Archives
- By thread 5224
-
By date
- June 2021 10
- July 2021 6
- August 2021 20
- September 2021 21
- October 2021 48
- November 2021 40
- December 2021 23
- January 2022 46
- February 2022 80
- March 2022 109
- April 2022 100
- May 2022 97
- June 2022 105
- July 2022 82
- August 2022 95
- September 2022 103
- October 2022 117
- November 2022 115
- December 2022 102
- January 2023 88
- February 2023 90
- March 2023 116
- April 2023 97
- May 2023 159
- June 2023 145
- July 2023 120
- August 2023 90
- September 2023 102
- October 2023 106
- November 2023 100
- December 2023 74
- January 2024 75
- February 2024 75
- March 2024 78
- April 2024 74
- May 2024 108
- June 2024 98
- July 2024 116
- August 2024 134
- September 2024 130
- October 2024 141
- November 2024 171
- December 2024 115
- January 2025 216
- February 2025 140
- March 2025 220
- April 2025 233
- May 2025 239
- June 2025 303
- July 2025 36
-
Invitation
Good Day Sir/Madam,
Hope this email finds you well. We are pleased to invite you or your company to quote the following item
listed below:Product/Model No: PAME PLS888117 CTB FORGED 20K GLOBE VALVE
Model Number: PLS888117
Port Size: DN80
Pressure Rating: PN16
Material: stainless steel 316
Qty. 55
Compulsory, Kindly send your quotation to: orders@shellsupplychain.com
for immediate approval.Kind Regards,
Kenneth Benthem
Global Head of Procurement & Supply Chains
SHELL GLOBAL SOLUTIONS INTERNATIONAL BV
Address: Grasweg 39, 1031 HW Amsterdam, Netherlands.
VAT: NL804013019B01
Tel: +31 85 064 4637
Fax: +31 62 273 6114
by "Shell Global" <cimorelli@aruba.it> - 08:04 - 23 Mar 2025 -
The quarter’s top themes
McKinsey&Company
At #1: AI explained: Test your knowledge
by "McKinsey Top Ten" <publishing@email.mckinsey.com> - 10:26 - 23 Mar 2025 -
(Video #6 Funnel Install) Gabe Schillinger's Viral Giveaway Funnel
Get 40,000 leads for free? Is that impossible??Hey everyone!
We’re up to Day 6 of the Funnel Install series, and today’s funnel is PERFECT if you don’t have a product to sell!
But first a quick review in case you’ve been living under a rock the last week and missed everything!!
✅ Day 1 - Trey Lewellen’s e-commerce funnel
✅ Day 2 - Dan Henry's webinar funnel
✅ Day 3 - Jeff Walker’s product launch funnel
✅ Day 4 - Pedro Adao's challenge funnel
✅ Day 5 - Steve Larsen’s affiliate funnel
Next in line is Gabe Schillinger!
GO HERE TO WATCH THE VIDEO FROM GABE SCHILLINGER AND STEAL HIS VIRAL GIVEAWAY FUNNEL FOR FREE! >>

The framework he’s about to teach you has helped Gabe grow his business, get featured in Billboard, and even land on stage at Funnel Hacking Live. ;)
If you’ve ever struggled to grow your list or wanted a way to get leads on autopilot… This is it!! THIS is the funnel you need!!GO HERE TO WATCH THE VIDEO FROM GABE SCHILLINGER AND STEAL HIS VIRAL GIVEAWAY FUNNEL FOR FREE! >>
Tomorrow is the final day of this series… and trust me, you don’t want to miss it!
See you then!
Russell Brunson
P.S. - Don’t forget, you’re just one funnel away….
P.P.S - To dive in and start implementing what these experts are teaching, you’ll need to get a ClickFunnels account. If you don’t have one yet, I have a special 2-week FREE TRIAL link HERE >>
© Etison LLC
By reading this, you agree to all of the following: You understand this to be an expression of opinions and not professional advice. You are solely responsible for the use of any content and hold Etison LLC and all members and affiliates harmless in any event or claim.
If you purchase anything through a link in this email, you should assume that we have an affiliate relationship with the company providing the product or service that you purchase, and that we will be paid in some way. We recommend that you do your own independent research before purchasing anything.
Copyright © 2018+ Etison LLC. All Rights Reserved.
To make sure you keep getting these emails, please add us to your address book or whitelist us. If you don't want to receive any other emails, click on the unsubscribe link below.
Etison LLC
3443 W Bavaria St
Eagle, ID 83616
United States
by "Russell @ ClickFunnels" <noreply@clickfunnelsnotifications.com> - 09:51 - 22 Mar 2025 -
The week in charts
The Week in Charts
Attitudes toward AI, e-commerce deliveries, and more Share these insights
Did you enjoy this newsletter? Forward it to colleagues and friends so they can subscribe too. Was this issue forwarded to you? Sign up for it and sample our 40+ other free email subscriptions here.
This email contains information about McKinsey's research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this email because you subscribed to The Week in Charts newsletter.
Copyright © 2025 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "McKinsey Week in Charts" <publishing@email.mckinsey.com> - 03:08 - 22 Mar 2025 -
EP155: The Shopify Tech Stack
EP155: The Shopify Tech Stack
Basically, Single Sign-On (SSO) is an authentication scheme.͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ Forwarded this email? Subscribe here for more😘Kiss bugs goodbye with fully automated end-to-end test coverage (Sponsored)

