickFunnels (the #1 tool you’ll need to build your funnel)!
That’s it - now hurry and go here to watch the video of Russell breaking down the awesomeness of the NEW OFA (and quickly sign up before the doors close)! →
See you in the challenge,
Todd Dickerson
© Etison LLC
By reading this, you agree to all of the following: You understand this to be an expression of opinions and not professional advice. You are solely responsible for the use of any content and hold Etison LLC and all members and affiliates harmless in any event or claim.
If you purchase anything through a link in this email, you should assume that we have an affiliate relationship with the company providing the product or service that you purchase, and that we will be paid in some way. We recommend that you do your own independent research before purchasing anything.
Copyright © 2018+ Etison LLC. All Rights Reserved.
To make sure you keep getting these emails, please add us to your address book or whitelist us. If you don't want to receive any other emails, click on the unsubscribe link below.
Etison LLC
3443 W Bavaria St
Eagle, ID 83616
United States
by "Todd Dickerson" <noreply@clickfunnelsnotifications.com> - 01:34 - 8 Apr 2025 -
EMB SPOT - Aufnäher zu einem aufregenden Preis
STICKEREI
AUFNÄHER
Präzision, Leidenschaft und perfekte Stiche
EMB Spot bietet Ihnen ein exklusives Angebot für hochwertige Aufnäher – stärken Sie Ihre Marke und hinterlassen Sie einen bleibenden Eindruck!Sublimations Aufnäher
Mindestens 50 Aufnäher für €92
Wir bieten
• Wärmeadhäsive Rückseite
• Klettverschluss-Rückseite
• Abziehbare Rückseite
• Zum Nähen auf der RückseiteGewebte Aufnäher
Mindestens 50 Aufnäher für €92
Wir bieten
• Wärmeadhäsive Rückseite
• Klettverschluss-Rückseite
• Abziehbare Rückseite
• Zum Nähen auf der RückseiteStickerei Aufnäher
Mindestens 50 Aufnäher für €115
Wir bieten
• Wärmeadhäsive Rückseite
• Klettverschluss-Rückseite
• Abziehbare Rückseite
• Zum Nähen auf der RückseitePVC-Aufnäher
Mindestens 50 Aufnäher für €115
Wir bieten
• Wärmeadhäsive Rückseite
• Klettverschluss-Rückseite
• Abziehbare Rückseite
• Zum Nähen auf der RückseiteLass uns anfangen.
Wir nutzen eine Vielzahl von Formaten, die mit Stickmaschinen kompatibel sind, und stellen sicher, dass Ihr Design jedes Mal perfekt aussieht.
www.embspot.com
by mary@embspot.com - 01:06 - 8 Apr 2025 -
How YouTube Supports Billions of Users with MySQL and Vitess
How YouTube Supports Billions of Users with MySQL and Vitess
As YouTube’s popularity soared, so did the complexity of its backend. This happens because every video upload, comment, like, and view creates more data.͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ Forwarded this email? Subscribe here for morePostgres for Agentic AI—Now in the Cloud (Sponsored)

If you’re building LLM-powered features, you don’t need another black box. pgai on Timescale Cloud gives you full control over your vector data, memory, and retrieval logic—inside PostgreSQL. Everything runs in one place, with SQL and the tools your team already uses. From prototype to production, it's built to scale with you.
Explore pgai on Timescale Cloud
Disclaimer: The details in this post have been derived from presentations and blogs written by the YouTube and Vitess engineering teams. All credit for the technical details goes to the YouTube and Vitess engineering teams. The links to the original articles and videos are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
As YouTube’s popularity soared, so did the complexity of its backend. This happens because every video upload, comment, like, and view creates more data.
Initially, a single MySQL database and a few web servers were enough to keep the site running smoothly. But as the platform evolved into a global giant with billions of daily views, this approach began to crumble under the weight of its success.
YouTube built a custom solution for managing and scaling MySQL. This was known as Vitess.
Vitess acts like a smart librarian in a massive library. Instead of letting everyone go through the shelves, it organizes requests, routes them efficiently, and ensures that popular books are available at the front.
In other words, Vitess isn’t a replacement for MySQL. It’s more like a layer on top of it, allowing YouTube to continue using the database system they were already familiar with while enabling horizontal scaling (adding more servers) and graceful traffic handling. By introducing Vitess, YouTube transformed its backend into a more intelligent, resilient, and flexible infrastructure.
In this article, we will look at the various challenges YouTube faced as part of this implementation and the learnings they derived.
The Critical Role of Documentation in Software Architecture (Sponsored)
Good documentation isn't just nice to have, it's essential for building scalable, maintainable software.
From improving team collaboration to reducing technical debt, well-structured architecture documentation delivers long-term value. Investing in documentation today means fewer headaches tomorrow.
In this 4-min read, you'll learn how to create documentation that truly supports your development teams.
How do Web Apps Typically Scale?
When developers first build a web or mobile application, setting up the backend is fairly straightforward. Typically, they spin up a MySQL database and connect it to their application via a few web servers. This setup works wonderfully in the beginning. It’s simple, well-documented, and allows the team to move quickly with the features that matter.
In this early phase, the database footprint is small. Users submit data (like account info or posts) and retrieve it as needed. With low traffic, everything runs smoothly. Reads and writes are fast, and backups can be taken by temporarily pausing the application if needed.
However, success introduces complexity. As the application becomes more popular, more users begin to interact with it simultaneously. Each read or write adds to the load on the single MySQL instance, which can lead to slowdowns and an unresponsive database.
Some of the first problems to appear include:
Slow queries due to growing data volume.
Downtime while performing backups or updates.
Risk of data loss if a single server fails.
Limited ability to serve users globally due to latency.