Bugs sneak out when less than 80% of user flows are tested before shipping. However, getting that kind of coverage (and staying there) is hard and pricey for any team.
QA Wolf’s AI-native service provides high-volume, high-speed test coverage for web and mobile apps, reducing your organization’s QA cycle to less than 15 minutes.
They can get you:
24-hour maintenance and on-demand test creation
Zero flakes, guaranteed
Engineering teams move faster, releases stay on track, and testing happens automatically—so developers can focus on building, not debugging.
Drata’s team of 80+ engineers achieved 4x more test cases and 86% faster QA cycles.
⭐Rated 4.8/5 on G2.
This week’s system design refresher:
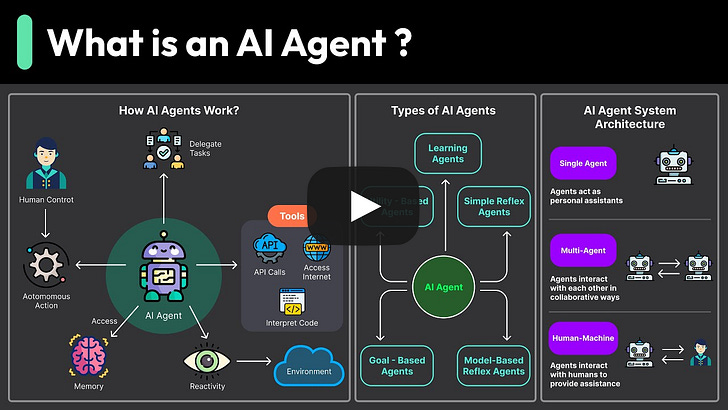
What Are AI Agents Really About? (Youtube video)
What is SSO (Single Sign-On)?
How Java Virtual Threads Work?
Redis VS Memcached
The Shopify Tech Stack
Hiring Now: Tech Roles
SPONSOR US
What Are AI Agents Really About?
What is SSO (Single Sign-On)?
Basically, Single Sign-On (SSO) is an authentication scheme. It allows a user to log in to different systems using a single ID.
The diagram below illustrates how SSO works.

Step 1: A user visits Gmail, or any email service. Gmail finds the user is not logged in and so redirects them to the SSO authentication server, which also finds the user is not logged in. As a result, the user is redirected to the SSO login page, where they enter their login credentials.
Steps 2-3: The SSO authentication server validates the credentials, creates the global session for the user, and creates a token.
Steps 4-7: Gmail validates the token in the SSO authentication server. The authentication server registers the Gmail system, and returns “valid.” Gmail returns the protected resource to the user.
Step 8: From Gmail, the user navigates to another Google-owned website, for example, YouTube.
Steps 9-10: YouTube finds the user is not logged in, and then requests authentication. The SSO authentication server finds the user is already logged in and returns the token.
Step 11-14: YouTube validates the token in the SSO authentication server. The authentication server registers the YouTube system, and returns “valid.” YouTube returns the protected resource to the user.
The process is complete and the user gets back access to their account.
Over to you:
Have you implemented SSO in your projects? What is the most difficult part?
What’s your favorite sign-in method and why?
How Java Virtual Threads Work?
Virtual Threads are lightweight threads introduced in Java 19 (Preview) and Java 21 (Stable). They allow Java to create millions of threads efficiently, helping handle concurrent tasks without wasting memory or CPU.

Virtual Threads do not map 1:1 to OS Threads and do not replace the original Platform Threads. The Platform Threads are backed by the OS Threads and are sometimes also known as Carrier Threads in this context.
Think of the Platform Threads as a small group of workers, and Virtual threads as tasks. With Virtual threads, tasks are given to workers only when needed, allowing one worker to handle thousands of tasks efficiently.
Here’s how Virtual Threads work:Virtual Threads run on top of Platform Threads. The JVM schedules them onto a small number of Platform Threads.
When a Virtual Thread starts, the JVM assigns it to a normal OS-backed Platform Thread.
Virtual Threads can also handle CPU-intensive work, but their real advantage is in scenarios with a high number of I/O-bound or concurrent tasks.
If the Virtual Thread performs a blocking operation (like I/O, database call, sleep, etc.), the JVM unmounts it from the Platform Thread. However, this does not block the underlying OS Thread as such.
The Platform thread is freed up to handle another Virtual Thread.
When the blocking operation finishes, the Virtual Thread is rescheduled on any available Platform thread.
Over to you: Have you used Virtual Threads?
Redis VS Memcached
The diagram below illustrates the key differences.

The advantages of data structures make Redis a good choice for:
Recording the number of clicks and comments for each post (hash)
Sorting the commented user list and deduping the users (zset)
Caching user behavior history and filtering malicious behaviors (zset, hash)
Storing boolean information of extremely large data into small space. For example, login status, membership status. (bitmap)
The Shopify Tech Stack

Shopify is a multi-channel commerce platform for small and medium businesses. It allows merchants to create a shop and sell products wherever they want.
Here’s the Shopify Tech Stack, which powers more than 600,000 merchants and serves 80,000 requests per second during peak traffic.
Programming Languages & UI: They use Ruby, Typescript, Lua, and React
Backend & Servers: They use Ruby on Rails, Nginx, OpenResty, and GraphQL.
Data: They use MySQL, Redis, and Memcached.
DevOps: They use GitHub, Docker, Kubernetes, GKE, BuildKite, and ShipIt. ShipIt has been also made open source.
Reference: E-Commerce at Scale: Inside Shopify's Tech Stack
Hiring Now: Tech Roles
I attended the A16Z Speedrun Demo Day last week. Jordan Mazer from A16Z was kind enough to compile a list of their portfolio companies that are hiring:
Sweatpals - Fitness creator & meetup platform (Job Listing)
FLORA - Combining creative AI models in one Figma-like infinite canvas (Job Listing)
Plots - Live events discovery platform (Job Listing)
Darwin - Interactive videos (Job Listing)
Trophi.ai - AI-backed coaching (Job Listing)
Blank - AI image generator (Job Listing)
Intangible - A "Canva for 3D" built to help creatives visualize ideas. Email talent@intangible.ai to apply for open positions including VP Eng, Full stack engineer, AI systems engineer.
Coverd - Gamified credit solution platform (Job Listing)
Genway - Generate insights with depth and scale using AI-interviewers (Job Listing)
Coverstar - A safe TikTok alternative for kids (JobListing)
KHK Games - Sweepstakes online poker platform (Job Listing)
Sunflower - A toolkit to help users stay sober (Job Listing)
Echo Chunk - Builds self-generating strategy games (Job Listing)
Human Computer - Game studio focused on story telling
AvatarOS - Authentic cross-platform 3D Avatars (Job Listing)
Nunu.ai - Building intelligent agents to test and play games - automating QA needs (Job Listing)
Hedra - Works on foundation models for generative video (Job Listing)
k-ID - Creates safer experiences for kids playing video games (Job Listing)
Neon - Off-platform mobile payments & web shop infrastructure (Job Listing)
Altera - Creates digital human beings (Job Listing)
Crater Studios - Game studio (Job Listing)
Quago - Create insights and predictions using in-game device sensor data (Job Listing)
Favorited - Live video social network (Job Listing)
Rascal Games - Builds multiplayer games (Job Listing)
Uthana - AI for 3d character animation (Job Listing)
You can find more job openings at a16z speedrun talent network
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.
Like
Comment
Restack
© 2025 ByteByteGo
548 Market Street PMB 72296, San Francisco, CA 94104
Unsubscribe

by "ByteByteGo" <bytebytego@substack.com> - 11:37 - 22 Mar 2025 -
(Video #5 Funnel Install) Steve Larsen’s Affiliate Funnel
the EXACT formula for making $ from other people’s products!It’s almost the weekend…
But you know what’s better than the weekend??
Day 5 of the Funnel Install series!!
And pay close attention today, because I think this presentation is the missing link for many of you out there!
So far, you’ve seen:
✅ Day 1 - Trey Lewellen’s e-commerce funnel
✅ Day 2 - Dan Henry's webinar funnel
✅ Day 3 - Jeff Walker’s product launch funnel
✅ Day 4 - Pedro Adao's challenge funnel
In today’s video Steve’s breaking down how to find the right affiliate products that practically sell themselves!
And… of course he’s giving YOU a copy of his affiliate funnel that does all the selling FOR YOU. (Even while you sleep!!!)
GO HERE TO WATCH THE VIDEO FROM STEVE LARSEN AND STEAL HIS AFFILIATE FUNNEL FOR FREE! >>

Don’t have your own product yet???
Steve’s funnel is the ultimate shortcut to making money online…
❌Without inventory…
❌Without product creation…
❌Without complicated setups…
Just plug in this funnel, drive traffic, and start earning commissions!!
GO HERE TO WATCH THE VIDEO FROM STEVE LARSEN AND STEAL HIS AFFILIATE FUNNEL FOR FREE! >>
OK… We’re closing in on the final days of the Funnel Install Series!
Two left, and we saved the best for last!
Even though it’s the weekend, be sure to check your email tomorrow and Sunday!
Trust me, you won’t want to miss what’s coming next!
See you tomorrow!
Russell Brunson
P.S. - Don’t forget, you’re just one funnel away….
P.P.S - To dive in and start implementing what these experts are teaching, you’ll need to get a ClickFunnels account. If you don’t have one yet, I have a special 2-week FREE TRIAL link HERE >>
© Etison LLC
By reading this, you agree to all of the following: You understand this to be an expression of opinions and not professional advice. You are solely responsible for the use of any content and hold Etison LLC and all members and affiliates harmless in any event or claim.
If you purchase anything through a link in this email, you should assume that we have an affiliate relationship with the company providing the product or service that you purchase, and that we will be paid in some way. We recommend that you do your own independent research before purchasing anything.
Copyright © 2018+ Etison LLC. All Rights Reserved.
To make sure you keep getting these emails, please add us to your address book or whitelist us. If you don't want to receive any other emails, click on the unsubscribe link below.
Etison LLC
3443 W Bavaria St
Eagle, ID 83616
United States
by "Russell @ ClickFunnels" <noreply@clickfunnelsnotifications.com> - 10:36 - 21 Mar 2025 -
LOS ANGELES CAMP FAIR 2025 : All Attendees and Visitors
Hi,
Hope you are doing well!
We are following up to confirm if you are interested in acquiring the Visitors/Attendees List.
Event Details:
Event Name: LOS ANGELES CAMP FAIR 2025Date:23 Mar 2025
Location: CAL STATE UNIVERSITY, NORTHRIDGE, US
Attendees/Visitors Count:3,754
Each line of the list contains:
Contact Name, Email Address, Company Name, URL/Website, Phone Number, and Title/Designation.In today's digital era, the most effective way to propel your business forward is through digital strategies. This list empowers you to effortlessly disseminate information about your organization and products directly and digitally to potential buyers, laying the groundwork for numerous valuable client connections.
We are offering the list at a discounted cost. Please let us know if you're interested, and we will share more details with you.
Looking forward to hearing from you!
by elise.turner@topleads.live - 07:25 - 21 Mar 2025 -
Any day now: The gen AI revolution
The Shortlist
Emerging ideas for leaders Curated by Alex Panas, global leader of industries, & Axel Karlsson, global leader of functional practices and growth platforms
Welcome to the latest edition of the CEO Shortlist, a biweekly newsletter of our best ideas for the C-suite. This week, we share updates from the front lines of gen AI in the enterprise. You can reach us with thoughts, ideas, or suggestions at Alex_Panas@McKinsey.com and Axel_Karlsson@McKinsey.com. Thank you, as ever.
—Alex and Axel
Holding for takeoff. Gen AI adoption is taking longer than some expected. But the pace of change is accelerating, regardless of whether companies are on board or not. On our most recent edition of the At the Edge podcast, we spoke with three industry experts on how companies can catch up and thrive in a world where widespread AI is not just likely, they say, but inevitable.
It’s never just tech. Getting real value out of AI requires transformation, not just shiny new tech tools. It’s a question of successful change management and mobilization, which is why C-suite leadership is essential. Our latest McKinsey Global Survey on AI reveals the steps companies are taking today to deliver value on their gen AI investments.
We hope you find these ideas inspiring and helpful. See you in a couple of weeks with more McKinsey ideas for the CEO and others in the C-suite.Share these insights
This email contains information about McKinsey’s research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this email because you subscribed to The CEO Shortlist newsletter.
Copyright © 2025 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "McKinsey CEO Shortlist" <publishing@email.mckinsey.com> - 04:44 - 21 Mar 2025 -
Re: OCTG steel pipe long trem supplier
Dear Manager
Lily again, here share our latest delivery photos of N80 Tubing / Pup Joints / Coupling / Cross Over to Middle East.
We also have Casing, Line Pipe, Drill Pipe, HWDP, Drill Collar, Torque Ring, Float collar and etc.
Welcome to contact me, if you have any enquiry. Please kindly note that this email is only for marketing, any demand just contact my WORKING ACCOUNT: lilyl@bestar-pipe.com / lilyl@bestar-tube.com
 Or if you want to get any market trend/freight cost/free sample/quotation, pls feel free to contact me at any time!
Or if you want to get any market trend/freight cost/free sample/quotation, pls feel free to contact me at any time!
*If my email bothering you, pls let me know so I can delete the address from my list.
Thanks&Best regards!
Lily Li| Overseas Business Dept.
Bestar Steel Co., Ltd|Shinestar Holdings Group
( Mobile /whatsapp: (0086)137-9019-6297
:Email: lilyl@bestar-pipe.com lilyl@bestar-tube.com
:http://www.bestartubes.com / www.bestarpipe.com
No.9 Xiangfu Road,Yuhua District, Changsha, Hunan, China 410000
---------------------------------------------------------------------------------------------
Steel Pipe Manufacturer Since 1993