Reading from Replicas
As web applications scale, one of the first techniques used to handle increasing load is replication: creating one or more copies (replicas) of the main database (often called the primary). These replicas are kept in sync with the primary by copying its data changes, typically through a process called asynchronous replication.
See the diagram below:
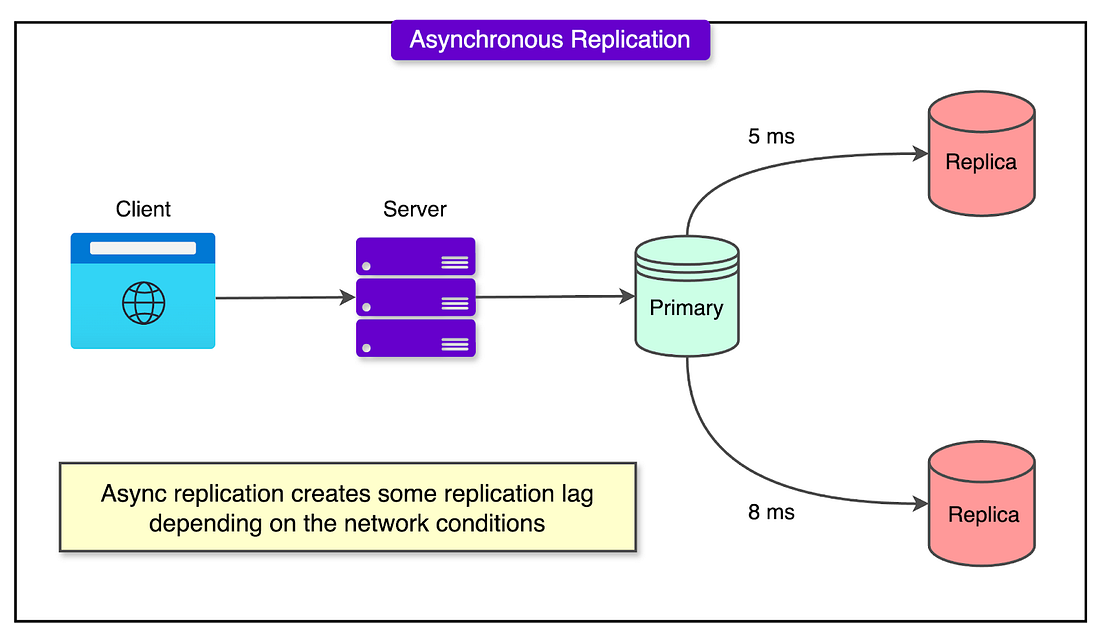
The main advantage of using replicas is load distribution.
Instead of having every user query hit the primary database, read queries (such as viewing a video, profile page, or browsing a list) are sent to the replicas. This reduces the load on the primary and helps the system handle a much higher volume of requests without degradation in performance.
However, this setup introduces a crucial trade-off: data staleness.
Since replicas receive updates from the master with a delay (even if just a few seconds), they may not always reflect the most current data. For example, if a user updates their profile and immediately refreshes the page, a replica might still contain the old information.
Let’s look at how YouTube handled this scenario.
Balancing Consistency and Availability
As YouTube grew, it faced a fundamental challenge in distributed systems: the CAP theorem.
This principle states that in the event of a network issue, a system can only guarantee two of the following three properties: Consistency, Availability, and Partition Tolerance.
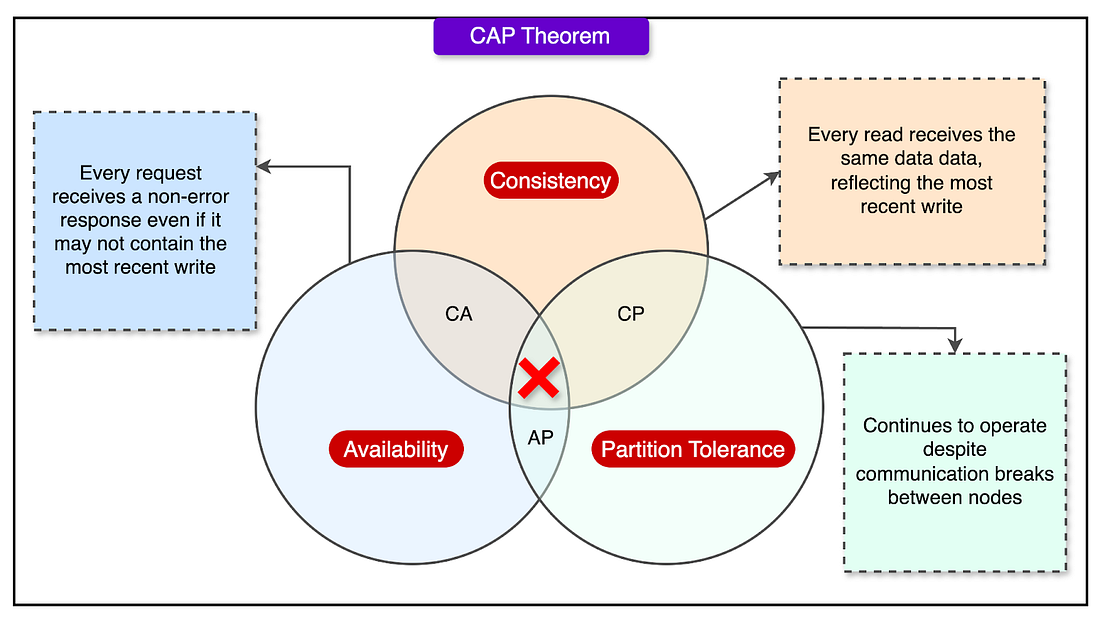
Partition tolerance is a must for distributed systems, so engineers are left choosing between consistency and availability.