by "Lily" <lily@pipe.bestar-tube.com> - 03:56 - 21 Mar 2025 -
What habits can help CEOs succeed?
On McKinsey Perspectives
Mindsets for success Brought to you by Alex Panas, global leader of industries, & Axel Karlsson, global leader of functional practices and growth platforms
Welcome to the latest edition of Only McKinsey Perspectives. We hope you find our insights useful. Let us know what you think at Alex_Panas@McKinsey.com and Axel_Karlsson@McKinsey.com.
—Alex and Axel
•
A peerless role. From setting a company’s direction to connecting with stakeholders and managing personal effectiveness, a CEO’s job is as demanding as it comes. Given CEOs’ long lists of personal priorities and professional duties, how do they maintain high performance? After talking with more than 100 leaders of companies around the world and analyzing interviews from CEO Excellence: The Six Mindsets That Distinguish the Best Leaders from the Rest—a McKinsey book that just celebrated its third anniversary—Senior Partners Gautam Kumra, Joydeep Sengupta, and Mukund Sridhar and their coauthors compiled the daily routines that most contribute to the leaders’ effectiveness in the role.
•
Daily practices. For many CEOs, the journey toward excellence is paved with small habits that leaders weave into their daily routines. To manage stress, for instance, some top executives breathe deeply for up to one minute before joining an important meeting, while others maintain a consistent sleep routine, even while traveling. Explore the practices and mindsets that help CEOs excel, and look out for the follow-up to CEO Excellence, called A CEO for All Seasons: Mastering the Cycles of Leadership, which publishes in October.
—Edited by Belinda Yu, editor, Atlanta
This email contains information about McKinsey's research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this email because you subscribed to the Only McKinsey Perspectives newsletter, formerly known as Only McKinsey.
Copyright © 2025 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "Only McKinsey Perspectives" <publishing@email.mckinsey.com> - 01:48 - 21 Mar 2025 -
(Video #4 Funnel Install) Pedro Adao’s Challenge Funnel!
How he turned a challenge into 42K customers!

It’s the first official day of Spring! I love it!
And even better… Holy cow!! This Funnel Install series keeps getting crazier!
So far, you’ve seen:
✅ Day 1 - Trey Lewellen’s e-commerce funnel
✅ Day 2 - Dan Henry's webinar funnel
✅ Day 3 - Jeff Walker’s product launch funnel
Next in line is Pedro Adao
Now, it’s time to hear from Jeff Walker!
GO HERE TO WATCH THE VIDEO FROM PEDRO ADAO AND STEAL HIS CHALLENGE FUNNEL FOR FREE! >>

So… what was his secret???
Challenges!
Pedro used a Challenge Funnel, and today he’s breaking down exactly how it works FOR YOU!
In his video, you’ll see how he turned a simple free challenge into 42,000 paying customers.
And remember… He did it without a massive following, expensive ads, or complicated tech.
(Hint: If you don’t have any of that, you can still crush it using challenges!)
Oh yea… And he’s giving you his exact Challenge Funnel template… TOTALLY FREE!!!
GO HERE TO WATCH THE VIDEO FROM PEDRO ADAO AND STEAL HIS CHALLENGE FUNNEL FOR FREE! >>
We’re only on Day 4… and the next few days are gonna be just as awesome!
See you tomorrow for the next funnel drop!
Russell Brunson
P.S. - Don’t forget, you’re just one funnel away….
P.P.S - To dive in and start implementing what these experts are teaching, you’ll need to get a ClickFunnels account. If you don’t have one yet, I have a special 2-week FREE TRIAL link HERE >>
© Etison LLC
By reading this, you agree to all of the following: You understand this to be an expression of opinions and not professional advice. You are solely responsible for the use of any content and hold Etison LLC and all members and affiliates harmless in any event or claim.
If you purchase anything through a link in this email, you should assume that we have an affiliate relationship with the company providing the product or service that you purchase, and that we will be paid in some way. We recommend that you do your own independent research before purchasing anything.
Copyright © 2018+ Etison LLC. All Rights Reserved.
To make sure you keep getting these emails, please add us to your address book or whitelist us. If you don't want to receive any other emails, click on the unsubscribe link below.
Etison LLC
3443 W Bavaria St
Eagle, ID 83616
United States
by "Russell @ ClickFunnels" <noreply@clickfunnelsnotifications.com> - 11:07 - 20 Mar 2025 -
Virtual Summit: Integration Insights Live
Join us on April 3 to see how a modern iPaaS powers transformation.
 With every new app, your IT landscape becomes more complex—but managing it doesn’t have to be.
With every new app, your IT landscape becomes more complex—but managing it doesn’t have to be.
Join us for an exclusive series of virtual events dedicated to the transformative power of integration. Explore how an integration platform as-a-service (iPaaS) can drive the modernization of your IT infrastructure and create a solid foundation for future innovation. Across five expert-led sessions, explore the latest research, trends, and strategies, to learn about:
- Gaining critical strategic value from a comprehensive integration platform
- Connecting both SAP and non-SAP applications with available adapters and connectors
- Unlocking the potential of AI with integration
Integration Insights Live: Innovate with a Modern iPaaS
April 3, 2025
[Time TZ1 | Time TZ2 | Time TZ3]
Kind regards,
The SAP Integration Suite teamWant to know more?
Find out how SAP Integration Suite gives you everything you need to modernize your business in this short video.
Contact us
See our complete list of local country numbers