YouTube, like many large-scale platforms, chose to make trade-offs, sacrificing strict consistency in some areas to maintain high availability.
They did this by classifying different types of read operations with a dual strategy:
Replica Reads: Used when absolute freshness isn’t critical. For example, displaying a video or showing view counts doesn't require second-to-second accuracy. A few seconds of delay in updating the view count won’t harm user experience.
Primary Reads: Reserved for operations that require up-to-date data. For example, after a user changes their account settings, they expect to see those changes reflected immediately. These read operations are directed to the primary, which has the most current data.
The underlying idea was that not all read requests are equal. Some data must be fresh, but a lot of content can tolerate a slight lag without negatively impacting the user experience.
Write Load Challenges and the Role of Prime Cache
As YouTube's traffic surged, so did the number of write operations to the database: uploads, comments, likes, updates, and more. This increase in write queries per second (QPS) eventually made replication lag a serious problem.
MySQL’s replication process, especially in its traditional form, is single-threaded. This means that even if the primary database handles many write operations efficiently, the replicas fall behind because they process changes one at a time. When the volume of writes crosses a certain threshold, the replicas can’t keep up. They begin to lag, causing stale data issues and inconsistencies.
See the diagram below that shows the MySQL replication process.
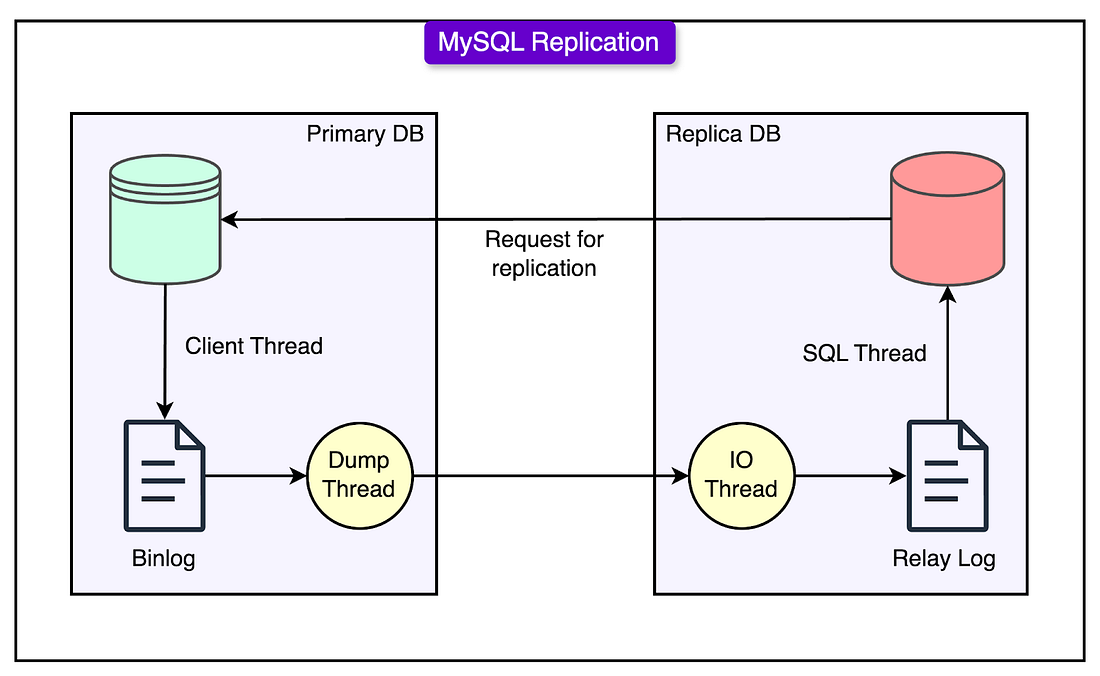
To address this, YouTube engineers introduced a tool called Prime Cache.
Prime Cache reads the relay log (a log of write operations that replicas use to stay in sync with the primary). It inspects the WHERE clauses of upcoming queries and proactively loads the relevant rows into memory (cache) before the replica needs them.
Here’s how it helps:
Normally, a replica processes a write operation and must fetch data from a disk as needed.
Prime Cache pre-loads the necessary data into memory, turning what was previously disk-bound work into memory-bound operations.
As a result, the replication stream becomes faster because memory access is much quicker than disk access.
This optimization significantly improved replication throughput. Replicas were now able to stay more closely in sync with the primary, even under high write loads.
While Prime Cache wasn’t a permanent fix, it allowed YouTube to handle a much higher volume of writes before needing to implement more complex scaling strategies like sharding.
Sharding and Vertical Splitting
As YouTube's backend continued to grow, even optimized replication couldn’t keep up with the sheer scale of the data. The size of the database itself became a bottleneck. It was too large to store efficiently on a single machine, and the load was too heavy for any one server to handle alone.
To address this, YouTube adopted two complementary strategies: vertical splitting and sharding.
Vertical Splitting
Vertical splitting involves separating groups of related tables into different databases.
For example, user profile data might be stored in one database, while video metadata is stored in another. This reduces the load on any single database and allows independent scaling of different components.
Sharding
Sharding takes this a step further by dividing a single table’s data across multiple databases, based on some key, often a user ID or a data range. Each shard holds only a portion of the overall data, which means that write and read operations are spread across many machines instead of one.
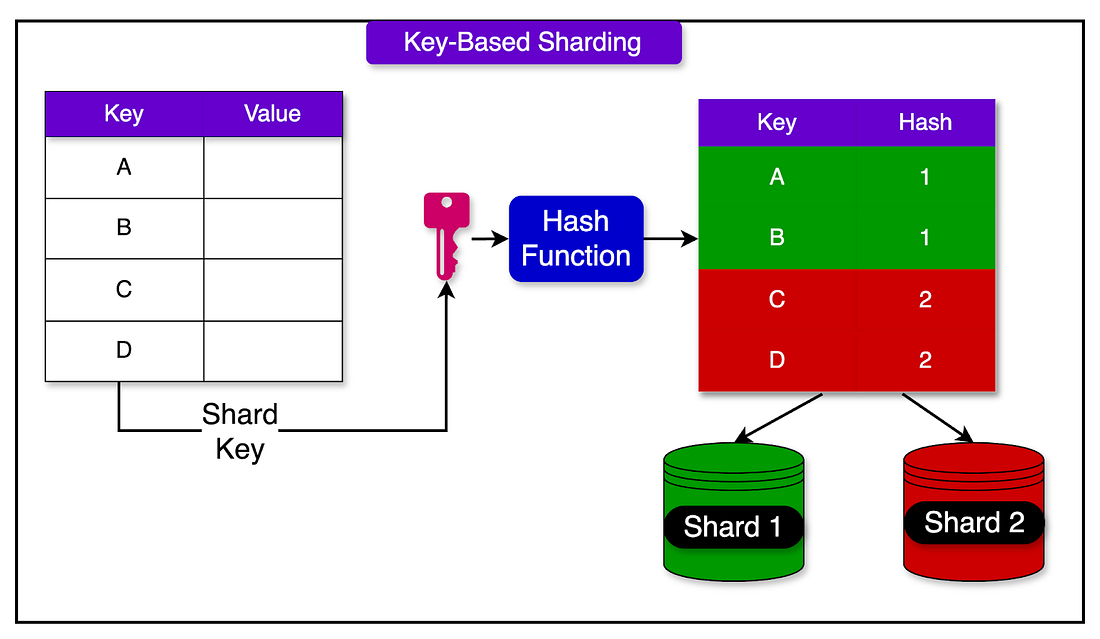
Sharding comes with some trade-offs as well:
Transactions that span multiple shards are difficult to coordinate, so strong guarantees like atomicity and consistency across shards are often sacrificed.
Queries that need data from multiple shards or tables may no longer work as expected.
The application must now know how to route queries to the correct shard and how to handle cross-shard queries when needed.
For certain types of queries that span shards, special indexing and synchronization logic are required.
To cope with this complexity, YouTube's client logic evolved significantly. It was no longer enough to simply connect to a database and send queries. The client now needed to determine whether a read should go to a replica or the master, decide which shard a query should be routed to, based on the query’s WHERE clause, and maintain and update cross-shard indexes where needed.
This shift placed more responsibility on the application layer, but it also enabled YouTube to scale far beyond the limits of a single MySQL instance.
One of the most powerful features of Vitess is its ability to automate sharding. Here’s how automatic sharding works in Vitess:
An engineer specifies that an existing shard (for example, one with too much data or traffic) needs to be split. This might be from 1 shard into 4, 16, or more.
In the background, Vitess sets up new MySQL instances, initializes them with the schema, and begins copying data.
Engineers can check the progress using Vitess tools. Once data has been moved and validated, the system signals readiness.
When everything is in place, the engineer authorizes a traffic switch. Vitess automatically redirects queries to the new shards and updates its metadata.
Once confirmed, the original overburdened shard is phased out of production.
The process is built to minimize downtime and manual intervention.
Query Routing with VTTablet and VTGate
In a sharded database environment like YouTube's, sending SQL queries to the right database instance becomes a challenge.
Vitess solves tchallenge with two key components: VTTablet and VTGate.
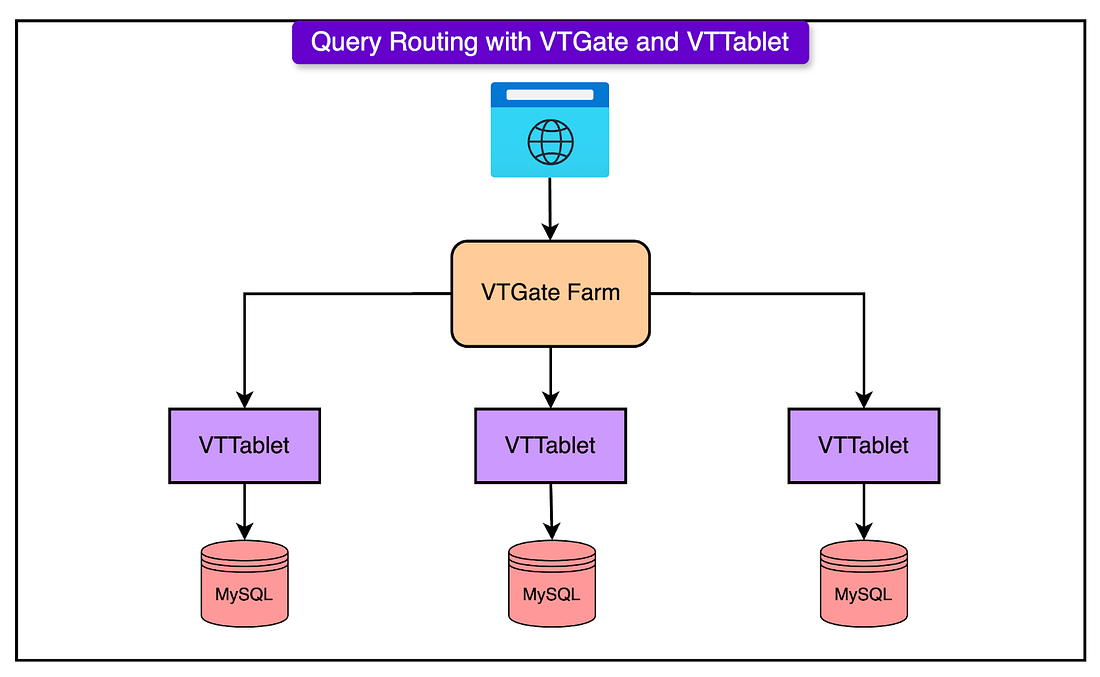
VTGate is a query router. It acts as the main entry point for all application queries. When an application sends an SQL statement, it doesn't need to know which shard to talk to or whether the data lives in one table or across several databases. VTGate handles all of that logic.