SAP (Legal Disclosure | SAP)
This e-mail may contain trade secrets or privileged, undisclosed, or otherwise confidential information. If you have received this e-mail in error, you are hereby notified that any review, copying, or distribution of it is strictly prohibited. Please inform us immediately and destroy the original transmittal. Thank you for your cooperation.
You are receiving this e-mail for one or more of the following reasons: you are an SAP customer, you were an SAP customer, SAP was asked to contact you by one of your colleagues, you expressed interest in one or more of our products or services, or you participated in or expressed interest to participate in a webinar, seminar, or event. SAP Privacy Statement
This email was sent to info@learn.odoo.com on behalf of the SAP Group with which you have a business relationship. If you would like to have more information about your Data Controller(s) please click here to contact webmaster@sap.com.
This e-mail was sent to info@learn.odoo.com by SAP and provides information on SAP’s products and services that may be of interest to you. If you received this e-mail in error, or if you no longer wish to receive communications from the SAP Group of companies, you can unsubscribe here.
To ensure you continue to receive SAP related information properly, please add sap@mailsap.com to your address book or safe senders list.
by "SAP Integration Suite team" <sap@mailsap.com> - 08:12 - 20 Mar 2025 -
Monolith vs Microservices vs Modular Monoliths: What's the Right Choice
Monolith vs Microservices vs Modular Monoliths: What's the Right Choice
In the ever-evolving landscape of software development, the choice of architecture can make or break a project.͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ Forwarded this email? Subscribe here for moreLatest articles
If you’re not a subscriber, here’s what you missed this month.
Dark Side of Distributed Systems: Latency and Partition Tolerance
Non-Functional Requirements: The Backbone of Great Software - Part 2
Non-Functional Requirements: The Backbone of Great Software - Part 1
To receive all the full articles and support ByteByteGo, consider subscribing:
In the ever-evolving landscape of software development, the choice of architecture can make or break a project.
It’s not merely a technical decision but a strategic one that shapes how efficiently a team can build, scale, and maintain an application. Whether crafting a simple tool or a complex system, the architecture selected lays the groundwork for everything that follows.
The architecture chosen influences not only how software is built but also how it grows and runs over time. A misstep can result in sluggish performance, tangled codebases, and frustrated teams. On the other hand, the right choice can streamline development, support seamless scaling, and make maintenance easier.
In this article, we explore the three key architectural styles: Monolith, Microservices, and Modular Monoliths. Each offers distinct approaches to structuring software, with unique benefits and challenges.
We’ll also examine the strengths and weaknesses of each approach, from the ease of a monolith to the resilience of microservices and the balanced design of a modular monolith. We’ll look at scenarios where switching from one architecture to another makes sense, equipping us with practical insights for navigating these critical decisions.
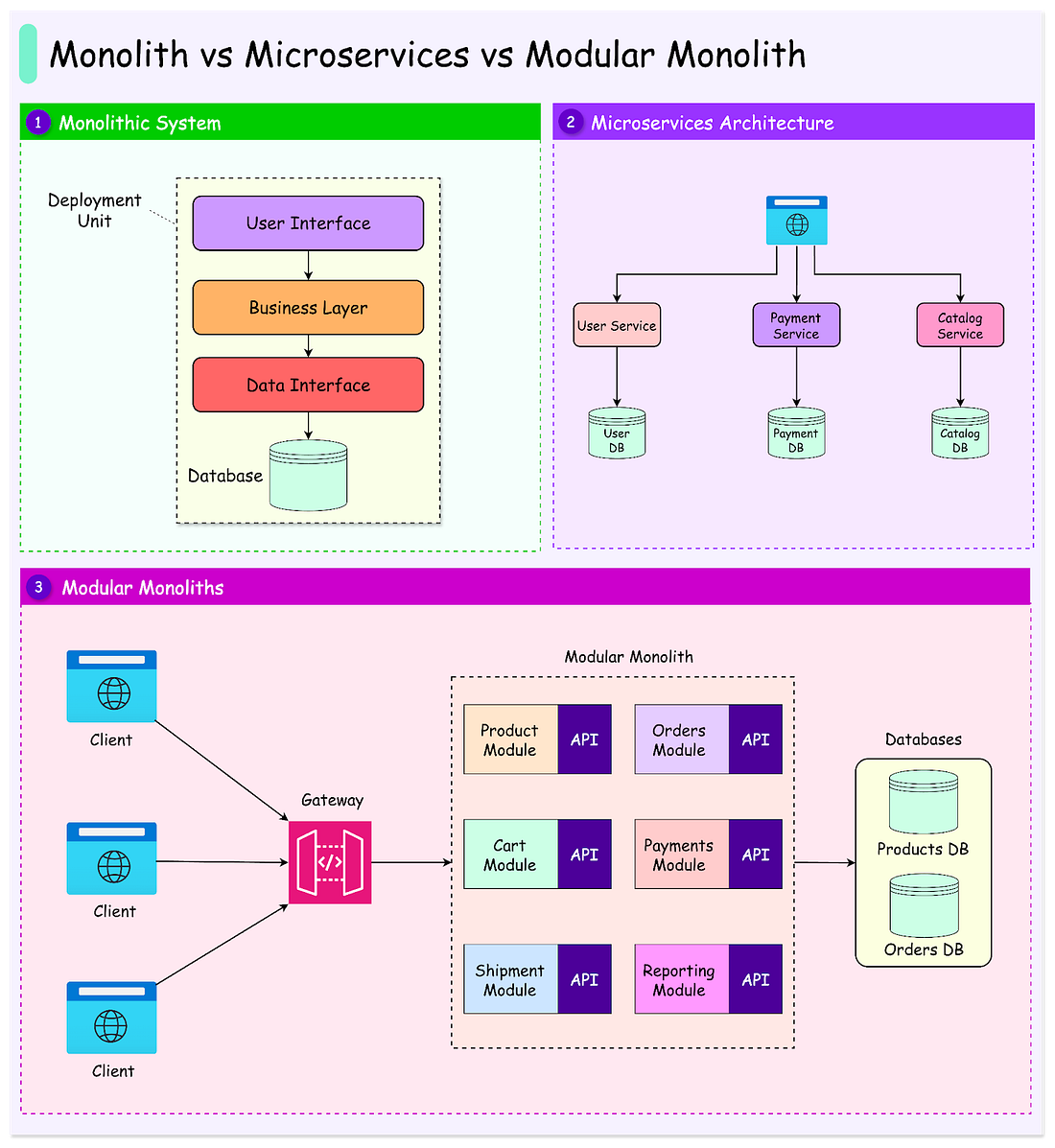
Monolithic Architecture...

Continue reading this post for free in the Substack app
© 2025 ByteByteGo
548 Market Street PMB 72296, San Francisco, CA 94104
Unsubscribe
by "ByteByteGo" <bytebytego@substack.com> - 11:37 - 20 Mar 2025 -
API governance doesn’t have to be hard. Let’s show you how
API governance doesn’t have to be hard. Let’s show you how
Unlock the secrets to scaling your API governance - without the headache!
Hi Md Abul,
Did you hear? We’re hosting a webinar that’s all about transforming the way you manage APIs. If you’ve been thinking about how to bring some control to your API ecosystem (without losing your sanity), then this one’s for you.
From chaos to confidence: Accelerating API governance maturity with Tyk
In this session, we’ll show you how a universal API governance platform can help your enterprise stay ahead of the game in today’s evolving API landscape. And let’s face it - staying ahead is the only option, right?
Why a universal API governance platform is key to keeping things consistent, secure, and future-ready.

How the API Governance Toolkit helps you level up your governance across teams and environments.

Strategies for enforcing governance at scale (no more chaos, promise).

How Tyk’s platform can make all of this easier, faster, and more reliable.
Plus, Budha Bhattacharya (our Developer Advocate) and Mark Boyd (API governance expert) will share practical insights about the realities of universal governance - what works, what doesn’t, and how you can put it all into action. Then, Carol Cheung (Tyk’s Senior Product Manager) will take you behind the scenes with a sneak peek at Tyk’s Universal API Governance Platform.
Ready to discover how to make governance easier and more scalable? We thought so.
📅 Date: March 27th 2025🕙 Time: 10 am EST/ 2 pm GMT
📍 Location: Zoom webinar, discussion, demo
See you in a week!,
Budha and team





Tyk, Huckletree 199 Bishopsgate, Broadgate, London, City of London EC2M 3TY, United Kingdom, +44 (0)20 3409 1911
by "Budha from Tyk" <budha@tyk.io> - 07:00 - 20 Mar 2025 -
(Video #3 Funnel Install) Jeff Walker’s Product Launch Funnel!
Jeff cracked the code on million-dollar launches!
What’s up! Have you been loving the emails coming this week!?
On Day 1 Trey Lewellen broke down his Ecom funnel.
On Day 2 Dan Henry revealed his Webinar funnel.
Now, it’s time to hear from Jeff Walker!
GO HERE TO WATCH THE VIDEO FROM JEFF WALKER AND STEAL HIS PRODUCT LAUNCH FUNNEL FOR FREE! >>