VTTablet sits in front of each MySQL instance (each shard). It acts as a lightweight proxy, but with several advanced capabilities:
Manages connection pooling: Rather than allowing thousands of direct connections to MySQL, which would overwhelm it, VTTablet maintains a limited set of pooled connections and serves multiple app queries efficiently.
Query safety checks: VTTablet inspects every incoming query. If a query is missing a LIMIT clause or is likely to return an excessive number of rows, VTTablet may block it or return an error.
Performance management: VTTablet tracks how long queries run and can kill long-running or resource-intensive ones.
Data validation and caching: It interfaces with the row cache, handles invalidations, and ensures data consistency without hitting MySQL for every request.
Vitess uses its own SQL parsers in both VTGate and VTTablet to understand the structure and intent of each query. While it doesn’t support every edge-case feature of MySQL, it covers nearly all common SQL syntax used in typical applications.
Reparenting and Backups in Vitess
Soon, the YouTube engineering team had to deal with the complexity of managing thousands of database instances.
Manual operations that once took a few minutes became risky and time-consuming. Even small mistakes (like misconfiguring a replica or pointing it to the wrong primary) could cascade into major outages.
Vitess was designed to automate many of these routine but critical database management tasks, such as reparenting and backups.
Reparenting
Reparenting is the process of promoting a replica to become the new primary if the current primary fails or needs to be taken offline.
Without automation, reparenting is a multi-step, manual process that involves the following steps:
Identify the failure.
Promote a suitable replica.
Update all other replicas to follow the new primary.
Reroute application traffic.
Even if each step takes only a few seconds, the total time can be significant. Worse, human error during this sensitive process can lead to data inconsistencies or prolonged downtime.
Vitess simplifies reparenting through its orchestration layer, powered by a lock server and specialized workflow components.
Backup Management
Vitess also automates backups. Rather than requiring administrators to manually bring down a server and extract data, Vitess tablets can initiate and manage backups on their own. They can perform these tasks without interrupting service, thanks to the separation between primary and replica roles.
This automation is critical at scale. With potentially thousands of database instances across many data centers, manual backups and recovery are not just inefficient, they’re impractical and error-prone.
Core Vitess Features That Helped YouTube Scale
Below is a detailed breakdown of the features that helped Vitess serve the needs of YouTube in terms of scaling.
1 - Connection Pooling
In MySQL, each client connection consumes memory. At YouTube's scale, with tens of thousands of simultaneous user requests, allowing each web server to directly connect to MySQL would quickly exhaust server memory and crash the system.
Vitess solves this with connection pooling, managed by VTTablet:
All incoming connections are handled by a smaller pool of MySQL connections.
This prevents memory exhaustion and reduces the load on the MySQL server.
When a new master comes online (for example, after failover), the system rapidly reconnects and resumes full service without downtime.
2 - Query Safety
In large teams, even well-intentioned developers can accidentally write inefficient queries. Vitess implements multiple safety mechanisms:
Row limits: If a query lacks a LIMIT clause and risks returning an enormous dataset, VTTablet automatically adds a limit or blocks the query.
Blacklisting: Administrators can blacklist problematic queries so they are never executed.
Query logging and statistics: Vitess logs all query behavior, including execution time, error frequency, and resource use. This data is critical for detecting misbehaving queries early.
Timeouts: Long-running queries are automatically killed to prevent resource hogging.
Transaction limits: Vitess enforces a cap on the number of open transactions, avoiding MySQL crashes from transaction overload.
3 - Reusing Results
In high-traffic environments, popular queries can become hotspots. Thousands of users might request the same data at the same time. In vanilla MySQL, each query would be independently executed, increasing CPU and disk usage.
Vitess handles this intelligently. When a request arrives for a query that is already in progress, VTTablet holds the new request until the first one is completed. Once the initial result is ready, it is shared across all waiting requests.
4 - Vitess Row Cache vs MySQL Buffer Cache
MySQL's buffer cache loads 16KB blocks from disk into memory, regardless of how many rows are needed. This works well for sequential reads but performs poorly for random-access patterns, which are common in modern web apps.
Vitess implements its row-level cache, optimized for random access:
It uses memcached to cache individual rows by primary key.
When a row is updated, the cache is invalidated.
If the system is operating in replica mode, Vitess listens to the MySQL replication stream and uses it to invalidate cached rows in real-time.
This means the cache stays accurate without relying on manual expiry times and delivers faster responses for frequently accessed records.
5 - System Fail-Safes To Protect Against Overload
Beyond query and connection management, Vitess implements broader fail-safes:
Idle or long transactions are terminated, reducing memory leaks and deadlocks.
Rate limits can be enforced to prevent specific users or services from flooding the database.
Detailed metrics and dashboards help Site Reliability Engineers (SREs) quickly spot and fix performance regressions.
Conclusion
As YouTube scaled to serve billions of users, its backend faced significant challenges in database performance, reliability, and manageability.
Initially relying on MySQL, the platform encountered limitations with connection capacity, replication lag, and query safety.
To address this, YouTube developed Vitess: a powerful, open-source database clustering system that extends MySQL’s scalability while adding critical features. Vitess introduced connection pooling to prevent overload, query safety mechanisms to guard against inefficient operations, and a smart query router to handle sharded data across multiple servers.
Features like result reuse and a custom row cache enhanced efficiency, while real-time cache invalidation ensured consistency. Automation of tasks such as reparenting and backup further reduced operational complexity.
Together, these innovations enabled YouTube to maintain high availability, rapid performance, and data integrity at a massive scale.
References:
Like
Comment
Restack
© 2025 ByteByteGo
548 Market Street PMB 72296, San Francisco, CA 94104
Unsubscribe

by "ByteByteGo" <bytebytego@substack.com> - 11:36 - 8 Apr 2025 -
Partnership
Dear Team, I hope this email finds you well. We are always looking to grow our community of valued partners. As a registered vendor, you'll have the opportunity to collaborate with us on various projects, supply goods and services, and contribute to our mission of delivering exceptional air travel experiences. We would like to register your Company as a supplier, vendor and intending partners for Oman Air 2025/2027 projects procurement systems Kindly indicate your interest by requesting for a vendor application form and registration terms & conditions document. Thank you for considering this invitation. Many thanks, Salah Al Bulushi Senior Vice President - Supply Chain Management Oman Air Muscat, Oman
by "Oman Air Vendor Registration" <vendors@omanair-tenders.com> - 05:33 - 8 Apr 2025 -
Final Invitation: Transform Your Finances and Your Golf Game
This is your final invitation to explore the remarkable opportunities... 

Hello Sir/Madam,
This is your final invitation to explore the remarkable opportunities on offer at Fairway Wealth Partners. By teaming up with our recommended IFA, you can:
- Strengthen your financial future through expert advice on pensions, investments, and life cover.
- Access the very best golf events and courses all year round.
- Leverage your time on the fairway to build professional connections.
- If you have wealth to protect, pensions to organise, or life cover to arrange, this partnership is tailored for you. Let’s maximise both your assets and your leisure time.
Reply now or click here to schedule a no-obligation consultation. We look forward to hearing from you soon!
Best regards,
Richard Ellis
Project Director
+44(0)7380 337 315
+44(0)1924 975 502



by "Richard - Fairway Wealth Partners" <info@fairwaywealthpartners.com> - 04:32 - 8 Apr 2025 -
Boosting consumer centricity in US healthcare
On McKinsey Perspectives
6 key areas Brought to you by Alex Panas, global leader of industries, & Axel Karlsson, global leader of functional practices and growth platforms
Welcome to the latest edition of Only McKinsey Perspectives. We hope you find our insights useful. Let us know what you think at Alex_Panas@McKinsey.com and Axel_Karlsson@McKinsey.com.
—Alex and Axel
—Edited by Querida Anderson, senior editor, New York
This email contains information about McKinsey's research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this email because you subscribed to the Only McKinsey Perspectives newsletter, formerly known as Only McKinsey.
Copyright © 2025 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "Only McKinsey Perspectives" <publishing@email.mckinsey.com> - 01:30 - 8 Apr 2025 -
Bring AI into your ERP processes
Discover how AI-ready data can streamline your operations.

SAP WEBCAST
Fuel your most important business processes with AI-ready data that is connected, actionable, and contextualWe’re thrilled to introduce our upcoming webcast, “Fuel your most important business process with AI-ready data.”
Join us on April 23 to explore how a harmonized data foundation empowers you to take full advantage of AI.
Join Threveni Mohan, Demo Portfolio Lead for BDC, Michel Haesendonckx, Global Functional Lead – oCFO, as well as Som Suresh, Senior Manager at Deloitte to:- Explore how to use your data to enable AI, deliver tailored insights, and optimize decision-making.
- Discover how AI-enabled ERP can optimize working capital management, sales and distribution, and people analytics.
- See a live walkthrough demonstrating real-world scenarios and solutions.
Don’t miss this opportunity to see how AI-ready data can help you elevate your business processes


Contact us
See our complete list of local country numbers



SAP (Legal Disclosure | SAP)
This e-mail may contain trade secrets or privileged, undisclosed, or otherwise confidential information. If you have received this e-mail in error, you are hereby notified that any review, copying, or distribution of it is strictly prohibited. Please inform us immediately and destroy the original transmittal. Thank you for your cooperation.
You are receiving this e-mail for one or more of the following reasons: you are an SAP customer, you were an SAP customer, SAP was asked to contact you by one of your colleagues, you expressed interest in one or more of our products or services, or you participated in or expressed interest to participate in a webinar, seminar, or event. SAP Privacy Statement
This email was sent to info@learn.odoo.com on behalf of the SAP Group with which you have a business relationship. If you would like to have more information about your Data Controller(s) please click here to contact webmaster@sap.com.
This offer is extended to you under the condition that your acceptance does not violate any applicable laws or policies within your organization. If you are unsure of whether your acceptance may violate any such laws or policies, we strongly encourage you to seek advice from your ethics or compliance official. For organizations that are unable to accept all or a portion of this complimentary offer and would like to pay for their own expenses, upon request, SAP will provide a reasonable market value and an invoice or other suitable payment process.
This e-mail was sent to info@learn.odoo.com by SAP and provides information on SAP’s products and services that may be of interest to you. If you received this e-mail in error, or if you no longer wish to receive communications from the SAP Group of companies, you can unsubscribe here.
To ensure you continue to receive SAP related information properly, please add sap@mailsap.com to your address book or safe senders list.
by "SAP" <sap@mailsap.com> - 10:37 - 7 Apr 2025 -
BEIJING HOLTOP/Professional factory with 20+ years of experiences for HVAC system units from China
Dear info,
Good morning!
I just visited your website, and know that you are the leading wholesaler/importer in your local market for HVAC industry, with a prestigious brand.
You may be happy to find a new reliable OEM/ODM supplier of HVAC system heat recovery ventilation units with superior quality & Reasonable prices. You can select from an abundant variety of our ERVs/HRVs and AHU with different specifications and installation types.