I’m pretty sure Jeff literally invented the concept of a product launch funnel!!
But here’s the crazy part… You’ll see when you watch the video, but Jeff wasn’t some natural-born marketer. When he started, he was a stay-at-home dad with NO marketing experience, NO product, and NO clue how to sell…
But that didn’t stop him (super inspiring for a lot of people in his situation!)
His first launch made $1,650…
Then $6,000…
Then $34,000…
And eventually…
He had a million-dollar launch in a single hour!!!
And now in today’s video, he’s handing YOU the keys to the exact Product Launch Funnel template that’s been responsible for over a billion dollars in sales!!
GO HERE TO WATCH THE VIDEO FROM JEFF WALKER AND STEAL HIS PRODUCT LAUNCH FUNNEL FOR FREE! >>
This is just Day 3! We have 4 more to go! 🤯
Tomorrow, another top expert will break down their most successful funnel… so don’t miss it!
See you then!
Russell Brunson
P.S. - Don’t forget, you’re just one funnel away….
P.P.S - To dive in and start implementing what these experts are teaching, you’ll need to get a ClickFunnels account. If you don’t have one yet, I have a special 2-week FREE TRIAL link HERE >>
© Etison LLC
By reading this, you agree to all of the following: You understand this to be an expression of opinions and not professional advice. You are solely responsible for the use of any content and hold Etison LLC and all members and affiliates harmless in any event or claim.
If you purchase anything through a link in this email, you should assume that we have an affiliate relationship with the company providing the product or service that you purchase, and that we will be paid in some way. We recommend that you do your own independent research before purchasing anything.
Copyright © 2018+ Etison LLC. All Rights Reserved.
To make sure you keep getting these emails, please add us to your address book or whitelist us. If you don't want to receive any other emails, click on the unsubscribe link below.
Etison LLC
3443 W Bavaria St
Eagle, ID 83616
United States
by "Russell @ ClickFunnels" <noreply@clickfunnelsnotifications.com> - 06:33 - 20 Mar 2025 -
Back link
Hey'
Are you want promote your website or want to rank on google .no need for further search here you will get google news site guest posts with do-follow backlinks. For getting the first position.
You need to get high- authority guest posts with do-follow backlinks. Google News-approved site is trusted by google Getting top quality backlinks from google's trusted is a million of times better than offer sites we will publish high DA guest posts on the DA 50-60 website with a do-follow backlink.The backlink would be permanent and it will be indexed in google.Not. I have many other sites besides this one.
I have many sites that will suit your budgetLet me know i have to wait your response .
Best regards
Hire backlinks expert
Rank your website [Backlinks expert]
Promote your website thought guest popostingList.
Contact.zainghumro4@gmail.com
WhatsApp. +923080825429
Fb.https://www.facebook.com/zain.ghumro.50?mibextipoposting
by "zain ghumro" <zainghumro4@gmail.com> - 04:44 - 20 Mar 2025 -
Order to Cash (O2C) Software
Hi.We have released our latest Order to Cash (O2C) Software Product Analysis.This report studies the Order to Cash (O2C) Software Capacity, Production, Volume, Sales, Price and future trends in global market. Focuses on the key global manufacturers, to analyse the product Characteristics, Product Specifications, Price, Volume, Sales revenue and market share of key manufacturers in global market. Historical data is from 2020 to 2024 and forecast data is from 2025 to 2031.If you are interested to know more, a sample as well as a quotation can be provided for your reference.The analysis presents profiles of competitors in the Fields, key players include:NewgenEmersonHighRadiusSidetradeEskerTradeshiftEmagiaSerralaNitroboxHubiFiVersapayTrayExela TechnologiesFazeshiftmindzie……----------------------------------Best regards / Mit freundlichen Grüßen / 此致敬意,Xin | Manager-Global SalesVic Market Research Co.,Ltd.E: xin@vicmarketresearch.comT:+86-15323335301 (7*24)GLOBAL LEADING MARKET RESEARCH PUBLISHER