Since 2002, our company specialized in producing and supplying Energy Recovery Ventilation(ERV), Air Handling Units(AHU), chillers, air conditioners, and Plate & Rotary Heat Exchangers, etc HVAC products. Our company has the largest ERV/HRV manufacturing base in China. We have ISO9001/ISO14001/ISO45001 certification and our products have CE/CSA/CB certifications. We not only have HOLTOP brand, but also we are ERV/HRV ODM/OEM supplier of Johnson Controls-York, Mitsubishi, Hisense Hitachi, Midea...etc in China.
I am confident that when you work with us, you will have the same satisfaction likes our other old customers. To enable you to get a good understanding of our quality and service, we would like to extend a very special offer for your first order, with 5% (only limited to the first container).If interested, please email me directly to talk more. In the next email, I will attach you the product catalogs. Please tell me what items are more saleable for you.
Best regards,Jun Gao
Beijing Holtop Air Conditioning Co.,Ltd
by "Gowri Kir" <kirgowri358@gmail.com> - 12:38 - 7 Apr 2025 -
Reliable Hotel Supplies for Accor Group
Dear info,
As the procurement supervisor at Accor Group, you know the importance of reliable suppliers. Miki Travel Essentials offers a range of hotel supplies that are both affordable and of consistent quality, perfect for maintaining your brand’s standards across multiple locations.
Would you be interested in a quick discussion on how we can collaborate to meet your supply needs? I can provide further details and samples for your consideration.
Looking forward to hearing from you.
Best,
Fathima Ahmed
Manufacturing Director
Miki Travel Essentials Co., Ltd.
by "Kennedi Jordan" <k58327102@gmail.com> - 12:11 - 7 Apr 2025 -
Spring Promotion: Free Extra Spare Parts with Customized AR-T7
Dear info,
Happily to announce that ARTRED Autumn Spring promotion is coming with our new designed model AR-T7! Partners around the world are sincerely invited to this great opening!
New model T7 with some major improved advantages:
Electric lifting brush & squeegee
Hidden suction pipe
LED headlight & taillight
Front double wheel design
Now, you can get it at the price $1499 only.
Besides, we offer you more:
1. Buy 1 unit of T7, you get 1 set of extra wearing parts, including brush,cleaning pad & pad holder;
2. Container order, you get 1 set of the major spare parts, including drive motor, brush motor&lifting motor.
If you have any interest in T7, don’t hesitate to reach us for more details.
Best regards,
ARTRED SMART TECH CO. LTD.
info@artredclean.com
Web:www.artredclean.com
SubscribeUnsubscribe
by "Barbara" <Barbara@art-red.com> - 08:45 - 7 Apr 2025 -
A leader’s guide to making work more enjoyable
Leading Off
Engage and enjoy Brought to you by Alex Panas, global leader of industries, & Axel Karlsson, global leader of functional practices and growth platforms
Welcome to the latest edition of Leading Off. We hope you find our insights useful. Let us know what you think at Alex_Panas@McKinsey.com and Axel_Karlsson@McKinsey.com.
—Alex and Axel
It’s an old saying with many variations: “If you love what you do, you’ll never work a day in your life.” For leaders, this can mean getting satisfaction from their own work and helping employees find purpose and fulfillment. Bringing more enjoyment to the workplace can be an important element of human-centric leadership, which benefits an organization’s culture as well as its performance. This week, we look at how leaders can make work more engaging, fun, and rewarding for everyone.
Adopting a generous mindset is a key shift for leaders in today’s high-pressure workplace environment, where it’s no longer enough to focus on strategy or to have all of the answers. Leaders can be more effective when they give more of themselves to employees, according to McKinsey’s Brooke Weddle, Bryan Hancock, and Dana Maor. “This means sharing the most precious resources you have as a leader—time, experience, and wisdom—to foster a culture of collaboration, openness, empowerment, and care,” Maor says in an episode of the McKinsey Talks Talent podcast. Weddle notes that generosity of leadership can take many forms, including giving constructive feedback and taking time to address employees’ development goals in a kind and purposeful way. Being more generous with employees also pays off for leaders themselves. “There’s a further benefit for you because we all get rewarded psychologically when we’re helping others,” Hancock says. “Generosity at work raises your happiness and your work satisfaction.”
That’s how much more likely employees are to report burnout symptoms when they experience high levels of toxic workplace behavior, according to a global survey from the McKinsey Health Institute. McKinsey’s Barbara Jeffery, Erica Coe, Kana Enomoto, and their coauthors note that toxic behaviors pose a major challenge to leaders, as workers experiencing burnout symptoms are six times more likely to report their intention to leave their employers within three to six months.
That’s McKinsey Senior Partner Aaron De Smet on how gen AI and other technological innovations can enable employees to focus on doing harder but more enjoyable work—that is, work that relies on skills such as judgment, creativity, and collaboration. This trend applies to employees across industries and roles: not only tech workers but also healthcare workers, educators, middle managers, and others. “As work becomes more innovative and collaborative, organizations can be more proactive in attracting and retaining the best people,” De Smet says.
People who find ways to break out of their comfort zone, or “competency trap,” can reinvigorate their careers. Media executive and journalist Gwendolyn Bounds found her escape in obstacle course racing. “I, too, was caught in a competency trap,” she says in an Author Talks interview. Bounds chronicles her experience in Not Too Late: The Power of Pushing Limits at Any Age. “I was in a cycle of sameness and leaning into work—and into the ways that I worked—very heavily.” Based on her own experience and her research, Bounds observes that taking on bold new challenges in life can help people in many ways, including making them more focused and successful at work. “Daily we mull over so many things, such as, ‘Did I nail that presentation?’ ‘That colleague said that really annoying thing to me at work.’ ‘Are we actually going to ever have an IPO?’” According to Bounds, “You can’t think about that when you are breathing at your limit and trying to climb a 17-foot rope while someone is chasing you.”