by "Basil" <basil@forecastingreport.com> - 02:14 - 20 Mar 2025 -
Gen AI: How organizations are capturing value
On McKinsey Perspectives
New risk-focused roles Brought to you by Alex Panas, global leader of industries, & Axel Karlsson, global leader of functional practices and growth platforms
Welcome to the latest edition of Only McKinsey Perspectives. We hope you find our insights useful. Let us know what you think at Alex_Panas@McKinsey.com and Axel_Karlsson@McKinsey.com.
—Alex and Axel
•
Accelerating AI adoption. The latest McKinsey Global Survey on AI finds that organizations are starting to implement structural changes that are aimed at generating future value from gen AI, with large companies leading the way. Alex Singla, a global leader of QuantumBlack, AI by McKinsey, and coauthors explain that companies’ use of AI continues to accelerate. More than three-quarters of the survey’s respondents report that their companies use AI in at least one business function. Their responses also show that the business uses of AI—gen AI, in particular—are increasing rapidly.
—Edited by Belinda Yu, editor, Atlanta
This email contains information about McKinsey's research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this email because you subscribed to the Only McKinsey Perspectives newsletter, formerly known as Only McKinsey.
Copyright © 2025 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "Only McKinsey Perspectives" <publishing@email.mckinsey.com> - 01:06 - 20 Mar 2025 -
Tailored Seating Solutions for Your Projects
Dear info,
I hope this message finds you well.
I’m reaching out to introduce our company, a specialist in manufacturing customized seating solutions for auditoriums, theaters, and conference rooms.
Our range, from auditorium chairs to theater seating, is crafted to meet a variety of project needs, all with a strong emphasis on quality craftsmanship and client satisfaction.
I would be delighted to discuss how we can work together to tailor our seating solutions to your specific requirements. Please feel free to contact me to explore customization options and to discuss your upcoming projects.
Best regards,
Luis
WhatsApp: 0086-13925149983
E-mail: luis@springfurnitures.comWebsite: www.springfurnitures.com
by "Fujana shanr" <4750119@gmail.com> - 05:18 - 19 Mar 2025 -
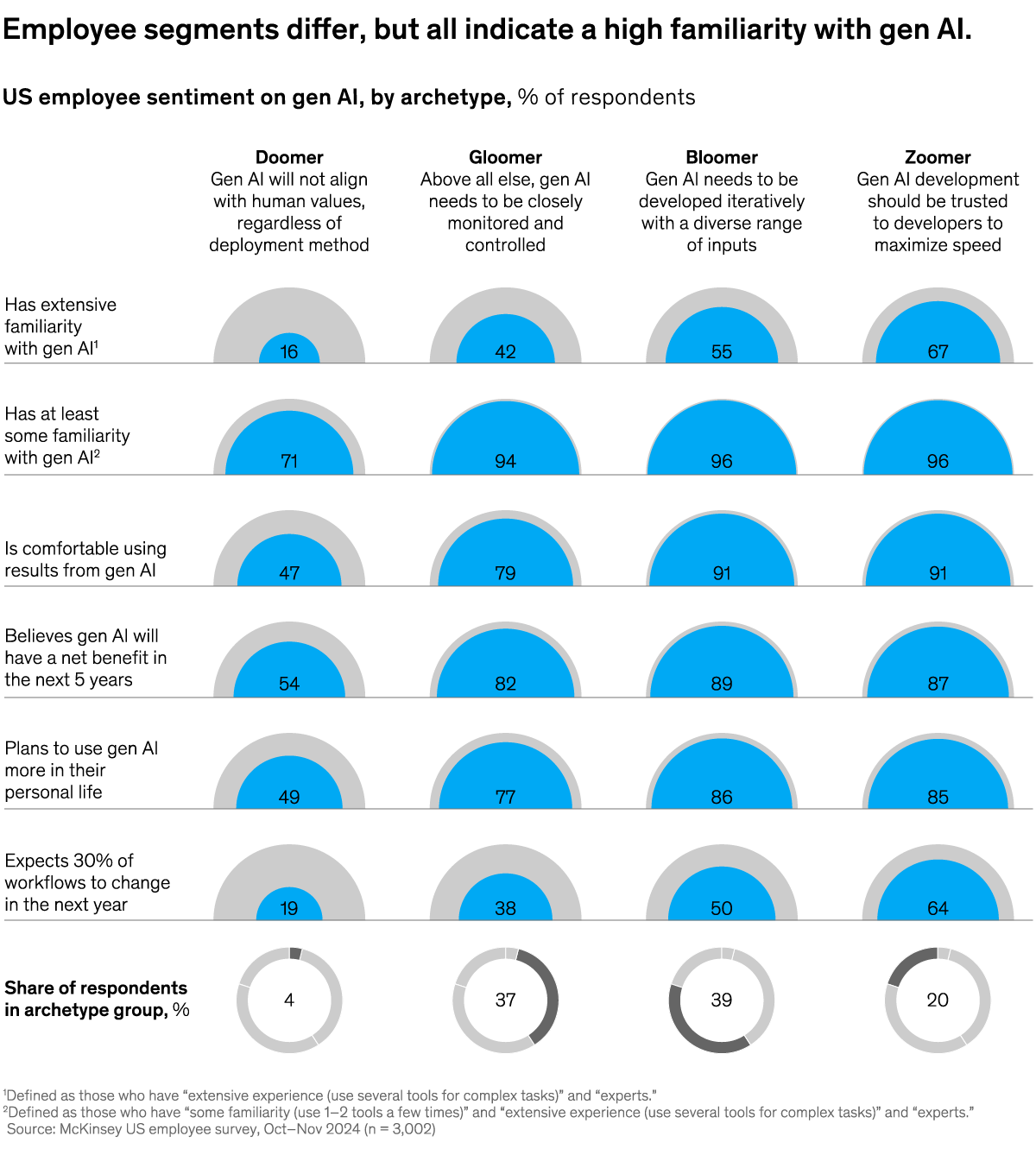
Employees are already using AI. How can leaders catch up?
Five Fifty
Get your briefing Many workers are already using AI, and business leaders who act on this momentum face a significant opportunity. Identifying four archetypes of employee sentiment can help companies understand where encouragement might be needed, say McKinsey’s Hannah Mayer, Lareina Yee, Michael Chui, and Roger Roberts. To learn more, check out the latest edition of the Five Fifty.
Share these insights
Did you enjoy this newsletter? Forward it to colleagues and friends so they can subscribe too. Was this issue forwarded to you? Sign up for it and sample our 40+ other free email subscriptions here.
This email contains information about McKinsey’s research, insights, services, or events. By opening our emails or clicking on links, you agree to our use of cookies and web tracking technology. For more information on how we use and protect your information, please review our privacy policy.
You received this email because you subscribed to our McKinsey Quarterly Five Fifty alert list.
Copyright © 2025 | McKinsey & Company, 3 World Trade Center, 175 Greenwich Street, New York, NY 10007
by "McKinsey Quarterly Five Fifty" <publishing@email.mckinsey.com> - 05:03 - 19 Mar 2025