Humor in the workplace can be risky business—but good business when it’s done right. Joking around at work has a real ROI, according to Stanford Graduate School of Business faculty members Jennifer Aaker and Naomi Bagdonas. In their research, the authors of Humor, Seriously: Why Humor Is a Secret Weapon in Business and Life found that leaders with a sense of humor are 27 percent more motivating and inspiring, and employees who work with them are 15 percent more engaged. What’s more, these leaders’ teams are twice as creative. Bagdonas adds that knowing when to use humor in the workplace is not always about getting laughs. “It’s about being human and more connected to our colleagues,” she says. “It’s not about what I say and whether people think I’m funny; it’s about how a joke will make people feel when it lands on them.”
Lead by making the work experience better for all.
— Edited by Eric Quiñones, senior editor, New York
Share these insights
Did you enjoy this newsletter? Forward it to colleagues and friends so they can subscribe too. Was this issue forwarded to you? Sign up for it and sample our 40+ other free email subscriptions here.
This email contains information about McKinsey’s research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this email because you subscribed to the Leading Off newsletter.
Copyright © 2025 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "McKinsey Leading Off" <publishing@email.mckinsey.com> - 04:53 - 7 Apr 2025 -
How higher social mobility could improve Europe’s economy
On McKinsey Perspectives
21 initiatives for change Brought to you by Alex Panas, global leader of industries, & Axel Karlsson, global leader of functional practices and growth platforms
Welcome to the latest edition of Only McKinsey Perspectives. We hope you find our insights useful. Let us know what you think at Alex_Panas@McKinsey.com and Axel_Karlsson@McKinsey.com.
—Alex and Axel
•
Sluggish social mobility. Europe has long been a leader in improving socioeconomic mobility. Yet its progress on this front has stalled over the past decade, limiting the economic growth the continent needs to stay competitive. More than one-third of Europeans now face significant socioeconomic barriers, including lower employment rates, less-productive jobs, and slower career advancement than their peers from wealthier backgrounds, McKinsey Senior Partners Massimo Giordano and Tania Holt and coauthors explain.
—Edited by Belinda Yu, editor, Atlanta
This email contains information about McKinsey's research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this email because you subscribed to the Only McKinsey Perspectives newsletter, formerly known as Only McKinsey.
Copyright © 2025 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "Only McKinsey Perspectives" <publishing@email.mckinsey.com> - 01:39 - 7 Apr 2025 -
Re: Cosmetics Industry Contacts list
Hi, Good day to you!
We have successfully built a verified file of Cosmetics Industry contacts with accurate emails. Would you be interested in acquiring Cosmetics Industry Professionals List across North America, UK, Europe and Global?
Few Lists:
ü Cosmetics and personal care product manufacturers
ü Fragrance Manufacturers, Home Care Manufacturers
ü Cosmetics and Personal Care Brand Owners
ü Perfume& Toiletries Manufacturers
ü Private label and Contract manufacturers
ü Salon and hotel chains
ü Consultants, Packaging Professionals, etc
Our list comes with: Company/Organization, Website, Contacts, Title, Address, Direct Number and Email Address, Revenue Size, Employee Size, Industry segment.
Please send me your target audience and geographical area, so that I can give you more information, Counts and Pricing just for your review.
Thank you for your time and consideration. I eagerly await your response.
Regards,
Rebecca Baker| Customer Success Manager
B2B Marketing & Tradeshow Specialist
PWe have a responsibility to the environment
Before printing this e-mail or any other document, let's ask ourselves whether we need a hard copy
by "Rebecca Baker" <Rebecca@b2bleadsonline.us> - 12:17 - 7 Apr 2025 -
Customizable Canned Goods for Your Diverse Needs
Dear info
I trust this message finds you in good health and high spirits.
I represent Nantong Everlasting Foodstuffs Co.,Ltd ,a distinguished manufacturer and supplier of a wide array of canned goods,including sweet corn,beans,mixed vegetables,and tomatoes.We specialize in providing customized solutions to cater to the unique tastes and requirements of our clients worldwide.
I am reaching out to explore the possibility of partnering with your esteemed organization to offer our high-quality,customizable canned products.Our commitment to quality,innovation,and customer satisfaction has positioned us as a reliable choice for businesses seeking the finest canned goods.
Our Product Range:
• Sweet Corn Cans:Our sweet corn is handpicked at peak ripeness to ensure the best flavor and texture,preserved in cans for your convenience.
• Bean Cans:We offer a variety of beans,including kidney,black,and garbanzo,canned with the option for custom seasoning and preservation methods.
• Mixed Vegetable Cans:A medley of vegetables canned to your specifications,ensuring a nutritious and versatile addition to any meal.
• Tomato Cans:Our tomatoes are sourced from the finest vineries,canned in various forms such as whole,diced,or puree,and customized to your preference.
Why Choose us:
• Customization:We pride ourselves on our ability to tailor our products to meet your specific needs,whether it's size,taste,or packaging.
I am confident that our products would be a great addition to your offerings,and I am keen to discuss how can meet your specific requirements.If you are interested,I would be more than happy to arrange a call or a video conference at your earliest convenience to further explore this potential collaboration.
Thank you for considering us for your canned goods needs.We are excited about the prospect of working with you and look forward to the opportunity to serve you.
Warm regards,
Nantong Everlasting Foodstuffs Co.,Ltd
Tel:
+86-513-84890228
+86-13901470212
+86-15050621368
E-mail:ceo@ntyhfood.com
Website:https://www.ntyhfood.com
by "Eric" <Eric@ntyhfood.cn> - 09:40 - 6 Apr 2025